Estimating Avocado Sales Using Machine Learning Algorithms and Weather Data


Abstract
:
1. Introduction
2. Materials and Methods
2.1. Data Sources
2.2. Data Selection and Cleaning
- Searching for missing values: blank spaces, words such as “NaN” or “null” and special characters such as “*” or “?” were searched for, as to verify if there were any missing values in the datasets. There was missing data only on the weather; this may be due to failures in the operation of the meteorological stations that capture such data. Since there was little data missing (a total of five records), we decided to delete those instances in both the weather and the market data. Finally, no data imputation process was implemented.
- Outliers detection: to detect if there were values that significantly deviated from the others, we used Clustering (DBSCAN, Density-based spatial clustering of applications with noise) and Distance (LOF, Local Outlier Factor) algorithms. No outliers or extreme values were found for the two datasets.
- Searching for duplicated instances: We used a filter in order to detect if there were repeated instances. The filter found no instances with this problem, since we constructed the datasets carefully and imputation algorithms were not implemented in the previous steps.
- Dimensionality reduction: an algorithm for this task was applied. Typically, the algorithm searches for a subset of most relevant features to represent the dataset. The objective is to contribute to learning accuracy. Considering the limited data dimensionality of the datasets used, the dimensionality was not reduced.
2.3. Dataset Construction
3. Results
3.1. Modeling for the Forecasting of the Avocado Market
- Linear Regression: a technique used to determine the relationship of a y variable with one or many other x1, …, xk variables. In a machine learning approach, it searches for several functions that model the relationship between the variables and selects the one that most closely approximates to or fits the data given in the class [19].
- Multilayer Perceptron: consists of units, called neurons, interconnected and organized in layers. Each neuron processes information, converting the input it receives into processed output. Through the links of neurons, knowledge is generated [20].
- Support Vector Machine for Regression: these algorithms seek to estimate a function from a training data. For this purpose, an initial set of points is required, which also contains two other subsets of points and which belongs to one of two possible classes. Based on these, the support vector machine creates a hyper-plane in order to find the largest distance separating the classes and thus builds a model that is capable of predicting which class a new point belongs to [21].
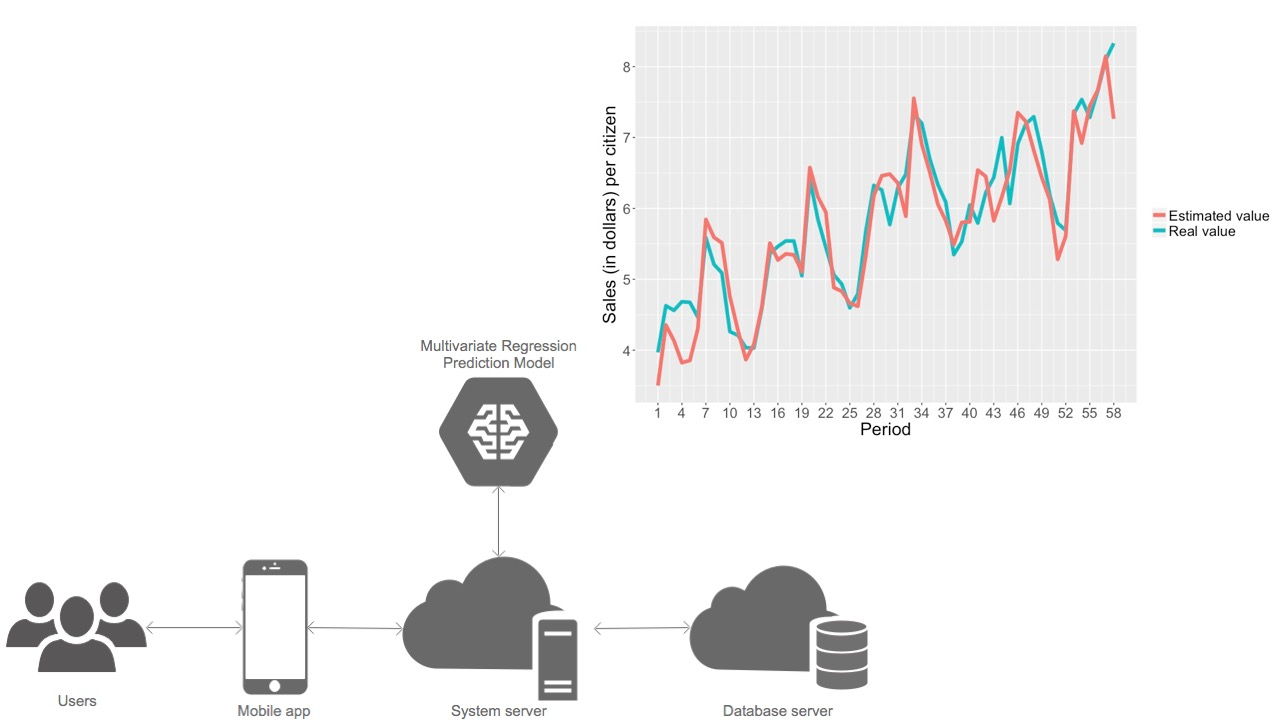
- Multivariate Regression Prediction Model: an algorithm that associates traditional decision trees with linear regression functions. To some special nodes, commonly known as leaves, the algorithm assigns a probability vector that indicates the chances that a class will take a certain value. The instances are classified following a path from the root of the tree to a leaf, according to the results of the tests performed in each of the test nodes [22].
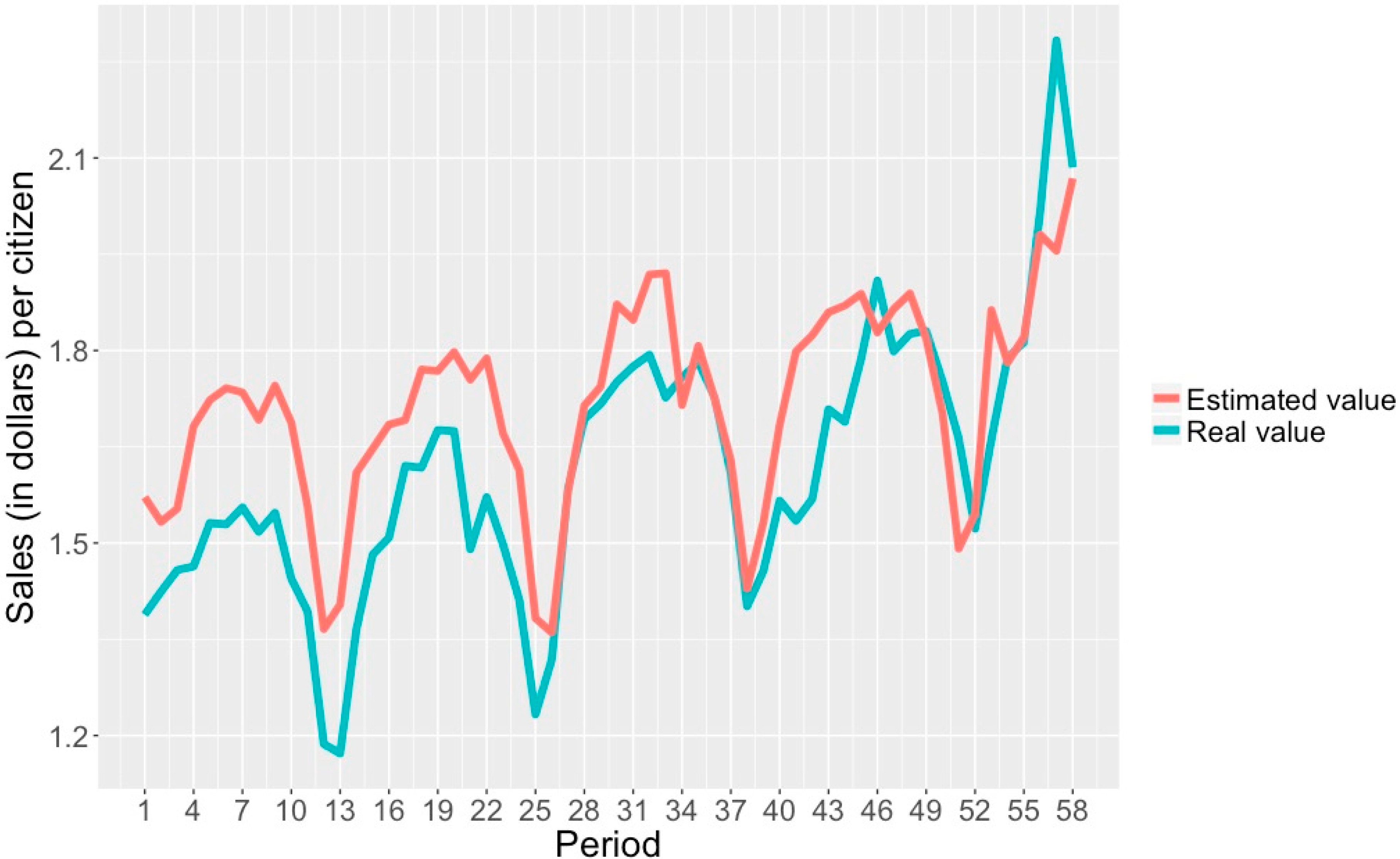
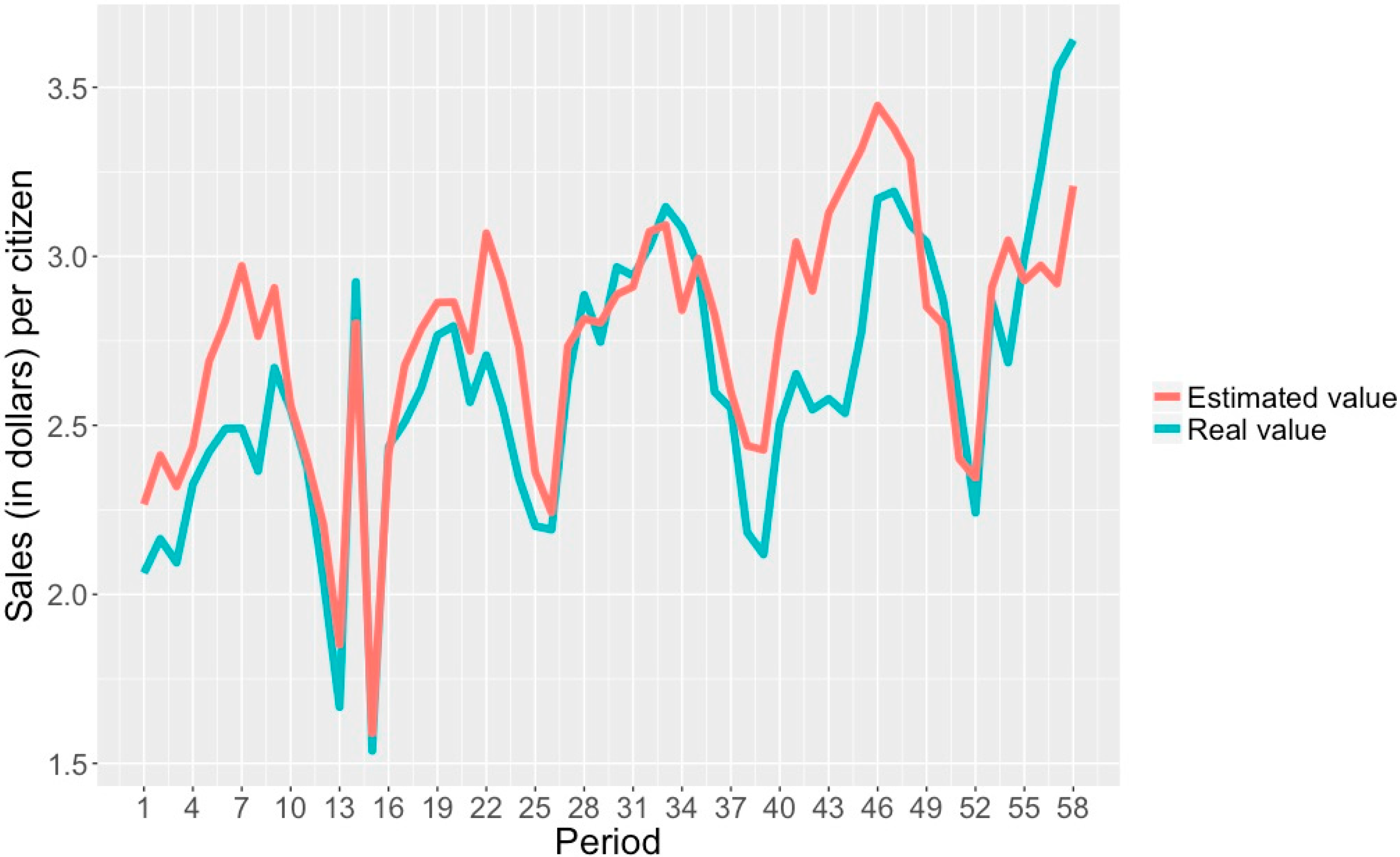
- A correlation coefficient of 0.991, which indicates a high correlation between the attributes and the class studied.
- An MAE of 0.564, showing the average difference of units/inhabitant between an estimated and a real class.
- An RAE of 11.832%, indicating the percentage at which an estimated and a real class can differ.
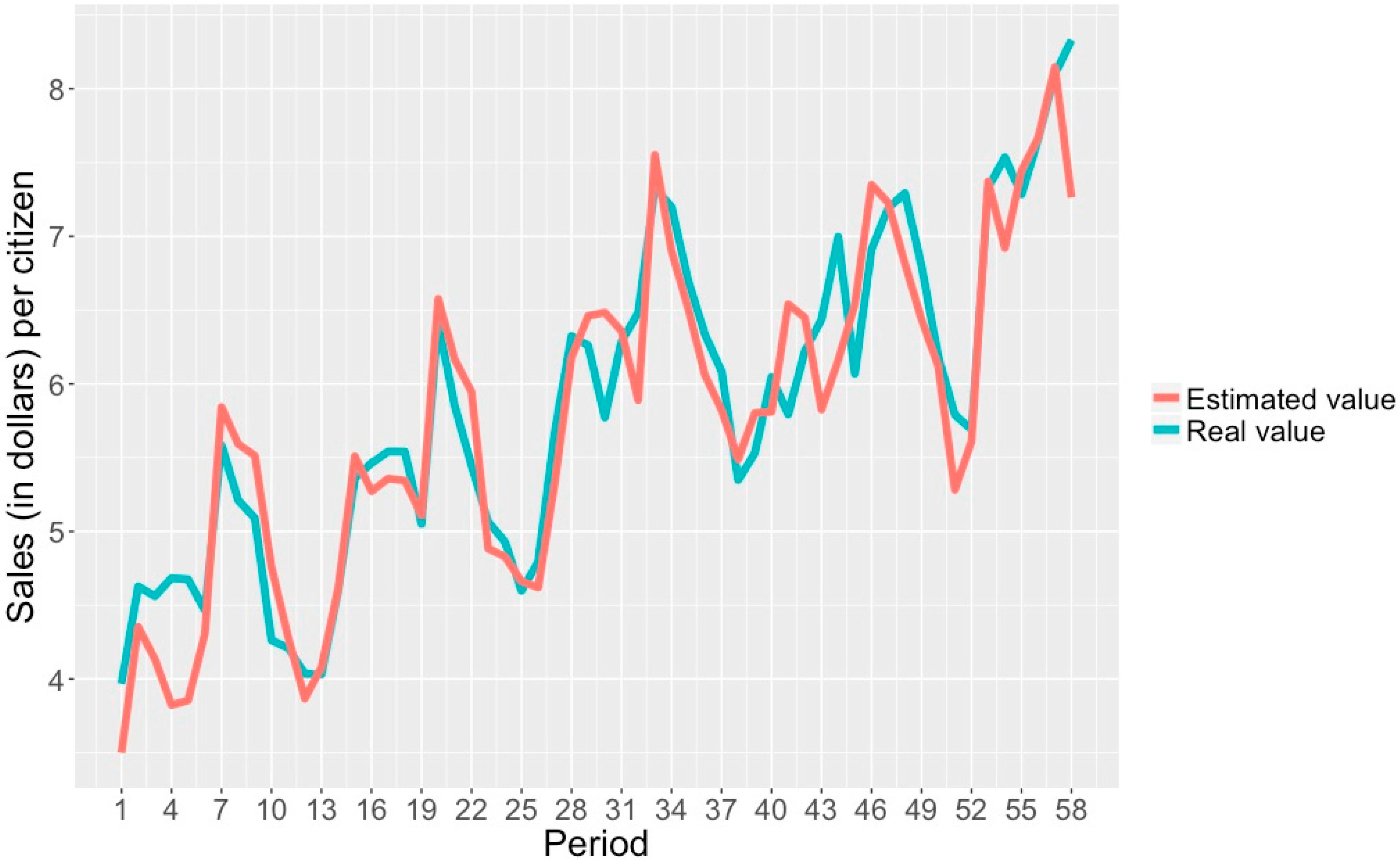
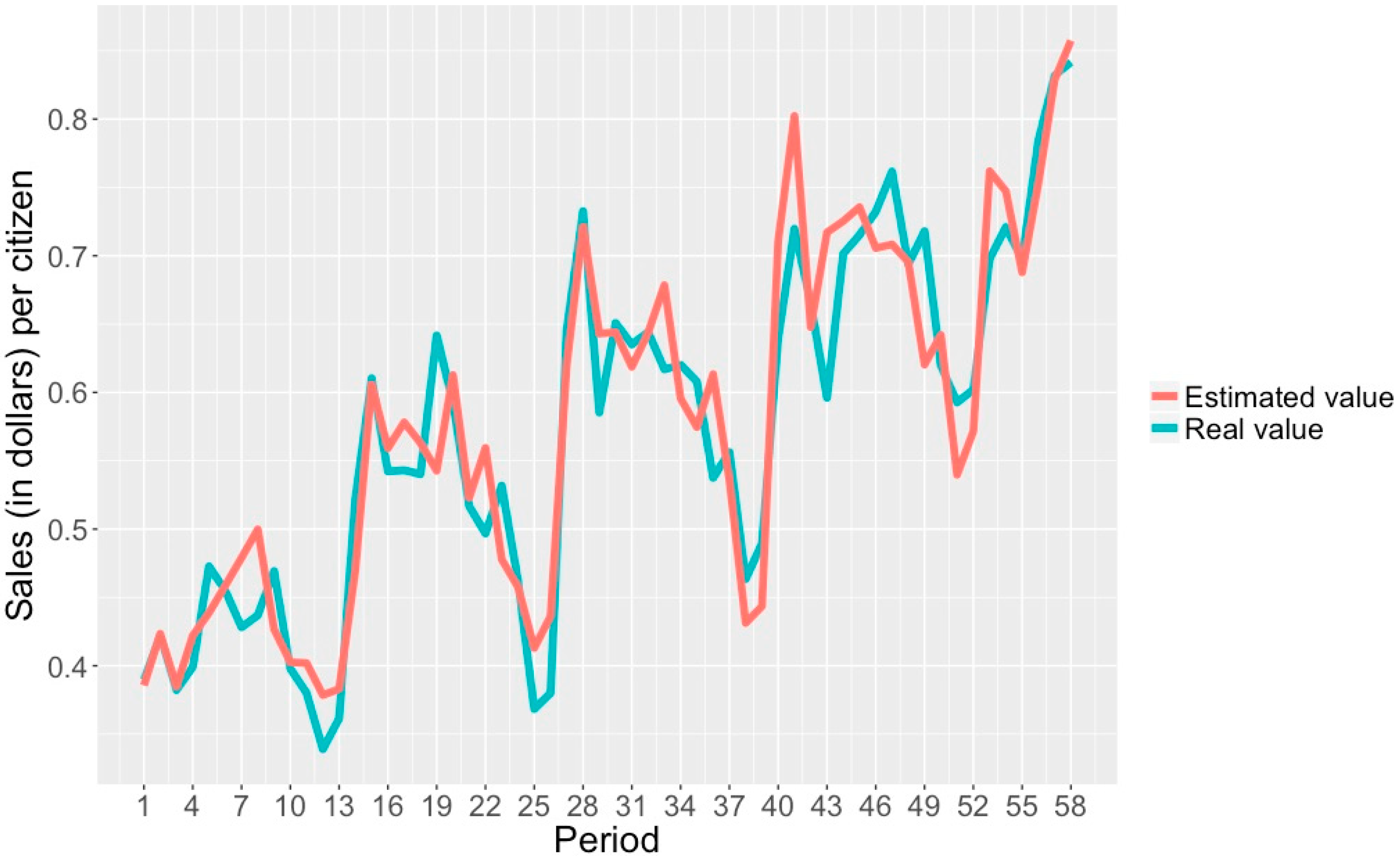
- A correlation coefficient of 0.996, which shows a high correlation between attributes and class.
- An MAE of 0.420, which indicates the average sales/inhabitant difference between an estimated class and a real class.
- An RAE of 7.812%, showing the percentage at which an estimated and a real class can differ.
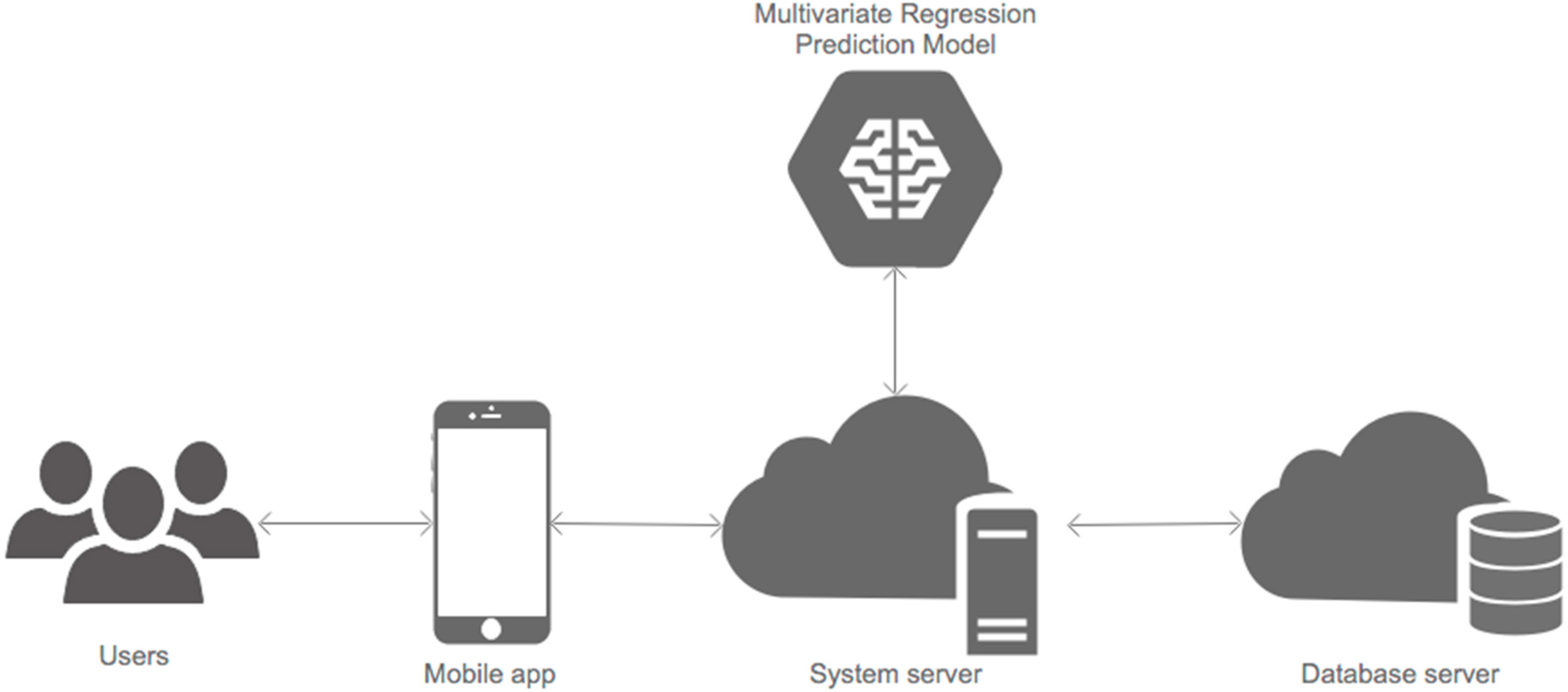
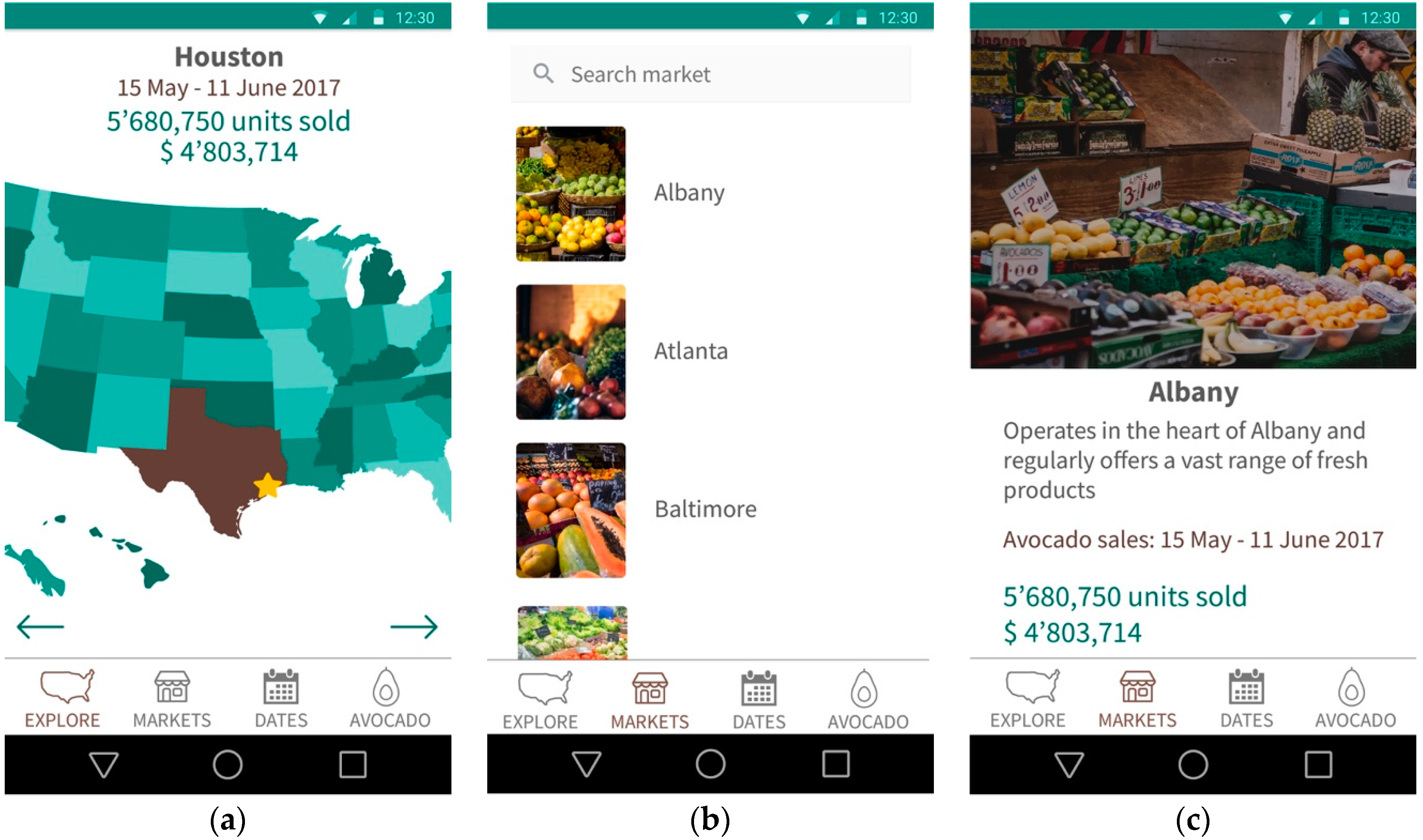
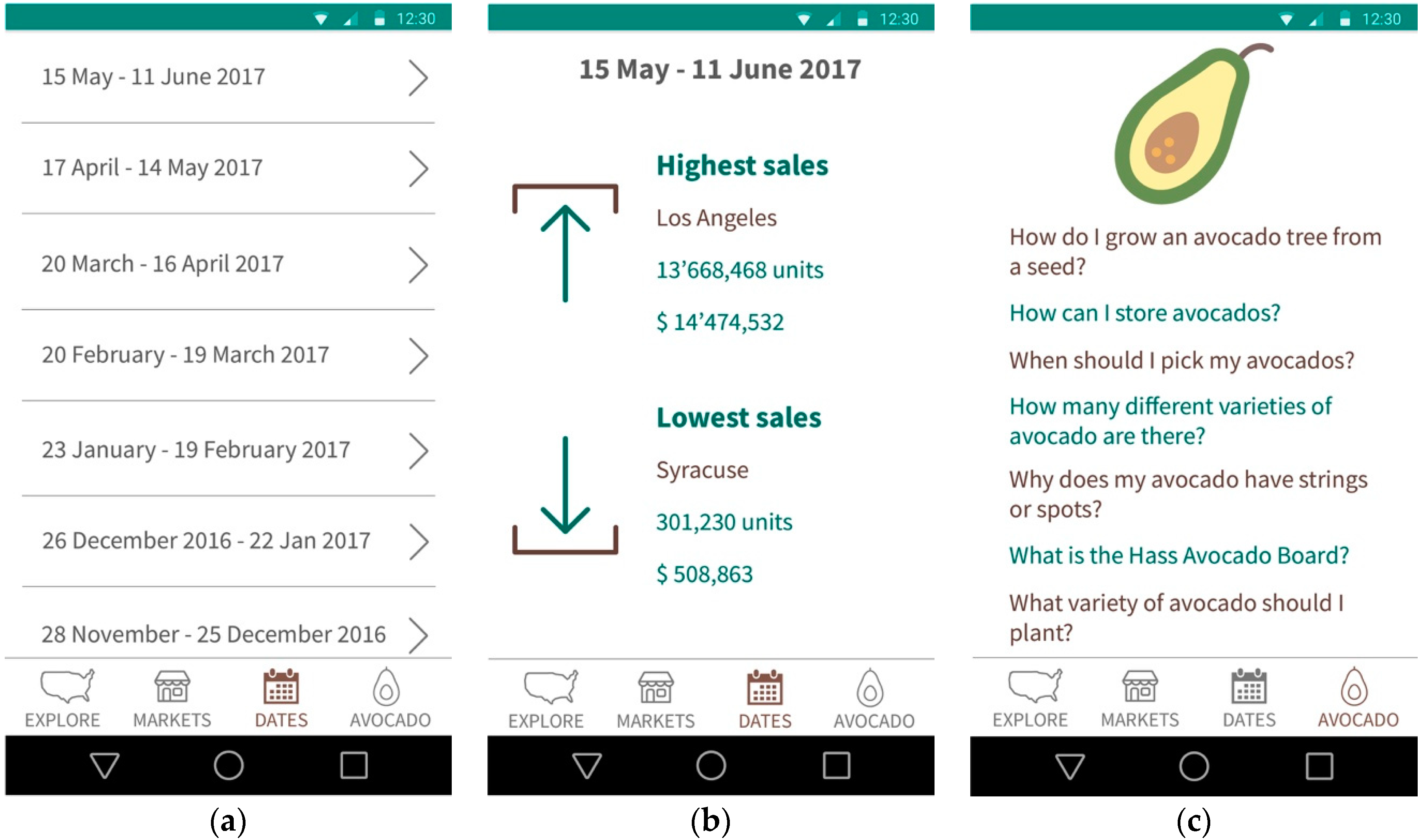
3.2. Mobile Application
4. Discussion and Future Works
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dreher, M.L.; Davenport, A.J. Hass avocado composition and potential health effects. Crit. Rev. Food Sci. Nutr. 2013, 53, 738–750. [Google Scholar] [CrossRef] [PubMed]
- Ayala Silva, T.; Ledesma, N. Avocado History, Biodiversity and Production. In Sustainable Horticultural Systems: Issues, Technology and Innovation; Nandwani, D., Ed.; Springer International Publishing: Cham, Switzerland, 2014; pp. 157–205. ISBN 978-3-319-06904-3. [Google Scholar]
- Cavaletto, G. The avocado market in the United States. In Proceedings of the VIII Congreso Mundial de la Palta 2015, Lima, Peru, 13–18 September 2015; pp. 463–466. Available online: http://www.avocadosource.com/WAC8/Section_07/CavalettoGiovanni2015.pdf (accessed on 28 September 2018).
- Furuya, J.; Kobayashi, S.; Yamauchi, K. Impacts of climate change on rice market and production capacity in the Lower Mekong Basin. Paddy Water Environ. 2014, 12, 255–274. [Google Scholar] [CrossRef]
- Kang, S.H.; Jiang, Z.; Lee, Y.; Yoon, S.-M. Weather effects on the returns and volatility of the Shanghai stock market. Phys. A Stat. Mech. Appl. 2010, 389, 91–99. [Google Scholar] [CrossRef]
- Murray, K.B.; Di Muro, F.; Finn, A.; Leszczyc, P.P. The effect of weather on consumer spending. J. Retail. Consum. Serv. 2010, 17, 512–520. [Google Scholar] [CrossRef] [Green Version]
- Symeonidis, L.; Daskalakis, G.; Markellos, R.N. Does the weather affect stock market volatility? Financ. Res. Lett. 2010, 7, 214–223. [Google Scholar] [CrossRef] [Green Version]
- Corrales, D.C.; Corrales, J.C.; Figueroa-Casas, A. Towards Detecting Crop Diseases and Pest by Supervised Learning. Ing. Univ. 2015, 19, 207–228. [Google Scholar] [CrossRef]
- Plazas, J.E.; López, I.D.; Corrales, J.C. A Tool for Classification of Cacao Production in Colombia Based on Multiple Classifier Systems. In Computational Science and Its Applications—ICCSA 2017, Proceedings of International Conference on Computational Science and Its Applications, Trieste, Italy, 3–6 July 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 60–69. ISBN 978-3-319-62395-5. [Google Scholar]
- Corrales, D.C.; Casas, A.F.; Ledezma, A.; Corrales, J.C. Two-Level Classifier Ensembles for Coffee Rust Estimation in Colombian Crops. Int. J. Agric. Environ. Inf. Syst. 2016, 7, 41–59. [Google Scholar] [CrossRef]
- Lasso, E.; Valencia, Ó.; Corrales, J.C. Decision Support System for Coffee Rust Control Based on Expert Knowledge and Value-Added Services. In Computational Science and Its Applications—ICCSA 2017, Proceedings of International Conference on Computational Science and Its Applications, Trieste, Italy, 3–6 July 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 70–83. ISBN 978-3-319-62395-5. [Google Scholar]
- Carman, H.; Li, L.; Sexton, R. Can Improved Market Information Benefit Both Producers and Consumers? Evidence from the Hass Avocado Board’s Internet Information Program. Agric. Resour. Econ. Updat. 2010, 13, 5–8. [Google Scholar]
- Carman, H. California farmers adapt mandated marketing programs to the 21st century. Calif. Agric. 2007, 61, 177–183. [Google Scholar] [CrossRef] [Green Version]
- Chapman, P.; Clinton, J.; Kerber, R.; Khabaza, T.; Reinartz, T.; Shearer, C.; Wirth, R. CRISP-DM 1.0 Step-by-Step Data Mining Guide; SPSS: Armonk, NY, USA, 2000. [Google Scholar]
- Corrales, D.C.; Corrales, J.C.; Ledezma, A. How to Address the Data Quality Issues in Regression Models: A Guided Process for Data Cleaning. Symmetry 2018, 10, 99. [Google Scholar] [CrossRef]
- Rasouli, K.; Hsieh, W.W.; Cannon, A.J. Daily streamflow forecasting by machine learning methods with weather and climate inputs. J. Hydrol. 2012, 414–415, 284–293. [Google Scholar] [CrossRef]
- Skrepnek, G.H. Regression methods in the empiric analysis of health care data. J. Manag. Care Pharm. 2005, 11, 240–251. [Google Scholar] [CrossRef] [PubMed]
- Clark, J.E.; Osborne, J.W.; Gallagher, P.; Watson, S. A simple method for optimising transformation of non-parametric data: An illustration by reference to cortisol assays. Hum. Psychopharmacol. 2016, 31, 259–267. [Google Scholar] [CrossRef] [PubMed]
- Benjamini, Y.; Leshno, M. Statistical Methods for Data Mining. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: Boston, MA, USA, 2005; pp. 565–587. ISBN 978-0-387-25465-4. [Google Scholar]
- Zhang, G.P. Neural Networks for Data Mining. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: Boston, MA, USA, 2010; pp. 419–444. ISBN 978-0-387-09823-4. [Google Scholar]
- Shmilovici, A. Support Vector Machines. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: Boston, MA, USA, 2005; pp. 257–276. ISBN 978-0-387-25465-4. [Google Scholar]
- Rokach, L.; Maimon, O. Classification Trees. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: Boston, MA, USA, 2010; pp. 149–174. ISBN 978-0-387-09823-4. [Google Scholar]
- Kohavi, R. A Study of Cross-validation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1995; pp. 1137–1143. [Google Scholar]
- Guazzelli, A.; Zeller, M.; Lin, W.-C.; Williams, G. PMML: An Open Standard for Sharing Models. R. J. 2009, 1, 60–65. [Google Scholar]
- Behnamian, J.; Ghomi, S.M.T.F. Development of a PSO–SA hybrid metaheuristic for a new comprehensive regression model to time-series forecasting. Expert Syst. Appl. 2010, 37, 974–984. [Google Scholar] [CrossRef]
- Chen, R.; Liang, C.-Y.; Hong, W.-C.; Gu, D.-X. Forecasting holiday daily tourist flow based on seasonal support vector regression with adaptive genetic algorithm. Appl. Soft Comput. 2015, 26, 435–443. [Google Scholar] [CrossRef]
- Liu, D.; Niu, D.; Wang, H.; Fan, L. Short-term wind speed forecasting using wavelet transform and support vector machines optimized by genetic algorithm. Renew. Energy 2014, 62, 592–597. [Google Scholar] [CrossRef]
- Langkvist, M.; Karlsson, L.; Loutfi, A. A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recognit. Lett. 2014, 42, 11–24. [Google Scholar] [CrossRef] [Green Version]
- Choi, T.; Hui, C.; Yu, Y. Intelligent time series fast forecasting for fashion sales: A research agenda. In Proceedings of the 2011 International Conference on Machine Learning and Cybernetics, Guilin, China, 10–13 July 2011; pp. 1010–1014. [Google Scholar]
- Kaneko, Y.; Yada, K. A Deep Learning Approach for the Prediction of Retail Store Sales. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 531–537. [Google Scholar]
- Gao, M.; Xu, W.; Fu, H.; Wang, M.; Liang, X. A Novel Forecasting Method for Large-Scale Sales Prediction Using Extreme Learning Machine. In Proceedings of the 2014 Seventh International Joint Conference on Computational Sciences and Optimization, Beijing, China, 4–6 July 2014; pp. 602–606. [Google Scholar]
- Gurnani, M.; Korke, Y.; Shah, P.; Udmale, S.; Sambhe, V.; Bhirud, S. Forecasting of sales by using fusion of machine learning techniques. In Proceedings of the 2017 International Conference on Data Management, Analytics and Innovation (ICDMAI), Pune, India, 24–26 February 2017; pp. 93–101. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Attributes | Class |
|---|---|---|
| 1 | Weather (maximum temperature, minimum temperature, average temperature, maximum humidity, minimum humidity, average humidity and precipitation) and Units-py | Units-cy |
| 2 | Weather and Sales-py | Sales-cy |
| 3 | Weather and Ln(Units-py) | Ln(Units-cy) |
| 4 | Weather and Ln(Sales-py) | Ln(Sales-cy) |
| 5 | Weather and Units-py/population | Units-cy/population |
| 6 | Weather and Sales-py/population | Sales-cy/population |
| Dataset—Class | Linear Regression | Multilayer Perceptron | ||||
|---|---|---|---|---|---|---|
| CC | MAE | RAE (%) | CC | MAE | RAE (%) | |
| DS1—Units | 0.981 | 220,443.407 | 16.683 | 0.976 | 278,670.948 | 21.091 |
| DS2—Sales | 0.992 | 139,969.705 | 10.611 | 0.988 | 188,091.636 | 14.259 |
| DS3—Ln(Units) | 0.985 | 0.118 | 16.092 | 0.980 | 0.136 | 18.527 |
| DS4—Ln(Sales) | 0.993 | 0.074 | 10.645 | 0.991 | 0.086 | 12.226 |
| DS5—Units/pop. | 0.991 | 0.589 | 12.382 | 0.992 | 0.705 | 14.802 |
| DS6—Sales/pop. | 0.995 | 0.435 | 8.079 | 0.995 | 0.579 | 10.763 |
| Dataset—Class | Support Vector Machine for Regression | Multivariate Regression Prediction Model | ||||
|---|---|---|---|---|---|---|
| CC | MAE | RAE (%) | CC | MAE | RAE (%) | |
| DS1—Units | 0.981 | 216,730.969 | 16.402 | 0.981 | 220,443.407 | 16.684 |
| DS2—Sales | 0.992 | 138,254.838 | 10.481 | 0.992 | 139,966.261 | 10.611 |
| DS3—Ln(Units) | 0.985 | 0.118 | 16.058 | 0.985 | 0.118 | 16.092 |
| DS4—Ln(Sales) | 0.993 | 0.074 | 10.629 | 0.993 | 0.074 | 10.645 |
| DS5—Units/pop. | 0.991 | 0.575 | 12.08 | 0.991 | 0.564 | 11.832 |
| DS6—Sales/pop. | 0.995 | 0.429 | 7.971 | 0.996 | 0.420 | 7.812 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rincon-Patino, J.; Lasso, E.; Corrales, J.C. Estimating Avocado Sales Using Machine Learning Algorithms and Weather Data. Sustainability 2018, 10, 3498. https://doi.org/10.3390/su10103498
Rincon-Patino J, Lasso E, Corrales JC. Estimating Avocado Sales Using Machine Learning Algorithms and Weather Data. Sustainability. 2018; 10(10):3498. https://doi.org/10.3390/su10103498
Chicago/Turabian StyleRincon-Patino, Juan, Emmanuel Lasso, and Juan Carlos Corrales. 2018. "Estimating Avocado Sales Using Machine Learning Algorithms and Weather Data" Sustainability 10, no. 10: 3498. https://doi.org/10.3390/su10103498