
Evaluation of Image-Assisted Forest Monitoring: A Simulation

Abstract
:1. Introduction
- Yt = the value of interest at the beginning of year t;
- Lt = growth in the value of interest on live trees during year t;
- Et = the value of interest on live trees as they enter the population during year t;
- Mt = the value of interest on trees as they die during year t and;
- Ht = the value of interest on trees as they are harvested during year t.
2. Methods
2.1. Simulated Population
2.2. Sampling Simulations

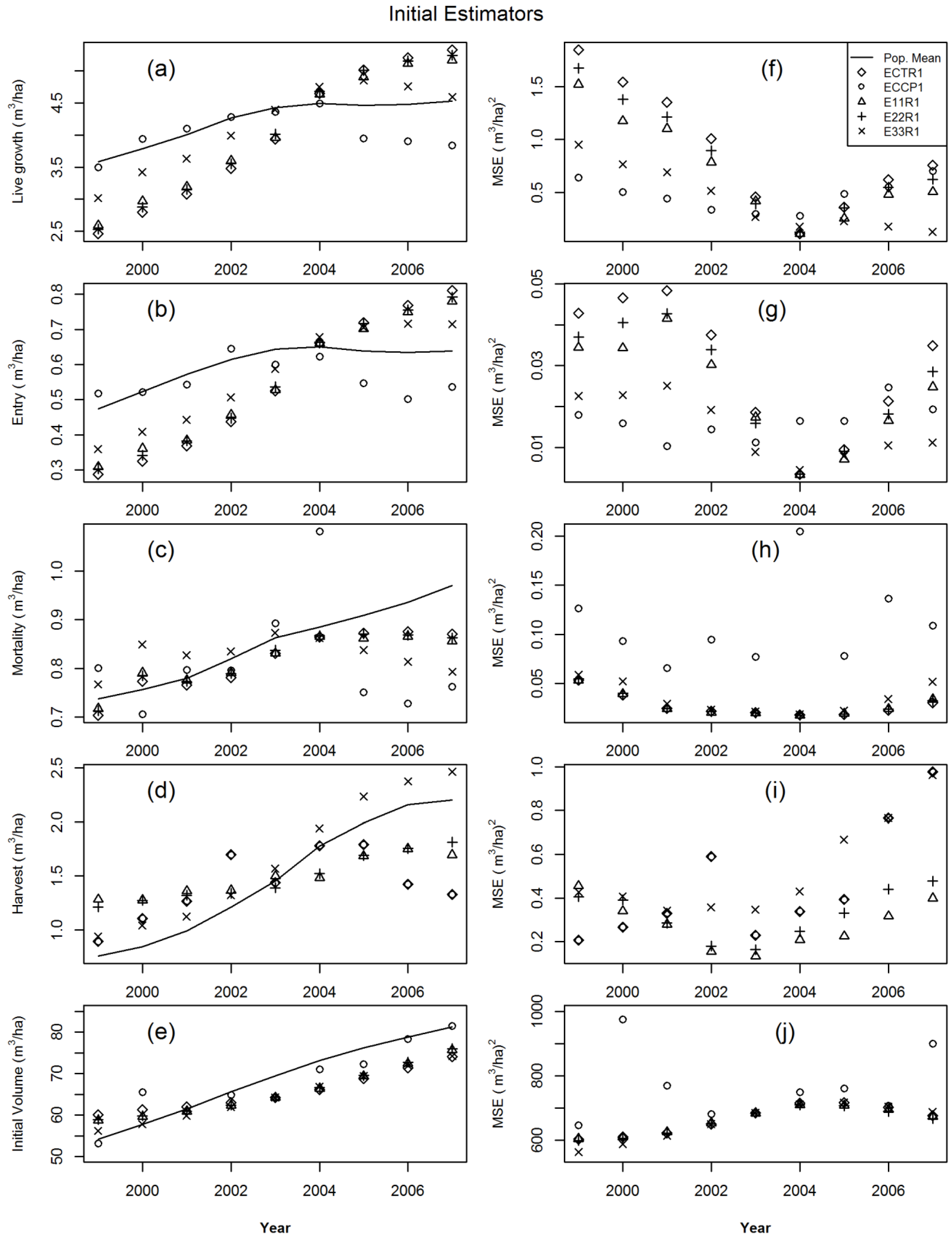{kind=link}
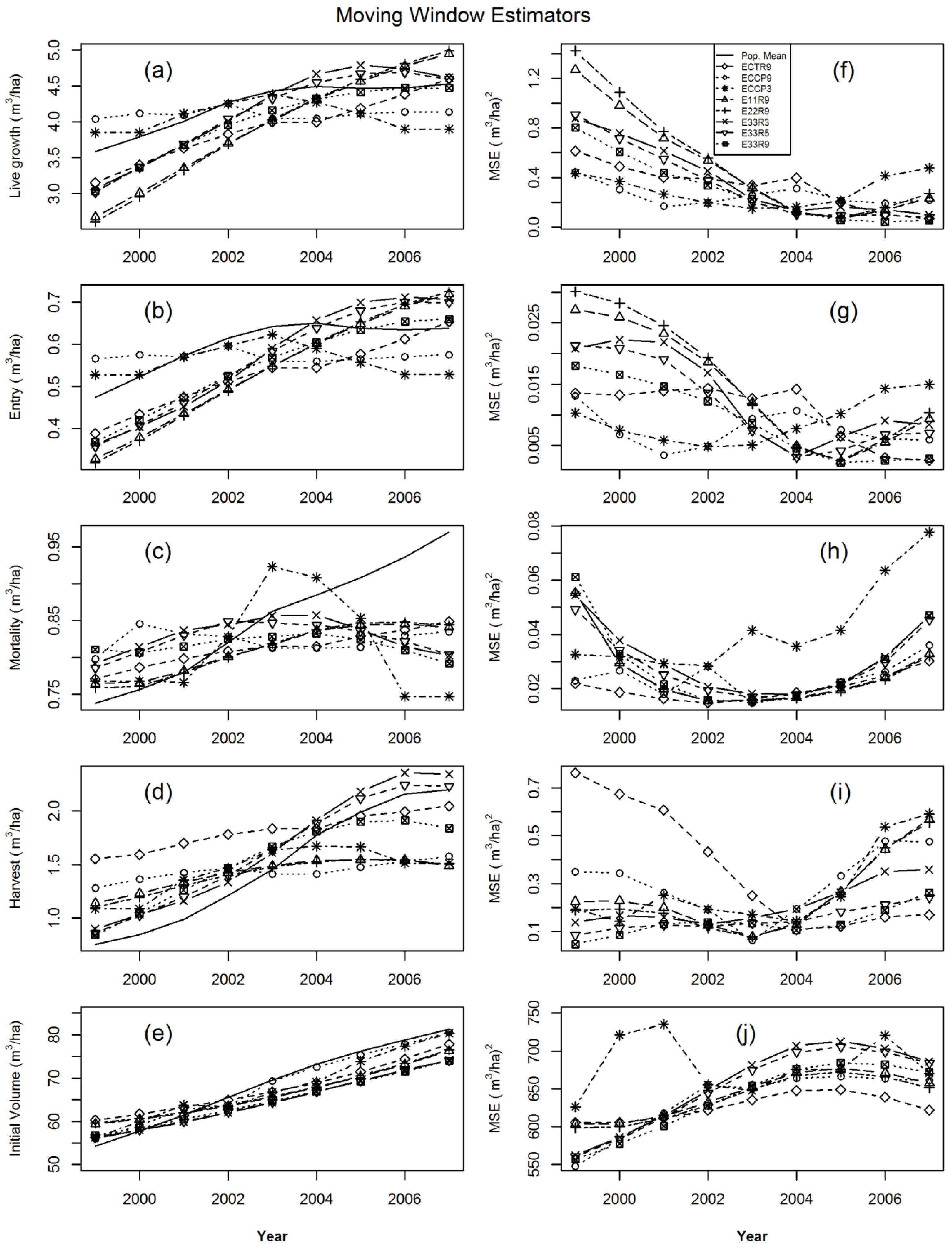{kind=link}
| Component | Statistic | Year | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | ||
| Volume | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.42 | 1.89 | 4.33 | 7.11 | 9.86 | 12.56 | 14.84 | 16.47 | 17.58 | 18.59 | 19.17 | 19.59 | |
| Median | 9.91 | 14.93 | 19.98 | 25.31 | 30.71 | 35.84 | 41.21 | 45.78 | 49.51 | 53.05 | 56.53 | 59.07 | 61.52 | 63.46 | |
| Mean | 50.53 | 54.21 | 57.79 | 61.45 | 65.60 | 69.50 | 73.21 | 76.16 | 78.78 | 81.30 | 83.62 | 85.70 | 87.46 | 89.00 | |
| 3rd Quartile | 77.83 | 83.76 | 89.56 | 95.08 | 101.26 | 106.63 | 110.80 | 113.99 | 116.78 | 120.38 | 123.21 | 126.65 | 130.25 | 132.89 | |
| Maximum | 813.34 | 813.36 | 814.69 | 815.08 | 816.37 | 818.58 | 821.72 | 825.90 | 831.01 | 837.24 | 844.48 | 852.75 | 862.01 | 872.21 | |
| Live Growth | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.29 | 0.66 | 0.73 | 0.66 | 0.50 | 0.22 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 1.19 | 1.49 | 2.02 | 2.49 | 3.04 | 3.36 | 3.43 | 3.40 | 3.36 | 3.20 | 2.35 | 0.73 | 0.00 | 0.00 | |
| Mean | 3.57 | 3.59 | 3.79 | 4.01 | 4.27 | 4.43 | 4.49 | 4.47 | 4.48 | 4.53 | 4.13 | 3.51 | 2.75 | 1.71 | |
| 3rd Quartile | 5.30 | 5.39 | 5.70 | 6.03 | 6.35 | 6.50 | 6.65 | 6.68 | 6.72 | 6.94 | 6.56 | 5.65 | 3.94 | 0.00 | |
| Maximum | 52.52 | 50.58 | 66.35 | 58.15 | 48.79 | 39.41 | 33.73 | 35.04 | 39.47 | 43.90 | 44.57 | 41.38 | 39.08 | 46.09 | |
| Entry | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.04 | 0.11 | 0.17 | 0.22 | 0.25 | 0.26 | 0.24 | 0.22 | 0.18 | 0.08 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.45 | 0.47 | 0.52 | 0.57 | 0.62 | 0.64 | 0.65 | 0.64 | 0.63 | 0.64 | 0.57 | 0.47 | 0.35 | 0.22 | |
| 3rd Quartile | 0.46 | 0.50 | 0.58 | 0.64 | 0.72 | 0.76 | 0.78 | 0.75 | 0.72 | 0.67 | 0.56 | 0.38 | 0.16 | 0.00 | |
| Maximum | 21.21 | 21.60 | 29.03 | 27.63 | 17.04 | 12.20 | 9.91 | 11.56 | 13.28 | 15.23 | 16.71 | 15.15 | 15.01 | 14.90 | |
| Mortality | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.06 | 0.06 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.74 | 0.74 | 0.76 | 0.78 | 0.82 | 0.86 | 0.88 | 0.91 | 0.94 | 0.97 | 0.90 | 0.77 | 0.60 | 0.38 | |
| 3rd Quartile | 0.21 | 0.28 | 0.39 | 0.46 | 0.55 | 0.65 | 0.71 | 0.73 | 0.72 | 0.69 | 0.48 | 0.20 | 0.00 | 0.00 | |
| Maximum | 108.46 | 93.27 | 78.00 | 77.97 | 78.57 | 78.77 | 79.11 | 79.44 | 79.54 | 80.31 | 80.39 | 80.51 | 80.83 | 80.94 | |
| Harvest | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.63 | 0.75 | 0.84 | 0.99 | 1.21 | 1.45 | 1.78 | 1.99 | 2.16 | 2.20 | 1.90 | 1.55 | 1.05 | 0.55 | |
| 3rd Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Maximum | 341.31 | 373.88 | 352.31 | 358.61 | 447.97 | 466.30 | 466.29 | 462.06 | 465.60 | 483.98 | 485.19 | 498.90 | 488.34 | 510.38 | |
| Component | Error Structure | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||||
| b | d | b | d | b | d | b | d | |
| Initial Volume | 1.01 | 0.10 | 1.00 | 0.03 | 1.00 | 0.05 | 0.99 | 0.10 |
| Entry | 1.01 | 0.10 | 1.00 | 0.03 | 1.00 | 0.05 | 0.99 | 0.10 |
| Live Growth | 1.01 | 0.10 | 0.99 | 0.03 | 0.98 | 0.05 | 0.95 | 0.10 |
| Mortality | 1.01 | 0.10 | 0.99 | 0.03 | 0.98 | 0.05 | 0.95 | 0.10 |
| Harvest | 1.01 | 0.10 | 0.99 | 0.03 | 0.98 | 0.05 | 0.95 | 0.10 |
2.3. Moving-Window Mean of Ratios Estimator
- the number of plots observing growth in year t;
- the product of portion of year t growing season observed by plot i and the portion of plot i area within the area of interest and;
- the value of component C observed on plot i, assignable to year t.
2.4. Incorporating Image Change Estimates
2.4.1. Estimation under A1
2.4.2. Estimation under A2
2.4.3. Estimation under A3
2.5. Compatibility and the Estimation of Initial Volume
2.6. Estimation Systems
- ECCP1 = CM for all change components and for initial annual volume,
- ECTR1 = CM for harvest, CT for the other change components, for annual volume,
- E11R1 = ChA1 for harvest, CoA1 for the other change components, for annual volume,
- E22R1 = ChA2 for harvest, CoA2 for the other change components, for annual volume,
- E33R1 = ChA3 for harvest, CoA3 for the other change components, for annual volume,
- ECCP3 = 3-year moving window on ECCP1,
- ECCP9 = 9-year moving window on ECCP1,
- ECTR9 = 9-year moving window on ECTR1,
- E11R9 = 9-year moving window on E11R1,
- E22R9 = 9-year moving window on E22R1,
- E33R3 = 3-year moving window on E33R1,
- E33R5 = 5-year moving window on E33R1 and,
- E33R9 = 9-year moving window on E33R1.
2.7. Estimator Evaluation
3. Results


4. Discussion and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tomppo, E.; Schadauer, K. Harmonization of national forest inventories in Europe: Advances under COST Action E43. For. Sci. 2012, 58, 191–200. [Google Scholar] [CrossRef]
- Roesch, F.A. An alternative view of continuous forest inventories. For. Sci. 2008, 54, 455–464. [Google Scholar]
- Roesch, F.A.; Van Deusen, P.C. Time as a Dimension of the Sample Design in National-Scale Forest Inventories. For. Sci. 2013, 59, 610–622. [Google Scholar] [CrossRef]
- Van Deusen, P.C.; Roesch, F.A. Estimating forest conversion rates with annual forest inventory data. Can. J. For. Res. 2009, 39, 1993–1996. [Google Scholar] [CrossRef]
- Roesch, F.A.; Van Deusen, P.C. Monitoring forest/non-forest land use conversion rates with annual inventory data. For. Int. J. For. Res. 2012, 85, 391–398. [Google Scholar] [CrossRef]
- Roesch, F.A. Toward robust estimation of the components of forest population change. For. Sci. 2014, 60, 1029–1049. [Google Scholar] [CrossRef]
- Eriksson, M. Compatible and time-additive change component estimators for horizontal-point-sampled data. For. Sci. 1995, 41, 796–822. [Google Scholar]
- Roesch, F.A. The components of change for an annual forest inventory design. For. Sci. 2007, 53, 406–413. [Google Scholar]
- Bechtold, W.A.; Patterson, P.L. The Enhanced Forest Inventory and Analysis Program-national Sampling Design and Estimation Procedures; U.S. Department of Agriculture Forest Service Southern Research Station: Asheville, NC, USA, 2005; Available online: http://www.srs.fs.fed.us/pubs/20371 (accessed on 16 July 2015).
- McCollum, J.M. Honeycombing the icosahedron and icosahedroning the sphere. In Proceedings of the second annual Forest Inventory and Analysis Symposium, Salt Lake City, UT, USA, 17–18 October 2000; Reams, G.A., McRoberts, R.E., Van Deusen, P.C., Eds.; USDA Forest Service Southern Research Station: Asheville, NC, USA, 2001; pp. 25–31. Available online: http://www.srs.fs.fed.us/pubs/4527 (accessed on 16 July 2015). [Google Scholar]
- Van Deusen, P.C. Alternatives to the Moving Average. In Proceedings of the second annual Forest Inventory and Analysis Symposium, Salt Lake City, UT, USA, 17–18 October 2000; Reams, G.A., McRoberts, R.E., Van Deusen, P.C., Eds.; USDA Forest Service Southern Research Station: Asheville, NC, USA, 2001; pp. 90–93. Available online: http://www.srs.fs.fed.us/pubs/4537 (accessed on 16 July 2015). [Google Scholar]
- Roesch, F.A.; Steinman, J.R.; Thompson, M.T. Annual Forest Inventory Estimates Based on the Moving Average. In Proceedings of the third annual Forest Inventory and Analysis Symposium, Traverse City, MI, USA, 17–19 October 2001; McRoberts, R.E., Reams, G.A., Van Deusen, P.C., Moser, J.W., Eds.; USDA Forest Service North Central Research Station: St. Paul, MN, USA, 2003; pp. 21–30. Available online: http://www.nrs.fs.fed.us/pubs/gtr/gtr_nc230.pdf#page=27 (accessed on 16 July 2015). [Google Scholar]
- Van Deusen, P.C. Issues Related to Panel Creep. In Proceedings of the third annual Forest Inventory and Analysis Symposium, Traverse City, MI, USA, 17–19 October 2001; McRoberts, R.E., Reams, G.A., Van Deusen, P.C., Moser, J.W., Eds.; USDA Forest Service North Central Research Station: St. Paul, MN, USA, 2003; pp. 31–35. Available online: http://www.nrs.fs.fed.us/pubs/gtr/gtr_nc230.pdf#page=37 (accessed on 16 July 2015). [Google Scholar]
- Westfall, J.A.; Frieswyk, T.; Griffith, D.M. Implementing the Measurement Interval Midpoint Method for Change Estimation. In Proceedings of the Eighth Annual Forest Inventory and Analysis Symposium, 16–19 October 2006; Monterey, C.A., McRoberts, R.E., Reams, G.A., Van Deusen, P.C., Williams, W.H., Eds.; USDA Forest Service: Washington, DC, USA, 2009; pp. 231–236. Available online: http://www.nrs.fs.fed.us/pubs/gtr/gtr_wo079/gtr_wo079_231.pdf (accessed on 16 July 2015). [Google Scholar]
- Raj, D. Sampling Theory; McGraw-Hill: New York, NY, USA, 1968. [Google Scholar]
- Walton, G.S.; DeMars, C.J. Empirical methods in the evaluation of estimators. In USDA Forest Service Research Paper NE-272; USDA Forest Service; Northeastern Forest Experiment Station: Upper Darby, PA, USA, 1973; Available online: http://www.fs.fed.us/ne/newtown_square/publications/research_papers/pdfs/scanned/OCR/ne_rp272.pdf (accessed on 16 July 2015).
- Cassel, C.M.; Särndal, C.E.; Wretman, J.H. Foundations of Inference in Survey Sampling; John Wiley & Sons: New York, NY, USA, 1977. [Google Scholar]
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley & Sons: New York, NY, USA, 1977. [Google Scholar]
- Li, M.; Huang, C.; Zhu, Z.; Shi, H.; Lu, H.; Peng, S. Assessing rates of forest change and fragmentation in Alabama, USA, using the vegetation change tracker model. For. Ecol. Manag. 2009, 257, 1480–1488. [Google Scholar] [CrossRef]
- Webb, J.; Brewer, C.K.; Daniels, N.; Maderia, C.; Hamilton, R.; Finco, M.; Megown, K.; Lister, A.J. Image-based change estimation for land cover and land use monitoring. In Moving from Status to Trends: Forest Inventory and Analysis (FIA) Symposium 2012; Morin, R.S., Liknes, G.C., Eds.; USDA Forest Service Northern Research Station: Newtown Square, PA, USA, 2012; pp. 46–53. Available online: http://www.nrs.fs.fed.us/pubs/gtr/gtr-nrs-p-105papers/08webb-p-105.pdf (accessed on 16 July 2015).
- Coulston, J.W.; Reams, G.A.; Wear, D.N.; Brewer, C.K. An analysis of forest land use, forest land cover and change at policy-relevant scales. Forestry 2014, 87, 267–276. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roesch, F.A.; Coulston, J.W.; Van Deusen, P.C.; Podlaski, R. Evaluation of Image-Assisted Forest Monitoring: A Simulation. Forests 2015, 6, 2897-2917. https://doi.org/10.3390/f6092897
Roesch FA, Coulston JW, Van Deusen PC, Podlaski R. Evaluation of Image-Assisted Forest Monitoring: A Simulation. Forests. 2015; 6(9):2897-2917. https://doi.org/10.3390/f6092897
Chicago/Turabian StyleRoesch, Francis A., John W. Coulston, Paul C. Van Deusen, and Rafał Podlaski. 2015. "Evaluation of Image-Assisted Forest Monitoring: A Simulation" Forests 6, no. 9: 2897-2917. https://doi.org/10.3390/f6092897