1. Introduction
An estimated 3 trillion trees, mostly in forests that cover 30% of the Earth’s landmass, are important for maintaining our ecosystems and counteracting climate change [
1,
2]. The management, maintenance and conservation of forests are enormous operations. Forests need to be adapted to stay resilient in the face of new rainfall patterns, increased wind, more generations of insect pests per year, and the arrival of new pathogens [
3]. At present, forests are monitored on a large scale from space [
4], and more locally with aerial surveys [
5]. However, many aspects of tree growth and health can best be determined from below the canopy, or require access to the ground. Conceivably, a sparse swarm of rovers could assist in monitoring forests [
6]. The swarm could gather spatio-temporal information, such as census data on healthy tree saplings, or visually inspect bark and leaves for symptoms of devastating invasive diseases [
7]. A swarm could collaboratively estimate the locations of forest areas that are prone to wildfires, enabling precise preventive measures [
8]. Importantly, the individual rovers of the swarm have to be small-sized (portable) to reduce their environmental impact, such as from soil compaction [
9]. The rovers also have to be inexpensive to allow their large-scale deployment as a swarm.
Off-trail navigation in forest environments is an open problem in field robotics [
10]. Forest environments comprise a variety of different vegetation such as leaves, twigs, fallen branches, grass, shrubs, standing and fallen trees, and overhanging bushes. Rovers are required to predict the terrain traversability over a priori unknown forest terrain relying solely on onboard sensors, and do so under varying lighting and weather conditions [
11,
12]. Furthermore, the prediction of the rover–terrain interactions is not only impacted by terrain and the weather conditions (such as wet versus dry foliage), but also susceptible to changes experienced by the rover in prolonged operation (e.g., mud sticking to the rover’s wheels) [
13]. For small rovers with a low camera viewpoint, which is easily occluded by compliant vegetation such as grass or overhanging leaves, forest navigation is especially challenging.
Off-road terrain traversability for ground robots has been investigated in numerous studies (c.f. [
14,
15]), often motivated by the DARPA programs [
16,
17]. Machine learning algorithms for off-road navigation typically utilize hand-crafted features [
18] engineered by experts based on the application scenario and the rover’s operating environment. In structured environments, these rely mainly on geometry (e.g., slope, step and roughness features of city walkways [
19]) and appearance (color and texture of obstacles [
20]). Unstructured environments typically require engineered features of proprioceptive information such as drive electrical currents, acceleration forces and chassis orientation on uneven terrain [
18,
21], in addition to geometry and appearance-based features. For example, features engineered from proprioceptive sensors, particularly the mean slope of terrain profiles from chassis orientation, were used in [
22] for mobility prediction models.
Hand-crafted features have limitations for terrain traversability analysis in off-road environments. Features engineered from geometric data, such as terrain roughness and slope, are often unreliable in unstructured environments due to limited depth information [
23,
24]. Estimated digital elevation maps can be incomplete due to occlusions [
23]. Compliant vegetation, such as high grass, is difficult to be captured with engineered geometry-based features [
24]. Hand-crafted visual features (e.g., color and textural descriptors) suffer from environmental factors such as high-contrast lighting [
25,
26]. In summary, hand-crafted features are impaired by engineering bias and often lead to poor discriminative power [
27]. Hand-crafted features that are robust to compliant objects, deep shadows, and motion blur are complicated to engineer, computationally expensive to run, and often brittle in varying environmental conditions.
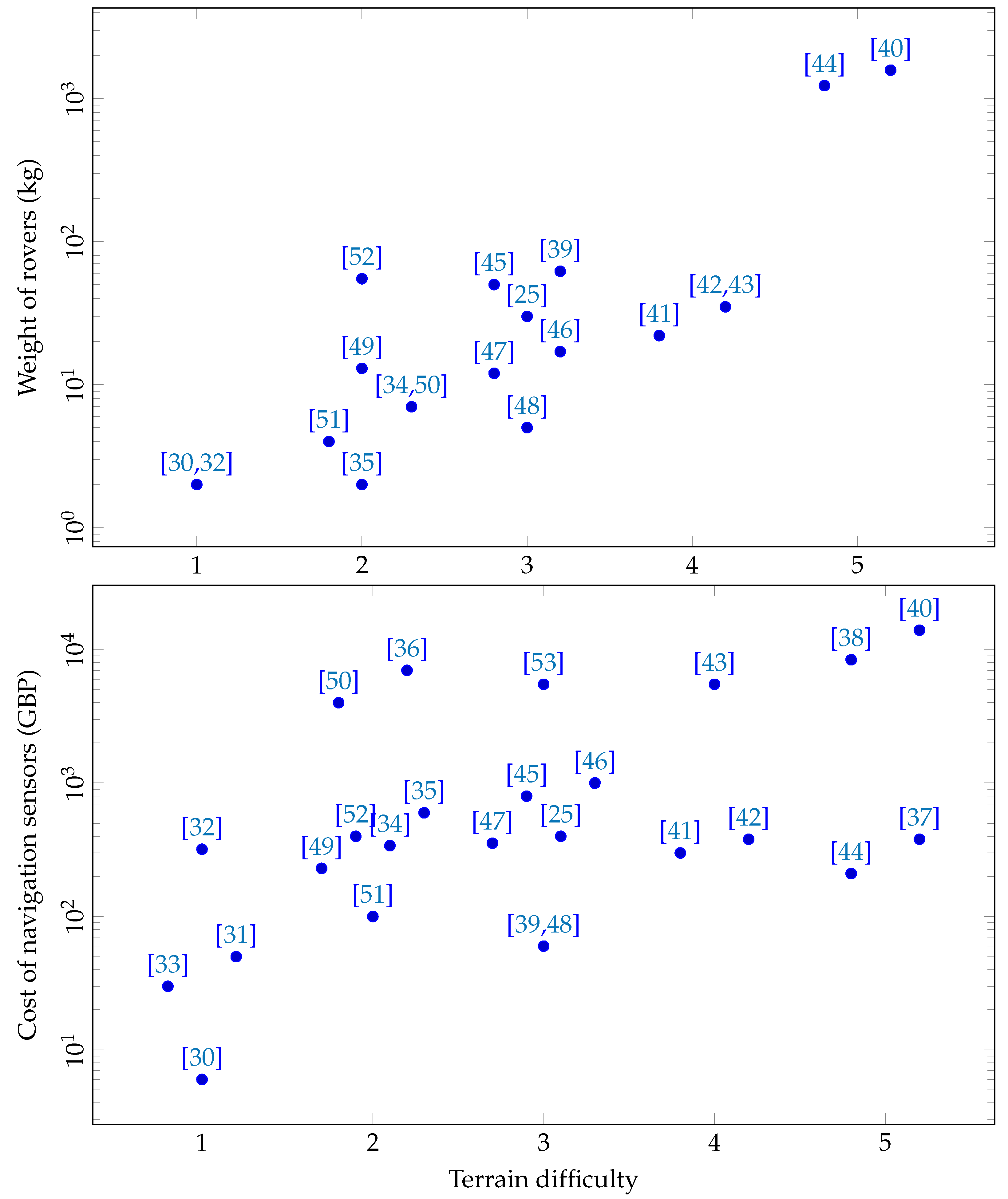
In contrast to hand-crafting, many recent studies have turned to self-learned features trained using end-to-end learning to directly output steering actions for a rover (see
Figure 1 and
Table A1). Steering prediction algorithms following end-to-end learning have been successfully applied in structured environments, such as in mazes [
28,
29], following colored tracks [
30,
31,
32,
33] and corridors [
25,
34,
35,
36]. In outdoor environments, algorithms using end-to-end learning have demonstrated some promising results in autonomous driving on well-paved roads in structured urban environments under varying lighting and weather conditions [
37,
38,
39,
40]. Moreover, recently, a few studies have investigated end-to-end learning algorithms for off-road navigation [
41,
42,
43]. For example, using control policy predictions of steering and throttle commands trained using an end-to-end imitation learning approach, a 1/5-scaled RC vehicle was able to successfully navigate a dirt track—without obstacles—at high speed [
41]. However, the application of end-to-end learning for small-sized rovers navigating forest environments comprising a variety of compliant (grass, shrubs) and rigid obstacles (fallen branches, tree stems) from a viewpoint tens of centimeters off the ground remains to be investigated.
We propose a low-viewpoint navigation system for small-sized forest rovers, trained using end-to-end learning. This approach targets the uncharted bottom-right region in
Figure 1. A mobile platform is designed to easily capture and automatically label training data of forest scenes, RGB images at a low-viewpoint. Four different state-of-the-art lightweight convolution neural networks—DenseNet-121, MobileNet-V1, MobileNet-V2 and NASNetMobile—have been investigated for multiclass classification of steering actions. The models are trained using real-world forest data captured from the Southampton Common woodlands (Hampshire, UK). From the four models, the MobileNet-V1 and MobileNet-V2 are selected for field experiments due to their high accuracy and runtime performance. To sidestep the additional challenges of designing a high-endurance locomotion system for a small-sized low-cost rover, in this study, we focus solely on the navigation system. Therefore, the mobile platform is pushed manually by an operator, guided by the steering actions of the classification model running on a Raspberry Pi onboard the platform. The developed low-viewpoint navigation algorithm uses a 128 × 96 resolution RGB image. Navigation using the developed classification model has been extensively tested in field trials, successfully navigating a total of over 3 km of real-world forest terrain under five different weather conditions and four different times of day, including high-contrast sunlight and low-lighting at dusk.
2. Materials and Methods
Our algorithm for forest navigation employs deep neural networks to train a multiclass classification model following end-to-end learning. Training data for the classification comprise RGB images and corresponding steering actions, obtained by an operator pushing the mobile platform through the forest. The trained models infer steering actions from RGB images in real-time, on an onboard embedded computer, with sufficient accuracy to facilitate navigation of the forest environment.
Training data for forest navigation: Data was collected at the Southampton Common (Hampshire, UK), a large area of over featuring woodlands, rough grassland, ponds, wetlands and lakes. Several paths of the woodlands, both on-trail and off-trail and totaling over 600 m, were selected for recording data. The selected paths comprised a number of different obstacles such as grass, bushes, fallen tree branches, leaf litter, and fallen and standing trees.
The customized mobile platform was manually pushed by an operator along the paths to be recorded (for platform details, see [
11]). On the platform, two incremental photoelectric rotary encoders were attached to a CamdenBoss X8 series enclosure box (L × W × H: 18.5 × 13.5 × 10 cm). Two black polyurethane scooter wheels were mounted on either side of the enclosure, one for each encoder. The wheels were 10 cm in diameter and 2.4 cm in width to enable traversal over rough terrain. The encoders were connected to a Micropython enabled Adafruit ItsyBitsy M4 Express ARM board, which made the time stamped rotary encoder readings available over a USB connection. The enclosure was mounted at the end of a 1.21 m telescopic extension pole, allowing the operator to roll the enclosure on its wheels along the ground by pushing it forward while walking. Inside the enclosure, an Intel RealSense D435i camera was mounted 15 cm above the ground with a free field of view in the direction of motion. The rotary encoder data were time synchronized with the recorded RGB images from the camera at 30 frames per second, and recorded at the same rate. A laptop computer connected to the camera, and to the USB connection from the rotary encoders, was used to store the data.
The operator pushed the mobile platform along forest paths while performing go straight (GS), turn left (TL), turn right (TR) and go back (GB) actions. All the actions were performed as discrete movements to ensure the wheels of the mobile platform rotated smoothly on challenging forest terrain, to provide reliable encoder data. With the GS action, the platform was pushed straight approximately 50 cm forward. Rotatory actions of TL and TR pivoted the platform by approximately 15 along the yaw axis. Finally, the GB action rotated the platform by approximately 180. The actions allowed the operator to navigate the mobile platform through the forest, avoiding collisions by steering around the obstacles, and turning around when there were no traversable paths to circumvent the obstacles.
In total, 29,005 RGB images were recorded by the mobile platform. To automatically label the recorded RGB images for training the multiclass classification models, the left and right wheel encoder data were used to label the corresponding timestamped RGB images. The images were labeled as one of GS, TL, TR and GB according to the steering angle of the platform. A few of the GB labeled RGB images had to be manually re-labeled as TL or TR (around 1% of the recorded data), if there was a traversable path on the far left or far right of the image, respectively. Following the labeling, we had 19,573, 3037, 3527, and 2868 images for the GS, TL, TR and GB actions, respectively. Subsets of the recorded data were used for training (70%), validation (15%) and testing (15%) the multiclass classifier models (see
Table A2 in
Appendix A for details).
Classification models: The multiclass classification models are required to infer steering directions (GS, TL, TR and GB) from input RGB images in real time. As the models are to be deployed on low-cost embedded computers, for our study, we compare four state-of-the-art light-weight neural networks—DenseNet-121 [
54], MobileNet-V1 [
55], MobileNet-V2 [
56] and NasNetMobile [
57]. The implementations of these networks are available at Keras (Keras is a deep learning API written in Python, see
https://keras.io/api/applications, accessed on 23 November 2020)
The initial weights of the DenseNet-121, MobileNet-V1, MobileNet-V2 and NasNetMobile models had been pre-trained on the ImageNet dataset [
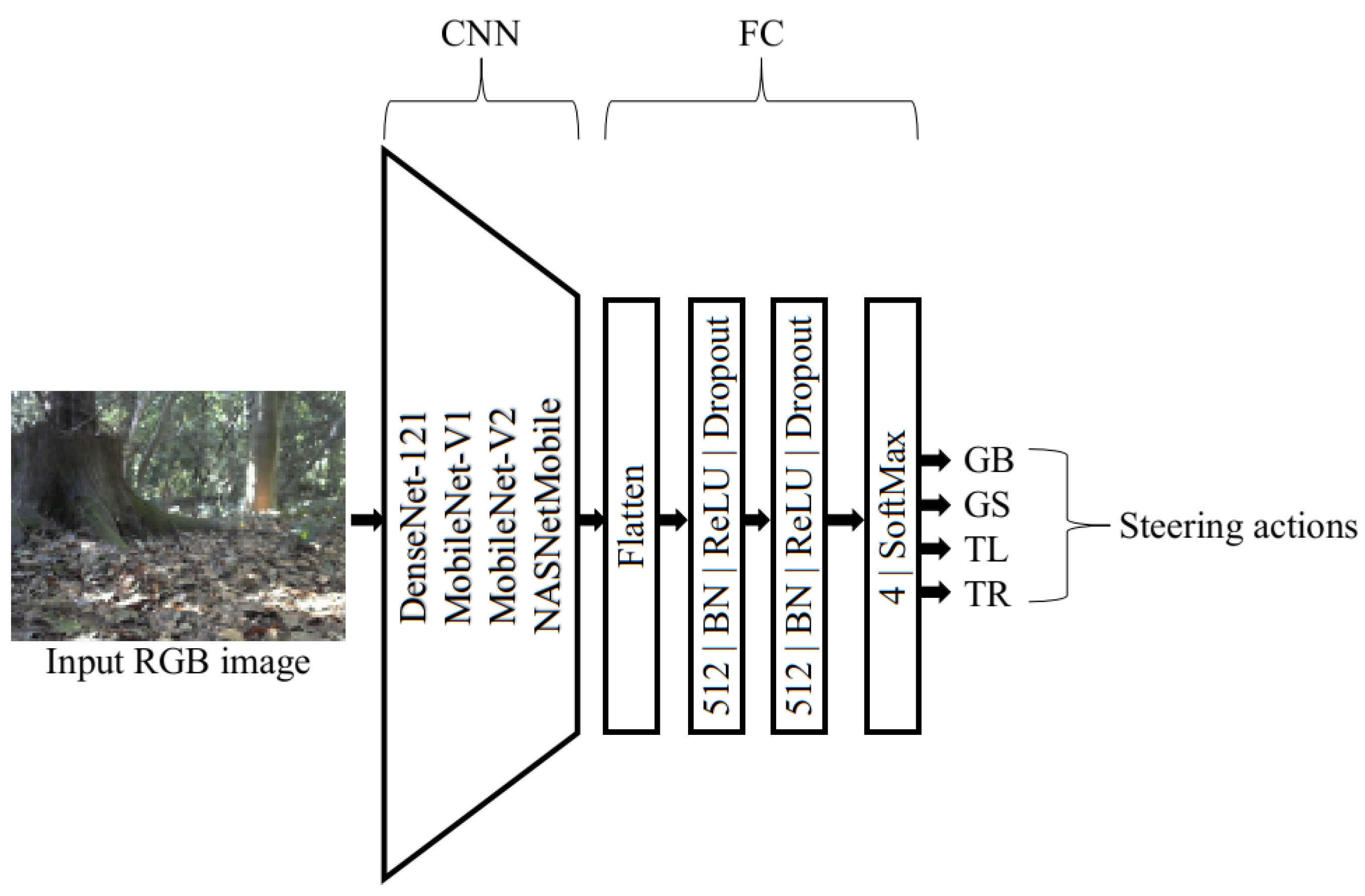
58] to speed up the model convergence. Subsequently, we unfroze all the layers in the investigated models and retrained them on our forest data. For steering direction prediction, a flattened convolutional layer followed by three fully connected (FC) layers were added to the models (see the architecture in
Figure 2). The first two FC layers had a rectified linear unit activation, and the last FC layer employed a softmax activation for steering direction selection. Batch normalization and dropout operations (probability of 0.2) were employed after each FC layer to prevent overfitting of the data [
59]. For a fair comparison across the models, all the RGB images in the training data were downsampled to 224 × 224. Each of the models were trained for 20 epochs with a batch size of 16, using the Adam optimizer with a categorical cross-entropy loss (log-loss) function [
60]. All of the models were implemented in TensorFlow [
61] and Keras [
62], and trained on a NVIDIA GTX 1080ti (11G) GPU. Training took approximately 16h (DenseNet-121), 7h (MobileNet-V1), 8h (MobileNet-V2) and 10h (NASNetMobile) on a NVIDIA GTX 1080ti (11G) GPU for 224 × 224 resolution RGB images. The trained Tensorflow models were compiled into TensorFlow-Lite models [
63], resulting in over a ten-fold improvement in runtime performance.
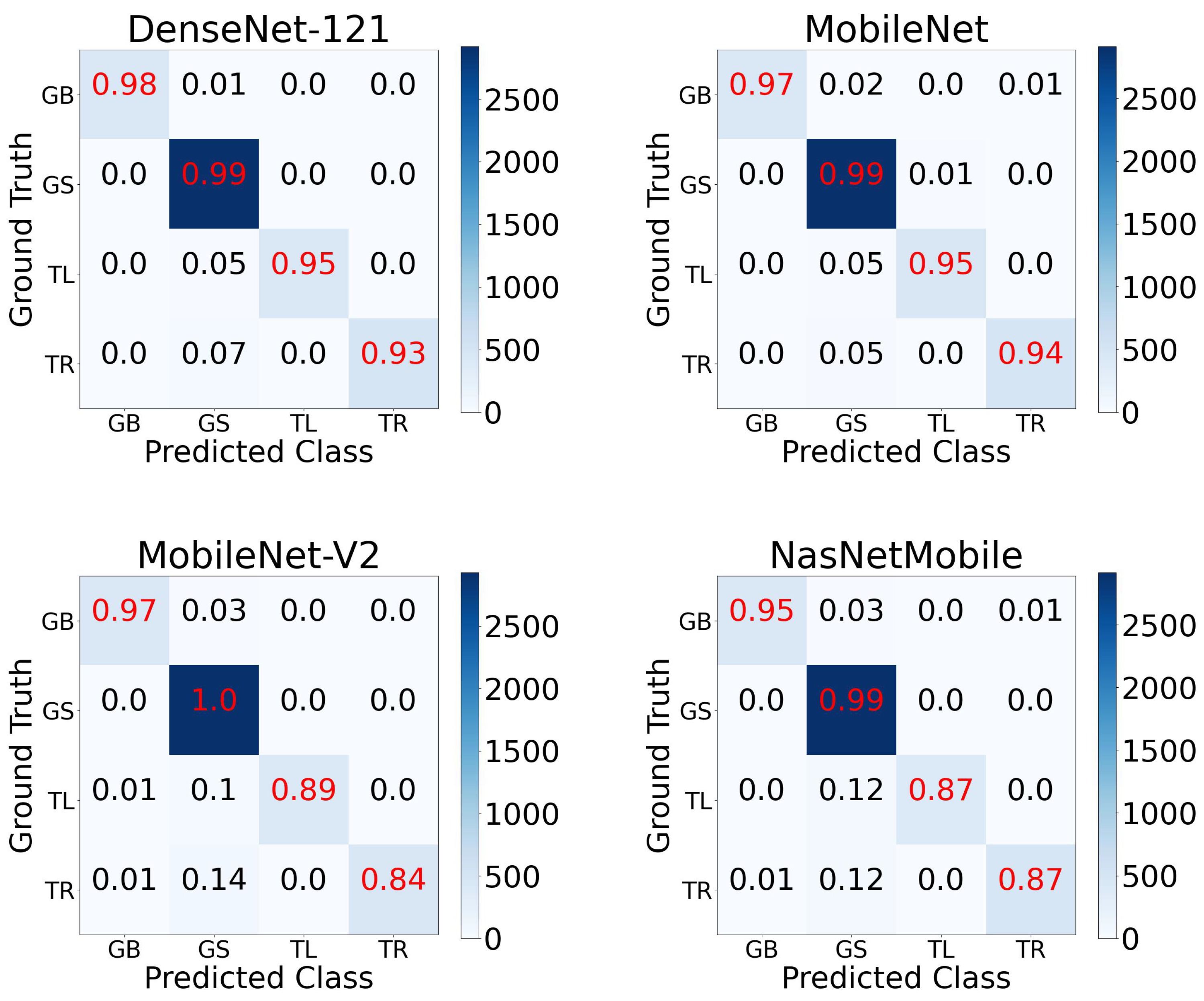
The trained DenseNet-121, MobileNet-V1, MobileNet-V2 and NASNetMobile models all achieved a high classification performance on the tested RGB images (see the accuracy and log-loss in
Table 1). In particular, all four models were largely able to accurately classify the GS, TL, TR and TB steering actions, with the DenseNet-121 model attaining a high overall accuracy across all four classes (see confusion matrix in
Figure 3). The high accuracy in steering action classification was further supported by a 5-fold cross-validation (see the details in
Table A4 in
Appendix A). However, the DenseNet-121 model was impaired by a high runtime, requiring over twice the time as the other models to classify the images on a Raspberry Pi 4 (see the runtime in
Table 1). Therefore, in considering the tradeoff between accuracy and runtime, the MobileNet-V1 and MobileNet-V2 were selected for field experiments.
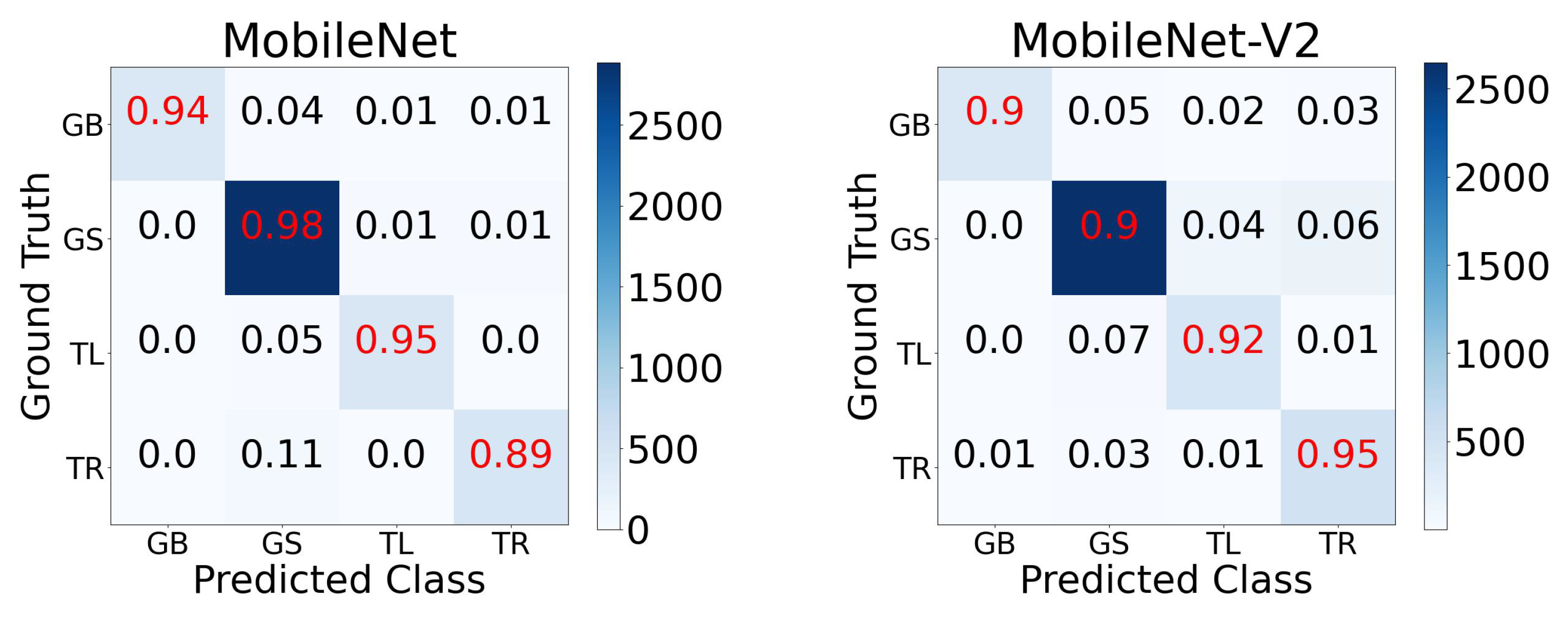
For the field experiments, the runtimes of the selected MobileNet-V1 and MobileNet-V2 models were improved by downsampling the resolution of the 224 × 224 RGB images input into the model. Therefore, these two models were retrained following the same experimental setup (20 epochs with a batch size of 16) after downsampling the RGB images of the training data to 128 × 128, 128 × 96, 64 × 64, and 32 × 32, in separate and independent experiments. The results from our parameter tuning experiments indicated a steep drop in accuracy at resolutions below 128 × 96 (see
Table A3 in
Appendix A for MobileNet-V1; similar trends in accuracy were observed for MobileNet-V2). Consequently, the MobileNet-V1 and MobileNet-V2 models trained with 128 × 96 resolution images (see the performance details in
Table 2, the 5-fold cross-validation in
Table A5 in
Appendix A, and the confusion matrix in
Figure 4) were deployed for the field experiments.
Mobile platform for field experiments: The mobile platform deployed to assess our multiclass classification models in field experiments was similar to the platform used to gather training data, but with a low-cost RGB webcam for capturing input images, and the addition of display hardware for the output steering commands to be visible to the operator (see the platform and operator in
Figure 5). A Logitech C270 HD webcam (diagonal 55
field of view) was mounted inside the enclosure (replacing the Intel RealSense D435i camera) at 18 cm above the ground and was connected to a Raspberry Pi 4. Additionally, a stripboard (9.5 × 12.7 cm) was fixed to two rectangular wooden blocks on the top of the enclosure, alongside two concentric NeoPixel rings of addressable RGB LEDs (Adafruit Industries, New York, NY, USA). The two NeoPixel rings were connected to the Raspberry Pi 4 (4 GB RAM) via a twisted pair (data) and a USB cable (power), while a Schmitt-trigger buffer (74LVC1G17 from Diodes Incorporated, Plano, Texas, USA) in the serial data line was used to overcome the capacitance of the long twisted pair wire. A HERO 9 (GoPro, San Mateo, CA, USA) action camera was also mounted on the telescopic pole 50 cm from the top of the enclosure for a third-person view high-resolution video recording of the field experiments.
The RGB images captured by the Logitech camera every four seconds—one control-cycle—were input into the multiclass classification model deployed on the Raspberry Pi. Subsequently, the classification model output a steering direction—one of GS, TL, TR and GB—which was displayed on the NeoPixel rings (see
Figure 5 for details on the direction indications). A fifth action, labeled waypoint, was introduced for the field experiments. The waypoint action superseded the direction outputs of the classification model. It prompted the operator to rotate the platform towards the direction of the goal waypoint. The action occurred every 10 control-cycles and in general could be based on GPS information.
3. Experiments
The field experiments to investigate the performance of the developed MobileNet-V1 and MobileNet-V2 multiclass classification models for forest navigation were performed in the Southampton Common woodlands. The experiments were performed for the following two scenarios: (i) following a long forest trail; and (ii) steering through a smaller but more challenging off-trail forest environment.
The performance of the classification models in navigating the forest was assessed with the following metrics: (i) the total distance traversed by the mobile platform to reach its target waypoint; and (ii) turning rate—the proportion of times the mobile platform steered left and right, which is zero for a straight-line trajectory to the target and in general is unbounded (arbitrary long detours and many arbitrary turns without forward progress).
Following a long forest trail: The mobile platform was navigated over a dried mud trail of around 120 m, comprising various compliant and rigid obstacles. Obstacles on and around the trail included dense bushes, tall grass, leaf litter, fallen branches, fallen tree trunks, and standing trees (see examples in
Figure 6A).
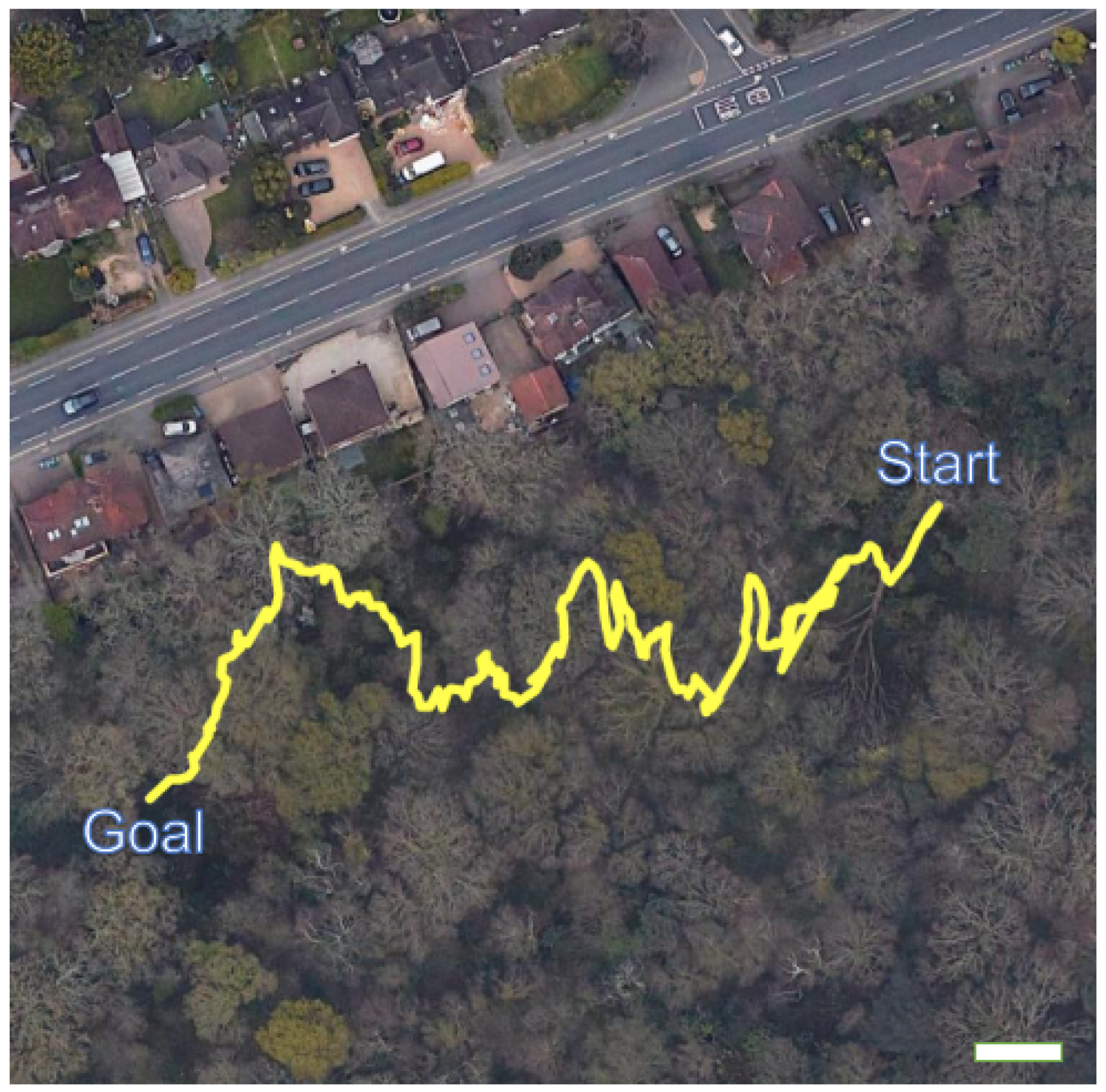
For the forest-trail experiments, the start and goal waypoints were positioned at (5056.1989 N, 124.0732 W) and (5056.1859 N, 124.1515 W), respectively (see
Figure 7). The actions GS, TL, TR, GB and waypoint (defined in
Section 2) were used to navigate the mobile platform towards the goal waypoint. As the goal was 210
SW of the start location, this bearing was used to rotate the mobile platform to face the goal, using a compass, when the waypoint action was triggered. The GB action was employed by the mobile platform to turn around and attempt to find an alternative path to circumvent large obstacles such as fallen tree trunks. If this action was triggered three times consecutively for the same obstacle, we assumed that there were no traversable paths around the obstacle; consequently, the operator would lift the platform over the obstacle, log the incident, and continue the experiment. The experiment was terminated when the platform reached the goal waypoint.
Forest-trail experiments were performed ten times for each of the MobileNet-V1 and MobileNet-V2 multiclass classification models under several different weather conditions and times of day (see details on the environmental conditions in
Table A6 of
Appendix A). Across all the experiments, the platform steered by the MobileNet-V1 and MobileNet-V2 models was able to reach the goal waypoint without sustaining any collisions. In navigating with the MobileNet-V1 model, the platform traversed a mean distance of
m with a turning rate of
(mean ± SD across ten replicates, see
Table 3). While the MobileNet-V2 model was also able to successfully navigate the platform, it was less efficient, steering left and right significantly more often (mean turning rate of
; Kruskal–Wallis test,
p < 0.001), and accumulating a slightly higher traversed mean distance of
m to reach the goal. Notably, in all the experiments, irrespective of the classification model employed for navigation, the platform had to be lifted over a large fallen tree that blocked the forest trail, as there were no traversable paths to circumvent the obstacle; the incident occurred once in each replicate.
Samples of the navigation performance of the MobileNet-V1 model in different forest scenes are shown in
Figure 8 (see more examples in the demonstration video of the
Supplementary Material). The platform is accurately directed to perform GS actions when there are no obstacles blocking its path, despite motion blur in the input RGB image (see an example of a clear trail in dense vegetation in
Figure 8A). Additionally, the classification model was able to steer the platform towards open spaces to avoid potential collisions (see
Figure 8B and C—turning towards the trail in diffuse and high contrast lighting). In scenarios where the robot was facing a close-range obstacle, or large untraversable areas in the distance, the GB action was successfully triggered to avoid potential collisions (see
Figure 8D—a fallen tree trunk covered in weeds and moss). Relatedly, the GB action was unnecessarily triggered only once, across all the experiments, when the platform encountered a fallen tree trunk and turned back rather than passing through the small hole between the trunk and the trail (see
Figure 8E).
Off-trail forest navigation: Experiments were performed in two unfrequented areas of the Southampton Common woodlands, labeled site A and site B, spanning around 400 m
and 200 m
of forest, respectively. The two sites included obstacles such as forest litter, standing trees and fallen tree branches. The sites differed in the nature of their environment (see examples in
Figure 6B). Site A had a high density of slender trees; it, however, had a very narrow corridor between waypoints for the mobile platform to slide through gaps between trees, requiring only a few turns to reach the destination. By contrast, site B comprised larger trees, tree stumps and fallen tree trunks on an uphill terrain.
Due to the small area of the off-trail environment, a round trip between waypoints was performed for each experiment. The platform was first steered by the navigation algorithm from the start to an intermediate waypoint. On reaching the intermediate waypoint, the platform was oriented back towards the start waypoint to navigate back to it. The experiment was terminated when the platformed reached the start waypoint. In our experiments, the start waypoints were located at (5056.1448 N, 124.0316 W) for site A and (5056.1568 N, 124.0155 W) for site B. Intermediate waypoints for the round trip were at (5056.1533 N, 124.0418 W) for site A and (5056.1666 N, 124.0240 W) for site B. Steering actions GS, TL, TR, GB and waypoint were used to navigate the platform. For the waypoint action, as the goal was always visible to the operator, the waypoint direction was updated through visual observation.
The off-trail experiments were performed ten times for each of the MobileNet-V1 and MobileNet-V2 classification models in several different weather conditions and times of day (see details on environmental conditions in
Table A7 of
Appendix A). Across all the replicates, for both the classification models, the mobile platform was able to successfully complete the round-trip path without sustaining any collisions, irrespective of the off-trail site, time of day and weather conditions. The platform steered by the MobileNet-V1 model traversed an average distance of
m (mean ± SD across 20 replicates from both sites A and B) in the round-trip, with a turning rate of
(see
Table 4). As with the forest trail experiments, the MobileNet-V2 model was less efficient in navigation, accumulating a higher average distance of
m to complete the round trip, and requiring a higher turning rate of
to avoid obstacles; the turning rate was significantly higher in site B, which comprised a high density of forest vegetation (Kruskal–Wallis test,
p < 0.001).
The performance of the MobileNet-V1 model in navigating the off-trail areas of the forest is illustrated with some examples in
Figure 9 (see more examples in the demonstration video of the
Supplementary Material). Despite low lighting conditions, the mobile platform was successfully steered between the narrow space among slender trees (see
Figure 9A). It was able to avoid obstacles with a sequence of turning actions (see examples in
Figure 9B,C of the platform avoiding a standing tree and tree stump). Moreover, to avoid potential collisions, the GB action was accurately triggered (see
Figure 9D of a long fallen tree trunk). Finally, as with the forest-trail experiments, the GB action was unnecessarily triggered only once when the platform failed to identify a narrow gap between two slender trees that it could be pushed through (see
Figure 9E).
4. Discussion
In this study, we have implemented a low-viewpoint navigation algorithm for inexpensive small-sized mobile platforms navigating forest environments. For navigation, an end-to-end learning model was trained to predict steering directions from RGB images of a monocular camera mounted on the mobile platform to direct the platform towards open traversable areas of the forest, while avoiding obstacles. A multi-sensor mobile platform was used to collect training data in a forest environment, totaling almost 30,000 low-viewpoint RGB images and the corresponding rotary encoder data. We trained four state-of-the-art lightweight convolution neural networks—DenseNet-121, MobileNet-V1, MobileNet-V2 and NASNetMobile—for multiclass classification of steering actions for RGB images. From the four models, the MobileNet-V1 and MobileNet-V2 were selected for field experiments due to their high accuracy and runtime performance. Our navigation algorithms were extensively tested in real-world forests under several different weather conditions and times of day. In field experiments, using 128 × 96 resolution monocular RGB images, the mobile platform was able to successfully traverse a total of over 3 km of forest terrain comprising small shrubs, dense bushes, tall grass, fallen branches, fallen tree trunks, ditches, small mounds and standing trees.
The developed multiclass classification model solely relies on appearance-based information for navigation. The addition of geometry-based information may potentially provide for a better discrimination of obstacles (e.g., small close-range obstacles vs. large obstacles in the distance) with similar visual features, and consequently enable more accurate steering actions. Geometry and appearance-based information have been successfully combined in few previous studies on end-to-end learning. For example, LiDAR sensor data have been integrated with RGB images from a camera as combined inputs for navigation in indoor environments [
32,
36]. Our classification models may be easily extended with the addition of geometry-based information. Moreover, for low-cost platforms, depth prediction models may be employed instead of expensive depth sensors such as LiDAR (e.g., see our previous study on low-viewpoint depth prediction models for forest environments [
64]).
Rovers operating in a forest are required to make safe and accurate steering decisions on a priori unknown and dynamically changing forest terrain. Therefore, a representation of the confidence of the predicted steering actions is essential for the navigation system [
65]. In our classification model, the distribution of the activation of the steering output neurons may be used to approximate the uncertainty in the selected action. More principled approaches such as Gaussian process models and Bayesian deep neural networks appear promising, but computationally expensive, to infer the uncertainty in steering directions, and consequently plan safe paths for the rover (e.g., [
66,
67]). Finally, hardware or behavior-based solutions (e.g., see [
68,
69]), to nudge and probe obstacles such as grass and dense bushes, may be integrated onto the rover platform to actively reduce the uncertainty in scene understanding.
The training data for our multiclass steering classification models are captured using a mobile platform steered by an operator walking through the forest. Consequently, the operator’s decisions on what obstacles may be overcome (e.g., pushing through grass, or rolling over a small fallen branch) will be distilled into the navigation algorithm of the rover. However, the training data for the steering classification models may be generalized to rovers with more advanced locomotion capabilities. Obstacles that could be overcome by a rover with better climbing ability than assumed by the operator will only occupy the area at the lower edge of the image frame. Such frames may be identified with image processing to automatically remove them from the training or relabel them with texture discrimination filters as compliant obstacles that may be successfully pushed through.
The aim of our study was to investigate the feasibility of using end-to-end learning for steering a small-sized platform at a low viewpoint through the forest. For our field experiments, coarse steering actions of turn-left and turn-right were employed for navigation. However, our approach could easily be extended to directly output wheel speeds to a rover, using techniques such as deep reinforcement learning [
47,
70]. Moreover, for the training of such a rover controller, the captured RGB images could be automatically labeled with a finer resolution of velocity vectors using the rotary encoder data from our mobile platform.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








