UAV-Based High-Throughput Approach for Fast Growing Cunninghamia lanceolata (Lamb.) Cultivar Screening by Machine Learning


Abstract
:1. Introduction
2. Material and Methods
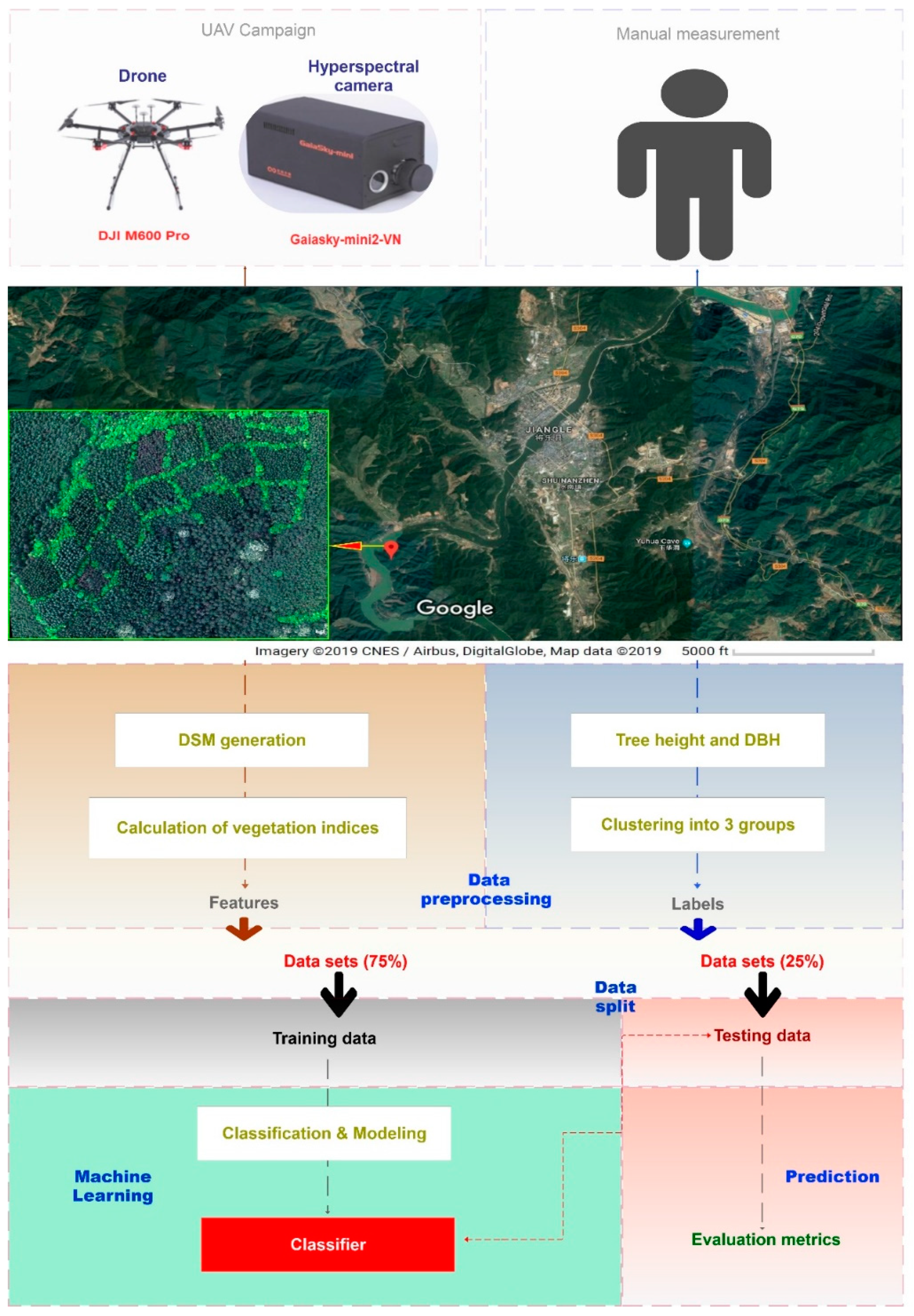
2.1. Study Area and Experimental Design
2.2. UAV-Based Hyperspectral Image Data Collection
2.3. Image Processing
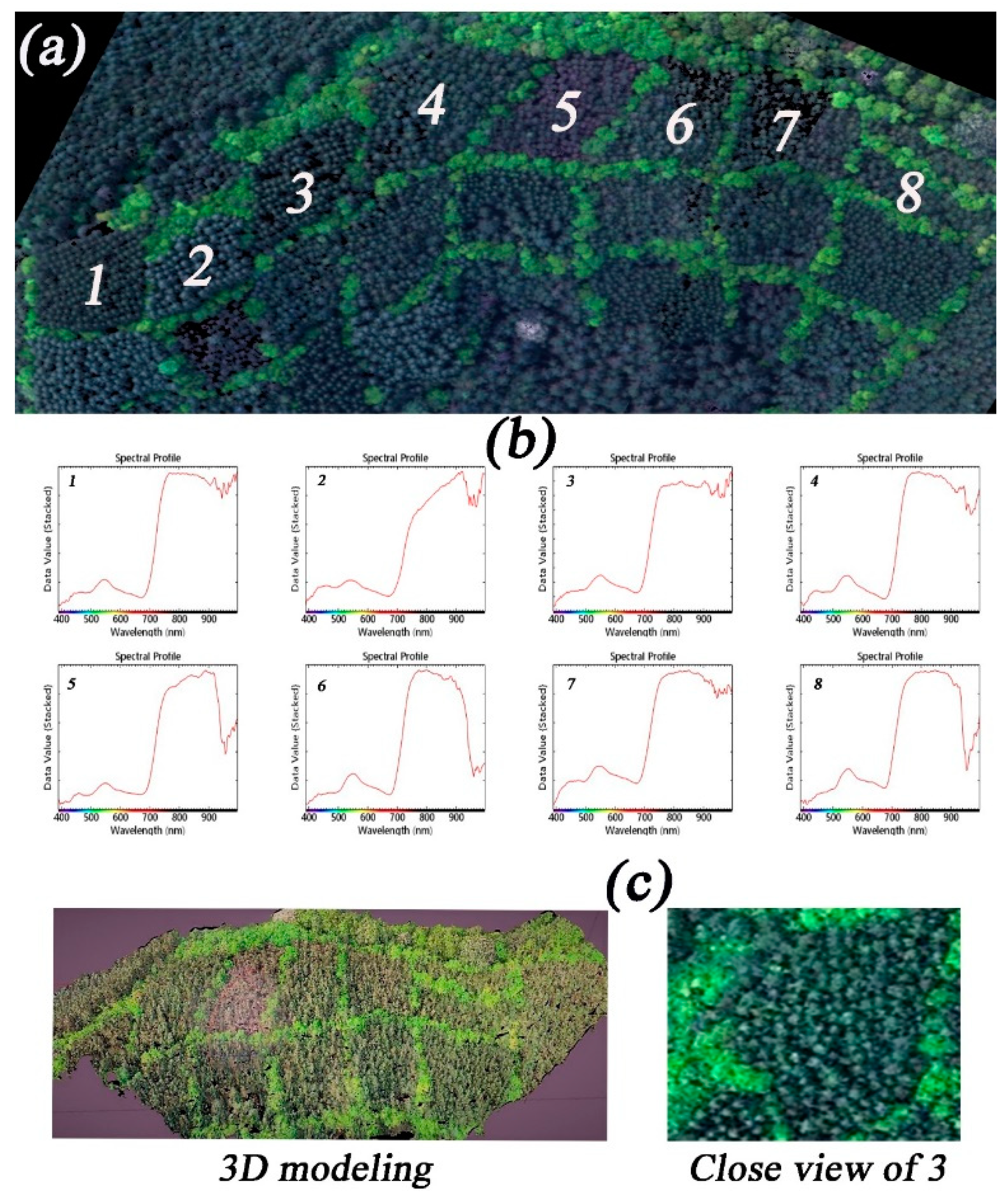
2.3.1. Digital Surface Models (DSM) Generation and Region of Interests (ROI) Selection
2.3.2. Parcel Detection, Random Sampling, and Dimensionality Reduction
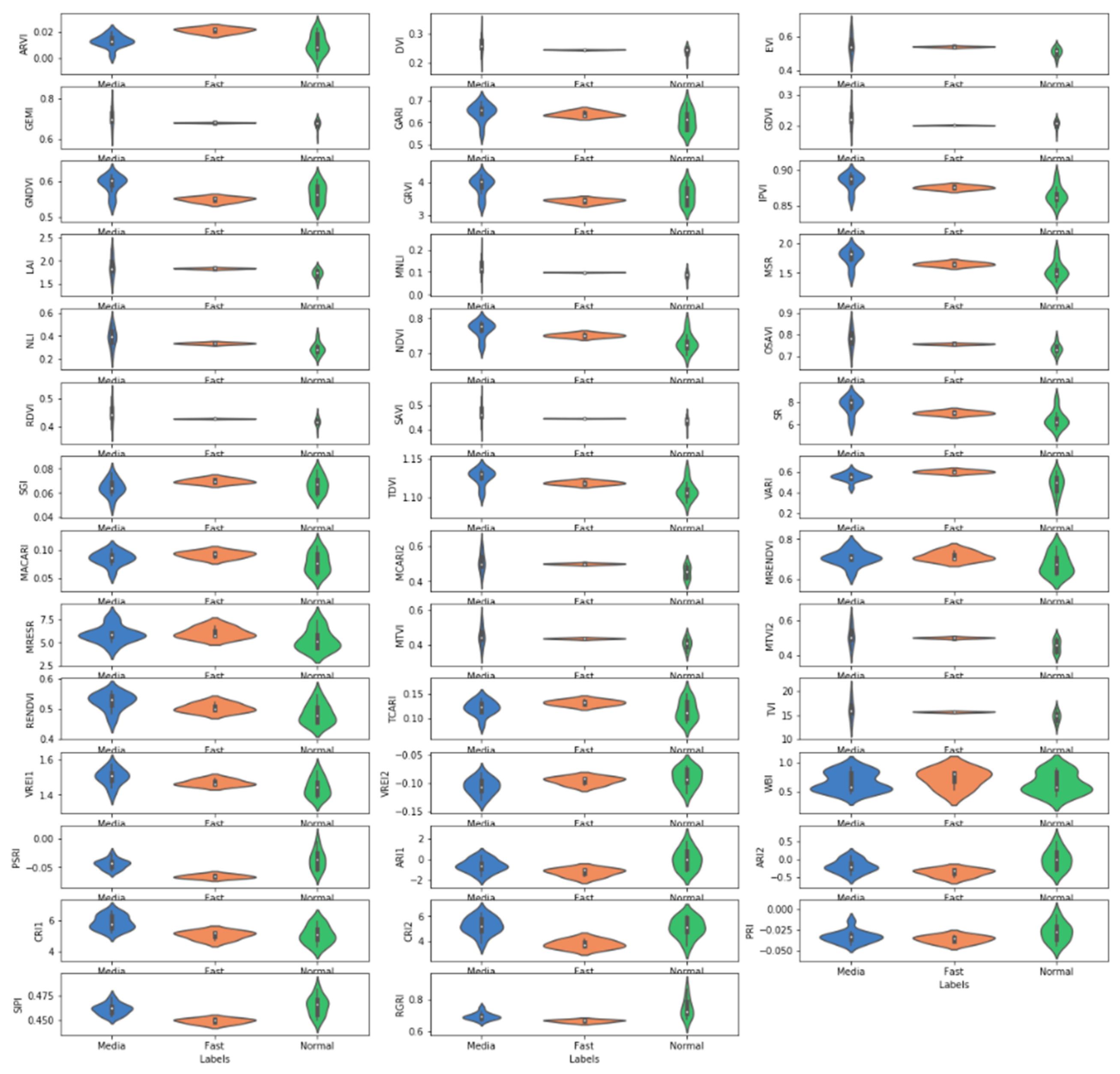
2.3.3. Calculation of Vegetation Indices
2.4. Data Processing and Modeling
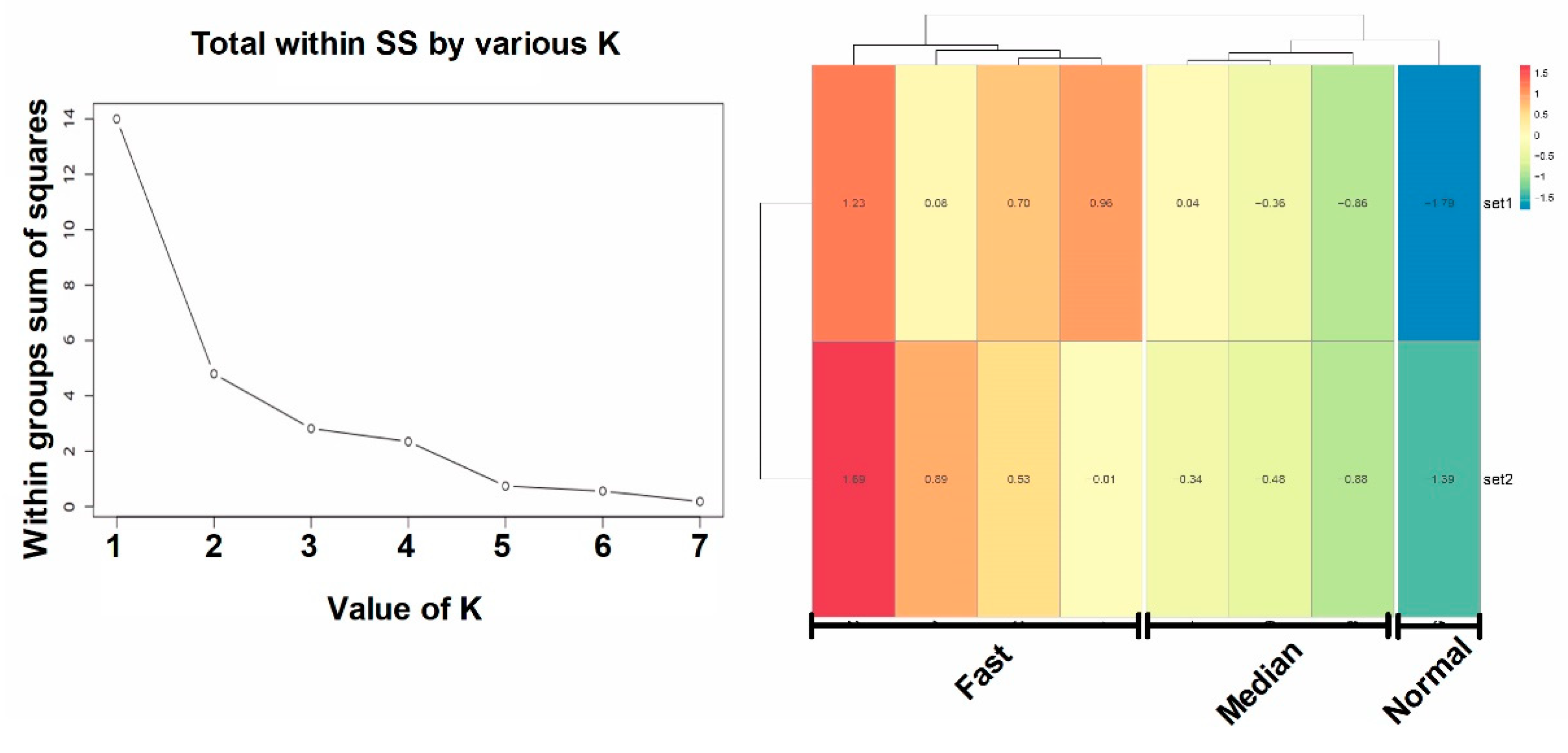
2.4.1. Manual Measurement Data Processing
2.4.2. Trimming the Vegetation Indices Data
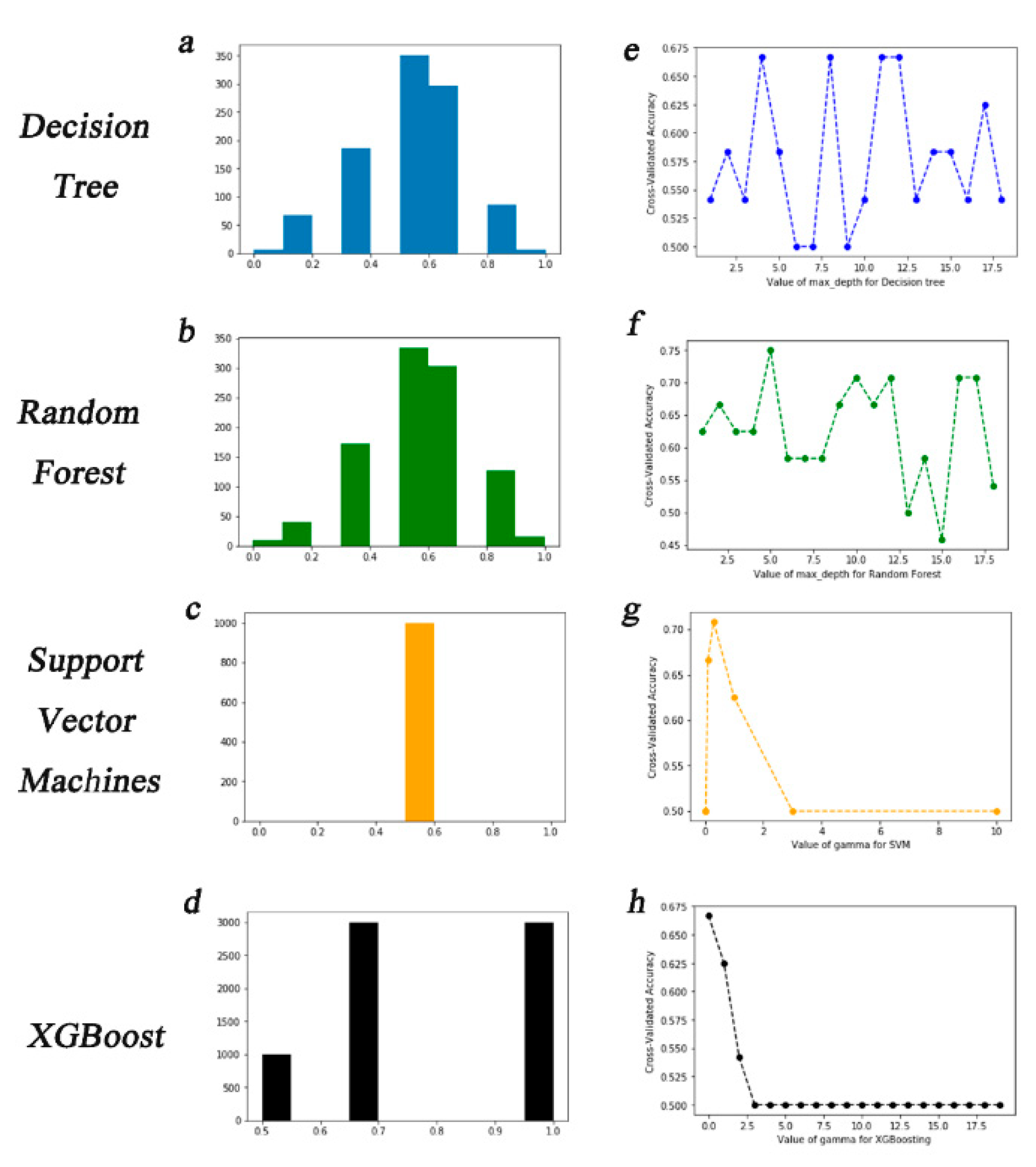
2.5. Modeling by Machine Learning
Classification algorithms and evaluation metrics
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Shi, J.; Zhen, Y.; Zheng, R. Proteome profiling of early seed development in Cunninghamia lanceolata (Lamb.) Hook. J. Exp. Bot. 2010, 61, 2367–2381. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.; Chen, J.; Hao, Z.; Shi, J. Comparative analysis of the chloroplast genomic information of Cunninghamia lanceolata (Lamb.) Hook with sibling species from the Genera Cryptomeria, D. Don, Taiwania Hayata, and Calocedrus Kurz. Int. J. Mol. Sci. 2016, 17, 1084. [Google Scholar] [CrossRef] [PubMed]
- Guan, F.Y.; Tang, X.L.; Fan, S.H.; Zhao, J.C.; Peng, C. Changes in soil carbon and nitrogen stocks followed the conversion from secondary forest to Chinese fir and Moso bamboo plantations. Catena 2015, 133, 455–460. [Google Scholar] [CrossRef]
- Zhao, M.F.; Xiang, W.H.; Peng, C.H.; Tian, D.L. Simulating age-related changes in carbon storage and allocation in a Chinese Fir plantation growing in southern China using the 3-PG model. For. Ecol. Manag. 2009, 257, 1520–1531. [Google Scholar] [CrossRef]
- Ablo, P.I.H.; Mathieu, J.; Claude, N.; Laurent, S.-A.; Quentin, P. Improving the robustness of biomass functions: From empirical to functional approaches. Ann. For. Sci. 2015, 72, 795–810. [Google Scholar]
- Guangyi, M.; Yujun, S.; Saeed, S. Models for Predicting the Biomass of Cunninghamia lanceolata Trees and Stands in Southeastern China. PLoS ONE 2017, 12, e0169747. [Google Scholar] [CrossRef] [PubMed]
- Hao, X.; Yujun, S.; Xinjie, W.; Jin, W.; Yao, F. Linear mixed-effects models to describe individual tree crown width for China-Fir in Fujian Province, Southeast China. PLoS ONE 2015, 10, e0122257. [Google Scholar] [CrossRef]
- White, J.W.; Andrade-Sanchez, P.; Gore, M.A.; Bronson, K.F.; Coffelt, T.A.; Conley, M.M.; Jenks, M.A.; Feldmann, K.A.; French, A.N.; Heun, J.T.; et al. Field-based phenomics for plant genetics research. Field Crop Res. 2012, 133, 101–112. [Google Scholar] [CrossRef]
- Yang, G.; Liu, J.; Zhao, C.; Li, Z.; Huang, Y.; Yu, H.; Xu, B.; Yang, X.; Zhu, D.; Zhang, X.; et al. Unmanned aerial vehicle remote sensing for field-based crop phenotyping: Current status and perspectives. Front. Plant Sci. 2017, 8, 1111. [Google Scholar] [CrossRef]
- Brede, B.; Lau, A.; Bartholomeus, H.; Kooistra, L. Comparing RIEGL RiCOPTER UAV LiDAR derived canopy height and DBH with terrestrial LiDAR. Sensors 2017, 17, 2371. [Google Scholar] [CrossRef]
- Torres-Sánchez, J.; López-Granados, F.; Serrano, N.; Arquero, O.; Peña, J.M. High Throughput 3-D Monitoring of Agricultural-Tree Plantations with Unmanned Aerial Vehicle (UAV) Technology. PLoS ONE 2015, 10, e0130479. [Google Scholar] [CrossRef] [PubMed]
- Sandino, J.; Pegg, G.; Gonzalez, F.; Smith, G. Aerial mapping of forests affected by pathogens using UAVs, hyperspectral sensors, and artificial intelligence. Sensors 2018, 18, 944. [Google Scholar] [CrossRef] [PubMed]
- Aasen, H.; Burkart, A.; Bolten, A.; Bareth, G. Generating 3D hyperspectral information with lightweight UAV snapshot cameras for vegetation monitoring: From camera calibration to quality assurance. ISPRS J. Photogramm. Remote Sens. 2015, 108, 245–259. [Google Scholar] [CrossRef]
- Calderon, R.; Navas-Cortes, J.; Lucena, C.; Zarco-Tejada, P. High-resolution airborne hyperspectral and thermal imagery for early detection of Verticillium wilt of olive using fluorescence, temperature and narrow-band spectral indices. Remote Sens. Environ. 2013, 139, 231–245. [Google Scholar] [CrossRef]
- Bilwaj, G.; Davatzikos, C. Analytic estimation of statistical significance maps for support vector machine based multi-variate image analysis and classification. Neuroimage 2013, 78, 270–283. [Google Scholar] [Green Version]
- Nasi, R.; Honkavaara, E.; Lyytikainen-Saarenmaa, P.; Blomqvist, M.; Litkey, P.; Hakala, T.; Viljanen, N.; Kantola, T.; Tanhuanpaa, T.; Holopainen, M. Using UAV-Based photogrammetry and hyperspectral imaging for mapping bark beetle damage at tree-level. Remote Sens. 2015, 7, 15467–15493. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposalnetworks. In Advances in Neural Information Processing Systems; The MIT Press: London, UK, 2015; pp. 91–99. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection andsemantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA; pp. 785–794. [Google Scholar]
- Pause, M.; Schweitzer, C.; Rosenthal, M.; Keuck, V.; Bumberger, J.; Dietrich, P.; Heurich, M.; Jung, A.; Lausch, A. In situ/remote sensing integration to assess forest health–A review. Remote Sens. 2016, 8, 471. [Google Scholar] [CrossRef]
- Sambo, P.; Nicoletto, C.; Giro, A.; Pii, Y.; Valentinuzzi, F.; Mimmo, T.; Terzano, R.; Lugli, P.; Orzes, G.; Mazzetto, F.; et al. Hydroponic solutions for soilless production systems: Issues and opportunities in a smart agriculture perspective. Front. Plant Sci. 2019, 10, 923. [Google Scholar] [CrossRef] [PubMed]
- Tilly, N.; Aasen, H.; Bareth, G. Fusion of plant height and vegetation indices for the estimation of barley biomass. Remote Sens. 2015, 7, 11449–11480. [Google Scholar] [CrossRef]
- Quirós Vargas, J.J.; Zhang, C.; Smitchger, J.A.; McGee, R.J.; Sankaran, S. Phenotyping of Plant Biomass and Performance Traits Using Remote Sensing Techniques in Pea (Pisum sativum, L.). Sensors 2019, 19, 2031. [Google Scholar] [CrossRef] [PubMed]
- Lowe, A.; Harrison, N.; French, A.P. Hyperspectral image analysis techniques for the detection and classification of the early onset of plant disease and stress. Plant Methods. 2017, 13, 80. [Google Scholar] [CrossRef] [PubMed]
- Jarolmasjed, S.; Kostick, S.; Si, Y.; Quiros, J.; Marzougui, A.; Evans, K.; Sankaran, S. High-Throughput Phenotyping of Fire Blight Disease Symptoms Using Sensing Techniques in Apple. Front. Plant Sci. 2019, 10, 576. [Google Scholar] [CrossRef] [PubMed]
- Vescovo, L.; Wohlfahrt, G.; Balzarolo, M.; Pilloni, S.; Sottocornola, M.; Rodeghiero, M.; Gianelle, D. New spectral vegetation indices based on the near-infrared shoulder wavelengths for remote detection of grassland phytomass. Int. J. Remote Sens. 2012, 33. [Google Scholar] [CrossRef] [PubMed]
- Maes, W.H.; Steppe, K. Perspectives for remote sensing with unmanned aerial vehicles in precision agriculture. Trends Plant Sci. 2019, 24, 152–164. [Google Scholar] [CrossRef] [PubMed]
- Fan, L.; Zhao, J.; Xu, X.; Liang, D.; Yang, G.; Feng, H.; Wei, P.; Yang, H.; Wang, Y.; Chen, G. Hyperspectral-Based Estimation of Leaf Nitrogen Content in Corn Using Optimal Selection of Multiple Spectral Variables. Sensors 2019, 19, 2898. [Google Scholar] [CrossRef] [PubMed]
- Rumpf, T.; Mahlein, A.; Steiner, U.; Oerke, E.; Dehne, H.; Plümer, L. Early detection and classification of plant diseases with support vector machines based on hyperspectral reflectance. Comput. Electron. Agric. 2010, 74, 91–99. [Google Scholar] [CrossRef]
- MacDicken, K.G. Global forest resources assessment 2015: What, why and how? For. Ecol. Manag. 2015, 352, 3–8. [Google Scholar] [CrossRef]
- Rodney, J.K.; Gregory, A.R.; Frédéric, A.; Joberto, V.D.F.; Alan, G.; Erik, L. Dynamics of global forest area: Results from the FAO global forest resources assessment 2015. For. Ecol. Manag. 2015, 352, 9–20. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Average Precisions (%) |
|---|---|
| decision tree | 66.67 |
| random forest | 75.00 |
| support vector machines | 71.34 |
| XGBoost | 67.47 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, X.; Liang, A.; Wu, B.; Su, J.; Zheng, R.; Li, J. UAV-Based High-Throughput Approach for Fast Growing Cunninghamia lanceolata (Lamb.) Cultivar Screening by Machine Learning. Forests 2019, 10, 815. https://doi.org/10.3390/f10090815
Zou X, Liang A, Wu B, Su J, Zheng R, Li J. UAV-Based High-Throughput Approach for Fast Growing Cunninghamia lanceolata (Lamb.) Cultivar Screening by Machine Learning. Forests. 2019; 10(9):815. https://doi.org/10.3390/f10090815
Chicago/Turabian StyleZou, Xiaodan, Anjie Liang, Bizhi Wu, Jun Su, Renhua Zheng, and Jian Li. 2019. "UAV-Based High-Throughput Approach for Fast Growing Cunninghamia lanceolata (Lamb.) Cultivar Screening by Machine Learning" Forests 10, no. 9: 815. https://doi.org/10.3390/f10090815