Introducing External Knowledge to Answer Questions with Implicit Temporal Constraints over Knowledge Base


Abstract
:1. Introduction
2. Related Work
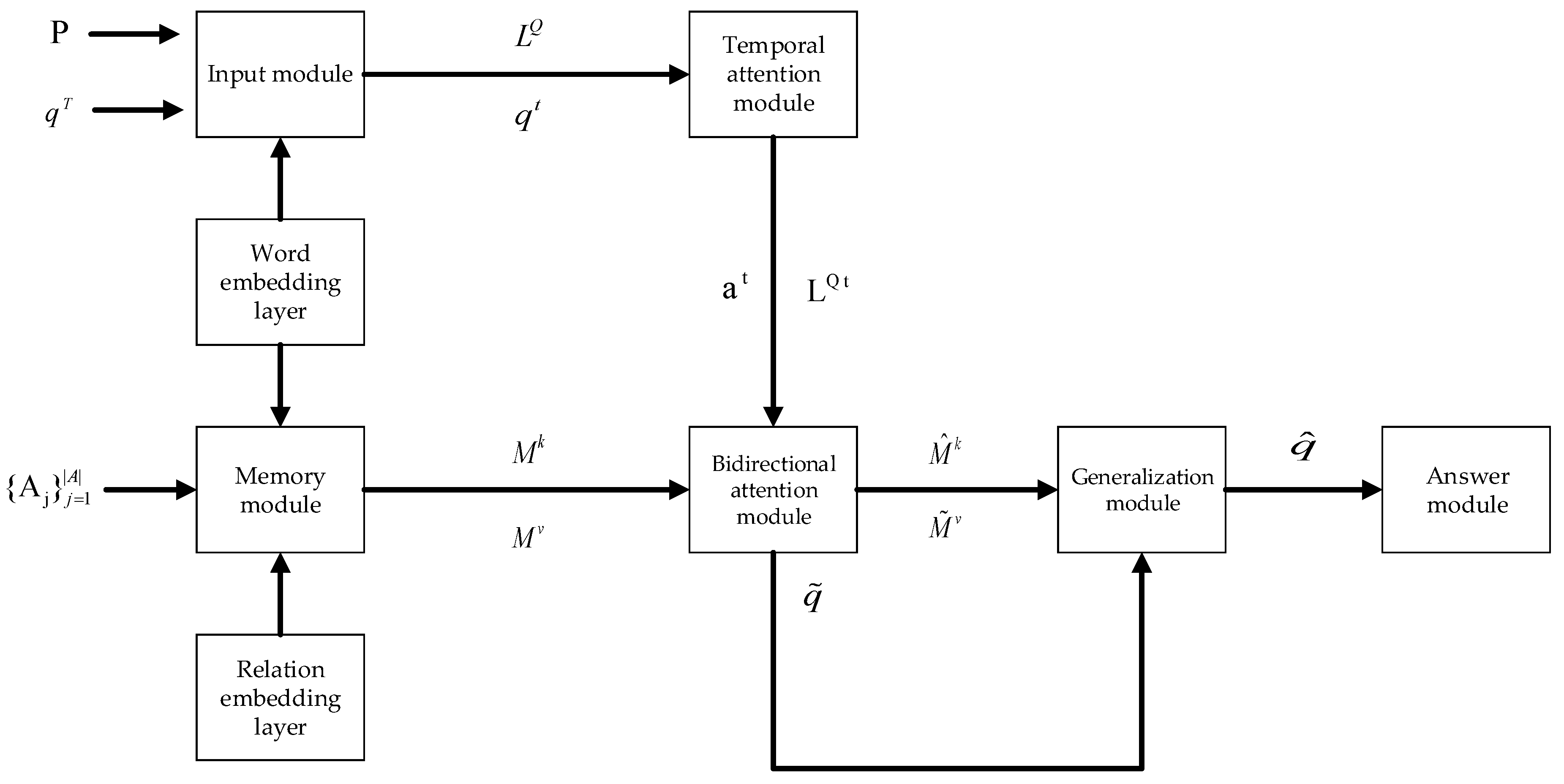
3. Model
3.1. Input Module
3.2. Memory Module
3.3. Temporal Attention Module
3.4. Bidirectional Attention Module
3.5. Generalization Module
3.6. Answer Module
4. Results
4.1. Experimental Datasets
4.2. Experimental Parameters
4.3. Results and Analysis
4.3.1. Results
4.3.2. Ablation Study
4.3.3. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. The Semantic Web, 6th International Semantic Web Conference, 2nd Asian Semantic Web Conference, Busan, Korea, 11–15 November 2007; pp. 722–735. [Google Scholar]
- Google. Freebase Data Dumps. Available online: https://developers.google.com/freebase (accessed on 20 December 2019).
- Sintek, M.; Decker, S. TRIPLE—A Query, Inference, and Transformation Language for the Semantic Web. In Proceedings of the International Semantic Web Conference, Sardinia, Italy, 9–12 June 2002; pp. 364–378. [Google Scholar]
- Xu, K.; Reddy, S.; Feng, Y.; Huang, S.; Zhao, D.; Erk, K.; Smith, N.A. Question Answering on Freebase via Relation Extraction and Textual Evidence. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2326–2336. [Google Scholar]
- Bast, H.; Haussmann, E.; Bailey, J.; Moffat, A.; Aggarwal, C.C.; De Rijke, M.; Kumar, R.; Murdock, V.; Sellis, T.; Yu, J.X. More Accurate Question Answering on Freebase. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management-CIKM ’15, Melbourne, VIC, Australia, 19–23 October 2015; pp. 1431–1440. [Google Scholar]
- Abujabal, A.; Yahya, M.; Riedewald, M.; Weikum, G. Automated Template Generation for Question Answering over Knowledge Graphs. In Proceedings of the 26th International Conference on World Wide Web Companion-WWW ’17 Companion, Perth, Australia, 3–7 April 2017; pp. 1191–1200. [Google Scholar] [CrossRef] [Green Version]
- Berant, J.; Liang, P. Semantic Parsing via Paraphrasing. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 1415–1425. [Google Scholar]
- Kwiatkowski, T.; Zettlemoyer, L.; Goldwater, S.; Steedman, M. Lexical generalization in ccg grammar induction for semantic parsing. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, Scotland, UK, 27–31 July 2011; pp. 1512–1523. [Google Scholar]
- Wong, Y.W.; Mooney, R. Learning synchronous grammars for semantic parsing with lambda calculus. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; pp. 960–967. [Google Scholar]
- Hu, S.; Zou, L.; Yu, J.X.; Wang, H.; Zhao, D. Answering Natural Language Questions by Subgraph Matching over Knowledge Graphs (Extended Abstract). In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–20 April 2018; pp. 1815–1816. [Google Scholar]
- Cai, Q.; Yates, A. Large-scale semantic parsing via schema matching and lexicon extension. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; pp. 423–433. [Google Scholar]
- Jayant Krishnamurthy, J.; Mitchell, M.T. Weakly supervised training of semantic parsers. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; pp. 754–765. [Google Scholar]
- Bordes, A.; Weston, J.; Usunier, N. Open Question Answering with Weakly Supervised Embedding Models. In Formal Aspects of Component Software; Springer-Verlag: New York, NY, USA, 2014; Volume 8724, pp. 165–180. [Google Scholar]
- Hao, Y.; Zhang, Y.; Liu, K.; He, S.; Liu, Z.; Wu, H.; Zhao, J.; Barzilay, R.; Kan, M.-Y. An End-to-End Model for Question Answering over Knowledge Base with Cross-Attention Combining Global Knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, Canada, 30 July–4 August 2017; Volume 1, pp. 221–231. [Google Scholar]
- Chen, Y.; Wu, L.; Zaki, M.J. Bidirectional Attentive Memory Networks for Question Answering over Knowledge Bases. arXiv 2019, arXiv:1903.02188. Available online: https://arxiv.org/abs/1903.02188 (accessed on 20 December 2019).
- Liang, P.; Jordan, M.; Klein, D. Learning dependency- based compositional semantics. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 590–599. [Google Scholar]
- Yih, W.-T.; Chang, M.-W.; He, X.; Gao, J. Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 1321–1331. [Google Scholar]
- Dong, L.; Lapata, M.; Erk, K.; Smith, N.A. Language to Logical Form with Neural Attention. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics (ACL), Berlin, Germany, 7–12 August 2016; pp. 33–43. [Google Scholar]
- Jia, R.; Liang, P.; Erk, K.; Smith, N.A. Data Recombination for Neural Semantic Parsing. In Proceedings of the Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 12–22. [Google Scholar]
- Yavuz, S.; Gur, I.; Su, Y.; Srivatsa, M.; Yan, X. Improving Semantic Parsing via Answer Type Inference. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 149–159. [Google Scholar] [CrossRef]
- Berant, J.; Liang, P. Imitation Learning of Agenda-based Semantic Parsers. Trans. Assoc. Comput. Linguistics 2015, 3, 545–558. [Google Scholar] [CrossRef]
- Xu, K.; Wu, L.; Wang, Z.; Yu, M.; Chen, L.; Sheinin, V. Exploiting Rich Syntactic Information for Semantic Parsing with Graph-to-Sequence Model. arXiv 2018, arXiv:1808.07624. Available online: https://arxiv.org/pdf/1808.07624.pdf (accessed on 20 December 2019).
- Berant, J.; Chou, A.; Frostig, R.; Percy Liang, P. Semantic parsing on freebase from question-answer pairs. In Proceedings of the EMNLP; Conference on Empirical Methods in Natural Language Processing, Chicago, IL, USA, 18–21 October 2013; pp. 1533–1544. [Google Scholar]
- Hu, S.; Zou, L.; Yu, J.X.; Wang, H.; Zhao, D. Answering Natural Language Questions by Subgraph Matching over Knowledge Graphs (Extended Abstract). TKDE 2018, 30, 1815–1816. [Google Scholar]
- Liang, C.; Berant, J.; Le, Q.; Forbus, K.D.; Lao, N.; Barzilay, R.; Kan, M.-Y. Neural Symbolic Machines: Learning Semantic Parsers on Freebase with Weak Supervision. arXiv 2016, arXiv:1611.00020. [Google Scholar]
- Williams, R.J. Simple statistical gradient following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Ben Veyseh, A.P.; Chakraborty, T.; Riedl, M.; Vydiswaran, V. Cross-Lingual Question Answering Using Common Semantic Space. In Proceedings of the TextGraphs-10: the Workshop on Graph-based Methods for Natural Language Processing, San Diego, CA, USA, 17 June 2016; pp. 15–19. [Google Scholar] [CrossRef]
- Yao, X.; Berant, J.; Van Durme, B. Freebase QA: Information Extraction or Semantic Parsing? In Proceedings of the ACL 2014 Workshop on Semantic Parsing, Baltimore, MD, USA, 26 June 2014; pp. 82–86. [Google Scholar] [CrossRef]
- Bordes, A.; Chopra, S.; Weston, J. Question Answering with Subgraph Embeddings. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 615–620. [Google Scholar]
- Jain, S.; Andreas, J.; Choi, E.; Lazaridou, A. Question Answering over Knowledge Base using Factual Memory Networks. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 12–17 June 2016; pp. 109–115. [Google Scholar] [CrossRef]
- Weston, J.; Chopra, S.; Antoine Bordes, A. Memory networks. arXiv 2014, arXiv:1410.3916. Available online: https://arxiv.org/abs/1410.3916 (accessed on 20 December 2019).
- Dong, L.; Wei, F.; Zhou, M.; Xu, K. Question Answering over Freebase with Multi-Column Convolutional Neural Networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 260–269. [Google Scholar] [CrossRef]
- Das, R.; Zaheer, M.; Reddy, S.; McCallum, A.; Barzilay, R.; Kan, M.-Y. Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks. arXiv 2017, arXiv:1704.08384. Available online: https://arxiv.org/abs/1704.08384 (accessed on 20 December 2019).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N. SIG. In Proceedings of the conference on empirical methods in natural language processing, Copenhagen, Denmark, September 2017, Copenhagen, Denmark, September 2017. [Google Scholar] [CrossRef]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional attention flow for machine comprehension. arXiv 2016, arXiv:1611.01603. Available online: https://arxiv.org/abs/1611.01603 (accessed on 20 December 2019).
- Xiong, C.; Zhong, V.; Socher, S. Dynamic coattention networks for question answering. arXiv 2016, arXiv:1611.01604. Available online: https://arxiv.org/abs/1611.01604 (accessed on 20 December 2019).
- Grefenstette, E.; Blunsom, P.; de Freitas, N.; Hermann, M.K. A Deep Architecture for Semantic Parsing, Baltimore. In Proceedings of the ACL 2014 Workshop on Semantic Parsing, chapter A Deep Architecture for Semantic Parsing, Baltimore, MD, USA, 26 June 2014; pp. 22–27. [Google Scholar] [CrossRef]
- Iyyer, M.; Boyd-Graber, J.; Claudino, L.; Socher, R.; Hal Daume III, H. A neural ´ network for factoid question answering over paragraphs. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 633–644. [Google Scholar]
- Yu, L.; Hermann, M.K.; Blunsom, P.; Pulman, S. Deep Learning for Answer Sentence Selection. aXiv 2014, arXiv:1412.1632. Available online: https://arxiv.org/abs/1412.1632 (accessed on 20 December 2019).
- Yih, W.-T.; He, X.; Meek, C. Semantic Parsing for Single-Relation Question Answering. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 643–648. [Google Scholar]
- Fader, A.; Soderland, S.; Etzioni, O. Identifying relations for open information extraction. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, EMNLP ’11, Edinburgh, UK, 30–31 July 2011; pp. 1535–1545. [Google Scholar]
- Qian, Q.; Huang, M.; Lei, J.; Zhu, X.; Barzilay, R.; Kan, M.-Y. Linguistically Regularized LSTM for Sentiment Classification. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, Canada, 30 July–4 August 2017; pp. 1679–1689. [Google Scholar]
- Lu, Q.; Zhu, Z.; Xu, F.; Guo, Q. Chinese Sentiment Classification Method with Bi-LSTM and Grammar Rules. Data Anal. Knowl. Discov. 2019, 3, 99–107. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. Available online: https://arxiv.org/abs/1412.3555 (accessed on 20 December 2019).
- Baudis, P.; Jan Pichl, J. Dataset Factoid Webquestions. Available online: https://github.com/brmson/dataset-factoid-webquestions (accessed on 20 December 2019).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. Available online: https://arxiv.org/abs/1412.6980 (accessed on 20 December 2019).
- Bao, J.; Duan, N.; Yan, Z.; Zhou, M.; Zhao, T. Constraint-based question answering with knowledge graph. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–17 December 2016; pp. 2503–2514. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods (Baseline) | Macro F1 |
|---|---|
| SP-based | |
| Yavuz et al. [20] | 0.516 |
| Bao et al. [48] | 0.524 |
| Yih et al. [19] | 0.525 |
| IR-based | |
| Hao et al. [15] | 0.429 |
| Xu et al. [4] | 0.471 |
| BAMnet and our method | |
| BAMnet | 0.557 |
| Our method | 0.563 |
| Model | Macro F1 |
|---|---|
| Full Model | 0.563 |
| w/o Temporal attention module | 0.556 |
| Category | Questions | Model w/o T-att | Full Model | Correct Answer |
|---|---|---|---|---|
| answer right | What did James K Polk do before he was president? | Governor of Tennessee, … United States Representative | Lawyer | Lawyer |
| Who did Cliff Lee play for last year? | Cleveland Indians | Philadelphia Phillies | Philadelphia Phillies | |
| Where does Michelle Pfeiffer live now? | Santa Ana | Orange County | Orange County | |
| answer rank up | Who was the original voice of Meg Griffin on family guy? | Mila Kunis, Lacey Chabert | Lacey Chabert, Mila Kunis | Lacey Chabert |
| Where was the first microsoft headquarters located? | Washington, Albuquerque, Redmond | Redmond, Albuquerque | Redmond | |
| Who are the senators of New Jersey now? | Frank Lautenberg, … Bob Menendez | Bob Menendez, … John Rutherfurd | Bob Menendez |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, W.; Zhu, Z.; Lu, Q.; Zhang, D.; Guo, Q. Introducing External Knowledge to Answer Questions with Implicit Temporal Constraints over Knowledge Base. Future Internet 2020, 12, 45. https://doi.org/10.3390/fi12030045
Wu W, Zhu Z, Lu Q, Zhang D, Guo Q. Introducing External Knowledge to Answer Questions with Implicit Temporal Constraints over Knowledge Base. Future Internet. 2020; 12(3):45. https://doi.org/10.3390/fi12030045
Chicago/Turabian StyleWu, Wenqing, Zhenfang Zhu, Qiang Lu, Dianyuan Zhang, and Qiangqiang Guo. 2020. "Introducing External Knowledge to Answer Questions with Implicit Temporal Constraints over Knowledge Base" Future Internet 12, no. 3: 45. https://doi.org/10.3390/fi12030045