


Performance Influencing Factors of Convolutional Neural Network Models for Classifying Certain Softwood Species
 , , , , , and
, , , , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Methods
2.2.1. Sample Preparation for the Dataset
2.2.2. Dataset Preprocessing
2.2.3. Verification Factors Influencing Neural Networks
2.2.4. Correlation Analysis between Factors
3. Results and Discussion
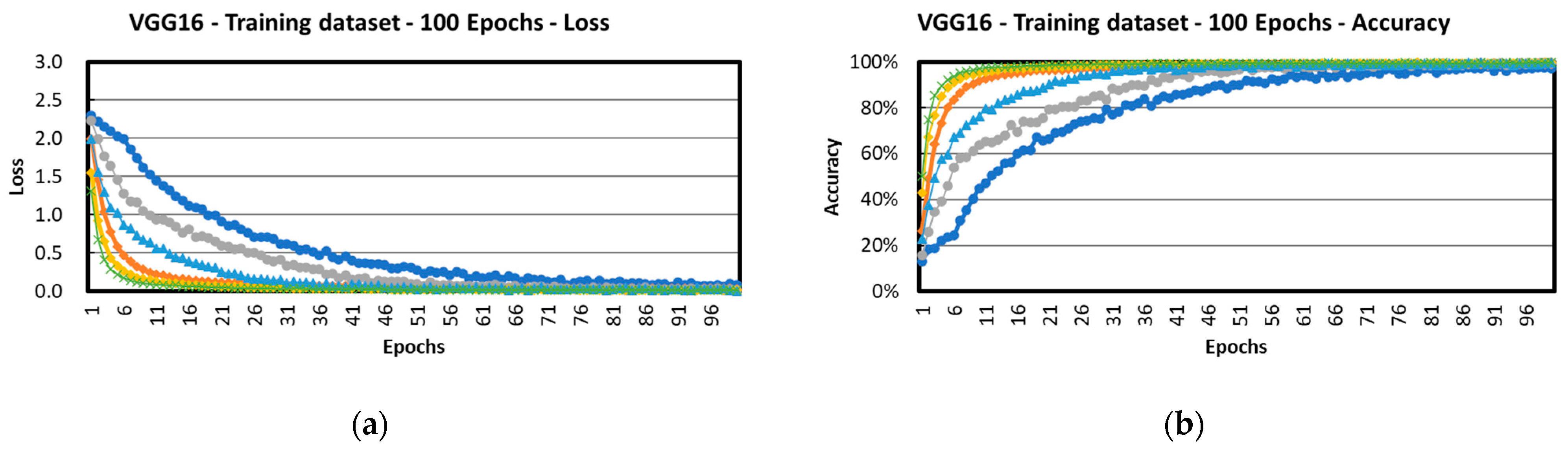
3.1. VGG16 Architecture
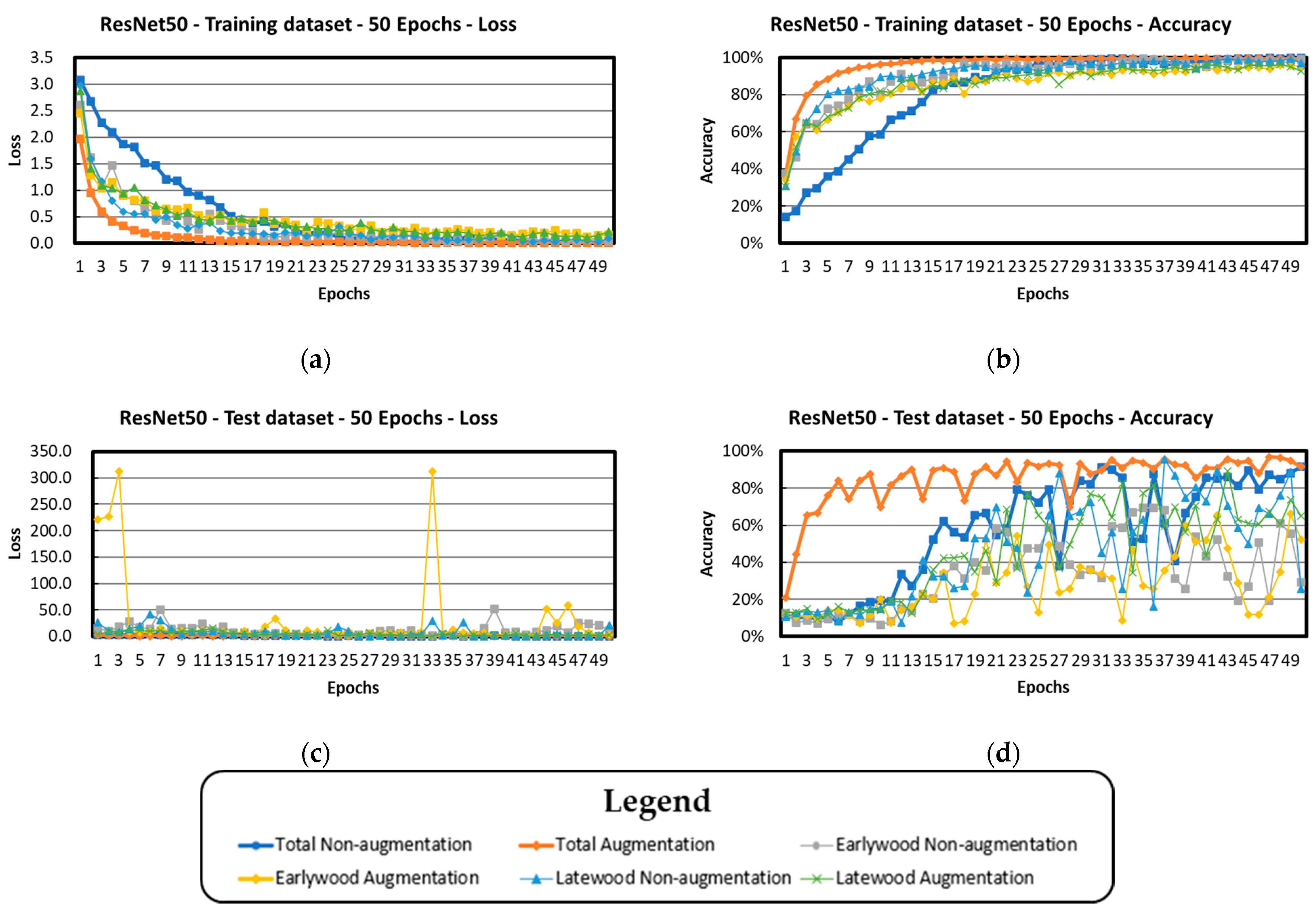
3.2. ResNet50 Architecture
3.3. GoogLeNet Architecture
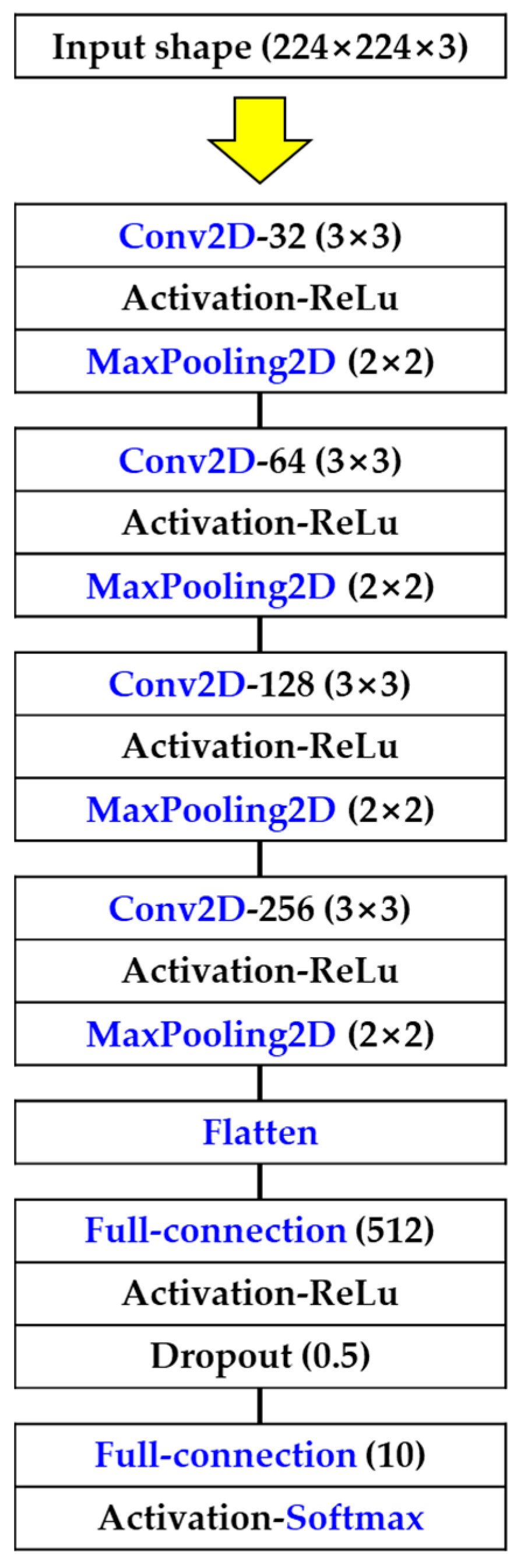
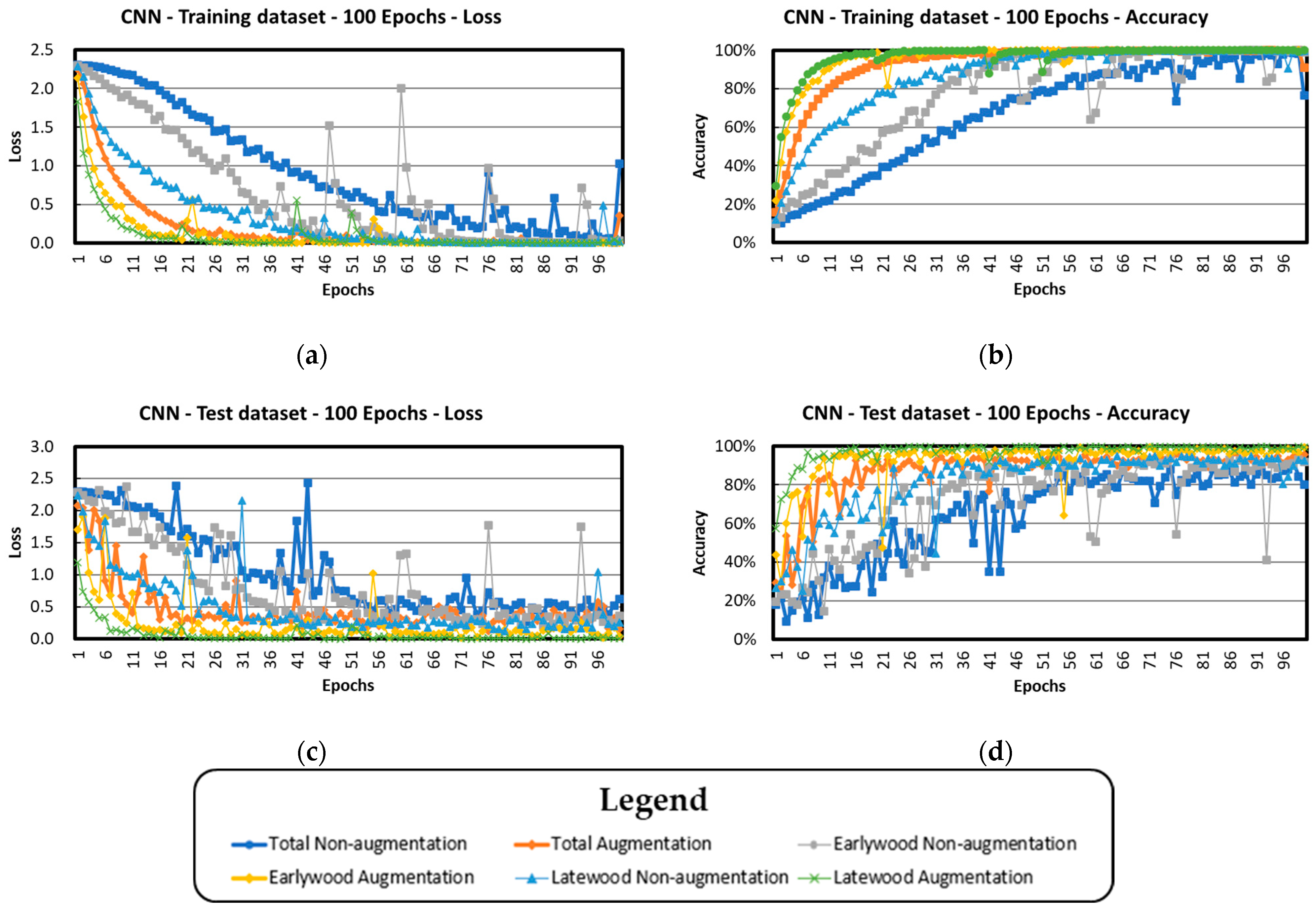
3.4. Basic CNN Architecture
3.5. General Trend
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- UNECE. Wood Resources Availability and Demands Implications of Renewable Energy Policies; UNECE: Geneva, Switzerland, 2007; pp. 12–13. [Google Scholar]
- FPL (Forest Products Laboratory). Identification of Central American, Mexican, and Caribbean Woods; USDA: Madison, WI, USA, 2022; p. 7. [Google Scholar]
- Hermanson, J.; Wiedenhoeft, A.; Gardner, S. A Machine Vision System for Automated Field–Level Wood Identification. In Proceedings of the Forest Trends, Online, 9 April 2014. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, W.; Aristov, A.; Lelek, M.; Hao, X.; Zimmer, C. Deep Learning Massively Accelerates Super-Resolution Localization Microscopy. Nat. Biotechnol. 2018, 36, 468–474. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramsundar, B. Deep Learning for the Life Science, 1st ed.; Acorn Publishing: Seoul, Republic of Korea, 2020; pp. 129–157. (In Korean) [Google Scholar]
- Ilic, J. Computer Aided Wood Identification Using Csiroid. IAWA J. 1993, 14, 333–340. [Google Scholar] [CrossRef]
- Zhao, Z.; Yang, X.; Ge, Z.; Guo, H.; Zhou, Y. Wood Microscopic Image Identification Method Based on Convolution Neural Network. BioResources 2021, 16, 4986–4999. [Google Scholar] [CrossRef]
- Cao, S.; Zhou, S.; Liu, J.; Liu, X.; Zhou, Y. Wood Classification Study based on Thermal Physical Parameters with Intelligent Method of Artificial Neural Networks. BioResources 2022, 17, 1187–1204. [Google Scholar] [CrossRef]
- Hu, K.; Wang, B.; Shen, Y.; Guan, J.; Cai, Y. Defect Identification Method for Poplar Veneer based on Progressive Growing Generated Adversarial Network and MASK R-CNN Model. BioResources 2020, 15, 3041–3052. [Google Scholar] [CrossRef]
- Wang, B.; Yang, C.; Ding, Y.; Qin, G. Detection of Wood Surface Defects based on Improved YOLOv3 Algorithm. BioResources 2021, 16, 6766–6780. [Google Scholar] [CrossRef]
- Ergun, H. Segmentation of Rays in Wood Microscopy Images using the U-net Model. BioResources 2021, 16, 721–728. [Google Scholar] [CrossRef]
- Kwon, O.K.; Lee, H.G.; Yang, S.Y.; Kim, H.B.; Park, S.Y.; Choi, I.K.; Yeo, H.M. Performance Enhancement of Automatic Wood Classification of Korean Softwood by Ensembles of Convolutional Neural Networks. J. Korean Wood Sci. Technol. 2019, 47, 265–276. [Google Scholar] [CrossRef]
- Lopes, D.J.V.; Burgreen, G.W.; Entsminger, E.D. North American Hardwoods Identification Using Machine-Learning. Forests 2020, 11, 298. [Google Scholar] [CrossRef] [Green Version]
- Fabijanska, A.; Danek, M.; Barniak, J. Wood Species Automatic Identification from Wood Core Images with a Residual Convolutional Neural Network. Comput. Electron. Agric. 2021, 181, 105941. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR) 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vonhaucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015. [Google Scholar]
- Gartner, H.; Schweingruber, F.H. Microscopic Preparation Techniques for Plant Stem Analysis; Verlag Dr. Kessel: Remagen, Germany, 2013; pp. 4–76. [Google Scholar]
- Arx, G.V.; Crivellaro, A.; Prendin, A.L.; Cufar, K.; Carrer, M. Quantitative Wood Anatomy—Practical Guidelines. Front. Plant Sci. 2016, 6, 781. [Google Scholar]
- Elgendy, M. Deep Learning for Vision Systems, 1st ed.; Hanbit Media: Seoul, Republic of Korea, 2021; pp. 243–294. (In Korean) [Google Scholar]
- Okataria, A.S.; Prakasa, E.; Suhartono, E.; Sugiarto, B.; Prajitno, D.R.; Wardoyo, R. Wood Species Identification using Convolutional Neural Network (CNN) Architectures on Macroscopic Images. J. Inf. Technol. Comput. Sci. 2019, 4, 274–283. [Google Scholar] [CrossRef] [Green Version]
- Kryl, M.; Danys, L.; Jaros, R.; Martinek, R.; Kodytek, P.; Bilik, P. Wood Recognition and Quality Imaging Inspection System. J. Sens. 2020, 2020, 19. [Google Scholar] [CrossRef]
- Andrade, B.G.D.; Basso, V.M.; Latorraca, J.V.D.F. Machine Vision for Field-Level Wood Identification. IAWA J. 2020, 41, 681–691. [Google Scholar] [CrossRef]
- Figueroa-Mata, G.; Mata-Montero, E.; Valverde-Otarola, J.C.; Arias-Aguilar, D.; Zamora-Villalobos, N. Using Deep Learning to Identify Costa Rican Native Tree Species from Wood Cut Images. Front. Plant Sci. 2022, 13, 789227. [Google Scholar] [CrossRef] [PubMed]
- Choo, H.S. Understanding the Latest Trends in Deep Learning through Easy-to-Follow Diagrams, 2nd ed.; WizPlanet: Seoul, Republic of Korea, 2021; p. 16. (In Korean) [Google Scholar]
- Jindal, H.; Sardana, N.; Mehta, R. Analyzing Performance of Deep Learning Techniques for Web Navigation Prediction. Procedia Comput. Sci. 2020, 167, 1739–1748. [Google Scholar] [CrossRef]
- Afaq, S.; Rao, S. Significance of Epochs on Training A Neural Network. Int. J. Sci. Technol. Res. 2020, 9, 485–488. [Google Scholar]
- Chollet, F. Deep Learning with Python, 1st ed.; Gilbut Publish: Seoul, Republic of Korea, 2018; pp. 35–37. (In Korean) [Google Scholar]
- Camgozlu, Y.; Kutlu, Y. Analysis of Filter Size Effect in Deep Learning. J. Artif. Intell. Appl. 2020, 1, 1–6. [Google Scholar]
- Ahmed, W.S.; Karim, A.A.A. The Impact of Filter Size and Number of Filters on Classification Accuracy in CNN. In Proceedings of the 2020 International Conference on Computer Science and Software Engineering (CSASE), Duhok, Iraq, 16–18 April 2020. [Google Scholar]
- Geron, A. Hands on Machine Learning with Scikit-Learn, Keras & Tensorflow, 2nd ed.; Hanbit Media: Seoul, Republic of Korea, 2020; p. 58. (In Korean) [Google Scholar]
- Fujita, K.; Takahara, A. Deep Learning Bootcamp with Keras, 1st ed.; Gilbut publish: Seoul, Republic of Korea, 2017; pp. 94–95. (In Korean) [Google Scholar]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding Data Augmentation for Classification: When to Warp. In Proceedings of the 2016 International Conference on Digital Image Computing, Gold Coast, Australia, 30 November 2016–2 December 2016. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Common Name | Scientific Name | Origin | Supplier |
|---|---|---|---|
| Cedar | Cryptomeria japonica | Japan | W Wood Co., Ltd. (Daejeon, Republic of Korea) |
| Japanese cypress | Chamaecyparis obtusa | Japan | |
| Mugo pine | Pinus mugo | Finland | |
| Radiata pine | Pinus radiata | USA | |
| Spruce | Picea abies | Estonia | |
| Yin shan shu | Cathaya argyrophylla | Russia | |
| Korean red pine | Pinus densiflora | Chuncheon, Republic of Korea | Research forest of Kangwon National University (Chuncheon, Republic of Korea: 37.7748857, 127.8134654) |
| Korean white pine | Pinus koraiensis | ||
| Metasequoia | Metasequoia glyptostroboides | ||
| Juniper | Juniperus chinensis |
| Common Name | Scientific Name | 40× Dataset (Total) | 200× Dataset (Earlywood, Latewood) | ||||
|---|---|---|---|---|---|---|---|
| Train | Test | Sum | Train | Test | Sum | ||
| Cedar | Cryptomeria japonica | 160 | 40 | 200 | 160 | 40 | 200 |
| Japanese cypress | Chamaecyparis obtusa | 160 | 40 | 200 | 160 | 40 | 200 |
| Mugo pine | Pinus mugo | 160 | 40 | 200 | 160 | 40 | 200 |
| Radiata pine | Pinus radiata | 160 | 40 | 200 | 160 | 40 | 200 |
| Spruce | Picea abies | 160 | 40 | 200 | 160 | 40 | 200 |
| Yin shan shu | Cathaya argyrophylla | 160 | 40 | 200 | 160 | 40 | 200 |
| Korean red pine | Pinus densiflora | 160 | 40 | 200 | 160 | 40 | 200 |
| Korean white pine | Pinus koraiensis | 160 | 40 | 200 | 160 | 40 | 200 |
| Metasequoia | Metasequoia glyptostroboides | 160 | 40 | 200 | 160 | 40 | 200 |
| Juniper | Juniperus chinensis | 160 | 40 | 200 | 160 | 40 | 200 |
| Sum | 1600 | 400 | 2000 | 1600 | 400 | 2000 | |
| Common Name | Scientific Name | 40× Dataset | 200× Dataset | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Earlywood | Latewood | |||||||||
| Train | Test | Sum | Train | Test | Sum | Train | Test | Sum | ||
| Cedar | Cryptomeria japonica | 160 | 40 | 200 | 1764 | 40 | 1804 | 1768 | 40 | 1808 |
| Japanese cypress | Chamaecyparis obtusa | 160 | 40 | 200 | 1774 | 40 | 1814 | 1754 | 40 | 1794 |
| Mugo pine | Pinus mugo | 160 | 40 | 200 | 1775 | 40 | 1815 | 1772 | 40 | 1812 |
| Radiata pine | Pinus radiata | 160 | 40 | 200 | 1781 | 40 | 1821 | 1775 | 40 | 1815 |
| Spruce | Picea abies | 160 | 40 | 200 | 1773 | 40 | 1813 | 1781 | 40 | 1821 |
| Yin shan shu | Cathaya argyrophylla | 160 | 40 | 200 | 1762 | 40 | 1802 | 1776 | 40 | 1816 |
| Korean red pine | Pinus densiflora | 160 | 40 | 200 | 1783 | 40 | 1823 | 1785 | 40 | 1825 |
| Korean white pine | Pinus koraiensis | 160 | 40 | 200 | 1767 | 40 | 1807 | 1777 | 40 | 1817 |
| Metasequoia | Metasequoia glyptostroboides | 160 | 40 | 200 | 1764 | 40 | 1804 | 1779 | 40 | 1819 |
| Juniper | Juniperus chinensis | 160 | 40 | 200 | 1784 | 40 | 1822 | 1768 | 40 | 1808 |
| Sum | 1600 | 400 | 2000 | 17,739 | 400 | 18,125 | 17,735 | 400 | 18,135 | |
| Architecture | Layers | Convolutional Filter | Structural Features |
|---|---|---|---|
| VGG16 | 25 | 3 × 3 convolutional layer |
|
| ResNet50 | 50 | 3 × 3 convolutional layer |
|
| GoogLeNet | 16 | 1 × 1 convolutional layer 3 × 3 convolutional layer 5 × 5 convolutional layer 3 × 3 pooling layer |
|
| Basic CNN | 12 | 3 × 3 convolutional layer |
|
| Dataset | Total (40×) | Earlywood (200×) | Latewood (200×) | ||||
|---|---|---|---|---|---|---|---|
| NAug | Aug | NAug | Aug | NAug | Aug | ||
| Train dataset | Loss | 0.546 d | 0.136 ab | 0.340 c | 0.080 a | 0.200 b | 0.058 a |
| accuracy | 0.803 a | 0.955 cd | 0.876 b | 0.972 d | 0.926 c | 0.980 d | |
| Test dataset | Loss | 1.500 c | 0.364 ab | 1.769 c | 1.968 c | 0.721 b | 0.157 a |
| accuracy | 0.649 a | 0.916 d | 0.682 a | 0.780 b | 0.844 c | 0.963 d | |
| Dataset | Total (40×) | Earlywood (200×) | Latewood (200×) | ||||
|---|---|---|---|---|---|---|---|
| NAug | Aug | NAug | Aug | NAug | Aug | ||
| Train dataset | Loss | 0.544 c | 0.121 ab | 0.287 b | 0.064 a | 0.237 ab | 0.048 a |
| accuracy | 0.822 a | 0.959 bc | 0.900 b | 0.978 c | 0.923 bc | 0.984 c | |
| Test dataset | Loss | 1.697 c | 0.637 ab | 2.435 d | 0.334 a | 1.100 b | 0.090 a |
| accuracy | 0.572 a | 0.854 c | 0.578 a | 0.927 cd | 0.765 b | 0.974 d | |
| Dataset | Total (40×) | Earlywood (200×) | Latewood (200×) | ||||
|---|---|---|---|---|---|---|---|
| NAug | Aug | NAug | Aug | NAug | Aug | ||
| Train dataset | Loss | 1.429 e | 1.680 f | 1.113 c | 1.246 d | 0.711 a | 0.972 b |
| accuracy | 0.480 b | 0.387 a | 0.595 d | 0.549 c | 0.734 e | 0.639 d | |
| Test dataset | Loss | 1.462 d | 1.609 e | 1.138 c | 1.159 c | 0.659 a | 0.898 b |
| accuracy | 0.464 b | 0.411 a | 0.582 c | 0.575 c | 0.752 e | 0.673 d | |
| Dataset | Total (40×) | Earlywood (200×) | Latewood (200×) | ||||
|---|---|---|---|---|---|---|---|
| NAug | Aug | NAug | Aug | NAug | Aug | ||
| Train dataset | Loss | 0.925 d | 0.205 ab | 0.671 c | 0.130 a | 0.349 b | 0.101 a |
| accuracy | 0.675 a | 0.930 d | 0.777 b | 0.957 d | 0.873 c | 0.965 d | |
| Test dataset | Loss | 1.038 e | 0.466 c | 0.832 d | 0.238 b | 0.503 c | 0.074 a |
| accuracy | 0.642 a | 0.873 d | 0.714 b | 0.927 e | 0.819 c | 0.972 e | |
| Total (40×) | Earlywood (200×) | Latewood (200×) | ||||
|---|---|---|---|---|---|---|
| NAug | Aug | NAug | Aug | NAug | Aug | |
| VGG16 | 72.5 (0.3) | 92.9 (0.1) | 87.9 (0.6) | 86.8 (0.7) | 96.6 (0.9) | 97.8 (1.4) |
| ResNet50 | 86.3 (4.5) | 93.6 (3.8) | 91.9 (18.0) | 99.1 (22.2) | 96.1 (23.8) | 99.5 (5.5) |
| GoogLeNet | 73.9 (2.7) | 70.5 (6.8) | 83.8 (6.1) | 81.5 (7.9) | 98.1 (1.4) | 91.6 (4.1) |
| CNN | 86.3 (4.3) | 94.0 (1.9) | 91.4 (1.2) | 98.3 (0.9) | 88.1 (5.4) | 99.3 (0.5) |
| N = 2700 | Epochs | Loss (Train) | Accuracy (Train) | Loss (Test) | Accuracy (Test) | Position (Total) | Position (Earlywood) | Position (Latewood) | Augmentation (No) | Augmentation (Yes) |
|---|---|---|---|---|---|---|---|---|---|---|
| Epochs | 1 | −0.157 ** | 0.166 ** | −0.225 ** | 0.267 ** | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | ||
| Loss (train) | −0.157 ** | 1 | −0.996 ** | 0.442 ** | −0.886 ** | 0.227 ** | −0.012 | −0.214 ** | 0.073 ** | −0.073 ** |
| p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.521 | p = 0.000 | p = 0.000 | p = 0.000 | ||
| Accuracy (train) | 0.166 ** | −0.996 ** | 1 | −0.442 ** | 0.889 ** | −0.219 ** | 0.018 | 0.201 ** | −0.068 ** | 0.068 ** |
| p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.337 | p = 0.000 | p = 0.000 | p = 0.000 | ||
| Loss (test) | −0.225 ** | 0.442 ** | −0.442 ** | 1 | −0.719 ** | 0.120 ** | 0.127 ** | −0.248 ** | 0.137 ** | −0.137 ** |
| p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | ||
| Accuracy (test) | 0.267 ** | −0.886 ** | 0.889 ** | −0.719 ** | 1 | −0.238 ** | −0.051 ** | 0.289 ** | −0.172 ** | 0.172 ** |
| p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.008 | p = 0.000 | p = 0.000 | p = 0.000 | ||
| Position (total) | 0.000 | 0.227 ** | −0.219 ** | 0.120 ** | −0.238 ** | 1 | −0.500 ** | −0.500 ** | 0.000 | 0.000 |
| p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | ||
| Position (earlywood) | 0.000 | −0.012 | 0.018 | 0.127 ** | −0.051 ** | −0.500 ** | 1 | −0.500 ** | 0.000 | 0.000 |
| p = 0.000 | p = 0.521 | p = 0.337 | p = 0.000 | p = 0.008 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | ||
| Position (latewood) | 0.000 | −0.214 ** | 0.201 ** | −0.248 ** | 0.289 ** | −0.500 ** | −0.500 ** | 1 | 0.000 | 0.000 |
| p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | ||
| Augmentation (yes) | 0.000 | 0.073 ** | −0.068 ** | 0.137 ** | −0.172 ** | 0.000 | 0.000 | 0.000 | 1 | −0.000 ** |
| p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | ||
| Augmentation (no) | 0.000 | −0.073 ** | 0.068 ** | −0.137 ** | 0.172 ** | 0.000 | 0.000 | 0.000 | −0.000 ** | 1 |
| p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 |
| N = 120 | Epochs | Loss (Train) | Accuracy (Train) | Loss (Test) | Accuracy (Test) | Position (Total) | Position (Earlywood) | Position (Latewood) | Augmentation (No) | Augmentation (Yes) |
|---|---|---|---|---|---|---|---|---|---|---|
| Epochs | 1 | 0.658 ** | −0.703 ** | 0.107 | −0.390 ** | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| p = 0.000 | p = 0.000 | p = 0.246 | p = 0.000 | p = 1.000 | p = 1.000 | p = 1.000 | p = 1.000 | p = 1.000 | ||
| Loss (train) | 0.658 ** | 1 | −0.982 ** | 0.181 * | −0.568 ** | 0.212 * | 0.026 | −0.238 ** | −0.023 | 0.023 |
| p = 0.000 | p = 0.000 | p = 0.047 | p = 0.000 | p = 0.020 | p = 0.782 | p = 0.009 | p = 0.799 | p = 0.799 | ||
| Accuracy (train) | −0.703 ** | −0.982 ** | 1 | −0.189 * | 0.591 ** | −0.230 * | −0.021 | 0.251 ** | 0.068 | −0.068 |
| p = 0.000 | p = 0.000 | p = 0.039 | p = 0.000 | p = 0.012 | p = 0.821 | p = 0.006 | p = 0.463 | p = 0.463 | ||
| Loss (test) | 0.107 | 0.181 * | −0.189 * | 1 | −0.827 ** | 0.328 ** | −0.033 | −0.295 ** | 0.165 | −0.165 |
| p = 0.246 | p = 0.047 | p = 0.039 | p = 0.000 | p = 0.000 | p = 0.721 | p = 0.001 | p = 0.071 | p = 0.071 | ||
| Accuracy (test) | −0.390 ** | −0.568 ** | 0.591 ** | −0.827 ** | 1 | −0.420 ** | 0.012 | 0.408 ** | −0.209 * | 0.209 * |
| p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.896 | p = 0.000 | p = 0.022 | p = 0.022 | ||
| Position (total) | 0.000 | 0.212 * | −0.230 * | 0.328 ** | −0.420 ** | 1 | −0.500 ** | −0.500 ** | 0.000 | 0.000 |
| p = 1.000 | p = 0.020 | p = 0.012 | p = 0.000 | p = 0.000 | p = 0.000 | p = 0.000 | p = 1.000 | p = 1.000 | ||
| Position (earlywood) | 0.000 | 0.026 | −0.021 | −0.033 | 0.012 | −0.500 ** | 1 | −0.500 ** | p = 0.000 | p = 0.000 |
| p = 1.000 | p = 0.782 | p = 0.821 | p = 0.721 | p = 0.896 | p = 0.000 | p = 0.000 | p = 1.000 | p = 1.000 | ||
| Position (latewood) | 0.000 | −0.238 ** | 0.251 ** | −0.295 ** | 0.408 ** | −0.500 ** | −0.500 ** | 1 | 0.000 | 0.000 |
| p = 1.000 | p = 0.009 | p = 0.006 | p = 0.001 | p = 0.000 | p = 0.000 | p = 0.000 | p = 1.000 | p = 1.000 | ||
| Augmentation (yes) | 0.000 | −0.023 | 0.068 | 0.165 | −0.209 * | 0.000 | 0.000 | 0.000 | 1 | −1.000 ** |
| p = 1.000 | p = 0.799 | p = 0.463 | p = 0.071 | p = 0.022 | p = 1.000 | p = 1.000 | p = 1.000 | p = 0.000 | ||
| Augmentation (no) | 0.000 | 0.023 | −0.068 | −0.165 | 0.209 * | 0.000 | 0.000 | 0.000 | −1.000 ** | 1 |
| p = 1.000 | p = 0.799 | p = 0.463 | p = 0.071 | p = 0.022 | p = 1.000 | p = 1.000 | p = 1.000 | p = 0.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-H.; Purusatama, B.D.; Savero, A.M.; Prasetia, D.; Yang, G.-U.; Han, S.-Y.; Lee, S.-H.; Kim, N.-H. Performance Influencing Factors of Convolutional Neural Network Models for Classifying Certain Softwood Species. Forests 2023, 14, 1249. https://doi.org/10.3390/f14061249
Kim J-H, Purusatama BD, Savero AM, Prasetia D, Yang G-U, Han S-Y, Lee S-H, Kim N-H. Performance Influencing Factors of Convolutional Neural Network Models for Classifying Certain Softwood Species. Forests. 2023; 14(6):1249. https://doi.org/10.3390/f14061249
Chicago/Turabian StyleKim, Jong-Ho, Byantara Darsan Purusatama, Alvin Muhammad Savero, Denni Prasetia, Go-Un Yang, Song-Yi Han, Seung-Hwan Lee, and Nam-Hun Kim. 2023. "Performance Influencing Factors of Convolutional Neural Network Models for Classifying Certain Softwood Species" Forests 14, no. 6: 1249. https://doi.org/10.3390/f14061249