
The Sensitivity Feature Analysis for Tree Species Based on Image Statistical Properties
Abstract
:1. Introduction
2. Materials
Image Statistical Properties
- (1)
- Color property
- (2)
- Texture property
- (3)
- Shape property
- (4)
- Power spectrum
- (5)
- Weibull distribution coefficients
- (6)
- Mean Subtracted Contrast Normalized coefficients
- (7)
- Discrete cosine transformation coefficients
- (8)
- Wavelet coefficients
3. Methods
3.1. Feature Correlation Ranking
- (1)
- Spearman
- (2)
- mRMR
- (3)
- ReliefF
3.2. Feature Importance
3.3. Deep SVDD
3.4. Validation
4. Results
4.1. Data Visualization
4.2. Feature Ranking
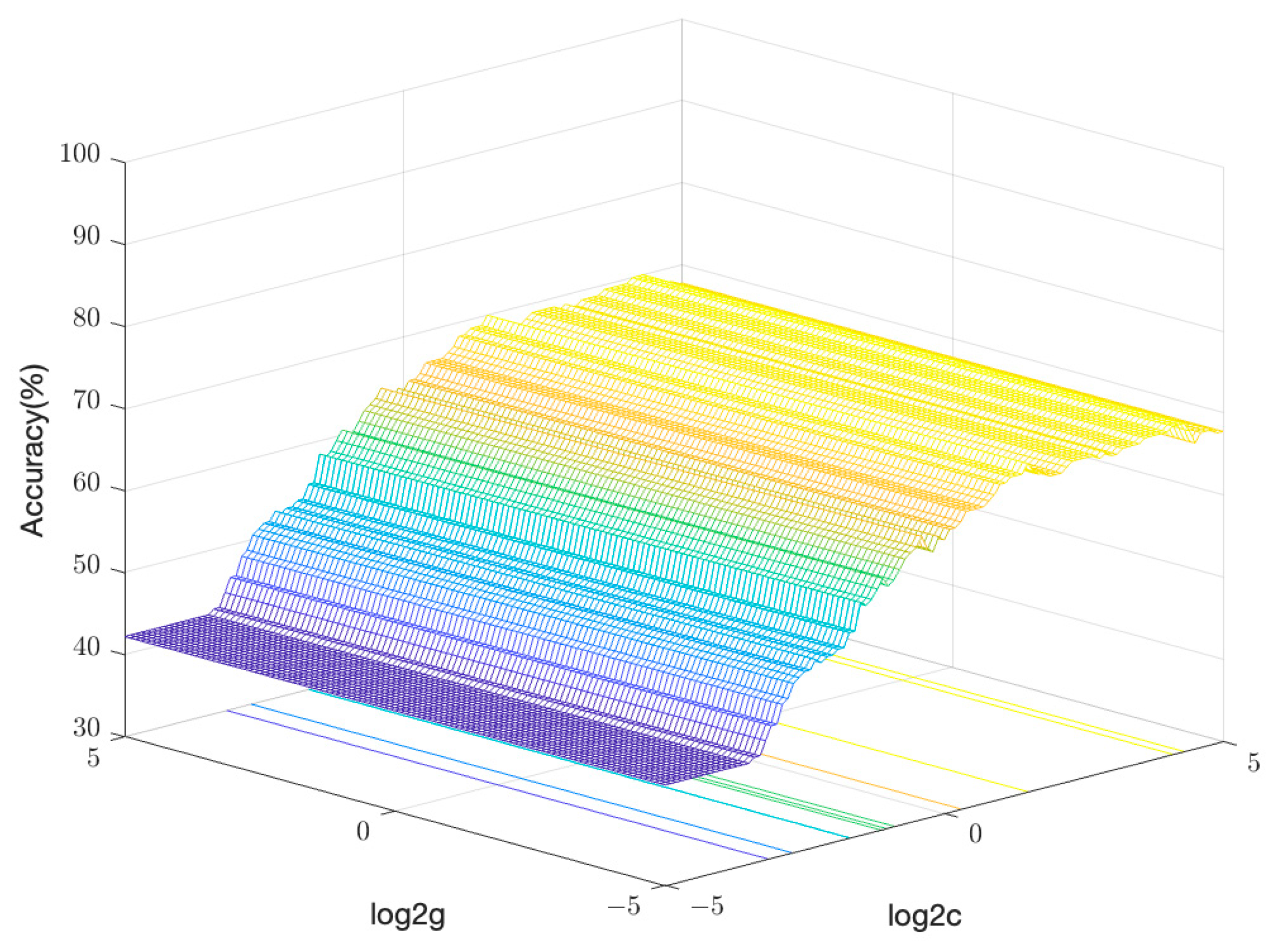
4.3. Accuracy Analysis
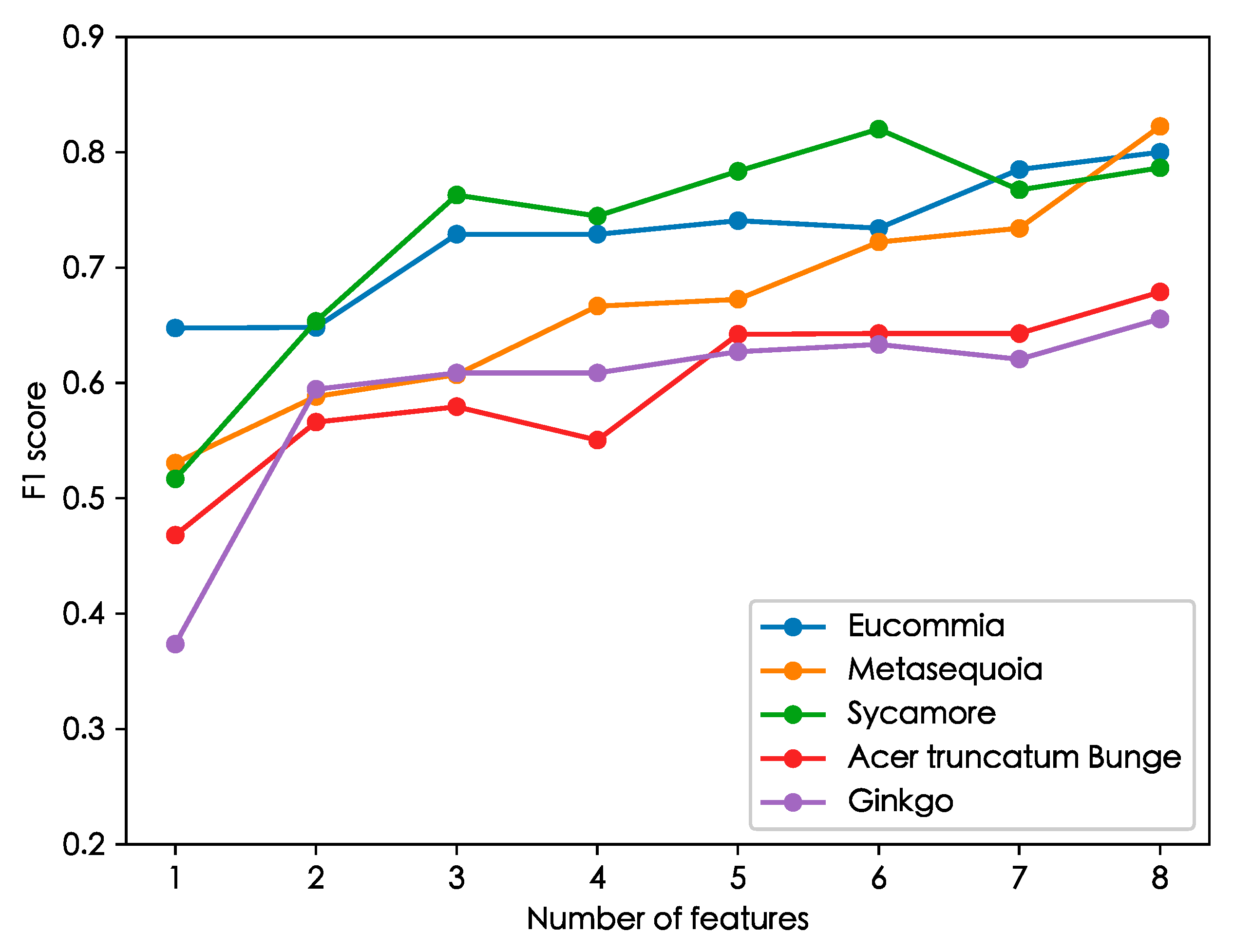
4.4. The Sensitivity Features Analysis
4.5. Validation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dugesar, V.; Satish, K.V.; Pandey, M.K.; Srivastava, P.K.; Petropoulos, G.P.; Anand, A.; Behera, M.D. Impact of Environmental Gradients on Phenometrics of Major Forest Types of Kumaon Region of the Western Himalaya. Forests 2022, 13, 1973. [Google Scholar] [CrossRef]
- Garforth, J.; Webb, B. Visual Appearance Analysis of Forest Scenes for Monocular SLAM. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1794–1800. [Google Scholar]
- Liu, L.; Liu, Y.; Lv, Y.; Xing, J. LANet: Stereo Matching Network Based on Linear-Attention Mechanism for Depth Estimation Optimization in 3D Reconstruction of Inter-Forest Scene. Front. Plant Sci. 2022, 13, 978564. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A Forest Fire Detection System Based on Ensemble Learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Lebedev, V.G.; Lebedeva, T.N.; Chernodubov, A.I.; Shestibratov, K.A. Genomic Selection for Forest Tree Improvement: Methods, Achievements and Perspectives. Forests 2020, 11, 1190. [Google Scholar] [CrossRef]
- Qin, H.; Zhou, W.; Yao, Y.; Wang, W. Individual Tree Segmentation and Tree Species Classification in Subtropical Broadleaf Forests Using UAV-Based LiDAR, Hyperspectral, and Ultrahigh-Resolution RGB Data. Remote Sens. Environ. 2022, 280, 113143. [Google Scholar] [CrossRef]
- Cerutti, G.; Tougne, L.; Mille, J.; Vacavant, A.; Coquin, D. Understanding Leaves in Natural Images–a Model-Based Approach for Tree Species Identification. Comput. Vis. Image Underst. 2013, 117, 1482–1501. [Google Scholar] [CrossRef]
- Fiel, S.; Sablatnig, R. Automated Identification of Tree Species from Images of the Bark, Leaves or Needles. In Proceedings of the Computer Vision Winter Workshop, Mitterberg, Austria, 2–4 February 2010. [Google Scholar]
- Bambil, D.; Pistori, H.; Bao, F.; Weber, V.; Alves, F.M.; Gonçalves, E.G.; de Alencar Figueiredo, L.F.; Abreu, U.G.; Arruda, R.; Bortolotto, I.M. Plant Species Identification Using Color Learning Resources, Shape, Texture, through Machine Learning and Artificial Neural Networks. Environ. Syst. Decis. 2020, 40, 480–484. [Google Scholar] [CrossRef]
- Fekri-Ershad, S. Bark Texture Classification Using Improved Local Ternary Patterns and Multilayer Neural Network. Expert Syst. Appl. 2020, 158, 113509. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, H.; Lin, H.; Fang, C. Textural—Spectral Feature-Based Species Classification of Mangroves in Mai Po Nature Reserve from Worldview-3 Imagery. Remote Sens. 2015, 8, 24. [Google Scholar] [CrossRef]
- Chen, X.; Wang, B.; Gao, Y. Symmetric Binary Tree Based Co-Occurrence Texture Pattern Mining for Fine-Grained Plant Leaf Image Retrieval. Pattern Recognit. 2022, 129, 108769. [Google Scholar] [CrossRef]
- Cetin, Z.; Yastikli, N. The Use of Machine Learning Algorithms in Urban Tree Species Classification. IJGI 2022, 11, 226. [Google Scholar] [CrossRef]
- Park, G.; Lee, Y.-G.; Yoon, Y.-S.; Ahn, J.-Y.; Lee, J.-W.; Jang, Y.-P. Machine Learning-Based Species Classification Methods Using DART-TOF-MS Data for Five Coniferous Wood Species. Forests 2022, 13, 1688. [Google Scholar] [CrossRef]
- Pantazi, X.E.; Moshou, D.; Tamouridou, A.A. Automated Leaf Disease Detection in Different Crop Species through Image Features Analysis and One Class Classifiers. Comput. Electron. Agric. 2019, 156, 96–104. [Google Scholar] [CrossRef]
- Zhao, H.; Zhong, Y.; Wang, X.; Hu, X.; Luo, C.; Boitt, M.; Piiroinen, R.; Zhang, L.; Heiskanen, J.; Pellikka, P. Mapping the Distribution of Invasive Tree Species Using Deep One-Class Classification in the Tropical Montane Landscape of Kenya. ISPRS J. Photogramm. Remote Sens. 2022, 187, 328–344. [Google Scholar] [CrossRef]
- Pan, H.; Xu, H.; Zheng, J.; Su, J.; Tong, J. Multi-Class Fuzzy Support Matrix Machine for Classification in Roller Bearing Fault Diagnosis. Adv. Eng. Inform. 2022, 51, 101445. [Google Scholar] [CrossRef]
- Ibrahim, I.; Khairuddin, A.S.M.; Abu Talip, M.S.; Arof, H.; Yusof, R. Tree Species Recognition System Based on Macroscopic Image Analysis. Wood Sci. Technol. 2017, 51, 431–444. [Google Scholar] [CrossRef]
- Wheeler, E.A. Inside Wood–A Web Resource for Hardwood Anatomy. Iawa J. 2011, 32, 199–211. [Google Scholar] [CrossRef]
- Zhang, Z.; Deng, X. Anomaly Detection Using Improved Deep SVDD Model with Data Structure Preservation. Pattern Recognit. Lett. 2021, 148, 1–6. [Google Scholar] [CrossRef]
- Sun, Y.; Huang, J.; Ao, Z.; Lao, D.; Xin, Q. Deep Learning Approaches for the Mapping of Tree Species Diversity in a Tropical Wetland Using Airborne LiDAR and High-Spatial-Resolution Remote Sensing Images. Forests 2019, 10, 1047. [Google Scholar] [CrossRef]
- Haralick, R.M. Statistical and Structural Approaches to Texture. Proc. IEEE 1979, 67, 786–804. [Google Scholar] [CrossRef]
- Michałowska, M.; Rapiński, J. A Review of Tree Species Classification Based on Airborne LiDAR Data and Applied Classifiers. Remote Sens. 2021, 13, 353. [Google Scholar] [CrossRef]
- Torralba, A.; Oliva, A. Statistics of Natural Image Categories. Netw. Comput. Neural Syst. 2003, 14, 391. [Google Scholar] [CrossRef]
- Yanulevskaya, V.; Geusebroek, J.-M. Significance of the Weibull Distribution and Its Sub-Models in Natural Image Statistics. In Proceedings of the VISAPP 2009—Proceedings of the Fourth International Conference on Computer Vision Theory and Applications, Lisbon, Portugal, 5–8 February 2009; pp. 355–362. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Sawant, S.S.; Manoharan, P. Unsupervised Band Selection Based on Weighted Information Entropy and 3D Discrete Cosine Transform for Hyperspectral Image Classification. Int. J. Remote Sens. 2020, 41, 3948–3969. [Google Scholar] [CrossRef]
- You, N.; Han, L.; Zhu, D.; Song, W. Research on Image Denoising in Edge Detection Based on Wavelet Transform. Appl. Sci. 2023, 13, 1837. [Google Scholar] [CrossRef]
- Jo, I.; Lee, S.; Oh, S. Improved Measures of Redundancy and Relevance for MRMR Feature Selection. Computers 2019, 8, 42. [Google Scholar] [CrossRef]
- Urbanowicz, R.J.; Meeker, M.; La Cava, W.; Olson, R.S.; Moore, J.H. Relief-Based Feature Selection: Introduction and Review. J. Biomed. Inform. 2018, 85, 189–203. [Google Scholar] [CrossRef]
- Kononenko, I.; Šimec, E.; Robnik-Šikonja, M. Overcoming the Myopia of Inductive Learning Algorithms with RELIEFF. Appl. Intell. 1997, 7, 39–55. [Google Scholar] [CrossRef]
- Lorena, L.H.; Carvalho, A.C.; Lorena, A.C. Filter Feature Selection for One-Class Classification. J. Intell. Robot. Syst. 2015, 80, 227–243. [Google Scholar] [CrossRef]
- Simoncelli, E.P.; Olshausen, B.A. Natural Image Statistics and Neural Representation. Annu. Rev. Neurosci. 2001, 24, 1193–1216. [Google Scholar] [CrossRef]
- Ratajczak, R.; Bertrand, S.; Crispim-Junior, C.F.; Tougne, L. Efficient Bark Recognition in the Wild. In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP 2019), Prague, Czech Republic, 25–27 February 2019. [Google Scholar]
- Yadav, A.R.; Anand, R.S.; Dewal, M.L.; Gupta, S. Performance Analysis of Discrete Wavelet Transform Based First-Order Statistical Texture Features for Hardwood Species Classification. Procedia Comput. Sci. 2015, 57, 214–221. [Google Scholar] [CrossRef]
- Arivazhagan, S.; Shebiah, R.N.; Ananthi, S.; Varthini, S.V. Detection of Unhealthy Region of Plant Leaves and Classification of Plant Leaf Diseases Using Texture Features. Agric. Eng. Int. CIGR J. 2013, 15, 211–217. [Google Scholar]
- Barmpoutis, P.; Dimitropoulos, K.; Barboutis, I.; Grammalidis, N.; Lefakis, P. Wood Species Recognition through Multidimensional Texture Analysis. Comput. Electron. Agric. 2018, 144, 241–248. [Google Scholar] [CrossRef]
- Garforth, J.; Webb, B. Lost in the Woods? Place Recognition for Navigation in Difficult Forest Environments. Front. Robot. AI 2020, 7, 541770. [Google Scholar] [CrossRef] [PubMed]
- Pang, Z.; Zhang, G.; Tan, S.; Yang, Z.; Wu, X. Improving the Accuracy of Estimating Forest Carbon Density Using the Tree Species Classification Method. Forests 2022, 13, 2004. [Google Scholar] [CrossRef]
- Sothe, C.; Dalponte, M.; de Almeida, C.M.; Schimalski, M.B.; Lima, C.L.; Liesenberg, V.; Miyoshi, G.T.; Tommaselli, A.M.G. Tree Species Classification in a Highly Diverse Subtropical Forest Integrating UAV-Based Photogrammetric Point Cloud and Hyperspectral Data. Remote Sens. 2019, 11, 1338. [Google Scholar] [CrossRef]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature Selection: A Data Perspective. ACM Comput. Surv. 2018, 50, 1–45. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A Survey on Feature Selection Methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Fu, B.; Liu, M.; He, H.; Lan, F.; He, X.; Liu, L.; Huang, L.; Fan, D.; Zhao, M.; Jia, Z. Comparison of Optimized Object-Based RF-DT Algorithm and SegNet Algorithm for Classifying Karst Wetland Vegetation Communities Using Ultra-High Spatial Resolution UAV Data. Int. J. Appl. Earth Obs. Geoinf. 2021, 104, 102553. [Google Scholar] [CrossRef]
- Razmjoo, A.; Xanthopoulos, P.; Zheng, Q.P. Online Feature Importance Ranking Based on Sensitivity Analysis. Expert Syst. Appl. 2017, 85, 397–406. [Google Scholar] [CrossRef]
- Jeong, Y.-S.; Kang, I.-H.; Jeong, M.-K.; Kong, D. A New Feature Selection Method for One-Class Classification Problems. IEEE Trans. Syst. Man Cybern. Part C 2012, 42, 1500–1509. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Feature Name | Dimension |
|---|---|
| mean_h, mean_s, mean_v, | 3 |
| Texture property | 5 |
| Shape property | 7 |
| Power spectrum | 8 |
| Weibull coefficients | 2 |
| MSCN coefficients | 18 |
| DCT coefficients | 4 |
| Wavelet coefficients | 88 |
| Feature | Spearman | mRMR | RelieF | Combined Ranking |
|---|---|---|---|---|
| Shape_property.1 | 8 | 8 | 2 | 6 |
| Texture_property.4 | 9 | 1 | 1 | 2 |
| mean_s | 3 | 4 | 4 | 2 |
| Weibull_distribution.1 | 1 | 6 | 3 | 1 |
| MSCN coefficients.11 | 5 | 10 | 10 | 10 |
| Wavelet_coefficients.11 | 7 | 3 | 5 | 4 |
| Wavelet_coefficients.23 | 6 | 9 | 9 | 9 |
| Wavelet_coefficients.25 | 1 | 7 | 6 | 4 |
| Wavelet_coefficients.29 | 11 | 10 | 6 | 11 |
| Wavelet_coefficients.47 | 4 | 5 | 10 | 6 |
| Wavelet_coefficients.72 | 10 | 2 | 8 | 8 |
| Eucommia | Metasequoia | Sycamore | Acer truncatum Bunge | Ginkgo | |
|---|---|---|---|---|---|
| Shape_property.1 | 6 | 6 | 2 | 5 | 1 |
| Texture_property.4 | 5 | 2 | 6 | 7 | 2 |
| mean_s | 6 | 8 | 4 | 2 | 6 |
| Weibull_distribution.1 | 1 | 1 | 3 | 2 | 3 |
| Wavelet_coefficients.11 | 4 | 7 | 7 | 6 | 8 |
| Wavelet coefficients.25 | 2 | 4 | 5 | 1 | 4 |
| Wavelet_coefficients.47 | 8 | 2 | 1 | 4 | 5 |
| Wavelet_coefficients.72 | 3 | 4 | 8 | 8 | 6 |
| Precision | Recall | F1-score | |
|---|---|---|---|
| Eucommia | 0.731 | 0.661 | 0.695 |
| Sycamore | 0.771 | 0.694 | 0.736 |
| Ginkgo | 0.674 | 0.582 | 0.639 |
| Metasequoia | 0.716 | 0.595 | 0.647 |
| Acer truncatum Bunge | 0.649 | 0.612 | 0.626 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, X.; Kan, J. The Sensitivity Feature Analysis for Tree Species Based on Image Statistical Properties. Forests 2023, 14, 1057. https://doi.org/10.3390/f14051057
Shi X, Kan J. The Sensitivity Feature Analysis for Tree Species Based on Image Statistical Properties. Forests. 2023; 14(5):1057. https://doi.org/10.3390/f14051057
Chicago/Turabian StyleShi, Xin, and Jiangming Kan. 2023. "The Sensitivity Feature Analysis for Tree Species Based on Image Statistical Properties" Forests 14, no. 5: 1057. https://doi.org/10.3390/f14051057