1.1. Context and Problem
Among the multitude of information that forest inventories are expected to provide [
1], knowledge about available standing timber volume on the national, regional, as well as enterprise level is still of high interest. Since on these spatial levels, a full census is too cost-intensive and, in most cases, even practically unfeasible, a broad range of methods in the framework of sampling theory has been developed and applied to estimate this quantity [
2,
3,
4]. The strength of forest inventory methods relying on design-based procedures is that (at least asymptotically) unbiased point and variance estimates can be obtained, and this without assuming the applied prediction models to be correct in the classical statistical (model-dependent) sense. An important advancement in increasing this accuracy without, at the same time, increasing the number of costly terrestrial samples has been achieved by combining terrestrial samples with auxiliary information provided by remote sensing data, so-called two-phase or double-sampling procedures [
2,
3,
5,
6]. In this context, especially airborne laser scanning (ALS) data have proven to provide a high degree of information for timber volume estimation [
7,
8,
9]. It has recently been shown that the efficiency of two-phase sampling can be further increased by extending this procedure to stratification [
10,
11] or by using part of the auxiliary information exhaustively when remote sensing data are covering the entire inventory area [
12]. The two-phase procedure is thus not restricted to large forest areas, but has also been applied in the context of small area estimation [
13]. Given that the number of terrestrial samples in the small area is sufficiently large (
i.e., one is not restricted to the application of synthetic estimations), even for small areas the accuracy specifications are ensured to be unbiased [
14]. While these forest inventory methods have the advantage of supplying reliable accuracy specifications for their estimates, they do not provide information about the spatial distribution of the estimated quantity. However, the availability of spatially explicit stand information is of prime importance for efficiently locating forest management operations.
Accordingly, mapping the spatial distribution of standing timber volume has been the subject of various recent studies. The statistical models that have been used for mapping can be divided into parametric models, particularly linear regression models [
15,
16], and non-parametric models [
17,
18,
19]. Among the non-parametric models,
k‑NN imputation has become increasingly popular due to its simplicity and easy implementation [
20].
k‑NN approaches have been investigated and applied in the model-dependent framework of forest inventory with promising results [
21] and have also been used for the mapping of various forest attributes [
22,
23,
24]. Haara and Kangas [
25] compared the
k‑NN method to linear regression in a simulation study and found the two methods to perform similarly well. Especially in the case where the relationship between observations and the auxiliary variable followed a linear trend, the regression model performed better than the
k‑NN approach. Fehrmann,
et al. [
26] came to a similar result when comparing linear and linear mixed effect models to an instance-based
k‑NN approach for single-tree biomass estimation. Also in their case, the performance of the
k‑NN approach and the linear mixed model only differed marginally, and both methods were slightly superior to simple linear regression. On the other hand, they also confirmed that the application of
k‑NN methods can be an effective and promising method if no
a priori knowledge about the relationship between target and auxiliary variable(s) exists, particularly if the relationship is considered to be complex due to random and interaction effects. However, they also raised the question of whether a
k‑NN approach should be used in situations where the functional relationship among variables is approximately known. Additionally, the performance of
k‑NN estimation and its potential superiority to already existing methods has also been investigated in the design-based framework of forest inventory [
27,
28]. While in several cases, the proposed
k‑NN estimator of the population mean achieved smaller errors than the Horwitz-Thompson estimator [
3], the result also turned out to be dependent on the underlying model of the investigated population.
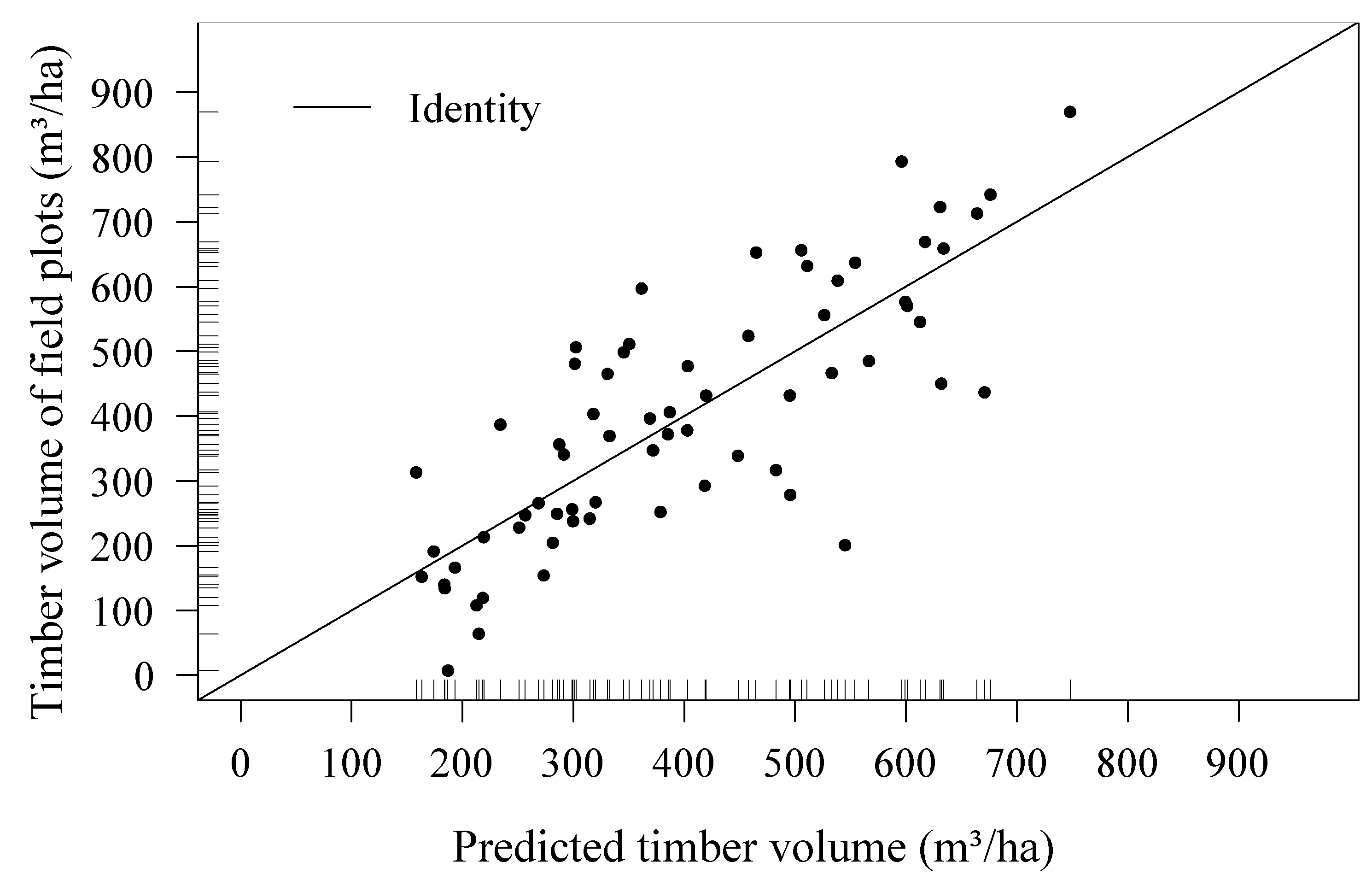
Irrespective of the model choice, a core issue of these mapping approaches is to characterize the accuracy of the resulting maps. If map predictions are made on a continuous prediction scale, the map precision is commonly characterized by quality parameters of the applied prediction model, such as the cross-validated root-mean-squared error (RMSE) and the coefficient of determination (
R2). However, the derived map predictions are often visualized using constant class intervals in order to provide users, such as forest managers, with a better visual interpretation of the map. In this case, it could be misleading to still use the previously mentioned RMSE and
R2 in order to provide information about the accuracy of resulting timber volume classes. This is because these parameters only describe the overall model performance on a continuous prediction scale, but do not quantify the accuracy of individual timber volume ranges (classes). A more appropriate validation strategy would then be to adopt the concept of confusion matrices, which provides a differentiated accuracy assessment (user’s and producer’s accuracy) for each particular volume class, as well as the complete mapping system. Franco-Lopez, Ek and Bauer [
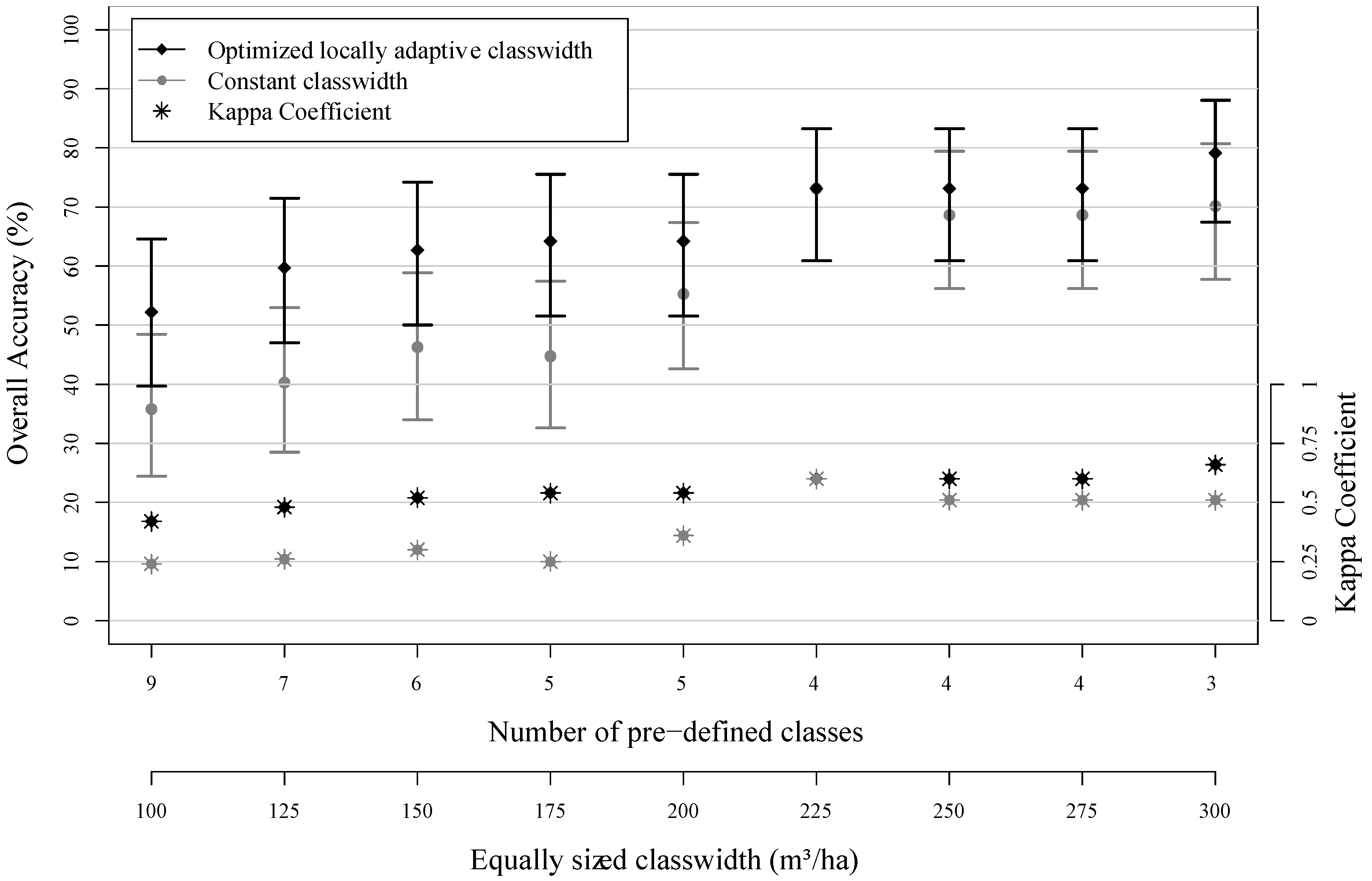
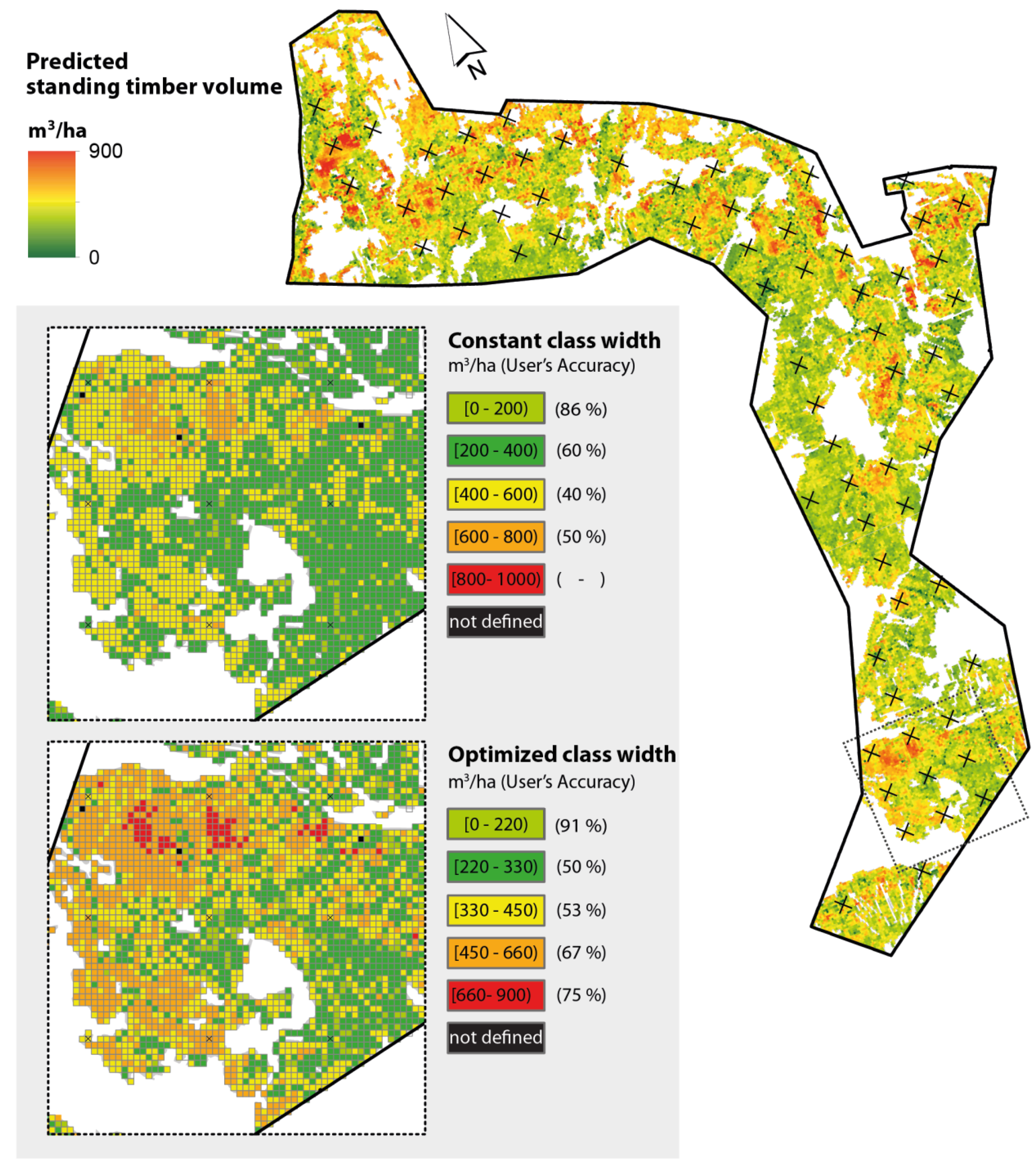
17], for example, used these metrics. However, their classification scheme of constant class intervals exhibited a strong gradient of degrading class accuracies towards higher volume classes (most likely due to saturation effects in the remote sensing data). Such a severe gradient in class accuracies, however, reveals the following problems: (1) it implies that the chosen classification scheme with constant class intervals is not accounting for the fact that the performance of the underlying model may not be constant across the entire volume range; and (2) it severely hampers the usability of the maps in forest practice due to the high uncertainty within higher timber volume classes.
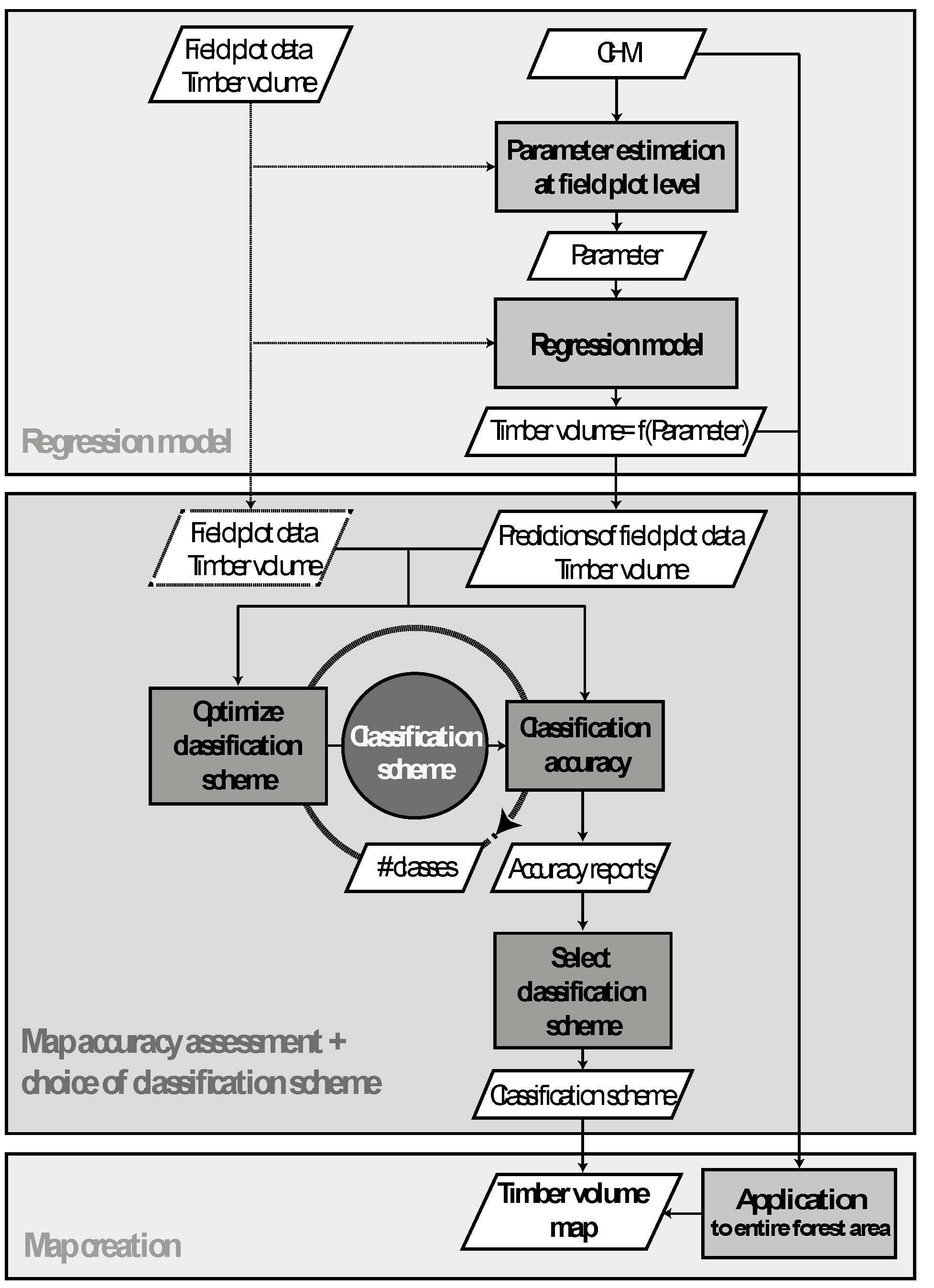
The motivation of this study was to improve the usability of volume maps for forest management operations by avoiding classification schemes of this kind. We hypothesized that this can be achieved by optimizing the class intervals with respect to the accuracy potential of the underlying prediction model. This implies using smaller class intervals in those volume ranges where the model ensures precise prediction performance and enlarging these intervals in ranges where the model performs worse. If the class boundaries are allocated according to this concept, it becomes possible to design classification schemes that provide highest possible accuracies for each class, while avoiding a severe gradient between class accuracies. This concept was investigated by implementing an optimization algorithm which can be applied to any type of prediction model that provides estimates on a continuous scale. Implicitly, the method also provides an additional option for evaluating the precision of prediction models.
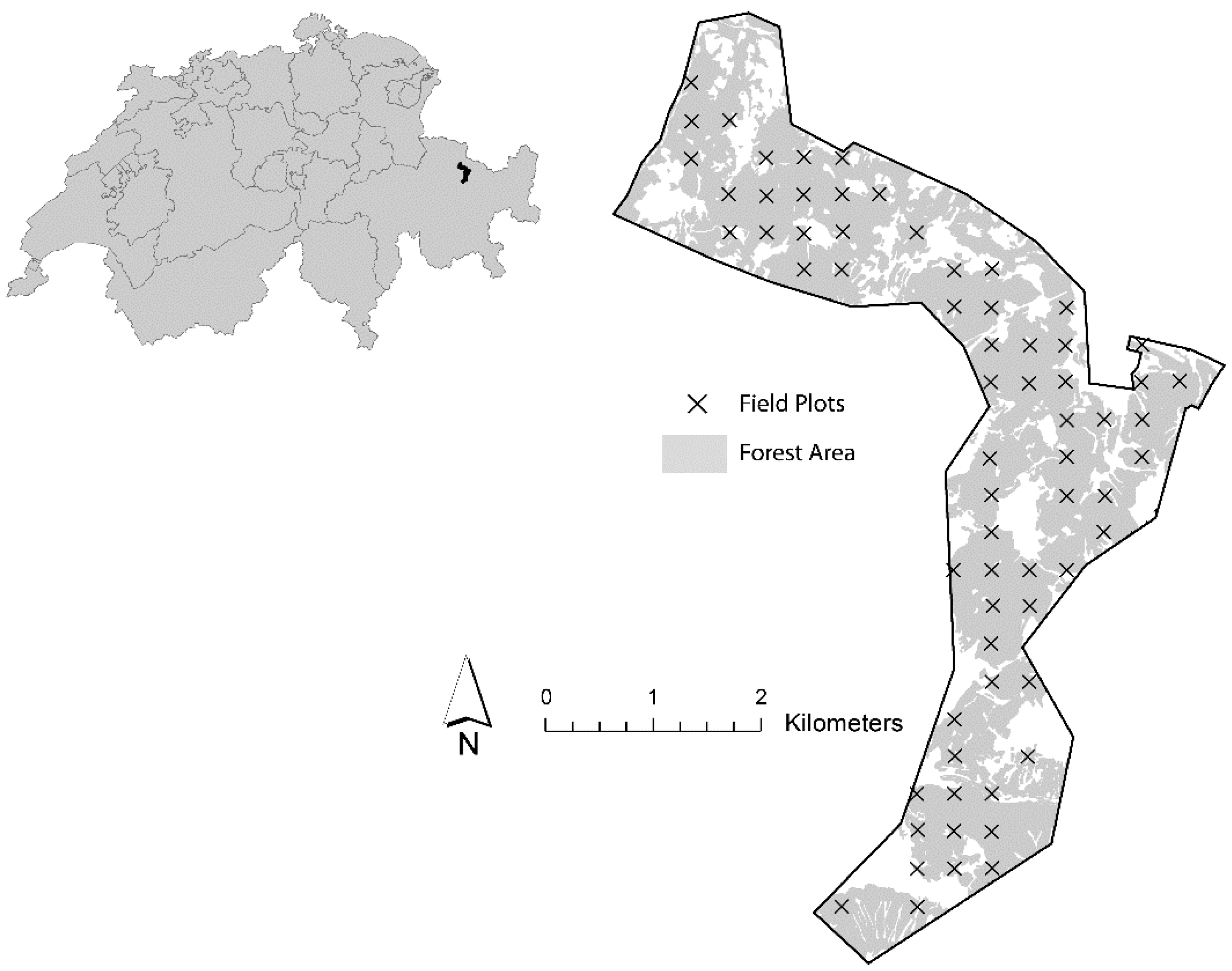
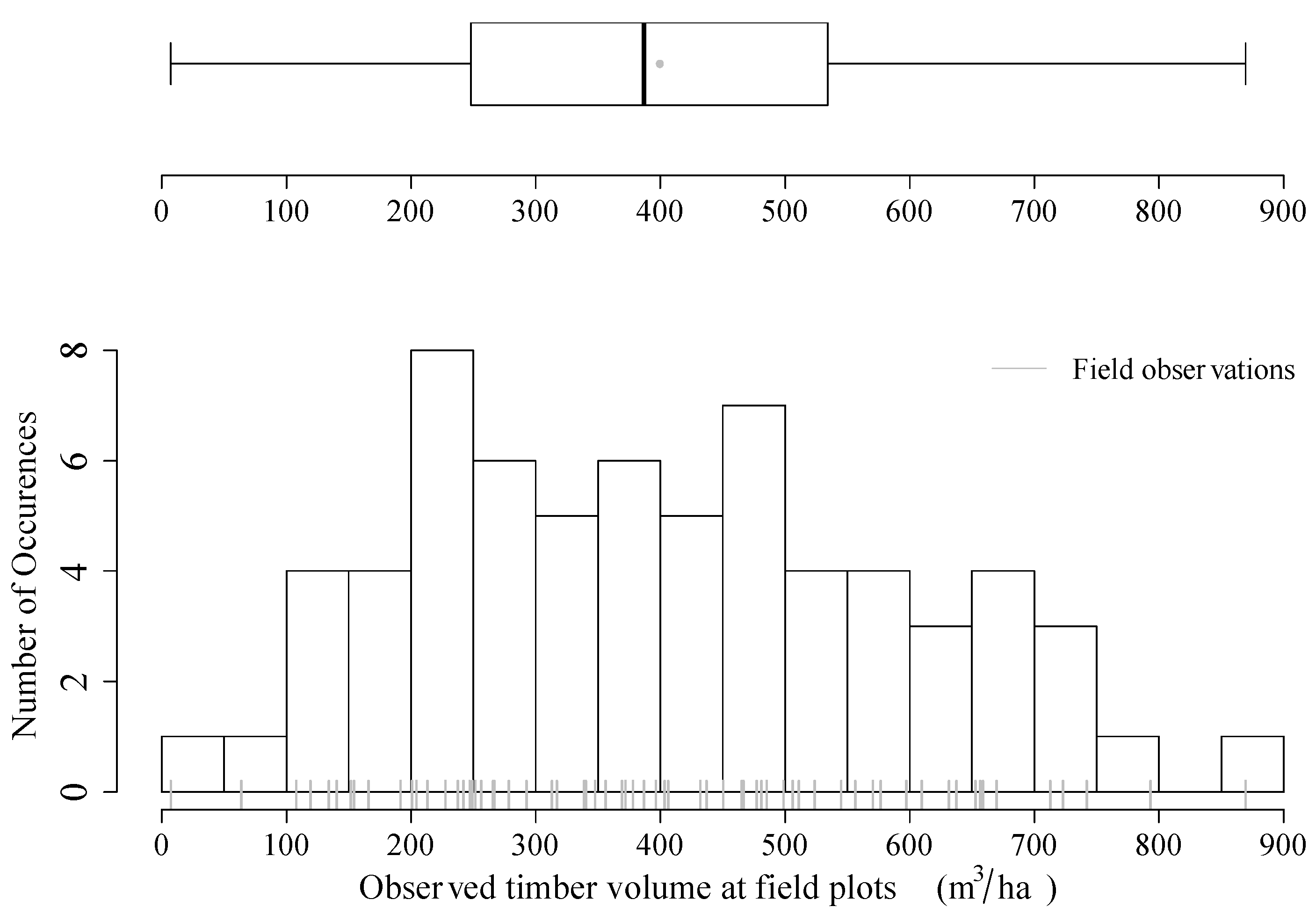
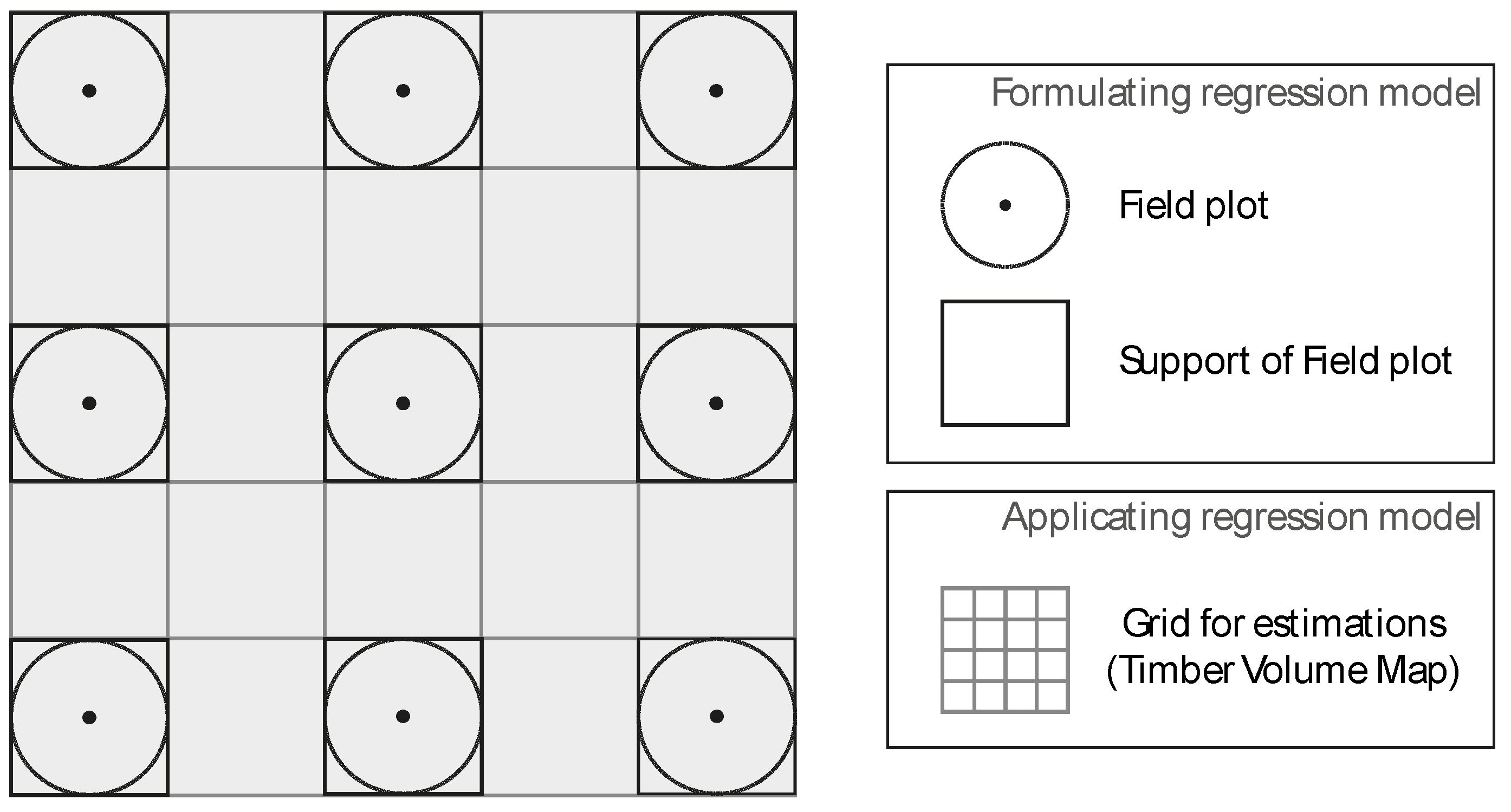
We demonstrate the method in a case study in the canton of Grisons using a LiDAR-derived canopy height model and regional forest inventory data. The workflow included: (1) the production of a map of estimated standing timber volume for the entire study area; (2) the calculation of reliable accuracy metrics for this map; and (3) the application of the proposed optimization algorithm in order to identify the classification schemes which provide the highest possible accuracies. In this particular case, we decided to use a multiple linear regression model, because most auxiliary variables exhibit a pronounced linear relationship to the terrestrial inventory [
29]. Additionally, the number of available terrestrial observations in our study was small (
n = 67) compared to similar studies, whereas it has been indicated that a good performance of
k-NN requires larger datasets [
26,
30].




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




