
Development of a Robust Machine Learning Model to Monitor the Operational Performance of Fixed-Post Multi-Blade Vertical Sawing Machines

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Machine Description, Observed Functions and Data Collection
2.2. Data Processing
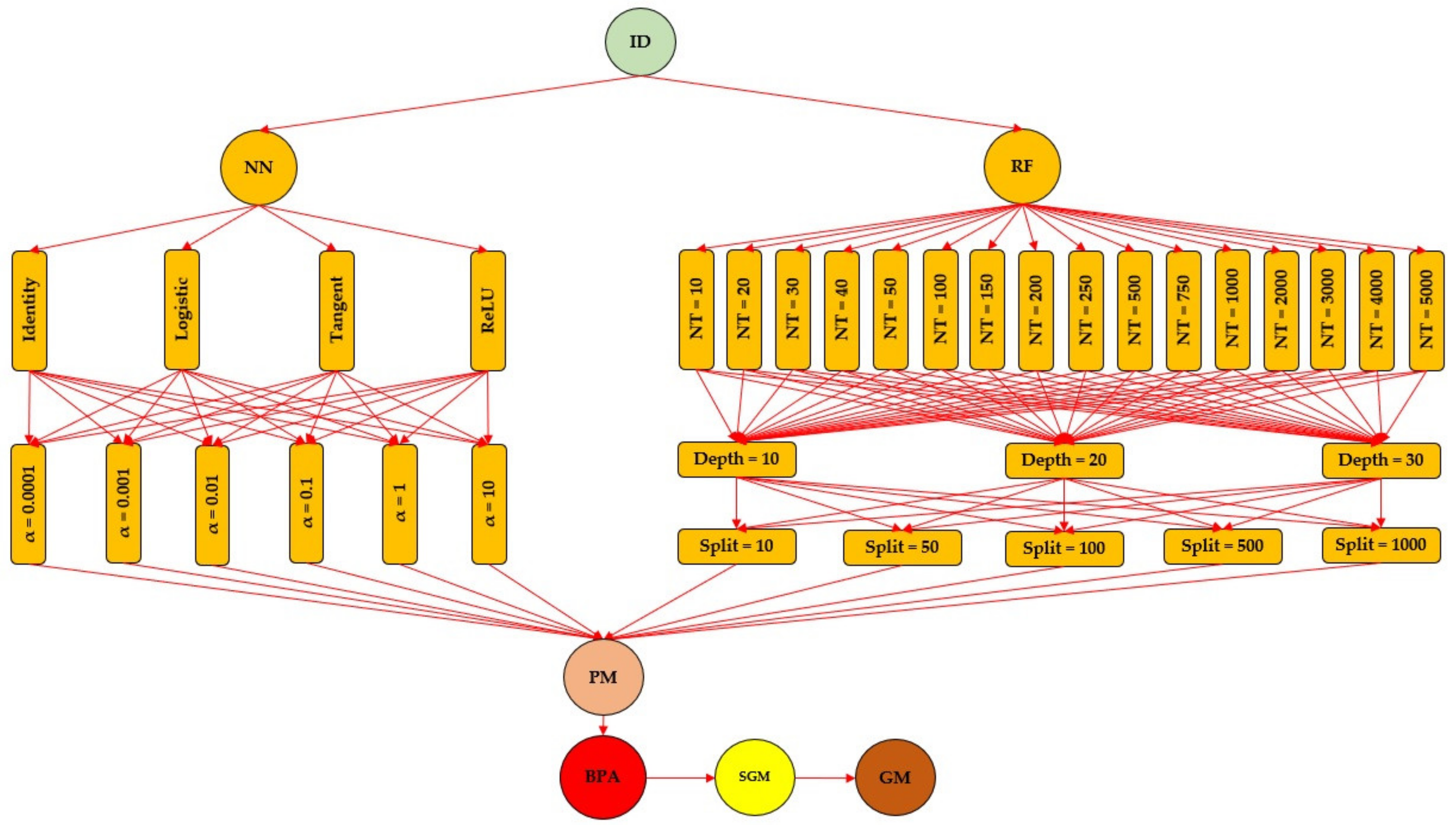
2.3. Machine Learning Algorithms
2.4. Computer Architecture and Software Used—Performance Evaluation
3. Results
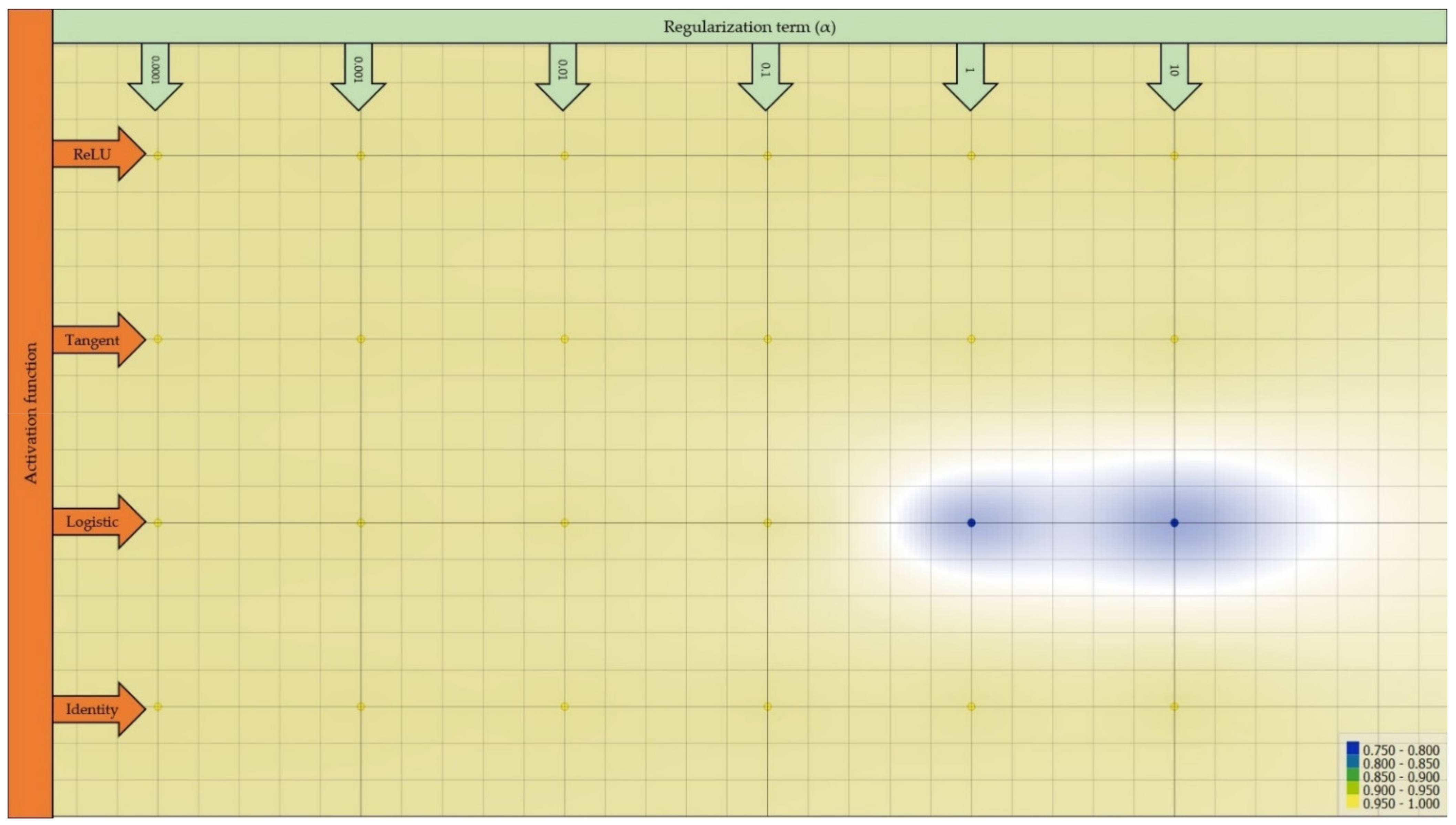
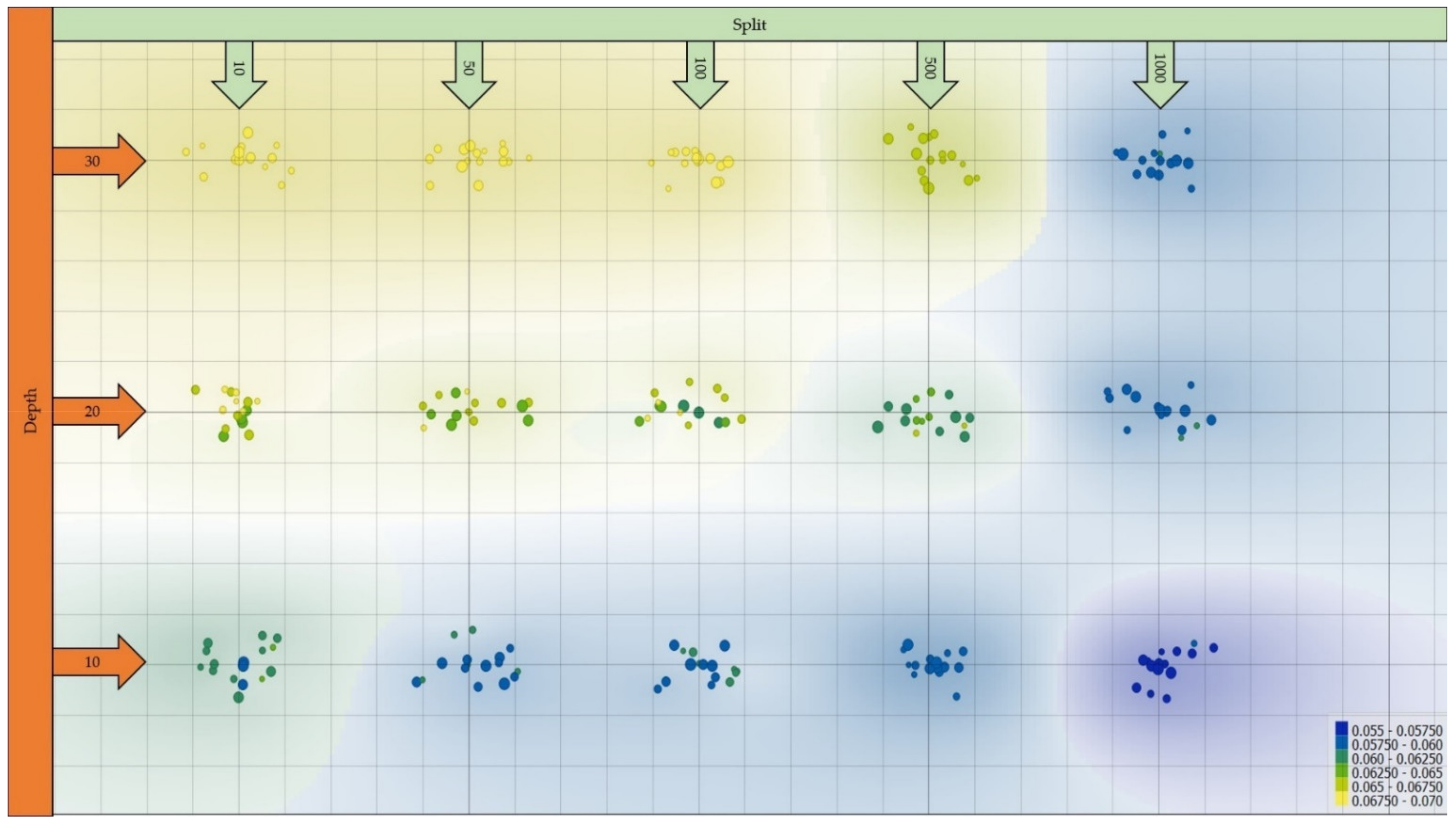
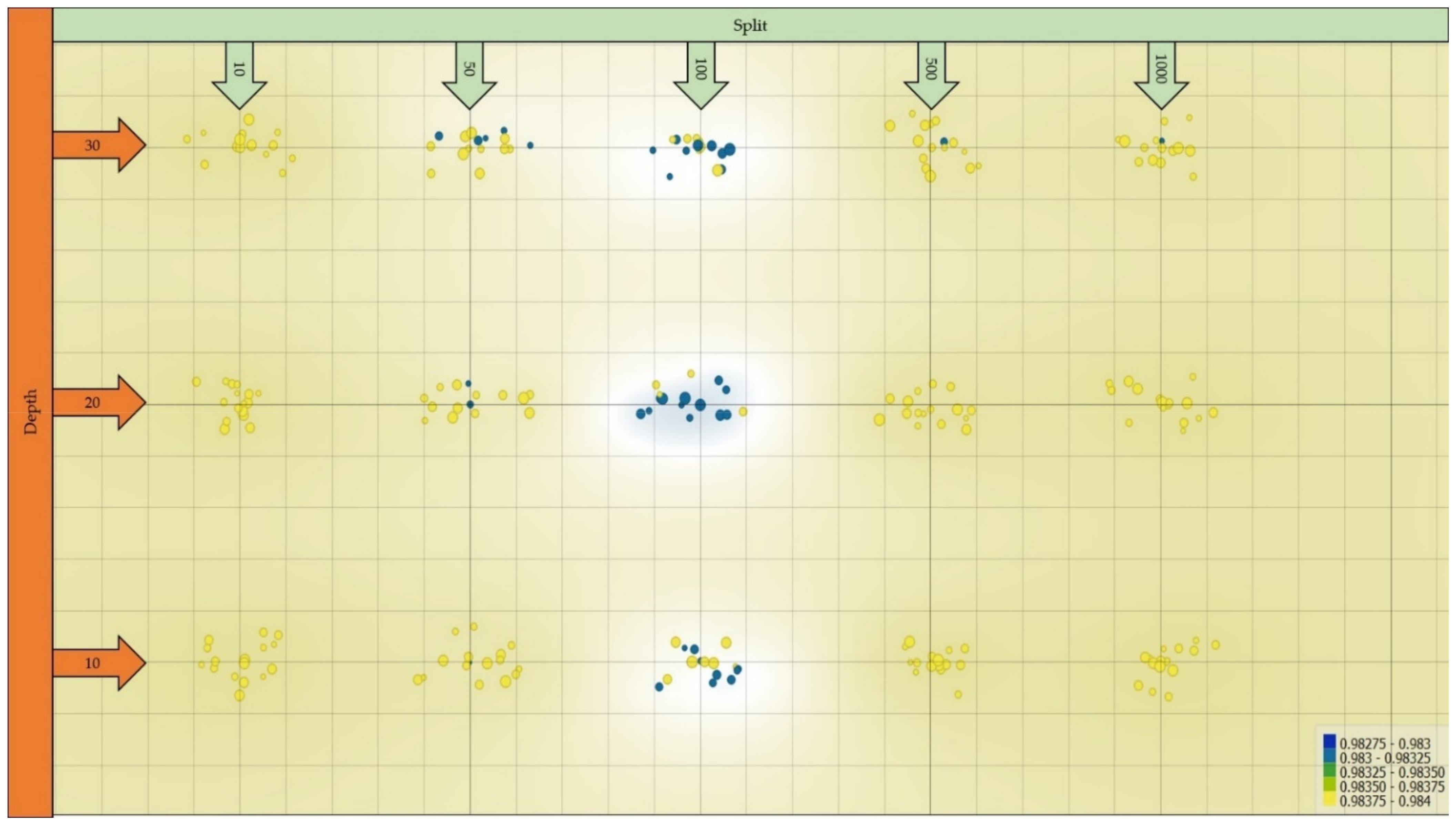
3.1. Best-Performing Model Architecture
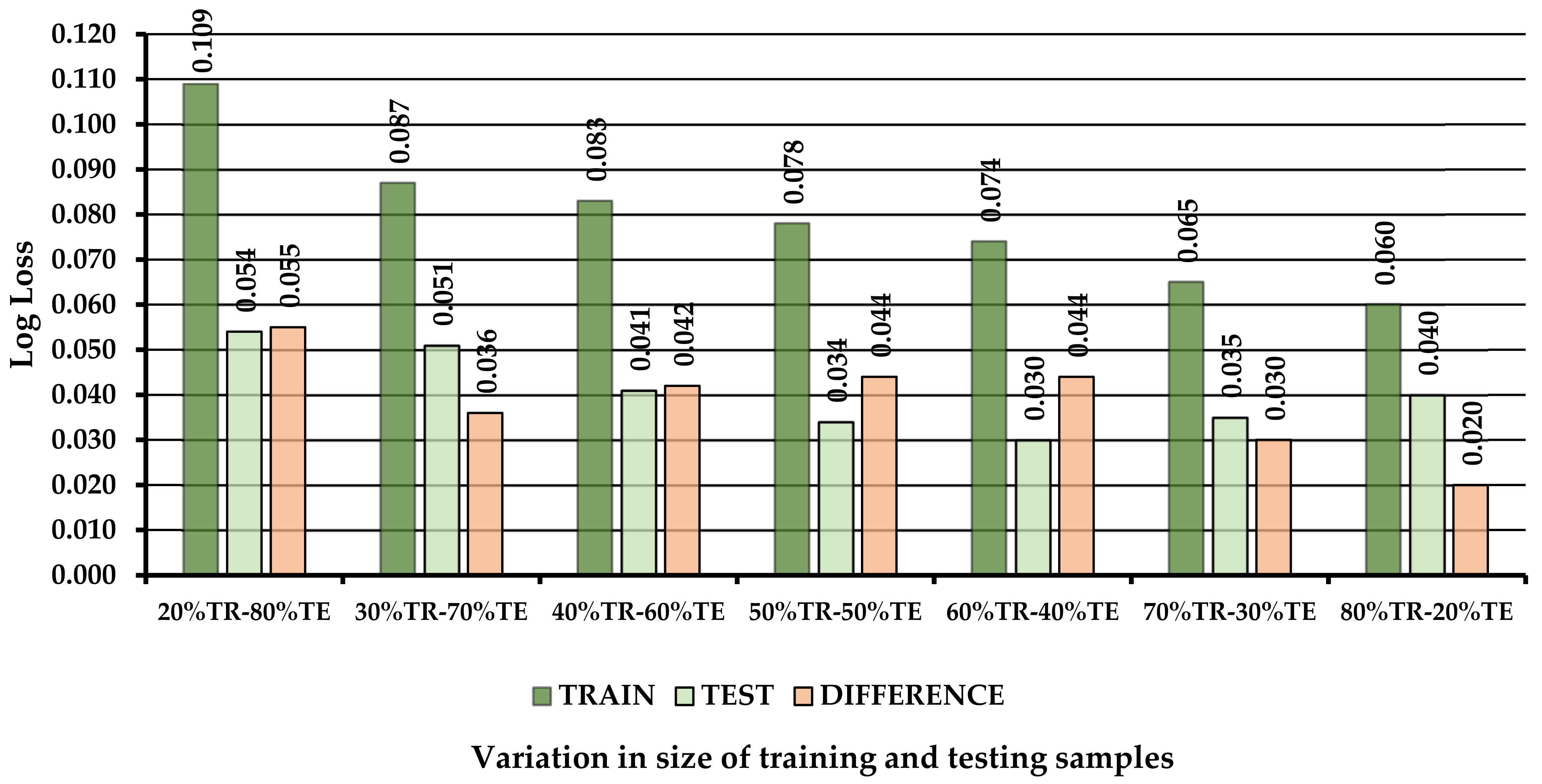
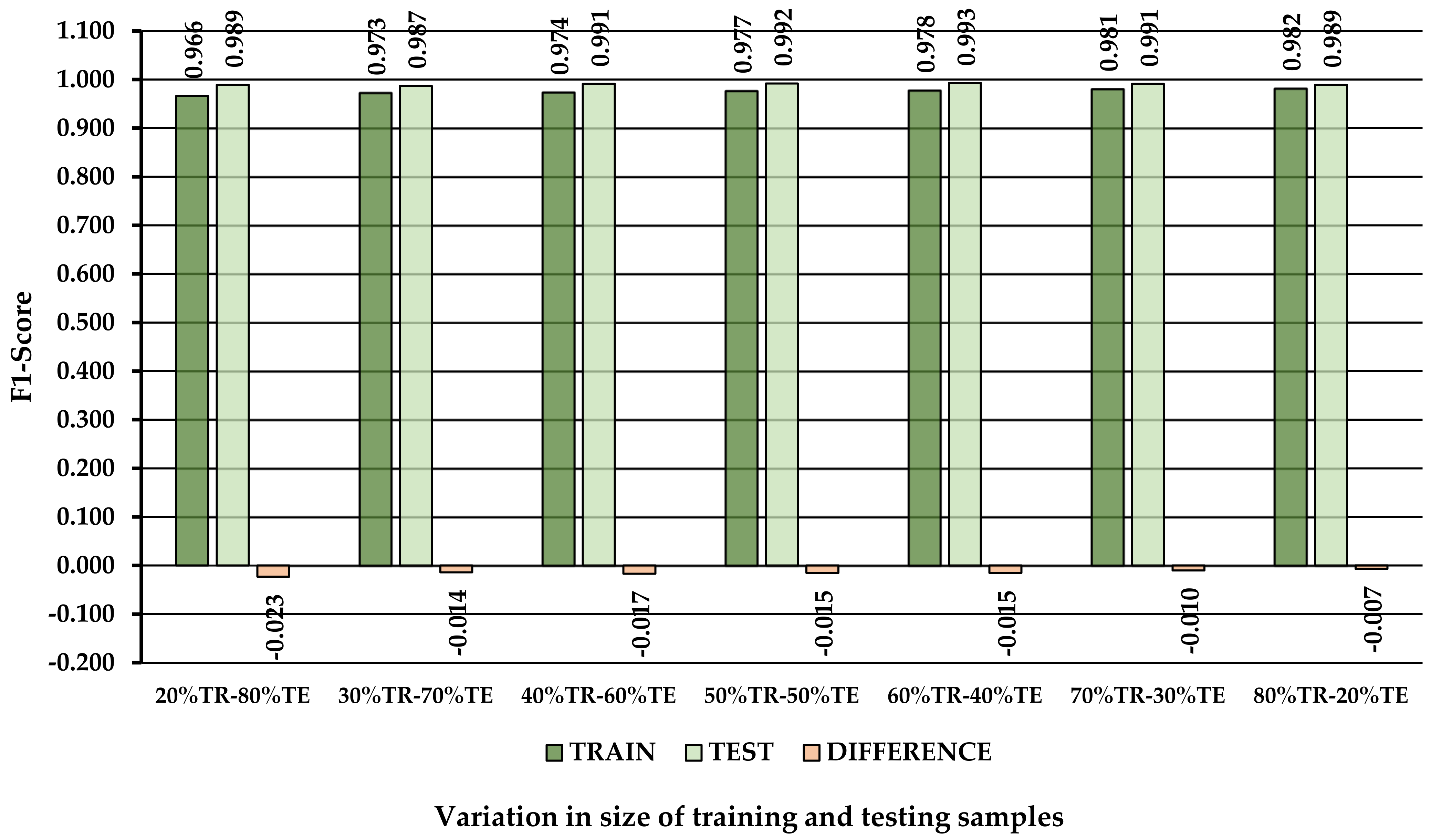
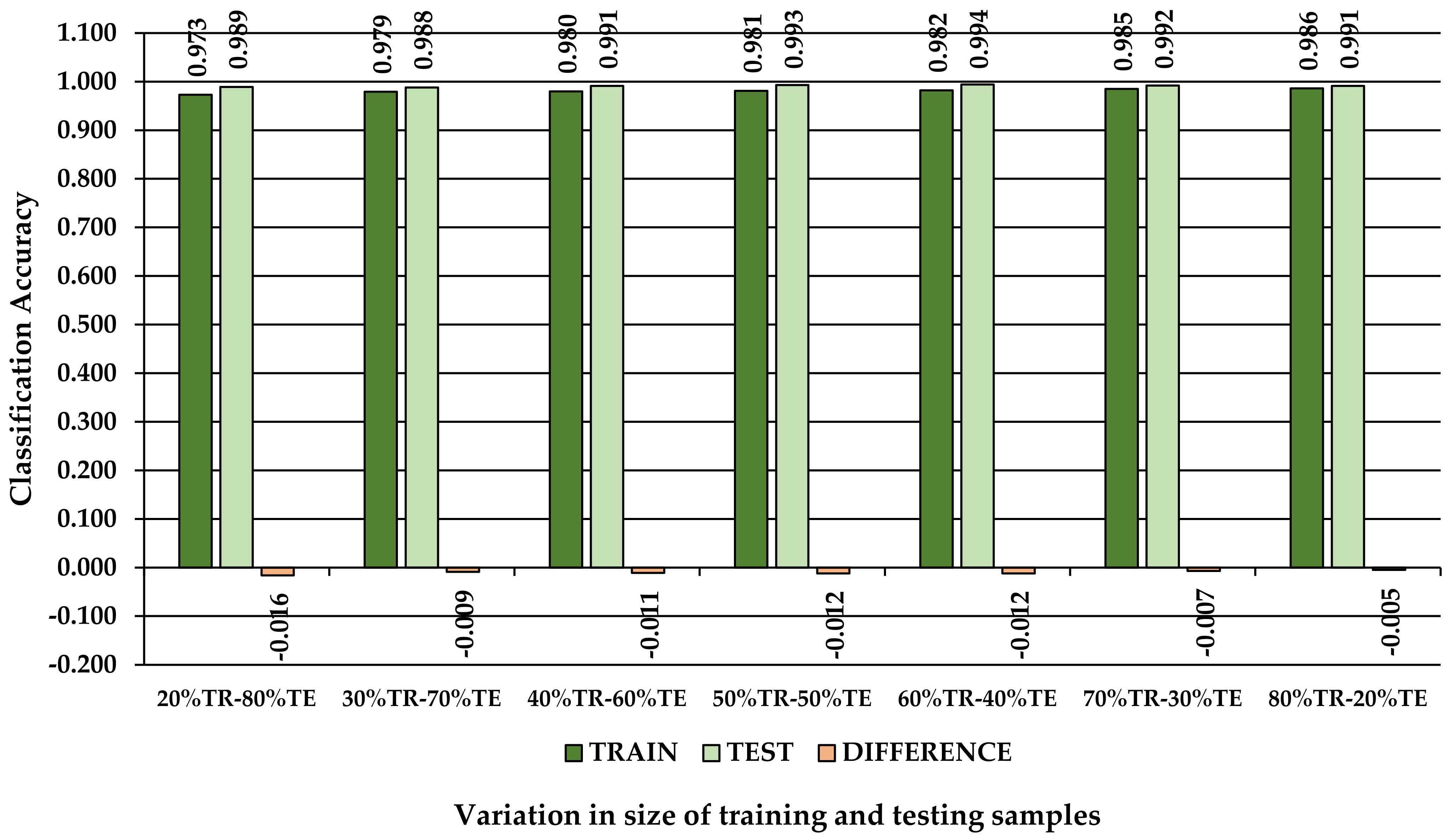
3.2. Effect of Data Share in the Training and Testing Subsets on Classification Performance
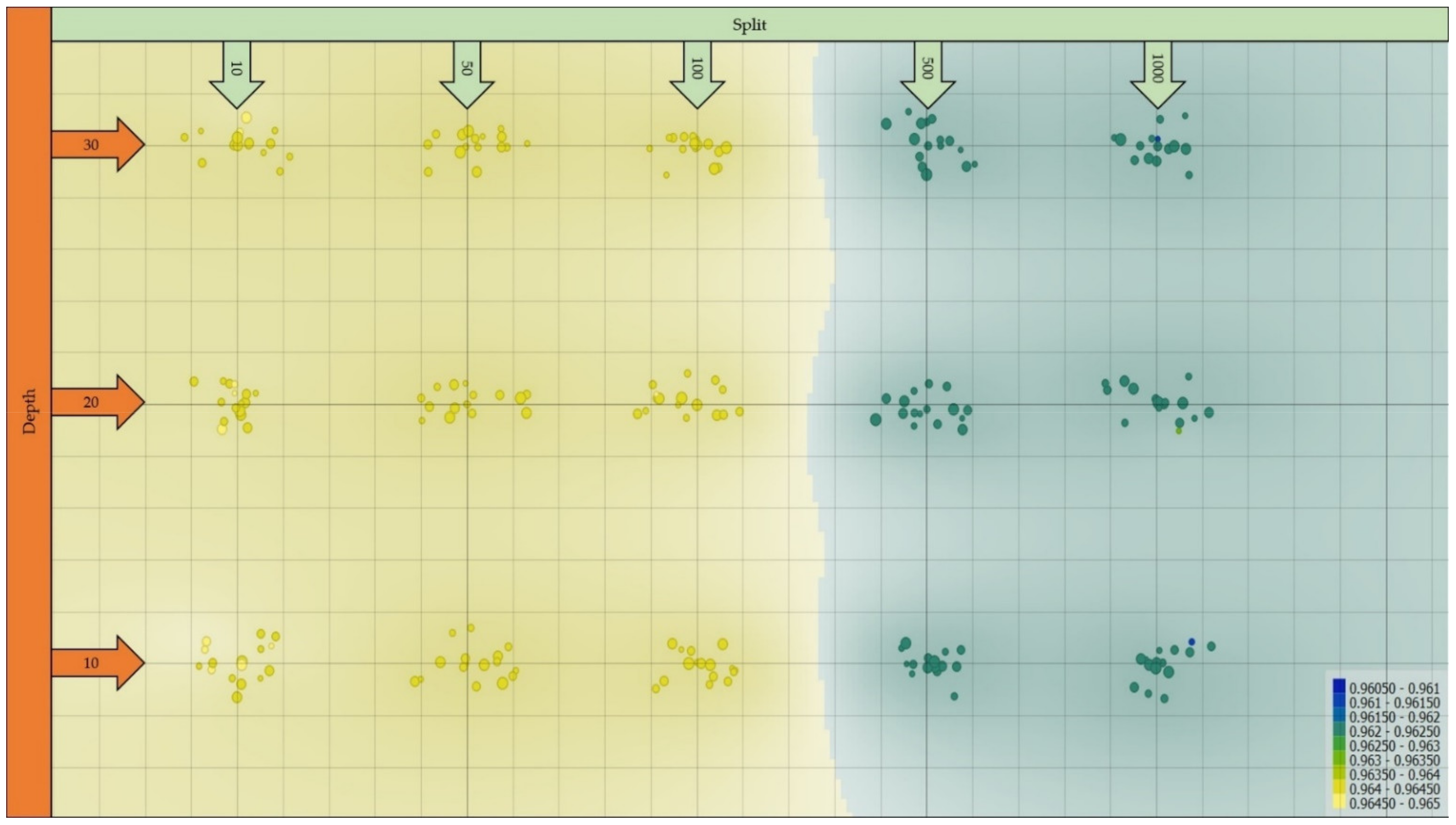
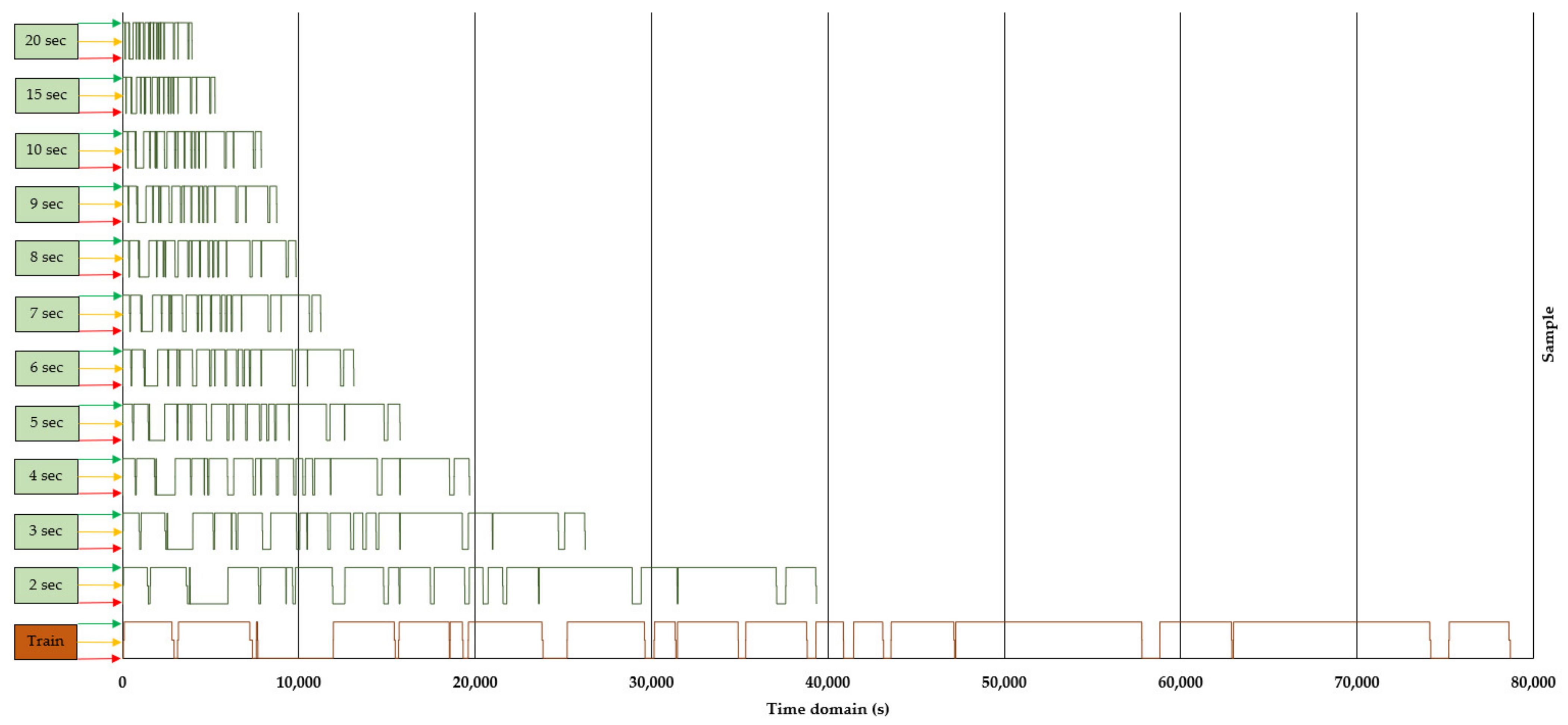
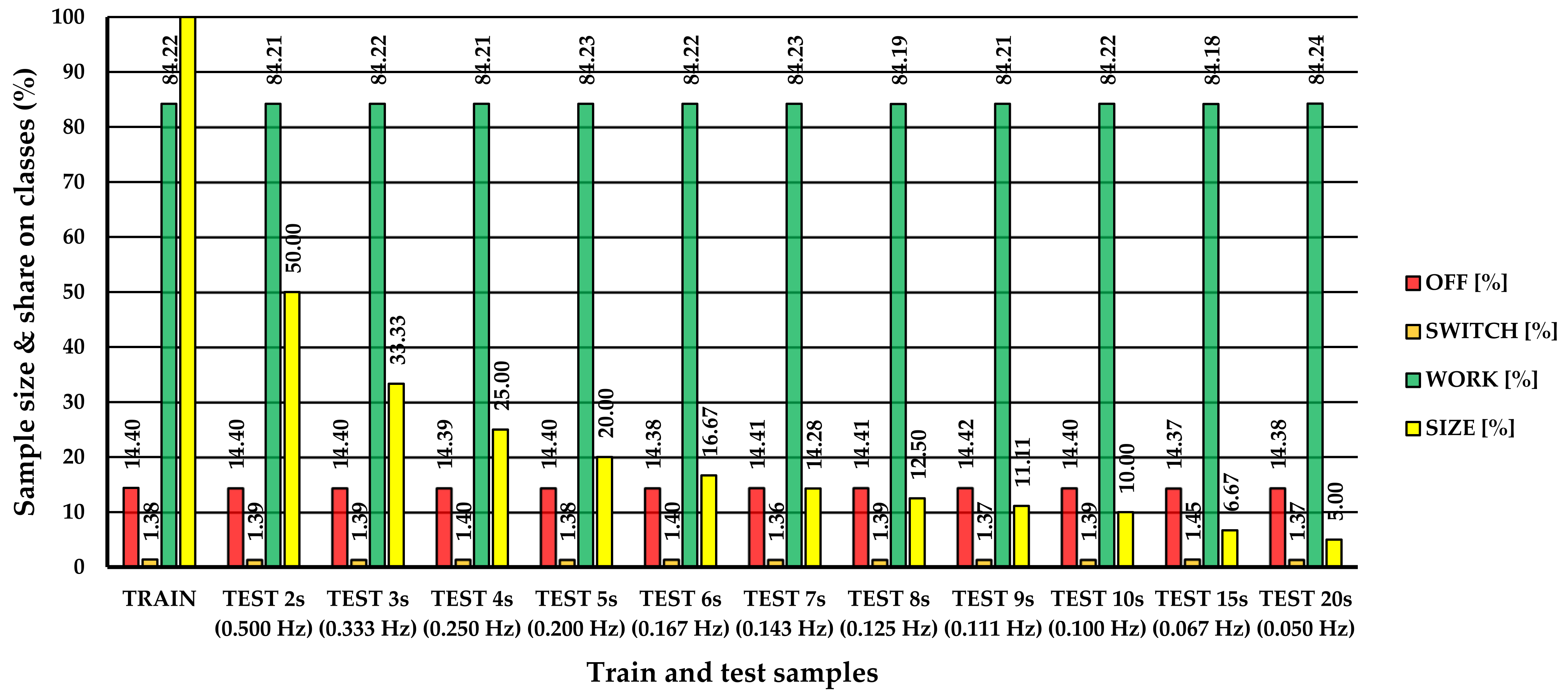
3.3. Effect of Sampling Rate on Classification Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shahi, S.K.; Dia, M.; Yan, P.; Choudhury, S. Developing and training artificial neural networks using bootstrap data envelopment analysis for best performance modeling of sawmills in Ontario. J. Model. Manag. 2022, 17, 788–811. [Google Scholar] [CrossRef]
- Schreiner, F.; Thorenz, B.; Schmidt, J.; Friedrich, M.; Döpper, F. Development of a measuring and control unit for an intelligent adjustment of process parameters in sawing. MM Sci. J. 2021, 5, 5203–5210. [Google Scholar] [CrossRef]
- Borz, S.A.; Oghnoum, M.; Marcu, M.V.; Lorincz, A.; Proto, A.R. Performance of small-scale sawmilling operations: A case study on time consumption, productivity and main ergonomics for a manually-driven bandsaw. Forests 2021, 12, 810. [Google Scholar] [CrossRef]
- Cheța, M.; Marcu, M.V.; Iordache, E.; Borz, S.A. Testing the capability of low-cost tools and artificial intelligence techniques to automatically detect operations done by a small-sized manually driven bandsaw. Forests 2020, 11, 739. [Google Scholar] [CrossRef]
- Cedamon, E.D.; Harrison, S.; Herbohn, J. Comparative analysis of on-site free-hand chainsaw milling and fixed site mini-bandsaw milling of smallholder timber. Small Scale For. 2013, 12, 389–401. [Google Scholar] [CrossRef]
- De Lasaux, M.J.; Spinelli, R.; Hartsough, B.R.; Magagnotti, N. Using a small-log mobile sawmill system to contain fuel reduction treatment cost on small parcels. Small Scale For. 2009, 8, 367–379. [Google Scholar] [CrossRef]
- Gigoraş, D.; Borz, S.A. Factors affecting the effective time consumption, wood recovery rate and feeding speed when manufacturing lumber using a FBO-02 CUT mobile bandsaw. Wood Res. 2015, 60, 329–338. [Google Scholar]
- Venn, T.J.; McGavin, R.L.; Leggate, W.W. Costs of portable sawmilling timbers from the acacia woodlands of Western Queensland, Australia. Small Scale For. Econ. Manag. Policy 2004, 3, 161–175. [Google Scholar] [CrossRef]
- Telford, C.G. Small Sawmill Operator’s Manual. Agriculture Handbook No 27—January 1952; United States Department of Agriculture: Washington, DC, USA, 1952. [Google Scholar]
- FAO. Small and Medium Sawmills in Developing Countries; Forestry Paper No. 28; FAO: Rome, Italy, 1981. [Google Scholar]
- Grönlund, A. Sågverksteknik del 2—Processen; Sveriges Skogsindustriförbund: Markaryd, Sweden, 1992; p. 270. [Google Scholar]
- Lundahl, C.G. Optimized Processes in Sawmills. Licentiate Thesis, Luleå University of Technology, Skellefteå, Sweden, 2007. [Google Scholar]
- Hyytiäinen, A.; Viitanen, J.; Mutanen, A. Production efficiency of independent Finnish sawmills in the 2000’s. Balt. For. 2011, 17, 280–287. [Google Scholar]
- Spinelli, R.; Visser, R.; Magagnotti, N.; Lombardini, C.; Ottaviani, G. The effect of partial automation on the productivity and cost of a mobile tower yarder. Ann. For. Res. 2020, 63, 3–14. [Google Scholar] [CrossRef]
- Borz, S.A. Turning a winch skidder into a self-data collection machine using external sensors: A methodological concept. Bull. Transilv. Univ. Braşov 2016, 9, 1–6. [Google Scholar]
- Cheța, M.; Borz, S.A. Automating data extraction from GPS files and sound pressure level sensors with application in cable yarding time and motion studies. Bull. Transilv. Univ. Braşov 2017, 10, 1–10. [Google Scholar]
- Björheden, R.; Apel, K.; Shiba, M.; Thompson, M. IUFRO Forest Work Study Nomenclature; Swedish University of Agricultural Science, Department of Operational Efficiency: Grapenberg, Sweden, 1995. [Google Scholar]
- Acuna, M.; Bigot, M.; Guerra, S.; Hartsough, B.; Kanzian, C.; Kärhä, K.; Lindroos, O.; Magagnotti, N.; Roux, S.; Spinelli, R.; et al. Good Practice Guidelines for Biomass Production Studies; Magagnotti, N., Spinelli, R., Eds.; CNR IVALSA: Sesto Fiorentino, Italy, 2012; Available online: http://www.forestenergy.org/pages/cost-action-fp0902/good-practice-guidelines/ (accessed on 15 April 2018).
- Ištvanić, J.; Lučić, R.B.; Jug, M.; Karan, R. Analysis of factors affecting log band saw capacity. Croat. J. For. Eng. 2009, 30, 27–35. [Google Scholar]
- Muşat, E.C.; Apăfăian, A.I.; Ignea, G.; Ciobanu, V.D.; Iordache, E.; Derczeni, R.A.; Spârchez, G.; Vasilescu, M.M.; Borz, S.A. Time expenditure in computer aided time studies implemented for highly mechanized forest equipment. Ann. For. Res. 2016, 59, 129–144. [Google Scholar] [CrossRef]
- Spinelli, R.; Laina-Relano, R.; Magagnotti, N.; Tolosana, E. Determining observer effect and method effects on the accuracy of elemental time studies in forest operations. Balt. For. 2013, 19, 301–306. [Google Scholar]
- Borz, S.A.; Păun, M. Integrating offline object tracking, signal processing, and artificial intelligence to classify relevant events in sawmilling operations. Forests 2020, 11, 1333. [Google Scholar] [CrossRef]
- Becker, R.M.; Keefe, R.F. A novel smartphone-based activity recognition modelling method for tracked equipment in forest operations. PLoS ONE 2022, 17, e0266568. [Google Scholar] [CrossRef]
- Borz, S.A. Development of a modality-invariant multi-layer perceptron to predict operational events in motor-manual willow felling operations. Forests 2021, 12, 406. [Google Scholar] [CrossRef]
- Borz, S.A.; Talagai, N.; Cheţa, M.; Chiriloiu, D.; Gavilanes Montoya, A.V.; Castillo Vizuete, D.D.; Marcu, M.V. Physical strain, exposure to noise and postural assessment in motor-manual felling of willow short rotation coppice: Results of a preliminary study. Croat. J. Eng. 2019, 40, 377–388. [Google Scholar] [CrossRef]
- Keefe, R.F.; Zimbelman, E.G.; Wempe, A.M. Use of smartphone sensors to quantify the productive cycle elements of hand fallers on industrial cable logging operations. Int. J. For. Eng. 2019, 30, 132–143. [Google Scholar] [CrossRef]
- Marogel-Popa, T.; Cheța, M.; Marcu, M.V.; Duță, C.I.; Ioraș, F.; Borz, S.A. Manual cultivation operations in poplar stands: A characterization of job difficulty and risks of health impairment. Int. J. Environ. Res. Public Health 2019, 16, 1911. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McDonald, T.P.; Fulton, J.P.; Darr, M.J.; Gallagher, T.V. Evaluation of a system to spatially monitor hand planting of pine seedlings. Comput. Electron. Agric. 2008, 64, 173–182. [Google Scholar] [CrossRef]
- Strandgard, M.; Mitchell, R. Automated time study of forwarders using GPS and a vibration sensor. Croat. J. Eng. 2015, 36, 175–184. [Google Scholar]
- Muşat, E.C.; Borz, S.A. Learning from acceleration data to differentiate the posture, dynamic and static work of the back: An experimental setup. Healthcare 2022, 10, 916. [Google Scholar] [CrossRef]
- Picchio, R.; Proto, A.R.; Civitarese, V.; Di Marzio, N.; Latterini, F. Recent contributions of some fields of the electronics in development of forest operations technologies. Electronics 2019, 8, 1465. [Google Scholar] [CrossRef] [Green Version]
- Wescoat, E.; Krugh, M.; Henderson, A.; Goodnough, J.; Mears, L. Vibration analysis using unsupervised learning. Procedia Manuf. 2019, 34, 876–888. [Google Scholar] [CrossRef]
- Borz, S.A.; Talagai, N.; Cheţa, M.; Gavilanes Montoya, A.V.; Castillo Vizuete, D.D. Automating data collection in motor-manual time and motion studies implemented in a willow short rotation coppice. Bioresources 2018, 13, 3236–3249. [Google Scholar] [CrossRef]
- Demsar, J.; Curk, T.; Erjavec, A.; Gorup, C.; Hocevar, T.; Milutinovic, M.; Mozina, M.; Polajnar, M.; Toplak, M.; Staric, A.; et al. Orange: Data Mining Toolbox in Python. J. Mach. Learn. Res. 2013, 14, 2349–2353. [Google Scholar]
- R Interface to Keras. Available online: https://keras.rstudio.com/ (accessed on 19 May 2022).
- Smith, S.W. Digital Signal Processing—A Practical Guide for Engineers and Scientists, 1st ed.; Newnes—Elsevier Science: Burlington, MA, USA, 2003. [Google Scholar]
- Proto, A.R.; Sperandio, G.; Costa, C.; Maesano, M.; Antonucci, F.; Macri, G.; Scarascia Mugnozza, G.; Zimbalatti, G. A three-step neural network artificial intelligence modeling approach for time, productivity and costs prediction: A case study in Italian forestry. Croat. J. For. Eng. 2020, 41, 15. [Google Scholar] [CrossRef]
- Neural Network Models (Supervised). Multi-Layer Perceptron. Available online: https://scikit-learn.org/stable/modules/neural_networks_supervised.html (accessed on 19 May 2022).
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cheța, M.; Marcu, M.V.; Borz, S.A. Effect of training parameters on the ability of artificial neural networks to learn: A simulation on accelerometer data for task recognition in motor-manual felling and processing. BUT Ser. II For. Wood Ind. Agric. Food Eng. 2020, 13, 19–36. [Google Scholar] [CrossRef]
- Goodfellow, J.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: https://www.deeplearningbook.org/ (accessed on 19 May 2022).
- Kingma, D.P.; Ba, J.L. 2015: ADAM: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Activation Functions in Neural Networks. Available online: https://towardsdatascience.com/activation-functions-neural-networks-1cbd9f8d91d6 (accessed on 19 May 2022).
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning (ICML 2013), Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML 2010), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- A Beginner’s Guide to Random Forest Hyperparameter Tunning. Available online: https://www.analyticsvidhya.com/blog/2020/03/beginners-guide-random-forest-hyperparameter-tuning/?utm_source=blog&utm_medium=decision-tree-vs-random-forest-algorithm (accessed on 19 May 2022).
- Orange Visual Programming. Random Forest. Available online: https://orange3.readthedocs.io/projects/orange-visual-programming/en/latest/widgets/model/randomforest.html (accessed on 19 May 2022).
- Fawcett, T. An introduction to ROC analysis. Pattern Recogn. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldu, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Sklearn Metrics. Log Loss. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.log_loss.html (accessed on 19 May 2022).
- Castro Pérez, S.N.; Borz, S.A. Improving the event-based classification accuracy in pit-drilling operations: An application by neural networks and median filtering of the acceleration input data. Sensors 2021, 21, 6288. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges and opportunities. J. ACM 2018, 37, 111. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial of human activity recognition using body-worn inertial sensors. ACM Comput. Surv. 2014, 46, 33. [Google Scholar] [CrossRef]
- Extech® User Manual. 3-Axis G-Force Datalogger. Model VB300. Available online: http://www.extech.com/products/resources/VB300_UM-en.pdf (accessed on 19 May 2022).
- van Hees, V.T.; Gorzelniak, L.; León, E.C.D.; Eder, M.; Pias, M.; Taherian, S.; Ekelund, U.; Renström, F.; Franks, P.W.; Horsch, A.; et al. Separating movement and gravity components in an acceleration signal and implications for the assessment of human daily physical activity. PLoS ONE 2013, 8, e61691. [Google Scholar] [CrossRef] [Green Version]
- Orange Visual Programming. Neural Network. Available online: https://orange3.readthedocs.io/projects/orange-visual-programming/en/latest/widgets/model/neuralnetwork.html (accessed on 19 May 2022).
- Aggarwal, C.C. Data Mining. The Textbook; Springer: New York, NY, USA, 2015; 734p. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann Publishers: Burlington, MA, USA, 2006. [Google Scholar]
- Kamperidou, V.; Aidinidis, E.; Barboutis, I. Impact of structural defects on the surface quality of hardwood species sliced veneers. Appl. Sci. 2020, 10, 6265. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Day of Observation | Number of Observations (Samples Taken at 1 Hz) | Share in the Dataset (%) | Time Covered (h) |
|---|---|---|---|
| Day 1 | 15,646 | 19.88 | 4.35 |
| Day 2 | 15,817 | 20.09 | 4.39 |
| Day 3 | 15,780 | 20.05 | 4.38 |
| Day 4 | 15,701 | 19.95 | 4.36 |
| Day 5 | 15,763 | 20.03 | 4.38 |
| Total | 78,707 | 100.00 | 21.86 |
| Dataset and Share of Data | Classification Performance Metrics | ||||||
|---|---|---|---|---|---|---|---|
| AUC | CA | F1 | PREC | REC | LOGLOSS | SPEC | |
| TRAIN 20% | 0.979 | 0.973 | 0.966 | 0.967 | 0.973 | 0.109 | 0.969 |
| TEST 80% | 0.991 | 0.989 | 0.989 | 0.988 | 0.989 | 0.054 | 0.970 |
| Difference | −0.012 | −0.016 | −0.023 | −0.021 | −0.016 | 0.055 | −0.001 |
| TRAIN 30% | 0.981 | 0.979 | 0.973 | 0.974 | 0.979 | 0.087 | 0.964 |
| TEST 70% | 0.991 | 0.988 | 0.987 | 0.987 | 0.988 | 0.051 | 0.962 |
| Difference | −0.010 | −0.009 | −0.014 | −0.013 | −0.009 | 0.036 | 0.002 |
| TRAIN 40% | 0.983 | 0.980 | 0.974 | 0.975 | 0.980 | 0.083 | 0.965 |
| TEST 60% | 0.991 | 0.991 | 0.991 | 0.990 | 0.991 | 0.041 | 0.964 |
| Difference | −0.008 | −0.011 | −0.017 | −0.015 | −0.011 | 0.042 | 0.001 |
| TRAIN 50% | 0.985 | 0.981 | 0.977 | 0.977 | 0.981 | 0.078 | 0.967 |
| TEST 50% | 0.991 | 0.993 | 0.992 | 0.991 | 0.993 | 0.034 | 0.963 |
| Difference | −0.006 | −0.012 | −0.015 | −0.014 | −0.012 | 0.044 | 0.004 |
| TRAIN 60% | 0.985 | 0.982 | 0.978 | 0.978 | 0.982 | 0.074 | 0.967 |
| TEST 40% | 0.990 | 0.994 | 0.993 | 0.992 | 0.994 | 0.030 | 0.956 |
| Difference | −0.005 | −0.012 | −0.015 | −0.014 | −0.012 | 0.044 | 0.011 |
| TRAIN 70% | 0.986 | 0.985 | 0.981 | 0.981 | 0.985 | 0.065 | 0.966 |
| TEST 30% | 0.990 | 0.992 | 0.991 | 0.991 | 0.992 | 0.035 | 0.959 |
| Difference | −0.004 | −0.007 | −0.010 | −0.010 | −0.007 | 0.030 | 0.007 |
| TRAIN 80% | 0.988 | 0.986 | 0.982 | 0.983 | 0.986 | 0.060 | 0.967 |
| TEST 20% | 0.983 | 0.991 | 0.989 | 0.991 | 0.991 | 0.040 | 0.932 |
| Difference | 0.005 | −0.005 | −0.007 | −0.008 | −0.005 | 0.020 | 0.035 |
| Dataset | Share | Number of Observations | Classification Performance Metrics | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AUC | CA | F1 | PREC | REC | LOGLOSS | SPEC | |||
| TRAIN | 100.00 | 78,707 | 0.987 | 0.987 | 0.984 | 0.984 | 0.987 | 0.056 | 0.964 |
| TEST 2 s (0.500 Hz) | 50.00 | 39,353 | 0.988 | 0.987 | 0.984 | 0.985 | 0.987 | 0.054 | 0.964 |
| TEST 3 s (0.333 Hz) | 33.33 | 26,235 | 0.987 | 0.987 | 0.984 | 0.985 | 0.987 | 0.055 | 0.964 |
| TEST 4 s (0.250 Hz) | 25.00 | 19,676 | 0.988 | 0.988 | 0.985 | 0.986 | 0.988 | 0.055 | 0.965 |
| TEST 5 s (0.200 Hz) | 20.00 | 15,741 | 0.988 | 0.987 | 0.984 | 0.985 | 0.987 | 0.055 | 0.965 |
| TEST 6 s (0.167 Hz) | 16.67 | 13,117 | 0.987 | 0.988 | 0.985 | 0.986 | 0.988 | 0.054 | 0.964 |
| TEST 7 s (0.143 Hz) | 14.28 | 11,243 | 0.988 | 0.988 | 0.985 | 0.986 | 0.988 | 0.056 | 0.964 |
| TEST 8 s (0.125 Hz) | 12.50 | 9838 | 0.988 | 0.988 | 0.985 | 0.986 | 0.988 | 0.055 | 0.965 |
| TEST 9 s (0.111 Hz) | 11.11 | 8745 | 0.986 | 0.987 | 0.984 | 0.984 | 0.987 | 0.057 | 0.961 |
| TEST 10 s (0.100 Hz) | 10.00 | 7870 | 0.987 | 0.988 | 0.985 | 0.986 | 0.988 | 0.057 | 0.966 |
| TEST 15 s (0.067 Hz) | 6.67 | 5247 | 0.986 | 0.987 | 0.984 | 0.985 | 0.987 | 0.058 | 0.963 |
| TEST 20 s (0.050 Hz) | 5.00 | 3935 | 0.986 | 0.989 | 0.986 | 0.988 | 0.989 | 0.055 | 0.969 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Borz, S.A.; Forkuo, G.O.; Oprea-Sorescu, O.; Proto, A.R. Development of a Robust Machine Learning Model to Monitor the Operational Performance of Fixed-Post Multi-Blade Vertical Sawing Machines. Forests 2022, 13, 1115. https://doi.org/10.3390/f13071115
Borz SA, Forkuo GO, Oprea-Sorescu O, Proto AR. Development of a Robust Machine Learning Model to Monitor the Operational Performance of Fixed-Post Multi-Blade Vertical Sawing Machines. Forests. 2022; 13(7):1115. https://doi.org/10.3390/f13071115
Chicago/Turabian StyleBorz, Stelian Alexandru, Gabriel Osei Forkuo, Octavian Oprea-Sorescu, and Andrea Rosario Proto. 2022. "Development of a Robust Machine Learning Model to Monitor the Operational Performance of Fixed-Post Multi-Blade Vertical Sawing Machines" Forests 13, no. 7: 1115. https://doi.org/10.3390/f13071115