
SHFL: K-Anonymity-Based Secure Hierarchical Federated Learning Framework for Smart Healthcare Systems

 , , ,
, , , 
Abstract
:1. Introduction
- 1.
- We propose the SHFL framework for smart healthcare systems. In particular, we added K-anonymity-based location privacy along with data privacy of FL to anonymize the identity of the participating clients.
- 2.
- The proposed SHFL framework leverages the centralized server that communicates with multiple directly and indirectly connected devices hierarchically. Moreover, the proposed SHFL formulates the hierarchical clusters of LBSs to execute hierarchical FL.
- 3.
- The performance of the proposed SHFL was evaluated through extensive simulation experiments conducted with multiple model architectures and datasets.
2. Related Work
3. System Models
3.1. FL Model
- 1.
- The LCs in the network independently train their models using their data.
- 2.
- After training the local models, the trained models are uploaded to the cloud server, which aggregates them to obtain a new global model.
- 3.
- The newly obtained global model is sent to the clients, who train their local models independently using new global parameters.
3.2. Threat Model
3.3. Network Model
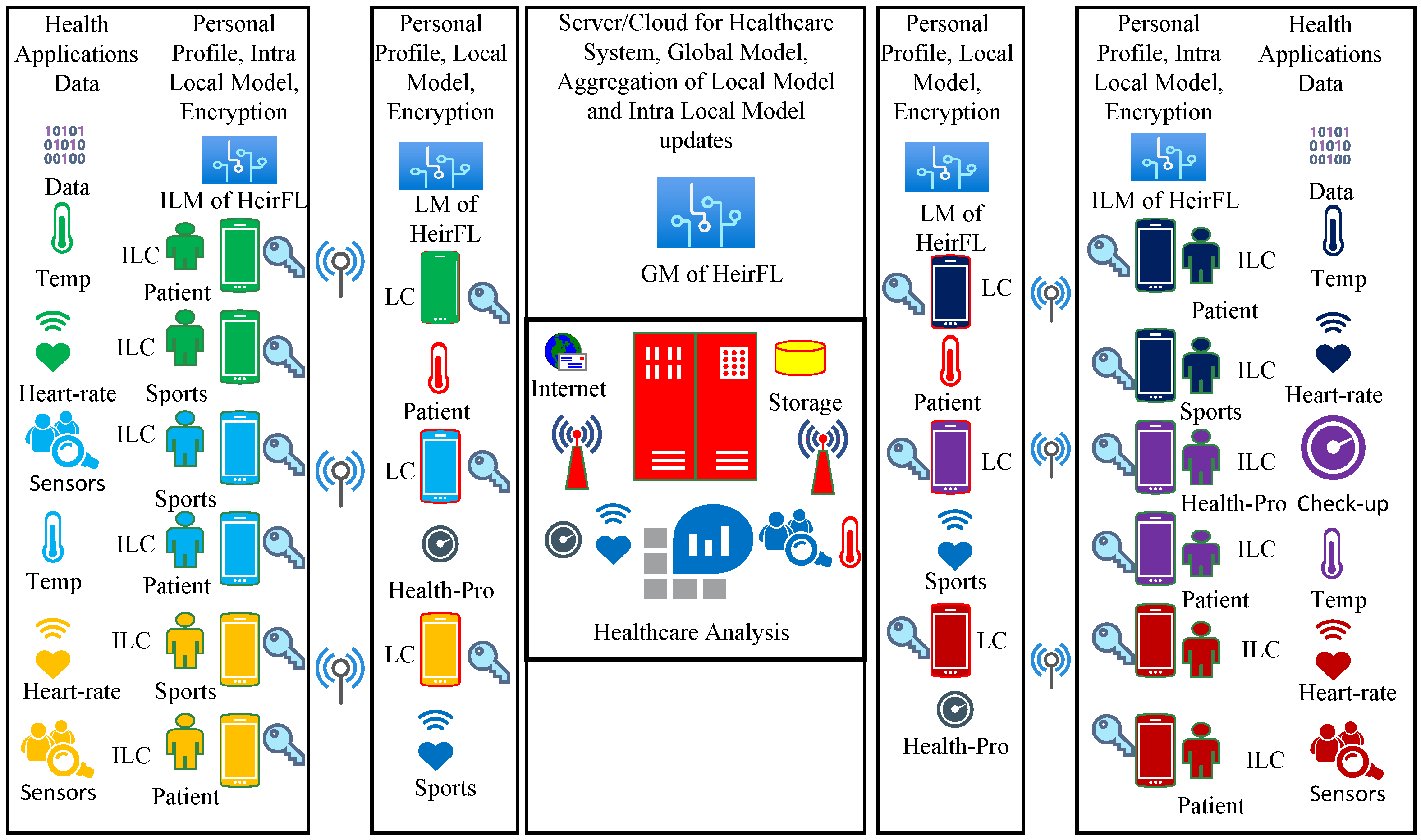
4. K-Anonymity-Based SHFL
4.1. Secure Hierarchical Distributed Architecture
4.1.1. Clustering Index of SHFL
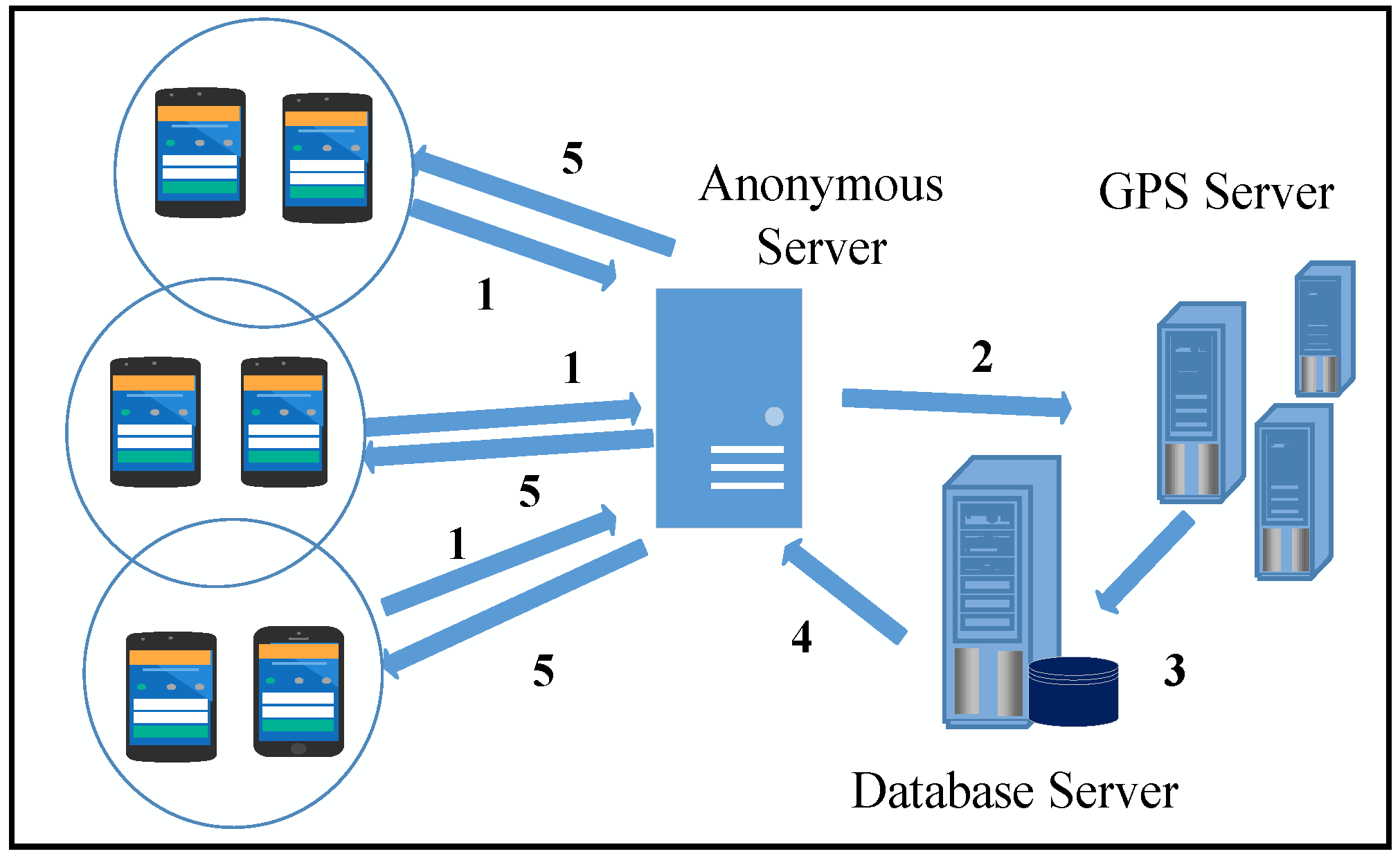
4.1.2. K-Anonymity-Based Regrouping of Anonymous Clusters of SHFL
- 1.
- The directly connected LCs transmit the initial dialogue with a trusted anonymous server and deliver their demand of anonymity with the degree of and its corresponding cluster size.
- 2.
- For anonymous re-clustering of the devices, the anonymous server computes the anonymous results for the set using the K-Anonymity algorithm and sends the results to the LBS server.
- 3.
- According to the position information provided by and the recommendation of the K-anonymous algorithm, the LBS and database server continue the anonymous query procedure. The LBS server regroups the nodes and formulates the set . Similarly, the LBS processes the re-clustering demand of the intra-local devices connected to in the form of .
- 4.
- The outcome of the LBS server and database server is delivered to the K-anonymous server.
- 5.
- Finally, the K-anonymous server re-checks the sets and according to the actual locations. It transmits the K-anonymous replies to the network devices.
| Algorithm 1: Generation of anonymous result sets. |
 |
- 1.
- Reachability distance (ReachDist) is calculated by the following equation:
- 2.
- K-nearest neighbor (K-NN) distance in the space can be defined as follows:
- 3.
- The density of object x in the client space is defined as follows, where k denotes the density and x denotes the object:
- 4.
- The Local Reachability Density (LRD) of the device is the opposite of the average RD of K-NN based on the device x. The following equation calculates the LRD:
- 5.
- Local Outlier Factor (LOF) characterizes x as an outlier, which is calculated by the following equation:
- 6.
- Centrifugal degree of the anonymous group is the average distance between the anchor and other points in the anonymous group. If the anonymous group C uses m as its anchor, the centrifugal degree of m can be calculated as follows:
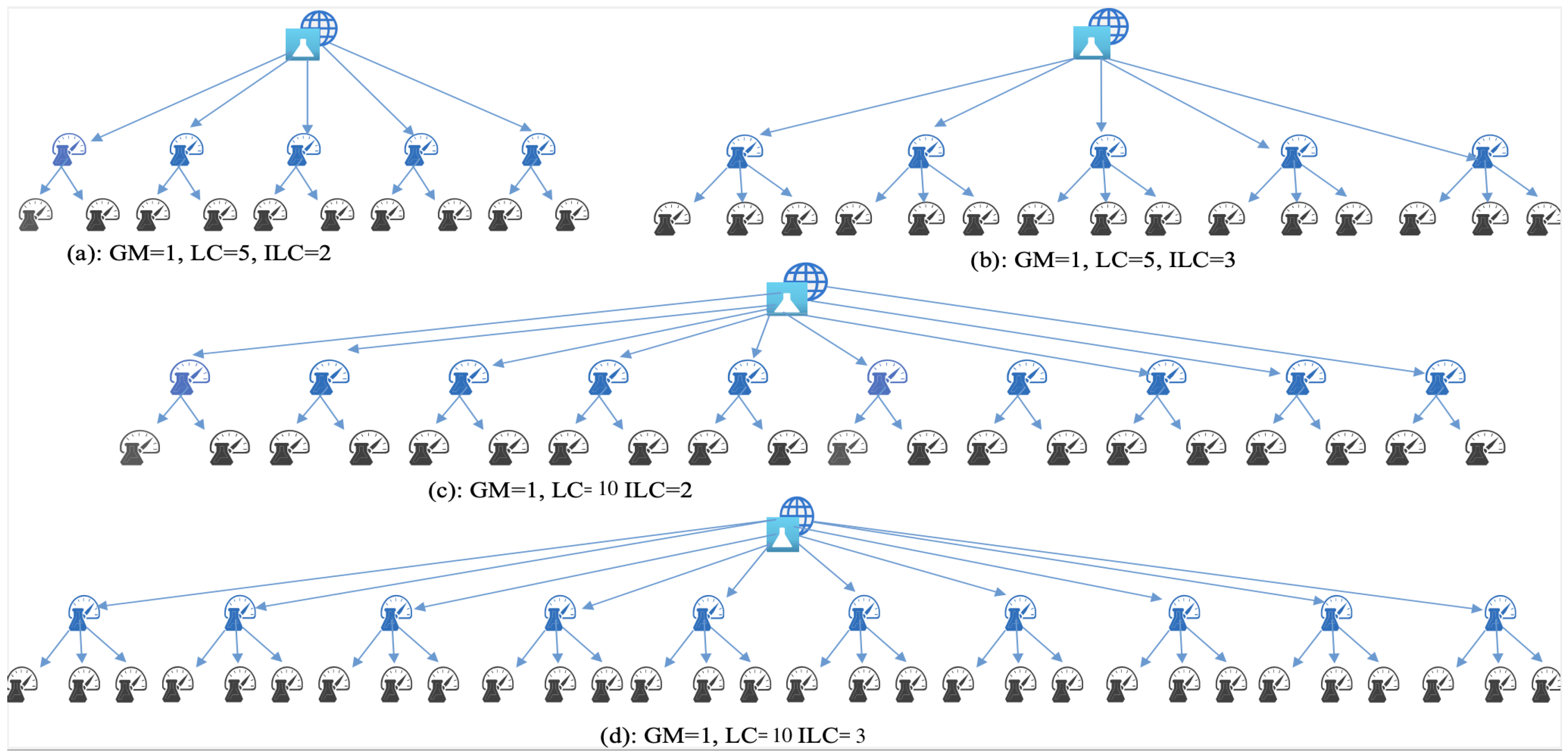
5. Experiments
- System Configuration: Our simulation experiments were conducted on a CPU i9-9980HK @ 2.40 GHz with 32 GB RAM. The SHFL framework was designed using Python in TensorFlow.
- Data Distribution: In all our experiments, we used the pathological distribution of data, where each LC can only receive images corresponding to eight labels; thus, each LC receives minimum 300 samples. The data were divided into distinct clusters using the distribution, and each cluster was evenly split across numerous LCs and ILCs.
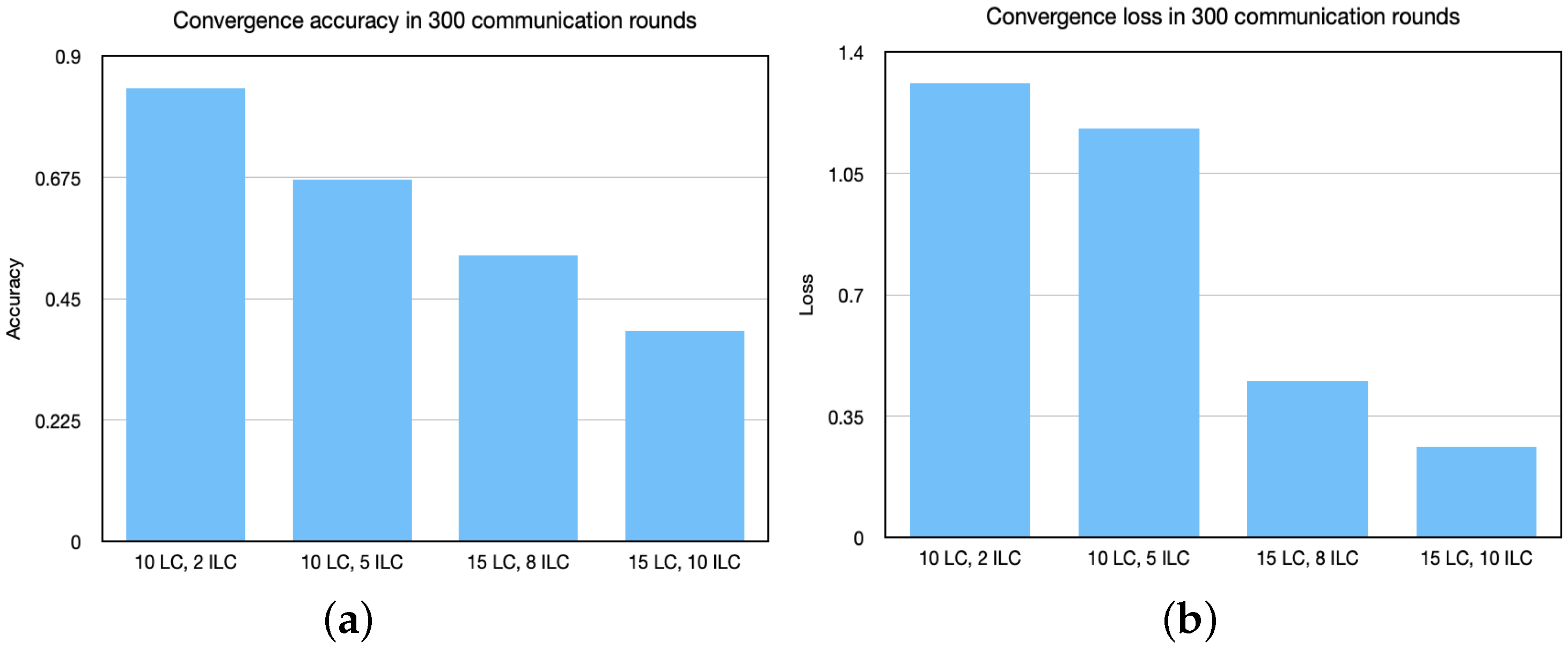
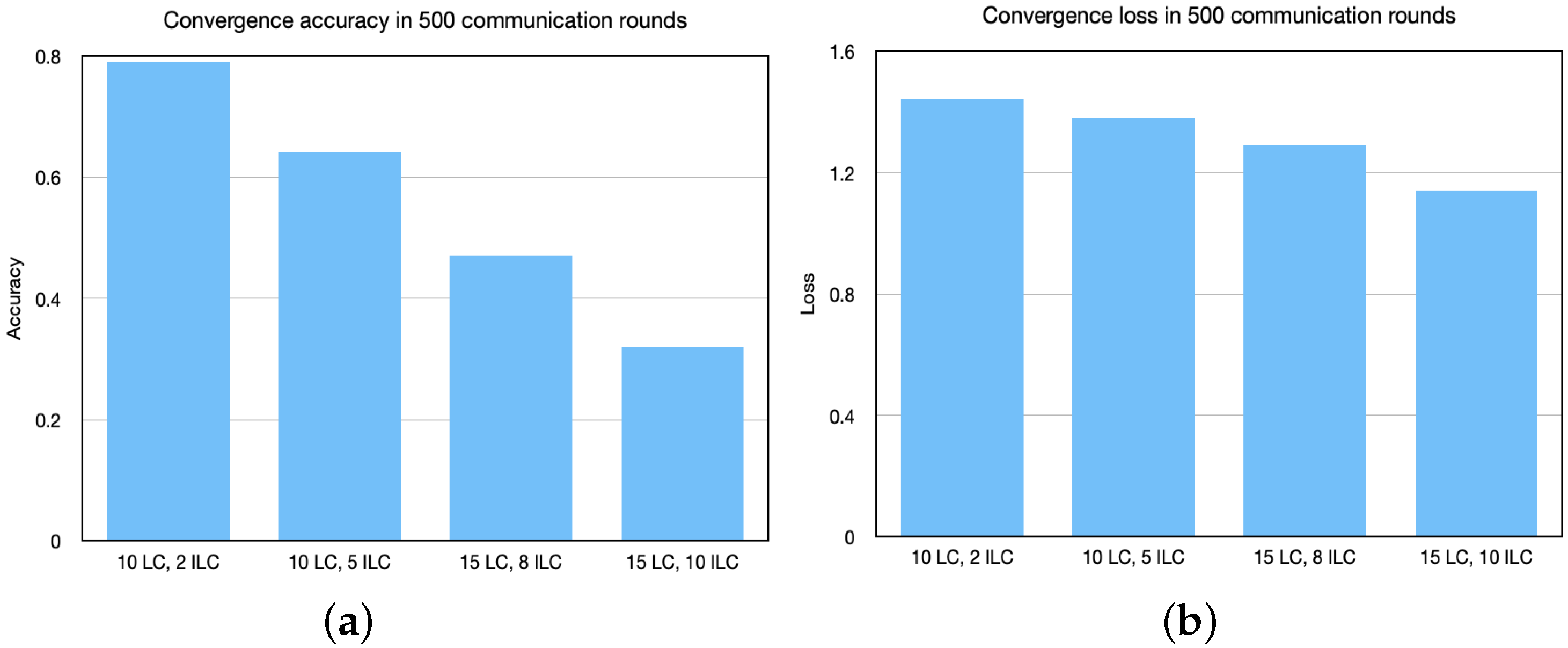
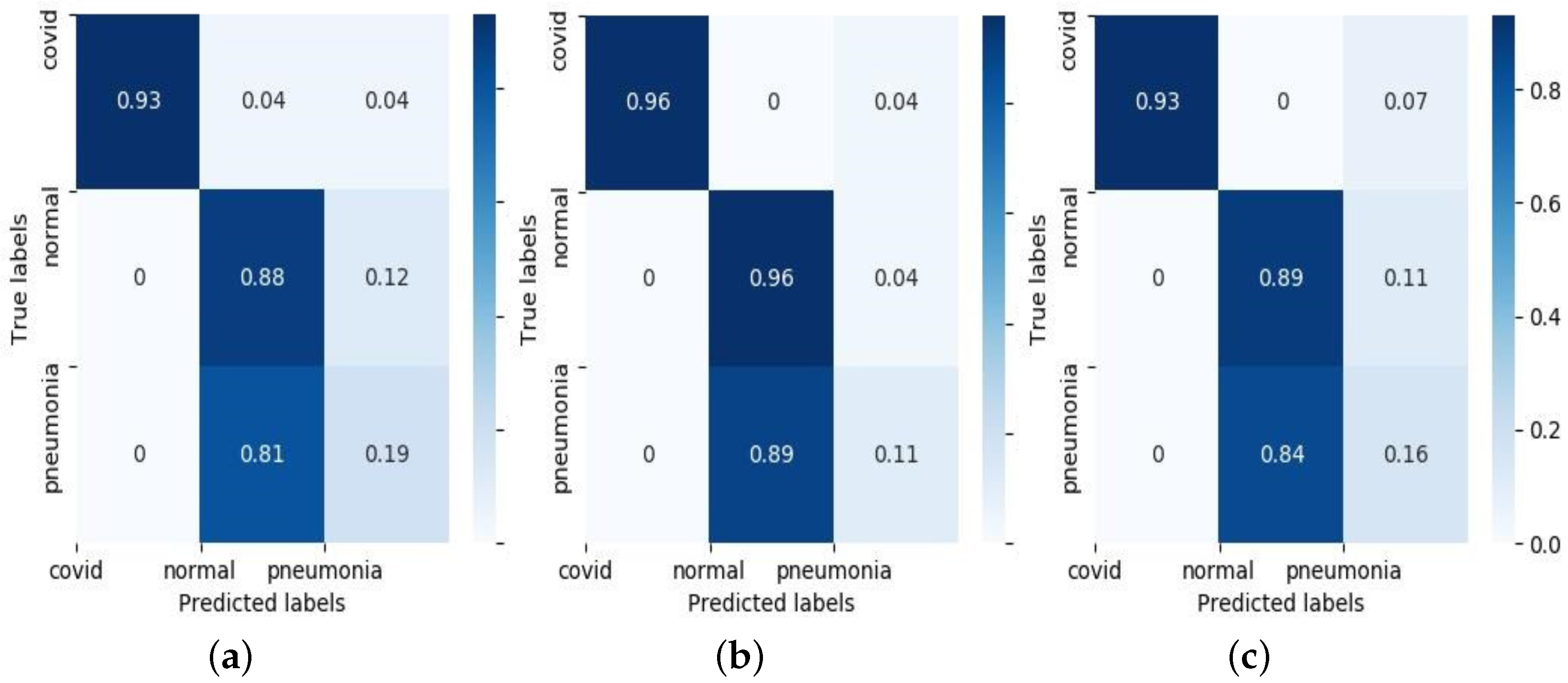
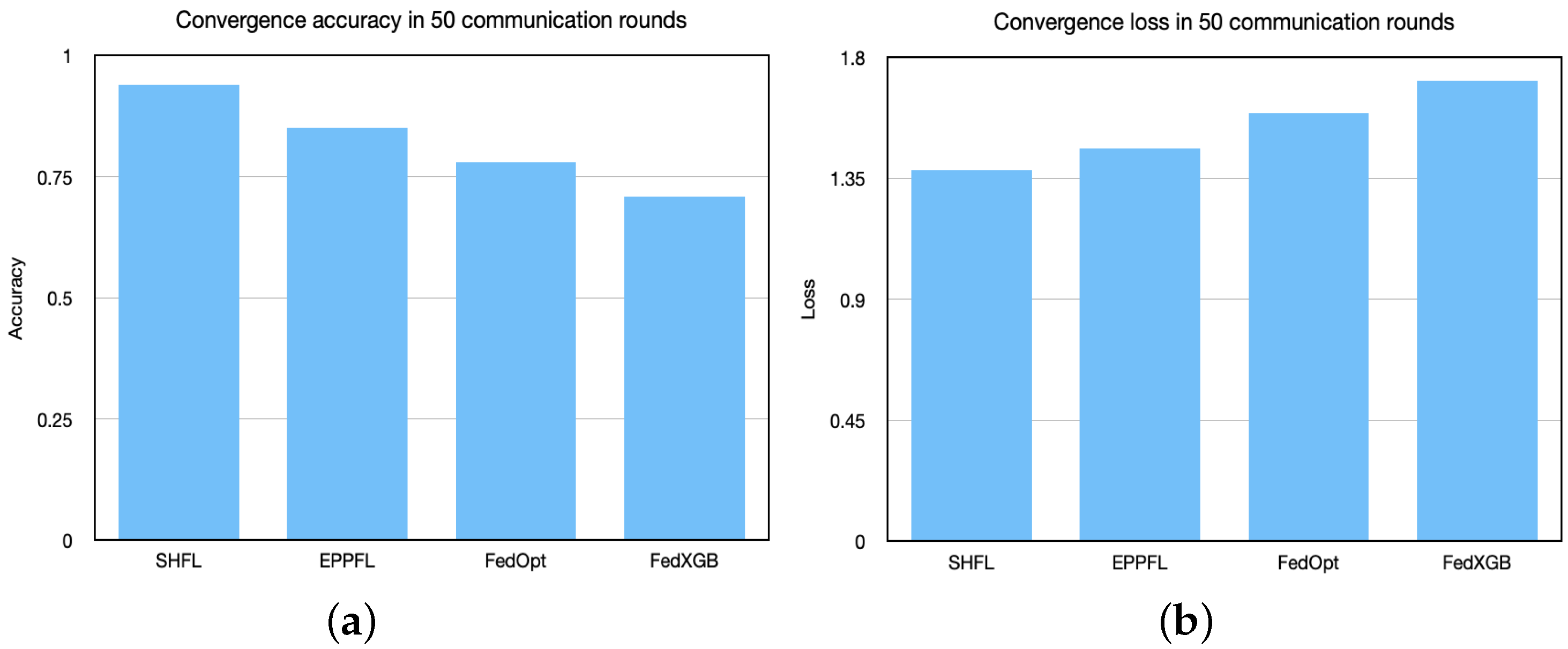
5.1. Convergence
5.2. Comparison
6. Conclusions
- Communication efficiency is a significant concern in FL, where SHFL needs to minimize the communication cost by using either compressed updates or sparse data, which could be the focus of our future work. Moreover, privacy attacks will be considered in our future work.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bi, Z.; Da Xu, L.; Wang, C. Internet of things for enterprise systems of modern manufacturing. IEEE Trans. Ind. Inform. 2014, 10, 1537–1546. [Google Scholar]
- Chiuchisan, I.; Chiuchisan, I.; Dimian, M. Internet of Things for e-Health: An approach to medical applications. In Proceedings of the 2015 International Workshop on Computational Intelligence for Multimedia Understanding (IWCIM), Prague, Czech Republic, 29–30 October 2015; pp. 1–5. [Google Scholar]
- Khatua, P.K.; Ramachandaramurthy, V.K.; Kasinathan, P.; Yong, J.Y.; Pasupuleti, J.; Rajagopalan, A. Application and assessment of internet of things toward the sustainability of energy systems: Challenges and issues. Sustain. Cities Soc. 2020, 53, 101957. [Google Scholar] [CrossRef]
- Jeong, J.S.; Han, O.; You, Y.Y. A design characteristics of smart healthcare system as the IoT application. Indian J. Sci. Technol. 2016, 9, 52. [Google Scholar] [CrossRef]
- Chen, C.M.; Liu, S.; Chaudhry, S.A.; Chen, Y.C.; Khan, M.A. p A Lightweight and Robust User Authentication Protocol with User Anonymity for IoT-Based Healthcare. CMES-Comput. Model. Eng. Sci. 2022, 131, 307–329. [Google Scholar] [CrossRef]
- Manogaran, G.; Varatharajan, R.; Lopez, D.; Kumar, P.M.; Sundarasekar, R.; Thota, C. A new architecture of Internet of Things and big data ecosystem for secured smart healthcare monitoring and alerting system. Future Gener. Comput. Syst. 2018, 82, 375–387. [Google Scholar] [CrossRef]
- Abawajy, J.H.; Hassan, M.M. Federated internet of things and cloud computing pervasive patient health monitoring system. IEEE Commun. Mag. 2017, 55, 48–53. [Google Scholar] [CrossRef]
- Patel, W.; Pandya, S.; Mistry, V. i-MsRTRM: Developing an IoT based Intelligent Medicare system for Real-Time Remote Health monitoring. In Proceedings of the 2016 8th International Conference on Computational Intelligence and Communication Networks (CICN), Tehri, India, 23–25 December 2016; pp. 641–645. [Google Scholar]
- Wu, Q.; Chen, X.; Zhou, Z.; Zhang, J. Fedhome: Cloud-edge based personalized federated learning for in-home health monitoring. IEEE Trans. Mob. Comput. 2020, 21, 2818–2832. [Google Scholar] [CrossRef]
- Ali, W.; Din, I.U.; Almogren, A.; Guizani, M.; Zuair, M. A lightweight privacy-aware iot-based metering scheme for smart industrial ecosystems. IEEE Trans. Ind. Inform. 2021, 17, 6134–6143. [Google Scholar] [CrossRef]
- Islam, A.; Al Amin, A.; Shin, S.Y. FBI: A federated learning-based blockchain-embedded data accumulation scheme using drones for Internet of Things. IEEE Wirel. Commun. Lett. 2022, 11, 972–976. [Google Scholar] [CrossRef]
- Gribbestad, M.; Hassan, M.U.; A Hameed, I.; Sundli, K. Health Monitoring of Air Compressors Using Reconstruction-Based Deep Learning for Anomaly Detection with Increased Transparency. Entropy 2021, 23, 83. [Google Scholar] [CrossRef]
- Malik, S.; Rouf, R.; Mazur, K.; Kontsos, A. The Industry Internet of Things (IIoT) as a Methodology for Autonomous Diagnostics in Aerospace Structural Health Monitoring. Aerospace 2020, 7, 64. [Google Scholar] [CrossRef]
- Harweg, T.; Peters, A.; Bachmann, D.; Weichert, F. CNN-Based Deep Architecture for Health Monitoring of Civil and Industrial Structures Using UAVs. Multidiscip. Digit. Publ. Inst. Proc. 2019, 42, 69. [Google Scholar]
- Zhu, X.; Li, H.; Yu, Y. Blockchain-based privacy preserving deep learning. In Proceedings of the International Conference on Information Security and Cryptology; Springer: Berlin/Heidelberg, Germany, 2018; pp. 370–383. [Google Scholar]
- Yang, Q.; Liu, Y.; Cheng, Y.; Kang, Y.; Chen, T.; Yu, H. Federated learning. Synth. Lect. Artif. Intell. Mach. Learn. 2019, 13, 1–207. [Google Scholar]
- Rauch, G.; Röhmel, J.; Gerß, J.; Scherag, A.; Hofner, B. Current challenges in the assessment of ethical proposals-aspects of digitalization and personalization in the healthcare system. Bundesgesundheitsblatt Gesundheitsforschung Gesundheitsschutz 2019, 62, 758–764. [Google Scholar] [CrossRef] [PubMed]
- Duan, M.; Liu, D.; Chen, X.; Liu, R.; Tan, Y.; Liang, L. Self-balancing federated learning with global imbalanced data in mobile systems. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 59–71. [Google Scholar] [CrossRef]
- Sun, L.; Qian, J.; Chen, X.; Yu, P.S. Ldp-fl: Practical private aggregation in federated learning with local differential privacy. arXiv 2020, arXiv:2007.15789. [Google Scholar]
- Pandey, S.R.; Tran, N.H.; Bennis, M.; Tun, Y.K.; Manzoor, A.; Hong, C.S. A crowdsourcing framework for on-device federated learning. IEEE Trans. Wirel. Commun. 2021, 19, 3241–3256. [Google Scholar] [CrossRef] [Green Version]
- Thrun, M.C.; Ultsch, A. Using Projection-Based Clustering to Find Distance-and Density-Based Clusters in High-Dimensional Data. J. Classif. 2020, 1–33. [Google Scholar] [CrossRef]
- Berke, A.; Bakker, M.; Vepakomma, P.; Raskar, R.; Larson, K.; Pentland, A. Assessing disease exposure risk with location histories and protecting privacy: A cryptographic approach in response to a global pandemic. arXiv 2020, arXiv:2003.14412. [Google Scholar]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the convergence of fedavg on non-iid data. arXiv 2019, arXiv:1907.02189. [Google Scholar]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef] [Green Version]
- Caldas, S.; Konečny, J.; McMahan, H.B.; Talwalkar, A. Expanding the reach of federated learning by reducing client resource requirements. arXiv 2018, arXiv:1812.07210. [Google Scholar]
- Luping, W.; Wei, W.; Bo, L. CMFL: Mitigating communication overhead for federated learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 954–964. [Google Scholar]
- Asad, M.; Moustafa, A.; Ito, T. FedOpt: Towards communication efficiency and privacy preservation in federated learning. Appl. Sci. 2020, 10, 2864. [Google Scholar] [CrossRef] [Green Version]
- Sattler, F.; Müller, K.R.; Samek, W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3710–3722. [Google Scholar] [CrossRef]
- Chen, M.; Poor, H.V.; Saad, W.; Cui, S. Wireless communications for collaborative federated learning. IEEE Commun. Mag. 2020, 58, 48–54. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Client-edge-cloud hierarchical federated learning. In Proceedings of the ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Zhang, J.; Chen, B.; Yu, S.; Deng, H. PEFL: A privacy-enhanced federated learning scheme for big data analytics. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Chen, Y.; Luo, F.; Li, T.; Xiang, T.; Liu, Z.; Li, J. A training-integrity privacy-preserving federated learning scheme with trusted execution environment. Inf. Sci. 2020, 522, 69–79. [Google Scholar] [CrossRef]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečnỳ, J.; Mazzocchi, S.; McMahan, H.B.; et al. Towards federated learning at scale: System design. arXiv 2019, arXiv:1902.01046. [Google Scholar]
- Hao, M.; Li, H.; Luo, X.; Xu, G.; Yang, H.; Liu, S. Efficient and privacy-enhanced federated learning for industrial artificial intelligence. IEEE Trans. Ind. Inform. 2019, 16, 6532–6542. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In European Conference on Computer Vision Proceedings of the Identity Mappings in Deep Residual Networks; Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
- Zhao, J.; Zhang, Y.; He, X.; Xie, P. Covid-ct-dataset: A ct scan dataset about covid-19. arXiv 2020, arXiv:1902.01046. [Google Scholar]
- Hao, M.; Li, H.; Xu, G.; Liu, S.; Yang, H. Towards efficient and privacy-preserving federated deep learning. In Proceedings of the ICC 2019-2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Liu, Y.; Ma, Z.; Liu, X.; Ma, S.; Nepal, S.; Deng, R. Boosting privately: Privacy-preserving federated extreme boosting for mobile crowdsensing. arXiv 2019, arXiv:1907.10218. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Limitations | Summary |
|---|---|---|
| [5] | Limited discussion on healthcare | A study on security vulnerabilities in the field of healthcare. |
| [7] | Single case study | A case study on patient health monitoring. |
| [9] | Non-personalized FL model | A study on client-edge-based FL framework for in-home health monitoring. |
| [20] | Limited to general architecture | A study on incentive mechanism for interaction between the crowdsourcing platform and the model training approach adopted by the client to optimize the communication efficiency. |
| [22] | Limited accuracy due to PSI protocol | A study to control COVID using cryptographic protocols to reduce the information revealed regarding the traces of positive users. |
| [23] | Non-personalized FL model | A study on FedAvg algorithm for non-identical and non-independent data. |
| [27] | Non-personalized FL model | A study on communication efficiency using sparse compression and privacy preservation using differential privacy in FL. |
| [28] | No-application specific | The study uses cosine similarity between the gradient updates for clustering in FL. |
| [30] | General hierarchical architecture | A study on hierarchical FL framework that uses edge nodes for additional model aggregation for faster communication. |
| [31] | Non-personalized FL model | A study on privacy preservation of FL using Pallier homomorphic cryptosystem. |
| MNIST | CIFAR-10 | COVID-19 | |
|---|---|---|---|
| Parameter | Values | ||
| Model | CNN | CNN | AlexNet |
| Momentum | 0.5 | 0.3 | 0.1 |
| Optimizer | SGD | SGD | SGD |
| Batch size | 10 | 20 | 30 |
| Learning rate | 0.25 | 0.5 | 0.5 |
| Clients | 500 | 200 | 200 |
| Client transmission power | 200 mW | 200 mW | 200 mW |
| Communication rounds | 300 | 500 | 200 |
| Local epochs | 200 | 200 | 100 |
| Local update size | 20,000 nats | 20,000 nats | 20,000 nats |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asad, M.; Aslam, M.; Jilani, S.F.; Shaukat, S.; Tsukada, M. SHFL: K-Anonymity-Based Secure Hierarchical Federated Learning Framework for Smart Healthcare Systems. Future Internet 2022, 14, 338. https://doi.org/10.3390/fi14110338
Asad M, Aslam M, Jilani SF, Shaukat S, Tsukada M. SHFL: K-Anonymity-Based Secure Hierarchical Federated Learning Framework for Smart Healthcare Systems. Future Internet. 2022; 14(11):338. https://doi.org/10.3390/fi14110338
Chicago/Turabian StyleAsad, Muhammad, Muhammad Aslam, Syeda Fizzah Jilani, Saima Shaukat, and Manabu Tsukada. 2022. "SHFL: K-Anonymity-Based Secure Hierarchical Federated Learning Framework for Smart Healthcare Systems" Future Internet 14, no. 11: 338. https://doi.org/10.3390/fi14110338