1. Introduction
Forest fire is the most destructive disaster to forestry, forest ecosystems, and living environments of animals, plants, and even human beings. Global environmental degradations and intense human activities, especially in recent years, cause an obvious increase in the number of forest fires, as reported by Greenpeace research laboratories and the climate change research of the US Environmental Protection Agency [
1]. According to the Statistical Yearbook of China [
2], there was a total of 2936 and 3223 forest fire incidents in China in 2015 and 2017, respectively. Among 30 specific ignition causes, more than 95% revolved in human activities, such as forestry and agricultural activities, tourist and resident behaviors, and traditional or cultural celebrations. To defend forest resources, governments and organizations all over the world have been devoted more efforts on forest fire prevention systems, including the monitoring by an observation tower, cruising aircraft, meteorological satellite, and the Internet of Things-based sensor network. Benefitting from a large area, all-weather, low cost in monitoring, computer vision-based systems gradually dominate the above-mentioned monitoring. In China, to keep the pace with forestry industry modernization, watchtower-mode monitoring has received increasing attention and has been selected first [
1,
3]. It is usually located at a high elevation hilltop with a wide visual region and is equipped with high-definition dome (video) cameras mounted on a rotatable platform for scanning in a 0–360° horizontal and 0–180° vertical view.
Vision-based methods are commonly divided into three categories: rule-, motion-, and model-based fire detections. In the literature, earlier work can be tracked back to the color-based rule-reasoning [
4,
5,
6]. Originated from pixel classification, Chen and Celik et al. empirically refined a set of rules for fire pixels, drawn from a RGB or YCbCr color space, respectively. Later, similar rules and image thresholding methods appeared one after another, involving in more color spaces, e.g., HSI, YUV, and the combination of multiple color spaces. Motion-based methods firstly focused on detecting the moving objects and constructed some dynamic features, such as the color of the fire flames, the scale of round, the number of cusps, flicker frequency, and changes in the flame area [
7,
8,
9]. Then, fire detection was carried on the detected movable objects, thus, the detection can be greatly sped up. A motion-based method may be efficient for indoor dead-directional video detection because the video fire or the area of the fire flame can be viewed as a movable object, and those non-fire background objects are viewed as static ones. Here, the word “object” refers to the understandable material object in human vision. However, it is unsuitable for the outdoor forest fire detection because in an omni-directional video, there is no static object, and all objects always move between frames. In the last decade, many machine learning-based methods are used for fire detection, including artificial neural networks [
10,
11], support vector machines (SVM) [
12,
13], data clustering [
14,
15], and deep learning-based methods that run on high-performance computers, even on the powerful GPU-based computers [
16,
17,
18,
19,
20,
21]; here, we only name a few. Compared with the first two categories, the machine learning-, or named model-based methods are superior in two aspects: faster detection speed and a higher accuracy rate. For example, if using a model-based method to detect fire, decision making is simpler and faster—it just needs to calculate a function value, rather than the rule-by-rule verification, as a rule-based method does. Moreover, such decisions can be also made in batch. As for the detection accuracy, a model-based method, e.g., SVM, is usually trained on the studying/monitoring forest scene, thus, it is more likely to achieve a higher fire detection rate for this scene.
However, if viewing a fire detection task as a two-class or multi-class classification, most model-based detections usually ignore or even violate the principles of statistics and machine learning—typically, independent and identical distribution (i.i.d., for short). Take the SVM-based detection as an example—to train SVM, two-class samples should be constructed first, e.g., the pixels are drawn automatically or manually from the fire flame regions (viewed as the positive class) and non-fire ones (negative), respectively. During this period, violation may be caused. In human vision, a common sense is that the color of fire flames is light yellow, orange-yellow, or reddish [
22], and is related to the combustible material, air convection speed, ignition point, combustion temperature, etc. In this view, it seems reasonable to construct the fire samples because they at least have similar color values. In contrast, those non-fire samples are not independently and identically distributed because of the complexity of various forest scenes. In terms of color composition, this negative class may be composed of various colorful objects, such as green shrubs and plants, withered and yellow weeds, blue sky, and white clouds. Therefore, it is obviously unreasonable if these non-fire pixels (in computer vision) or objects (in human vision) are viewed as drawn from the identical distribution. Additionally, if replacing two-class with multi-class, although it can reduce the dependence of data distributions, it also increases the difficulties, e.g., the multi-class sample construction and unbalance classification. Furthermore, it is not easy to determine an appropriate number of classes for multi-class classification. In machine learning, it is still an open problem.
On the other hand, according to the Bayes theory, a model would be optimal if it is combined with data distribution. Reflecting on forest fire detection, we can pay less or even no attention on the non-fire samples because, for a given sample, we do not need to know which non-fire object it should belong to. The use of the non-fire samples is to push the decision plane to an appropriate position, in which the fire samples can be well-separated from the non-fire ones. However, for the fire class, it is different. For example, in a given frame, we do not need to only know whether there is a fire, but if so, we also need to know where the fire pixels are, i.e., fire positioning. This reminds us to consider the one-class model.
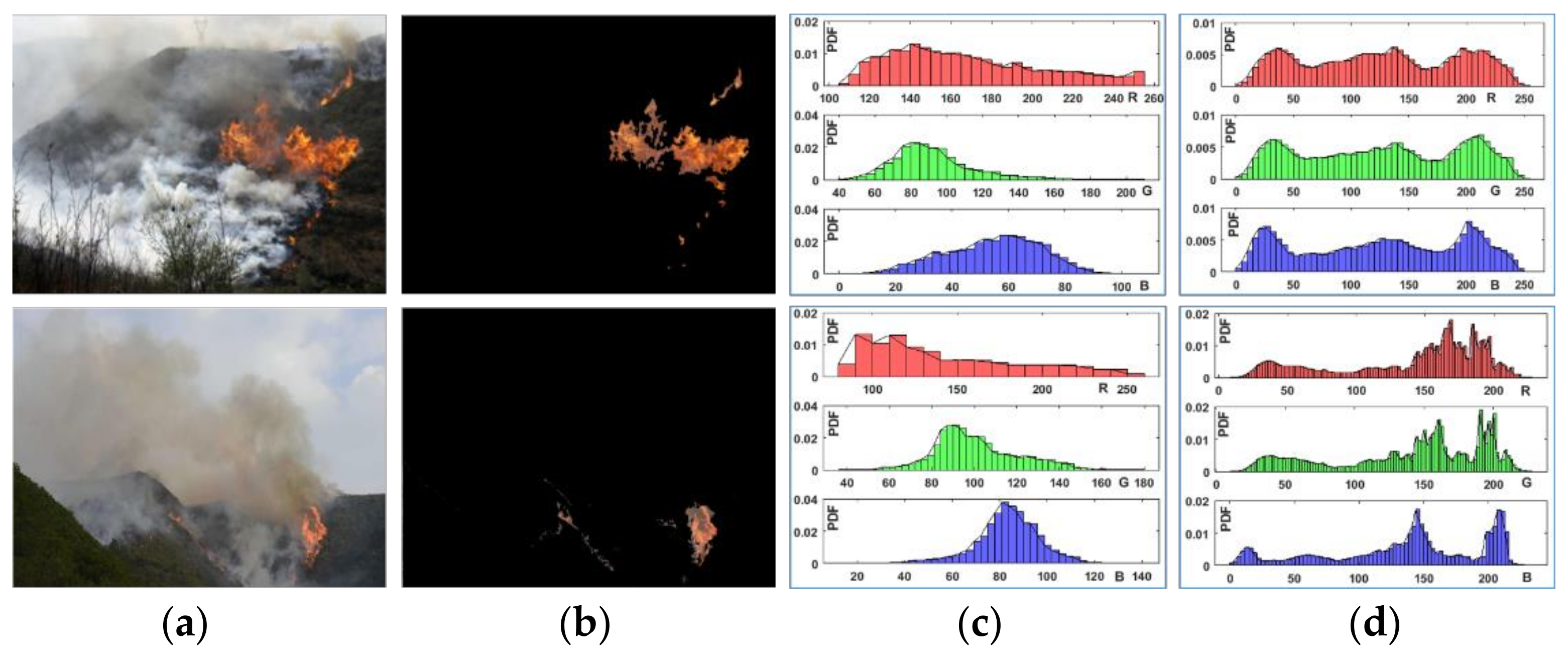
To clarify the above opinions,
Figure 1 shows an example on pixel distribution. A pixel in the annotation image is filled with the original pixel if it is from the fire (positive) class; otherwise, it is filled with the values (0, 0, 0), as shown in the panel (b). Additionally, the panels (c) and (d) show the marginal distributions of the fire and non-fire pixels, respectively. Here, pixel distributions are characterized by probability density functions (PDF, for short). It shows that the distribution of positive classes tends to be unimodal; however, for the non-fire one, it tends to be a complex multi-modal distribution. Furthermore, in computation, estimating a unimodal PDF, e.g., by a Gaussian, is much easier than multi-modal PDF. Following this idea, a direct ambition is to seek a compact Gaussian “sphere”, satisfying that all fire samples are included inside, and simultaneously, as many as possible non-fire samples are excluded outside. Additionally, considering the requirements of real-time and high-precision video detection together, we aim to propose a supervised method based on the one-class model. Compared with start-of-the-art methods, the main advantages lie in three-fold: (1) This method is easier to use, either in sample collection or model training; (2) it has a solid theoretical base, e.g., following the principle of data distribution; (3) it has more potential in the real-time and high-precision detection, and does not need to consider extra feature constructions or color-space transformations.
The rest of this work is organized as below. In
Section 2, the data used in this paper, including forest fire images, ground-, and UAV-monitoring videos, are presented. Our method will be detailed in
Section 3, including the modeling and solution, and geometrical interpretation. To verify the performance of our proposal, experimental verification is arranged in
Section 4. We conclude the whole paper in
Section 5.
4. Discussion
The first three indicators, i.e., fire detection rate, error warning rate, and fire positioning, are visualized in
Figure 4. The results show that among the four fire detection methods, the supervised SVM and one-class SVM are superior, then the YCbCr rule-based method follows. The slight difference between the SVM and one-class SVM regards the area of the detected fire flames. This may be explained by the compactness, due to the fact that: (1) The fire pixel distribution cannot be well represented by the selected fire pixels. According to the interactive image annotation method [
24], the fire samples used for training a KNN classifier are selected from the pixels that are most likely to be flames, e.g., usually selected from the central region of the fire flame; (2) Because of the compactness, the area of the fire flame tends to be smaller than that of SVM. Different from the baselines, here, the one-class method is originated from the i.i.d. hypothesis. Therefore, in view of machine learning, it will be better if the fire samples for training a one-class model are selected from a complete flame region.
Extensive results on all video frames are shown in
Figure 5. Among the four indicators, both fire detection rates and error warning rates can be used to measure the performance of fire detection. In this view, an ideal detector should be able to achieve a high-fire detection rate and a low-error warning rate at the same time. Towards this goal, both SVM and our one-class model outperform the other two. Concretely, as for the fire detection rate, the YCbCr rule achieves the highest fire detection rate on the first two videos; however, on the third one, it seems unstable and the obtained fire detection rates vary from 40% to 100%. In contrast to the results of the first two data, due to the long-distance in UAV-monitoring, the flame areas of the third video are always small, as shown by the cyan reference line (GT) in
Figure 5c and the test fames in the last row of
Figure 4. That is, a small number of miss-detected fire pixels may result in a big oscillation in the fire detection rate. This explanation can also be used for the k-Medoids. If together with the error warning rate, in general, over-high error warning rates make both unsupervised methods unsuitable for forest fire detection, especially in the complex forest scenes. Furthermore, if further considering the requirement of real-time, the situation will be even worse. The predicted values of the detection time are always greater than the reference values. Visually, as shown in
Figure 5d, the line of the predicted values is always above the cyan reference line. Here, the reference value is measured by FPS (frame per second), with the real-time value of 1/fps second. In the detection time, both supervised methods are superior and able to satisfy the requirement of real-time detection on the first two videos. However, due to a high resolution, they cannot satisfy the requirement on the third video, i.e., the real-time value of 0.0345 s per frame (1/29). Moreover, it is also a big challenge for the current computation and vision-based recognition techniques. In order to suit this requirement, the frame-skipping detection should be the second best, as shown in the right-bottom figure, where another cyan wider reference line means a 10× delay, i.e., the value of 0.345 s.
At the end, let us come to fire positioning. In a real forest fire monitoring, the ability of an accurate fire location can help us in two aspects: (1) it can be used to measure the performance of a fire detector, and (2) it is useful for a fire emergency rescue, especially in the stage of early fire. If returning the pixel coordinates, it is a direct and intuitive representation for fire positioning, e.g., in the manner of visualization. However, it is unsuitable for video detection if want to show the result in a frame-by-frame manner. To relieve this dilemma, the pixel coordinates in the same frame can be replaced with the area of the detected fire flame. Visually, if the predicted value is close to the area of GT, the accurate pixel positioning of the whole frame can be achieved. In other words, the accuracy of the fire positioning can be measured by the consistence between the predicted line (or values) and the GT line. Here, the consistency includes the proximity and change trend. As shown in
Figure 5c, tendencies of three lines, i.e., the predicted values of SVM, our one-class model, and GT, respectively, are consistent. This means that both SVM and our one-class model are capable of accurate fire pixel positioning. Therefore, if considering the above indicators together, the one-class model is the best method for the forest fire video detection.
5. Conclusions
In this work, we propose a new method for forest fire video detection. It is oriented on pixel distribution, i.e., the i.i.d. hypothesis, which is significantly different from the existing methods. Inspired by the supervised fire detectors and the empirical results of the unimodal fire pixel distribution, we develop a one-class model for fire detection. In computation, the leading problem can be solved by a convex QP optimization. To speed fire detection, we also provide a strategy for batch decision-making. Due to the compactness of the one-class ball, it can be used for controlling the error warning rate. Compared with the state-of-the-art methods, the comparison on the forest fire videos shows its superiority in a higher fire detection rate, a lower error warning rate, more accurate fire location in positioning, and the fastest detection speed. In computation, although it can be solved by one-class SVM, a variant of SVM, it differs from SVM in three-fold: (1) It needs less supervision information for model training. For example, in a balance classification, training a one-class model just depends on the positive samples, nearly half of the training set for SVM; (2) It is easy to use without considering non-fire information. In fact, it is not easy for training a two-class or multi-class model on how to select negative samples; (3) Due to the unimodal distribution, the obtained decision domain is bounded, i.e., the “ball” in geometry for the fire pixels. However, for SVM, it aims to separate the input space into two disjointed half-spaces. Therefore, its decision domain may be unbounded or not. Even if it is bounded, it is still unclear whether it is formed by the joint action of both classes of samples or by the single action of one class. This can be used to explain that if selecting training samples carefully, sometimes a better detection result can also be obtained without considering the data distribution for a two-class or multi-class method. In this case, if the obtained decision boundary is tight enough for one of the multi-class training samples, e.g., the fire class, in essence, the data distribution is applied subconsciously in the sample selection.
Different from the general object recognition, the difficulties for fire recognition are that: (1) As a special object, fire is non-rigid, shapeless, has color uncertainty, and is made up of many complex substances. Until now, it is still unclear what features are conducive for extracting a fire flame; (2) Due to the complexity of various forest scenes, public fire images and video databases with high-precision annotations are still few or unavailable [
31]; (3) In a practical view, a forest fire detector should be evaluated by multiple indicators, e.g., the fire detection rate, error warning rate, real-time, and fire location (for the fire-spread trend prediction and fire rescue), rather than a single indicator such as test accuracy in the general object recognition; (4) It frequently suffers from an unbalance classification problem, especially at the early fire stage.
Furthermore, in view of the independently and identically distributed (i.i.d.) hypothesis in machine learning, it is a little far-fetched for viewing fire detection as a binary classification. For example, it is unreasonable for those non-fire objects, composed of sky, ground, trees, plants, etc., to be viewed from the same class. However, if viewing it as a multi-class classification to reduce the dependence on the i.i.d. hypothesis, what should be the appropriate number of classes (categories) for a scene-changing forest environment? Additionally, for a large-scale dataset, SVM tends to be extremely cumbersome, e.g., is intolerant time- or memory-consuming. In the literature, many variants or called approximators have been proposed, such as LSSVM (least square SVM), TWSVM (TWin SVM) [
32], PSVM (Proximate SVM), and newly FSVC (fast SVM) [
31]. If using them for fire detection, the performance also remains to be studied. In this paper, our method is oriented from pixel classification, and fire detection is expected to be accomplished in one-time scanning. Due to the high-precision real-time detection and model interpretability, there is no comparison with deep learning-based methods. Additionally, for a given forest scene, if fire information is insufficient or unobtainable, how to train a machine to match this fire-absent scene? Obviously, it is a bigger challenge in forest fire detection. Our potential avenue for future research also involves smoke detection and its relation to fire.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}