

Optimizing Speech Emotion Recognition with Deep Learning and Grey Wolf Optimization: A Multi-Dataset Approach

Abstract
:1. Introduction
- The intricate nature of human emotions poses a challenge to developing accurate SER systems as emotions are complex and expressed in various ways. For instance, happiness may be conveyed through laughter, smiling, and a high-pitched voice, but also through tears, a frown, and a low-pitched voice.
- The variability in human speech further complicates SER systems, as individuals speak differently based on factors like age, gender, and accent. For example, a young woman from the United States may have a different speaking style than an older man from the United Kingdom.
2. Related Work
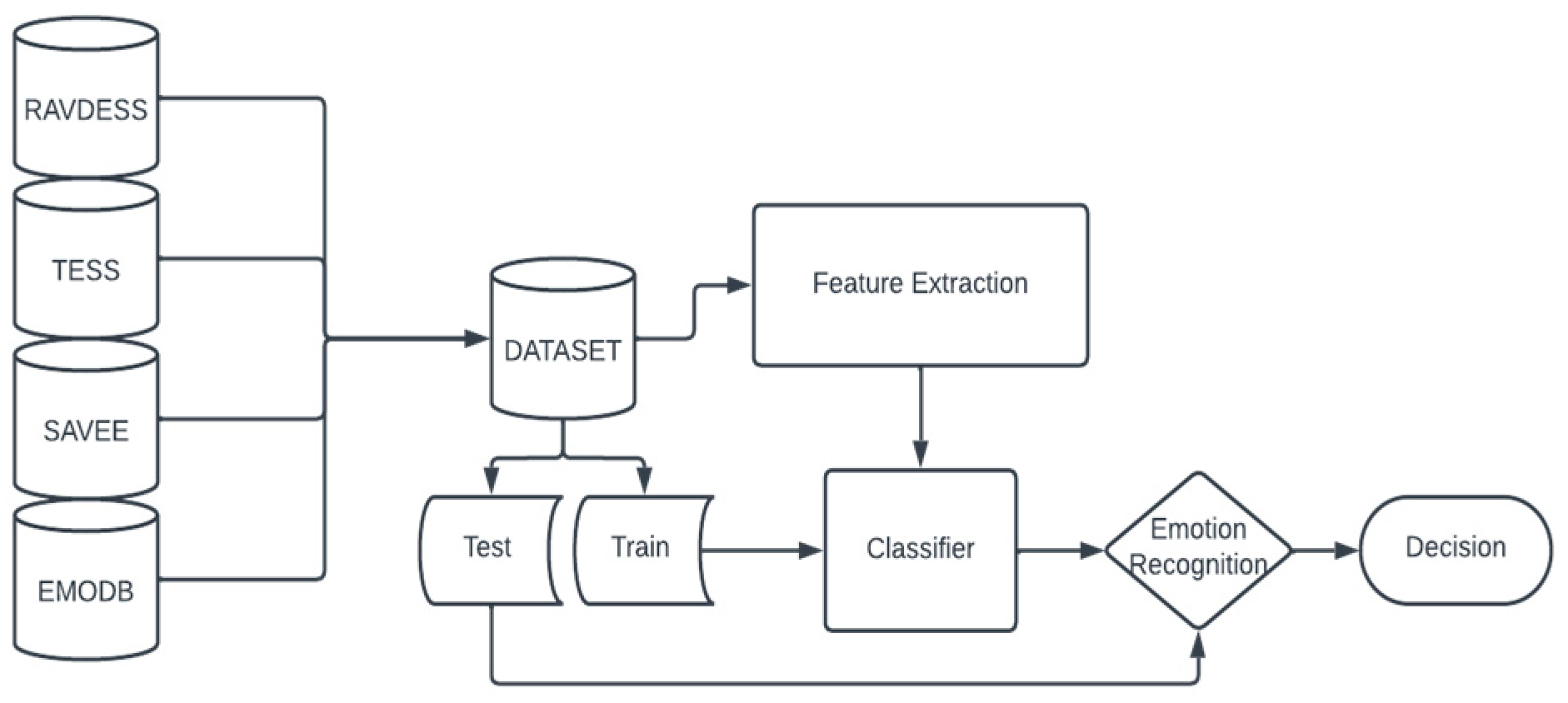
3. Dataset
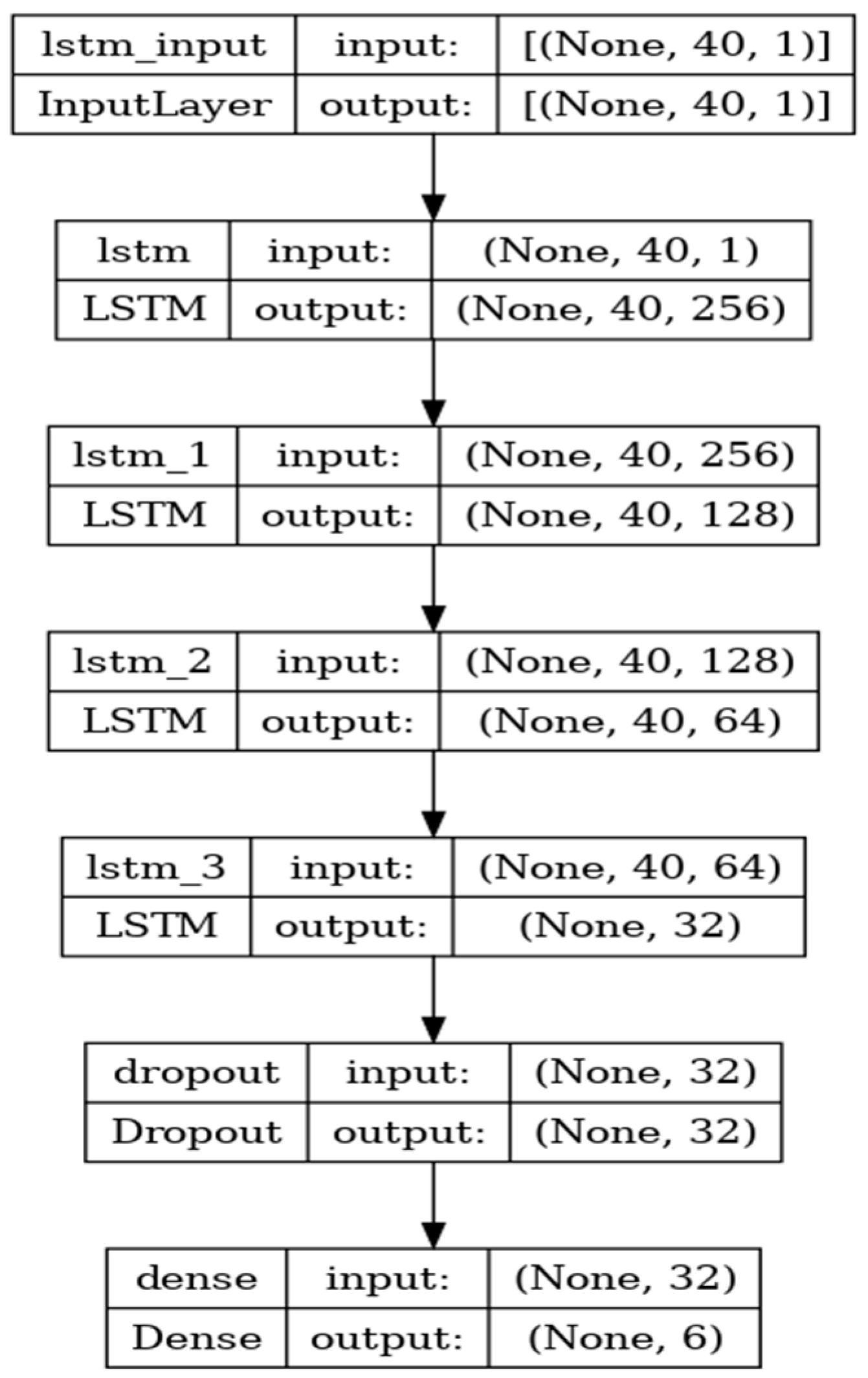
4. Experimental Setup
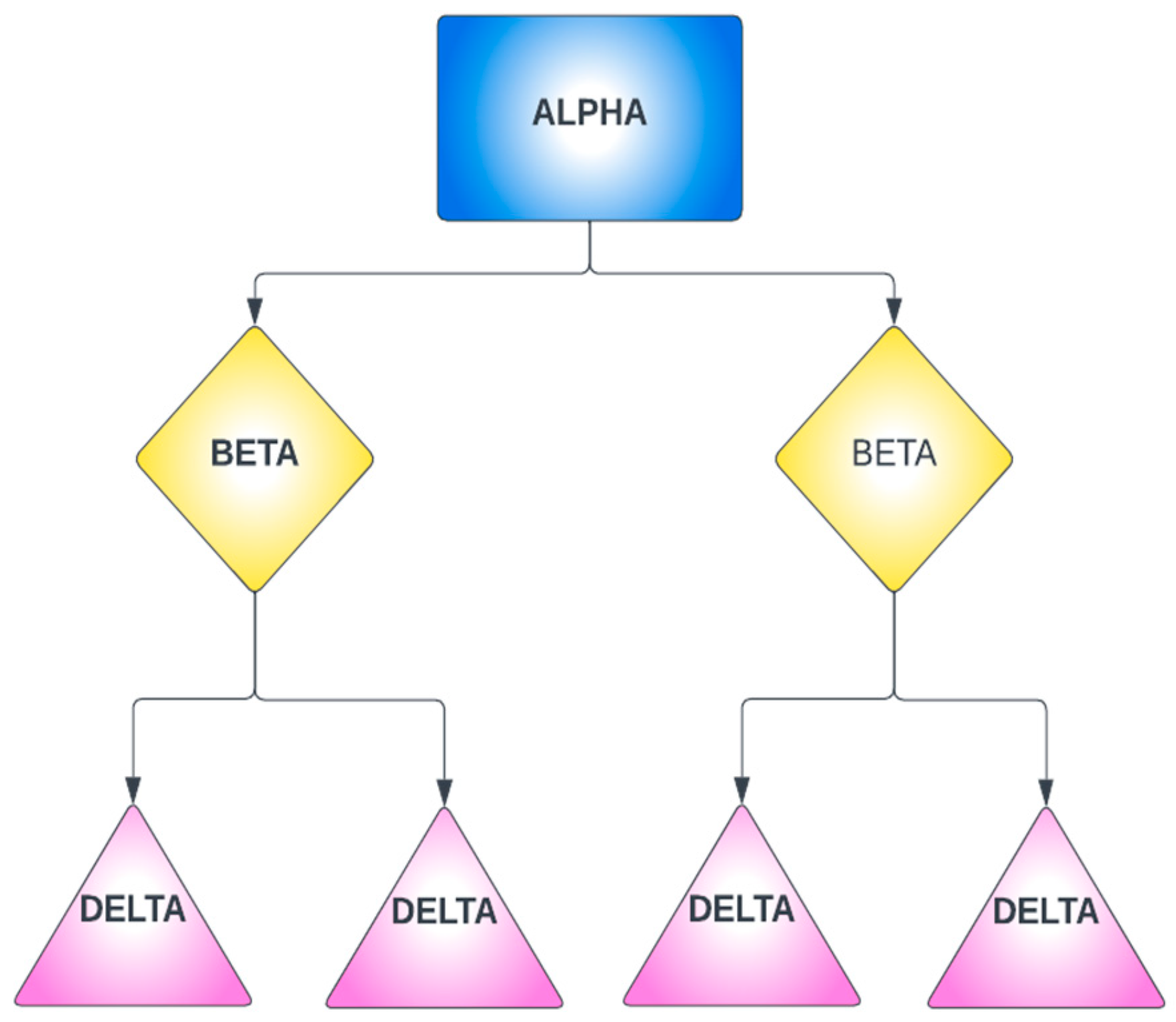
4.1. Social Hierarchy
4.2. Hunting Strategy
4.3. Prey Search (Exploration)
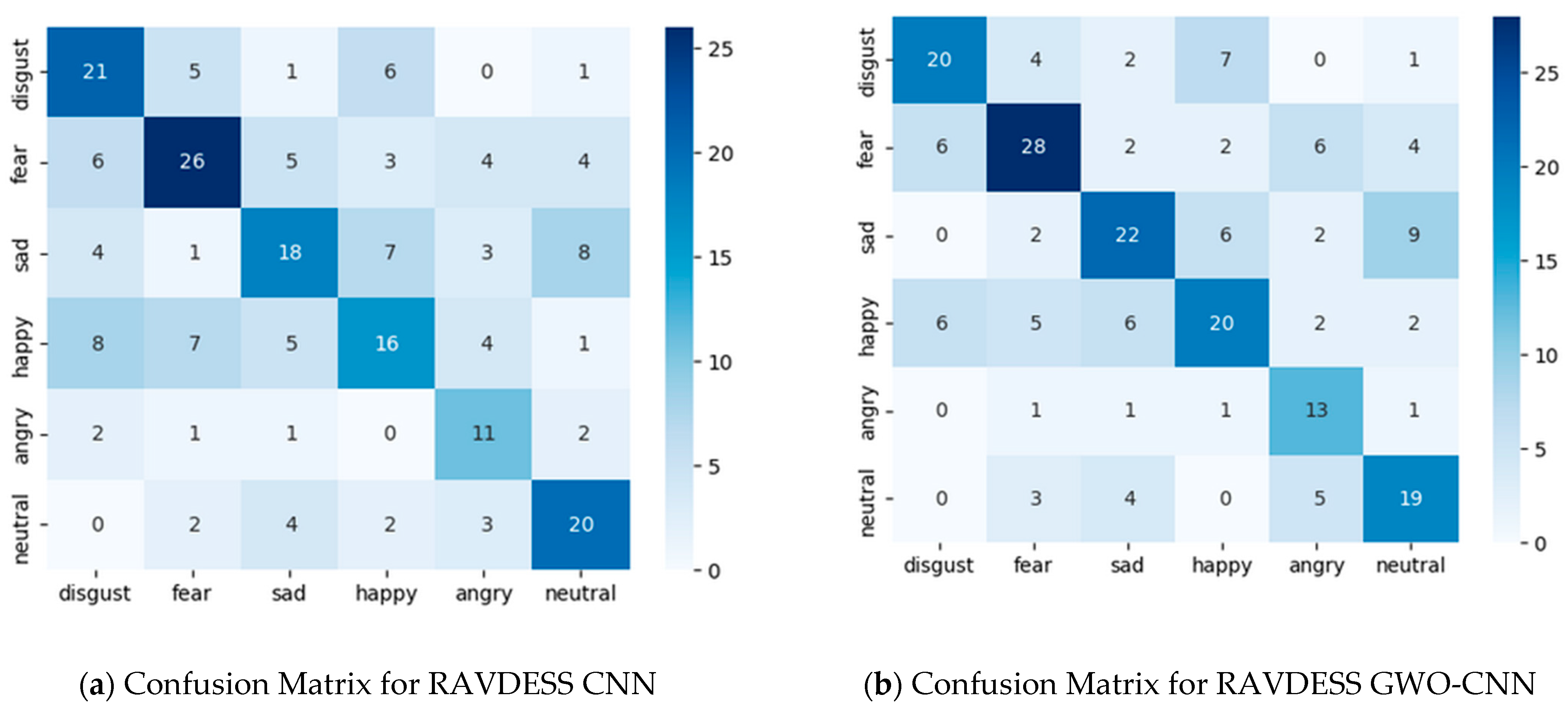
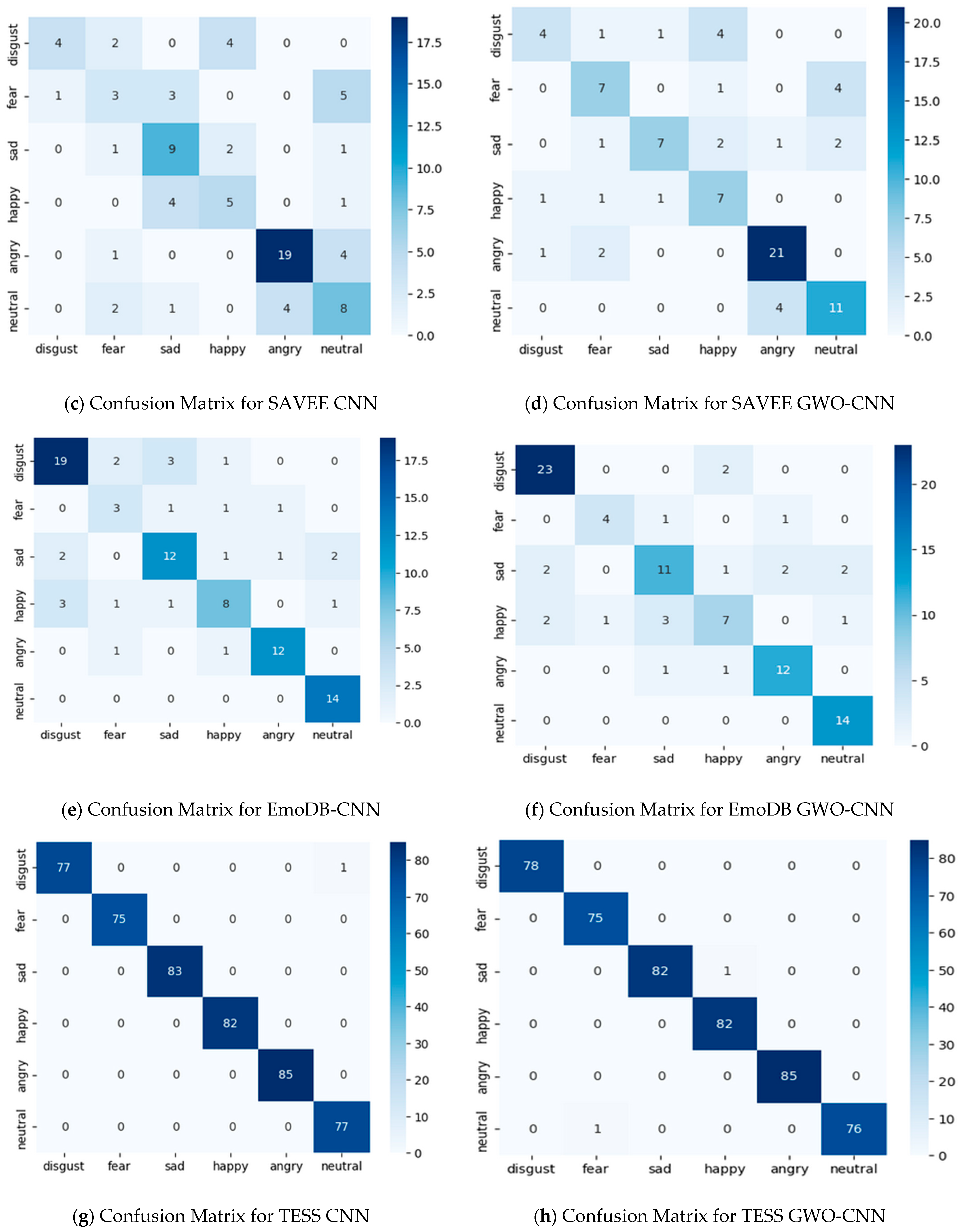
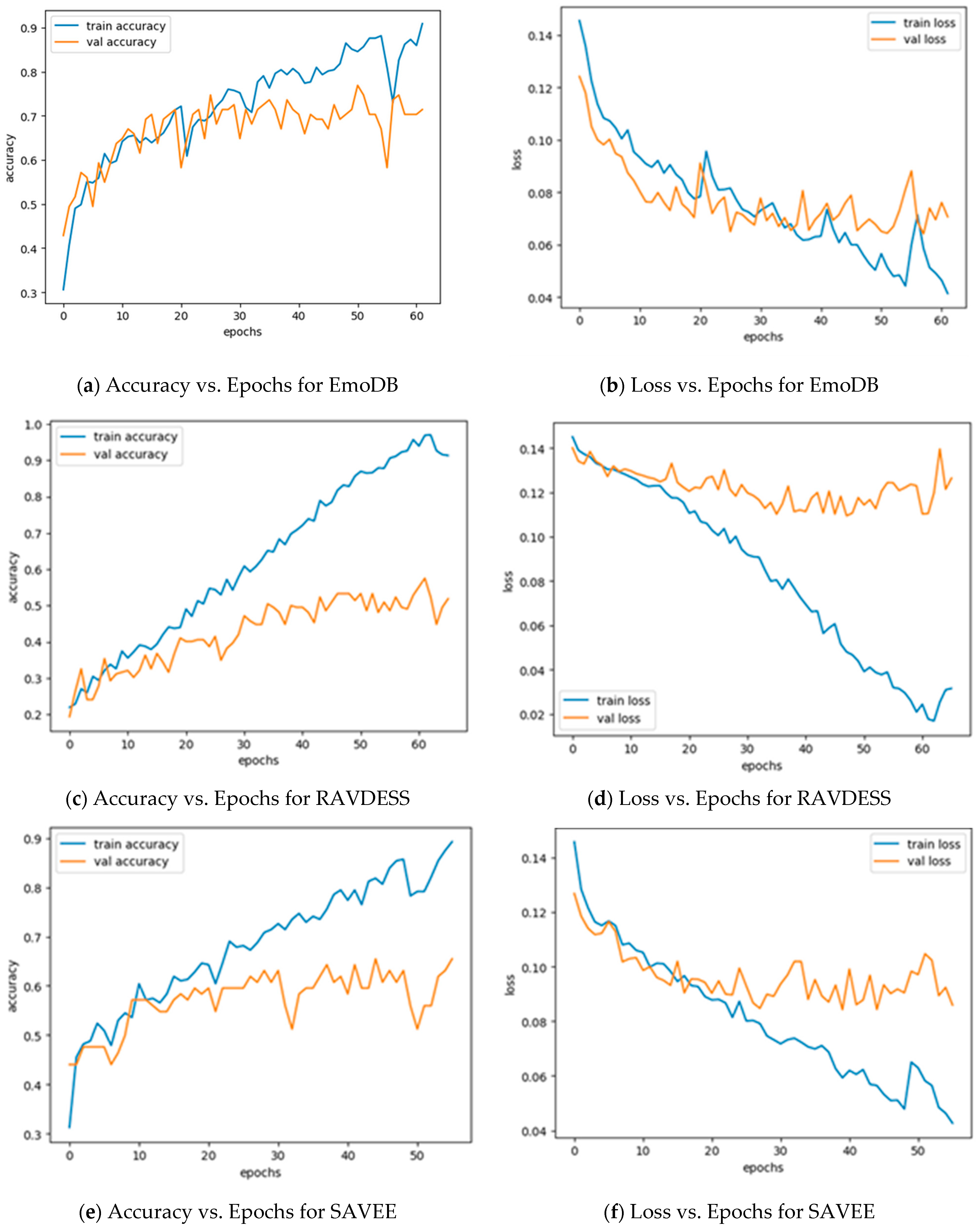
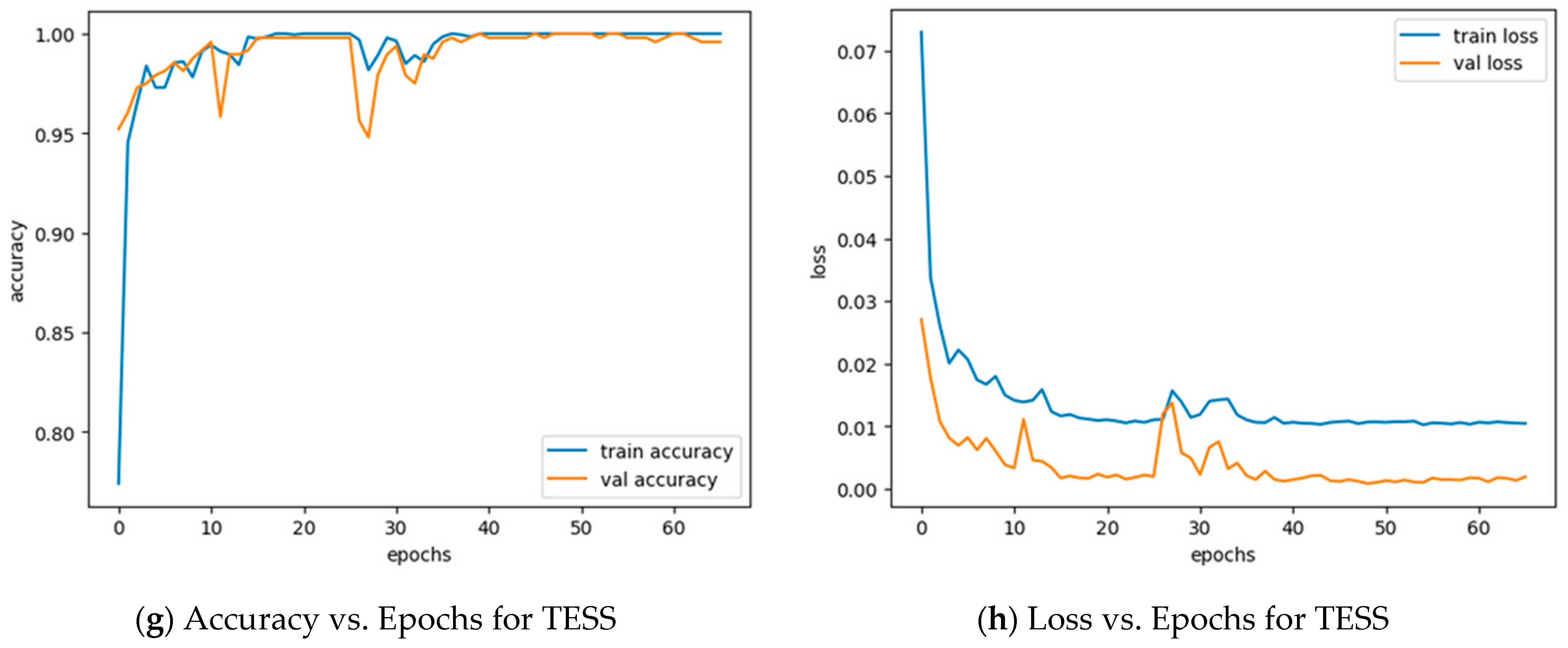
5. Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Banse, R.; Scherer, K.R. Acoustic profiles in vocal emotion expression. J. Personal. Soc. Psychol. 1996, 70, 614–634. [Google Scholar] [CrossRef]
- Mustafa, M.B.; Yusoof, A.M.; Don, Z.M.; Malekzadeh, M. Speech emotion recognition research: An analysis of research focus. Int. J. Speech Technol. 2018, 21, 137–156. [Google Scholar] [CrossRef]
- Schuller, B.; Rigoll, G.; Lang, M. Hidden markov model-based speech emotion recognition. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Hong Kong, China, 6–10 April 2003; Volume 2, p. II-1. [Google Scholar]
- Hu, H.; Xu, M.-X.; Wu, W. GMM supervector based SVM with spectral features for speech emotion recognition. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. IV-413–IV-416. [Google Scholar]
- Lee, C.; Mower, E.; Busso, C.; Lee, S.; Narayanan, S. Emotion recognition using a hierarchical binary decision tree approach. Speech Commun. 2009, 4, 320–323. [Google Scholar]
- Kim, Y.; Mower, E. Provost, Emotion classification via utterance level dynamics: A pattern-based approach to characterizing affective expressions. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Eyben, F.; Wollmer, M.; Schuller, B. Openear—Introducing the munich open-source emotion and affect recognition toolkit. In Proceedings of the 2009 3rd International Conference on Affective Computing and Intelligent Interaction (ACII), Amsterdam, The Netherlands, 10–12 September 2009; pp. 1–6. [Google Scholar]
- Mower, E.; Mataric, M.J.; Narayanan, S. A framework for automatic human emotion classification using emotion profiles. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 1057–1070. [Google Scholar] [CrossRef]
- Han, K.; Yu, D.; Tashev, I. Speech emotion recognition using deep neural network and extreme learning machine. In Proceedings of the INTERSPEECH 2014, Singapore, 7–10 September 2014; pp. 223–227. [Google Scholar]
- Jin, Q.; Li, C.; Chen, S.; Wu, H. Speech emotion recognition with acoustic and lexical features. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 4749–4753. [Google Scholar]
- Lee, J.; Tashev, I. High-level feature representation using recurrent neural network for speech emotion recognition. In Proceedings of the INTERSPEECH 2015, Dresden, Germany, 6–10 September 2015; pp. 223–227. [Google Scholar]
- Neumann, M.; Vu, N.T. Attentive convolutional neural network based speech emotion recognition: A study on the impact of input features, signal length, and acted speech. In Proceedings of the INTERSPEECH 2017, Stockholm, Sweden, 20–24 August 2017; pp. 1263–1267. [Google Scholar]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Zafeiriou, S.; Schuller, B. Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar]
- Lim, W.; Jang, D.; Lee, T. Speech emotion recognition using convolutional and recurrent neural networks. In Proceedings of the 2016 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Jeju, Republic of Korea, 13–16 December 2016; pp. 1–4. [Google Scholar]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2227–2231. [Google Scholar]
- Satt, A.; Rozenberg, S.; Hoory, R. Efficient emotion recognition from speech using deep learning on spectrograms. In Proceedings of the INTERSPEECH 2017, Stockholm, Sweden, 20–24 August 2017; pp. 1089–1093. [Google Scholar]
- Ma, X.; Wu, Z.; Jia, J.; Xu, M.; Meng, H.; Cai, L. Emotion recognition from variable-length speech segments using deep learning on spectrograms. In Proceedings of the INTERSPEECH 2018, Hyderabad, India, 2–6 September 2018; pp. 3683–3687. [Google Scholar]
- Yenigalla, P.; Kumar, A.; Tripathi, S.; Singh, C.; Kar, S.; Vepa, P. Speech emotion recognition using spectrogram phoneme embedding. In Proceedings of the INTERSPEECH 2018, Hyderabad, India, 2–6 September 2018; pp. 3688–3692. [Google Scholar]
- Guo, L.; Wang, L.; Dang, J.; Zhang, L.; Guan, H. A feature fusion method based on extreme learning machine for speech emotion recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2666–2670. [Google Scholar]
- Dai, W.; Dai, C.; Qu, S.; Li, J.; Das, S. Very deep convolutional neural networks for raw waveforms. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 421–425. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the INTERSPEECH 2005, Libon, Portugal, 4–8 September 2005; pp. 1517–1520. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.-C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Shao, S.; Saleem, A.; Salim, H.; Pratik, S.; Sonia, S.; Abdessamad, M. AI-based Arabic Language and Speech Tutor. In Proceedings of the 2022 IEEE/ACS 19th International Conference on Computer Systems and Applications (AICCSA), Abu Dhabi, United Arab Emirates, 5–8 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar]
- Wang, J.; Xue, M.; Culhane, R.; Diao, E.; Ding, J.; Tarokh, V. Speech emotion recognition with dual-sequence LSTM architecture. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6474–6478. [Google Scholar]
- Chernykh, V.; Sterling, G.; Prihodko, P. Emotion recognition from speech with recurrent neural networks. arXiv 2017, arXiv:1701.08071. [Google Scholar]
- Sathiyabhama, B.; Kumar, S.U.; Jayanthi, J.; Sathiya, T.; Ilavarasi, A.K.; Yuvarajan, V.; Gopikrishna, K. A novel feature selection framework based on grey wolf optimizer for mammogram image analysis. Neural Comput. Appl. 2021, 33, 14583–14602. [Google Scholar] [CrossRef]
- Sreedharan, N.P.N.; Ganesan, B.; Raveendran, R.; Sarala, P.; Dennis, B.; Boothalingam, R.R. Grey wolf optimisation-based feature selection and classification for facial emotion recognition. IET Biom. 2018, 7, 490–499. [Google Scholar] [CrossRef]
- Dey, A.; Chattopadhyay, S.; Singh, P.K.; Ahmadian, A.; Ferrara, M.; Sarkar, R. A hybrid meta-heuristic feature selection method using golden ratio and equilibrium optimization algorithms for speech emotion recognition. IEEE Access 2020, 8, 200953–200970. [Google Scholar] [CrossRef]
- Shetty, S.; Hegde, S. Automatic classification of carnatic music instruments using MFCC and LPC. In Data Management, Analytics and Innovation; Springer: Berlin/Heidelberg, Germany, 2020; pp. 463–474. [Google Scholar]
- Saldanha, J.C.; Suvarna, M. Perceptual linear prediction feature as an indicator of dysphonia. In Advances in Control Instrumentation Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 51–64. [Google Scholar]
- Mannepalli, K.; Sastry, P.N.; Suman, M. Emotion recognition in speech signals using optimization based multi-SVNN classifier. J. King Saud Univ.-Comput. Inf. Sci. 2018, 34, 384–397. [Google Scholar] [CrossRef]
- Yildirim, S.; Kaya, Y.; Kılıç, F. A modified feature selection method based on metaheuristic algorithms for speech emotion recognition. Appl. Acoust. 2021, 173, 107721. [Google Scholar] [CrossRef]
- Kerkeni, L.; Serrestou, Y.; Mbarki, M.; Raoof, K.; Mahjoub, M.A.; Cleder, C. Automatic speech emotion recognition using machine learning. In Social Media and Machine Learning; IntechOpen: London, UK, 2019. [Google Scholar]
- Shen, P.; Changjun, Z.; Chen, X. Automatic speech emotion recognition using support vector machine. In Proceedings of the 2011 International Conference on Electronic & Mechanical Engineering and Information Technology, Harbin, China, 12–14 August 2011; IEEE: Piscataway, NJ, USA, 2011; Volume 2, pp. 621–625. [Google Scholar]
- Issa, D.; Demirci, M.F.; Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 2020, 59, 101894. [Google Scholar] [CrossRef]
- Gomathy, M. Optimal feature selection for speech emotion recognition using enhanced cat swarm optimization algorithm. Int. J. Speech Technol. 2021, 24, 155–163. [Google Scholar] [CrossRef]
- Daneshfar, F.; Kabudian, S.J. Speech emotion recognition using discriminative dimension reduction by employing a modified quantum-behaved particle swarm optimization algorithm. Multimed. Tools Appl. 2020, 79, 1261–1289. [Google Scholar] [CrossRef]
- Shahin, I.; Hindawi, N.; Nassif, A.B.; Alhudhaif, A.; Polat, K. Novel dual-channel long short-term memory compressed capsule networks for emotion recognition. Expert Syst. Appl. 2022, 188, 116080. [Google Scholar] [CrossRef]
- Kanwal, S.; Asghar, S. Speech emotion recognition using clustering based GA- optimized feature set. IEEE Access 2021, 9, 125830–125842. [Google Scholar] [CrossRef]
- Zhang, Z. Speech feature selection and emotion recognition based on weighted binary cuckoo search. Alex. Eng. J. 2021, 60, 1499–1507. [Google Scholar] [CrossRef]
- Wolpert, D.H. The lack of a priori distinctions between learning algorithms. Neural Comput. 1996, 8, 1341–1390. [Google Scholar] [CrossRef]
- Zeng, Y.; Mao, H.; Peng, D.; Yi, Z. Spectrogram based multi-task audio classification. Multimed. Tools Appl. 2019, 78, 3705–3722. [Google Scholar] [CrossRef]
- Shegokar, P.; Sircar, P. Continuous wavelet transform based speech emotion recognition. In Proceedings of the 2016 10th International Conference on Signal Processing and Communication Systems (ICSPCS), Surfers Paradise, QLD, Australia, 19–21 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–8. [Google Scholar]
- Bhavan, A.; Chauhan, P.; Shah, R.R.; Hitkul. Bagged support vector machines for emotion recognition from speech. Knowl.-Based Syst. 2019, 184, 104886. [Google Scholar] [CrossRef]
- Mao, Q.; Dong, M.; Huang, Z.; Zhan, Y. Learning salient features for speech emotion recognition using convolutional neural networks. IEEE Trans. Multimed. 2014, 16, 2203–2213. [Google Scholar] [CrossRef]
- Özseven, T. A novel feature selection method for speech emotion recognition. Appl. Acoust. 2019, 146, 320–326. [Google Scholar] [CrossRef]
- Singh, P.; Sahidullah; Saha, G. Modulation spectral features for speech emotion recognition using deep neural networks. Speech Commun. 2023, 146, 53–69. [Google Scholar] [CrossRef]
- Gerczuk, M.; Amiriparian, S.; Ottl, S.; Schuller, B.W. EmoNet: A transfer learning framework for multi-corpus speech emotion recognition. IEEE Trans. Affect. Comput. 2021, 14, 1472–1487. [Google Scholar] [CrossRef]
- Avila, A.R.; Akhtar, Z.; Santos, J.F.; Oshaughnessy, D.; Falk, T.H. Feature pooling of modulation spectrum features for improved speech emotion recognition in the wild. IEEE Trans. Affect. Comput. 2021, 12, 177–188. [Google Scholar] [CrossRef]
- Seyedali, M.; Mohammad, I.S.; Andrew, L. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Description |
|---|---|
| RAVDESS | The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) is a publicly available dataset designed for affective computing and emotion recognition research. It contains audio and video recordings of 24 actors performing eight different emotions in both speech and song. The dataset provides a diverse set of emotional expressions for study and is widely used in emotion recognition research. |
| TESS | The Toronto Emotional Speech Set (TESS) is a comprehensive and publicly available collection of 2803 audio recordings, featuring professional actors portraying seven distinct emotional categories. The dataset includes balanced representation from both male and female actors, making it valuable for developing and evaluating emotion recognition models. |
| SAVEE | The Surrey Audio-Visual Expressed Emotion (SAVEE) dataset is designed for research into speech emotion recognition, featuring 480 audio recordings with a single male actor portraying seven emotional states. The dataset provides a standardized resource for studying emotional speech and has been widely used in affective computing research. |
| EmoDB | The Emotional Database (EmoDB) is utilized for studying emotional speech recognition and consists of recordings from ten professional German actors portraying different emotions. The dataset, developed by the Technical University of Berlin, is valuable for developing and evaluating algorithms for automatic emotion classification from speech signals. |
| Observations | Dataset-Specific Observations |
|---|---|
| Limited Actor Diversity | RAVDESS: 24 actors may not fully represent diverse vocal characteristics. SAVEE: Only four male actors may limit diversity and variability. EmoDB: Ten actors may not fully capture wide-ranging vocal characteristics. |
| Imbalanced Emotional Classes | RAVDESS, SAVEE, EmoDB: Some emotions have fewer instances, impacting model performance. |
| Controlled Recording Conditions | RAVDESS, SAVEE, EmoDB: Recordings in controlled studios lack natural variability, affecting generalizability to real-world scenarios. |
| Limited Contextual Information | RAVDESS, SAVEE, EmoDB: A lack of contextual cues in datasets may limit the applicability to real-world scenarios influenced by various factors. |
| Limited Language Representation | RAVDESS: Primarily English, limiting cross-lingual applications. EmoDB: Primarily German, affecting cross-lingual usability. |
| Limited Emotional Variability | SAVEE: Four basic emotions may restrict generalizability. EmoDB: Seven discrete emotions may not cover the full spectrum of human emotional experiences. |
| TESS Advantages | Diverse emotional expressions, large number of actors, naturalistic recording conditions, high-quality recordings, detailed metadata, and multimodal data: the TESS dataset stands out for its richness, naturalness, and comprehensive features, contributing to its reliability and robustness in emotional speech analysis. |
| Without GWO Optimizer | GWO Optimizer | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Datasets | Measurements | SVM | K-SVM | CNN | LSTM | SVM | K-SVM | CNN | LSTM |
| Accuracy | 0.74 | 0.55 | 0.75 | 0.76 | 0.85 | 0.85 | 0.78 | 0.83 | |
| EmoDB | Precision | 0.71 | 0.42 | 0.74 | 0.73 | 0.82 | 0.87 | 0.77 | 0.82 |
| Recall | 0.70 | 0.45 | 0.69 | 0.71 | 0.82 | 0.84 | 0.77 | 0.87 | |
| F1-Score | 0.70 | 0.39 | 0.71 | 0.71 | 0.82 | 0.84 | 0.77 | 0.84 | |
| Accuracy | 0.74 | 0.55 | 0.53 | 0.73 | 0.85 | 0.87 | 0.60 | 0.73 | |
| RAVDESS | Precision | 0.71 | 0.42 | 0.53 | 0.73 | 0.84 | 0.88 | 0.59 | 0.69 |
| Recall | 0.70 | 0.45 | 0.52 | 0.82 | 0.83 | 0.85 | 0.56 | 0.71 | |
| F1-Score | 0.70 | 0.39 | 0.52 | 0.76 | 0.83 | 0.86 | 0.59 | 0.71 | |
| Accuracy | 0.54 | .35 | 0.57 | 0.62 | 0.76 | 0.75 | 0.68 | 0.71 | |
| SAVEE | Precision | 0.53 | 0.10 | 0.59 | 0.53 | 0.74 | 0.72 | 0.66 | 0.59 |
| Recall | 0.51 | 0.25 | 0.51 | 0.57 | 0.75 | 0.68 | 0.64 | 0.72 | |
| F1-Score | 0.52 | 0.15 | 0.53 | 0.59 | 0.73 | 0.68 | 0.64 | 0.71 | |
| Accuracy | 0.98 | 0.91 | 0.99 | 0.97 | 0.99 | 0.99 | 0.99 | 0.99 | |
| TESS | Precision | 0.98 | 0.93 | 0.99 | 0.96 | 0.99 | 0.99 | 0.99 | 0.99 |
| Recall | 0.98 | 0.91 | 0.99 | 0.95 | 0.99 | 0.99 | 0.99 | 0.99 | |
| F1-Score | 0.98 | 0.91 | 0.99 | 0.96 | 0.99 | 0.99 | 0.99 | 0.99 | |
| Reference | Dataset | Classifier Used | Accuracy |
|---|---|---|---|
| Bhavan et al. [44] | RAVDESS | Bagged ensemble of SVMs | 75.69% |
| Zeng et al. [42] | RAVDESS | DNNs | 64.52% |
| Shegokar and Sircar [43] | RAVDESS | SVMs | 60.1% |
| This Work (Proposed Method) | SAVEE | GWO-SVM GWO-CNN | 75% 65.47% |
| This Work (Proposed Method) | EmoDB | GWO-SVM GWO-CNN | 85% 78% |
| This Work (Proposed Method) | TESS | GWO-SVM GWO-CNN | 99.97% 99.93% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tyagi, S.; Szénási, S. Optimizing Speech Emotion Recognition with Deep Learning and Grey Wolf Optimization: A Multi-Dataset Approach. Algorithms 2024, 17, 90. https://doi.org/10.3390/a17030090
Tyagi S, Szénási S. Optimizing Speech Emotion Recognition with Deep Learning and Grey Wolf Optimization: A Multi-Dataset Approach. Algorithms. 2024; 17(3):90. https://doi.org/10.3390/a17030090
Chicago/Turabian StyleTyagi, Suryakant, and Sándor Szénási. 2024. "Optimizing Speech Emotion Recognition with Deep Learning and Grey Wolf Optimization: A Multi-Dataset Approach" Algorithms 17, no. 3: 90. https://doi.org/10.3390/a17030090