

Scope and Accuracy of Analytic and Approximate Results for FIFO, Clock-Based and LRU Caching Performance

Abstract
:1. Introduction: Basic Caching Methods and Their Evaluations
- product form solutions are extended to clock-based methods and combinations of those methods, with FIFO and RANDOM for single and multilevel caches,
- the scope of analytical solutions is clarified regarding scalable computation as well as the solutions’ applicability for data of different sizes, and
- quantitative evaluations of the accuracy of approximations identify the worst cases and error bound extensions for varying data sizes in caches.
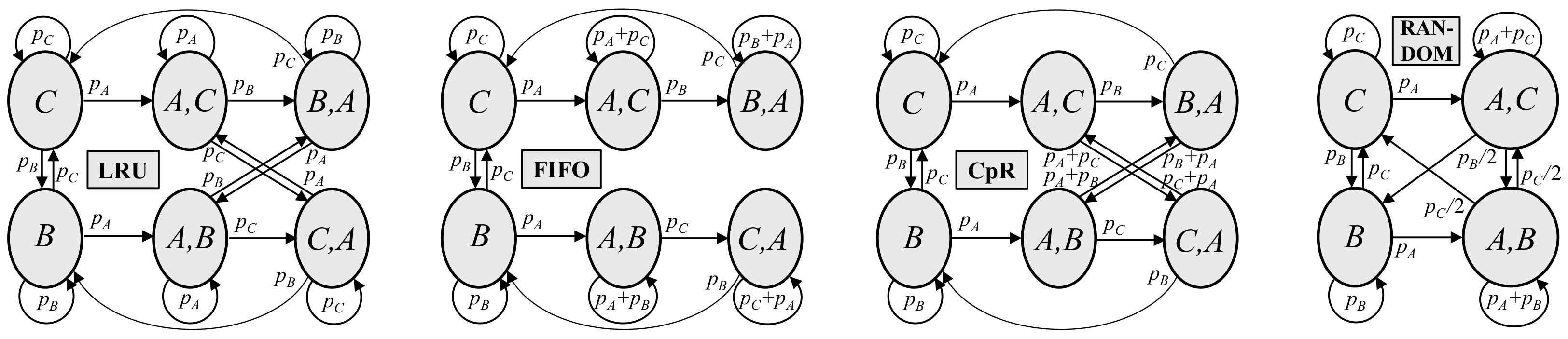
2. Markov Analysis Results for Basic Caching Strategies
2.1. Common Hit Ratio Analysis of FIFO, RANDOM and Clock-Based Caching
2.2. Scalable Iterative Evaluation of the Product Form Solution
3. Approximation of the IRM Hit Ratio for FIFO
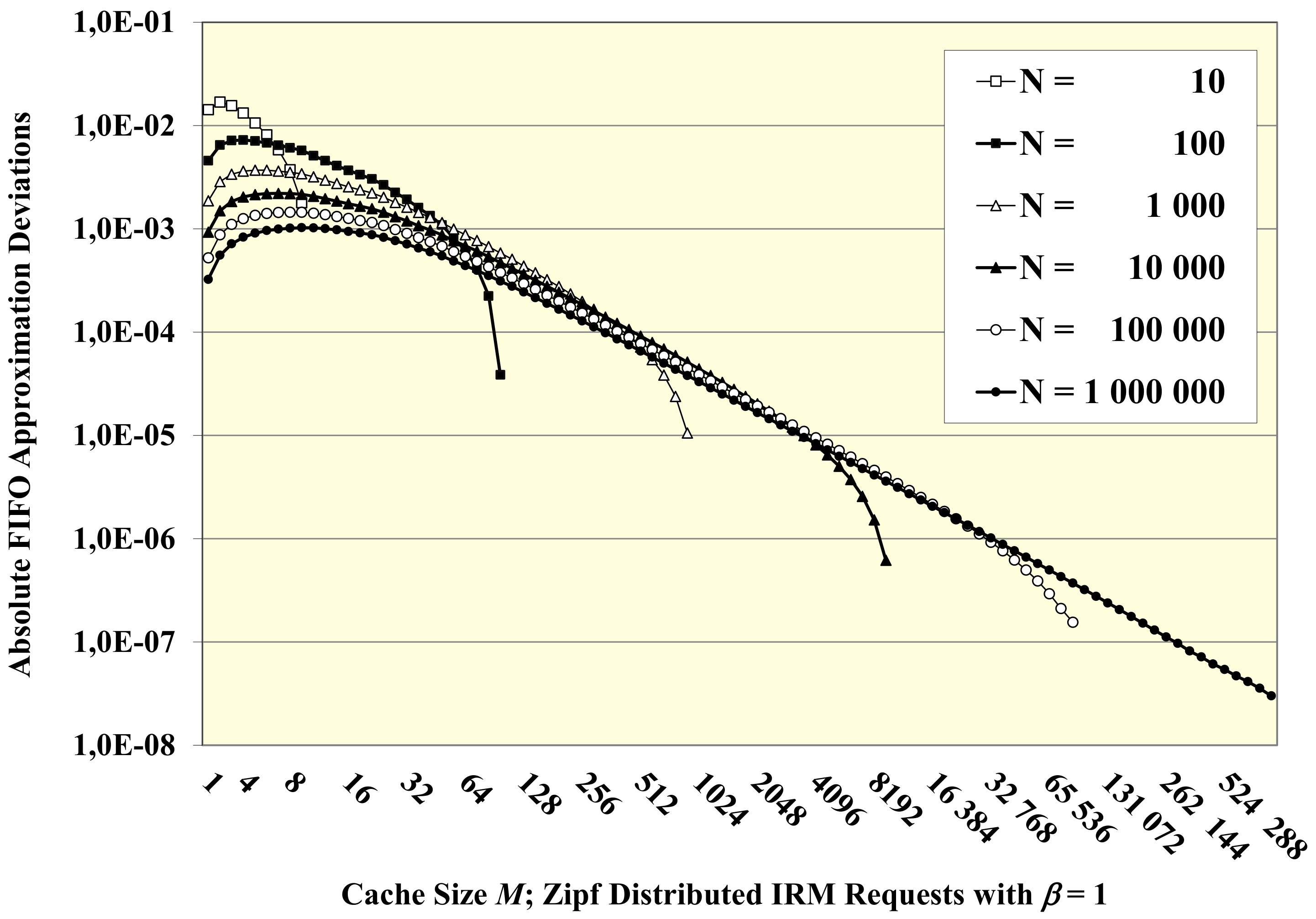
3.1. Precision of the FIFO Approximation for Zipf-Distributed IRM Requests

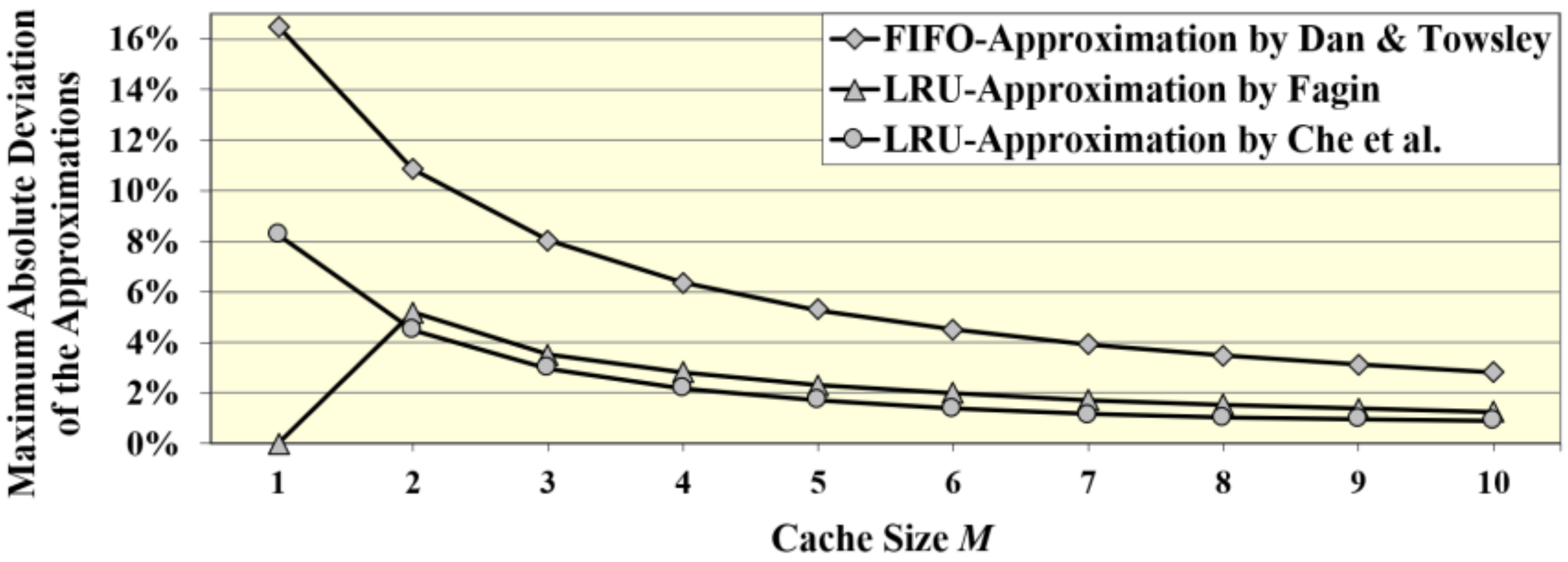
3.2. Maximum Error Cases of the FIFO Approximation for Small Cache Size M
- Considerable errors of up to 16.5% are encountered for small cache size M.
- They are reduced towards a fair accuracy with errors below 3% for M ≥ 10.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Maximum Deviations of the FIFO, RANDOM & CpR Approximation for Cache Size M: Worst Cases Are Request Distributions of the Type (6) with n = M | ||||
|---|---|---|---|---|
| M | p1= ∙∙∙ = pn (n = M) | Exact Result of Equation (2) | Approximation of Equations (4) and (5) | Maximum Deviation |
| 1 | 0.8838 | 78.11% | 61.62% | –16.49% |
| 2 | 0.4705 | 84.13% | 73.30% | –10.83% |
| 3 | 0.3213 | 87.49% | 79.45% | –8.04% |
| 4 | 0.2440 | 89.75% | 83.37% | –6.38% |
| 5 | 0.1965 | 91.35% | 86.07% | –5.28% |
| 6 | 0.1645 | 92.51% | 88.00% | –4.51% |
| 7 | 0.1414 | 93.41% | 89.48% | –3.93% |
| 8 | 0.1240 | 94.10% | 90.62% | –3.48% |
| 9 | 0.1104 | 94.69% | 91.57% | –3.13% |
| 10 | 0.0995 | 95.14% | 92.30% | –2.84% |
4. Approximations of the LRU Hit Ratio
- is approximated by the unique solution of the equation M =.
- Thereafter, the LRU hit ratio is obtained per object (hChe (Oj)) and in total (hChe):
- The maximum deviations ∆hChe of Che’s approximation are decreasing with the cache size M from 8.25% for M = 1 down to less than 1% for M ≥ 10.
- The maximum deviations ∆hFagin of Fagin’s approximation are decreasing with the cache size M from 5.2% for M = 2 down to less than 1.3% for M ≥ 10.
5. Extended Product Form Solution for Multisegment Caches

6. FIFO and LRU Caching Analysis with Data of Different Sizes
6.1. LRU Cache Hit Ratio Solution for Objects of Different Sizes
6.2. No Common FIFO, RANDOM and CpR Solution for Objects of Different Sizes
- (1)
- The FIFO, RANDOM and CpR hit ratios are different for variable data sizes. Their common product form solution (2) [6] is restricted to unit-size objects.
- (2)
- The proven “LRU is better than FIFO under IRM” result [40] is also restricted to unit data size and again violated in the previous example.
- (3)
- Moreover, a monotonous increase in the LRU, FIFO, RANDOM and CpR hit ratio curves (HRC) with the cache size M again holds only for unit data size.
- Value and Byte Hit Ratio
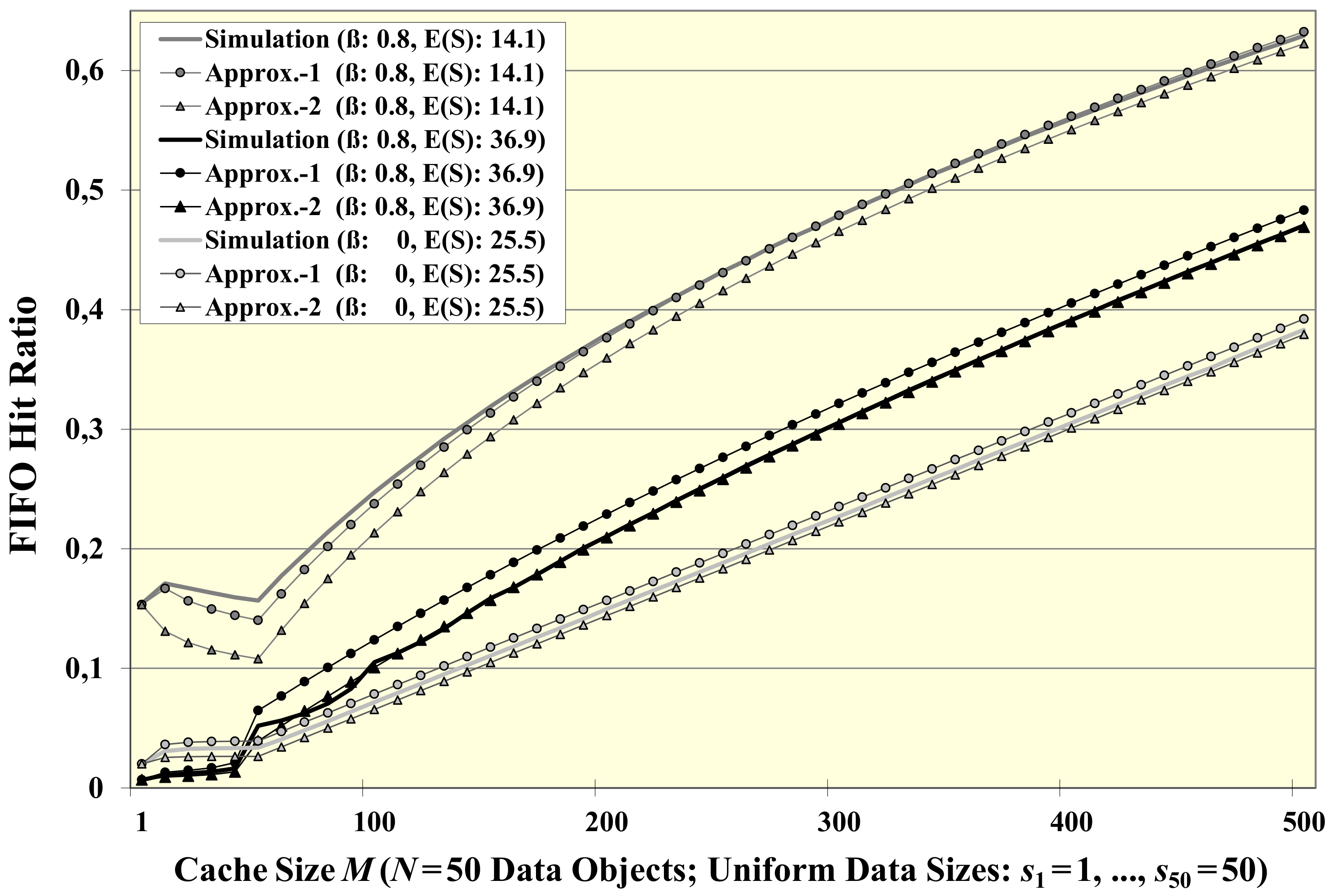
6.3. Extended Approximations for Objects of Different Sizes
6.4. Oversize Objects and Unused Cache Space (UCS)
6.5. Approximation Scheme for the Mean Unused Space in FIFO Caches
- β = 0, i.e., for uniform requests among all data objects (p1 = … = p50 = 2%),
- β = 0.8 with a preference for small objects (p1 ≈ 15.3%, p2 ≈ 8.8%, …, p50 ≈ 0.67%), and
- β = 0.8 with a preference for large objects (p50 ≈ 15.3%, …, p1 ≈ 0.67%).

7. Conclusions
- The maximum absolute deviations |∆hChe| of Che’s approximation are decreasing with the cache size M from 8.25% for M = 1 down to less than 1% for M ≥ 10.
- The maximum absolute deviations |∆hFagin| of Fagin’s approximation are decreasing with the cache size M from 5.2% for M = 2 down to less than 1.3% for M ≥ 10.
- The maximum deviations of the FIFO approximation [25] are decreasing with the cache size M from 16.5% for M = 1 down to less than 3% for M ≥ 10.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Podlipnik, S.; Böszörmenyi, L. A survey of web cache replacement strategies. ACM Comput. Surv. 2003, 35, 374–398. [Google Scholar] [CrossRef]
- Arlitt, M.; Williamson, C. Internet web servers: Workload characterization and performance implications. IEEE Trans. Netw. 1997, 5, 631–645. [Google Scholar] [CrossRef]
- Li, S.; Xu, J.; van der Schaar, M.; Li, W. Popularity-driven content caching. In Proceedings of the IEEE Infocom, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]
- Paschos, G.S.; Iosifidis, G.; Tao, M.; Towsley, D.; Caire, G. The role of caching in future communication systems and networks. IEEE JSAC 2018, 36, 1111–1125. [Google Scholar] [CrossRef] [Green Version]
- Corbato, F.J. A paging experiment with the Multics system. MIT Proj. MAC Rep. MAC-M-384 1968, 1–14. [Google Scholar]
- Gelenbe, E. A unified approach to the evaluation of a class of replacement algorithms. IEEE Trans. on Comp. 1973, 100, 611–618. [Google Scholar] [CrossRef]
- McCabe, J. On serial files with relocatable records. Oper. Res. 1965, 13, 609–618. [Google Scholar] [CrossRef]
- King, W.F., III. Analysis of demand paging algorithms. In Proceedings of the IFIP Congress, Ljubljana, Yugoslavia, 23–28 August 1971; pp. 485–490. [Google Scholar]
- Lee, D.; Choi, J.; Kim, J.H.; Noh, S.H.; Min, S.L.; Cho, Y.; Kim, C.S. LRFU: A spectrum of policies that subsumes the least recently used and least frequently used policies. IEEE Trans. Comput. 2001, 50, 1352–1361. [Google Scholar]
- Dehghan, M.; Massoulie, L.; Towsley, D.; Menasche, D.S.; Tay, Y.C. A Utility optimization approach to network cache design. IEEE/ACM Trans. Netw. 2019, 27, 1013–1027. [Google Scholar] [CrossRef] [Green Version]
- Hasslinger, G.; Ntougias, K.; Hasslinger, F.; Hohlfeld, O. Performance evaluation for new web caching strategies combining LRU with score-based selection. Comput. Netw. 2017, 125, 172–186. [Google Scholar] [CrossRef]
- Li, J.; Shakkottai, S.; Lui, J.C.S.; Subramanian, V. Accurate learning or fast mixing? Dynamic adaptability of caching algorithms. IEEE JSAC 2018, 36, 1314–1330. [Google Scholar] [CrossRef] [Green Version]
- Paschos, G.S.; Iosifidis, G.; Caire, G. Cache optimization models and algorithms. Found. Trends Commun. Inf. Theory 2020, 16, 156–345. [Google Scholar] [CrossRef]
- Eytan, O.; Harnik, D.; Ofer, E.; Friedman, R.; Kat, R. It’s time to revisit LRU vs. FIFO. In Proceedings of the 12th USENIX HotStorage Workshop, Berkeley, CA, USA, 13–14 July 2020; pp. 1–7. [Google Scholar]
- Hasslinger, G.; Ntougias, K.; Hasslinger, F.; Hohlfeld, O. Fast and efficient web caching methods regarding the properties per data. In Proceedings of the IEEE CAMAD, Limassol, Cyprus, 11–13 September 2019; pp. 1–7. [Google Scholar]
- Yang, J.; Yue, Y.; Rashmi, K.V. A large-scale analysis of key-value cache clusters at Twitter. ACM Trans. Storage 2021, 17, 1–35. [Google Scholar] [CrossRef]
- ElAarag, H. Web Proxy Cache Strategies: Simulation, Implementation and Performance Evaluation; Springer Publisher: Berlin/Heidelberg, Germany, 2013; pp. 1–103. [Google Scholar]
- Megiddo, N.; Modha, S. Outperforming LRU with an adaptive replacement cache algorithm. IEEE Comput. 2004, 37, 58–65. [Google Scholar] [CrossRef]
- Ntougias, K.; Papadias, C.B.; Papageorgiou, G.K.; Hasslinger, G.; Sorensen, T.B. Coordinated caching and QoS-aware resource allocation for spectrum sharing. Wirel. Pers. Comm. 2020, 112, 49–79. [Google Scholar] [CrossRef]
- Gast, N.; Van Houdt, B. Transient and steady-state regime of a family of list-based cache replacement algorithms. In Proceedings of the ACM Sigmetrics, Portland, OR, USA, 15–19 June 2015. [Google Scholar]
- Hasslinger, G.; Ntougias, K.; Hasslinger, F.; Hohlfeld, O. Analysis of the LRU cache startup phase and convergence time and error bounds on approximations by Fagin and Che. In Proceedings of the WiOpt Symposium, CCDWN workshop, Turin, Italy, 19 September 2022; pp. 1–8. [Google Scholar]
- Wong, K.Y.; Yeung, A.; Choi, K.C.; Lei, P.; Lam, C.T. Exact transient analysis on LRU cache startup for IoT. In Proceedings of the 9th International Conference on Information Technology: IoT and Smart City, New York, NY, USA, 22–25 December 2021; pp. 310–315. [Google Scholar]
- Fagin, R. Asymptotic miss ratios over independent references. J. Comp. Syst. Sci. 1977, 14, 222–250. [Google Scholar] [CrossRef] [Green Version]
- Che, H.; Tung, Y.; Wang, Z. Hierarchical web caching systems: Modeling, and experimental design. IEEE JSAC 2002, 20, 1305–1314. [Google Scholar]
- Dan, A.; Towsley, D. An approximate analysis of the LRU and FIFO buffer replacement schemes. In Proceedings of the ACM SIGMETRICS, Boulder, CO, USA, 22–25 May 1990; pp. 143–152. [Google Scholar]
- Berthet, C. Approximation of LRU caches miss rate: Application to power-law popularities. arXiv 2017, arXiv:1705.10738. [Google Scholar]
- Brenner, M. A Lyapunov analysis of LRU. Master Thesis, University of Illinois Urbana-Champaign, Champaign, IL, USA, 2020; pp. 1–42. [Google Scholar]
- Fricker, C.; Robert, P.; Roberts, J. A versatile, accurate approximation for LRU cache performance. In Proceedings of the ITC 24, Krakow, Poland, 4–7 September 2012; pp. 1–8. [Google Scholar]
- Poojary, P.; Moharir, S.; Jagannathan, K. A coupon collector based approximation for LRU cache hits for Zipf requests. In Proceedings of the 19th International Symposium on Modeling and Optimization in Mobile, Ad hoc, and Wireless Networks (WiOpt), Philadelphia, PA, USA, 18–21 October 2021; pp. 1–8. [Google Scholar]
- Fagin, R.; Price, T.G. Efficient calculation of expected miss ratios in the independent reference model. SIAM J. Comput. 1978, 7, 288–296. [Google Scholar] [CrossRef]
- Breslau, L.; Cao, P.; Fan, L.; Phillips, G.; Shenker, S. Web caching and Zipf-like distributions: Evidence and implications. In Proceedings of the IEEE Infocom, New York, NY, USA, 21–25 March 1999; pp. 126–134. [Google Scholar]
- Traverso, S.; Ahmed, M.; Garetto, M.; Giaccone, P.; Leonardi, E.; Niccolini, S. Unraveling the impact of temporal and geographical locality in caching systems. IEEE Trans. 2015, 17, 1839–1854. [Google Scholar]
- Hasslinger, G.; Kunbaz, M.; Hasslinger, F.; Bauschert, T. Web caching evaluation for Wikipedia request statistics. In Proceedings of the IEEE WiOpt Symposium, Paris, France, 15–19 May 2017; pp. 1–6. [Google Scholar]
- Rosensweig, E.J.; Menasche, D.S.; Kruose, J. On the steady-state of cache networks. In Proceedings of the IEEE Infocom, Turin, Italy, 14–19 April 2013; pp. 863–871. [Google Scholar]
- Marin, A.; Rossi, S.; Burato, D.; Sina, A.; Sottana, M. A product-form model for the performance evaluation of a bandwidth allocation strategy in WSN. ACM TOMACS 2018, 28, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Tsukada, N.; Hirade, R.; Miyoshi, N. Fluid limit analysis of FIFO and RR caching for IRM. Perform. Eval. 2012, 69, 403–412. [Google Scholar] [CrossRef]
- Garetto, M.; Leonardi, E.; Martina, V. A unified approach to the performance analysis of caching systems. ACM Trans. Model. Perform. Eval. Comput. Syst. 2016, 1, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Gast, N.; Van Houdt, B. TTL approximations of the cache replacement algorithms LRU(m) and h-LRU. In Performance Evaluation; Elsevier: Amsterdam, The Netherlands, 2017; pp. 33–57. [Google Scholar]
- Gomaa, H.; Messier, G.G.; Williamson, C.; Davies, R. Estimating instantaneous cache hit ratio using Markov chain analysis. IEEE/ACM Trans. Netw. 2013, 21, 1472–1483. [Google Scholar] [CrossRef]
- Van den Berg, J.; Gandolf, A. LRU is better than FIFO under the independent reference model. J. Appl. Probab. 1992, 29, 239–243. [Google Scholar] [CrossRef] [Green Version]
- Starobinsky, D.; Tse, D. Probabilistic methods for web caching. Perf. Eval. 2001, 46, 125–137. [Google Scholar] [CrossRef] [Green Version]




| Solution Type and References | Applies to | Scalable Computation | Different Object Sizes | Maximum Deviations | |
|---|---|---|---|---|---|
| Analytic Cache Hit Ratio Results | Product Form [8] Equations (1) and (2) | FIFO, Clock p.R., RANDOM | ☑ [30] Section 2.2 | ☒ No Common Solution fo FIFO, CpR, RANDOM | Numerially Exact Evaluations |
| Extension [20] Equation (10) | Multi-Level Caches | Complex, but Scalable | |||
| LRU Formula [8] Equations (11) and (12) | LRU & Cache Fill Phases | ☒ Only for Small Caches | ☑ Extension Equation (13) [21] | ||
| Approximations | Dan et al. [25] Equations (4) and (5) | FIFO, CpR, RANDOM | ☑ | ☑ but less accurate Section 6.3, Section 6.4, Section 6.5 | 16% for M = 1 <3% for M ≥ 10 |
| Fagin [23] Equation (8) | LRU & Cache Fill Phases | 5.4% for M = 2 <1.3% for M ≥ 10 | |||
| Che et al. [24] Equation (7) | 8.5% for M = 1 <1% for M ≥ 10 | ||||
| Maximum Errors of Che’s and Fagin’s Approximation for Cache Sizes M ≤ 10 Worst Case Request Distributions Are of the Type (6) with p1= ∙∙∙ = pn = p/n | ||||||
|---|---|---|---|---|---|---|
| M | Max. Error |ΔhChe| | Worst Case (6) | || hChe | Max. Error |ΔhFagin| | Worst Case (6) | || hFagin |
| n || p/n | n || p/n | |||||
| 1 | 8.25% | 1 || 0.845 | 0.7055 || 0.6230 | Fagin’s approximation is exact for M = 1 | ||
| 2 | 4.48% | 2 || 0.455 | 0.7971 || 0.7523 | 5.20% | 1 || 0.675 | 0.6041 || 0.6561 |
| 3 | 2.97% | 3 || 0.310 | 0.8247 || 0.7950 | 3.53% | 1 || 0.540 | 0.4876 || 0.5229 |
| 4 | 2.18% | 4 || 0.235 | 0.8523 || 0.8305 | 2.82% | 2 || 0.360 | 0.6655 || 0.6937 |
| 5 | 1.71% | 5 || 0.192 | 0.8818 || 0.8647 | 2.31% | 2 || 0.315 | 0.5867 || 0.6098 |
| 6 | 1.39% | 6 || 0.160 | 0.8922 || 0.8783 | 1.99% | 3 || 0.247 | 0.6894 || 0.7093 |
| 7 | 1.17% | 7 || 0.139 | 0.9046 || 0.8929 | 1.72% | 3 || 0.227 | 0.6342 || 0.6514 |
| 8 | 1.03% | 6 || 0.155 | 0.9055 || 0.9158 | 1.54% | 4 || 0.187 | 0.7033 || 0.7187 |
| 9 | 0.97% | 7 || 0.134 | 0.9188 || 0.9285 | 1.39% | 5 || 0.158 | 0.7500 || 0.7639 |
| 10 | 0.91% | 8 || 0.119 | 0.9314 || 0.9405 | 1.26% | 5 || 0.150 | 0.7043 || 0.7169 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasslinger, G.; Ntougias, K.; Hasslinger, F.; Hohlfeld, O. Scope and Accuracy of Analytic and Approximate Results for FIFO, Clock-Based and LRU Caching Performance. Future Internet 2023, 15, 91. https://doi.org/10.3390/fi15030091
Hasslinger G, Ntougias K, Hasslinger F, Hohlfeld O. Scope and Accuracy of Analytic and Approximate Results for FIFO, Clock-Based and LRU Caching Performance. Future Internet. 2023; 15(3):91. https://doi.org/10.3390/fi15030091
Chicago/Turabian StyleHasslinger, Gerhard, Konstantinos Ntougias, Frank Hasslinger, and Oliver Hohlfeld. 2023. "Scope and Accuracy of Analytic and Approximate Results for FIFO, Clock-Based and LRU Caching Performance" Future Internet 15, no. 3: 91. https://doi.org/10.3390/fi15030091