1. Introduction
What are cryptocurrencies? How do they compare to traditional financial instruments? Are they like traditional money, like commodities, a hybrid of the former or an utterly new type of asset that merit their own definition and understanding? Early research, mainly focusing on Bitcoin (henceforth BTC), provides mixed insights. While the creation of new BTCs resembles the mining process of gold—or precious metals in general—its attributes clearly differentiate it from conventional commodities [
1]. The claim that BTC is fundamentally different from valuable metals like gold is also backed by Klein et al. [
2] due to its shortage in stable hedging capabilities. Along with [
3], Cheah and Fry [
1] also argue that standard economic theories cannot explain BTC price formation and using data up to 2015, they provide evidence that BTC lacks the qualities necessary to be qualified as money. However, using GARCH models, Dyhrberg [
4] demonstrates that BTC has similarities to both gold and the US dollar (USD) and somewhat surprisingly that it may be ideal for risk-averse investors. Also, while the BTC is useful to diversify financial portfolios—due to the negative correlation to the US implied volatility index (VIX)—it otherwise has limited
safe-haven properties [
5,
6,
7]. Using data from a longer period (between 2010 and 2017), Demir et al. [
8] conclude the opposite, namely that BTC may indeed serve as a hedging tool, due to its relationship to the Economic Policy Uncertainty Index (EUI).
The fact that cryptocurrencies are different from any other asset in the financial market is further supported by [
9,
10,
11]. High volatility, speculative forces and large dependence on social sentiment at least during its earlier stages—as measured by social media and Internet data (Google trends, Wikipedia searches and Twitter posts)—are qualified by many as some of the main determinants of BTC prices [
12,
13]. Yet, a large amount of price variability remains unaccounted for. Moreover, the proliferation of cryptocurrencies other than BTC that are supported by different technologies, i.e., variations of the standard Proof-of-Work distributed consensus of the BTC blockchain, e.g., [
14], calls for a more comprehensive research approach. Despite the high documented correlation in the price of the various cryptocurrencies, it is highly debated whether this trend will also continue into future or not [
15,
16].
In the present paper, we make an effort towards understanding the correlation between a set of traditional assets and cryptocurrencies. We adopt an economic/financial perspective and use a set of 14 financial and economic predictors comprising main exchange rates (4 variables), equity indices (4 variables), commodity future prices (oil and gold) and economic uncertainty indicators (2 variables) along with 2 quasi-economic and 2 cryptocurrency specific variables: the hash rate which captures the amount of investment on mining equipment and hence accounts for the economic size of the network and the average block size which implicitly measures the amount of transactions and hence the activity in the respective cryptocurrency. All the variables and the applied transformations are summarized in
Table 1. Also, we report the correlations between the explanatory variables in
Table 2.
Earlier studies highlight the scarcity of results on cryptocurrencies other than BTC and underline the need for a better understanding of the entire cryptocurrency ecosystem and its properties (statistical and economic), see e.g., [
11,
17]. Studies that go beyond the BTC prices and confirm via various financial models the importance of using diverse cryptocurrencies—rather than a single one—in portfolio optimization include but are not limited to [
18] and [
15]. In view of the above, in the present study, apart from Bitcoin (BTC), we also focus on Ether (ETH), the native coin of the Ethereum blockchain [
14,
19], and currently the second largest cryptocurrency in terms of market capitalization [
20]. Unlike the BTC blockchain, the Ethereum blockchain has been launched eponymously and is governed, or more aptly researched and developed, by the Ethereum Foundation [
21], a non-profit organization-based in Switzerland. The architecture of the Ethereum ecosystem has far-reaching implications on its long-term development and sustainability that clearly differentiate it from BTC. Supporting smart contract execution—execution of code snippets that go beyond the simple monetary transactions of BTC—Ethereum has scheduled a transition from the currently computationally heavy Proof of Work (introduced by BTC and followed by most cryptocurrencies) to the computationally efficient alternative of Proof of Stake, which saves on energy resources and provides a scalable infrastructure while retaining the same security guarantees as Proof of Work. Without going further into the technical details, the main motivation to study ETH that stems from these considerations is the following. Given the different technological advancements that are promised by Ethereum, will ETH become independent from BTC and follow its own path as a cryptocurrency or are after all the values of all cryptocurrencies inevitably tied, as they are up to now [
16]? Keeping in mind that ETH—i.e., the native coin—is only one of the main applications of the ETH blockchain—and the blockchain technology in general—it should also be noted that price movements of ETH may not necessarily align in the future with technological advancements in the Ethereum blockchain.
From a methodological perspective, we perform a two-layer Bayesian analysis. First, we transform the cryptocurrency series into a binary series and apply a logistic regression model on the transformed series. Specifically, if the current price return, i.e.,
, exceeds a predefined threshold then we assign the value 1 and 0 otherwise. Then, we investigate whether the logistic regression model—which is widely used by applied statisticians and econometricians for analyzing binary data, see [
22] and references therein—with a specific covariate set is an appropriate model for estimating the probability of observing the value 1 in these binary series. We use the methodology of Polson et al. [
23] to make inference on the model’s parameters with an additional reversible jump step to allow for model uncertainty, cf.
Section 2.1. Secondly, we model the log-price series data using a novel Hidden Markov (regime switching) model, namely the non-homogeneous Pólya Gamma Hidden Markov model (NHPG) of [
24], cf.
Section 2.2. Hidden Markov models introduce time-variation in the parameters through an underlying unobserved discrete process. In brief, at any given time
t, the observed log-price data point depends on a latent (hidden) state. Hence, conditionally on the hidden states, the parameters of the data generating process vary and thus allowing for a flexible data representation. In our setting, the underlying process follows a binomial process with exogenous variables. It has been shown that the NHPG model outperforms similar models in forecasting conventional financial data, cf. [
25]. Also, it uses Bayesian Model Averaging (BMA) approach for inference which has been shown to possess desirable properties for forecasting applications [
26,
27,
28,
29].
With all these in mind, the questions we aim to address are the following:
- Q1.
Does the underlying information from fiat currencies, commodities, stock indices and blockchain specific variables explain/predict the probability of positive returns?
- Q2.
Do the same variables have explanatory/predictive power on both the BTC and ETH cryptocurrencies?
- Q3.
Do the same explanatory variables affect the BTC price series both on the long and short run?
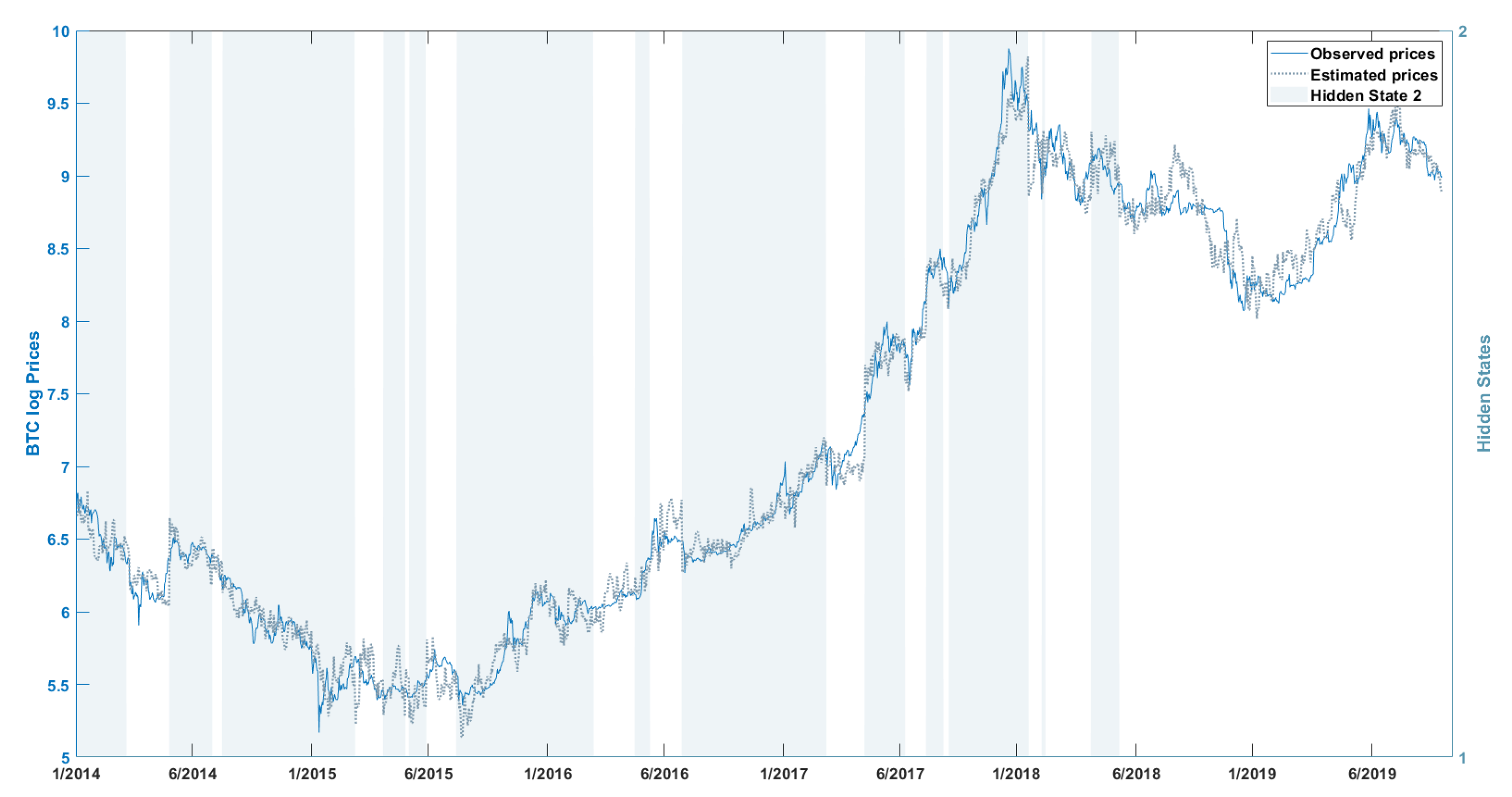
We use daily data (for both the response and the explanatory variables) between 2017 and 2019. For question Q3, we compare the BTC data of the whole 2014–2019 period to the 2017–2019 period (also used in Q1–Q2). As in most of the recent studies, we exclude the period up to 2014 which exhibits markedly different characteristics.
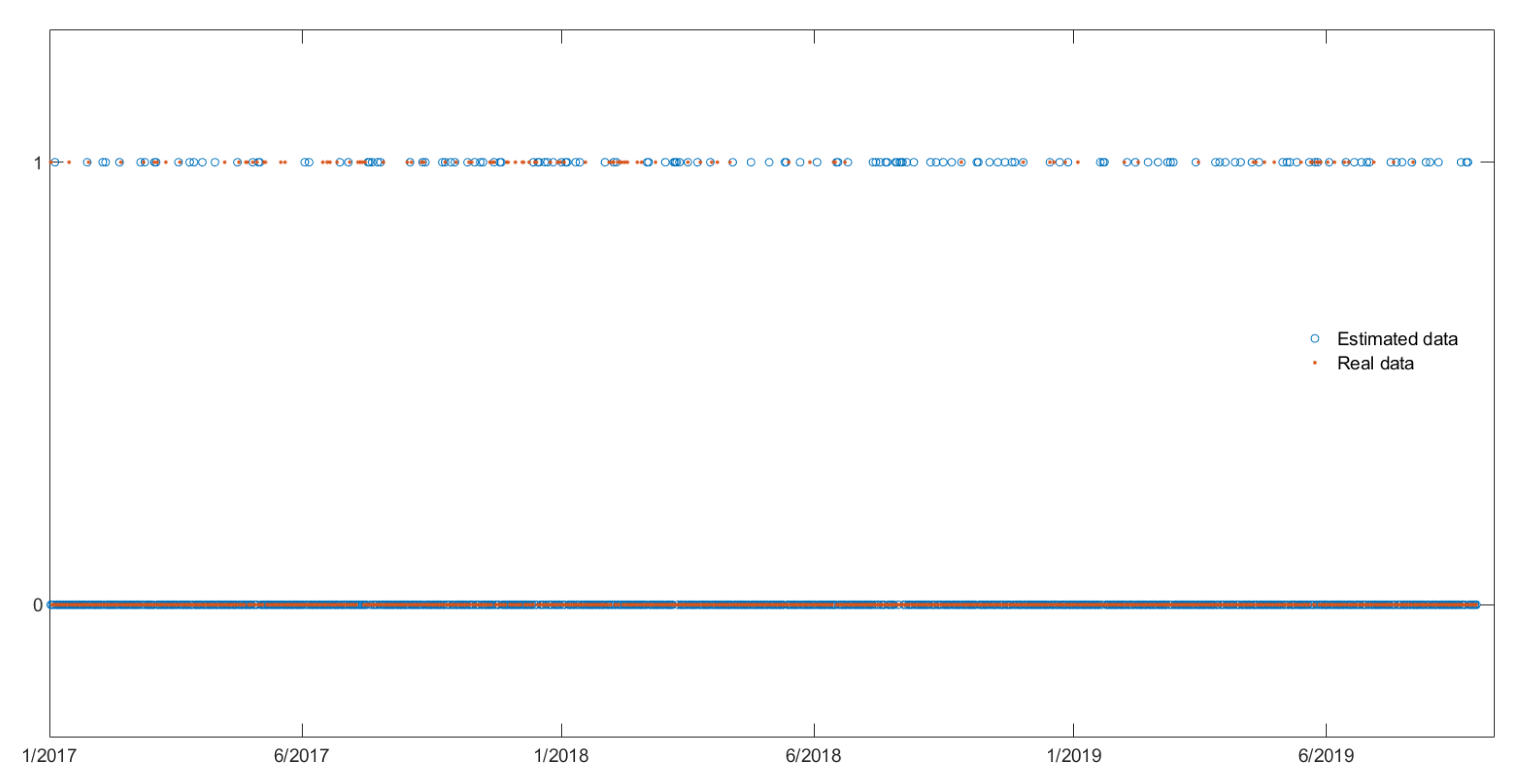
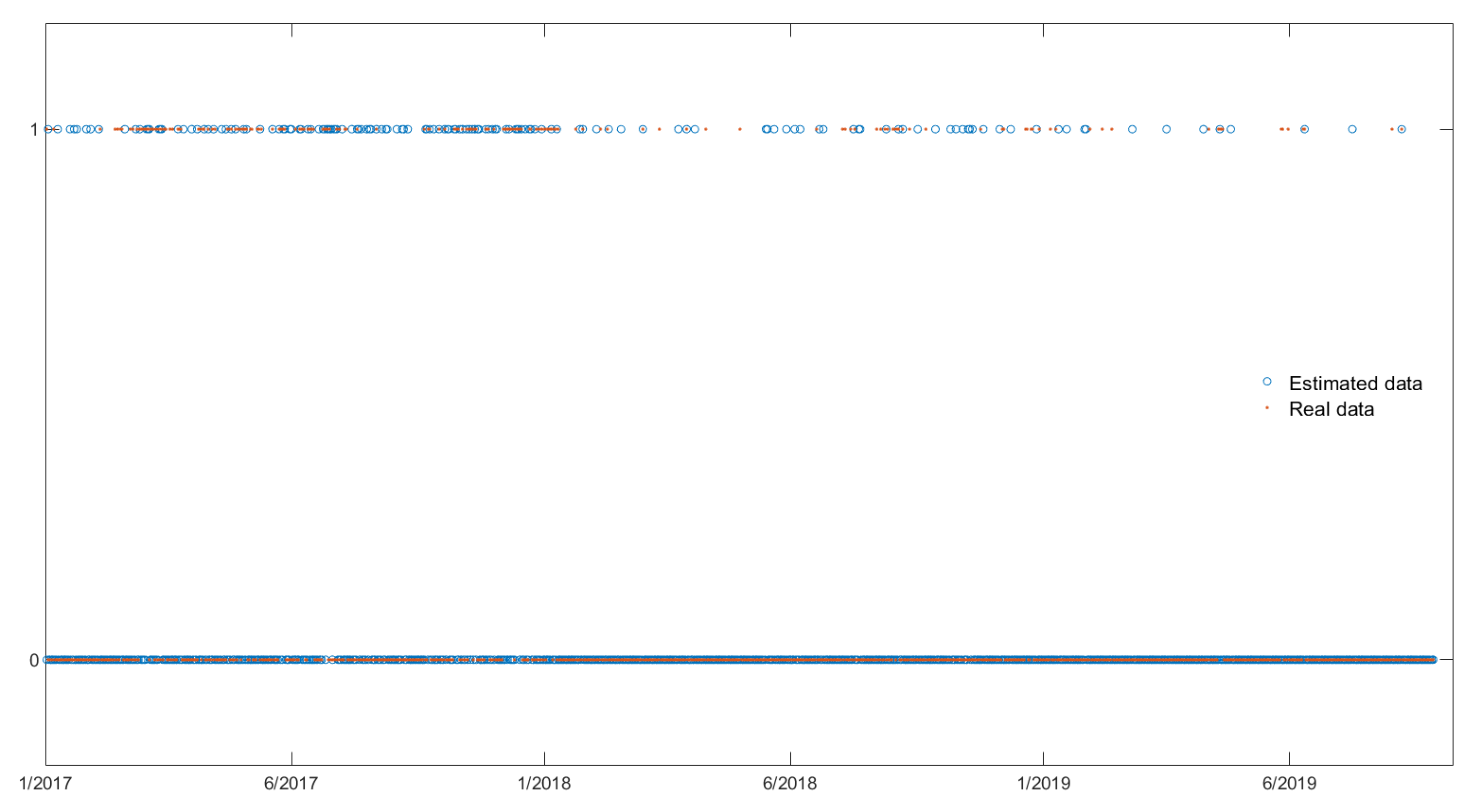
The findings of our experiments can be summarized as follows. The logistic model is not suitable to model the probabilities of positive daily returns of BTC and ETH. However, changing the magnitude of returns, we observe that (a) the logistic model has improved performance (b) the statistical significant covariates in the logistic regression model change and (c) the in-sample (fitting) results are different for the BTC and ETH series.
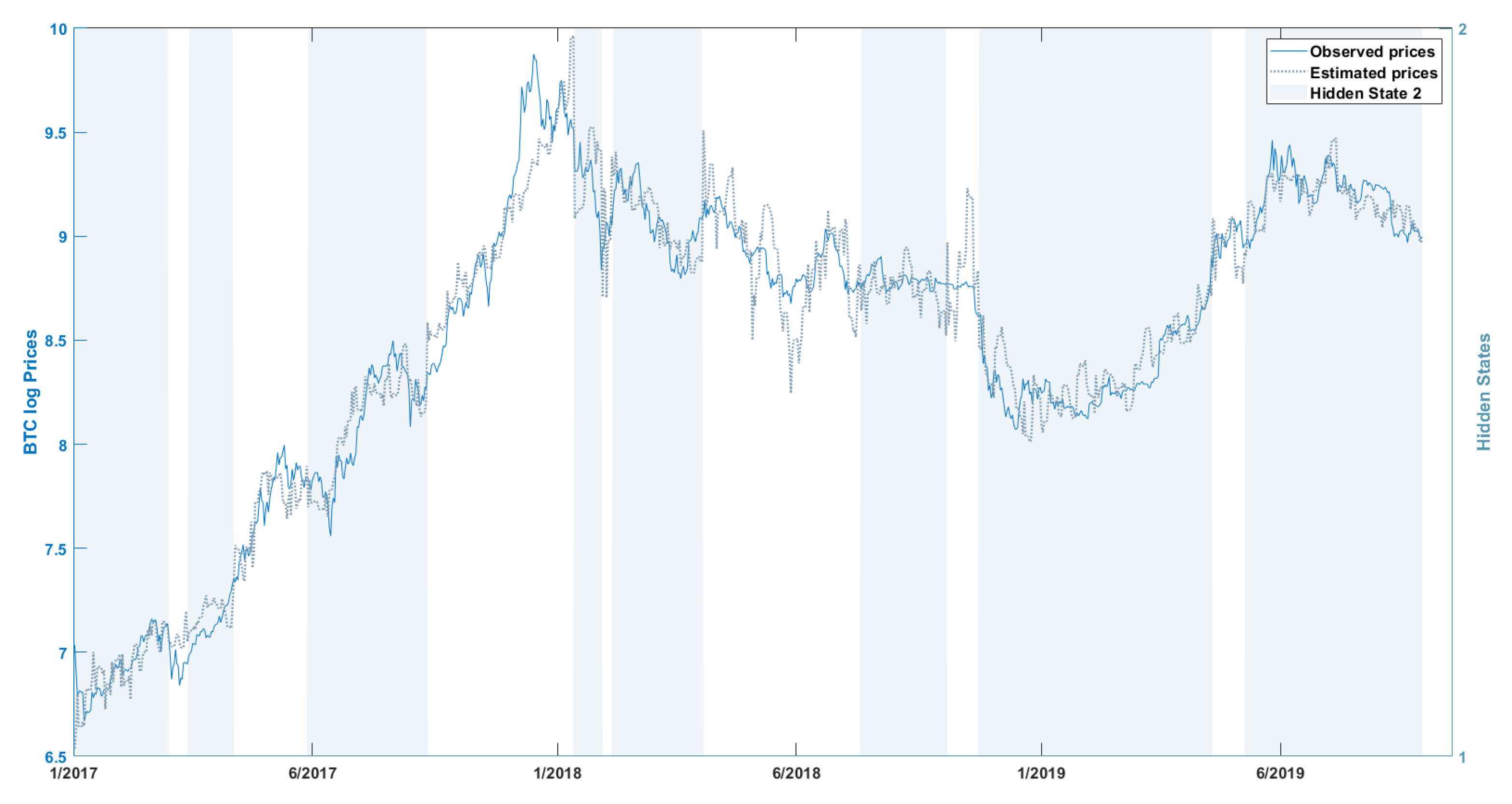
Considering the second experiment, we find that the NHPG model identifies periods of different volatility and accounts well for the heteroskedacity of all three price series (BTC short and long periods and ETH). Graphically, this is illustrated in later figures. The hidden states—which may be described as periods of high and low volatility—are not persistent, i.e., the transitions between the two states are frequent. Based on the same figures, the in-sample performance of the NHPG algorithm is good. However, the set of included predictors—predictors with posterior probability of inclusion above 0.5—is large, which implies that each predictor explains only a small fraction of the volatility of the series. Concerning specific predictors, the exclusion of some of the fiat currency exchange rates for the ETH series suggests a (still) more geographically restricted interest for the currency in comparison to BTC. It is also worth mentioning that the cryptocurrency specific variables, hash rate and average block size are not significant for modeling the BTC and ETH price series. This may indicate a more mature and stabilizing mining network that is less responsive to price expectations, sentiment or extreme speculation.
Finally, as shown in the last figure, the mean posterior out-of-sample predictions, although better for ETH than for BTC, are in general not good as they frequently even miss the direction of movement of the series. However, this is a common outcome in exchange rates [
30,
31]. In sum, our results confirm that the Hidden Markov approach is promising in the understanding of cryptocurrencies price formation and back earlier findings that cryptocurrencies are unlike any existing financial asset and hence that their understanding requires novel tools and ideas.
In the related literature, the first layer of our methodology, i.e., the logistic regression model, falls into the binary regression models literature. They have only been applied in the cryptocurrency context, by [
32] to forecast the daily price direction of BTC, by [
33] to study the price co-explosivity in leading cryptocurrencies and by [
34] to study the herding behavior of BTC. As far as the second layer of our methodology, the present NHPG model falls into the Markov-switching literature that is the benchmark for predicting exchange rates, see [
35] and [
36,
37] and explaining financial time series, see [
38] and references therein. This class of models, account for the non-stationarities and non-linearities of the time series. Although standard in financial applications ([
38]), Hidden Markov models have been applied in the cryptocurrency context by [
39] as Markov-switching GARCH models to model the volatility dynamics of BTC, by [
40], as a state-space model for representing the BTC price series, by [
18] as multivariate state state-space models in forecasting cryptocurrencies, as homogeneous Hidden Markov, i.e., hidden Markov models with constant transition probabilities, by [
41,
42], and in the understanding of price bubbles by [
43]. Also, [
44], study the BTC and ETH prices under structural break setting while [
45] study the cryptocurrency returns and volatility under stochastic volatility model with discontinuous jumps. The use of the NHPG model in explaining and predicting the BTC and ETH price series is also supported by the findings of various articles. For example the authors of [
46,
47] and [
8], demonstrate the non-stationarity of the BTC index and volume and underline the importance of modeling non-linearity in Bitcoin prediction models. This is further elaborated by Beckmann and Schüssler [
26] who suggest that model selection and the use of averaging criteria are necessary to avoid poor forecasting results. Following the similar reasoning, Phillip et al. [
11] posit that standard models are inadequate to capture the extreme variability of cryptocurrencies and argue in favor of more composite approaches. In an important finding, Ciaian et al. [
3] show that the Bitcoin price series exhibits structural breaks and identifies periods of data (prior to 2013 and between 2013 and 2015) of markedly different variance and other econometric characteristics. Their findings further suggest that significant price predictors may vary over time. Pichl and Kaizoji [
48] use data from various time periods to demonstrate, among other results, that the BTC price series exhibits heteroskedasticity.
Finally, the present paper falls into the strand of literature that studies the explanatory and predictive power of traditional financial and economic indices on the cryptocurrency price series. To name a few, Refs. [
4,
49] analyze the relationship between BTC, gold and USD, Ref. [
50] study the predictive power of a large set of exogenous variables, such as commodities, volatility indices, stock indices. Subsets of the studied indices are studied under various settings, see e.g., [
7,
18,
40,
47,
48,
51,
52,
53].
All in all, our aim is to contribute to the literature that studies the modeling and prediction of cryptocurrencies, using a novel Bayesian elaborate econometric model and to try to gain understanding in the statistical, econometric and financial properties of existing cryptocurrencies.
The rest of the paper is structured as follows. In
Section 2, we describe the two econometric models of this study: the logistic regression model is described analytically in
Section 2.1 and the NHPG model and simulation scheme is described in
Section 2.2. The empirical study is presented in
Section 3. In detail, the data set that we used is described in
Section 3.1, the results regarding the logistic model are presented in
Section 3.2 and lastly, the results regarding the NHPG model are presented in
Section 3.3. We conclude the paper with a discussion of the limitations of the present model and directions for future work in
Section 4.
This paper considerably extends its earlier conference version. Concerning the applied methodology, we provide a rigorous description of the logistic regression model for studying the probabilities of positive returns (
Section 2.1) and of the NHPG model (
Section 2.2). In addition, we have updated the data set—BTC and ETH series—and the covariate set. Specifically, in the covariate set, (
Table 1), we have included the Russel 2000 index, excluded the autoregressive terms and applied different transformations on the variables. More importantly, concerning the results, this paper includes the novel analysis of the logistic model (
Section 3.2) and based on the new covariate set, it offers more enriched outcomes and more comprehensive insight from the analysis of the NHPG model (
Section 3.3).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





