Forest-Type Classification Using Time-Weighted Dynamic Time Warping Analysis in Mountain Areas: A Case Study in Southern China


Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data Sets
2.2.1. Remote Sensing Images
2.2.2. Training and Validation Samples
2.3. Methodology
2.3.1. Preprocessing
- Cloud mask. For Landsat-8, “cloud shadows” (bit 3), “clouds” (bit 5), medium–high “cloud confidence” (bits 6–7), and medium–high “cirrus confidence” (Landsat-8 only, bits 8–9) were masked using the pixel quality attributes band. For Sentinel, Sentinel-2 Band QA60 was used to identify and mask flagged cloud and cirrus pixels. The remaining cloud and aerosols were then identified using an aerosol band (Band 1) and were likewise masked. The latter was accomplished using a threshold of Band 1 ≥ 1500.
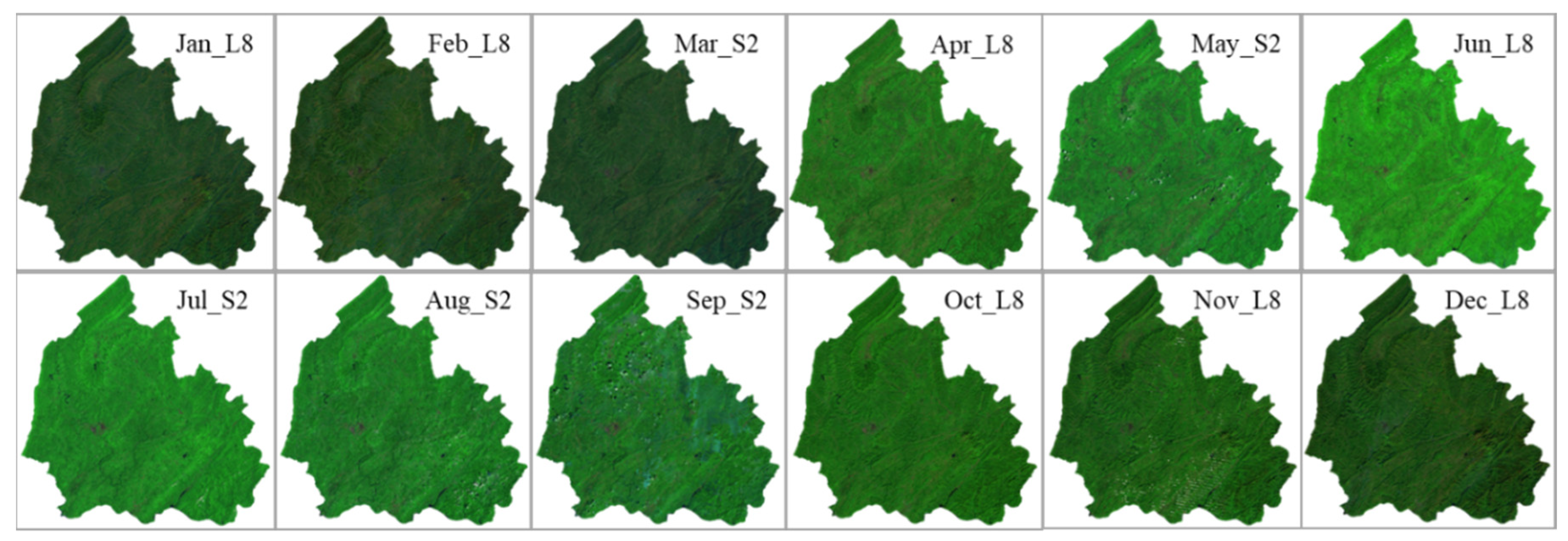
- Image composition. The method described by [43] was used to composite a new image, which includes topographic corrections and image composition. The images from the same month were used to composite an image to obtain time-series images for the study area. Sentinel-2 data were used, and if for a specific month (e.g., June), an image covering the study area using Sentinel-2 could not be obtained, Landsat-8 data from the same month between 2016 and 2018 were used to compose the image. To ensure the consistency in spatial resolution for Landsat-8 and Sentinel-2, the all bands used for Landsat-8 were resampled to the same spatial resolution to Sentinel-2 (10 m). Finally, 12 images with only visible blue, green, red, and near-infrared bands for the study area with 10 m spatial resolution were generated, as shown in Figure 3.
- NDVI time series creation. The NDVI was used to extract temporal patterns. This index is regarded as an appropriate spectral indicator of vegetation activity and phenological characteristics and a powerful and phenology-based method to carry out vegetation-cover classification at regional and global scales [29,44,45,46]. The NDVI has been generated from the red and near-infrared bands:
2.3.2. Classification
2.3.3. Comparison and Evaluation
3. Results
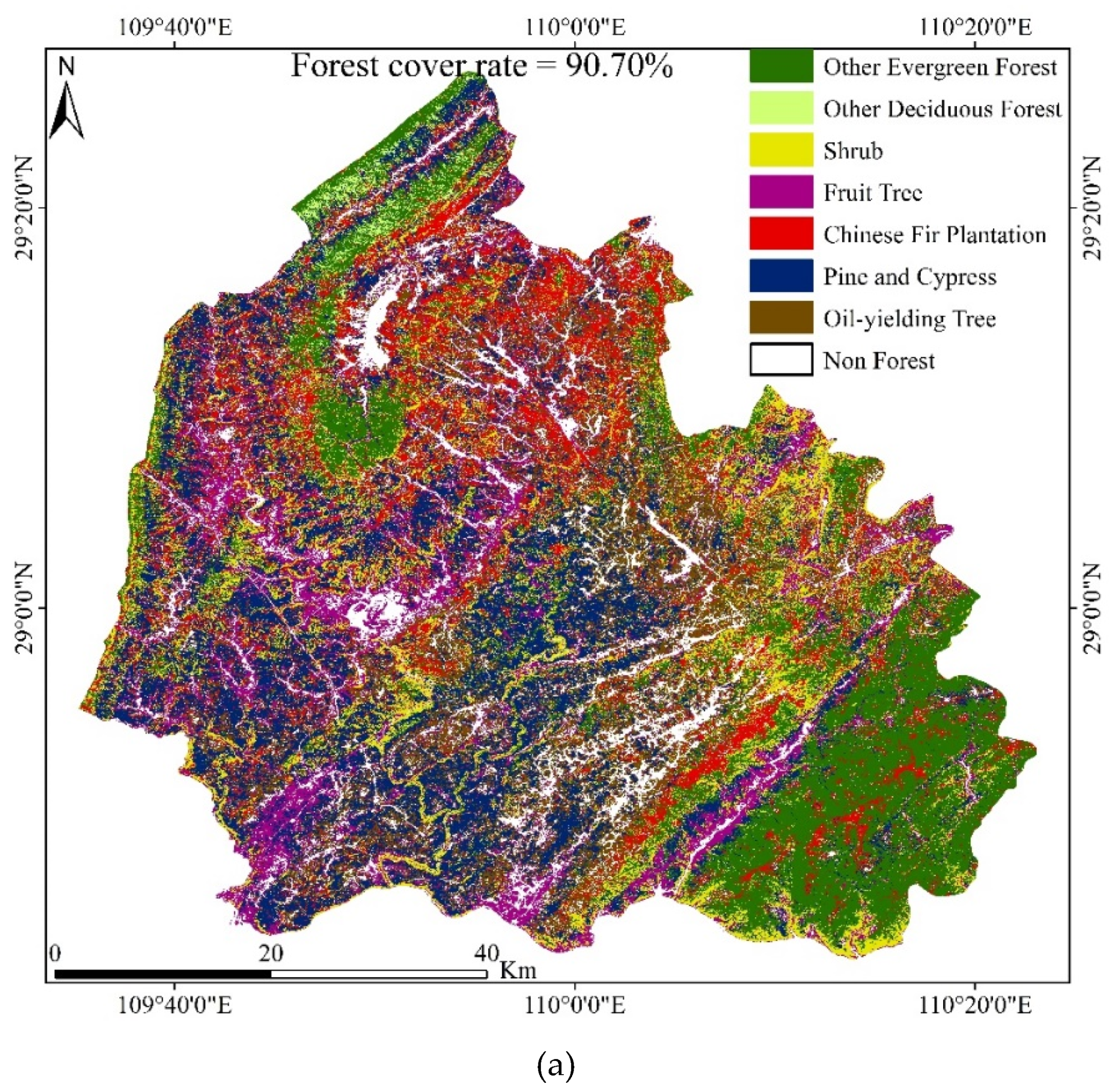
3.1. Classification Results
3.2. Evaluation
4. Discussion
4.1. Identification of Temporal Patterns
4.2. Comparison of TWDTW, RF, and SMV Methods
4.3. Sensitivity to the Number of Training Data
4.4. Combination of Sentinel-2 and Landsat-8 Time Series
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tang, S.Q. Soil and water conservation of forest in mountain area. Fujian Soil Water Conserv. 2003, 2, 10–13. [Google Scholar]
- Iverson, L.R.; Graham, R.L.; Cook, E.A. Applications of satellite remote sensing to forested ecosystems. Landsc. Ecol. 1989, 3, 131–143. [Google Scholar] [CrossRef]
- Kerr, J.T.; Ostrovsky, M. From space to species: Ecological applications for remote sensing. Trends Ecol. Evol. 2003, 18, 299–305. [Google Scholar] [CrossRef]
- Liu, Y.; Gong, W.; Hu, X.; Gong, J. Forest Type Identification with Random Forest Using Sentinel-1A, Sentinel-2A, Multi-Temporal Landsat-8 and DEM Data. Remote Sens. 2018, 10, 946. [Google Scholar] [CrossRef]
- Lei, G.B.; Li, A.N.; Bian, J.H.; Zhang, Z.J.; Zhang, W.; Wu, B.F. An practical method for automatically identifying the evergreen and deciduous characteristic of forests at mountainous areas: A case study in Mt.Gongga Region. Acta Ecol. Sin. 2014. [Google Scholar] [CrossRef]
- Peterson, D.L.; Spanner, M.A.; Running, S.W.; Teuber, K.B. Relationship of thematic mapper simulator data to leaf area index of temperate coniferous forest. Remote Sens. Environ. 1987, 22, 323–341. [Google Scholar] [CrossRef]
- Ardö, J. Volume quantification of coniferous forest compartments using spectral radiance recorded by Landsat Thematic Mapper. Int. J. Remote Sens. 1992, 13, 1779–1786. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K.; Teply, J. Mapping old growth forests on national forest and park lands in the Pacific Northwest from remotely sensed data. Photogramm. Eng. Remote Sens. 1993, 59, 529–535. [Google Scholar]
- Gemmell, F.M. Effects of forest cover, terrain, and scale on timber volume estimation with thematic mapper data in a rocky mountain site. Remote Sens. Environ. 1995, 51, 291–305. [Google Scholar] [CrossRef]
- Martin, M.E.; Newman, S.D.; Aber, J.D.; Congalton, R.G. Determining forest species using high spectral resolution remote sensing data. Remote Sens. Environ. 1998, 65, 249–254. [Google Scholar] [CrossRef]
- Kilpeläinen, P.; Tokola, T. Gain to be achieved from stand delineation in LANDSAT TM image-based estimates of stand volume. For. Ecol. Manag. 1999, 124, 105–111. [Google Scholar] [CrossRef]
- Pax-Lenney, M.; Woodcock, C.E.; Macomber, S.A.; Song, C. Forest mapping with a generalized classifier and Landsat TM data. Remote Sens. Environ. 2001, 77, 241–250. [Google Scholar] [CrossRef]
- Tokola, T.; Sarkeala, J.; Linden, M.V.D. Use of topographic correction in Landsat TM-based forest interpretation in Nepal. Int. J. Remote Sens. 2001, 22, 551–563. [Google Scholar] [CrossRef]
- Dorren, L.K.A.; Maier, B.; Seijmonsbergen, A.C. Improved Landsat-based forest mapping in steep mountainous terrain using object-based classification. For. Ecol. Manag. 2003, 183, 31–46. [Google Scholar] [CrossRef]
- Kosaka, N.; Akiyama, T.; Tsai, B.; Kojima, T. Forest type classification using data fusion of multispectral and panchromatic high-resolution satellite imageries. In Proceedings of the IGARSS ′05 2005 IEEE International Geoscience and Remote Sensing Symposium, Seoul, Korea, 29 July 2005. [Google Scholar]
- Ruefenacht, B.; Finco, M.V.; Nelson, M.D.; Czaplewski, R.; Helmer, E.H.; Blackard, J.A.; Holden, G.R.; Lister, A.J.; Salajanu, D.; Weyermann, D.; et al. Conterminous U.S. and Alaska Forest Type Mapping Using Forest Inventory and Analysis Data. Photogramm. Eng. Remote Sens. 2008, 74, 1379–1388. [Google Scholar] [CrossRef]
- Kim, M.; Madden, M.; Warner, T.A. Forest Type Mapping using Object-specific Texture Measures from Multispectral Ikonos Imagery. Photogramm. Eng. Remote Sens. 2009, 75, 819–829. [Google Scholar] [CrossRef]
- Kempeneers, P.; Sedano, F.; Seebach, L.; Strobl, P.; San-Miguel-Ayanz, J. Data Fusion of Different Spatial Resolution Remote Sensing Images Applied to Forest-Type Mapping. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4977–4986. [Google Scholar] [CrossRef]
- Laurel, B.; Leonhard, B.; Ellen, H.; Kruse, B. Tree Species Classification Using Hyperspectral Imagery: A Comparison of Two Classifiers. Remote Sens. 2016, 8, 445. [Google Scholar]
- Zhang, X.; Treitz, P.M.; Chen, D.; Quan, C.; Shi, L.; Li, X. Mapping mangrove forests using multi-tidal remotely-sensed data and a decision-tree-based procedure. Int. J. Appl. Earth Obs. Geoinf. 2017, 62, 201–214. [Google Scholar] [CrossRef]
- Jia, M.M.; Ren, C.Y.; Liu, D.W.; Wang, Z.M.; Tang, X.G.; Dong, Z.Y. Object-oriented forest classification based on combination of HJ-1 CCD and MODISNDVI data. Acta Ecol. Sin. 2014, 34, 7167–7174. [Google Scholar]
- Grabska, E.; Hostert, P.; Pflugmacher, D.; Ostapowicz, K. Forest Stand Species Mapping Using the Sentinel-2 Time Series. Remote Sens. 2019, 11, 1197. [Google Scholar] [CrossRef]
- Pasquarella, V.J.; Holden, C.E.; Woodcock, C.E. Improved mapping of forest type using spectral-temporal Landsat features. Remote Sens. Environ. 2018, 210, 193–207. [Google Scholar] [CrossRef]
- Zhu, X.; Liu, D. Accurate mapping of forest types using dense seasonal Landsat time-series. ISPRS J. Photogramm. Remote Sens. 2014, 96, 1–11. [Google Scholar] [CrossRef]
- Cheng, K.; Wang, J. Forest Type Classification Based on Integrated Spectral-Spatial-Temporal Features and Random Forest Algorithm—A Case Study in the Qinling Mountains. Forests 2019, 10, 559. [Google Scholar] [CrossRef]
- Li, M.; Im, J.; Beier, C. Machine learning approaches for forest classification and change analysis using multi-temporal Landsat TM images over Huntington Wildlife Forest. GISci. Remote Sens. 2013, 50, 361–384. [Google Scholar] [CrossRef]
- Duro, D.C.; Franklin, S.E.; Dubé, M.G. A comparison of pixel-based and object-based image analysis with selected machine learning algorithms for the classification of agricultural landscapes using SPOT-5 HRG imagery. Remote Sens. Environ. 2012, 118, 259–272. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Potapov, P.V.; Dempewolf, J.; Talero, Y.; Hansen, M.C.; Stehman, S.V.; Vargas, C.; Rojas, E.J.; Castillo, D.; Mendoza, E.; Calderón, A.; et al. National satellite-based humid tropical forest change assessment in Peru in support of REDD+ implementation. Environ. Res. Lett. 2014, 9, 124012. [Google Scholar] [CrossRef]
- Bader, M.Y.; Ruijten, J.J.A. A topography-based model of forest cover at the alpine tree line in the tropical Andes. J. Biogeogr. 2008, 35, 711–723. [Google Scholar] [CrossRef]
- Gottlicher, D.; Obregon, A.; Homeier, J.; Rollenbeck, R.; Nauss, T.; Bendix, J. Land-cover Classification in the Andes of Southern Ecuador Using Landsat ETM+ Data as a Basis for SVAT Modelling. Int. J. Remote Sens. 2009, 30, 1867–1886. [Google Scholar] [CrossRef]
- Gudex-Cross, D.; Pontius, J.; Adams, A. Enhanced forest cover mapping using spectral unmixing and object-based classification of multi-temporal Landsat imagery. Remote Sens. Environ. 2017, 196, 193–204. [Google Scholar] [CrossRef]
- Luis, V.I.; Yasumasa, H.; Lenin, V.S.; Noemi, S.T. Natural Forest Mapping in the Andes (Peru): A Comparison of the Performance of Machine-Learning Algorithms. Remote Sens. 2018, 10, 782. [Google Scholar]
- Wessel, M.; Brandmeier, M.; Tiede, D. Evaluation of Different Machine Learning Algorithms for Scalable Classification of Tree Types and Tree Species Based on Sentinel-2 Data. Remote Sens. 2018, 10, 1419. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Nitze, I.; Schulthess, U.; Asche, H. Comparison of machine learning algorithms random forest, artificial neural network and support vector machine to maximum likelihood for supervised crop type classification. In Proceedings of the 4th GEOBIA, Rio de Janeiro, Brazil, 7–9 May 2012; pp. 7–9. [Google Scholar]
- Sakoe, H.; Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 43–49. [Google Scholar] [CrossRef]
- Baumann, M.; Ozdogan, M.; Richardson, A.D.; Radeloff, V.C. Phenology from Landsat when data is scarce: Using MODIS and dynamic time-warping to combine multi-year Landsat imagery to derive annual phenology curves. Int. J. Appl. Earth Obs. Geoinf. 2017, 54, 72–83. [Google Scholar] [CrossRef]
- Petitjean, F.; Inglada, J.; Gançarski, P. Satellite image time series analysis under time warping. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3081–3095. [Google Scholar] [CrossRef]
- Maus, V.; Camara, G.; Cartaxo, R.; Sanchez, A.; Ramos, F.M.; Queiroz, G.R.D. A time-weighted dynamic time warping method for land-use and land-cover mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1–11. [Google Scholar] [CrossRef]
- Chen, Z. Feature and administering studying of the landslide at center street, Huitong county. Hunan Geol. 1999, 18, 249–260. [Google Scholar]
- Segovia, A.R.; Bullock, E.L.; Corral, L.; Nolte, C. Project Impact Assessment on Deforestation and Forest Degradation (1-44, Rep. No. 2149/BL-GU). Available online: https://hdl.handle.net/2144/31321 (accessed on 31 August 2019).
- Hurni, K.; Heinimann, A.; Würsch, L. Technical Report. Centre for Development and Environment (CDE) University of Bern, (Google Earth Engine Image Pre-processing Tool: Background and Methods). 2017. Available online: https://www.cde.unibe.ch/e65013/e542846/e707304/e707386/e707388/CDE_Pre-processingTool-BackgroundAndMethods_eng.pdf (accessed on 9 October 2019).
- Potapov, P.; Turubanova, S.; Hansen, M.C. Regional-scale boreal forest cover and change mapping using Landsat data composites for European Russia. Remote Sens. Environ. 2011, 115, 548–561. [Google Scholar] [CrossRef]
- Wardlow, B.D.; Egbert, S.L.; Kastens, J.H. Analysis of Time-Series MODIS 250m Vegetation Index Data for Crop Classification in the US Central Great Plains. Remote Sens. Environ. 2007, 108, 290–310. [Google Scholar] [CrossRef] [Green Version]
- Jia, M.; Wang, Z.; Wang, C.; Mao, D.; Zhang, Y. A New Vegetation Index to Detect Periodically Submerged Mangrove Forest Using Single-Tide Sentinel-2 Imagery. Remote Sens. 2019, 11, 2043. [Google Scholar] [CrossRef] [Green Version]
- Lawrence, R.; Juang, B. Fundamentals of Speech Recognition; Prentice-Hall International, Inc.: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Berndt, D.J.; Clifford, J. Using Dynamic Time Warping to Find Patterns in Time Series. In KDD Workshop; Fayyad, U.M., Uthurusamy, R., Eds.; AAAI Press: Seattle, WA, USA, 1994; pp. 359–370. [Google Scholar]
- Eamonn, K.; Ratanamahatana, C.A. Exact Indexing of Dynamic Time Warping. Knowl. Inf. Syst. 2005, 7, 358–386. [Google Scholar]
- Petitjean, F.; Weber, J. Efficient satellite image time series analysis under time warping. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1143–1147. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sens. Environ. 2017, 204, 509–523. [Google Scholar] [CrossRef]
- Victor, M.; Gilberto, C.; Marius, A.; Pebesma, E. Dtwsat: Time-Weighted Dynamic Time Warping for Satellite Image Time Series Analysis in R. J. Stat. Softw. 2019, 88, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Wood, S.N. Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2011, 73, 3–36. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Breiman, L. Random forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and regression by random Forest. R News 2002, 2, 18–22. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lawrence, R.L.; Wood, S.D.; Sheley, R.L. Mapping invasive plants using hyperspectral imagery and Breiman cutler classifications (Random Forest). Remote Sens. Environ. 2006, 100, 356–362. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recogn. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Hasan, S.; Shi, W.; Zhu, X.; Abbas, S. Monitoring of Land Use/Land Cover and Socioeconomic Changes in South China over the Last Three Decades Using Landsat and Nighttime Light Data. Remote Sens. 2019, 11, 1658. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.; Song, K.; Kim, S.; Townshend, J.R.G.; Davis, P.; Masek, J.G.; Goward, S.N. Use of a dark object concept and support vector machines to automate forest cover change analysis. Remote Sens. Environ. 2008, 112, 970–985. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Ma, Y.Z. Study on application of bushes and shrubs in planting landscape of Hunan. Hunan For. Sci. Technol. 2006, 1, 49–51. [Google Scholar]
- Yan, L.; Roy, D.P. Automated crop field extraction from multi-temporal web enabled Landsat data. Remote Sens. Environ. 2014, 144, 42–64. [Google Scholar] [CrossRef] [Green Version]
- Manabe, V.D.; Melo, M.R.S.; Rocha, J.V. Framework for Mapping Integrated Crop-Livestock Systems in Mato Grosso, Brazil. Remote Sens. 2018, 10, 1322. [Google Scholar] [CrossRef] [Green Version]
- Viana, C.M.; Girão, I.; Rocha, J. Long-Term Satellite Image Time-Series for Land Use/Land Cover Change Detection Using Refined Open Source Data in a Rural Region. Remote Sens. 2019, 11, 1104. [Google Scholar] [CrossRef] [Green Version]
- Chinsu, L.; Wu, C.C.; Tsogt, K.; Ouyang, Y.C.; Chang, C.I. Effects of Atmospheric Correction and Pansharpening on LULC Classification Accuracy Using WorldView-2 Imagery. Inf. Process. Agric. 2015, 2, 25–36. [Google Scholar]
- Song, C.; Woodcock, C.; Seto, K.; Lenney, M.P.; Macomber, S. Classification and Change Detection Using Landsat TM Data: When and How to Correct Atmospheric Effects? Remote Sens. Environ. 2001, 75, 230–244. [Google Scholar] [CrossRef]
- Hao, P.; Zhan, Y.; Wang, L.; Niu, Z.; Shakir, M. Feature selection of time series MODIS data for early crop classification using random forest: A case study in Kansas, USA. Remote Sens. 2015, 7, 5347–5369. [Google Scholar] [CrossRef] [Green Version]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of random forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Millard, K.; Richardson, M. On the importance of training data sample selection in random forest image classification: A case study in peatland ecosystem mapping. Remote Sens. 2015, 7, 8489–8515. [Google Scholar] [CrossRef] [Green Version]
- Valero, S.; Morin, D.; Inglada, J.; Sepulcre, G.; Arias, M.; Hagolle, O.; Dedieu, G.; Bontemps, S.; Defourny, P.; Koetz, B. Production of a dynamic cropland mask by processing remote sensing image series at high temporal and spatial resolutions. Remote Sens. 2016, 8, 55. [Google Scholar] [CrossRef] [Green Version]
- Reiche, J.; Hamunyela, E.; Verbesselt, J.; Hoekman, D.; Herold, M. Improving near-real time deforestation monitoring in tropical dry forests by combining dense Sentinel-1 time series with Landsat and ALOS-2 PALSAR-2. Remote Sens. Environ. 2018, 2018, 147–161. [Google Scholar] [CrossRef]
- Mizuochi, H.; Hayashi, M.; Tadono, T. Development of an Operational Algorithm for Automated Deforestation Mapping via the Bayesian Integration of Long-Term Optical and Microwave Satellite Data. Remote Sens. 2019, 11, 2038. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forest Type | Abbreviation | Training | Validation |
|---|---|---|---|
| Other evergreen trees | OEF | 60 | 60 |
| Other deciduous trees | ODF | 71 | 71 |
| Shrub | SHR | 80 | 80 |
| Fruit tree | FT | 75 | 75 |
| Chinese fir plantation | CFP | 67 | 67 |
| Pine and cypress | PC | 73 | 73 |
| Oil-yielding tree | OYT | 57 | 57 |
| Non-forest | Non | 50 | 50 |
| Method | MOA (%) | MKC |
|---|---|---|
| TWDTW | 93.81 (±0.003) | 0.93 (±0.002) |
| RF | 91.54 (±0.004) | 0.90 (±0.005) |
| SVM | 89.66 (±0.005) | 0.88 (±0.006) |
| Method | OA (%) | KC |
|---|---|---|
| TWDTW | 93.44 | 0.92 |
| RF | 91.11 | 0.89 |
| SVM | 89.19 | 0.87 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, K.; Wang, J. Forest-Type Classification Using Time-Weighted Dynamic Time Warping Analysis in Mountain Areas: A Case Study in Southern China. Forests 2019, 10, 1040. https://doi.org/10.3390/f10111040
Cheng K, Wang J. Forest-Type Classification Using Time-Weighted Dynamic Time Warping Analysis in Mountain Areas: A Case Study in Southern China. Forests. 2019; 10(11):1040. https://doi.org/10.3390/f10111040
Chicago/Turabian StyleCheng, Kai, and Juanle Wang. 2019. "Forest-Type Classification Using Time-Weighted Dynamic Time Warping Analysis in Mountain Areas: A Case Study in Southern China" Forests 10, no. 11: 1040. https://doi.org/10.3390/f10111040