In this section, the proposed booking algorithm is able to control social gatherings. The indoor positioning technology is crucial for providing navigation services with congestion control strategies, and the risk assessment model also requires people’s locations.
3.1. Booking Algorithm
Subareas exist in an enclosed space, e.g., different shops and dining rooms are in a shopping mall. Physically, each subarea is able to contain plenty of people; nevertheless, gathering crowds lead to higher infection risks. Hence, an optimized booking algorithm is introduced.
Here, an example to explain how to calculate
,
, and
is shown in
Table 1. There are 4 people (A, B, C, and D) applying to enter an area which can only contain 1 person.
Related details are shown below (
Table 2). At 12:00, A applies to enter the area, and he plans to stay there for about 1 minute (service time). At 12:01, B attempts to enter the area and the request is then immediately satisfied. At 12:02, C should wait for B until 12:05, and so should D. At 12:05, the waiting time for C and D is 3 minutes and 1 minute, respectively.
The booking algorithm is a variant of the original HRRN algorithm. In the original HRRN algorithm,
is defined as below (Equation (1)).
The main idea of the HRRN algorithm is to allocate the CPU resource to the job or process waiting longer (greater ) and requiring less service time (less ), i.e., the job or process with greater has higher priority to get the CPU resource. In the booking algorithm, an area is seen as a CPU, and people are seen as processes. If the space can contain the amount of people who are requesting to enter, their requests will be satisfied immediately (e.g., 3 people concurrently apply to enter an area with 5 free vacancies).
Nonetheless, pandemic guidelines do not encourage a person to spend too much time waiting. Additionally, for fairness, individuals requiring too little service time are also not encouraged. Therefore, the original definitions of waiting time and service time are modified. In Equations (2)–(4),
and are constant values preliminarily set by the manager of an area.
Other related scheduling algorithms such as FCFS, SJF, and HPF are unsuited for COVID-19 prevention and control. FCFS ensures that a person who comes earlier can also get an earlier permit. However, people who only need to stay in an area for a short time may wait for a long time. The sum of waiting time of all people will not be the minimum. Though SJF is conducive to getting a minimum total waiting time, it is unfair for people needing to stay in an area for a longer time, leading to bad user experience. As for HPF, we cannot confirm the priority values for individuals easily in advance. Therefore, the HRRN is a compromise which considers both COVID-19 prevention and control and user experience.
Let
,
. Hence, Equations (5) and (6) are presented.
In Equations (7) and (8), the response ratio
r always increases with
w (
), and
, viz., 1 minute is the threshold value for the encouraged waiting time.
Excessive waiting does not contribute much to the increase in priority. Because , similarly, 1 minute is the threshold value for the encouraged service time. All these strategies should be told to users first in a user-friendly way, and then they can make their own choices. To get a higher priority (higher ) to enter an area, people ought to consciously follow pandemic prevention and control policies.
The result of applying Equations (5) and (6) to the example in
Table 2 is shown in
Table 3. The status “In” indicates that a person is in the area with permission. Statuses “Left” and “Not Arrived” mean that a person is not in the area. When the region is full, a new user wanting to enter must wait. At 12:05, C and D compete for the vacancy and D is satisfied because of their higher
(
).
The algorithm does not ensure the first person will get the first permit, which sometimes makes people unhappy. The manager of the area may take some measures for compensation, e.g., in a shopping mall, it is acceptable to give e-coupons.
Reservation and booking approaches are widely adopted nowadays, especially in the pandemic period, e.g., a scenic spot may sell fewer tickets and ask tourists to queue up to enter the scenic spot in batches. When using the algorithm, a manager of a region should help people to understand and follow the pandemic prevention and control guidelines. Sometimes, urgent entry requests (jumping the queue) should be also processed in time.
3.2. Indoor Positioning
In an enclosed place, the relationship between a location and corresponding RSSI vector is built by selecting reference points and collecting RSSI values from iBeacon nodes at each reference point.
denotes a series of RSSI values;
represents the RSSI value from node
. At each point, a receiver (usually a mobile phone) gets RSSI values steadily in a period from iBeacon nodes. The vector
is a vector of RSSI values from an iBeacon node via repeated measurements. The simplest way is to average the values in the vector
(in Equation (9)).
Nevertheless, this simple method is unable to adapt to the real situation, especially when the indoor environment is complex and volatile. Kalman filtering (KF), a linear, minimum variance estimation method, is required to be used; the KF algorithm consists of a gain calculation loop (filter gain, estimation error, and prediction error) and a filter calculation loop (state prediction and state estimation) [
53,
54]. The covariance of the observation noise
is calculated by averaging the variance of the RSSI at each reference point. The system process noise is
, and the state transition is
(the RSSI value is expected to be stable). The observation is
. The first estimated error covariance of the point is shown in Equation (10).
is the first sample RSSI of reference point l. is the expected RSSI value of the corresponding point. N is the number of elements of the vector .
The prediction error covariance of the
-th sample RSSI is shown in Equation (11).
The filter gain of the
-th sample RSSI is denoted by
(Equation (12)).
The estimated error covariance of the
-th sample RSSI is confirmed by Equation (13) (
is the unit vector).
The predicted value of the
-th RSSI is calculated via Equation (14).
In order to gain the predicted value of the
-th sample of RSSI, we put the filter gain into the filter calculation (Equation (15)).
Through the KF algorithm, the error of RSSI measurement can be reduced so that we can gain more accurate RSSI values. For the fingerprinting database, a more reliable offline fingerprinting database is established.
Figure 2 shows the process of building a fingerprint database (offline stage) and real-time positioning (online stage).
The distance between a received RSSI vector and fingerprint vector
needs to be calculated. The corresponding location for
is
. Firstly, we calculate the first
largest distances and record the corresponding
, then we generate an ascending distance vector
. The method of calculation is shown below Equations (16)–(18).
The implementation of an indoor positioning system requires some experiments. An ideal place for testing the feasibility of the algorithm is a typical enclosed space. Firstly, we select points, and at each point we carry out positioning many times. Then, the positioning errors at each point are averaged and recorded. Among all of the different values of , the value which can make the positioning results stable and accurate is acceptable. Though a larger may make the result more accurate, we should consider the computation pressure of server computers. In this process, is determined.
After that, we select a fixed point to carry out continuous positioning to observe the distribution of positioning results. This can verify the static stability and reliability of positioning. However, individuals are always moving in an enclosed space; thus, it is needed to move and form a trajectory, and then compare the real trajectory to the predicted trajectory. This experiment demonstrates dynamic stability and reliability. The indoor positioning system should be reliable whether people are moving or not.
3.3. Path-Planning Algorithm with Congestion Control
The main function of the path-planning algorithm is to guide users to destinations as soon as possible, which reduces the infection risk. For a COVID-19-positive individual, fewer contaminants will be unconsciously emitted; and for a healthy person, the exposure time to contaminants will be reduced.
The path-finding algorithm is introduced to solve the Single-Source Shortest Path problem with efficiency. The Dijkstra algorithm is a ubiquitous and typical solution to find the shortest path between two given vertices. In the statement of Dijkstra,
is a set saving all nodes in the graph, and
is initialized to store nodes whose shortest paths from the start vertex are found. Every time, we select a node
with the shortest distance from start vertex
in
(difference set between
set and
set). After that, the vertex
can be considered as the intermediary point, and then the shortest distance between the start vertex
and any vertex
that can be reached from
is optimized [
55]. The pseudo code of the sequential Dijkstra algorithm is presented in Algorithm 1.
| Algorithm 1: Sequential Dijkstra Algorithm |
| Input: vertex s, graph G |
| Output: None |
However, for a public area in which many people stay, a single-thread Dijkstra algorithm implementation is of low efficiency for handling a great many simultaneous requests. An increase in the use of the General-Purpose Graphics Processing Unit (GPGPU) offers massive-scale parallel computing capabilities. The GPGPU is based on a single-instruction, multiple-thread (SIMT) execution model, i.e., each thread executes the same code. CUDA (Compute Unified Device Architecture) is a parallel computing framework enabling programmers to develop GPU-accelerated applications on major architectures including x86, Arm and POWER. It dispatches GPU parallelism for general-purpose computing and retains performance. It is developed based on industry-standard C++. CUDA consists of a small set of extensions to enable heterogeneous programming [
56].
| Algorithm 2: Parallel Dijkstra Algorithm |
| Input: |
| vertex s, graph G |
Output: Nonegenerate subgroups; while (there are vertices not in collected){ for (vertices in the subgroup but outside collected){ select the locally closest vertex; } find the globally closest vertex; }
|
In the sequential algorithm, the outer loop must be executed in order. Subgroups for every
vertices are partitioned.
is the number of computation units, which is set by programmers according to the need, and
is the number of vertices. Each core finds its closest vertex to the source vertex, selects the globally closest one, and broadcasts the result to all cores. In Algorithm 2, at each loop, the value for
cores is updated separately, and the gross execution time is
[
57,
58].
After surveying and mapping, the original graph of an enclosed space is generated, and then it is converted to an adjacency table or adjacency matrix. The graph is sometimes a multi-graph (e.g.,
Figure 3). The edges represent roads, and the numbers indicate the distance between two vertices. The vertices are marked by the manager of the enclosed space as needed.
An appropriate path is generated very soon after a user selects a destination. The maximum number of people that each road can accommodate should be set in advance, and “congestion” means that the number of people on a road exceeds a predetermined limit. In
Figure 4, the limitation information for
Figure 3 is presented (the numbers refer to a number limit).
It is required to make statistics and record the roads (edges in the multi-graph) most prone to congestion (or manually analyze which roads have higher probabilities for congestion), and these roads are stored in a set . Every time a user sends a request for navigation, the multi-graph needs to be converted to a simple graph.
Edges between two vertices (e.g., three edges between A and C with weight 5, 6, and 7, respectively) are divided into two categories: “congestion edges” and “ordinary edges”. Congestion edges with probability of
and ordinary edges with probability of
are selected. If the congestion edges are selected, they are stored in
. Then, let
, and
denotes the distance of the
-st edge in
. Let
, and
represents the number limit of the
-st edge. The probability of selecting
follows Equations (19) and (20).
The probability of finally selecting
follows Equation (21).
Indicator is the “capacity density”. An edge with greater capacity and shorter distance has a larger capacity density. Edges with a higher capacity density are more likely to be selected. The strategy for selecting ordinary edges is similar.
After this process, a simple graph is generated. The navigation for a user is based on . Each person’s real-time location is marked on a multi-graph , and the number of people on each edge is monitored in real time. If a user is moving and the server finds that the number of people on the next planned edge has reached the limit, it will open any adjacent edge near . The next vertex is selected as the start vertex to find the shortest path to the destination. If all edges have reached the number limit, the booking algorithm in this paper is applied to wait for an edge.
As shown in
Figure 5, a person plans to go to A from D, and the path is D ≥ C ≥ A (
is selected among
,
, and
). The number inside parentheses indicates the current number of people on this edge. When the person is on the edge between C and D and about to reach C, the number of people on
and
exceeds the limit, and C is chosen as the start vertex to find the shortest path from C to A. Rollback is not allowed, and the person will go through
. In the case where the number of people on
,
, and
has all reached the limit, the booking algorithm will work.
Though the parallel algorithm is fast, we introduce a cache strategy which can greatly reduce the computation pressure on the server. An unordered map is a hash-based data structure which stores key-value pairs. On the premise of a proper hash algorithm implementation, the value can be accessed in constant time complexity via the key. The key of the unordered map is a combination of information (the differences between the original multi-graph and simple graph, and the start vertex with the destination vertex). For example, a key-value pair is (Key: (Delete , , and edges between A and B, Move from D to A), Value: (A path)). Every time the parallel algorithm finds the shortest path, the path is stored in the unordered map if it is never added to the cache. Additionally, we can even adopt a more aggressive cache strategy: it is feasible to generate and store most of the possible paths as early as possible.
In this paper, our purpose is not to build a high-performance computing center, and the hardware budget is also limited. Because of the cache strategy, the computing pressure on the server is reduced. When the cache has not been established or there are many changes to the multi-graph, the real-time path-planning algorithm will work, which often takes much more time than loading a path from the cache. In general, there is no need to invoke the parallel algorithm. The test of cache is relatively simple. The time consumption of loading a path from the cache should be within a reasonable time. To examine the performance of the path-finding algorithm, we generate different scales of graphs, and use the parallel algorithm to find out all of the shortest paths (the shortest path for any two vertices is generated). The sequential algorithm is applied for comparison. Ideally, when the scale of a graph is large, the parallel algorithm will be faster than the sequential algorithm.
3.4. Risk Assessment Model
Potential COVID-19-positive individuals may enter an enclosed place, putting others at risk. As a whole, the closer an uninfected person is to an infected person, the greater the risk of infection. Moreover, due to the pollutants produced by infected individuals, the space is still at risk of infecting people after infected individuals leave, and the infectivity of pollutants left in the site will gradually decrease with the passage of time. The risk assessment model will assess the infection risk of all relevant people during the period from the time the infected individual enters the enclosed space to the time when he is diagnosed with COVID-19. Ideally, all relevant people should be isolated and nucleic acid tested, and even the whole city should be shut down. However, this is an impossible measure in many countries, so a relatively accurate risk assessment model is necessary. The model divides people into different risk levels and provides information for them and managers. It is up to the authorities and regulations to decide what measures to take.
Nowadays, many countries that have adopted strict measures are also gradually improving the efficiency of pandemic prevention and control. Recently, the concept of “possible contacts in time and space” has been put forward by the health departments in China, and people who appear in the same area as infected individuals for a certain period of time are likely to meet this definition. At present, this is mainly realized by base station positioning technology, which requires the cooperation of base stations and mobile phones. This model based on the indoor positioning technology provide accurate assessment services.
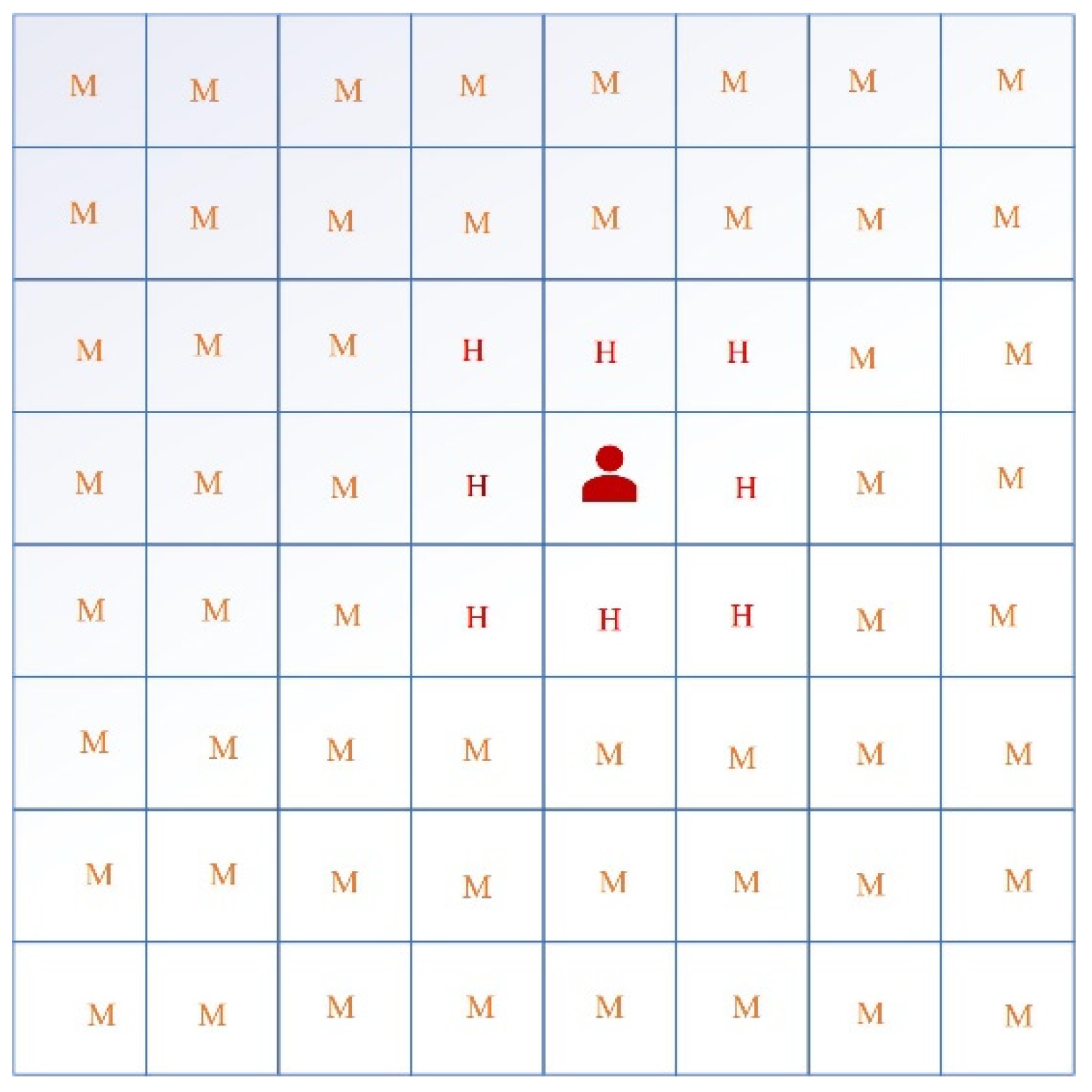
The enclosed space is divided into many grids (each grid 20 m × 20 m) such as
Figure 6, and every person’s arrival and leaving times at a grid are recorded. In
Figure 6, a COVID-19-positive individual is in a grid, and the location of this grid is denoted as
, and the risk level of this grid is seen as “Extremely High” at this moment. There are four risk levels for each grid: “Extremely High = 1”, “High = 2”, “Medium = 3”, and “Low = 4”. They change in real time. Risk levels at this moment of other grids
follow Equation (22).
Let us assume that the patient disappears directly at this moment. Then, every grid launches a timer. Suppose the time from the disappearance of the patient is
, and the principles of risk level changes follows
Table 4.
When , the risk level of all grids remains unchanged. The second row in the table represents that when , the former grid with “Extremely High” risk level is “High”, etc. The risk level can only be reduced by two levels at most.
A patient cannot disappear directly in a grid. He can only leave from the boundary. When he moves, the new grid he steps in will be subsequently defined as “Extremely High” level and other grids will change their levels according to Equation (22). Visually, it is like “sliding” the original risk distribution window with the patient’s footsteps. The risk level is influenced by both Equation (22) and
Table 4, and the final risk level of a grid is the highest result. An example is presented in
Figure 7. At 12:00, a patient was at D and all grids are defined as “High” risk level (except D). He entered E at 12:05 without leaving. After 5 h, the timer at E defines the risk level as “High” according to
Table 4, but Equation (22) considers E as “Extremely High”, so the final definition is “Extremely High” for “
”. Each grid may start more than one timer because of the continuous movement of a patient, and we only recognize the results that are considered the riskiest.
A user with a mobile phone sends an RSSI vector to the server and the server matches information in the fingerprint database with the vector to return a location, which means it is simple to associate the location with time. After dividing the enclosed space into grids, when a person enters the grid, when he leaves the grid, and how long he stays are recorded. Thus, many statistics are available, including but not limited to the following:
Viewing a patient’s track on the timeline.
Viewing a user’s track on the timeline.
Checking how long a user has been in risk areas.
Finding the closest point to an infected individual a person has ever been to.
Based on this information, individuals can be classified by different risk levels. People who have ever been in any grid in the “Extremely High” level are marked “Extremely High infection risk”; those who have stayed in “High”-level grids, or the gross staying time in “Medium”-level grids exceeds 2 h are denoted “High infection risk”; other related people are seen as “potentially infected”. If someone has never been to the enclosed space after an infected individual went in, he is deemed to be at low risk. All these threshold values are not arbitrarily determined, and they refer to the pandemic prevention and control policies conducted by governments around the world (e.g., red–yellow–green code strategy for marking different crowds) [
59].














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}