1. Introduction
The study of background subtraction for moving object detection is an active research area divided into two main paradigms: modeling the scene with stationary and non-stationary objects. Traditionally, methods found in the literature try to create groupings of space-time regions that present coherence in the movement to discern between the model representing the scene and non-stationary objects.
There are several challenges in posing the detection problem as a motion segmentation problem. The most straightforward approach is based on translational motion, in which two frames are compared [
1,
2,
3]. This method is highly adaptable to dynamic changes in the scene but generally leads to poor results due to incorrect motion detection and not detecting uniform regions of the objects, which contain relevant information for segmentation.
Moreover, probabilistic models set the object as the detection of outliers in motion [
4,
5,
6]. These methods use pixel statistics to update and maintain background model information and compare it with the statistical data of moving objects. Probabilistic models are increasingly used for their reliability in scenarios where shadows, noise, and lighting changes are present. Even so, they assume that the movement changes are relatively small compared to the scene. So, if the statistical information does not come from the background, the problem becomes more challenging.
These models are capable of modeling variability in video sequences, which is why they have been widely used primarily in applications of video surveillance [
7,
8,
9], moving object detection [
10,
11], human detection [
12,
13,
14], and vehicle detection for traffic [
15,
16], among others.
The ability of the method to reduce the influence of noise [
17], shadows, changes in lighting [
18], changes in the structure of the object [
19], or textures [
20] depends on the robustness of the algorithm [
21]. Although there are many concepts for background modeling or foreground detection, algorithms dedicated to solving all these situations increase their complexity, so the focus of actual methods is to solve more specific problems. Some solutions to these problems are described below.
Background Estimation (
). In the method proposed by [
22], a variance estimator is used to understand the variability of pixel intensity. This estimator is used as a threshold. Then, their intensity fluctuations are compared to update the background to a temporal dispersion. Some limitations are the inefficiency of detecting moving objects in complex or very dense backgrounds and temporarily settled objects; these objects are quickly incorporated into the background model.
Markov Random Field-Based Motion Detection (MRFMD). This method, introduced by [
23], divides the image into several regions to segment it spatially. In the Markov model, the color distribution, temporal color coherence, and edge map in the time frame are used to determine a moving object’s spatial direction, color characteristics, and temporal direction. The advantage of this model is to preserve edges to improve object detection with fewer contour effects.
Difference-Based Spatio-Temporal Entropy Image (DSTEI). As described in [
24,
25,
26], changes in pixel intensities are considered as energy. Moving objects produce more energy, so a normalized histogram is calculated for the area in the image to obtain the frequency of intensity changes. Finally, color information is quantified with the scalar product between the logarithm of the frequency vector and the frequency vector. The advantage of this method is its robustness to gradients, but it is susceptible to false detections, such as sudden changes in shadows or lighting.
Eigen-Background Subtraction. This technique is used by many authors, such as [
27,
28,
29]. Here, the background is represented by a reconstructed image from a set of dominant eigenvectors. Then, only the difference between the current image and the reconstructed image is calculated to find the foreground object. In response to this idea in [
30], using the least essential feature vector as an alternative solution and improving the background model representation is recommended.
Simplified Self-Organized Background Subtraction (SOBS). In this model, each color pixel is mapped to a neural map of
n segments. This map is the background model, and each current pixel is evaluated to find the best match. That is, the Euclidean distance is used to find the minimum distance between the intensity of the current color and the neural map [
31,
32,
33]. The advantage of this model is to adapt to gradual lighting changes or dynamic backgrounds. Even so, the shadow cast by the object will be detected and included in the reconstructed background model.
Dynamic Mode Decomposition (DMD). Despite being a method used to analyze the behavior of fluids [
34,
35,
36,
37,
38], ref. [
39] used it for image analysis, considering a video sequence as a dynamic fluid. A matrix decomposition is carried out from the image sequences, which will be propagated to a matrix, from which the singular value decomposition is obtained. The eigenvectors of this decomposition are dynamic patterns, and the values represent the temporal dynamics of these patterns. This technique allows fast and scalable decomposition of video sequences.
Sliding Window-Based Change Detection (SWCD). It was introduced by [
40]. Among them, the dynamic changes of pixel intensity are detected and adjusted to the background image. In addition, this approach features a sliding window and dynamic control to update the background image and perform background subtraction. According to the authors, this method overcomes intermittent changes in lighting, camera vibration, and moving objects. However, removing misclassified pixels depends on the window size [
41]. This method is applied in various studies, including the analysis of eucalyptus plantation [
42], change detection on the Earth’s surface [
43], and the dynamic inference of airport flight ground service networks [
44].
A universal background subtraction algorithm (ViBe). This method was proposed by [
45] and has been widely used in scenes with dynamic background [
46], camera movement [
47], or foggy scene [
48], because of its easy implementation and high efficiency. The proposal consists of storing a set of past values for each neighborhood pixel. Then, the set is compared to determine if each pixel belongs to the background model or if the model must be adapted to these changes. Finally, the neighboring pixels are evaluated when the pixel is classified as the background. However, ref. [
49] identifies problems such as the ghost effect, sensitivity to shadows, or sensitivity to the target’s movement speed.
Gaussian Mixture Model (GMM). This method was introduced by [
6]. It has been widely accepted in the literature [
50] and is one of the primary references because it is a powerful tool for grouping. Generally, this method characterizes each newly observed pixel value as a Gaussian mixture representing the background pattern. If the observed pixels do not match any Gaussian distribution, the distribution with the least probability is replaced by the new parameter. However, there are difficulties with shadows, irregular background motion, objects that stop suddenly, or objects that maintain a similar intensity to the background. Nevertheless, the model has been proven to be stable outdoors and reliable for light or long-term changes in the scene [
51].
Euclidean distance (DEU). It is a simple background model where moving objects can be detected with the Euclidean distance measure. The lighting changes are updated iteratively with the previous image as the background model. However, it is not robust in the face of changes in light, stationary objects, shadows, and ghost effects [
52].
Deep Learning Methods. In recent years, the adoption of deep learning techniques for computer vision applications has surged due to their successful implementation. Consequently, researchers have transitioned from conventional to deep learning models for background subtraction. Convolutional neural networks (CNNs) were introduced for background subtraction in 2016 [
33]. Trained in a supervised way, the CNNs used in background subtraction are categorized into basic CNN, multi-scale and cascaded CNNs, fully CNNs, deep CNNs, 3D-CNNs, and structured CNNs [
21]. Deep learning-based methods such as FgSegNet [
53,
54] and its variants represent the field’s current state; however, their supervised nature relies on the availability of large amounts of data for training.
This paper proposes a background subtraction method based on local texture analysis. We assume that the discrete topological surface of the scene satisfies a specific frequency and direction of the Gabor filter bank. The Gabor filter is a linear filter mainly used for texture analysis and discrimination. In its two-dimensional representation, it is a Gaussian kernel function modulated by a sine wave, characterized by the parameters
and
. In this work, we use it as a texture descriptor. We propose to use the magnitude and phase of the filter to characterize the information that is not sensitive to light changes and build a background model. Based on the results, our method maintains the invariance of subtle changes in light. We assess computational efficiency by processing image series of varying sizes and resolutions. Our test is run on Intel(R) Core i7-7500U CPU with 32.0 GB RAM, achieving a processing rate of 10 frames per second. Upon repeating the experiments, variability in the execution times for each series is observed, which is why it is decided to carry out 30 repetitions, analyzing a total of 181,470 images. The purpose of this is to calculate descriptive statistics, thus obtaining the following results showed in
Table 1.
While the proposed method may not achieve the same level of performance as deep learning approaches, it offers several advantages that make it a valuable alternative in certain scenarios. For example, the method is particularly useful when the traditional method cannot handle situations where an object’s color intensity and texture are similar to its surroundings. The proposed method is also invariant to light changes, a common challenge in video surveillance systems. Moreover, the proposed method is computationally efficient and can process video data in real time, making it a faster alternative to deep learning approaches that require large amounts of computational resources and training data. These advantages suggest that the proposed method may be more suitable for real-time object detection and tracking applications, such as video surveillance systems.
The main contributions of this work are (i) the spatio-temporal algorithm that incorporates statistical moments into the Gabor filter bank, (ii) overcoming the shadow detection problem, and (iii) the segmentation of objects with uniform texture around the environment.
The rest of this document is organized as follows.
Section 2 describes the theoretical aspects, and
Section 3 describes the experimental model, in which texture analysis and motion detection are performed.
Section 4 presents the experiments and results.
Section 5 discusses the results, and
Section 6 presents the conclusion and limitations of the approach.
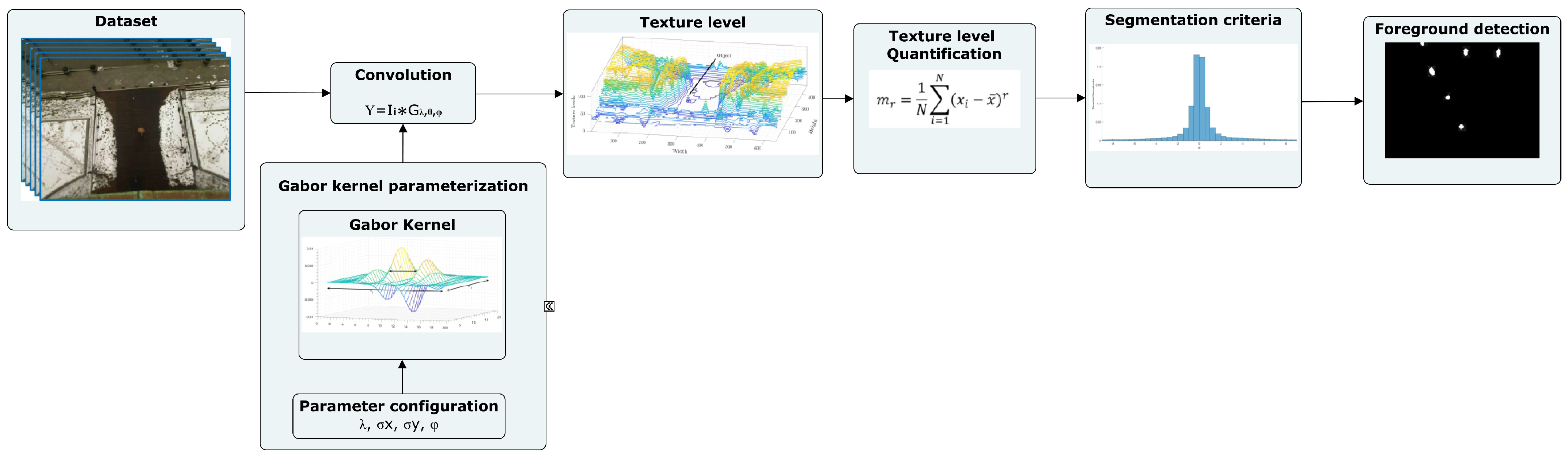
3. Materials and Methods
This section describes how to perform background subtraction of our method called GMBSM.
Section 3.1 describes the dataset used and the scene’s challenges.
Section 3.2 explains the construction of the Gabor kernel for texture characterization.
Section 3.3 describes texture-level quantization, and
Section 3.4 describes foreground detection.
Figure 2 shows the process.
3.1. Dataset
Scene
. We use the dataset in [
63] to analyze a sequence of 500 images with
pixels dimensions. This scene consists of a fixed camera that can see the ground floor. According to the author, the most notable feature is the constantly changing lighting due to the position of the sun, artificial light sources, and shadows cast by some buildings.
Scene
. To deepen our analysis, we extract 700 images with a size of
pixels from the PETS database [
64]. This scene includes scattered people walking randomly in bright, dark jackets of uniform and non-uniform textures.
Scene . The scene involves people walking through a train station while someone stops and leaves an object on the floor. We choose this scene because shadows and reflections are present due to the lighting conditions. In addition, in some areas of the image, the intensity of the background and the object’s intensity are similar. These effects cause other models to consider that the objects and the background have the same structure. The image size of this sequence is pixels.
Scene . The traffic flow shows some shadows on the highway from the sun’s position. In addition, dynamic backgrounds are generated due to the movement of the leaves. The dimensions of these images are pixels.
Scene . A man walked into the office, picked up a book, read it, and left the room in this scene. There are some difficulties here, such as light changes and the color intensity of the clothes relative to the background. The dimensions of these images are pixels.
Scene . This scene shows some people walking or cycling through the park. The challenge in this scene is the over-illumination and under-sampling of the sequence. The dimensions of these images are pixels.
The images of the
to
scenes are obtained from the dataset in [
65].
3.2. Gabor Kernel Parameterization
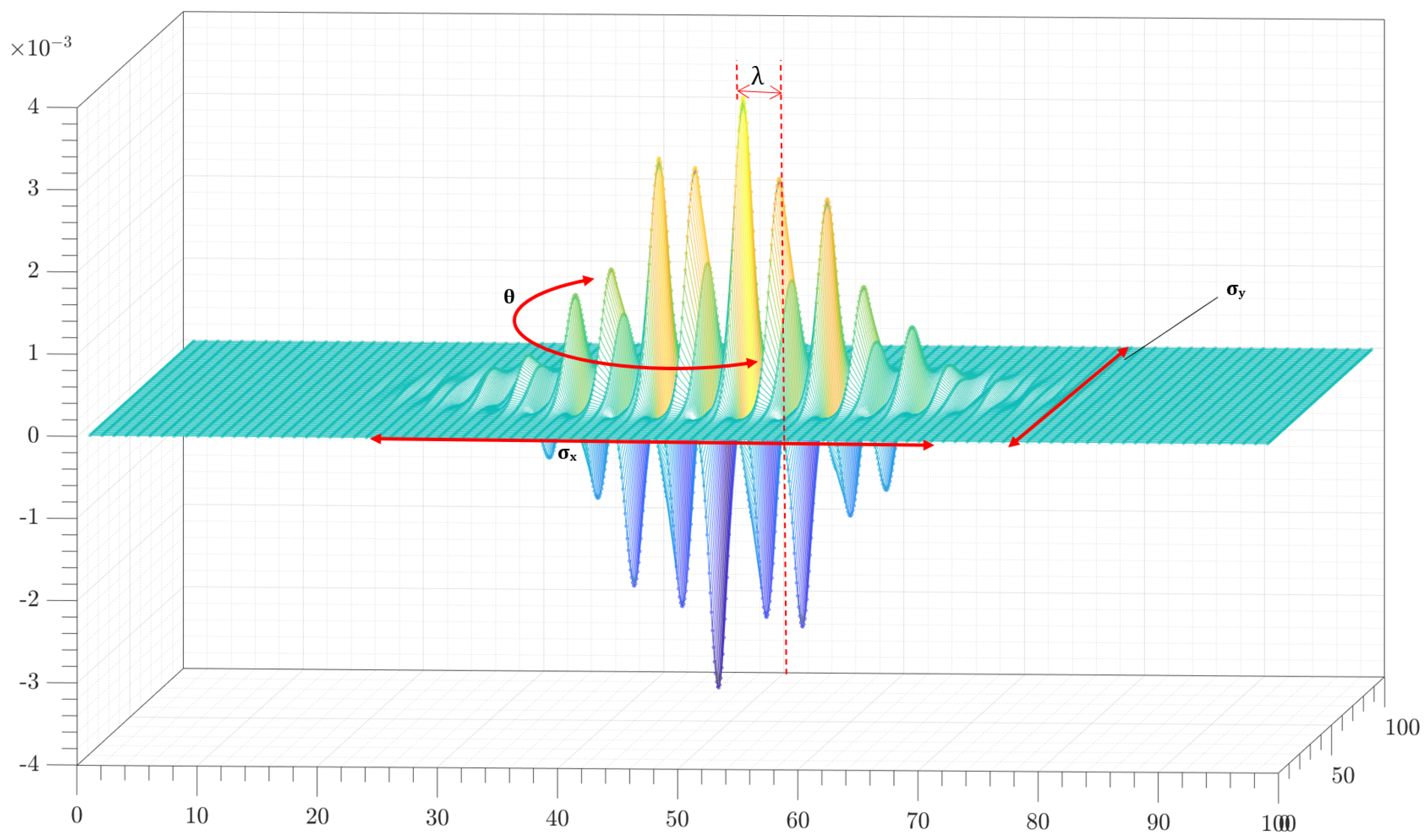
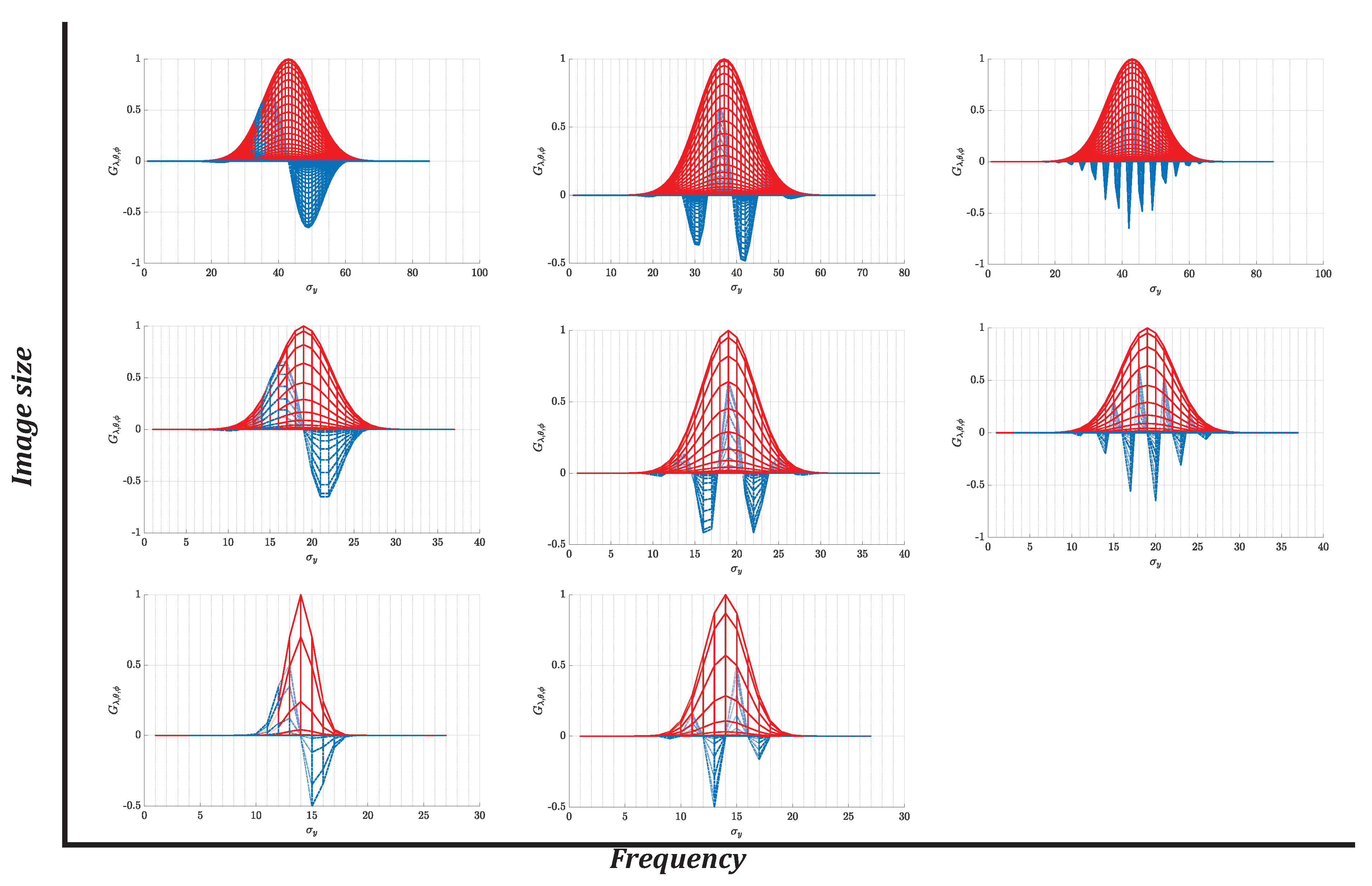
The Gabor function depends on parameters , , and , which produce different effects on the image. Both the carrier function and the envelope are in function of , which means that when you have a large value, the frequency of the envelope is lower. In modeling terms, the filter will attenuate objects with thin edges. However, if the lambda is small, it will have a higher frequency, which allows the filter to attenuate coarse edges so that more details can be visualized but with a higher sensitivity to noise.
On the other hand, and make the Gaussian term large or small in some of its axes, which means that if the Gaussian function extends more on the x-axis than on the y-axis, and vice versa, the noise and edges on that axis will be dimmed on that axis. However, if the Gaussian term is small, the image’s smoothness will be low and noisy.
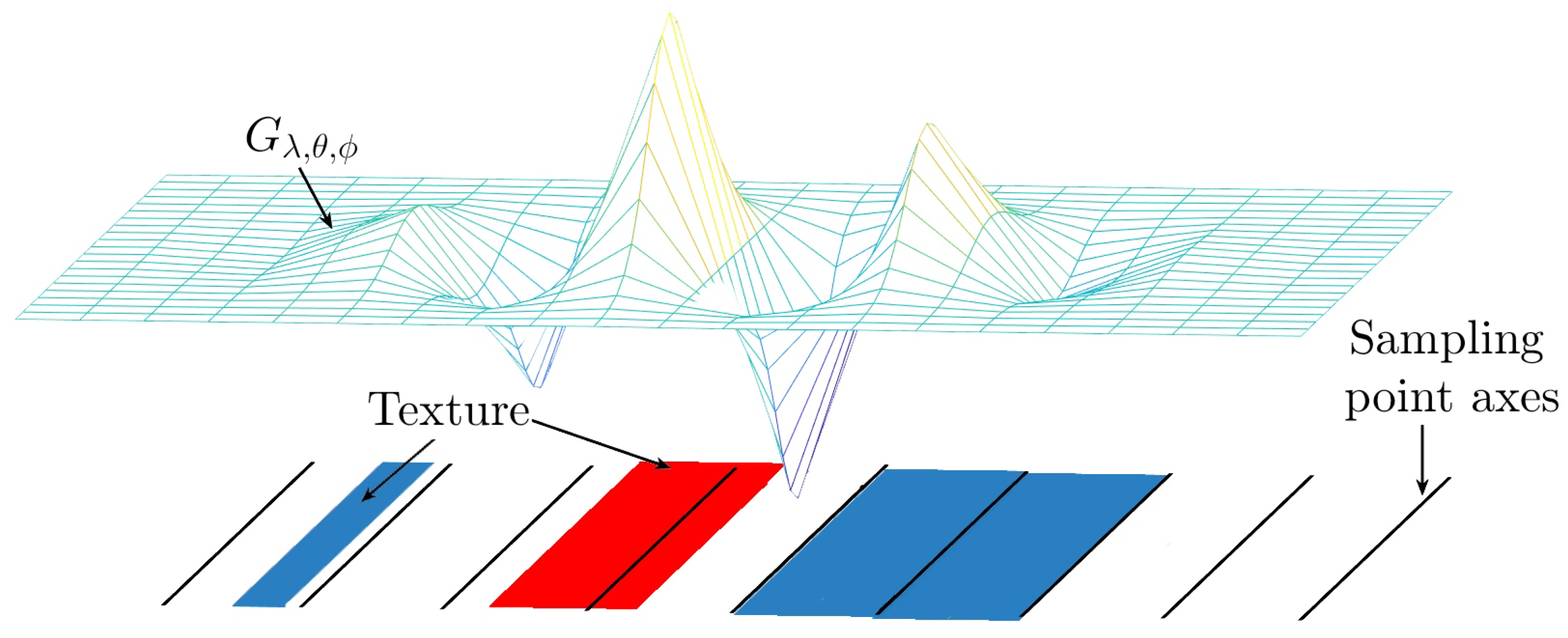
In
Figure 3, we show two distributions:
the Gaussian function, whose size depends on
, and
the relative frequencies of the Gabor filter, where the peak value both positive and negative represent sampling points. Then, as can be seen in the figure, the larger the image size, the higher the density of the Gaussian required. In this way, the noise attenuation is greater. And the smaller the image size, the lower the frequency and density required, but this response will generate more noise and possible false edges.
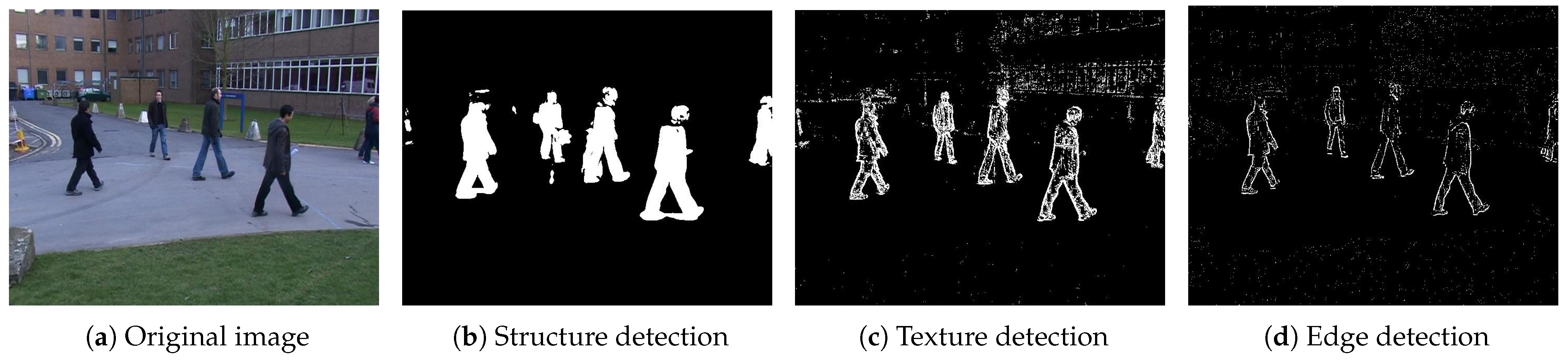
3.3. Texture Level Maps
Generally, a background model represents a stationary or near-stationary scene with structured elements in an uniform area. Where the light changes of a sequence of images are mainly characterized and quantified, each region of presents a variation of intensity in the pixel values ().
So, it is assumed that when a moving object () passes through the scene (), it will cause that scene structure to change.
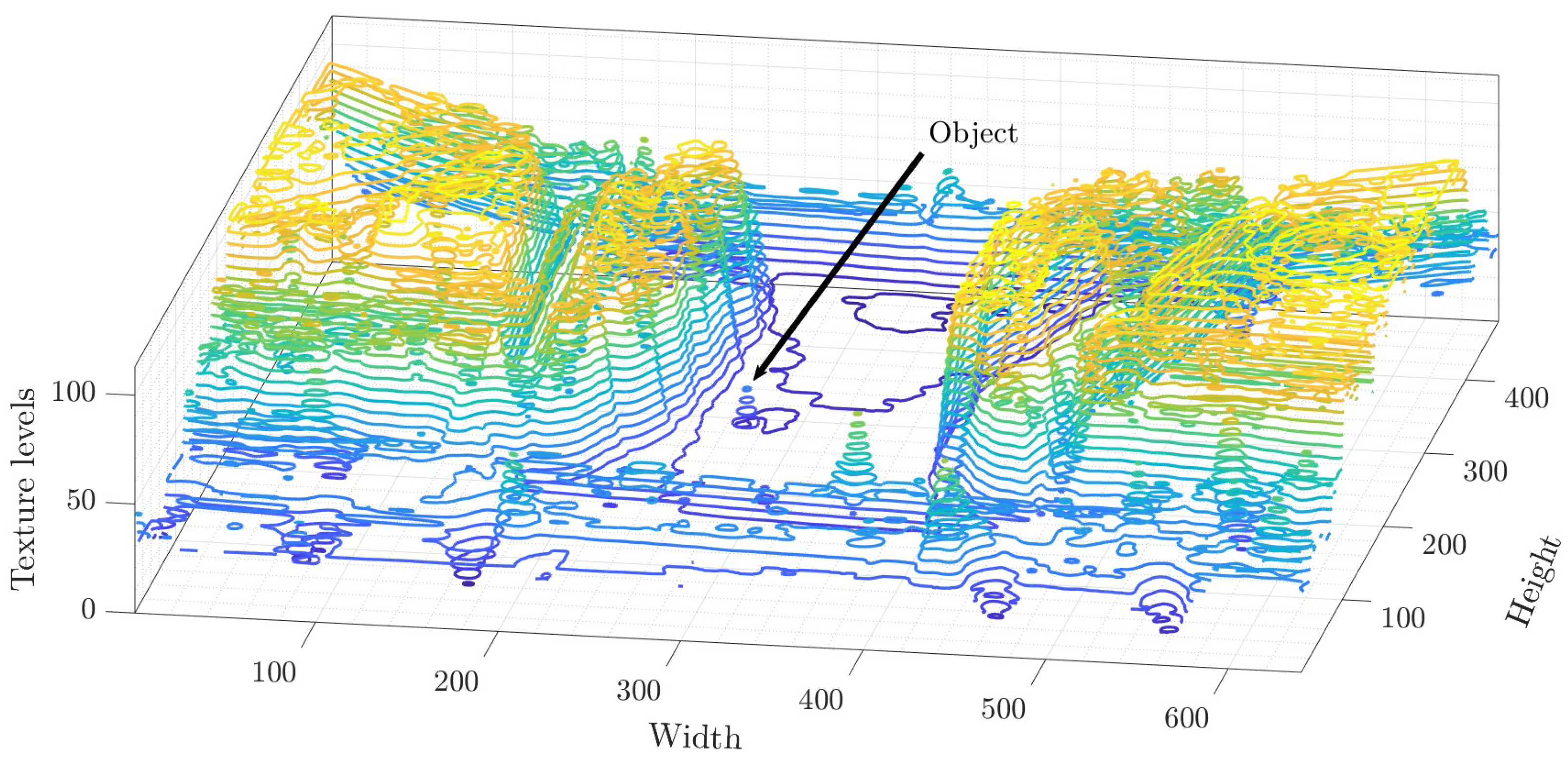
In
Figure 4, a scene is observed in which an object of interest
can be seen with an intensity value similar to its surrounding environment. This fact is a problem because it is difficult to distinguish between objects and scenes.
Figure 3.
Gabor filter size–frequency ratio. This figure shows the comparison between the size of the envelope function (the Gaussian distribution in red) and the response of (the blue distribution) relative to the size of the image.
Figure 3.
Gabor filter size–frequency ratio. This figure shows the comparison between the size of the envelope function (the Gaussian distribution in red) and the response of (the blue distribution) relative to the size of the image.
Although the intensity levels are similar, we can see that the areas on the scene are not entirely uniform. When another object occludes the scene structure, the structure is altered. Therefore, the distribution and direction of the texture are different. Structural changes are detected using Equations (
6) and (
7), which allow us to characterize the main frequencies of these regions and represent the structure of the perceived texture. The relative frequency of the Gabor filter’s three–dimensional projection corresponds to the scene’s change.
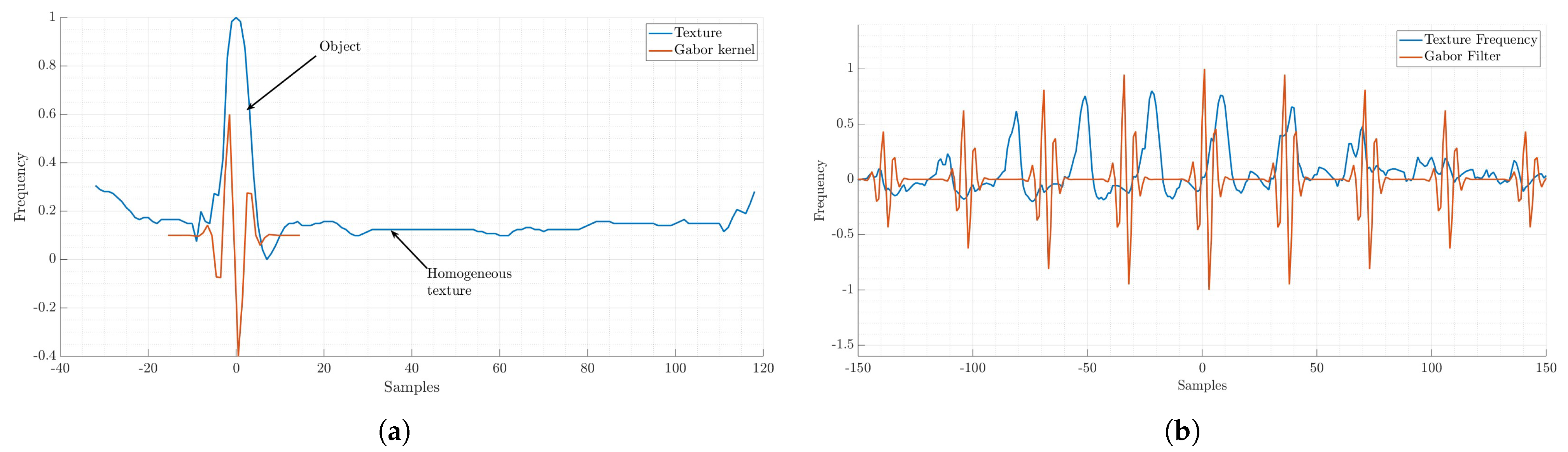
Figure 5 shows the texture detected by the filter (red segment) and the not detected texture (blue segments).
The frequency of the uniform and non–uniform region and the frequency of the Gabor kernel are shown in
Figure 6. The maximum values, both positive and negative, represent sampling points. And they measure the texture deformation in the object’s structure; this effect is shown in
Figure 6a. Meanwhile,
Figure 6b shows when the structure is periodical, and the frequency is similar to the Gabor filter. These structures will not be recognized because the detected changes are not so significant that the filter will attenuate them.
When the Gabor filter is applied, a representation is obtained in the frequency and orientation domain, allowing the identification and characterization of different levels and patterns of texture. The extracted features are essentially a decomposition of the image into components that highlight the texture levels, providing a detailed description of the textures in different scales and orientations. The texture level map obtained is represented in
Figure 7, where a subtle change of
with respect to
is appreciated.
3.4. Texture Level Quantification
To obtain a more uniform area, the r-th moment is calculated. In this way, the texture level is quantified according to the statistical model. In Equation (
9), the second statistical moment is used because the average value provides a smooth area:
where
represents the quantized texture,
,
is the average of the
n distributions of the
and
texture map, and
X is the latest distribution of the texture map.
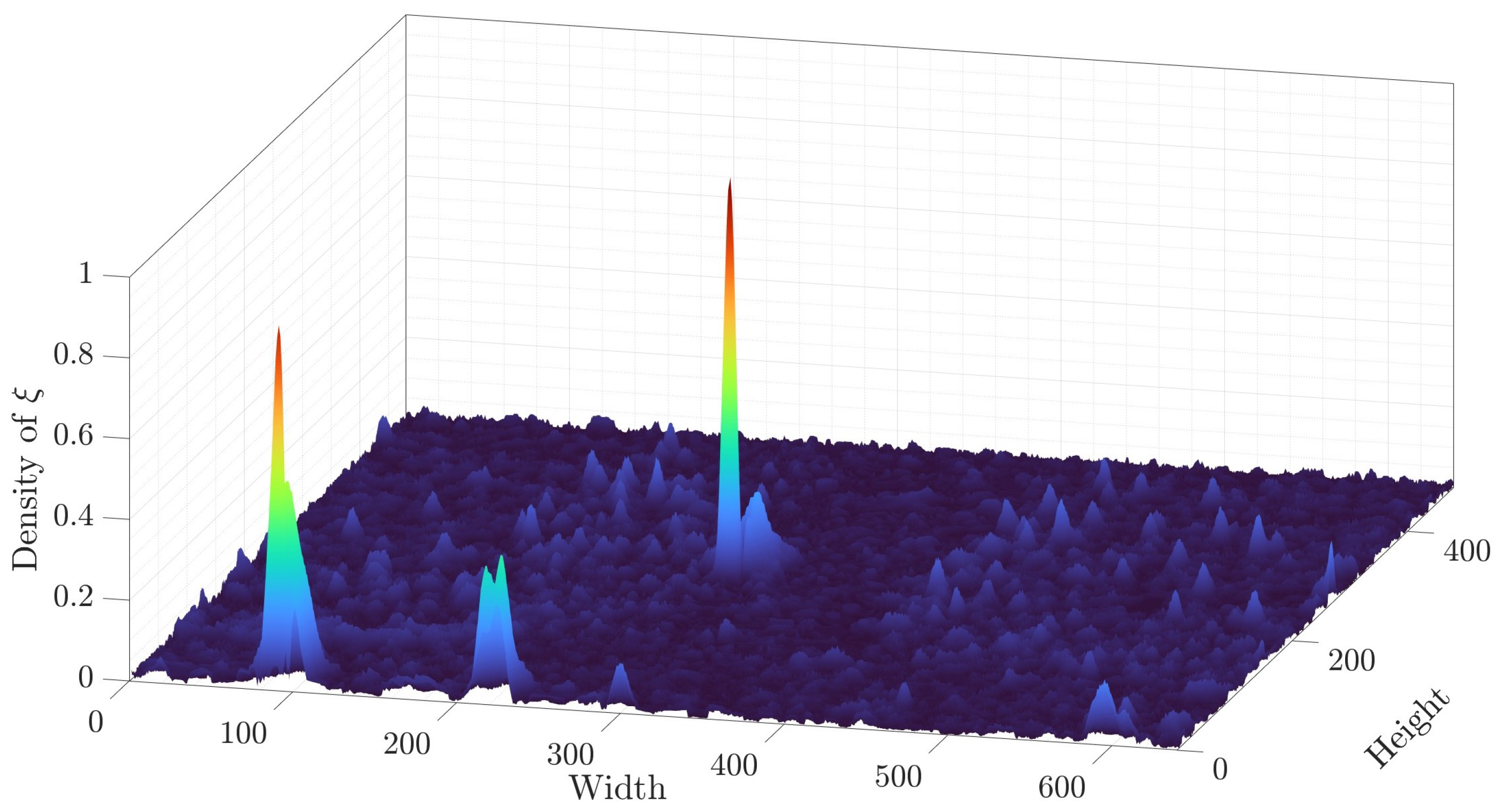
The resulting surface is shown in
Figure 8, which reflects the distribution of moments in the scene. While the scene distribution appears almost homogeneous, the object distribution shows a greater dispersion in its surroundings, so it is now possible to compare the data variability. According to these distributions, the movement can be detectable.
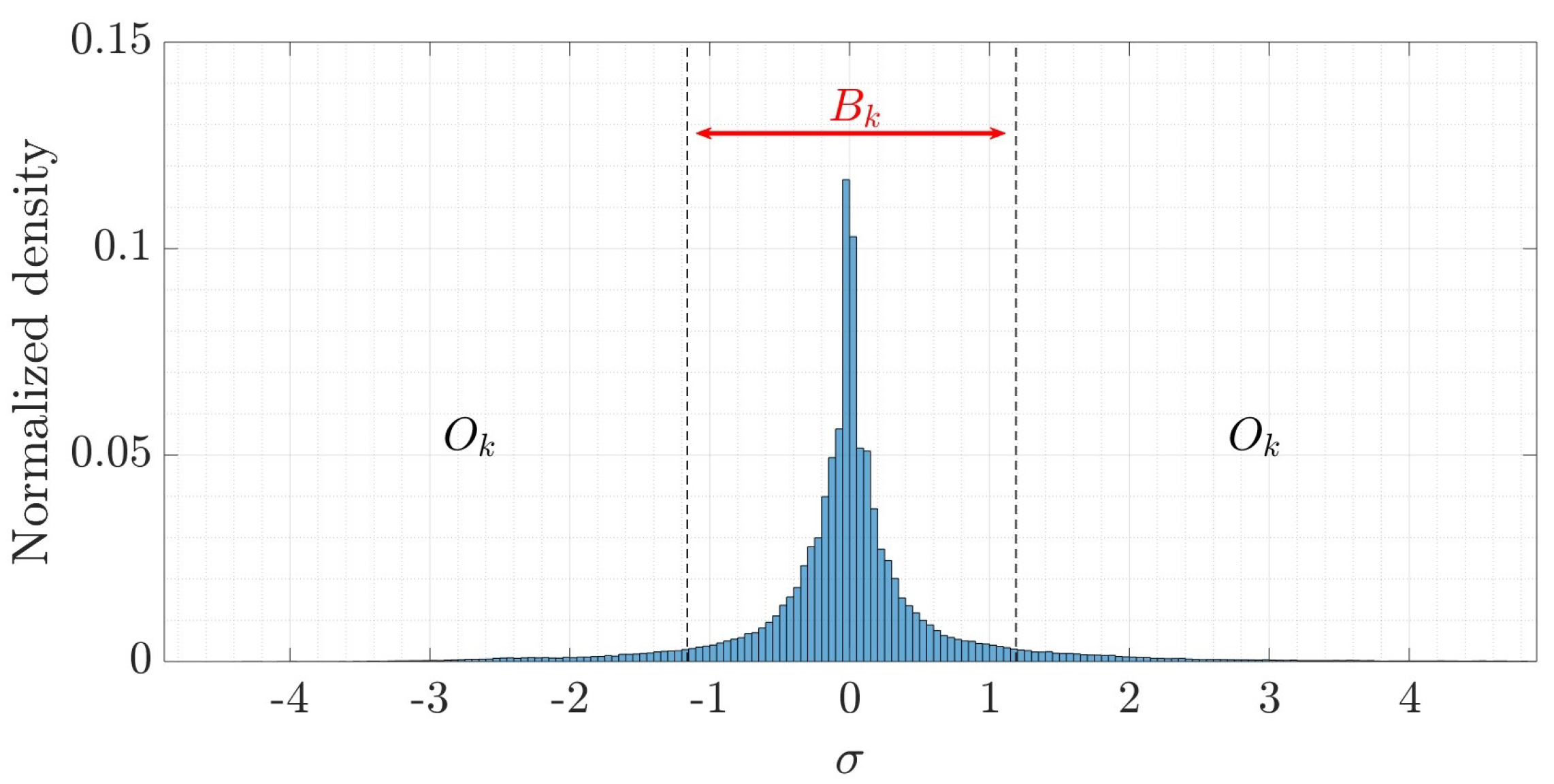
3.5. Segmentation Criteria
Finally, a threshold is chosen to distinguish between stationary
and non–stationary objects
because the scene now exhibits the distribution shown in
Figure 9.
The objects that are in motion can be located from . In this sense, represents the threshold of stationary objects, which is between , and moving objects can be determined between . Therefore, is a function of the confidence interval of the texture distribution we want to compare.
The steps of the background subtraction algorithm are summarized in Algorithm 1. It should be noted that the analysis is based on the texture of the object, the real term of the filter is used to obtain the object’s structure, and the filter’s imaginary term explains the texture in detail. If there are subtle changes, they can be modeled with any Gabor filter frequency.
| Algorithm 1: Texture analysis algorithm |
![Algorithms 17 00133 i053]() |
4. Results
This section presents the experimental results of the proposed method. The first experiments consist of adjusting the filter parameters to characterize the light changes in the texture, that is, the number of details in the image that will be used for object analysis, so it is important to adjust the frequency value because an excess of texture may not be as relevant when performing the analysis.
Figure 10 shows the results of the level texture analysis of the scene
, where both the object and the background distributions are similar. The parameters or this scene are
and
,
and 24 orientations with an angular displacement of 15.
The result below corresponds to scene
. Different values for
are used to enhance the texture of people (
Figure 11b), to enhance the texture of the floor (
Figure 11c), and to enhance the edges of buildings (
Figure 11d). The influence of these
values can be seen in
Figure 11. The parameters that characterize this scene are as follows: Gaussian function value
and
, while
. In addition, 24 orientations with an angular displacement of 15 degrees are used.
We try to focus on the object’s structure, the texture of the object’s clothes, and the object’s edge. The results are shown in
Figure 12.
The parameter values of the Gaussian function used are , , and . Focusing on analyzing different scene levels can reduce the amount of data and only focus on the specific object information. According to the displayed results, adjusting the value allows the filter to attenuate light changes so that the texture of objects on different levels can be specified to segment them.
We analyze sequences of 900 images for each activity, and the results from our proposal are compared with other methods, such as
[
22], DMD [
39], MRFMD [
23], DSTEI [
26], Eigen-Background [
30], SOBS [
33], SWCD [
40], ViBe [
47], GMM [
51] and DEU [
67]. The results analysis can be seen in
Table 2.
According to the results, in , the proposed method helps to reduce the effects produced by shadows while preserving most of the structure, but a value of causes the filter to be susceptible to noise, and objects that are not in motion can be seen. In , the vehicle structure is preserved, but the disadvantage is that the light changes of the leaves are detected as a movement. In scenario , unlike the other methods, our proposal can obtain a large part of the object structure without noise or deformations. Finally, in , there is an acquisition error because the speed of movement of the cyclist is greater than the speed of acquisition of the images, so the cyclist is not clearly seen. Nevertheless, we obtained good results because the complete structure of the cyclist can be appreciated regardless of the shadow and noise; classic noise reduction methods can minimize noise reduction and residual. The morphological closing method can be applied to obtain a complete object structure if necessary.
The parameters used in each model are shown in
Table 3, which were reported by each author so that each model maintains the best performance of its algorithm.
In addition to the qualitative tests performed, we conducted quantitative tests on 3600 images, corresponding to a sequence of 900 images from each scene, to estimate the rates of true positives and false positives. Although there are different ways to evaluate performance, the evaluation here is performed at the pixel level. In addition to measurement accuracy and sensitivity, the indicators described below are also used to evaluate and verify data. According to [
68], these are defined as follows.
Sensitivity (also known as True Positive Rate or Recall): This metric measures the proportion of actual positives that are correctly identified as such. It is calculated as:
Specificity: It measures the proportion of actual negatives that are correctly identified. It is calculated as:
False Positive Rate (FPR): This is the proportion of actual negatives that are incorrectly identified as positives. It is calculated as:
False Negative Rate (FNR): This metric measures the proportion of actual positives that are incorrectly identified as negatives. It is calculated as:
PWC (Percentage of Wrong Classifications): It represents the percentage of all classifications that were incorrect. It is calculated as:
Precision (also known as Positive Predictive Value): This metric measures the proportion of identified positives that are actually correct. It is calculated as:
F Measure (or F1 Score): This is the harmonic mean of Precision and Sensitivity. It provides a single score that balances the trade-off between Precision and Recall. It is calculated as:
True positive
refers to pixels correctly identified as part of the moving object. True negative
denotes pixels correctly identified as part of the static background. False positive
pertains to pixels incorrectly labeled as part of the moving object when they belong to the background, while false negative
refers to pixels incorrectly labeled as background when they are truly part of the moving object.
Table 4 and
Table 5 compare existing methods and GABSM.
Table 4 shows the results achieved by our method, which achieves a sensitivity of
. This reflects its efficiency in correctly identifying relevant foreground elements. On the other hand, a specificity of
shows the ability to exclude noise generated by reflections. With a misclassification rate of
, it demonstrates a low error rate in classifying textures, even when they are complex or appear homogeneous with the environment, under variable lighting conditions. These fluctuations in lighting can significantly alter how textures are perceived, representing a challenge for their classification and analysis. Nevertheless, an
score of
evidences that our method is capable not only of recognizing complex texture patterns but also of adapting to the variability caused by changes in lighting.
In
Table 5, a sensitivity of
is obtained, reflecting our method’s ability to correctly detect objects of interest. Its specificity of
and an FPR of
demonstrate its efficacy in discarding irrelevant elements, even in a dynamic environment due to the movement of leaves. According to the
score of
, our method proves to be effective in facing the complexity of environments influenced by shadows and dynamic movements, such as those generated by moving tree leaves. Additionally, this environment introduces changes in perspective, where the distinction between distant and nearby objects complicates the detection of moving objects due to a fixed Gabor core.
In
Table 6, a sensitivity of
and a high specificity of
are observed, along with a relatively low FNR of
and an FPR of
. These parameters demonstrate that the GABSM method can adapt to scenarios where moving objects may stop unexpectedly, presenting a problem for traditional background modeling methods. With an accuracy of
and an F1 score of
, GABSM proves its reliability in adapting to such scenarios.
Table 7 presents the results obtained in a scenario characterized by acquisition errors and the presence of shadows on moving objects. With a sensitivity of
, our method can detect foreground moving objects, even in conditions where sampling is not adequate. A specificity of
shows its efficiency in differentiating between objects of interest and the background, thus minimizing misdetections caused both by shadows and acquisition errors.
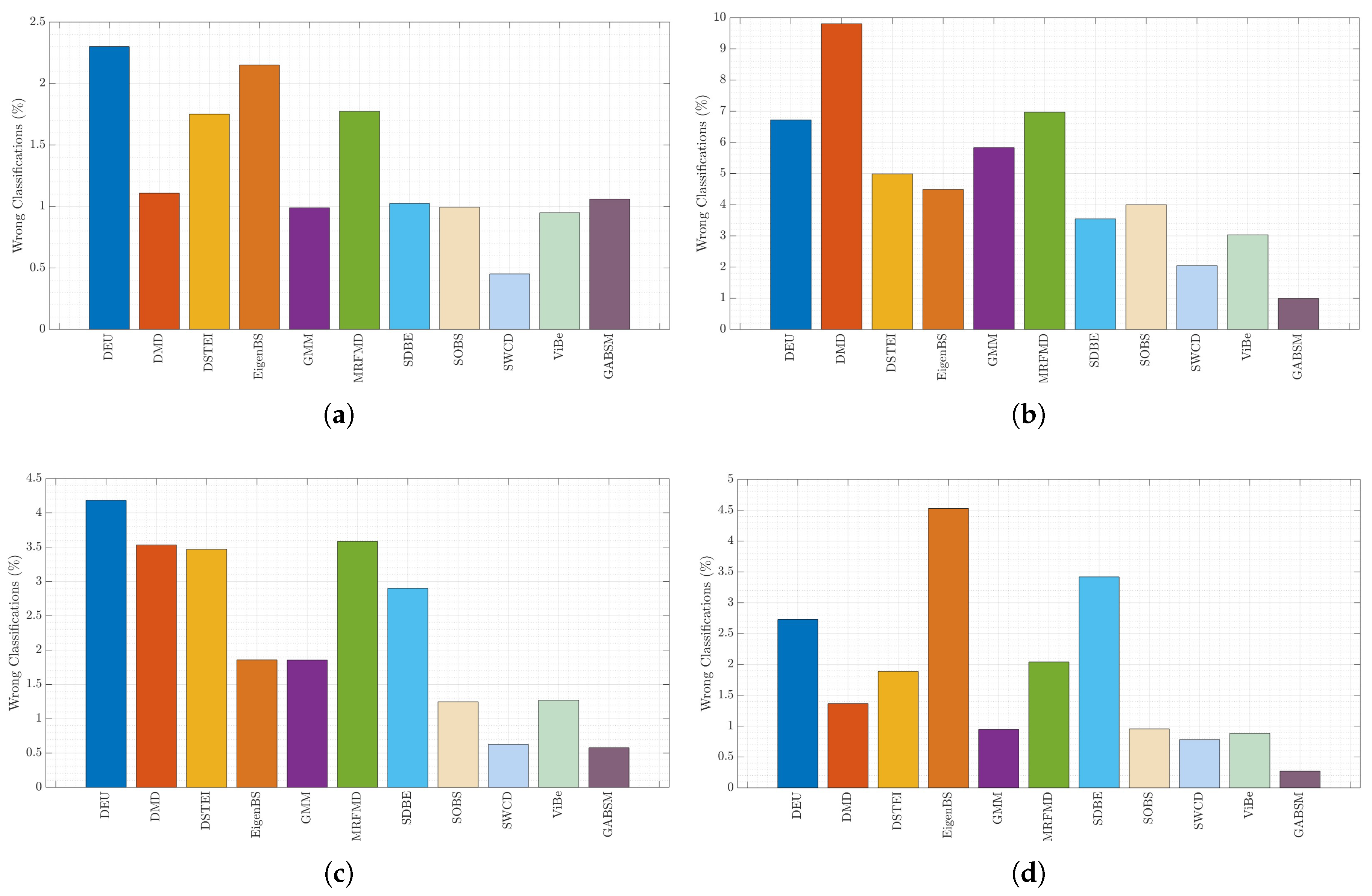
Figure 13 shows the percentage of wrong classifications
, which shows the deviation error in the scene. This error is caused by the number of false positives
and false negatives
described.
Figure 13a shows that the proposed method has an error percentage similar to most methods (about
) due to the change in the object’s perspective. This problem is the main weakness of the Gabor filter because it requires functions
of different sizes and frequencies. This increases the complexity of parameter selection and the processing time. This same problem is shown in
Figure 13b. However, in
Figure 13c,d, we can see that the percentage of error is lower; this is because the objects in
and
scenes do not have perspective with respect to the camera. For this reason, the size of the
function is fixed so that the texture can be better modeled. The problem in these scenarios is that they have lower resolution, which means that
and
have to be reduced, as well as, therefore, the lambda value. This effect increases the amount of noise detected and therefore impacts the amount of true positives detected.
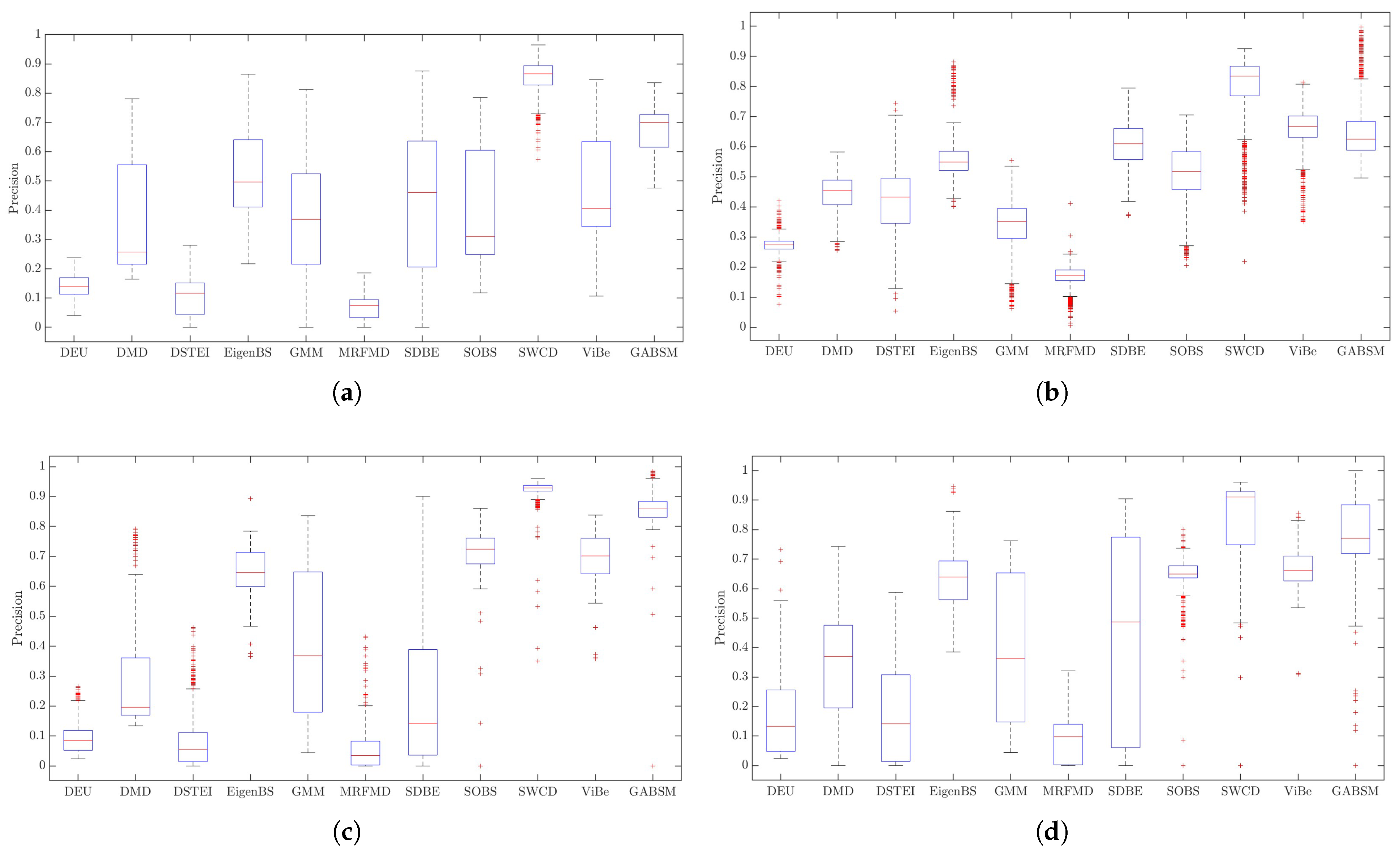
Figure 14 shows the precision of the methods, which helps us to visualize which method provides us with more information about moving objects and minimizes irrelevant information caused by noise, the presence of shadows, or changes in lighting. Although our method has good precision regarding positive predictions, its performance is reduced when the images are smaller or difficult to characterize lighting changes.
5. Discussion
According to the results obtained in
Table 2, only methods such as DEU, DSTEI, and RFMD obtained the objects’ contour. The methods DMD, GMM, Sigma-Delta, and SWCD, although they partially preserve the structure of the objects, present loss of information in distant objects and are susceptible to shadows and reflections caused by lighting.From our point of view, the Eigen-Background, SOBS, ViBe, and our GMBSM method provide better results in preserving the object structure, but they cause the loss of information about distant objects. Among them, GMBSM is the best, and the results in
Figure 13 and
Figure 14 show a lower error percentage and higher accuracy. Nevertheless, distant objects in scenes
and
will lose information due to the perspective of these scenes.
As mentioned in
Section 3.2, a larger object in the image requires a higher density Gaussian so that the noise attenuation is greater. Although the object is smaller, it requires a lower frequency response and Gaussian density, producing more noise and possible false contours. This effect is one of the weaknesses of our method because it requires different G functions to be applied to the scene. This will increase the execution time and the complexity of adjusting the parameters.
The advantages of our method are that (i) the representation of an object whose texture is almost the same as its environment, (ii) it can recover quickly when the object in motion remains stationary, (iii) according to experiments, it exhibits invariance to light changes, and (iv) it allows the analysis of texture levels to obtain different texture details.
However, it also has disadvantages: (i) the proper selection of the size of depends on the size of the objects in the scene, (ii) experience is required to select the appropriate filter parameters and finally, and (iii) the suggested threshold is not the best method because it depends on the variance of the data, and in the absence of objects, it will only produce noise. These issues are being considered for future work, as well as improvements to the method.
6. Conclusions
We introduced a background subtraction technique that leverages texture-level analysis through the integration of a Gabor filter bank and statistical moments. This approach is differentiated by its capacity to distinguish between foreground and background entities in dynamic scenes, a critical challenge where traditional methods often need to improve. Our method has demonstrated superior performance in maintaining the structural integrity of the objects while effectively addressing gradual changes in lighting, shadows, and scenarios with nearly uniform environmental textures. Our experimental validation exhibited benefits over conventional methods by ensuring lower false detection rates and maintaining high accuracy in object detection across a variety of challenging conditions.
Despite its performance, our method encounters limitations when processing images of reduced size or in scenarios with complex lighting variations. The difficulty in characterizing such changes impacts the algorithm’s performance, suggesting a need for improved strategies in handling small objects or subtle texture variations. Additionally, the reliance on specific Gabor filter parameters and the selection of an optimal threshold for background subtraction present complexities in parameter optimization, potentially restricting the method’s adaptability and ease of implementation across diverse surveillance contexts.
Looking forward, we aim to address these limitations by exploring adaptive parameterization techniques that can dynamically adjust the Gabor filter settings based on the scene’s characteristics. This could enhance the method’s robustness against varied image sizes and complex lighting conditions. Further, we plan to investigate deep learning frameworks that could learn these parameters autonomously, offering a more sophisticated understanding of the scene dynamics. Additionally, integrating multimodal data sources, such as depth information, could enrich the algorithm’s contextual awareness, opening opportunities for more subtle object detection and background modeling. Through these advancements, we aspire to broaden the applicability of our method, making it a more versatile tool for real-time surveillance and motion tracking in an array of real-world settings.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















































