
Cluster-Based Data Aggregation in Flying Sensor Networks Enabled Internet of Things


Abstract
:1. Introduction
- An effective mechanism designed based on a honey-bee algorithm (HBA) to select optimal unmanned aerial vehicles–cluster head (UAVs-CH).
- The formation of balanced and stable clusters reduces re-affiliation rates.
- Data aggregation algorithm proposed to limit duplicated data communication to the base station (BS).
- Avoids the transmission of unwanted packets to the BS and save FSNet bandwidth.
- Mathematical techniques measure the accuracy and correctness of the proposed scheme.
2. Background
2.1. Energy Efficient Clustering
2.2. UAVs-Based Data Aggregation
3. Flying Sensor Network Cluster Optimization
Clustering Setup
| Algorithm 1: Pseudo Code of UAVs Enabled CH Selection. | |
| 1 | Procedure CH-Selection-Multi-UAVs (MUAVs)() |
| 2 | . |
| 3 | Output: UAVs-CH |
| 4 | call function calculate-UAVs-Nectar () // v1 represents the number of nodes (UAVs) when there are n total UAVs in the network |
| 5 | do // selection of UAVs-CH in a random way |
| 6 | ) |
| 7 | end for |
| 8 | while (highest-value! = yes) do |
| 9 | do // the suitability of current selection is computed |
| 10 | if (v1 in UAVs-CH) then |
| 11 |
|
| 12 | end if |
| 13 | end for |
| 14 | ) then is the suitable value in the existing solution |
| 15 | |
| 16 | end if |
| 17 | if (UAVs-CH-optimum! = yes) then |
| 18 | do // Employed bee (empb) is UAV affiliation with the current round while y is the neighborhood size |
| 19 | // selection of different UAVs from fellow citizen |
| 20 | end while |
| 21 | //) |
| 22 | while (the Obees ≠ Є) do //Onlooker bees (Obees) |
| 23 | |
| 24 | end while |
| 25 | Else |
| 26 | return UAVs-CH |
| 27 | end while |
| 28 | end procedure |
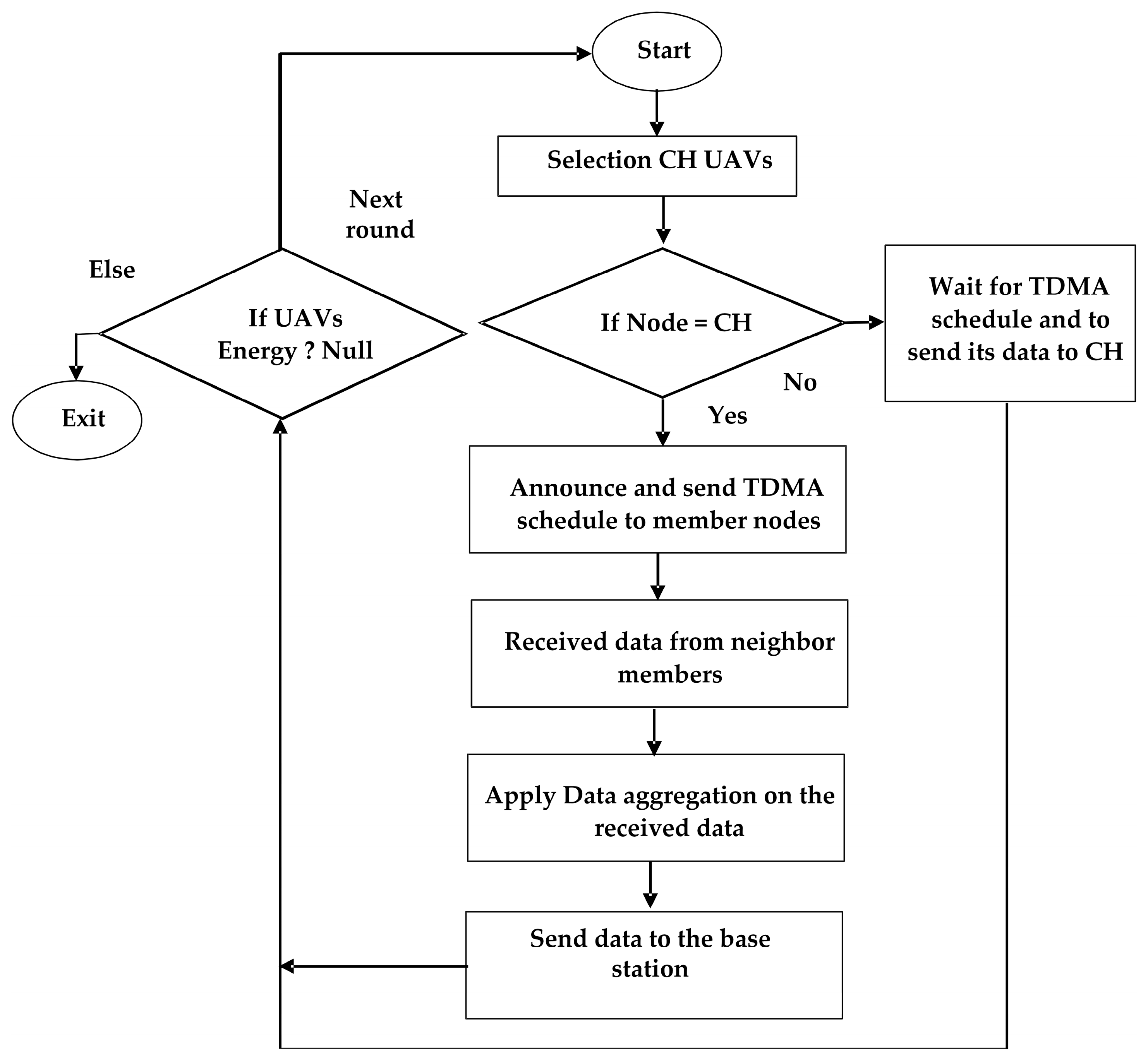
4. Data Aggregation and Communication
- The insertion of a character, at a location, , gives .
- The substitution of a character at the location, , with character, , results in .
- The partial data movement with factors converts into .
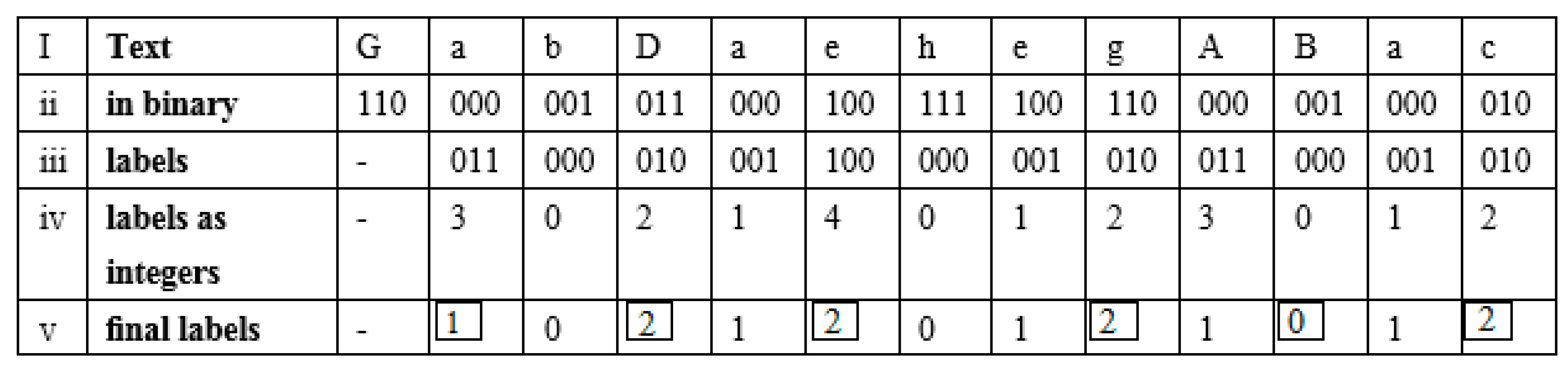
4.1. Data Embedding
4.1.1. EPS
- (a)
- Maximum adjacent partial data of that comprise a repetitive sign ( shows in the form for where ).
- (b)
- Length of partial data (Long) at least not of type 1 above.
- (c)
- Length of partial data (short) less than not of type 1.
4.1.2. Type 2: Long Data without Duplications
4.1.3. Type 1 (Repeating mbs) and Type 3 (Short mbs)
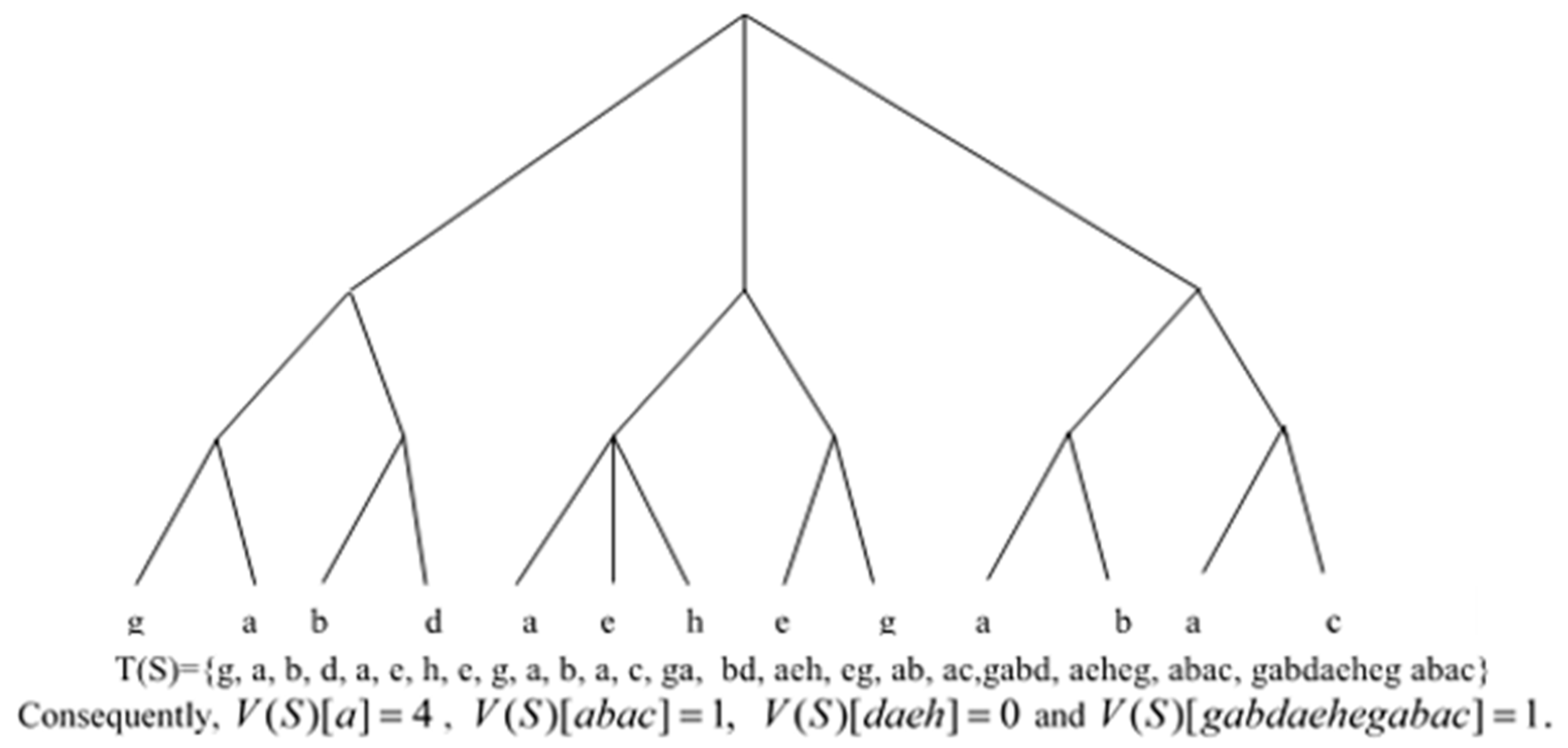
4.1.4. Constructing ET (X)
4.1.5. Properties of ESP
4.2. Upper Bound Proof
4.3. Data Aggregation Level 2 Problem Solution
4.3.1. Pruning Lemma
4.3.2. ESP Sub-Trees
4.4. Data Aggregation Level 2 Algorithm
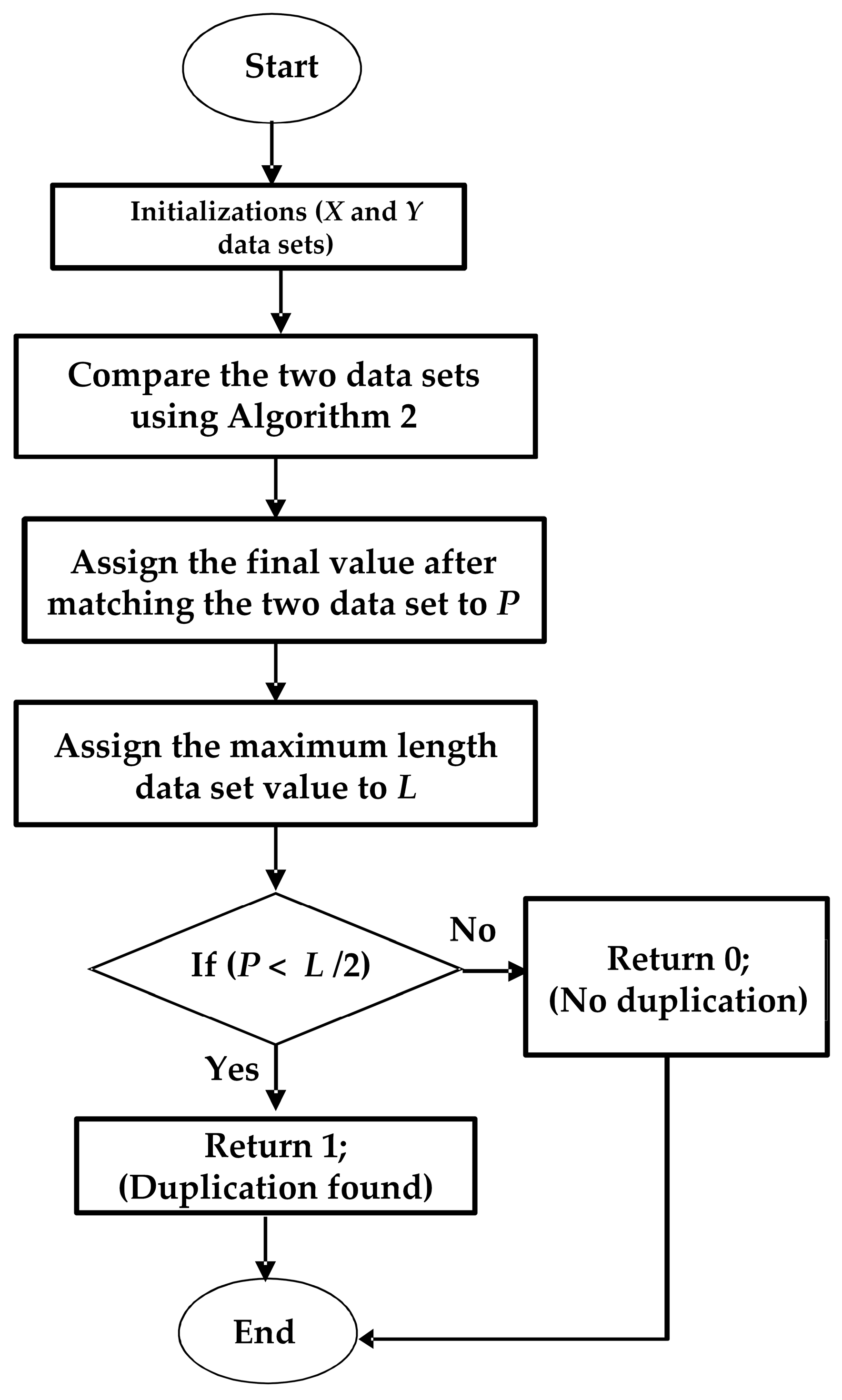
| Algorithm 2: Data Aggregation Algorithm to Find the Duplicated Data in Two Datasets, X and Y | |
| Procedure Data_Match_with_Moves (DMM) | |
| Input: Datasets, X and Y | |
| Output: True/False // Duplication Found or Not Found | |
| 1. | Initializations
|
| 2. | Allocate vector space V[0:m, 0:n] ▷ V[i, j] will contain the length of X[1:i] and Y[1:j]. |
| 3. | V[0, j] ← 0 for all 0 ≤ j ≤ n and V[i, 0] ← 0 for all 0 ≤ i ≤ m. ▷ Base Cases |
| 4. | for (i ← 1 to Xlen) then |
| 5. | for (j ← 0 to Ylen) then // matching the symbols from X with Y symbols |
| 6. | if (j = 0) then // if Y is blank then eliminate all X symbols // if symbol from both dataset is matching then no operation is required |
| 7. | V[i % 2][j] ← i; |
| 8. | else if (X[j − 1] = Y[i − 1]) then |
| 9. | V[i % 2][j] ← V[(i − 1) % 2][j − 1]; |
| 10. | end else if // if symbols from both datasets do not match, then we take the smallest from 3 operations. // i.e., insert, delete and substitute |
| 11. | else then |
| 12. | V[i % 2][j] ← 1 + min(V[(i − 1) % 2][j], |
| 13. | min(V[i % 2][j − 1], |
| 14. | V[(i − 1) % 2][j − 1])); |
| 15. | end if |
| 16. | end for |
| 17. | end for // after filling the V vector, if the size of Xlen is even, then //we end up in the 0th row else //we end up in the ith row, so we take Xlen % 2 to get row |
| 18. | P←V[Xlen % 2][Ylen] // the final value after matching two datasets |
| 19. | L←max (Xlen, Ylen) |
| 20. | if (P < L/2), then |
| 21. | return 1 // true value will return, i.e., duplication found |
| 22. | else then |
| 23. | return 0 // false value will return, i.e., duplication not found |
| 24. | end if |
| 25. | end procedure DMM |
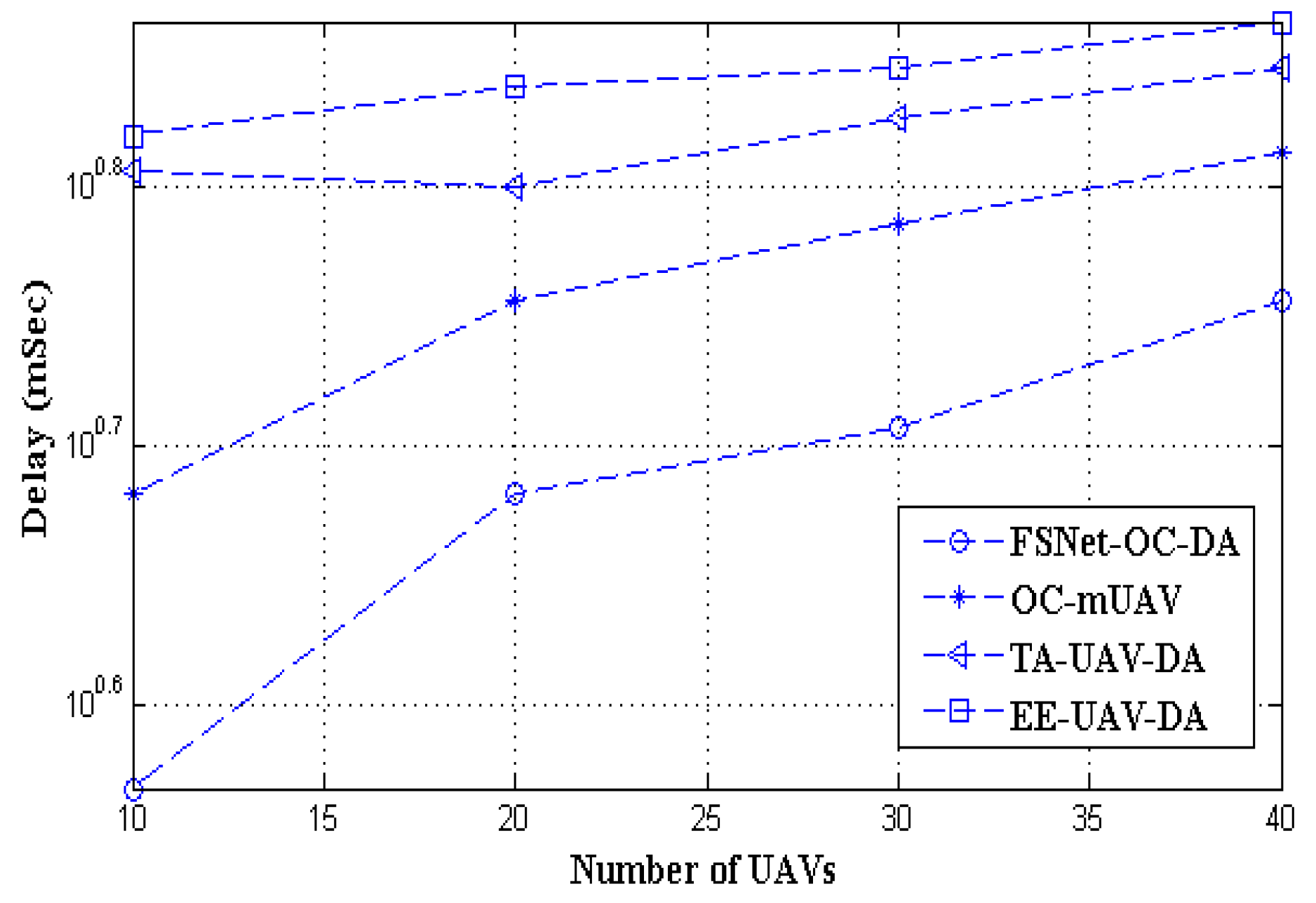
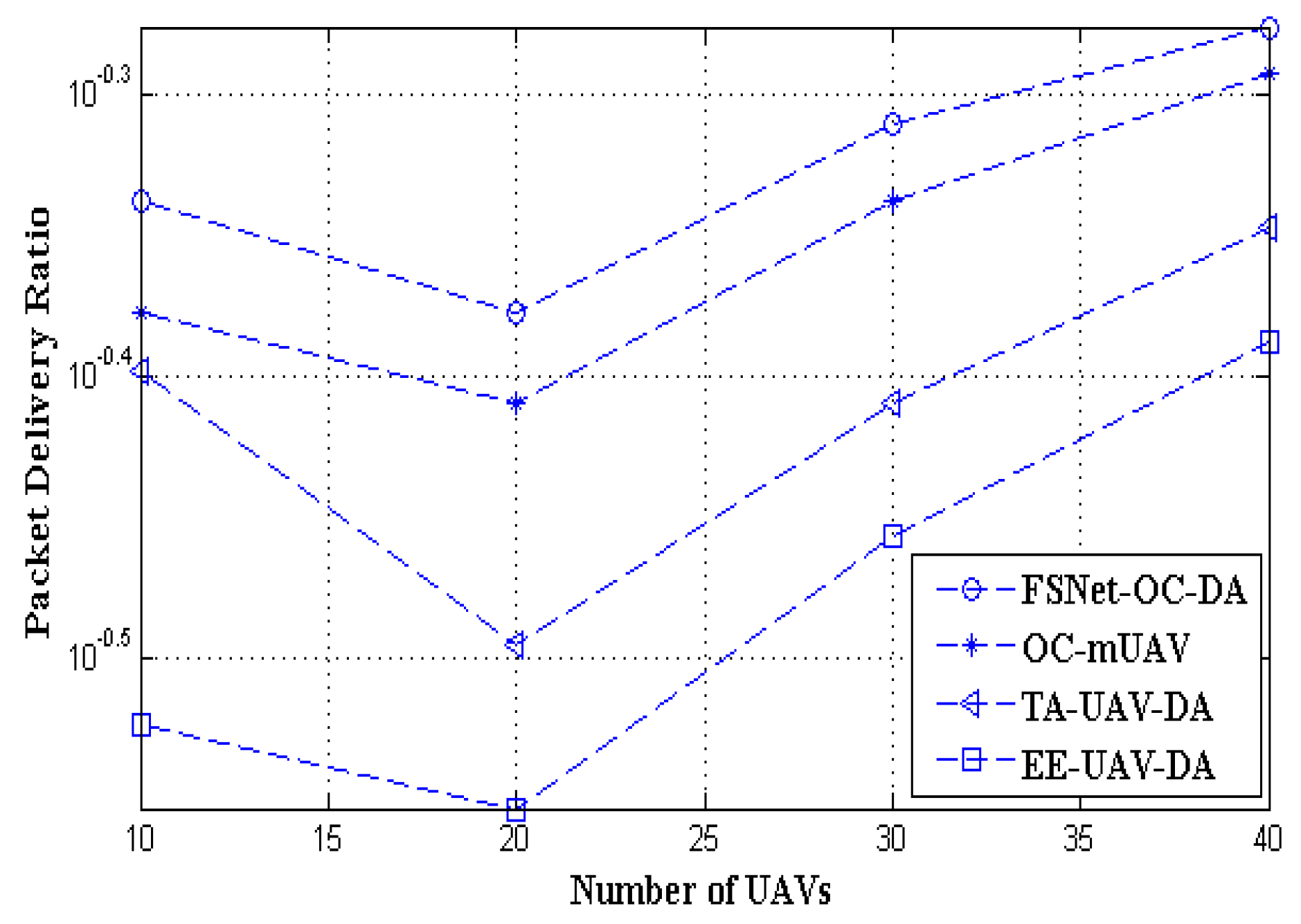
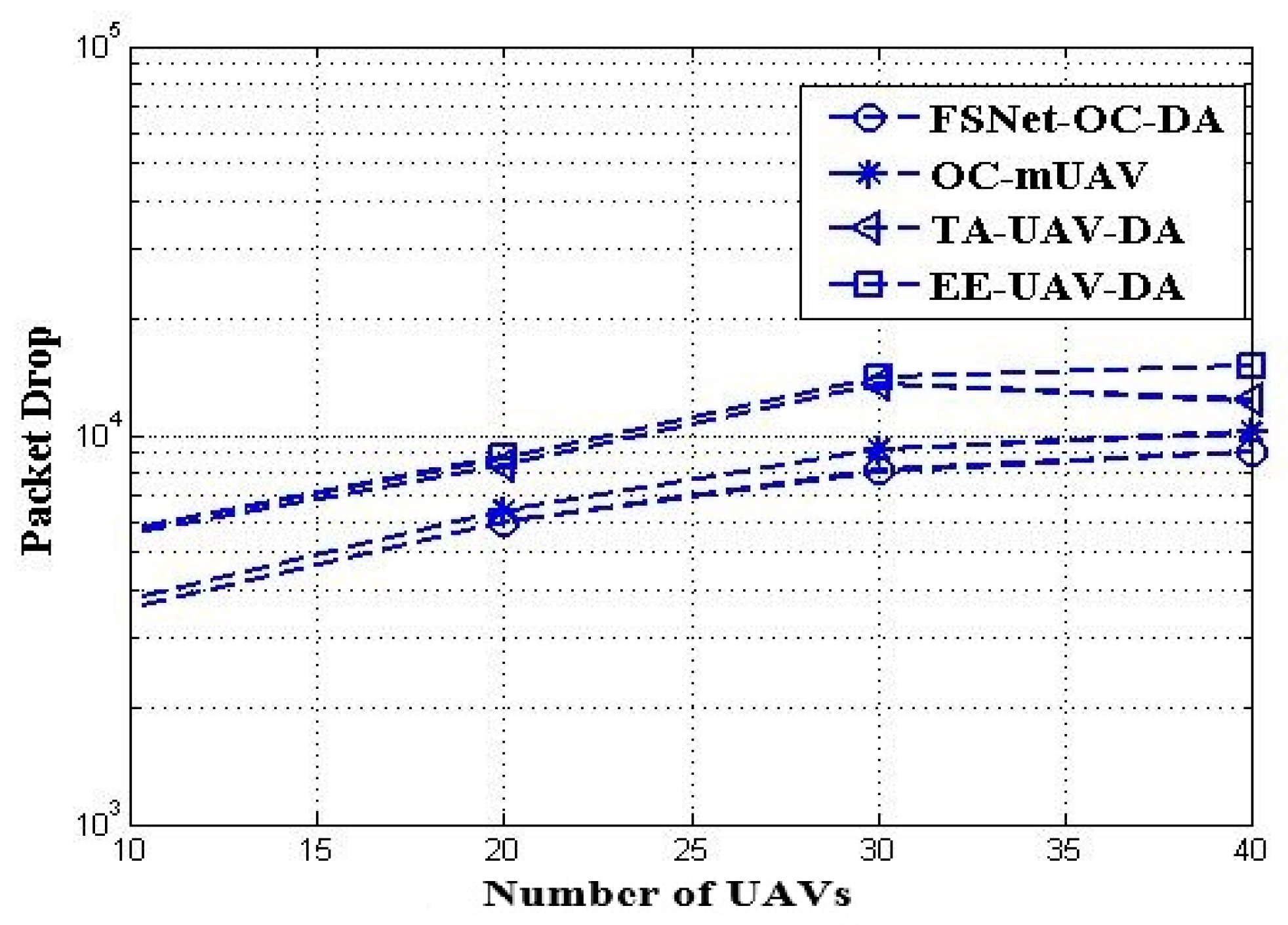
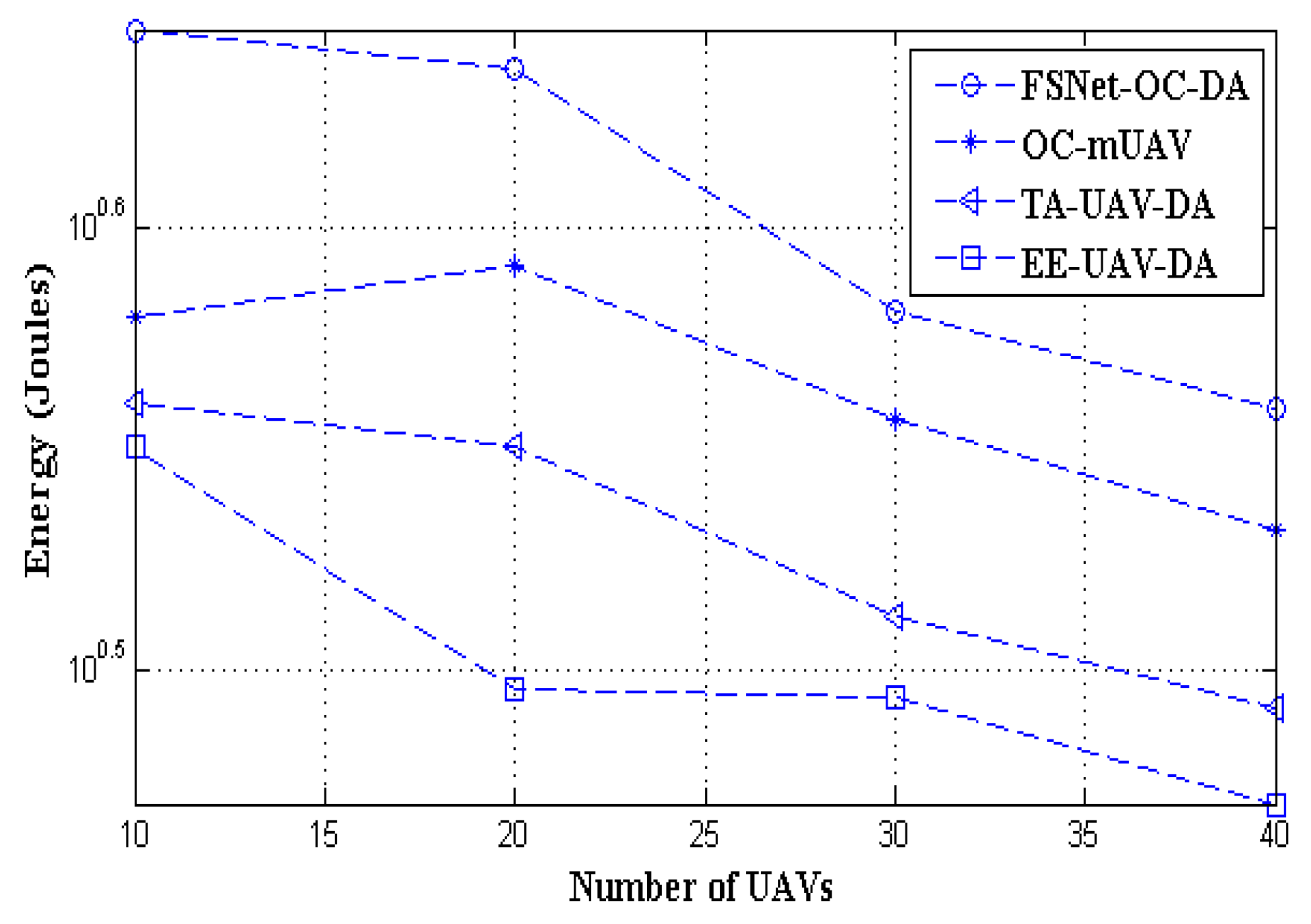
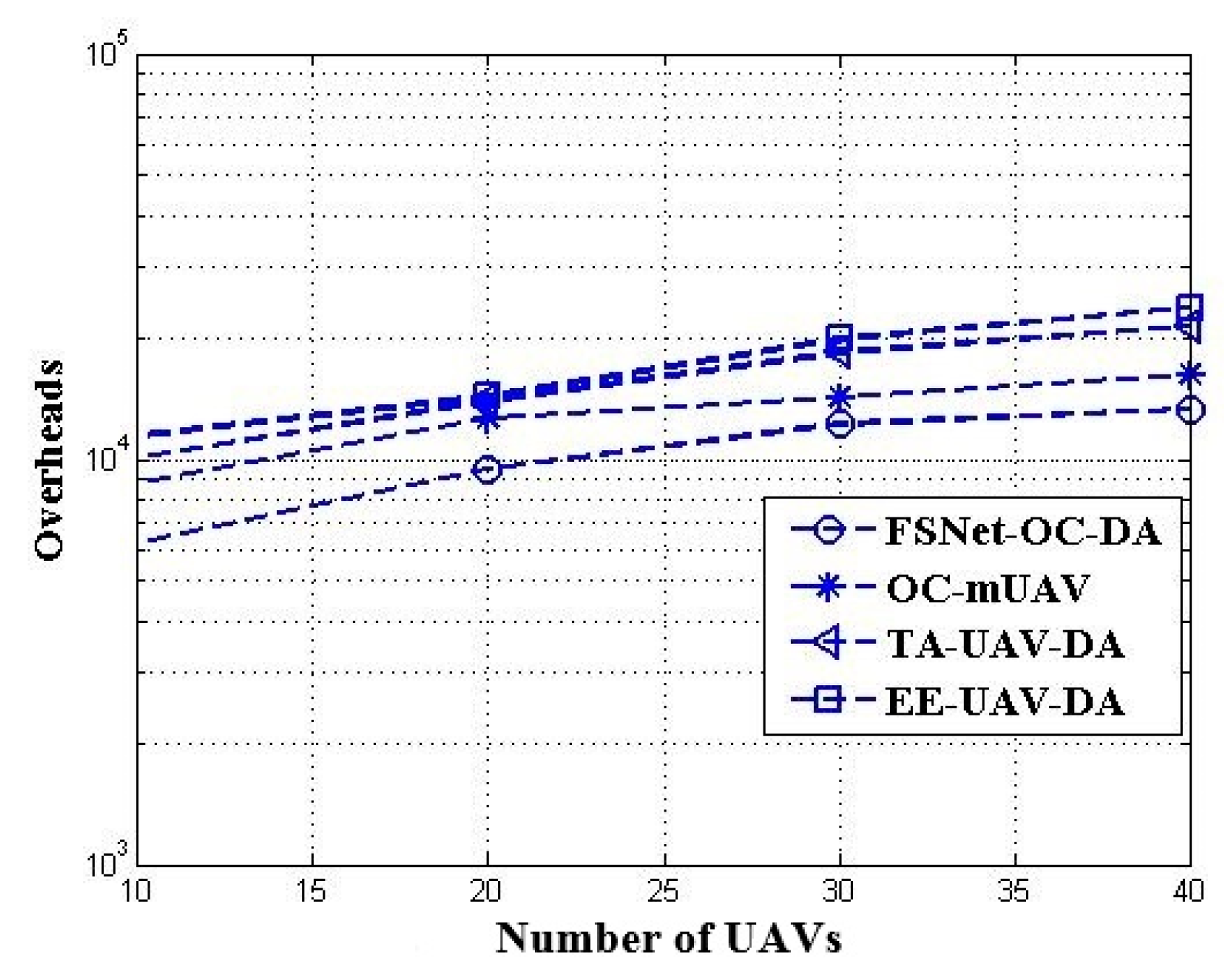
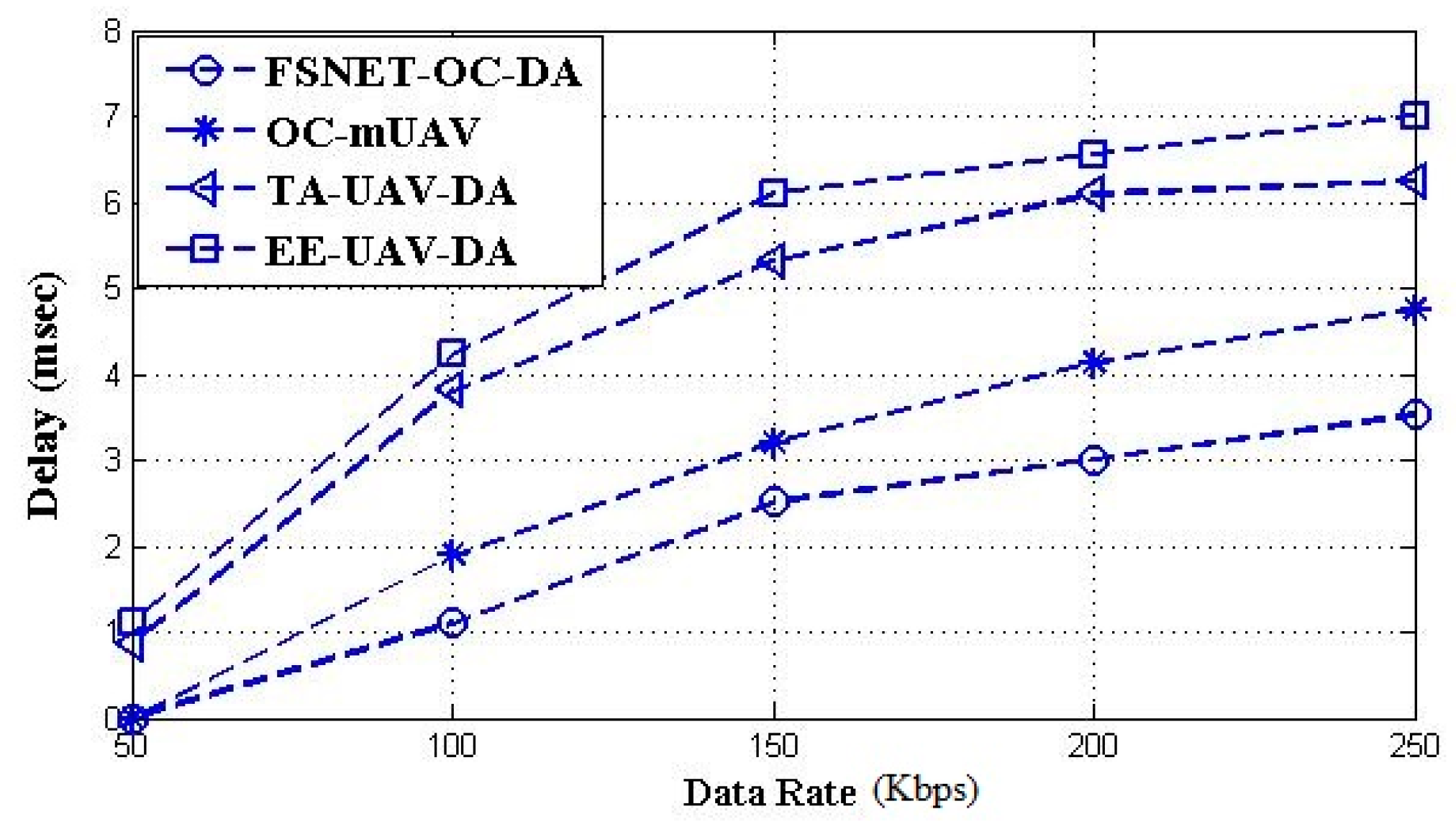
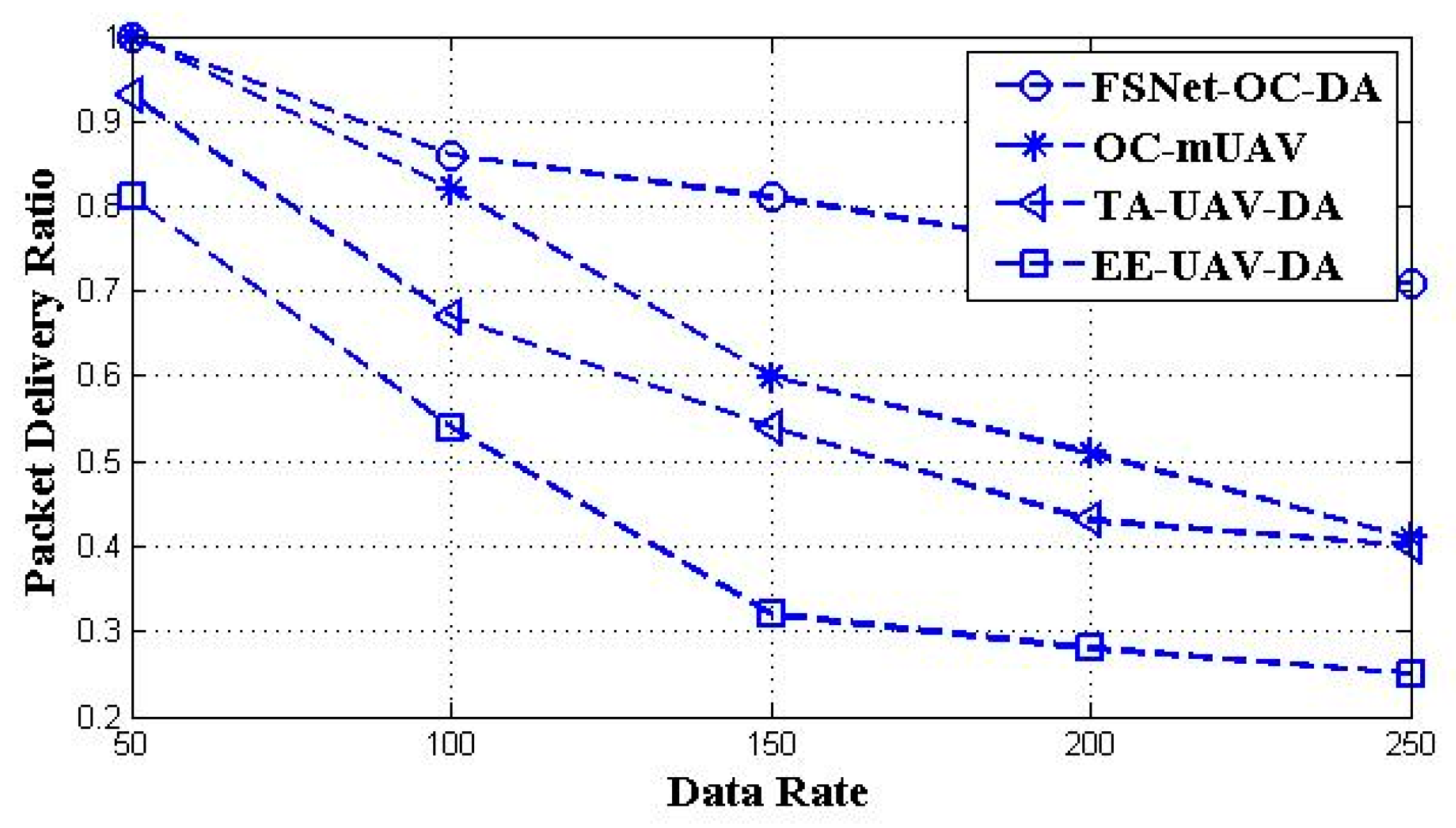
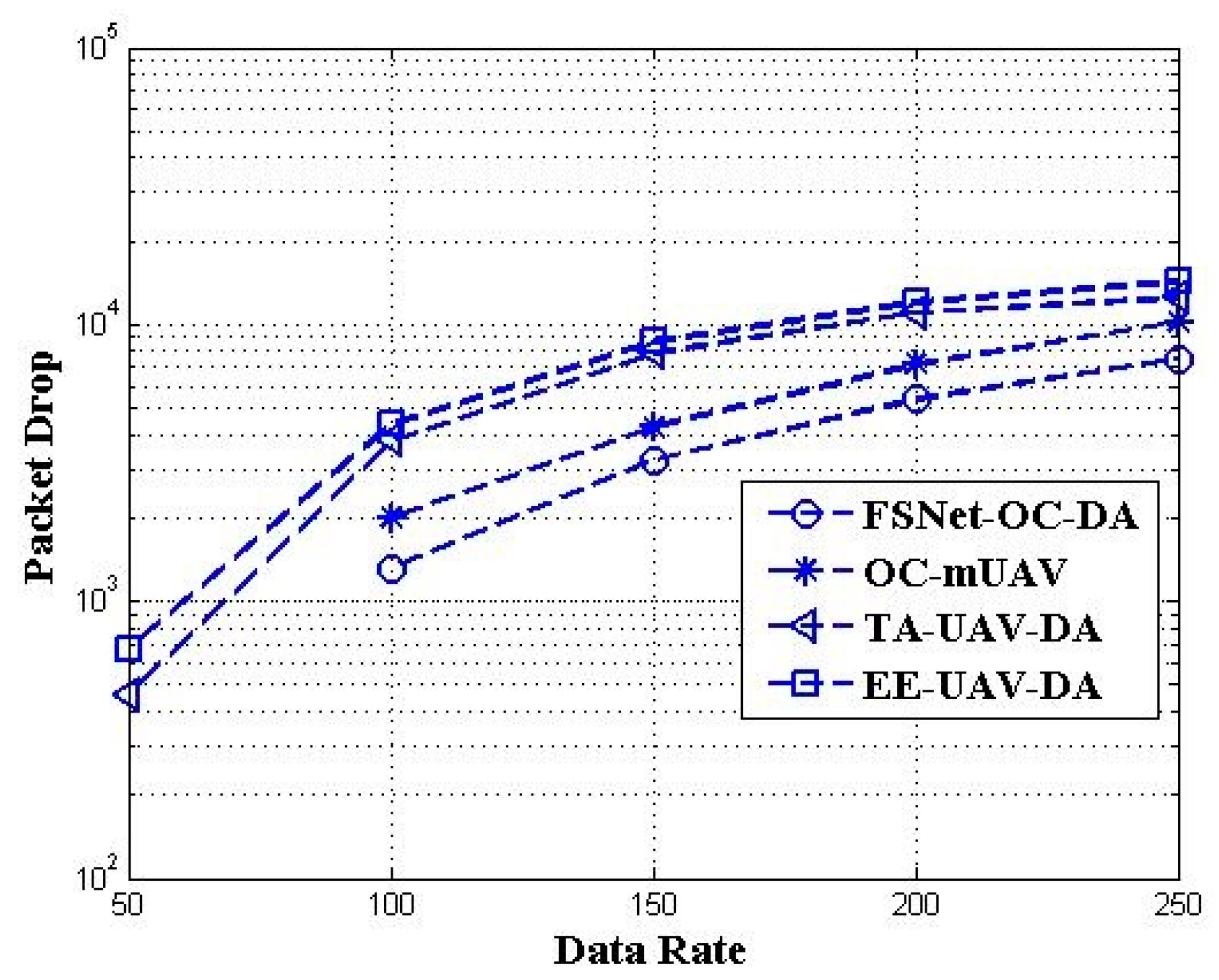
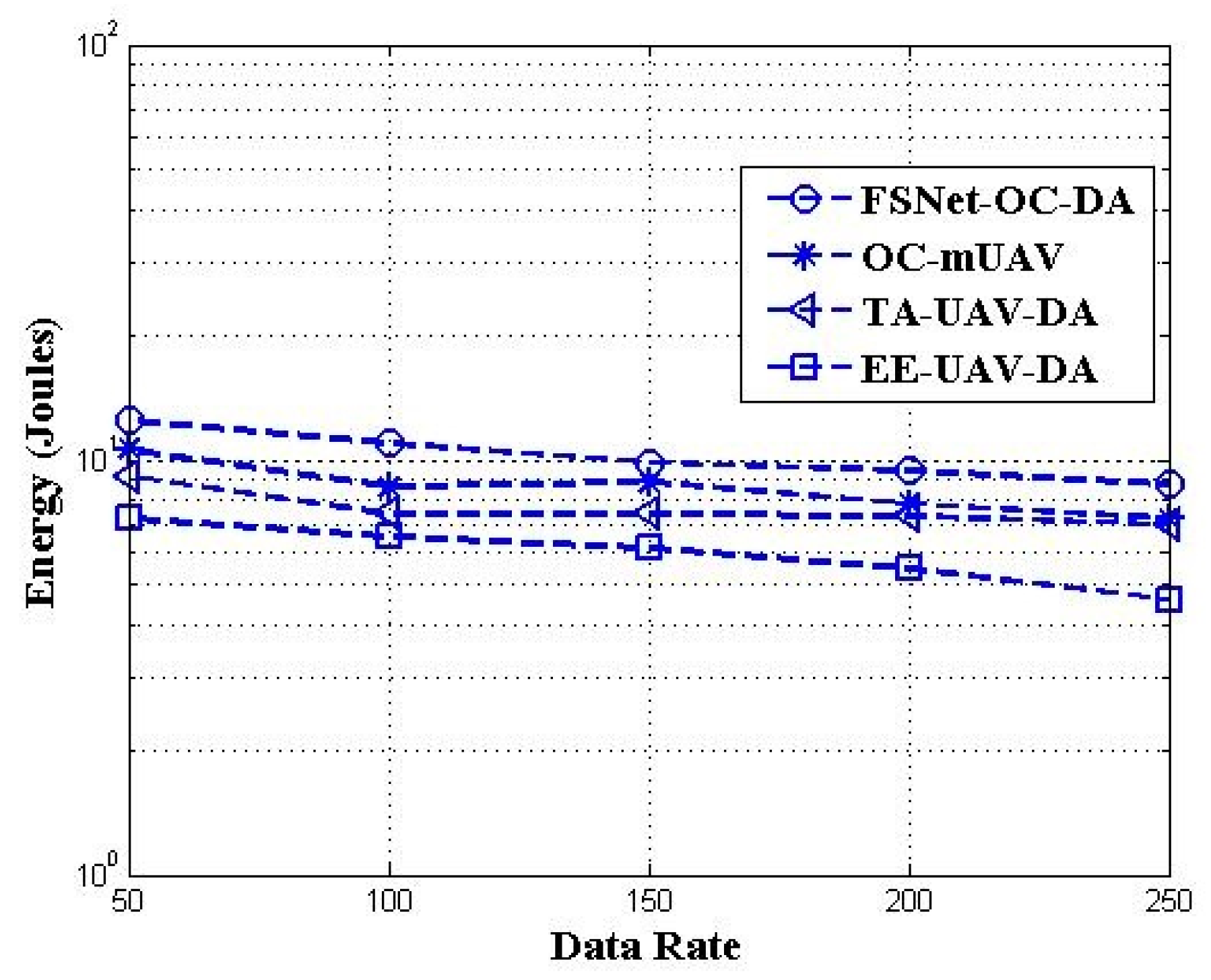
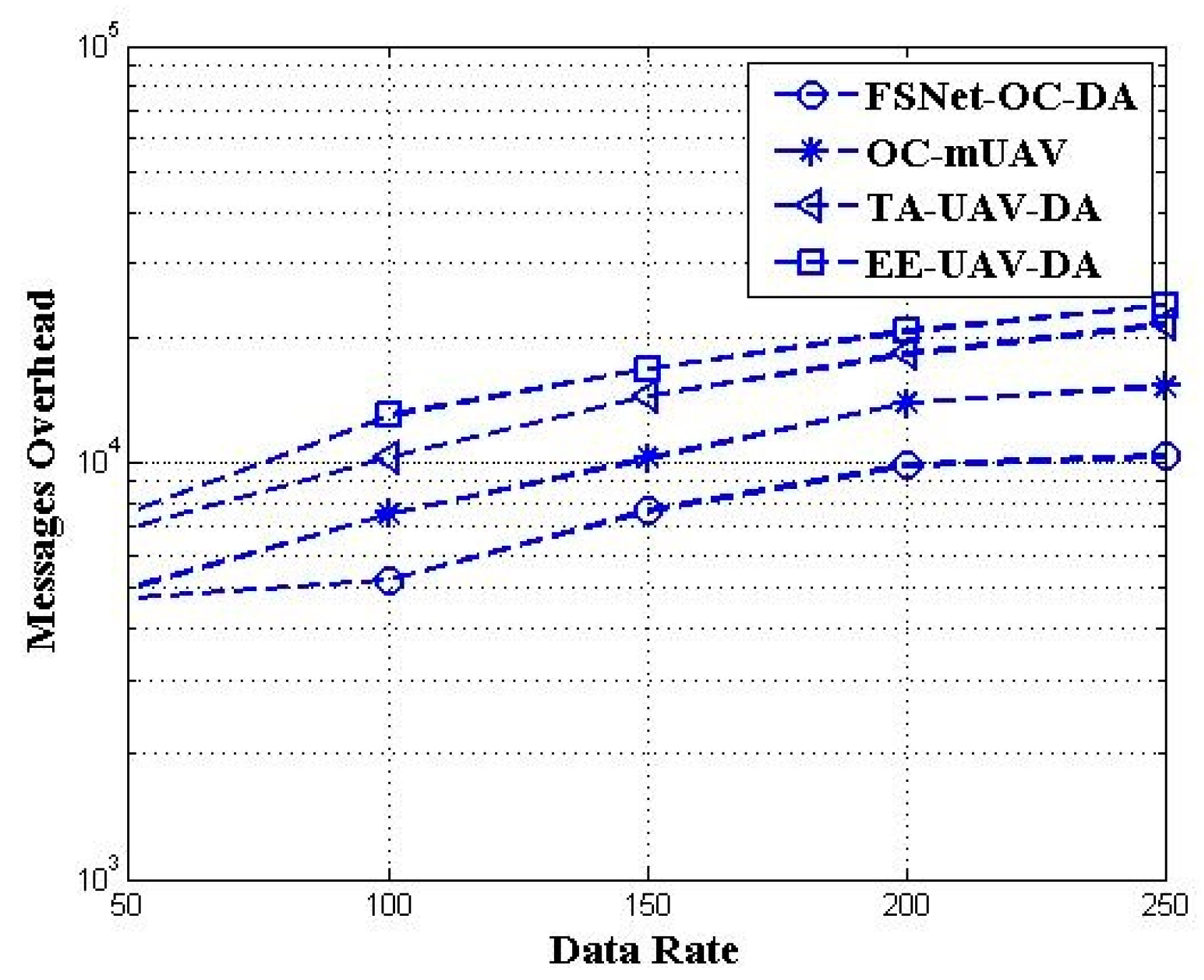
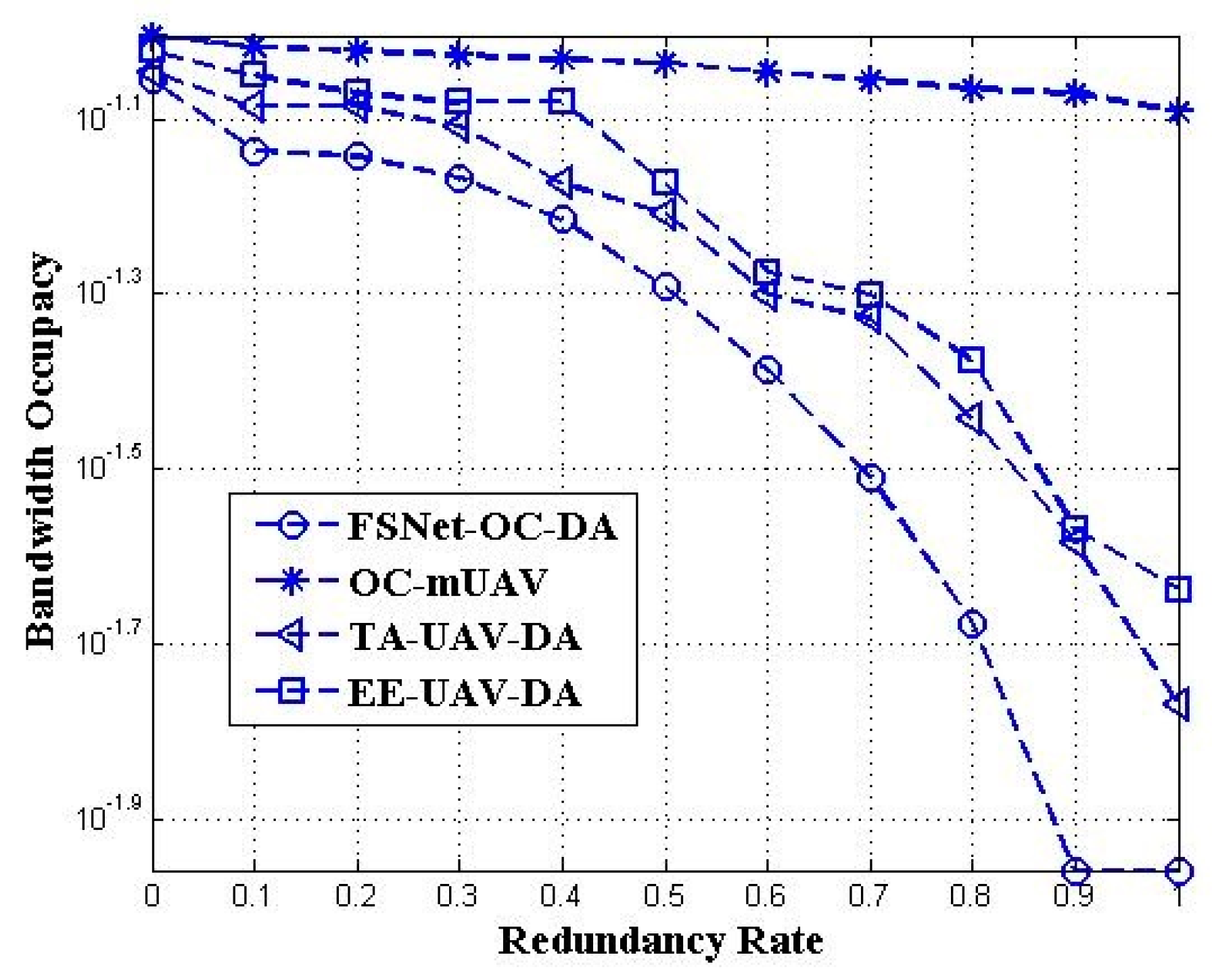
5. Performance Evaluation and Simulation Study
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Alam, M.M.; Arafat, M.Y.; Moh, S.; Shen, J. Topology control algorithms in multi-unmanned aerial vehicle networks: An extensive survey. J. Netw. Comput. Appl. 2022, 207, 103495. [Google Scholar] [CrossRef]
- Sarkar, N.I.; Gul, S. Artificial Intelligence-Based Autonomous UAV Networks: A Survey. Drones 2023, 7, 322. [Google Scholar] [CrossRef]
- Abu-Baker, A.; Shakhatreh, H.; Sawalmeh, A.; Alenezi, A.H. Efficient data collection in UAV-assisted cluster-based wireless sensor networks for 3D Environment: Optimization Study. J. Sens. 2023, 2023, 9513868. [Google Scholar] [CrossRef]
- Luo, X.; Chen, C.; Zeng, C.; Li, C.; Xu, J.; Gong, S. Deep Reinforcement Learning for Joint Trajectory Planning, Transmission Scheduling, and Access Control in UAV-Assisted Wireless Sensor Networks. Sensors 2023, 23, 4691. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, S.; Zhang, J.; Khan, A.; Khan, U.A.; Hayat, B. JO-TADP: Learning-Based Cooperative Dynamic Resource Allocation for MEC–UAV-Enabled Wireless Network. Drones 2023, 7, 303. [Google Scholar] [CrossRef]
- Zhou, R.; Zhang, X.; Song, D.; Qin, K.; Xu, L. Topology Duration Optimization for UAV Swarm Network under the System Performance Constraint. Appl. Sci. 2023, 13, 5602. [Google Scholar] [CrossRef]
- Salam, A.; Javaid, Q.; Ali, G.; Ahmad, F.; Ahmad, M.; Wahid, I. Flying Sensor Network optimization using Bee Intelligence for internet of things. In Advances in Intelligent Systems and Computing, Proceedings of the International Conference on Computer Science and Information Technologies, Zbarazh, Ukraine, 23–26 September 2020; Springer: Cham, Switzerland, 2020; Volume 1252, pp. 331–339. [Google Scholar]
- Chen, T.; Dong, F.; Ye, H.; Wang, Y.; Wu, B. Data Collection Mechanism for UAV-Assisted Cellular Network Based on PPO. Electronics 2023, 12, 1376. [Google Scholar] [CrossRef]
- Amodu, O.A.; Nordin, R.; Jarray, C.; Bukar, U.A.; Raja Mahmood, R.A.; Othman, M. A Survey on the Design Aspects and Opportunities in Age-Aware UAV-Aided Data Collection for Sensor Networks and Internet of Things Applications. Drones 2023, 7, 260. [Google Scholar] [CrossRef]
- Xiong, J.; Li, Z.; Li, H.; Tang, L.; Zhong, S. Energy-Constrained UAV Data Acquisition in Wireless Sensor Networks with the Age of Information. Electronics 2023, 12, 1739. [Google Scholar] [CrossRef]
- Kim, T.; Lee, S.; Kim, K.H.; Jo, Y.-I. FANET Routing Protocol Analysis for Multi-UAV-Based Reconnaissance Mobility Models. Drones 2023, 7, 161. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. JRCS: Joint Routing and charging strategy for logistics drones. IEEE Int. Things J. 2022, 9, 21751–21764. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Habib, M.A.; Moh, S. Routing Protocols for UAV-Aided Wireless Sensor Networks. Appl. Sci. 2020, 10, 4077. [Google Scholar] [CrossRef]
- Noh, K.-L.; Wu, Y.-C.; Qaraqe, K.; Suter, B.W. Extension of pairwise broadcast clock synchronization for Multicluster sensor networks. EURASIP J. Adv. Signal Process. 2008, 2007, 286168. [Google Scholar] [CrossRef]
- Cheng, K.-Y.; Lui, K.-S.; Wu, Y.-C.; Tam, V. A distributed Multihop Time Synchronization Protocol for wireless sensor networks using pairwise broadcast synchronization. IEEE Trans. Wirel. Commun. 2009, 8, 1764–1772. [Google Scholar] [CrossRef]
- Alam, M.M.; Moh, S. Survey on Q-Learning-Based Position-Aware Routing Protocols in Flying Ad Hoc Networks. Electronics 2022, 11, 1099. [Google Scholar] [CrossRef]
- Xiong, F.; Zheng, H.; Ruan, L.; Wang, H.; Tang, L.; Dong, X.; Li, A. Energy-saving data aggregation for Multi-UAV system. IEEE Trans. Veh. Technol. 2020, 69, 9002–9016. [Google Scholar] [CrossRef]
- Aadil, F.; Raza, A.; Khan, M.F.; Maqsood, M.; Mehmood, I.; Rho, S. Energy Aware Cluster-Based Routing in Flying Ad-Hoc Networks. Sensors 2018, 18, 1413. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Moh, S. Localization and clustering based on swarm intelligence in UAV Networks for Emergency Communications. IEEE Internet Things J. 2019, 6, 8958–8976. [Google Scholar] [CrossRef]
- Yang, J.; Wang, X.; Li, Z.; Yang, P.; Luo, X.; Zhang, K.; Zhang, S.; Chen, L. Path planning of unmanned aerial vehicles for farmland information monitoring based on WSN. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation (WCICA) 2016, Guilin, China, 12–15 June 2016. [Google Scholar]
- Yu, Y.; Ru, L.; Chi, W.; Liu, Y.; Yu, Q.; Fang, K. Ant colony optimization based polymorphism-aware routing algorithm for ad hoc UAV network. Multimed. Tools Appl. 2016, 75, 14451–14476. [Google Scholar] [CrossRef]
- Holtorf, L.; Titov, I.; Daschner, F.; Gerken, M. UAV-Based Wireless Data Collection from Underground Sensor Nodes for Precision Agriculture. AgriEngineering 2023, 5, 338–354. [Google Scholar] [CrossRef]
- Zhang, X.; Cao, Y. Memetic Algorithm with Isomorphic Transcoding for UAV Deployment Optimization in Energy-Efficient AIoT Data Collection. Mathematics 2022, 10, 4668. [Google Scholar] [CrossRef]
- Bharany, S.; Sharma, S.; Frnda, J.; Shuaib, M.; Khalid, M.I.; Hussain, S.; Iqbal, J.; Ullah, S.S. Wildfire Monitoring Based on Energy Efficient Clustering Approach for FANETS. Drones 2022, 6, 193. [Google Scholar] [CrossRef]
- Wang, X.; Zhou, Q.; Cheng, C.-T. A UAV-assisted topology-aware data aggregation protocol in WSN. Phys. Commun. 2019, 34, 48–57. [Google Scholar] [CrossRef]
- Wu, Q.; Sun, P.; Boukerche, A. An energy-efficient UAV-based data aggregation protocol in Wireless Sensor Networks. In Proceedings of the 8th ACM Symposium on Design and Analysis of Intelligent Vehicular Networks and Applications 2018, Montreal, QC, Canada, 28 October—2 November 2018; pp. 34–40. [Google Scholar]
- Thammawichai, M.; Baliyarasimhuni, S.P.; Kerrigan, E.C.; Sousa, J.B. Optimizing Communication and computation for Multi-UAV information gathering applications. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 601–615. [Google Scholar] [CrossRef]
- Dong, M.; Ota, K.; Lin, M.; Tang, Z.; Du, S.; Zhu, H. UAV-Assisted Data Gathering in wireless sensor networks. J. Supercomput. 2014, 70, 1142–1155. [Google Scholar] [CrossRef]
- Liu, B.; Zhu, H. Energy-Effective Data Gathering for UAV-Aided Wireless Sensor Networks. Sensors 2019, 19, 2506. [Google Scholar] [CrossRef] [PubMed]
- Cvetković, A.; Blagojević, V.; Manojlović, J. Capacity Analysis of Power Beacon-Assisted Industrial IoT System with UAV Data Collector. Drones 2023, 7, 146. [Google Scholar] [CrossRef]
- Cao, J.; Zhu, X.; Sun, S.; Wei, Z.; Jiang, Y.; Wang, J.; Lau, V.K.N. Toward industrial metaverse: Age of information, latency and reliability of short-packet transmission in 6G. IEEE Wirel. Commun. 2023, 30, 40–47. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, W.; Liu, C. Completion Time Minimization for UAV-UGV-Enabled Data Collection. Sensors 2022, 22, 5839. [Google Scholar] [CrossRef]
- Nie, M.; Huang, P.; Zeng, J.; Lu, Y.; Zhang, T.; Lv, T. A Novel Dynamic Transmission Power of Cluster Heads Based Clustering Scheme. Electronics 2023, 12, 619. [Google Scholar] [CrossRef]
- Zhang, M.; Li, J.; Wu, X.; Wang, X. Coalition Game Based Distributed Clustering Approach for Group Oriented Unmanned Aerial Vehicle Networks. Drones 2023, 7, 91. [Google Scholar] [CrossRef]
- Mehmood, A.; Iqbal, Z.; Shah, A.A.; Maple, C.; Lloret, J. An Intelligent Cluster-Based Communication System for Multi-Unmanned Aerial Vehicles for Searching and Rescuing. Electronics 2023, 12, 607. [Google Scholar] [CrossRef]
- Chen, G.; Chen, G. A Method of Relay Node Selection for UAV Cluster Networks Based on Distance and Energy Constraints. Sustainability 2022, 14, 16089. [Google Scholar] [CrossRef]
- Salam, A.; Javaid, Q.; Ahmad, M. Bioinspired mobility-aware clustering optimization in flying ad hoc sensor network for internet of things: Bimac-FASNET. Complexity 2020, 2020, 9797650. [Google Scholar] [CrossRef]
- Cormode, G.; Muthukrishnan, S. The string edit distance matching problem with moves. ACM Trans. Algorithms 2007, 3, 1–19. [Google Scholar] [CrossRef]
- Shapira, D.; Storer, J.A. Edit Distance with Move Operations. In Combinatorial Pattern Matching, Proceedings of the CPM 2002, Fukuoka, Japan, 3–5 July 2002; Lecture Notes in Computer Science; Apostolico, A., Takeda, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2373, p. 2373. [Google Scholar] [CrossRef]
- Maruyama, S.; Nakahara, M.; Kishiue, N.; Sakamoto, H. ESP-index: A compressed index based on edit-sensitive parsing. J. Discrete Algorithms 2013, 18, 100–112. [Google Scholar] [CrossRef]
- Wheeb, A.H.; Nordin, R.; Samah, A.A.; Kanellopoulos, D. Performance Evaluation of Standard and Modified OLSR Protocols for Uncoordinated UAV Ad-Hoc Networks in Search and Rescue Environments. Electronics 2023, 12, 1334. [Google Scholar] [CrossRef]
- Liu, P.; Wang, X.; Hawbani, A.; Busaileh, O.; Zhao, L.; Al-Dubai, A. FRCA: A novel flexible routing computing approach for wireless sensor networks. IEEE Trans. Mob. Comput. 2020, 19, 2623–2639. [Google Scholar] [CrossRef]
- Hu, Y.; Liu, Y.; Kaushik, A.; Masouros, C.; Thompson, J. Timely data collection for UAV-based IOT Networks: A deep reinforcement learning approach. IEEE Sens. J. 2023, 23, 12295–12308. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Network Simulator | MATLAB |
| Covered Area | 2 km × 2 km |
| MAC Protocol | IEEE 802.11 and IEEE 802.16 |
| Antenna Type | Omni directional |
| Propagation Model | Two-ray ground reflection model (intra-cluster) Long-distance propagation loss model (inter-cluster) |
| Radio Frequency | 2.4 GHz, 5 GHz |
| Number of UAVs | 10 to 60 |
| UAV Altitude | 40–50 m |
| UAV Transmission Range | 200 to 300 m |
| UAV Mobility Model | Random waypoint model |
| Transport Protocol | Stream control transmission protocol (SCTP) |
| Traffic Model | Poisson traffic model |
| Application Packet Size | 1000 Bytes |
| Initial Energy | 2 to 5 J |
| Channel Model | Multi-Propagation Channel (MPC) Model |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salam, A.; Javaid, Q.; Ahmad, M.; Wahid, I.; Arafat, M.Y. Cluster-Based Data Aggregation in Flying Sensor Networks Enabled Internet of Things. Future Internet 2023, 15, 279. https://doi.org/10.3390/fi15080279
Salam A, Javaid Q, Ahmad M, Wahid I, Arafat MY. Cluster-Based Data Aggregation in Flying Sensor Networks Enabled Internet of Things. Future Internet. 2023; 15(8):279. https://doi.org/10.3390/fi15080279
Chicago/Turabian StyleSalam, Abdu, Qaisar Javaid, Masood Ahmad, Ishtiaq Wahid, and Muhammad Yeasir Arafat. 2023. "Cluster-Based Data Aggregation in Flying Sensor Networks Enabled Internet of Things" Future Internet 15, no. 8: 279. https://doi.org/10.3390/fi15080279