1. Introduction
Mathematical programing methods such as linear or dynamic programing have been widely used for harvest scheduling since the 1970s [
1]. A number of different scheduling models have been created since then. In the 1990s, the effective use of geographic information systems (GIS) [
2] enabled forest managers and researchers to include spatial requirements in the scheduling process. Without tracking spatial detail, it would be impossible to fulfill certain environmental requirements because the spatial structure of forest ecosystems significantly affects ecological processes [
3]. In addition, contemporary forest certification programs and wildlife habitat models allude to the spatial nature of forest activities. Therefore, forest plans may need to recognize when and where harvest activities are scheduled in order to meet the goals of a forest landowner and to suggest feasible sets of activities.
There are two widely known approaches to model the spatial harvest scheduling problem: area restrictions models (ARM) and unit restrictions models (URM) [
4]. In contrast with ARM, when employing the URM approach, each potential harvest area is exactly predefined by the size of each management unit. In the ARM model, management units can be aggregated to form larger potential harvest areas. These types of restrictions on harvest unit configuration can lead to lower objective function values in some cases [
5]. The ARM model is more flexible with regard to the timing and placement of harvests, and should theoretically produce forest plans with higher objective function values than when using the URM model. However, the ARM model is computationally difficult to use for forest management that is typical for Central Europe, which constrains not only the maximum area but also the maximum width and length of a harvest unit.
When incorporating spatial requirements into the harvest scheduling models, it is often necessary to develop algorithms for specifying adjacency constraints. The traditional algorithm for problems involving the URM model of adjacency consists of defining pairwise constraints for each harvest unit and for all adjacent units. However, this approach could be limited by a maximum possible number of constraints in commercial solving software [
6]. For this reason, many researchers have tried to develop different techniques for the reduction of adjacency constraints number. A branch and bound algorithm is the most classical method of solving URM. There are two directions to reduce the size of URM with adjacency constraints. The first one is the reduction of the number of adjacency constraints, which can, however, lead to lower efficiency of a branch and bound algorithm [
7]. The second one is to reformulate adjacency constraints to increase the efficiency of the branch and bound algorithm [
8]. McDill and Braze [
9] present five groups of adjacency constraints types that encompass 14 constraint types. Each of these types have different levels of reducing the number of constraints, which can lead to different levels of efficiency of the branch and bound algorithm.
Some authors compared the efficiency of different adjacency algorithms (see for example [
10]). However, the efficiency of the algorithms is not the only crucial part of their practical utilization. There is a rapid improvement of commercial mixed integer and integer programming solvers, and hence, many solvers now accept an unlimited number of constraints [
8]. Due to this, the structure of storing spatial data and creating the adjacency constraints can be the most limiting factor for practical use of decision support systems (DSS) today.
The spatial structure of forest stands or harvest units can be described using graph theory, which is applied in many fields of human activities [
11,
12,
13]. A graph representing the adjacencies of stands or units is undirected, unweighted and can also be disconnected [
13] depending on the real situation in a forest area. Although graphical representation by way of a set of vertices and edges is the most well known approach, it is not a suitable method for storing graph data in computers. For this purpose, the most common way of data storing is an adjacency matrix [
11]. Another common way of data storing is an adjacency list [
14]. These two graph representations have many differences that could affect the total computing time of spatially dependent forest DSSs.
The main difference between the data storing approaches is in the time of adding or deleting one edge from the vertex. In the case of the adjacency list, this time is equal to
where
is the length of the list containing the successors of vertex
. In the case of the adjacency matrix, the time needed for adding or deleting one edge from the vertex is equal to
where
is the number of vertices. This can be effective only for a very dense graph where the total number of edges
[
14]. However, large numbers of adjacency relations are not very common in real forest structures [
7].
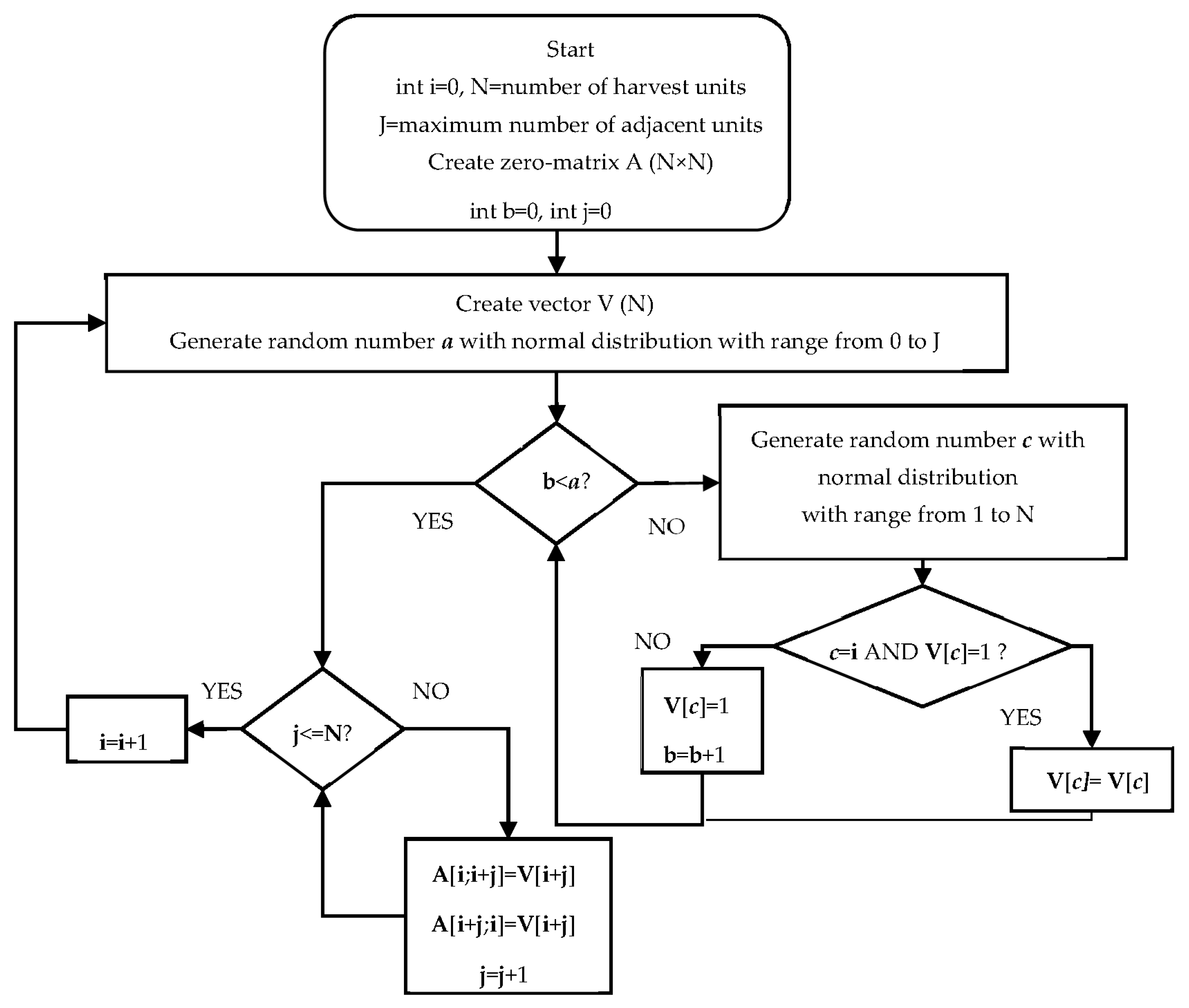
The goal of this paper is to compare the time efficiency of employing the two concepts of adjacency representation, which differ in the structure of data storage and the algorithm suitable for creating constraints. The first concept is the development of conventional pairwise constraints from an adjacency list. The second concept is the development of an adjacency matrix using three analytical algorithms described by Yoshimoto and Brodie [
6]. These algorithms are based on simple linear algebraic operations. The results of these comparisons should confirm or refute the following two assumptions for each selected type of adjacency constraints: (1) the number of harvest units affects the time needed to solve the model; and (2) the number of adjacent harvest units affects the time required to solve the model.
3. Results
The final results of the analysis are presented in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10. The calculated average values of the solution time required, the final gap tolerance characteristics, and the number of solved instances in the case of the 60 s and 120 s solving time limit are presented in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 (100, 200, 300, 400 and 500 harvest units) and
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10 (100, 200, 300, 400 and 500 harvest units), respectively.
In
Table 1, we see that nearly all (9 of 10) attempts to solve the problem using pairwise constraints were successful for all assumptions of the number of adjacent neighbors. This problem only involved 100 stands, yet several formulations using the TAM, RAM, and RTAM adjacency matrices were unable to be solved in 60 s. From
Table 2,
Table 3,
Table 4 and
Table 5, we see that the different constraint formulations prevent the problem described in this research from being solved within 60 s when the number of stands assumed increases. In this case, when the number of stands increased to 200, none of the formulations with 5 adjacent stands on average were able to be solved in 60 s.
Table 3 suggests that a problem with 3 or more (on average) adjacency relationships associated with 300 stands is not solvable in 60 s using any of the methods employed in this research.
Table 4, when 400 stands are modeled, suggests that only problems with 2.5 adjacent stands (on average) can be solved in 60 s. The results in
Table 5 are similar, when 500 stands are modeled, yet the problems with pairwise constraints were the only ones somewhat consistently solved in 60 s. In this case, however, only 5 of 10 attempts were solved. In each case, the smallest optimality gap (on average) was observed when using the pairwise constraints.
In
Table 6, we see that all 10 attempts to solve the problem using pairwise constraints were successful for all assumptions of the number of adjacent neighbors. This problem only involved 100 stands, yet several formulations using the TAM, RAM, and RTAM adjacency matrices were unable to be solved in 120 s. From
Table 7 onward, we begin to see that the different constraint formulations prevent the problem described in this research from being solved within 120 s when the number of stands assumed increases. Here, when the number of stands increased to 200, none of the formulations with 5 adjacent stands on average were able to be solved in 120 s. In
Table 8, one can see that the pairwise constraint formulation was able to solve the problem (1 of 10 times) in 120 s when 300 stands were modeled and the average number of adjacent stands was 3.5 or 4. The other constraint formulations seemed to require more than 120 s in these cases. In
Table 9, one can see that the pairwise constraint formulation was the only one of the four tested that was able to solve the problem (3 of 10 times) in 120 s when 400 stands were modeled and the average number of adjacent stands was 3.
Table 10 suggests that a problem with 3 or more (on average) adjacency relationships associated with 500 stands is not solvable in 120 s, using any of the methods employed in this research.
It is clear from the tables that the complexity of the model instances increases not only with the number of harvest units but also with the average number of the adjacent harvest units. This fact can be seen in the behavior of all three measured characteristics for all four different types of adjacency constraints. It can also be proclaimed that with the increasing complexity of the model instances, the solution time and the final gap tolerance (the lower the gap tolerance, the better the result) also increase, while the number of model instances solved under the time limit decreases.
The calculated standard deviations and coefficients of variation of solving time for all combinations are presented in
Table 11 and
Table 12. One can observe that the higher complexity of model instance is coupled with higher standard deviation and coefficient of variation of solving time. Unfortunately, the lower number of solved model instances in some cases may cause discredit of the calculated values. In addition, it is shown in previous tables that the chances to solve the various models in real time decrease with increases in the model complexity. The results are not surprising, since a time limit applied to more complex models does not allow the branch and bound algorithm to sufficiently search the solution space. Therefore, the solutions reported after 60 or 120 s are expectedly sub-optimal, leading to greater variation in the sample objective function values.
Only in the case of very simple spatial structures (where the average number of adjacent units ranges from 0.5 to 2.0 units), all four types of adjacency constraints had the same effect on the solving time, gap tolerance, and number of solved instances within the time limit (
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10). These very simple spatial structures can represent forest management areas with very low density of mature forests stands.
The pairwise adjacency constraints were more successful in solving most instances than other types of adjacency constraints. Even in the cases when the average time of solving was greater, the final gap tolerance was lower or the number of solved instances within the time limit was higher. Even in spite of the really low number of constraints obtained by TAM, RAM and RTAM (
Table 13), the pairwise constraints were more successful in solving these problems in a timely manner.
4. Discussion
Without adjacency restrictions represented by adjacency constraints in a harvest scheduling model, a forest manager cannot be sure that the results of such a model are feasible in real management situations. However, these constraints can dramatically complicate the process of developing a forest plan [
10], especially in the case of small-scale unit restriction models. In our case, the maximum area of each harvest unit was not to exceed 2 hectares (yet could be 1 hectare in some countries), which represents a very common planning situation in Central Europe. In other areas of the world, this scale of problem could be similar to the arrangement and scheduling of group selection harvest patches, where the patches should not touch within a given time frame in order to maintain the patch size suggested in the silvicultural system [
16]. In either case, the small-scale unit restriction problem is a microcosm of larger-scale adjacency issues that involve restricting the maximum final harvest size (e.g., 50 ha) within a given green-up period.
At the beginning of the computer-based spatial harvest scheduling in 1990’s, it was possible to solve only small scheduling problems (
i.e., small number of decision variables and constraints) because of the limitations of personal computers and solvers. However, increasing computing speeds and improved commercial solvers enable us to solve larger and larger problems [
8]. It is generally known that the power of computers has been growing exponentially, and solvers have also been dramatically improved. In connection with this, the use of forest harvest scheduling DSSs has also dramatically increased. For this reason, researchers should periodically re-analyze different practical and theoretical aspects of harvest scheduling models. This service to society allows knowledge of the capabilities of forest planning systems to grow and to become adapted within forest management organizations.
Few scientific papers have dealt with the effect of reducing the number of adjacency constraints by different methods (see for example [
6,
7,
17]). The number of adjacency constraints can be significantly reduced as is confirmed and presented in this paper. This is especially true in the case of large problems with complex spatial structures. As the number of constraints is reduced within a complex planning problem, one would hope that the time required to solve the problem would also be reduced. We have confirmed this hypothesis as well for the problem instances that were examined in this work. Therefore, our contribution incrementally adds to the body of science associated with applied optimization in this respect.
One of the first papers dealing with measuring the efficiency of adjacency constraints was presented by Murray and Church [
18]. They tested several different types of adjacency constraints including pairwise constraints and TAM constraints presented above. The results of their analyses showed that TAM had the lowest efficiency, which was also confirmed in this paper. Tóth
et al. [
19] explored strengthening procedures for improving adjacency formulations of the area restriction forest planning problem. These efforts underscore the need to expand science in this area through the development and analysis of new methods for addressing practical forest management problems. Our work complements and adds to the growing body of science, yet due to the various types of forest management problems encountered around the world, by no means represents the final word on the subject. As the expectations of society evolve, the decision space within which forest managers can operate changes. Therefore, we expect novel and creative methods for combinatorial problems will continue to be assessed in association with efforts aimed at sustainable forest management.
The solving time and the final gap tolerance were also analyzed by McDill and Braze [
10]. The authors randomly generated hypothetical forests of four different age structures. They tested three types of adjacency constraints: pairwise constraints, Type I constraints (encompassing several methods leading to the same results and proposed by many authors) and NOAM constraints based on the adjacency matrix proposed by Murray and Church [
20]. The authors achieved the best results with Type I constraints. This fact could not be confirmed or confuted by the results presented here, although the algorithm based on the adjacency matrix had longer solution time as was presented before in the Results section. This means that adjacency matrix algorithms do not have to be an optimal approach for defining the adjacency relationships. On the other hand, the authors used another solver (CPLEX
® (Armonk, NY, USA)) and also a different type of computer, of which the latter is already outdated. It is questionable if the results would be the same with currently used computers and software.
The solving time of harvest scheduling models is dependent not only on the inherent spatial forest structure, but also on the number of planning periods, the length of each period, other types of constraints related to the planning problem (e.g., a type of harvest flow constraints), the computer employed, the software employed and its settings [
21]. The input age structure can affect the model complexity [
9]. The evaluation of the effects of all these aspects was not the aim of this study. We focused on the types of adjacency constraints, which are used in the DSS called Optimal [
22,
23]. Other mentioned aspects should be analyzed individually in more detail.
As we stated before, one aspect of different types of adjacency constraints that has not been studied yet, though it has an impact on real-life scheduling situations, is their consumption of computer random-access memory. The consumption of memory can limit using DSSs aimed at spatial harvest scheduling, for instance Optimal or Heureka [
24]. In these cases, adjacency constraints can be created directly from a database, in which the spatial information is saved in the form of pairwise adjacency constraints. However, all spatial information must be uploaded to the computer memory at first, and kept in the memory during the algebraic process when using the presented analytical algorithms. Therefore, the amount of memory used to manage the data may take away memory available to a solver in developing a forest plan. This may have varying effects on the ability and time required to solve a problem, and likely depends on the data, computer, and software at the disposal of the forest planner.
Following the assumptions we stated in the Introduction, we can confirm that the number of harvest units affects the solving time of model instances, although the number of adjacent units has a greater effect. On the basis of the presented results, we can recommend using the pairwise type of adjacency constraints for solving unit restriction harvest scheduling models.







{kind=link}