
High-Performance Computing and ABMS for High-Resolution COVID-19 Spreading Simulation


Abstract
:1. Introduction
2. Agent Based Modelling and Simulation
3. Agent Based Modeling and Simulation for Epidemic Scenarios
4. Actor Based Modeling and Simulation
4.1. Using Actors for Large Scale ABMS Applications
4.2. ActoDeS
4.3. Using ActoDeS for ABMS Large Scale Applications
5. The Simulator
- Unique identifier
- Province or municipality of residence
- Age
- Number of daily contacts
- Current infection state
- If the individual is an essential worker
- If the individual wears a protective mask during the simulation period.
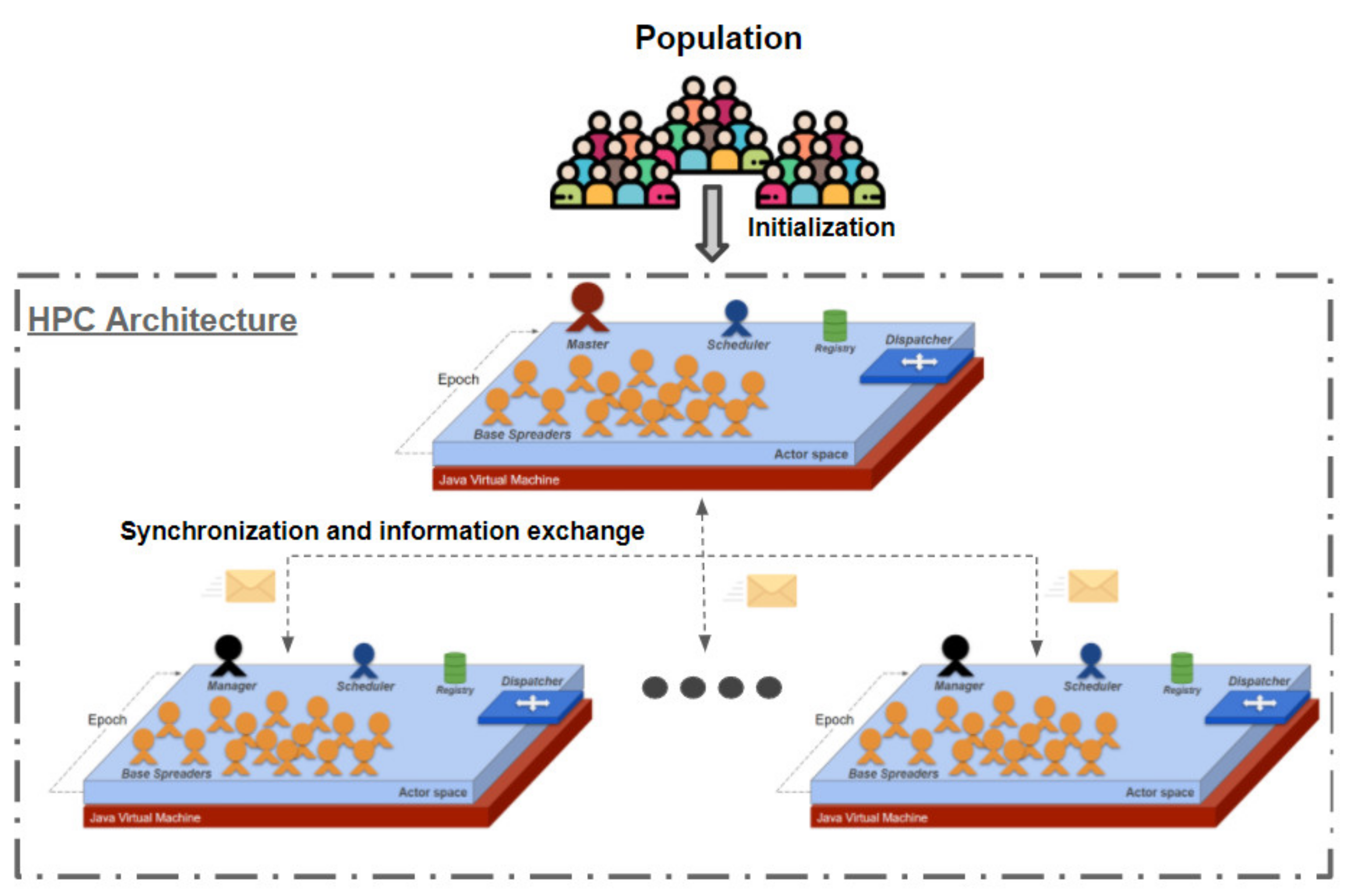
5.1. Software Architecture with HPC
5.2. Commuting Model
- ▪
- The grain: the finer the grain of the model, the more accurate the commuting model is.
- ▪
- The economic quotient: the most effective models take into account the economic quotient of every zone. Moreover, a municipality with a high number of businesses attracts more workers than another with few job opportunities.
- is the probability that an individual living in i works or studies in municipality j
- number of individuals living in municipality i (or j)
- proportional constant equal to 0.0005
- inhabitants damping constant of i equal to 0.28
- inhabitants damping constant of j which changes according to the number of people living in j:
- 0.65 if the number of inhabitants is greater than 150,000
- 0.66 if the number of inhabitants is between 5000 and 150,000
- 0.78 if the number of inhabitants is less than 5000
- distance between the municipalities i and j
- constant amplifying the dependence from distance which changes according to the number of people living in j:
- 3.05 if the number of inhabitants is greater than 150,000
- 2.95 if the number of inhabitants is between 5000 and 150,000
- 2.5 0.78 if the number of inhabitants is less than 5000
- is the probability that an individual living in i works or studies in municipality j
- initial commuting probability of municipality i. This parameter can assume three different values according to the number of people who live in i:
- if the number of inhabitants is greater than 150,000
- 0.3 if the number of inhabitants is between 5000 and 150,000
- 0.4 if the number of inhabitants is less than 5000
- number of individuals living in municipality i (or j)
- population that lives within the circle with radius equal to the distance between i and j minus the population living in i and j
6. Use-Cases: Modeling the Emilia-Romagna and Lombardy Regions
6.1. Social-Demographic Model
- Single with children
- Single without children
- Single with children plus another adult
- Couple without children
- Couple without children plus another adult
- Couple with children
- Couple with children plus another adult
- Adults that live together
- Family groups (with at least one child)
- Any family group must contain at least one adult
- The age of each child must be between 18 and 43 years less than the younger parent
- The age difference of a couple is less than or equal to 15 years and they must be adult
- Kindergarten, attendance rate: 90%
- Preschool, attendance rate: 90%
- Elementary school, attendance rate: 100%
- Middle school, attendance rate: 100%
- High school, attendance rate: 92%
- University, attendance rate: 31%
- Kindergarten: 40 children
- Preschool: 20 children
- Elementary school: 19 children
- Middle school: 21 lads
- High school: 21 lads
- University: 34 lads
- 15–19 years: 8%
- 20–26 years: 30%
- 27–34 years: 62.5%
- 35–54 years: 73.5%
- 55–70 years: 54.3%
- Very small company: up to 5 employees
- Small company: up to 9 employees
- Small-medium company: up to 19 employees
- Medium company: up to 49 employees
- Medium-large company: up to 99 employees
- Large company: up to 249 employees
- Very large company: over 250 employees
6.2. Restrictions
- White: no restrictions
- White from 10/18 to 10/24: represents the restrictions introduced on 18 October 2020: no limitations regarding work, but high schools and universities at 50% in attendance. The number of daily interactions is reduced by 40% to shape the closure of businesses such as bars after 9 pm and restaurants after midnight.
- White from 10/25 to 11/05: represents the latest restrictions introduced before the zoning: no limitations regarding work, but schools and universities still at 50% in attendance. Closing of activities such as gyms, theaters and cinemas, closing restaurants after 6 pm, also the recommendation not to move. The number of social interactions is reduced by 50% compared to the initial value.
- Yellow: high schools and universities closed (100% distance learning). Curfew from 22.00. Closure to the public of exhibitions, museums and other places of culture such as archives and libraries. To model these additional restrictions, the number of social interactions is reduced by 60%.
- Orange: in addition to the limitations of the yellow area, the prohibitions on moving between municipalities except for proven work needs and the closure of catering activities (excluding take-away) are added. The use of smart working is encouraged and recommended even for workers, excluding essentials. In the model, social interactions are reduced by 70% compared to the initial values and cannot take place outside the municipalities (except those related to work activities).
- Red: in addition to the limitations of the orange zone, the prohibition of movement within the municipality. For this, the daily interactions are reduced by 80% and reduced to zero those regarded as usual ones.
6.3. Spreading Parameters’ Selection
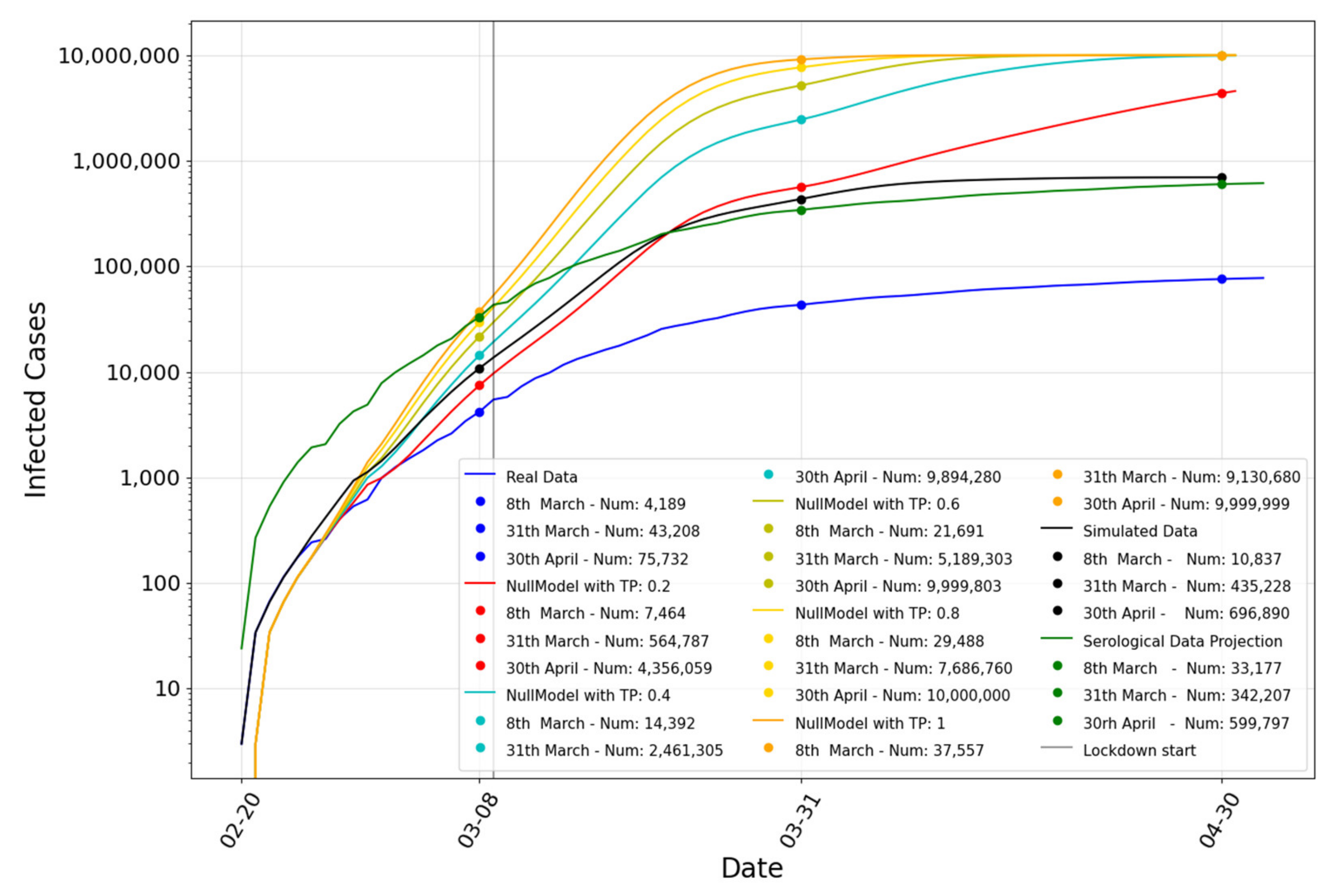
6.4. Results for Emilia-Romagna
6.5. Results for the Lombardy Region
7. Discussion
- The contagion susceptibility by age
- The protection achieved thanks to wearable protective devices
- The quarantine mechanism
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, M.Y.; Muldowney, J.S. Global stability for the SEIR model in epidemiology. Math. Biosci. 1995, 125, 155–164. [Google Scholar] [CrossRef]
- He, S.; Peng, Y.; Sun, K. SEIR modeling of the COVID-19 and its dynamics. Nonlinear Dyn. 2020, 101, 1667–1680. [Google Scholar] [CrossRef] [PubMed]
- Macal, C.M.; North, M.J. Tutorial on agent-based modeling and simulation. In Proceedings of the Winter Simulation Conference, Orlando, FL, USA, 4 December 2005. [Google Scholar]
- Simini, F.; González, M.C.; Maritan, A.; Barabási, A.L. A universal model for mobility and migration patterns. Nature 2012, 484, 96–100. [Google Scholar] [CrossRef] [PubMed]
- Xia, Y.; Bjørnstad, O.N.; Grenfell, B.T. Measles metapopulation dynamics: A gravity model for epidemiological coupling and dynamics. Am. Nat. 2004, 164, 267–281. [Google Scholar] [CrossRef]
- Pellegrino, M.; Lombardo, G.; Mordonini, M.; Tomaiuolo, M.; Cagnoni, S.; Poggi, A. ActoDemic: A Distributed Framework for Fine-Grained Spreading Modeling and Simulation in Large Scale Scenarios. In Proceedings of the 22nd Workshop “From Objects to Agents” (WOA, 2021), Bologna, Italy, 1–3 September 2021. [Google Scholar]
- Niazi, M.; Hussain, A. Agent-based computing from multi-agent systems to agent-based models: A visual survey. Scientometrics 2011, 89, 479–499. [Google Scholar] [CrossRef] [Green Version]
- Bandini, S.; Manzoni, S.; Vizzari, G. Agent based modeling and simulation: An informatics perspective. J. Artif. Soc. Soc. Simul. 2009, 12, 4. [Google Scholar]
- Bandini, S.; Manzoni, S.; Vizzari, G. Agent-based modeling and simulation. In Complex Social and Behavioral Systems: Game Theory and Agent-Based Models; Sotomayor, M., Pérez-Castrillo, D., Castiglione, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 667–682. [Google Scholar]
- Epstein, J.M. Generative Social Science: Studies in Agent-Based Computational Modeling. In Princeton Studies in Complexity; Princeton University Press: Princeton, NJ, USA, 2007. [Google Scholar]
- Klügl, F.; Bazzan, A.L. Agent-based modeling and simulation. AI Mag. 2012, 33, 29. [Google Scholar] [CrossRef]
- Grimm, V.; Railsback, S.F. Individual-based modeling and ecology. In Princeton Series in Theoretical and Computational Biology; Princeton University Press: Princeton, NJ, USA, 2013. [Google Scholar]
- Wolfram, S. Cellular automata as models of complexity. Nature 1984, 311, 419–424. [Google Scholar] [CrossRef]
- Reynolds, C.W. Flocks, Herds and Schools: A Distributed Behavioral Model. Available online: https://dl.acm.org/doi/pdf/10.1145/37401.37406?casa_token=xKKdS6A0HnkAAAAA:Y_z7E8qgBvJFzBVuAJMKujqyHiAfjAj9lQdlIPYYMUaZOhsV_6dmTtx8lV9TU8Uq718OjAp1Wvgslg (accessed on 18 February 2022).
- Gimblett, H.R. Integrating Geographic Information Systems and Agent-Based Modeling Techniques for Simulating Social and Ecological Processes; Oxford University Press: Oxford, UK, 2002. [Google Scholar]
- Allan, R.J. Survey of Agent Based Modelling and Simulation Tools; Science & Technology Facilities Council: New York, NY, USA, 2010; ISSN 1362-0207. [Google Scholar]
- Tobias, R.; Hofmann, C. Evaluation of free Java-libraries for social-scientific agent based simulation. J. Artif. Soc. Soc. Simul. 2004, 7. Available online: https://www.zora.uzh.ch/id/eprint/115438/1/Robert%20Tobias%20and%20Carole%20Hofmann-%20Evaluation%20of%20free%20Java-libraries%20for%20social-scientific%20agent%20based%20simulation.pdf (accessed on 18 February 2022).
- Nikolai, C.; Madey, G. Tools of the trade: A survey of various agent based modeling platforms. J. Artif. Soc. Soc. Simul. 2009, 12, 2. [Google Scholar]
- Abar, S.; Theodoropoulos, G.K.; Lemarinier, P.; O’Hare, G.M. Agent Based Modelling and Simulation tools: A review of the state-of-art software. Comput. Sci. Rev. 2017, 24, 13–33. [Google Scholar] [CrossRef]
- Parker, M. Ascape: An Agent-Based Modeling Framework in Java. Available online: https://www.osti.gov/servlets/purl/795682-rnZK04/native/#page=158 (accessed on 18 February 2022).
- Luke, S.; Cioffi-Revilla, C.; Panait, L.; Sullivan, K.; Balan, G. Mason: A multiagent simulation environment. Simulation 2005, 81, 517–527. [Google Scholar] [CrossRef] [Green Version]
- North, M.J.; Collier, N.T.; Vos, J.R. Experiences creating three implementations of the repast agent modeling toolkit. ACM Trans. Model. Comput. Simul. 2006, 16, 1–25. [Google Scholar] [CrossRef]
- Borshchev, A.; Brailsford, S.; Churilov, L.; Dangerfield, B. Multi-method modelling: AnyLogic. In Discrete-Event Simulation and System Dynamics for Management Decision Making; Wiley: Hoboken, NJ, USA, 2014. [Google Scholar]
- Wilensky, U.; Rand, W. An Introduction to Agent-Based Modeling: Modeling Natural, Social, and Engineered Complex Systems with NetLogo; MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Chumachenko, D.; Meniailov, I.; Bazilevych, K.; Chumachenko, T. On intelligent decision making in multiagent systems in conditions of uncertainty. In Proceedings of the 2019 XI International Scientific and Practical Conference on Electronics and Information Technologies (ELIT), Lviv, Ukraine, 16–18 September 2019. [Google Scholar]
- Lees, M.; Logan, B.; Oguara, T.; Theodoropoulos, G. Simulating Agent-Based Systems with HLA: The Case of SIM_AGENT-Part II (03E-SIW-076). In Proceedings of the 2003 European Simulation Interoperability Workshop, Stockholm, Sweden, 14–19 September 2003. [Google Scholar]
- Massaioli, F.; Castiglione, F.; Bernaschi, M. OpenMP parallelization of agent-based models. Parallel Comput. 2005, 31, 1066–1081. [Google Scholar] [CrossRef]
- Erra, U.; Frola, B.; Scarano, V.; Couzin, I. An efficient GPU implementation for large scale individual-based simulation of collective behavior. In Proceedings of the 2009 International Workshop on High Performance Computational Systems Biology, Trento, Italy, 14–16 October 2009. [Google Scholar]
- Cicirelli, F.; Furfaro, A.; Giordano, A.; Nigro, L. HLA_ACTOR_REPAST: An approach to distributing RePast models for high-performance simulations. Simul. Model. Pract. Theory 2011, 19, 283–300. [Google Scholar] [CrossRef]
- Cordasco, G.; De Chiara, R.; Mancuso, A.; Mazzeo, D.; Scarano, V.; Spagnuolo, C. Bringing together efficiency and effectiveness in distributed simulations: The experience with D-MASON. Simulation 2013, 89, 1236–1253. [Google Scholar] [CrossRef]
- Lysenko, M.; D’Souza, R.M. A framework for megascale agent based model simulations on graphics processing units. J. Artif. Soc. Soc. Simul. 2008, 11, 10. [Google Scholar]
- Scheutz, M.; Schermerhorn, P. Adaptive algorithms for the dynamic distribution and parallel execution of agent-based models. J. Parallel Distrib. Comput. 2006, 66, 1037–1051. [Google Scholar] [CrossRef]
- Som, T.K.; Sargent, R.G. Model structure and load balancing in optimistic parallel discrete event simulation. In Proceedings of the Fourteenth Workshop on Parallel and Distributed Simulation, Bologna, Italy, 28–31 May 2000. [Google Scholar]
- Lorig, F.; Johansson, E.; Davidsson, P. Agent-based social simulation of the COVID-19 pandemic: A systematic review. JASSS J. Artif. Soc. Soc. Simul. 2021, 24, 5. [Google Scholar] [CrossRef]
- Dyke Parunak, H.V.; Savit, R.; Riolo, R.L. Agent-based modeling vs. equation-based modeling: A case study and users’ guide. In International Workshop on Multi-Agent Systems and Agent-Based Simulation; Springer: Berlin/Heidelberg, Germany, 1998; pp. 10–25. [Google Scholar]
- Rahmandad, H.; Sterman, J. Heterogeneity and network structure in the dynamics of diffusion: Comparing agent-based and differential equation models. Manag. Sci. 2008, 54, 998–1014. [Google Scholar] [CrossRef] [Green Version]
- Ajelli, M.; Gonçalves, B.; Balcan, D.; Colizza, V.; Hu, H.; Ramasco, J. Comparing large-scale computational approaches to epidemic modeling: Agent-based versus structured metapopulation models. BMC Infect. Dis. 2010, 10, 190. [Google Scholar] [CrossRef] [Green Version]
- Silva, P.C.; Batista, P.V.; Lima, H.S.; Alves, M.A.; Guimarães, F.G.; Silva, R.C. COVID-ABS: An agent-based model of COVID-19 epidemic to simulate health and economic effects of social distancing interventions. Chaos Solitons Fractals 2020, 139, 110088. [Google Scholar] [CrossRef] [PubMed]
- Hinch, R.; Probert, W.J.; Nurtay, A.; Kendall, M.; Wymant, C.; Hall, M. OpenABM-COVID19—An agent-based model for non-pharmaceutical interventions against COVID-19 including contact tracing. PLoS Comput. Biol. 2021, 17, e1009146. [Google Scholar] [CrossRef] [PubMed]
- Gabler, J.; Raabe, T.; Röhrl, K. People Meet People: A Microlevel Approach to Predicting the Effect of Policies on the Spread of COVID-19. Available online: https://www.econstor.eu/bitstream/10419/232651/1/dp13899.pdf (accessed on 18 February 2022).
- Wolfram, C. An agent-based model of COVID-19. Complex Syst. 2020, 29, 87–105. [Google Scholar] [CrossRef]
- Shamil, M.; Farheen, F.; Ibtehaz, N.; Khan, I.M.; Rahman, M.S. An agent-based modeling of COVID-19: Validation, analysis, and recommendations. Cogn. Comput. 2021, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Truszkowska, A.; Behring, B.; Hasanyan, J.; Zino, L.; Butail, S.; Caroppo, E.; Jiang, Z.-P.; Rizzo, A.; Porfiri, M. High-Resolution Agent-Based Modeling of COVID-19 Spreading in a Small Town. Adv. Theory Simul. 2021, 4, 2000277. [Google Scholar] [CrossRef]
- Chumachenko, D.; Meniailov, I.; Bazilevych, K.; Chumachenko, T.; Yakovlev, S. On intelligent agent-based simulation of COVID-19 epidemic process in Ukraine. Procedia Comput. Sci. 2022, 198, 706–711. [Google Scholar] [CrossRef]
- Agha, G.A. Actors: A Model of Concurrent Computation in Distributed Systems; MIT, Cambridge Artificial Intelligence Lab: Cambridge, MA, USA, 1985. [Google Scholar]
- Kafura, D.; Briot, J.P. Actors and agents. IEEE Concurr. 1998, 6, 24–28. [Google Scholar] [CrossRef]
- Wooldridge, M. An Introduction to Multiagent Systems; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Jang, M.W.; Agha, G. Agent framework services to reduce agent communication overhead in large-scale agent-based simulations. Simul. Model. Pract. Theory 2006, 14, 679–694. [Google Scholar] [CrossRef]
- Scheutz, M.; Schermerhorn, P.; Connaughton, R.; Dingler, A. Swages—An Extendable Distributed Experimentation System for Large-Scale Agent-Based Alife Simulations. Available online: citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.86.4219&rep=rep1&type=pdf (accessed on 18 February 2022).
- Wittek, P.; Rubio-Campillo, X. Scalable agent-based modelling with cloud hpc resources for social simulations. In Proceedings of the 4th IEEE International Conference on Cloud Computing Technology and Science, Taipei, Taiwan, 3–6 December 2012. [Google Scholar]
- Collier, N.; North, M. Parallel agent-based simulation with repast for high performance computing. Simulation 2013, 89, 1215–1235. [Google Scholar] [CrossRef]
- Clarke, L.; Glendinning, I.; Hempel, R. The MPI message passing interface standard. In Programming Environments for Massively Parallel Distributed Systems; Birkhäuser: Basel, Switzerland, 1994. [Google Scholar]
- Fan, Y.; Lan, Z.; Childers, T.; Rich, P.; Allcock, W.; Papka, M.E. Deep reinforcement agent for scheduling in HPC. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Portland, OR, USA, 17–21 May 2021. [Google Scholar]
- Santana, E.F.Z.; Lago, N.; Kon, F.; Milojicic, D.S. Interscsimulator: Large-scale traffic simulation in smart cities using erlang. In Proceedings of the International Workshop on Multi-Agent Systems and Agent-Based Simulation, São Paulo, Brazil, 8–12 May 2017. [Google Scholar]
- Bergenti, F.; Poggi, A.; Tomaiuolo, M. An actor based software framework for scalable applications. In Proceedings of the International Conference on Internet and Distributed Computing Systems, Calabria, Italy, 22–24 September 2014. [Google Scholar]
- Mathieu, P.; Secq, Y. Environment Updating and Agent Scheduling Policies in Agent-based Simulators. In Proceedings of the 4th International Conference on Agents and Artificial Intelligence (ICAART), Algarve, Portugal, 6–8 February 2012. [Google Scholar]
- Brisolara, L.; Han, S.I.; Guerin, X.; Carro, L.; Reis, R.; Chae, S.I.; Jerraya, A. Reducing fine-grain communication overhead in multithread code generation for heterogeneous MPSoC. In Proceedings of the 10th International Workshop on Software & Compilers for Embedded Systems Nice France, New York, NY, USA, 20 April 2007. [Google Scholar]
- Wesolowski, L.; Venkataraman, R.; Gupta, A.; Yeom, J.S.; Bisset, K.; Sun, Y.; Kale, L.V. Tram: Optimizing fine-grained communication with topological routing and aggregation of messages. In Proceedings of the 43rd International Conference on Parallel Processing, Minneapolis, MN, USA, 9–12 September 2014. [Google Scholar]
- Poggi, A. Agent Based Modeling and Simulation with ActoMoS. In Proceedings of the 16th Workshop “From Objects to Agents” (WOA, 2015), Napoli, Italy, 17–19 June 2015. [Google Scholar]
- Lombardo, G.; Fornacciari, P.; Mordonini, M.; Tomaiuolo, M.; Poggi, A. A multi-agent architecture for data analysis. Future Internet 2019, 11, 49. [Google Scholar] [CrossRef] [Green Version]
- Riccio, A. Analysis of the SARS-CoV-2 epidemic in Lombardy (Italy) inits early phase. Are we going in the right direction? medRxiv 2020. [Google Scholar]
- Godio, A.; Pace, F.; Vergnano, A. Seir modeling of the italian epidemic of SARS-CoV-2 using computational swarm intelligence. Int. J. Environ. Res. Public Health 2020, 17, 3535. [Google Scholar] [CrossRef] [PubMed]
- COVID-19 Aggiornamento Quotidiano dei Dati-Provincia Reggio Nell’Emilia. Available online: https://www.ausl.re.it/covid-19-aggiornamento-quotidiano-dei-dati (accessed on 17 February 2022).
- Archivio GitHub COVID-19 Dati Regioni. Available online: https://github.com/pcm-dpc/COVID-19/tree/master/dati-regioni (accessed on 17 February 2022).
- Coordinate Geografiche Comuni Italiani. Available online: https://www.dossier.net/utilities/coordinate-geografiche (accessed on 17 February 2022).
- Istat. Available online: https://www.istat.it (accessed on 17 February 2022).
- Analisi Pendolarismo Comune per Comune della Regione Emilia Romagna. Available online: https://statistica.regione.emilia-romagna.it/servizi-online/rappresentazioni-cartografiche/pendolarismo/analisi-comune (accessed on 17 February 2022).
- Adosoglou, G.; Lombardo, G.; Pardalos, P.M. Neural network embeddings on corporate annual filings for portfolio selection. Expert Syst. Appl. 2021, 164, 114053. [Google Scholar] [CrossRef]
- Lombardo, G.; Poggi, A.; Tomaiuolo, M. Continual representation learning for node classification in power-law graphs. Future Gener. Comput. Syst. 2022, 128, 420–428. [Google Scholar] [CrossRef]
- Lombardo, G.; Poggi, A. A Scalable and Distributed Actor-Based Version of the Node2Vec Algorithm. In Proceedings of the 20th Workshop “from Objects to Agents” (WOA, 2019), Parma, Italy, 26–28 June 2019. [Google Scholar]
- Fornacciari, P.; Mordonini, M.; Poggi, A.; Sani, L.; Tomaiuolo, M. A holistic system for troll detection on Twitter. Comput. Hum. Behav. 2018, 89, 258–268. [Google Scholar] [CrossRef]
- Tomaiuolo, M.; Lombardo, G.; Mordonini, M.; Cagnoni, S.; Poggi, A. A survey on troll detection. Future Internet 2020, 12, 31. [Google Scholar] [CrossRef] [Green Version]
- Angiani, G.; Fornacciari, P.; Lombardo, G.; Poggi, A.; Tomaiuolo, M. Actors based agent modelling and simulation. In International Conference on Practical Applications of Agents and Multi-Agent Systems; Springer: Cham, Switzerland, 2018; pp. 443–455. [Google Scholar]
- Bergenti, F.; Caire, G.; Monica, S.; Poggi, A. The first twenty years of agent-based software development with JADE. Auton. Agents Multi-Agent Syst. 2020, 34, 36. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RMSE | Pearson Correlation | |
|---|---|---|
| Simulated Data—Real Data | 398,042 | 0.9903 |
| RMSE | Pearson Correlation | |
|---|---|---|
| Simulated Data—Serological | 105,343 | 0.9903 |
| Null model with TP = 0.2–Serological | 1,301,649 | 0.8674 |
| Null model with TP = 0.4–Serological | 4,662,723 | 0.9456 |
| Null model with TP = 0.6–Serological | 5,840,197 | 0.9805 |
| Null model with TP = 0.8–Serological | 6,422,819 | 0.9763 |
| Null model with TP = 1–Serological | 6,759,554 | 0.9616 |
| RMSE | Pearson Correlation | |
|---|---|---|
| Simulated Data—Serological | 105,343 | 0.990 |
| SEIR 1—Serological | 269,197 | 0.769 |
| SEIR 2—Serological | 270,060 | 0.859 |
| SEIR 3—Serological | 318,034 | 0.713 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pellegrino, M.; Lombardo, G.; Cagnoni, S.; Poggi, A. High-Performance Computing and ABMS for High-Resolution COVID-19 Spreading Simulation. Future Internet 2022, 14, 83. https://doi.org/10.3390/fi14030083
Pellegrino M, Lombardo G, Cagnoni S, Poggi A. High-Performance Computing and ABMS for High-Resolution COVID-19 Spreading Simulation. Future Internet. 2022; 14(3):83. https://doi.org/10.3390/fi14030083
Chicago/Turabian StylePellegrino, Mattia, Gianfranco Lombardo, Stefano Cagnoni, and Agostino Poggi. 2022. "High-Performance Computing and ABMS for High-Resolution COVID-19 Spreading Simulation" Future Internet 14, no. 3: 83. https://doi.org/10.3390/fi14030083