1. Introduction
Blockchain was originally proposed by Satoshi Nakamoto [
1] as the underlying technology for Bitcoin [
2]. Blockchain 1.0 is represented by Bitcoin, which focuses on solving the problem of decentralization of currencies and payments. Blockchain 2.0 is represented by Ethereum [
3], which uses smart contracts to solve the trust issues of decentralization in the financial sector. Blockchain transaction involve three main components: the sender, the receiver, and the transaction amount. But both Bitcoin and Ethereum have limitations in privacy protection [
4]. The identities of the sender and receiver are realized through user public key addresses, which has a certain degree of anonymity [
5]. However, it is still possible to obtain the real identities of the traders by mining their associated information through data analysis or machine learning techniques. Furthermore, since the transaction amount is completely exposed on the blockchain and anyone can access it by querying the blockchain full node, attackers can deduce information such as account balances and fund flows [
6], thereby compromising transaction privacy. Current anonymous cryptocurrencies like Dash, Monero and later Beam/Grin [
7] utilize ZKPs (zero-knowledge proofs), ring signatures, and cryptographic commitments to protect the privacy of transaction details and participant identities [
8]. However, these methods lack regulatory functions and may be used for illegal trading activities.
In order to address the issues mentioned above, we propose a scheme that balances privacy protection and regulatory functions. Our main contributions are summarized below:
We propose a blockchain transaction scheme that integrates a variety of cryptographic technologies to balance privacy protection and regulatory functions. Specifically, it adopts probabilistic public-key encryption to protect the user’s identity from being exposed.
To validate the basic legality of blockchain transactions, our scheme employs cryptographic commitment schemes and zero-knowledge proof technology. It further integrates graph neural networks (GNNs) technology for anomaly detection in blockchain transaction data, thus meeting the requirements for transaction privacy protection and regulatory compliance without disclosing sensitive transaction information.
Our scheme allows regulatory authorities to avoid storing users’ real identities and key information, significantly reducing storage and computational burdens. Under the premise of ensuring transaction efficiency as much as possible, it balances the implementation of privacy protection and regulatory functions.
This paper is organized as follows:
Section 2 introduces the prerequisite knowledge necessary for constructing the scheme.
Section 3 explores the blockchain transaction privacy protection model.
Section 4 makes a comprehensive analysis of the scheme.
Section 5 provides the conclusions and discussions of this study.
2. Preparatory Knowledge
2.1. Literature Review
Blockchain features include decentralized storage, data immutability, and consensus mechanisms. These features ensure the transparency and security of blockchain data, but they also create challenges for users’ privacy protection. Researchers have introduced numerous privacy protection technologies to safeguard privacy.
Coin mixing is a significant privacy protection scheme that obscures the relationship between inputs and outputs in blockchain transactions to protect privacy. CoinJoin is a specific type of coin mixing scheme, its core idea is to merge transactions from multiple users into a single transaction to hide the source and destination of each user’s funds. Dash [
9] uses CoinJoin technology to ensure privacy by facilitating coin mixing through network master nodes. This process involves master nodes in chain mixing, where the output of one node becomes the input of another, undergoing multiple rounds of mixing to enhance anonymity.
Besides coin mixing, cryptographic privacy protection mechanisms are also a key research direction. Researchers use technologies like ZKP and ring signatures to secure transaction data confidentiality. Zerocoin [
10] employs non-interactive ZKP and RSA accumulators within a cryptocurrency framework that allows Bitcoin conversion into Zerocoin, concealing the identities of both the sender and the receiver during transactions. However, Zerocoin faces issues like high costs and low transaction efficiency. Building on Zerocoin, Zerocash [
11] introduces improvements using zk-SNARKs technology to reduce the transaction verification time required by Zerocoin, enhancing transaction efficiency. Moreover, Zerocash enables private transactions of differing amounts and allows direct transfers to user addresses. Monero focuses on privacy protection, it uses a ring signature framework to keep transaction senders anonymous. Additionally, it employs stealth address technology, generating a one-time address for each transaction to prevent address reuse.
Beyond privacy protection, regulatory technology is another vital aspect of blockchain transactions, which can effectively prevent illegal activities. Thus, balancing transaction regulation with privacy protection is an essential research direction. Li et al. [
12] proposed a traceable Monero system that adds an accountability mechanism to the original system. It can trace the flow of funds and infer users’ long-term addresses from one-time anonymous addresses. Sun et al. [
13] proposed an MBDC framework for CBDC, which employs permissioned blockchain technology and utilizes a multi-blockchain structure and ChainID to improve scalability. However, MBDC focuses on regulatory features and has limitations in privacy protection. Zhang et al. [
14] introduced Gemini-Chain, which adopts a dual-chain structure to store and access complete transaction and verification information, maintaining a balance between privacy security and regulatory functions. But its structure is relatively complex.
2.2. UTXO Model
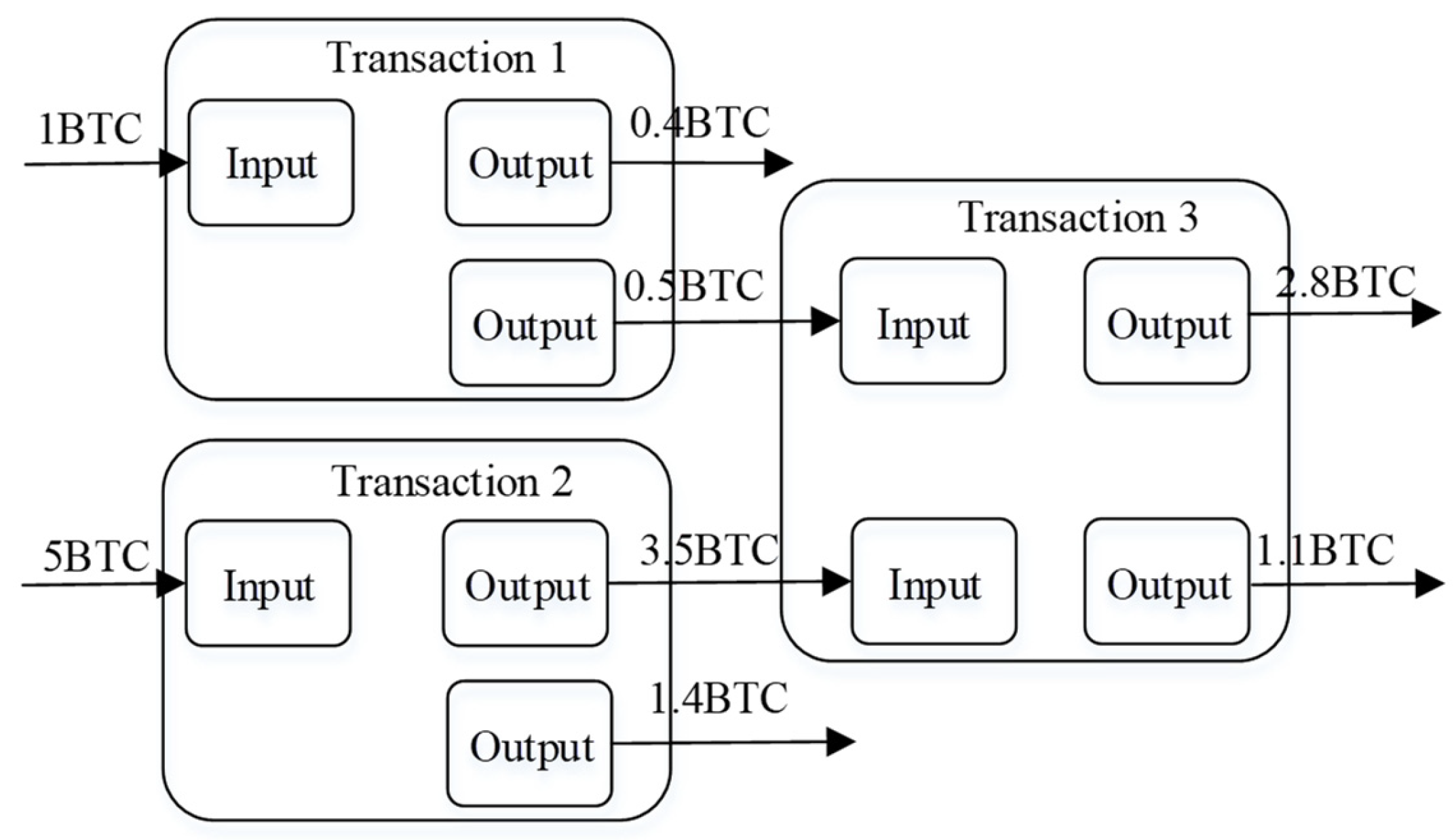
UTXO (unspent transaction output) represents the outputs of transactions that have not yet been spent [
15]. Multiple transactions are recorded on the Bitcoin ledger, each with several transaction inputs (transferors) and outputs (recipients). These outputs constitute the UTXO.
Figure 1 shows an instance of the Bitcoin UTXO model. In this model, Transaction 1 has an input of 1 BTC, distributing two outputs, one of 0.4 BTC and another of 0.5 BTC, where the 0.1 BTC discrepancy acts as the transaction fee. Transaction 2 is the same as Transaction 1, with its output becoming the input for Transaction 3, thereby establishing a sequential linkage of transactions.
2.3. Probabilistic Public-Key Cryptosystems
Probabilistic public-key encryption is a non-deterministic cryptography that generates randomly varying ciphertexts for the same plaintext. Under the computational security assumption, it is impossible to acquire any reliable information about the plaintext within polynomial time by using ciphertext correlation attacks. Goldwasser and Micali designed a probabilistic public-key scheme [
16] (referred to as the GM probabilistic public-key encryption algorithm) using the quadratic residual theorem. However, the GM scheme has a high ciphertext expansion rate, leading to low transmission efficiency. Blum and Goldwasser proposed a more efficient probabilistic encryption scheme [
17] (referred to as the BG cryptosystem), significantly reducing the expansion of ciphertext data. Hence, we primarily employ the BG scheme for encrypting user identity information. The BG probabilistic encryption mainly utilizes the BBS [
18] generator to enhance ciphertext randomness. The detailed algorithm is as follows:
Parameter Setting: Let , where and are large primes, and . Here, is the public key, while and serve as the private keys. Define the plaintext space as , the ciphertext space as , and the key space as .
Encryption: For plaintext message to be encrypted, the process is as follows:
Randomly select a seed and use the BBS generator to produce random bits as the keystream;
Calculate ;
Calculate , ;
The ciphertext is .
Decryption: The process of decrypting the ciphertext is as follows:
Calculate ;
Calculate ;
Calculate ;
Calculate ;
Utilize the Chinese remainder theorem to calculate , satisfying and ;
Using the BBS generator, derive from the seed ;
For each bit , compute ;
The decrypted plaintext is .
2.4. Identity-Based Cryptosystems
IBC (identity-based cryptography) [
19] addresses the challenges associated with the supervision of digital certificates in public-key infrastructure (PKI). Within IBC, an entity’s identification ID serves as its public key, while the private key is created using the KGC’s (key generation center) master keys alongside the entity’s ID. We employ the Chinese national standard algorithm SM9 as an example of IBC, and the SM9 algorithm is introduced as follows [
20]:
Define as the generator of an additive cyclic group on an elliptical curve , as the generator of a similar group on an elliptical curve , as a hash function, and as a bilinear pair. Considering A as the signer and B as the verifier, the digital signature process for SM9 is as follows:
Key Generation: The KGC selects a random number as the master private key for signing and computes as the master public key. Therefore, the master key pair is established as . The identification of user A is . To create A’s private signing key , the KGC computes and within the field , subsequently obtaining .
Signing: To sign a message , A’s signing process is as follows:
;
Select a random number ;
, , ;
. Then, ’s signature is .
Verification: For verifying a signature on the message , B follows the following steps:
;
, ;
, , ;
, if , the signature verification is successful; if not, it fails.
2.5. Password Commitment Program
Cryptographic commitment is a two-stage interactive protocol involving a sender and a receiver. In Monero, the Pedersen commitment is a widely utilized homomorphic commitment scheme; it satisfies perfect hiding and computational binding properties and is used to protect the confidentiality of transaction values. The formula is:
represents the concealed transaction amount,
and
are base points in elliptic curve cryptography,
is a random number, and
is the transaction amount. Additionally, the Bulletproofs zero-knowledge proof technique [
21] is utilized to efficiently prove the range of transaction amounts.
2.6. Graph Neural Networks
GNNs (graph neural networks) [
22] are a deep learning model for processing graph-structured data. They are capable of capturing complex relationships and dependencies between nodes in a graph. The representation of each node is updated based on information from neighboring nodes and propagated through the neural network layers. This enables GNNs to handle a wide variety of graphical architecture tasks. The important strength of GNNs is they can operate directly on the graph structure, effectively utilizing the topological information of the graph. They have been widely used for tasks such as social network analysis, recommender systems and knowledge graphs.
Common GNN variants include GCNs (graph convolutional networks) [
23], GATs (graph attention networks) [
24], and GAEs (graph autoencoders) [
25], which use different mechanisms to aggregate and update node information. GCNs process graph data based on the concept of convolution, and its core principle is to update the representation of each node by aggregating information from neighboring nodes, thus capture the topology of the graph. In GCNs, the new feature representation of each node is realized by weighted average aggregation of its own features and the features of neighboring nodes. This process can be considered as a special convolution operation. GATs are neural network models for graph-structured data; they incorporate an attention mechanism to aggregate information from neighboring nodes. The core feature of GATs are that different neighbors contribute differently to the central node, which is reflected by attention coefficients. Each node updates its feature representation by first calculating the attention coefficients of all its neighbors (including itself) and then aggregating the neighbors’ features weighted by these coefficients, considering the relative positional relationships of the nodes and individual characteristics. GAEs are a type of autoencoder model specifically for graph data, combining the characteristics of autoencoders with the capabilities of graph neural networks to capture reduced-dimensional embeddings of graph nodes. The core idea of GAEs are to encode graph nodes into a compressed space using a graph neural network, and then use a decoder to restore the structural details of the graph, such as the interconnections between nodes.
Blockchain transaction data can form complex graph structures, encompassing a variety of transaction entities and their interactions. This presents an ideal application scenario for GNNs. For instance, IBM’s AI Lab has proposed using GNNs to identify money laundering rings in Bitcoin transactions [
26]. Researchers created a temporal graph dataset comprising over 200,000 Bitcoin transactions (known as the Elliptic dataset) for identifying and classifying legal and illegal transactions. The graph in the dataset consists of 203,769 nodes and 234,355 edges, where nodes denote transaction entities and edges denote Bitcoin transaction flows between two entities. Each node is associated with 166 transaction-related features, including the first 94 local features representing the node’s time step, in-degree and out-degree, payment expenditure fees, and derived features like the average amount of Bitcoin transactions; the remaining 72 are aggregated features obtained by aggregating maximum, minimum, standard deviation, and correlation coefficient information of neighbor transactions from the central node. About 2% of the nodes in the data are fraudulent, 21% are non-fraudulent, and the rest are unlabeled. Using GNN-based semi-supervised learning, each unlabeled Bitcoin transaction can be classified as illegal or legal.
The purpose of anomaly identity authentication detection is to infer account identities by capturing characteristics of transaction patterns. For instance, analyzing identity addresses can help determine the causes of cryptocurrency price fluctuations and their association with specific types of accounts, which is essential in safeguarding the blockchain’s ecological integrity and establishing standardized transaction protocols. Traditional methods of identity recognition mainly include manual annotation and source code analysis. The former requires considerable manpower and is virtually impossible to accomplish for hundreds of millions of identity information. Although source code analysis for address identification (which involves analyzing the source code of a smart contract to identify potential backdoors or vulnerabilities) is more accurate, this approach is difficult to implement and many smart contracts do not disclose their source code. In contrast, graph neural network technology offers a novel solution. Liu et al. [
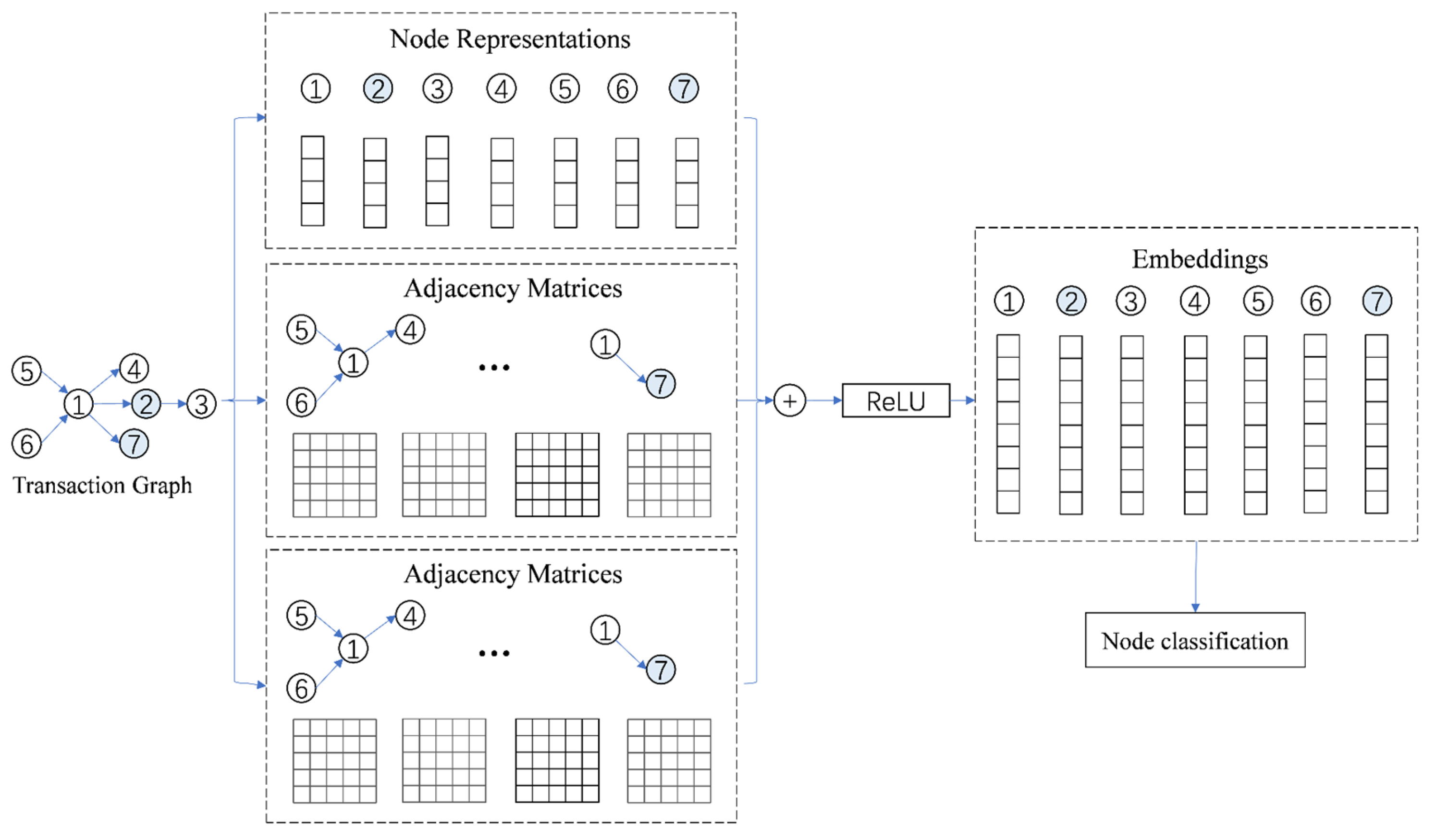
27] designed a blockchain address identification method based on graph deep learning, and its framework is shown in
Figure 2.
This model primarily comprises three major modules. The graph construction is based on node representation matrices, adjacency matrices and temporal density matrices to construct a directed weighted graph, generating distinctive feature representations for each node. In this framework, the node representation matrix includes information about the nodes’ out-degree and in-degree, as well as the node type. The adjacency matrix is constructed with four types of edges based on transactions, contract calls, rewards, and other methods. The time density matrix is built according to the frequency and timing of interactions between account addresses. The model employs graph convolutional neural networks for learning and ultimately uses the softmax function to predict the node types for anomaly identity detection.
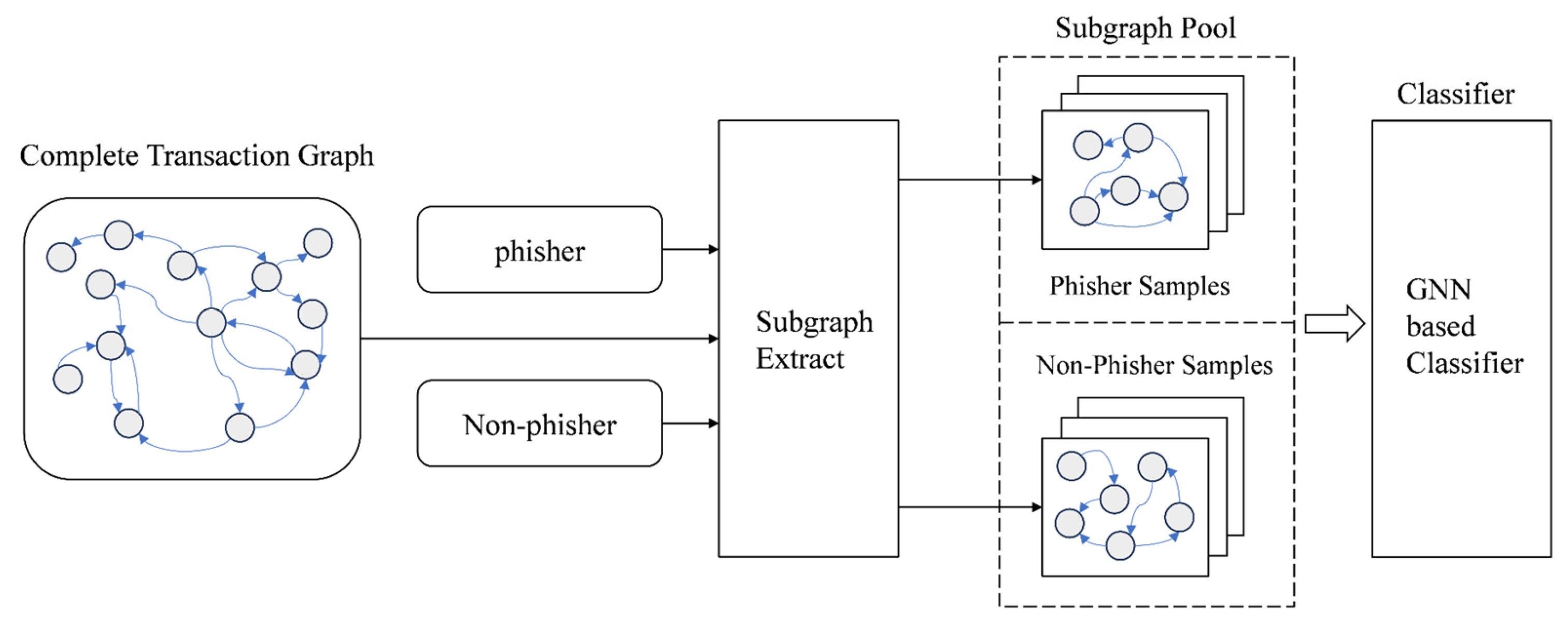
Shen et al. developed a model named I2BGNN [
28], an end-to-end network specifically designed for processing the graph structure of blockchain transaction data. The I2BGNN model learns and captures patterns within transaction subgraphs and associates these patterns with user identities to enable de-anonymization. This approach infers user identities from transaction behaviors by analyzing transaction subgraphs, transforming the task of identity inference into a problem of graph classification. The model architecture of I2BGNN is shown in
Figure 3:
The model initially constructs a graph network through blockchain transaction information, then samples labeled accounts, extracting subgraphs centered around the target accounts as input for the model. Finally, it trains a GNN model and evaluates the results. Experiments conducted on the EOSG and ETHG datasets demonstrate that this method achieves superior results in the domain of identity inference.
3. Deep Learning-Based Blockchain Transaction Privacy Protection Model
This paper integrates technologies such as the UTXO transaction model, the BG probabilistic public-key encryption algorithm, the IBC cryptographic system, Pedersen commitments, and graph neural networks to propose a supervised blockchain transaction privacy protection scheme. The design process is introduced in detail below.
3.1. Model
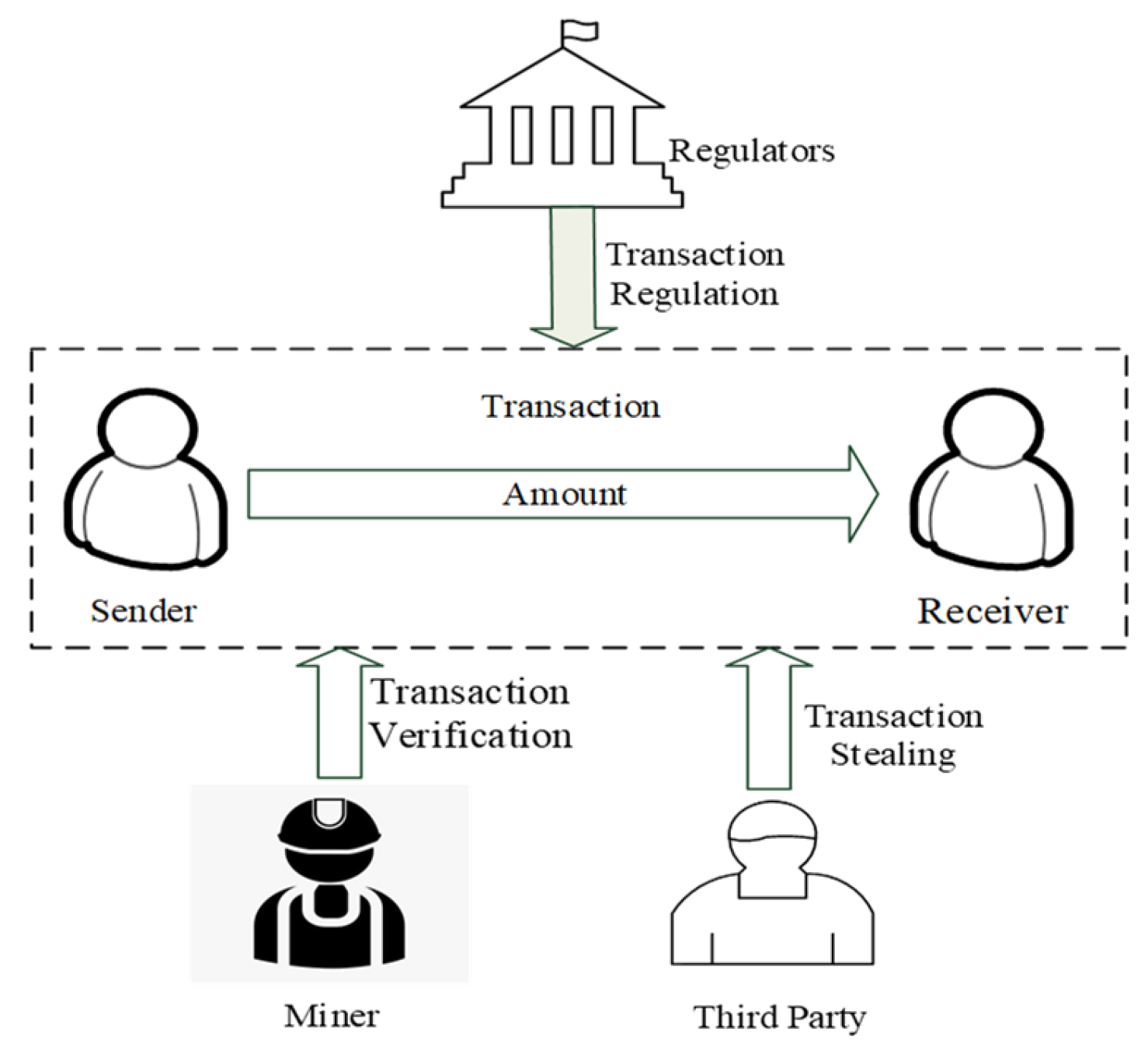
As shown in
Figure 4, participants in the program primarily include the following: (1) The transaction’s primary entities, the sender and the receiver, who aim to safeguard their anonymity and the confidentiality of the transaction sum through a secure transaction. In basic transaction activities, the sender transfers a certain amount of money to the receiver. (2) The miner, who verifies the legitimacy of the transaction and ensures that there is no double payment or fraud; after the transaction is verified, the miner packages it into a new block and stores it on the blockchain through a consensus mechanism to ensure the immutability of the transaction record. (3) Regulators, who are responsible for supervising and regulating the blockchain network. When necessary, they track the relevant participants and financial transactions to combat illegal financial activities. (4) Third parties, who may act as malicious actors using technical means to steal transaction-related information for undue gain.
The scheme comprises the following seven algorithms:
: This is the key generation process of the BG algorithm. It generates the BG algorithm’s public key pk and private key sk using large primes p and q. This algorithm provides probabilistic encryption, which generates different ciphertexts even if the same message is encrypted multiple times.
: This is the encryption process of the BG algorithm. It encrypts message m utilizing the public key pk of the probabilistic public-key BG algorithm to produce the ciphertext.
: This is the decryption process of the BG algorithm. It decrypts ciphertext ct utilizing the private key sk of the probabilistic public-key BG algorithm to retrieve the plaintext. A user with the correct private key can successfully decrypt the ciphertext.
: This is the key generation function of the SM9 algorithm based on IBC. Generate the user’s private key by employing the SM9 algorithm’s master key (sk) and the user’s identifier (id).
: This is the encryption process of the SM9 algorithm. It encrypts message m using the public key pk of the SM9 algorithm to produce ciphertext. SM9 is an identity-based encryption algorithm, which means that the encryption can be performed directly using the user’s public identity information.
: This is the decryption process of the SM9 algorithm. It decrypts ciphertext ct using the private key sk of the SM9 algorithm to retrieve the plaintext. A user with the correct private key can decrypt successfully.
: This is the signature process of the SM9 algorithm. It signs message m using the private key sk of the SM9 algorithm to obtain the signature value. This ensures the message remains unaltered throughout transmission, ensuring data integrity and non-repudiation.
This scheme provides public-key encryption and decryption using the BG probabilistic public-key cryptography algorithm (with a key size of 2048 b), which provides strong security guarantees for transactions, especially in terms of its ability to counter selective plaintext attacks. We also use the SM9 algorithm based on the IBC cryptosystem (with a key size of 256 b), whose encryption strength is equivalent to the RSA encryption algorithm of 3072 b. The SM9 algorithm allows the direct use of a user’s identification data as the public key, which simplifies the process of distributing and managing the key. In addition, it provides digital signature and authentication functions; this approach can secure transactions and verify user identities in certain situations. The use of these two algorithms enhances the system compatibility and flexibility, enabling the scheme to meet different transaction scenarios. By combining different encryption algorithms, a more complex security framework is constructed for the scheme, which enhances the security of the whole system.
3.2. Anonymous Identity Realization
During the initialization phase of the scheme, the regulatory authority needs to generate three public-private key pairs: firstly, using the BG algorithm to produce private key and public key ; secondly, as the KGC within the IBC framework, the regulatory authority creates a master public key and corresponding a master private key ; thirdly, defining the identity marker in IBC as , considering as the public key, the signature private key is created using the master private key based on the IBC algorithm. Then, users apply for key distribution from the regulatory authority using unique identifiable information (which needs to be self-proving, such as an email address, ID card number, or phone number).
After verifying user identity information, the regulatory authority encrypts it using the public key of the BG probabilistic cryptography algorithm to generate . To ensure that is certified by the regulatory authority, it needs to be signed by the authority, generating . Define . Since is obtained using the BG probabilistic public-key encryption algorithm and has good randomness, and is obtained through the IBC signature, also possesses good randomness, effectively hiding the user’s real identity information .
Next, is used as the public-key identity. Utilizing the IBC algorithm, the regulatory authority generates the corresponding private key for the user. The user’s verifiable true identity is denoted as , while represents their calculated anonymous identity, being the corresponding private key. Employing the BG algorithm enables the generation of various from the same , establishing a one-to-many connection between and . This relationship permits the theoretical creation of limitless from the same , allowing users to continuously renew their anonymous identities.
For ease of subsequent description, define the transaction sender and receiver’s identity markers as and , respectively. Through the above process, their corresponding anonymous identities and , and private keys and can be calculated. When the sender transacts with the receiver, they can utilize to decrypt the UTXO input script and set as the receiver’s address, thereby maintaining identity anonymity.
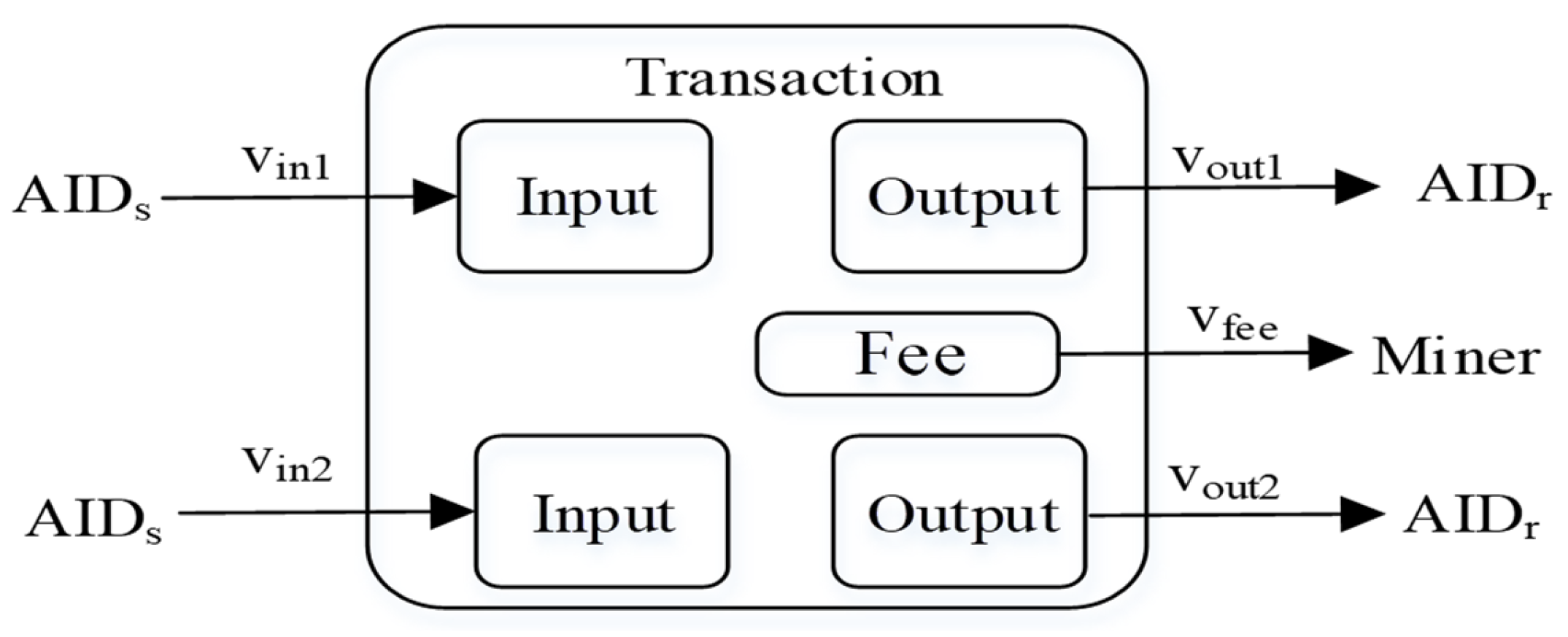
3.3. Transaction Data Privacy Protection
When
transacts with
, without loss of generality, suppose the structure of the transaction is as shown in
Figure 5.
In this transaction, there are two inputs with amounts and and two outputs: one for the transaction with , amounting to , and the other returning change to oneself, amounting to . Additionally, the portion is the transaction fee, serving as the miner’s fee for packaging the transaction.
Our approach primarily employs Pedersen commitments to ensure the privacy protection of transaction amounts (
while the transaction fees
are publicly disclosed. For the transaction inputs, it is necessary to introduce previous outputs, represented as
where
and
can be decrypted by
using the private key
.
The sender
sets
and
, then calculates
and
are primarily used to facilitate the miner’s verification of the transaction’s legitimacy. To enable the receiver to obtain
and
, it needs to be encrypted using the public keys of both receiver and sender, resulting in
To ensure the transaction’s legality, it must be verified that
Consequently, the following can be calculated:
Define the transaction’s public key as
The transaction’s private key is
The entire transaction is defined as
The transaction is signed using the SM9 signature algorithm, resulting in
Additionally, it is necessary to verify the transaction amount range to prevent negative values; Bulletproofs can achieve this. Due to the complexity involved, this paper will not elaborate further, but Reference [
15] can be consulted for more information. The final transaction is
where
encompasses details verifying the range of the transaction value.
is broadcast across the network and after miners verify its legitimacy, it is incorporated into blocks and documented in the blockchain ledger via consensus protocols. The receiver can acknowledge the transaction using
and then decrypt
using their private key
to obtain transaction information, thereby completing the entire process of the transaction while concealing the amount of the transaction.
3.4. Transaction Legitimacy Verification
In a blockchain, transactions are recorded via a consensus mechanism. During the consensus process, miners verify transactions’ legitimacy, which primarily includes the verification of participant identity and transaction amount legitimacy.
Identity legitimacy verification involves verifying the legitimacy of both the sender and receiver’s identities. Within the UTXO model, the sender uses to unlock UTXO inputs. Therefore, miners only need to use the sender’s anonymous identity public key (called ) to verify the legitimacy of the unlocking script signature.
Verifying the receiver’s address is crucial to prevent fraudulent transactions and potential asset loss. Our scheme uses the receiver’s anonymous identity public key (denoted as
) as the receiver’s address.
represents the signature performed by the regulatory authority using its private key on . Thus, to validate the unlocking script’s signature, miners just have to utilize the sender’s anonymized public identity key (designated as ).
Transaction amount legitimacy also requires two aspects of verification: the equality of input and output amounts and the validity of the range of output amounts.
For the transaction
and
, miners need to calculate the transaction public key:
Using
to verify the legitimacy of the transaction signature
, fulfilling the requirement of input and output amount equality. To ensure the output amount is within a valid range, the existing Bulletproofs zero-knowledge proof technology is used to verify
, as referenced in [
15].
3.5. Micro-Level Supervision Algorithm for Transaction Data
Blockchain transaction privacy protection is relative, primarily aimed at protecting user data from unauthorized access by malicious third parties. Nevertheless, regulatory authorities need transaction monitoring to combat illegal activities. Thus, it is crucial to ensure participant identities and transaction amounts can be regulated.
The anonymous identities of the participants in a transaction are
, but their real identities
are hidden.
The regulatory authority first verifies the legitimacy of the identity authentication using
. Then, using its BG probabilistic public-key encryption algorithm’s private key
, it decrypts
, obtaining the true identity of the transaction participant.
To access the transaction amount information, the IBC algorithm is first utilized. As the KGC in the IBC cryptographic system, the regulatory authority can compute the receiver
’s private key
, denoted as
For transactions
and
, the regulatory authority then uses
to decrypt
, obtaining
The regulatory authority thus obtains the transfer amount to . Similarly, processing allows for the querying and monitoring of blockchain transactions.
3.6. Anomaly Transaction Data Detection Based on Graph Neural Networks
Anomaly detection is a method used to identify behaviors that deviate from the expected norm. The task of graph-based anomaly detection aims to uncover nodes, edges, or subgraphs within a network that exhibit significantly outlier characteristics. Anomaly detection of transaction data using GNNs is particularly useful in identifying fraudulent activities, money laundering and other anomalous patterns in financial transactions. This method is especially adept at handling complex financial networks, where transaction relationships can be modeled as graph structures, with nodes representing participants (such as individuals and companies) and edges representing transactions.
In this application, the GNNs’ role is to leverage the structural information of the graph to learn underlying patterns within transaction data. Traditional fraud detection methods typically rely on rules or simple machine learning models that may not be able to capture complex non-linear fraud patterns. In contrast, GNNs can more effectively identify anomalous patterns by considering the relationships between nodes and transaction patterns in the transaction network.
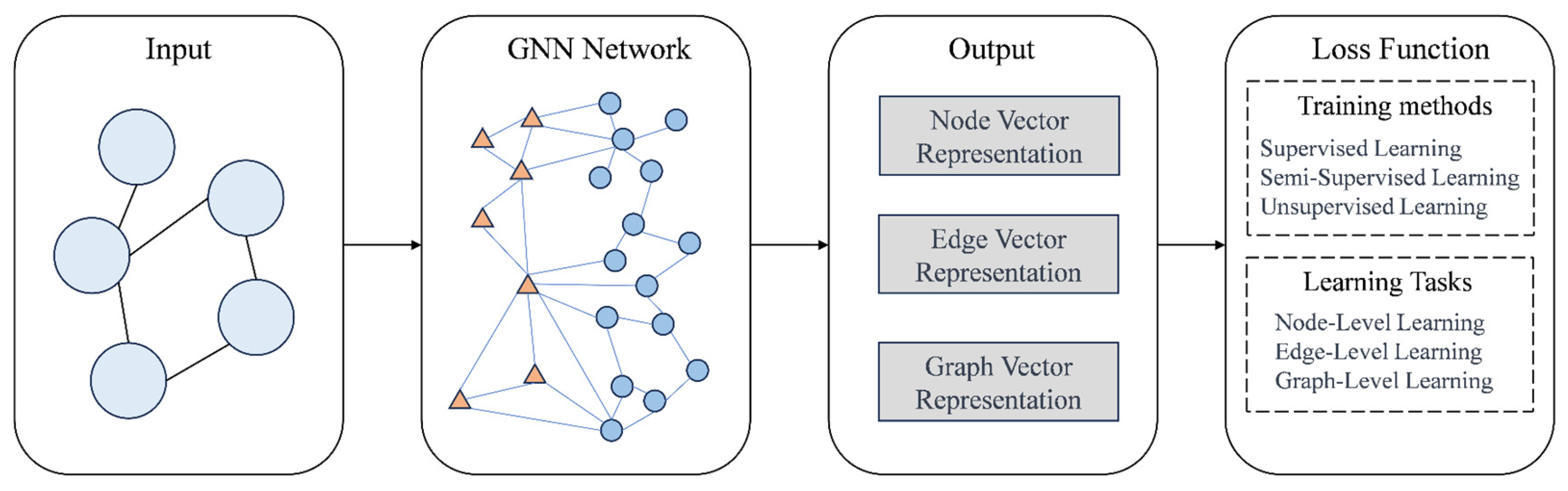
The general design process for GNNs is divided into four parts, as illustrated in the following
Figure 6:
First, identify the graph structure relevant to the specific context and represent the data in graphical format. Next, determine the type of graph, such as directed/undirected or homogenous/heterogeneous. Subsequently, develop a loss function. Depending on the graph learning task, prediction types can be categorized at various levels: node, edge, community, or graph-wide. Finally, establish computational modules and train the model. The propagation module facilitates information exchange between nodes, enabling the aggregation of information to capture the graph’s characteristics and topological details. The sampling module is responsible for graph sampling. For higher-dimensional subgraph representations, the pooling module can extract node information.
In a graph structure, each node is defined by its own features as well as the features of its connected neighbors. GNNs learn a state-embedding vector
for each node. This vector incorporates information from neighboring nodes. The node’s state vector (denoted as
) can be utilized to generate an output
. Suppose
is a function with parameters shared by all nodes, called the local transition function. This function updates node states based on neighboring node information. The local output function
defines how the output is generated.
denotes the feature vector of
,
denotes the feature vector of the edges linked to
,
symbolizes the state vector for
’s adjacent nodes, and
indicates the feature vector for
’s adjacent nodes. Suppose we assemble vectors of various types into their respective composite vectors. These composite vectors can be denoted as
for the state vectors,
for the output vectors,
for the feature vectors, and
for the node features. This aggregation makes the representation more compact:
and
represent the global transition and output functions, respectively. They are obtained by stacking the node-wise functions
and
for all nodes in the graph. GNN iteratively computes state parameters using a traditional method based on the Banach fixed-point theorem.
where
represents the tensor of
at the
-th iteration cycle.
Supervised learning is conducted using target information; the loss function is defined as follows:
With supervised nodes, the loss function for GNN training incorporates true values and predicted values , and leverages a gradient descent strategy with the following steps: The state is iteratively updated according to Equation (24) for cycles until it approaches the fixed-point solution near Equation (26), at which point the obtained will be close to the fixed-point solution . During backpropagation, the gradient of the weight is calculated from the loss, and then is continuously updated based on the gradient computed in the previous step. After cycles, the gradient with respect to is obtained, which is then used to update the model parameters.
The framework for anomaly detection in transaction data based on GNNs is a technique for identifying and locating abnormal information in transaction data, which plays a significant role in fields like finance, e-commerce, and insurance. The process flow of the GNN-based transaction data anomaly detection model can be broadly divided into the following:
Data Preprocessing: Initially, transaction data are converted into graph data where nodes represent transaction entities (e.g., users, merchants, banks, etc.) and edges represent transaction relationships (e.g., payments, transfers, refunds, etc.). Attributes of nodes and edges represent transaction characteristics (e.g., amount, time, frequency, type, etc.).
Graph Neural Networks: Subsequently, GNNs are employed for feature extraction and representation learning of the graph data. Utilizing the attribute information and structural information of nodes and edges, low-dimensional vector representations for each node and edge are obtained.
Anomaly Scoring: The vector representations of each node and edge are then assessed using an anomaly scoring function to compute their level of anomaly. Candidates for abnormal transactions are selected based on certain thresholds or ranking methods.
Anomaly Interpretation: Finally, the anomaly interpretation module explains the candidate nodes and edges involved in abnormal transactions. This analysis includes the causes and effects of anomalies, providing visual and interpretable results to help users understand and address abnormal transactions.
The detailed design of the detection model includes the following:
Input: Transaction data forms an attribute graph G = (V, E, X). Nodes V denote transaction entities, while edges E depict the relationships between them. X is the node attribute matrix representing transaction features like amount, time, frequency, type, etc.
Output: An anomaly score S ∈ R|V| for each node, indicating the degree of anomaly. A higher score suggests a higher likelihood of anomaly.
Model Structure: The model has three parts: the graph neural network, the anomaly scoring function, and the loss function.
- ♦
Graph Neural Network: The graph neural network extracts feature representations from the graph data. Various types of GNNs can be used. Assuming GCN as an example, the GNN formula is as follows:
Here, is the node feature matrix at layer l, is the feature dimension of layer l, is the trainable weight matrix at layer l, is the adjacency matrix with self-loops, is the degree matrix of , and is an activation function like ReLU. After L layers of the GNN, the final node feature representation is obtained.
- ♦
Anomaly Scoring Function: The anomaly scoring function computes the anomaly score based on the node’s feature representation. Various types of scoring functions can be used, such as those based on reconstruction error, distance, or density. Assuming a scoring function based on the reconstruction error as an example, the equation is
Here, is the reconstructed node attribute matrix, which can be decoded from . is the Frobenius norm, representing the root of the total sum of each matrix element squared. The larger the reconstruction error, the more inconsistent the node’s attributes are with the normal pattern, hence the higher the anomaly score.
- ♦
Loss Function: The loss function optimizes the model’s parameters to better distinguish between normal and abnormal nodes. Various types of loss functions can be used, such as contrastive, self-supervised, or adversarial. Assuming a contrastive-based loss function as an example, the formula can be expressed as
Here, is the anomaly score of node v, and is a temperature parameter for controlling the scaling of scores. The purpose of this loss function is to maximize the scores of anomalous nodes while minimizing the scores of normal nodes, thereby increasing the score differences between nodes. This loss function requires some prior anomaly labels, which can be obtained by simple rules or statistical methods, or by semi-supervised or unsupervised methods.
5. Conclusions and Discussions
To address the challenge of balancing privacy protection and regulatory requirements in blockchain transactions, we integrate multiple cryptographic technologies, utilizing probabilistic public-key cryptography, identity-based cryptography (IBC), Pedersen commitments, and Bulletproofs techniques, combined with deep learning graph neural networks, to propose a blockchain transaction and regulatory scheme that offers both privacy protection and regulatory functions. Our scheme can be applied as an independent module in existing blockchain technologies. Our analysis of its security performance reveals that the blockchain transaction scheme is simple and practical. It holds extensive applicative value in areas such as digital asset risk analysis and financial transaction regulation.
Although our scheme balances privacy protection and regulatory functions, it still has some limitations. For example, there is still room for optimizing the improvement in transaction efficiency. It is an important research direction to improve the transaction speed, reduce the verification time, and minimize the computational overhead as much as possible in regulatable blockchain transactions. In addition, it is also important to choose appropriate privacy protection schemes for different transaction scenarios. Therefore, future research will focus on realizing the balance of privacy protection, regulatory function, transaction efficiency and other elements in blockchain transactions.
Legal regulations are also an important issue to be considered for blockchain technology. Blockchain’s decentralization, tamper-resistance, transparency, and security make it widely applicable in the financial sector, which has resulted in some illegal activities choosing to use blockchain technology for transactions. Therefore, countries are developing specific laws and regulations related to cryptocurrencies, such as registration requirements for trading platforms and anti-money laundering regulations. At the same time, they are actively supervising the digital currency market to prevent possible financial risks. In addition, several other countries have established specific regulatory frameworks for blockchain, aiming to maintain financial security, protect consumer interests, and enhance the ability to combat money laundering. Our scheme provides regulatory capabilities for blockchain trading activities under the premise of privacy protection, which can help relevant organizations avoid illegal transactions. However, the current legal system of each country for blockchain technology is still not perfect, and the relevant rules are still being optimized. Therefore, future research should enhance the compatibility and flexibility of the scheme to adapt to the legal requirements of different countries.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}