1. Introduction
In this study, we review the methods presented in the field of routing in VANET network. The need to control the traffic network has led to many researches in this field. By categorizing the methods introduced in this paper, we can offer a suitable perspective and direction to those interested in this field. A lot of papers use fuzzy methods, regression based methods, linear and nonlinear methods, and also machine learning methods [
1]. Recently, unsupervised and supervised methods as well as different RL methods have been used in this field.
Several studies have used reinforcement learning methods to optimize network throughput and improve latency, packet delivery rate, and quality of service in VANETs [
2]. Fuzzy logic algorithms have been used to find the most optimal path in the VANET network and improve network performance [
3]. Also, machine learning methods such as Q learning have been used to increase the efficiency of the vehicle network in terms of reducing delay and improving the packet delivery ratio [
4]. Furthermore, deep reinforcement learning algorithms have been used to improve VANET performance by predicting vehicle speed and position and identifying the most appropriate route [
5]. The use of a centralized SDN controller as a learning agent for VANET routing has also been investigated, and recent methods including the use of satellites and drones to achieve better routing and convergence in VANET networks have been investigated [
6].
Various researches have been conducted to evaluate and classify routing problems in this field, focusing on further analyzing the potential of reinforcement learning methods and artificial intelligence [
7]. In some researches, the combination of fuzzy logic and reinforcement learning approaches has been effective to improve vehicle routing in VANET network [
8]. Further analysis has been done on the effectiveness of fuzzy logic and reinforcement learning methods in network [
9].
In addition, the use of multi-agent reinforcement learning techniques for traffic flow optimization has been promising [
10]. Another study has investigated and classified routing and scheduling methods for emergency vehicles, including ambulance, fire trucks, and police, in VANET networks [
11]. These studies provide valuable insights into the challenges and potential solutions for achieving optimal routing in VANETs.
The goal of this research is to propose the most suitable method for achieving optimal routing in VANETs. The advancement of technology in the automotive industry, including the development of connected and autonomous vehicles and computing, has created a need for optimal use of resources. One way to achieve this is through automotive cloud computing, which can perform computing tasks from the edge or remote cloud.
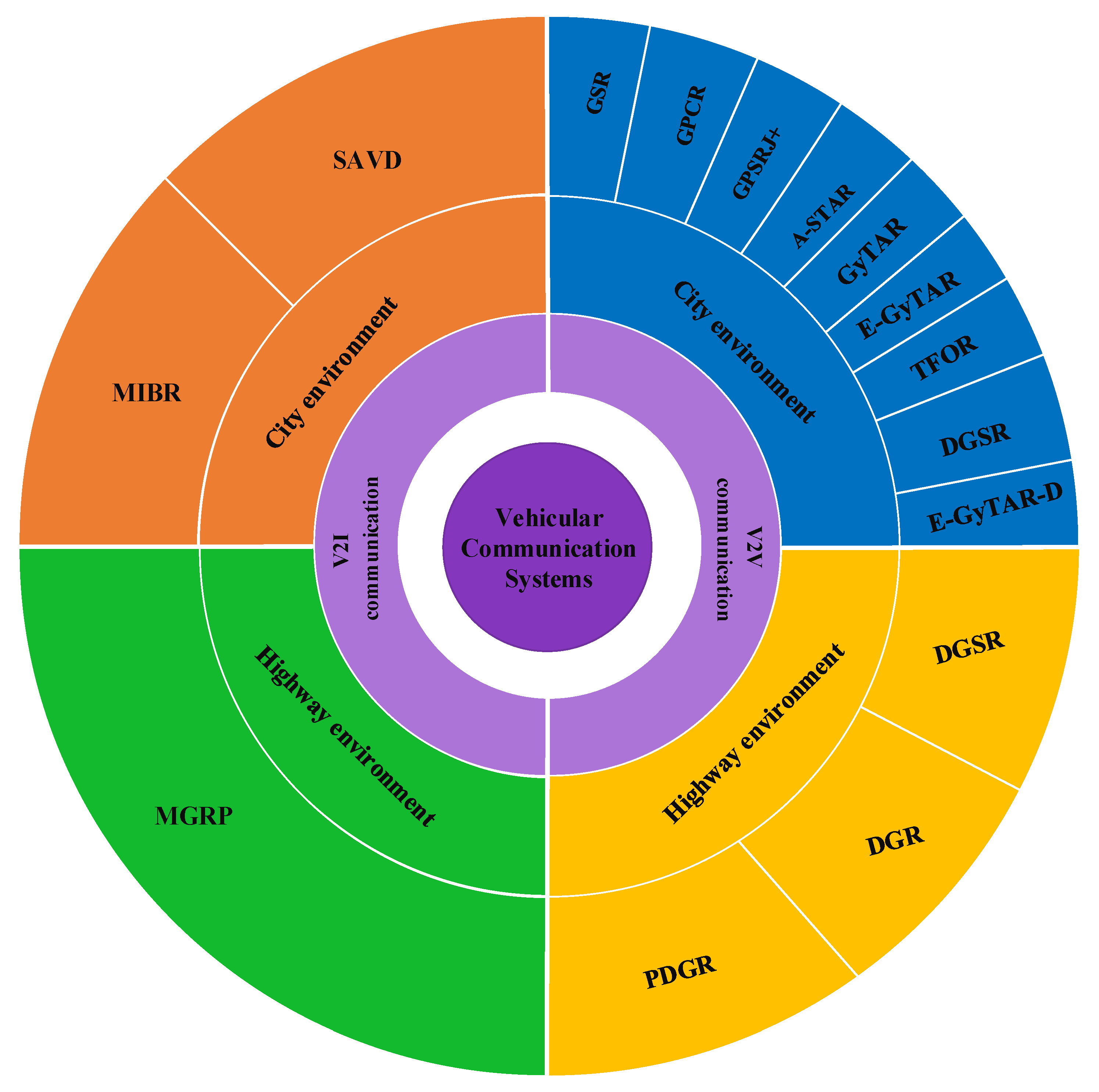
VANET is a subclass of mobile systems in which nodes are constantly moving and does not depend on a specific infrastructure. Routing protocols in VANET networks are divided into vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) routing. The research addresses challenges such as security and privacy issues, energy management, scheduling between centers at the origin and destination, network congestion control, and multiple routing and scheduling in VANET. In addition, the routing protocols in VANET networks are reviewed in
Figure 1.
The classification of position-based routing protocols is as follows:
GSR: Geographic Resource Routing
GPCR: Greedy Peripheral Coordinator Routing
GPSRJ+: The Geographic Perimeter Stateless Routing Junction+
A-STAR: Anchor-based Street and Traffic Aware Routing
GyTAR: Greedy Traffic Aware Routing
E-GyTAR: Enhanced Greedy Traffic Aware Routing
TFOR: Traffic Flow Oriented Routing
DGSR: Directional Greedy Source Routing
E-GyTAR-D: Enhanced Greedy Traffic Aware Routing Directional
GPSR: Greedy Perimeter Stateless Routing
DGR: Directional Greedy Routing
PDGR: Predictive Directional Greedy Routing
SADV: Static-Node-Assisted Adaptive Data Dissemination in Vehicular Networks
MIBR: Mobile Infrastructure-Based VANET Routing Protocol
MGRP: Mobile Gateway Routing Protocol
There are many challenges such as security and privacy, energy, scheduling among centers at the origin and destination, network congestion control, and numerous routing and scheduling problems in the VANET network.
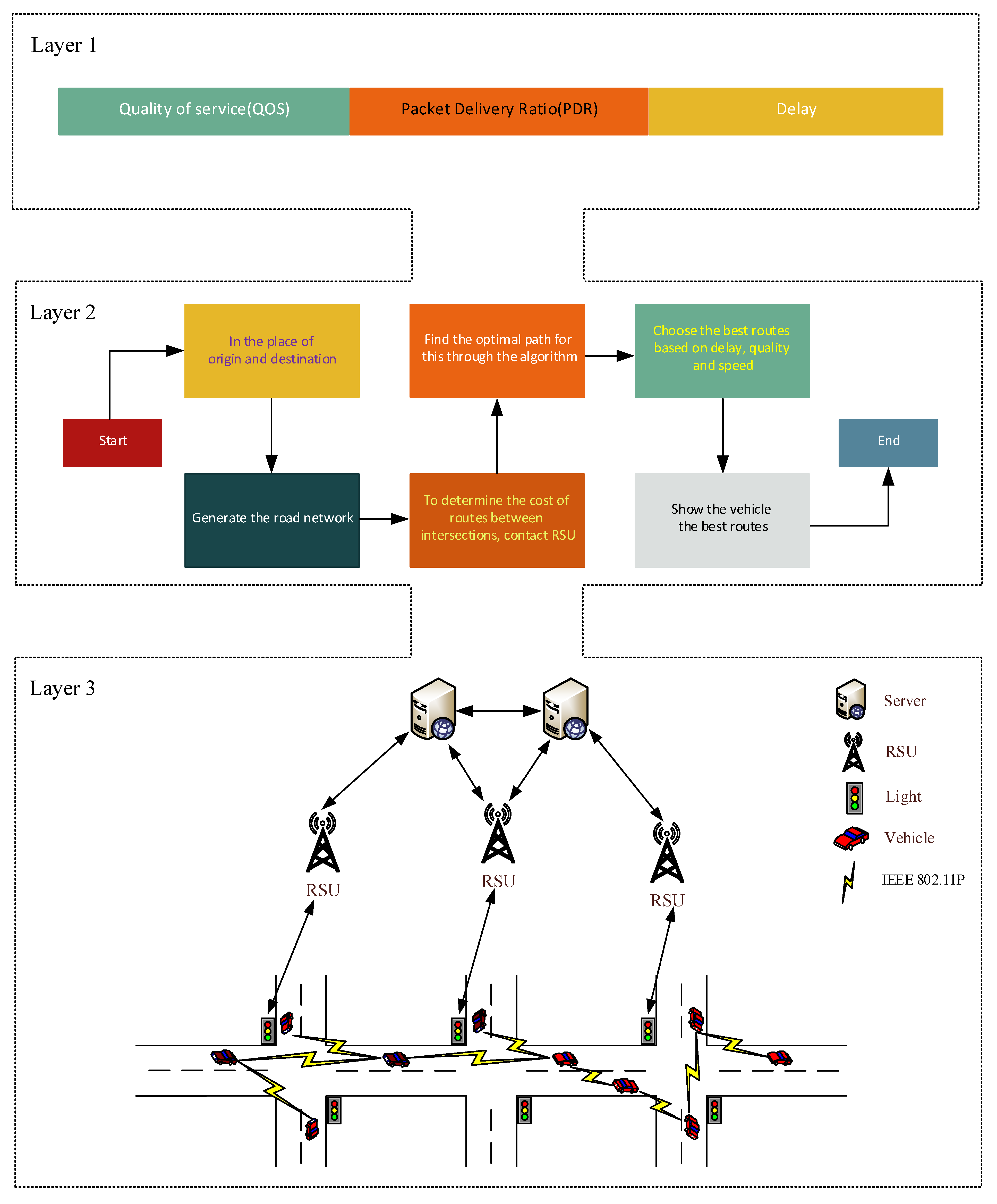
This research investigates traffic congestion control, optimal routing and network load reduction. The purpose of this study is to review various references in order to propose a suitable method for routing and load reduction in VANET network. The proposed method can be analyzed in several layers. In the first layer, according to the criterion of increasing network performance, our goals include increasing the quality of service, delay reduction and packet delivery ratio. In the second layer, a route is created at the origin and destination of the network, in which the cost and interaction of the routes between intersections are determined using RSUs. Through this algorithm, the best routes are selected based on reducing delay and increasing quality of service. In this layer, the speed of the most optimal routes is shown to the vehicles. In the third layer, the communication between servers, RSUs, traffic lights and vehicles in the environment is defined. Finally, an overview of routing in VANET network is drawn in
Figure 2 for a better understanding of this issue.
Significance of the Study
Cloud computing environments have limitations in extensive data processing systems. For example, nodes in a cloud environment encounter many clusters for calculations. Efficient task scheduling and resource allocation plans are required for fast data processing. These plans should distribute tasks on nodes in such a way that resource usage is maximized. For this purpose, we need task scheduling for data management. This research investigates scheduling and task scheduling with the goal of assigning tasks to appropriate resources and checking QoS in the network. A review paper is necessary for future research in various fields such as VANET, 5G, and 6G to choose the most appropriate methods and route.
Goals (Objectives)
This research aims to collect and classify related work in the fields of RL, FUZZY, and DRL in the VANET network to achieve the most optimal routing in the network. We classify the related work into four categories: reinforcement learning, fuzzy logic, overview, and deep reinforcement learning. The papers investigate criteria such as packet delivery ratio and delay, and one of the main goals is to study optimal routing and network overhead control. The areas of use of different protocols such as the type of routing, discovery of optimal routes, and quality of service (QoS) are evaluated. The study also investigates how to design and model different algorithms for routing in the network, and network efficiency for routing, network overhead control, and convergence speed.
The Overall Structure of the Paper
Section 2 presents related work, and reinforcement learning, fuzzy logic, and deep reinforcement learning methods are classified.
Section 3 describes the proposals, and
Section 4 is devoted to discussion and conclusion.
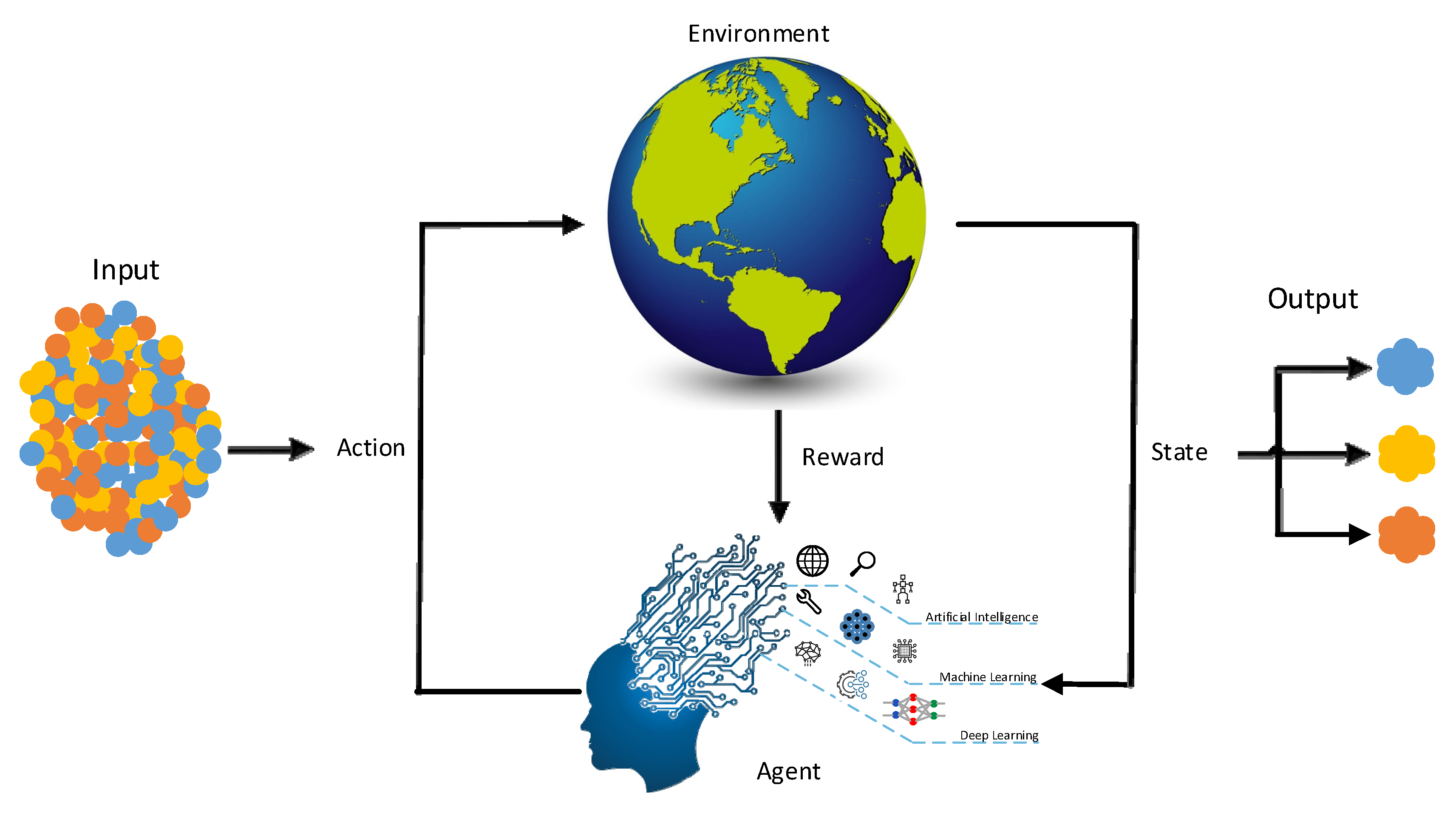
Machine Learning in VANET Networks
Machine learning includes reinforcement learning and algorithms in which a learning agent tries to maximize rewards in its environment to achieve a specific goal. By interacting with the environment, the learner selects appropriate actions to apply to the environment. In general, the RL agent’s objective is to maximize warehouses’ reward. An overview of machine learning in VANET networks is drawn in
Figure 3 for better understanding.
In general, there are three approaches to reinforcement learning:
Value-oriented approach
In the value-oriented approach, the aim is to optimize the value function
. The value function is a function that determines the maximum future reward that the agent receives in each state. The value of each state is equal to the total value of the reward that the agent can expect to gain in the future starting from that state.
Policy-oriented approach
Policy-oriented reinforcement learning aims to optimize the policy function
without using the value function. Policy is what determines the behavior of an agent at a given time. The agent learns a policy function. This helps him to map each situation to the best possible action.
There are two types of policies:
Deterministic: The policy always returns the same action for a given state.
Stochastic (random): a probability distribution is considered for each action.
A stochastic policy, in which performing a specific action is conditional on a specific state, is defined as follows and
Figure 4 shows finding random policies:
Model-Oriented Approach
In model-oriented reinforcement learning, the environment is modeled, meaning that a model of the behavior of the environment is created. An important issue in this approach is providing a different model for each environment.
Supervised Learning Method
Supervised machine learning looks for a relationship among a series of functions that optimize the data cost function. For example, in the regression problem, the cost function can be the square of the difference between the forecast and the actual output values, or in the classification problem, the loss is equal to the negative logarithm of the output probability. The problem with learning neural networks is that this optimization problem is no longer convex, and we face local minima.
One of the common methods of solving the optimization problem in neural networks is backpropagation. This method calculates the gradient of the cost function for all weights of the neural network and then uses gradient descent methods to find a set of optimal weights. Gradient decreasing methods try to alternately move against the direction of the gradient and thereby minimize the cost function. Finding the gradient of the last layer is simple and can be obtained using partial differentiation. However, the gradient of the middle layers cannot be obtained directly, and methods such as the chain rule must be used in differentiation. The backpropagation method uses the chain rule to calculate the gradients, starting from the highest layer and distributing them in the lower layers.
Unsupervised Learning Methods
Unsupervised learning has much more difficult algorithms than supervised learning because there is little information about the data or the results. In unsupervised learning, we look for items with which we can form groups or make clusters, estimate density, and reduce dimensions. Compared to these two types of learning, unsupervised learning has fewer tests and models used to ensure the model’s accuracy. In supervised learning, the data is “labeled” and classified according to these labels. In unsupervised learning, the model is allowed to discover information, and this action is hidden from the human eye.
Artificial Intelligence-Based Methods
Artificial intelligence is the simulation and modeling of human intelligence processes by machines, including computer systems. By examining the environment, artificial intelligence takes actions that increase its chances of success. By planning artificial intelligence, we can achieve the desired goals by getting environmental rewards.
Most artificial intelligence algorithms have the ability to learn from data. These algorithms can reinforce themselves by learning from past achievements. Through managing infrastructure, artificial intelligence can control the health of servers, storage and network equipment, and check the health of systems and predict the time of equipment failure. In addition, workload management helps direct data automatically toward appropriate infrastructures at a specific time. Moreover, it can guarantee security and regularly check network traffic, alerting experts when problems occur. Finally,
Figure 5 shows an overview of the artificial intelligence for better understanding
Neural Network Learning Methods
The neural network is trained through its inputs, including the input, hidden, and output layers. Neurons include a threshold value and an activation function. Our desired output is compared with the output of the neural network. The closer their values are, the lower the error and the more accurate the output. In one node, the input data is multiplied by a weight. The higher the weight, the greater the impact of the data. Then, the sum of the data multiplied by their weight is calculated, and the total value obtained passes through an activation function to produce the output.
Convolutional Neural Networks (CNN)
Convolutional Neural Networks, or CNNs, are a special type of neural network used for image recognition and classification. CNNs perform a mathematical operation called convolution, which is a linear operation. Convolutional networks are similar to neural networks, but they use convolution instead of general matrix multiplication.
Recurrent Neural Networks (RNN)
Recurrent Neural Networks have a recurrent neuron, and the output of this neuron returns to itself t times. They are a type of artificial neural network used for speech recognition, sequential data processing, and natural language processing. They can remember their previous input due to their internal memory and use this memory to process a sequence of inputs. In other words, recurrent neural networks have a recurrent loop that prevents the loss of previously acquired information, allowing this information to remain in the network.
Random Learning Methods (Random Forest)
Random Forest is considered a supervised learning algorithm. As its name suggests, this algorithm creates a random forest, which is actually a group of decision trees. The forest is usually created using the bagging method, where a combination of learning models increases the overall results of the model. In other words, Random Forest constructs multiple decision trees and merges them together to produce more accurate and stable predictions.
One advantage of Random Forest is that it can be used for both classification and regression problems, which make up the majority of current machine learning systems. Here, the performance of Random Forest for classification will be explained, as classification is sometimes considered the building block of machine learning. In the picture below, you can see two Random Forests made up of two trees.
2. A Review of Past Research (Related Work)
The studies reviewed in this research are divided into several tables: reinforcement learning, fuzzy logic, review articles, and deep reinforcement learning, respectively. First, a short summary of the studies is provided in the tables, and the simulation tools used to simulate them are also mentioned. In addition, the advantages and disadvantages of each article are discussed. Finally, the evaluation criteria are presented in
Table 1.
Reinforcement Learning
Machine learning includes Reinforcement Learning and algorithms in which a learning agent tries to maximize rewards in its environment to achieve a specific goal. By interacting with the environment, the learner selects appropriate actions to apply to the environment. In general, the objective of the RL agent is to maximize the stock reward.
In 2022, Ankita Singh et al. [
1] presented an optimization algorithm using reinforcement learning for wireless mesh networks (WMN). This algorithm uses reinforcement learning to find the shortest path with minimum delay and deliver the packets in the WMN. In fact, this algorithm aims to check and reduce the criteria of packet transmission ratio, packet delivery ratio (PDR), delay and network congestion. This algorithm was able to improve network throughput.
In 2022, Jingjing Guo et al. [
2] provided a routing method using intelligent clustering. This algorithm includes clustering, regulating clustering policies and routing modeling. This method examined ultrasonic unmanned networks and improved delay, packet delivery ratio and quality of service in this network.
In 2022, Ming Zhao et al. [
4] presented a data transmission method based on the Manhattan model and used Temporal Convolutional Network (TCN) and Reinforcement Learning based Genetic Algorithm (RLGA) to improve the network load. This method solved the routing problem and reduced data transmission time and delay in the network.
In 2022, Arbelo Lolai et al. [
5] proposed a reinforcement learning-based routing method I for VANETs. They also used Machine learning methods such as Q-learning to improve the structure of reinforcement learning based routing. Results showed that this method improved the efficiency of the vehicle network in terms of delay reduction and packet delivery ratio.
In 2022, Kazim Ergun et al. [
6] investigated solving routing problems using the IoT systems reinforcement learning.
In 2018, Liang Xiao et al. [
7] defined a VANETs network using aerial vehicles such as drones and then analyzed and controlled it using artificial intelligence and reinforcement learning methods. The actions and reactions between drones are formulated as a game theory. According to this formulation, the interference of the Nash balance of the drone game is calculated in order to determine the cost of the optimal transmission of Drones.
In 2020, Jinqiao Wu et al. [
8] designed a RSU strategy based on Q-learning as a routing mechanism for traffic network. The method had the required efficiency for routing in VANETs and also reduced the density and delay in this network.
In 2018, Fan Li et al. [
9] focused on hierarchical routing in VANETs using reinforcement learning. This routing was done using Q-Grid algorithm and improved the packet delivery ratio. Q-Grid consists of Q-learning algorithms and network-based routing. In this method, Q-values are obtained according to the traffic flow and density of the network, and then, using Markov’s law, optimal policies are chosen. This mechanism reduced the delay and network load.
In 2010, Celimuge Wu et al. [
10] proposed a distributed reinforcement learning algorithm named Q-Learning AODV for routing in VANETs, in which a Q-Learning pattern is used to obtain VANETs network state data. This method reduces the length of the route and route discovery to choose the best route to deliver data. According to the research results, this mechanism significantly efficiently routed in VANETs network.
In 2018, Jinqiao Wu et al. [
12] proposed a routing mechanism named ARPRL for VANETs using reinforcement learning methods. They used the Q-learning pattern to achieve optimal routing in the VANETs. In addition, MAC layer has been used to develop Q coordination with VANETs network. Finally, this method had the necessary efficiency in terms of packet delivery ratio, delay reduction, and selection of suitable routes for VANETs network.
In 2016, Celimuge Wu et al. [
13] presented a method that stores the data in VANETs by transferring data to vehicles before moving, and then uses a fuzzy algorithm to investigate reward recognition for vehicle speed and Bandwidth efficiency in order for selecting the carrier nod. In addition, reinforcement learning and clustering have been used to investigate future reward and data collection to improve the efficiency of VANETs.
In 2020, Xiaohan Bi et al. [
14] proposed a routing mechanism using reinforcement learning and clustering methods for VANETs to improve network performance and reduce the number of routes.
In 2021, Long Luo et al. [
15] proposed a V2X routing mechanism for intersections in VANETs using artificial intelligence and reinforcement learning methods. This mechanism was intended for real-time networks in which Q -learning was used to calculate routing table. this routing mechanism could control network overhead, packet delivery ratio, network density and delay.
In 2021, Benjamin Sliwa et al. [
16] presented an algorithm for routing prediction in the traffic network using reinforcement learning methods.
In 2021, Chengyue Lu et al. [
17] provided a reinforcement learning algorithm to control and reduce VANETs network congestion. This reinforcement learning algorithm has been investigated in a multi-agent way. In this method, an agent t receives a reward in real time. The reward depends on the previous interval and the interval after sending reward. If the sending fails, a penalty will be charged. This method has led to reducing the delay and controlling the congestion of vehicles in the traffic network.
In 2021, Zhang et al. [
18] have investigated vehicle-to-vehicle (V2V) routing in VANETs. By combining fuzzy logic and reinforcement learning approaches, they have improved network performance, increased packet delivery ratio, and reduced delay. Also, dynamic management of VANET network and adaptability to network changes are also investigated.
In 2022, Hasanain Alabbas et al. [
19] presented a new gateway selection mechanism to find the best mobile gateway for vehicles that require Internet access. In this method, there is a system with two cloud servers, the first collects the necessary information about CVs and MGs, collects the necessary information about CVs and MGs, and the second uses the data to train the agent.
In 2022, Nitika Phull et al. [
20] combined game theory and reinforcement learning methods to improve routing in VANETs. The game theory was used to classify vehicles. and select a leader for the group. A reinforcement learning method (K-means) is also applied to expand the clusters. This proposed method causes better and more stable routing.
In 2022, J. Aznar-Poveda et al [
21] dealt with traffic light control and traffic network congestion reduction using reinforcement learning techniques. The traffic network control problem is formulated using the Markov algorithm in this study. Problem-solving process and optimal actions are performed using reinforcement learning. Faster convergence, packet delivery, and optimal routing indicated the excellent performance of the algorithm.
Table 1.
Review of articles that have used reinforcement learning methods to control the VANET network.
Table 1.
Review of articles that have used reinforcement learning methods to control the VANET network.
| Refs | Short Description | Simulation | Advantages | Disadvantages | Evaluation Criteria |
|---|
| Waiting Time | Queue Length | Travel Time | Delay Time | PDR |
|---|
| [1] | An optimization algorithm using reinforcement learning for wireless mesh networks (WMN) is presented | NS-3 | | | | | | ✓ | ✓ |
| [2] | A routing method using intelligent clustering is proposed | OPNET | By communicating with each other, each agent performs only high-level subtasks it learns the value of a common abstract action. Reduce calculations
| | | | | ✓ | ✓ |
| [4] | Network control is done using reinforcement learning and genetic algorithm. | -- | | | | | | ✓ | |
| [5] | A routing method in VANETs based on reinforcement learning algorithms is proposed. | MATLAB | | | | | | ✓ | ✓ |
| [6] | IoT system has been investigated in terms of network routing using reinforcement learning. | NS-3 | | Collecting and managing data from all devices is challenging In case of failure of one of the devices, there is a possibility of failure of other devices as well.
| | | | ✓ | ✓ |
| [7] | Using aerial vehicles such as drones, a network of VANETs has been defined and then the proposed method has been analyzed using artificial intelligence and reinforcement learning methods. | -- | Improve network quality Reduce interference
| | | | | | |
| [8] | Designing a routing mechanism for traffic network using RSU and reinforcement learning | VanetMobiSim | | | | | | ✓ | ✓ |
| [9] | Hierarchical routing in VANETs has been aaddressed using reinforcement learning | -- | communicating with each other, each agent performs only high-level subtasks it learns the value of a common abstract action. The hierarchical method improves mobility in the traffic network
| | | | | ✓ | |
| [10] | A distributed reinforcement learning algorithm is proposed for routing in VANETs. | NS-2 | | | | | | | ✓ |
| [11] | Using reinforcement learning methods, a routing mechanism for VANETs is proposed | QualNet | | | | | | ✓ | ✓ |
| [13] | fuzzy algorithms and reinforcement learning have been used to control VANETs network. | NS-2 | Flexible implementation and simplicity of the algorithm The possibility of simulating human logic and thinking The possibility of creating two solutions for one problem
| | | | | ✓ | |
| [14] | A routing mechanism has been proposed for VANETs using reinforcement learning and clustering methods | Python | communicating with each other, each agent performs only high-level subtasks it learns the value of a common abstract action.
| | | | | ✓ | ✓ |
| [15] | A V2X routing mechanism for intersections in VANETs is proposed using artificial intelligence and reinforcement learning methods, in which real-time networks were focused. | OMNeT++ and SUMO | Simultaneous control for fast processing High security and reliability in real-time systems that perform critical and sensitive tasks Predictability and guarantee of doing things
| Real-time systems are large and complex In these systems, it is not allowed to combine hardware and software of real-time systems.
| | | | ✓ | ✓ |
| [16] | An algorithm for predicting routing in the traffic network using reinforcement learning methods is presented. | OMNeT++ | | | | | | ✓ | ✓ |
| [17] | A reinforcement learning algorithm is presented to control and reduce VANETs network congestion. | 3GPP TR | | | | | | ✓ | ✓ |
| [19] | A new gateway selection mechanism is proposed to find the best mobile gateway for vehicles that require Internet access. | SUMO | | | | | | | |
| [20] | Combining game theory and reinforcement learning methods, an algorithm for improving routing in VANETs is presented. | -- | Game theory provides the possibility of framing strategic decisions. This theory can predict the outcome of competitive conditions Identify optimal strategic decisions.
| | | | | | |
| [21] | By using reinforcement learning techniques, traffic light control and traffic network congestion reduction have been done. | SUMO | | | | | | ✓ | ✓ |
| [22] | Traffic flow control using multi-agent reinforcement learning (MARL) method and coordination between traffic lights at intersections | SUMO | | | | ✓ | | ✓ | ✓ |
| [23] | Presenting a Markov approach for Internet of Vehicles (IoV) transportation systems. | | | | | | | ✓ | |
Fuzzy Logic
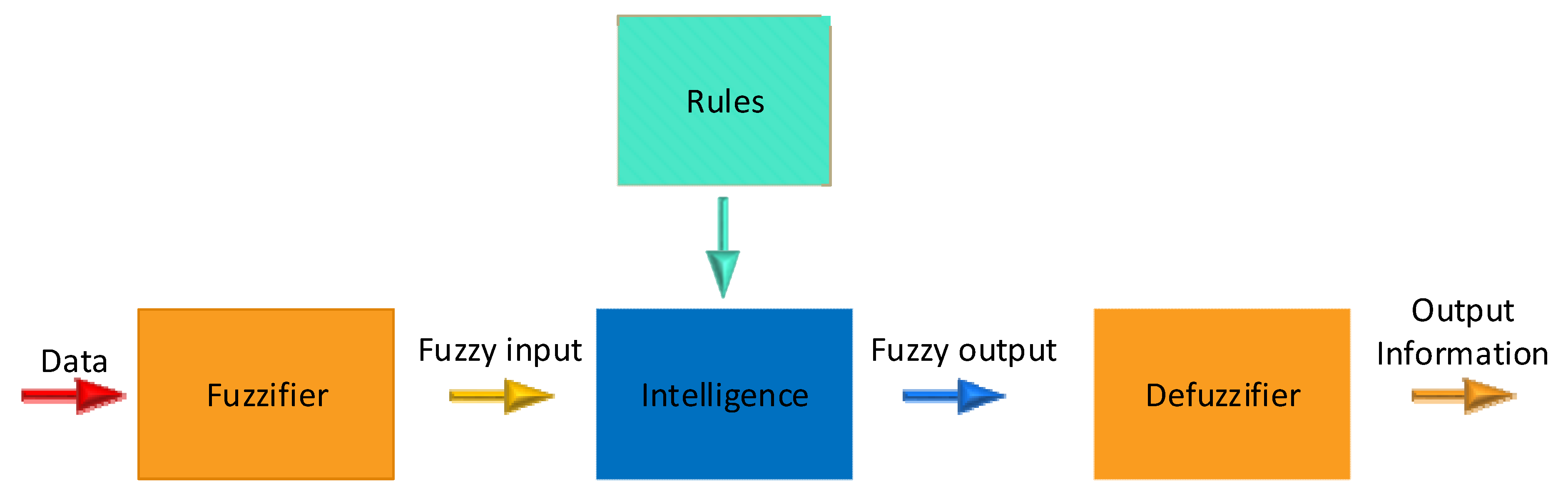
The optimal routing is obtained using a fuzzy constraint and Q-learning method in the VANET network. Fuzzy logic has four main parts which are introduced below. Then,
Figure 6 shows the diagram of how to connect these parts.
Basic rules: This section contains all the rules and conditions specified as “if...then” by an expert to be able to control the “decision-making system”. According to the new methods in the fuzzy theory, it is possible to adjust and reduce the rules and regulations so that the best results can be obtained with the least number of rules.
Fuzzification: In this step, inputs are converted into fuzzy information. This means that the numbers and information to be processed will be converted into fuzzy sets and fuzzy numbers. The input data, for example, measured by sensors in a control system, are changed in this way and prepared for fuzzy logic-based processing.
Inference engine or intelligence: This section determines the degree of compliance of the inputs obtained from fuzzification with the basic rules. Based on the compliance percentage, different decisions are made as the results of the fuzzy inference engine.
Defuzzification: In the last step, the results of fuzzy inference, which are in the form of fuzzy sets, are converted into quantitative and numerical data and information. At this stage, you make the best decision according to the outputs, including different decisions with different compliance percentages. Usually, this choice will be based on the highest degree of compliance.
In 2022, Omid Jafarzadeh et al. [
3] provided a routing algorithm based on multi-agent reinforcement learning (MARL) and fuzzy methods for VANETs. They also utilized Mamdani method to derive the fuzzy model. Metrics such as packet delivery ratio and delay have been improved.
Review articles
In 2019, Zoubir Mammeri et al. [
11] reviewed and categorized articles in the field of routing in networks using reinforcement learning.
In 2021, Rezoan Ahmed Nazib et al. [
24] reviewed studies on optimal routing in VANETs using artificial intelligence and reinforcement learning methods.
In 2021, Sifat Rezwan et al. [
25] reviewed, categorized and compared studies in the field of reinforcement learning and artificial intelligence applications in flight networks. In addition, by examining the problems and ideas of various articles, they help researchers in conducting new research.
In 2022, Miri et al. [
23] used Markov for Internet of Vehicles (IoV) systems, which finally proposed a resource interpretation scheme using Time Division Markov Multiple Access (TDMA) algorithm.
In 2022, Daniel Teixeira et al. [
26] reviewed studies in the field of intelligent routing in VANETs. They also investigated the effectiveness of the algorithms used in the studies and evaluation of the routing methods proposed for the traffic network. According to this research, heuristic methods, fuzzy algorithms and reinforcement learning have the necessary efficiency to improve network performance. Also,
Table 2 examines the advantages and disadvantages of the research that used the fuzzy method.
In
Table 3, different routing approaches in the VANET network, such as fuzzy logic and reinforcement learning methods, have been compared, and this comparison has been made according to the advantages, disadvantages and evaluation criteria.
Deep reinforcement learning
In the Q-learning algorithm, with the increase of the data volume, limitations occur that this algorithm can no longer solve the problem. So, it is possible that the algorithm does not reach convergence. Deep learning uses a memory that obtains output based on approximations of Q values. From this memory, the data are randomly selected for training.
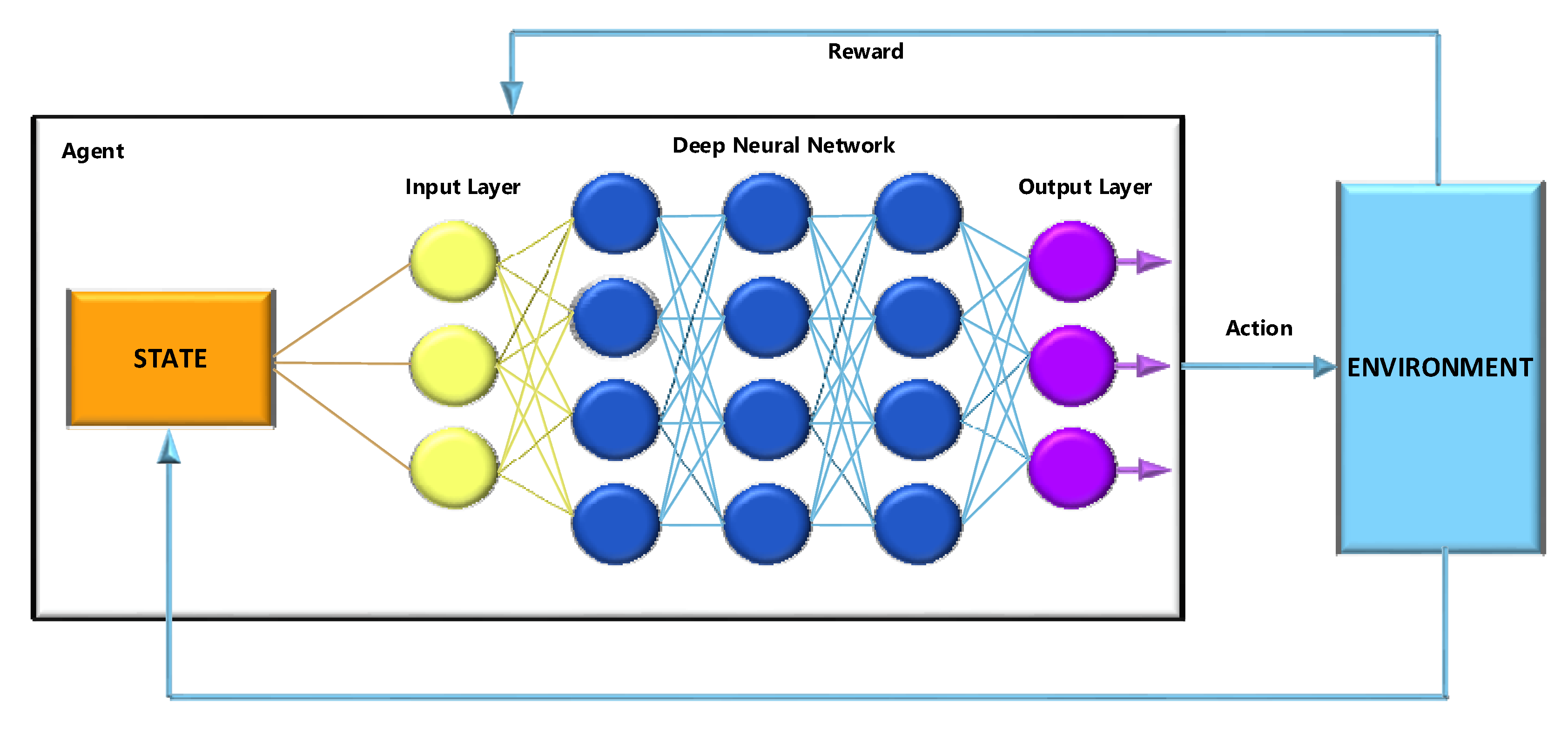
DRL uses deep neural networks to solve reinforcement learning problems, hence the word ‘deep’ is used in its name. Q-learning is considered a classical reinforcement learning and is different from Deep Q-learning in some ways.
In the first approach, traditional algorithms are used to build a Q table to help the agent determine the action in each state. In the second approach, a neural network estimates the reward based on the state, q value. In general, deep reinforcement learning helps us make better decisions faster. Also, to better understand deep reinforcement learning, an overview is drawn in
Figure 7.
In deep reinforcement learning, a neural network is an Artificial Intelligence (AI) agent. The neural network interacts directly with its environment. The network observes the current state of the environment and decides which action to take according to its current state and past experiences (for example, move left, right, etc.) The AI agent may receive a reward or outcome based on the action the AI agent takes. The reward or outcome is merely a scale. A negative outcome (for example −6) occurs if the agent performs poorly and a positive reward (for example +6) occurs if the agent performs well.
The quality of the action is directly related to the quantity of the reward and it predicts the probability of solving the problem (e.g., learning how to walk). In other words, an agent’s goal is to perform an action that maximizes the accumulated reward over time in any given situation.
Markov decision process
Markov decision process (MDP) is a time-discrete stochastic control process, the best approach we have so far for modeling the complex environment of an AI agent. Any problem that the artificial intelligence agent intends to solve can be considered as a sequence of states: .
The agent performs actions and moves from one state to another. In the following, we show you the mathematics that determines which action the agent should perform in each situation.
Markov processes
Markov process (or Markov chain) is a stochastic (random) model l that describes a sequence of possible states in which the current state depends only on the previous state. This feature is also called Markov. For reinforcement learning, it means that the next stage of an AI agent depends only on the last state and not on all previous states.
The Markov process is stochastic (random), which means that the transition from the current state (
s) to the next state (
) occurs only with a certain probability (
)
is the entry in the state transition matrix P, which defines the transition probabilities from all states to all successor states (
).
Markov reward process
The reward Markov process is a tuple
. Here, R is the reward that the agent expects to receive in state s. The AI agent is motivated by the fact that to achieve a particular goal (e.g., winning a game of chess), certain states (game configurations) are more promising than others in terms of strategy and potential for winning the game.
The main issue is the total reward (Gt) equation, which is the expected cumulative reward that the agent receives across the sequence of all states. The discount coefficient
measures each reward. We find discounting rewards mathematically convenient because doing so avoids infinite returns in cyclic Markov processes. In addition, the discount factor means that the further into the future we consider, the less important the rewards are to immediate satisfaction since the future is often uncertain. For example, if the reward is financial, immediate rewards may be more beneficial than delayed rewards.
Value function
Another important concept is the concept of the value function
. This function draws a measure for each state ‘s’. The value of a state ‘s’ is the total expected reward that the AI agent will receive if it starts progressing in state ‘s’.
The value function can be divided into two parts:
Bellman equation for Markov reward processes
The decomposed value function is considered as the Bellman equation for Markov reward processes. This function is visualized using node graph. Starting at state ‘s’ results in the value
. By being in state ‘s’, we have a certain probability (
) to end up in the next state ‘s’. In this particular case, two next states may occur. To obtain the value of
, the values of
of the possible next states weighted by the probabilities of
should be added and then added to the immediate reward of being in state ‘s’. Also, for better visualization, a graph is drawn in
Figure 8.
Markov decision process vs. Markov reward process
Markov decision process is a reward Markov process with a decision that is described by a set of tuples
. In this example, A is the finite set of possible actions that the agent can take in state ‘s’. Therefore, the immediate reward of being in state ‘s’ also depends on the agent’s action in this state.
Policy
The agent decides what action to take in a particular situation. The policy determines the π of an action. Mathematically, a policy is a distribution over all actions given to a state, which determines the mapping of a state to an action that the agent should perform.
In other words, we can describe the policy π as the agent’s strategy to choose specific actions depending on the current situation. This policy leads to a new definition of the value function -state v(s).
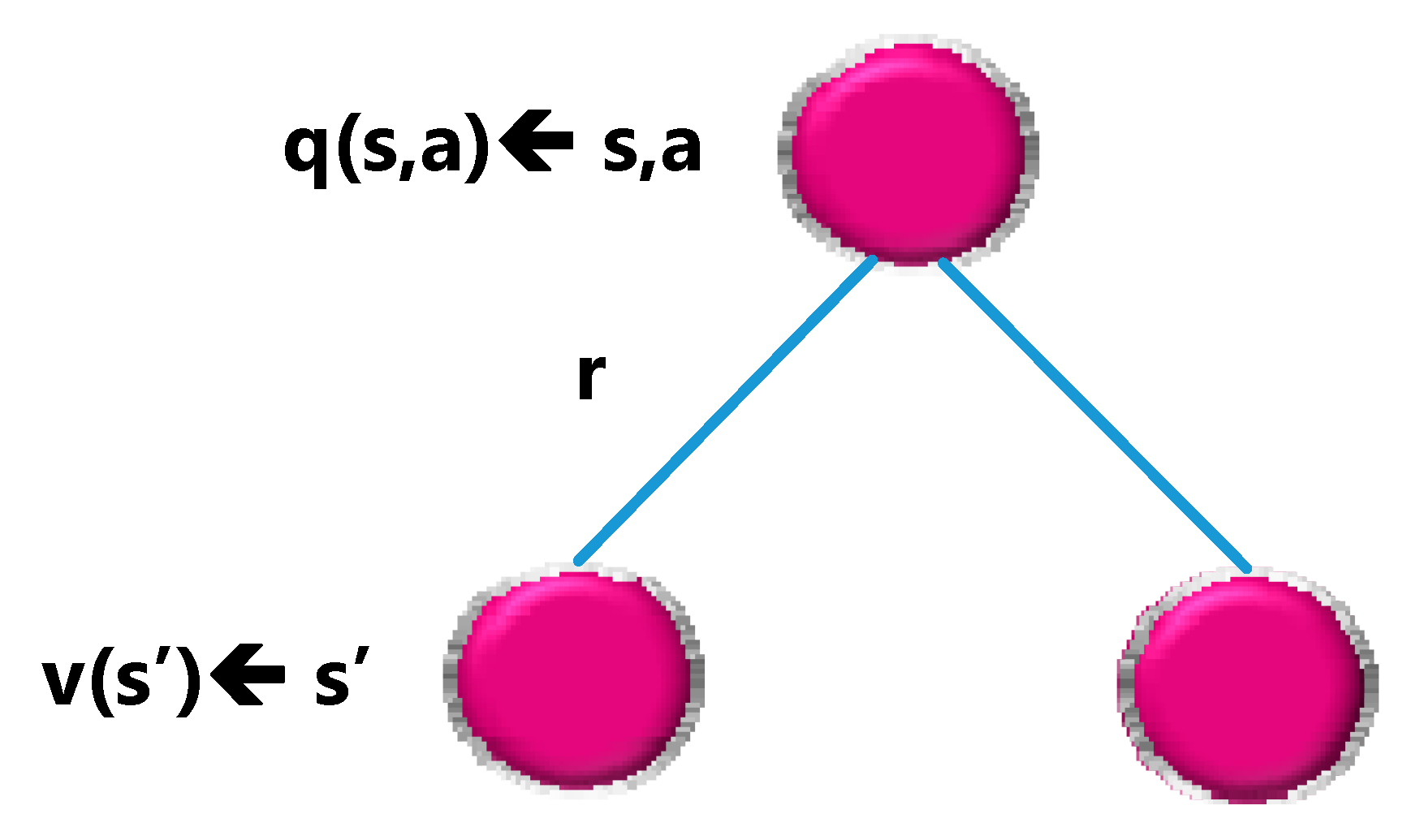
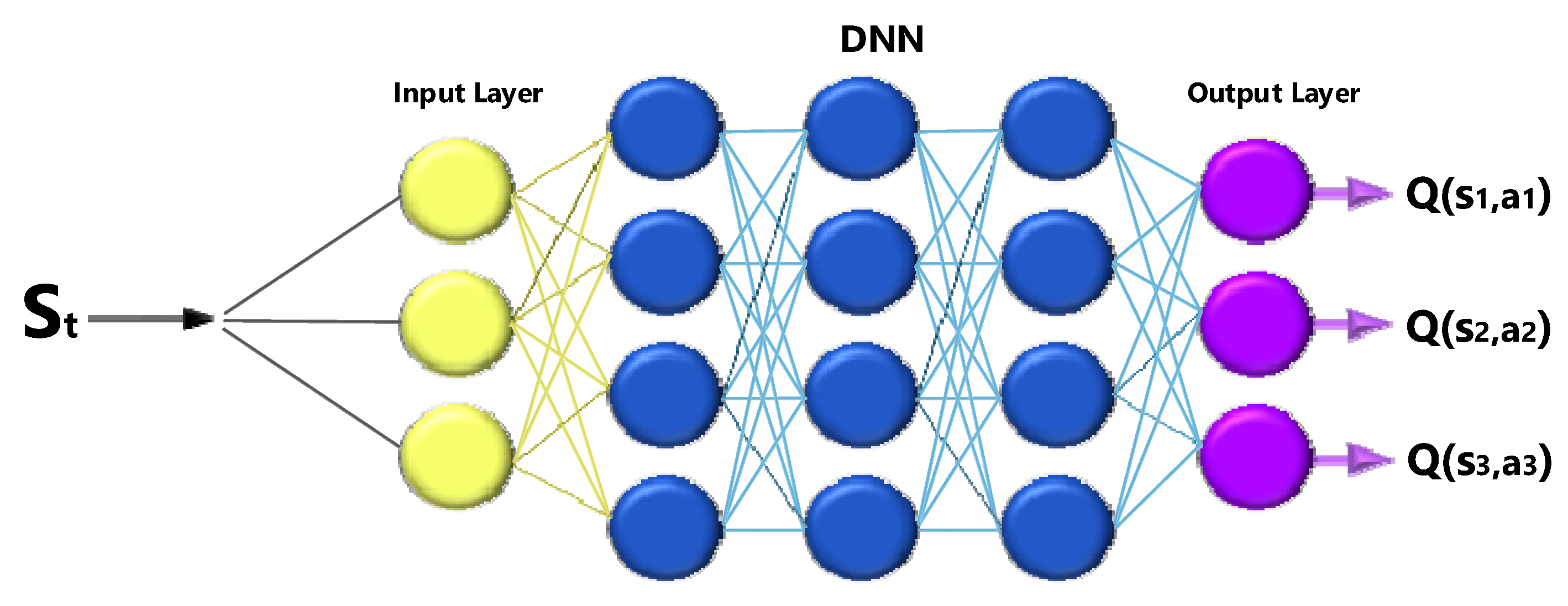
ACTION-VALUE Function
Another essential function is the action value function q(s,a), which is the expected return obtained by starting in state ‘s’, performing action a, and then following a policy π. Note that a state s, q(s,a) can have multiple values because there are multiple actions that the agent can perform in state ‘s’. The neural network calculates Q(s,a). Considering state ‘s’ as input, the network calculates the quality of every possible action in this state in a scalar form. Higher quality means better action according to the given goal. Finally,
Figure 9 graph of the description of the action value function is drawn.
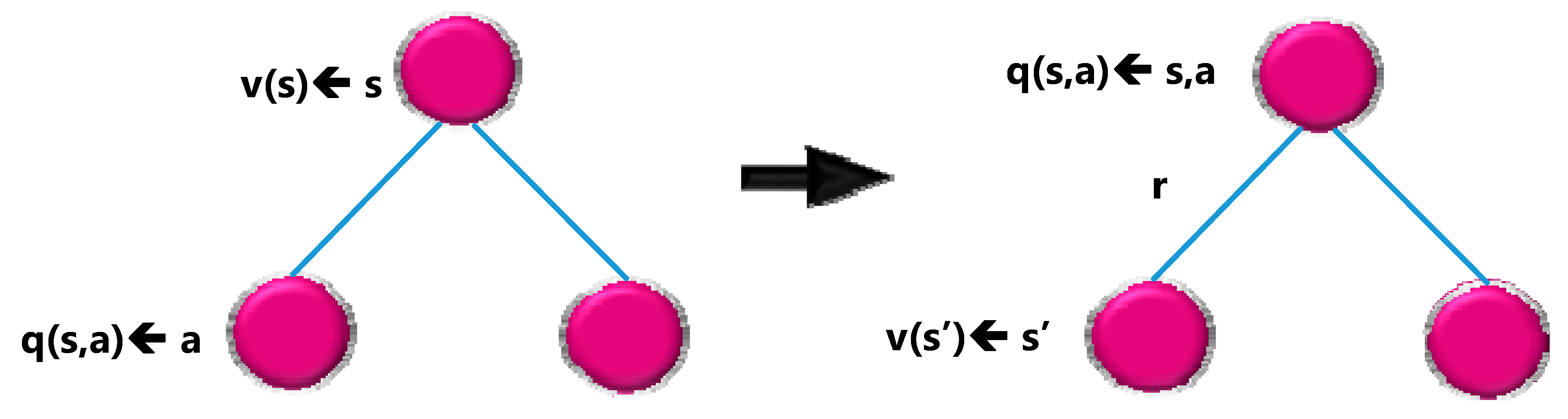
Remember that the Action-value function tells us how good it is to perform a specific action in a certain state.
By definition, performing a specific action in a specific state results in an action value q(s,a). The value function v(s) is the sum of possible q(s,a) weighted by the probability (which is nothing but the policy π) of performing an action in state ‘s’.
Figure 10 shows a visualization with a node graph.
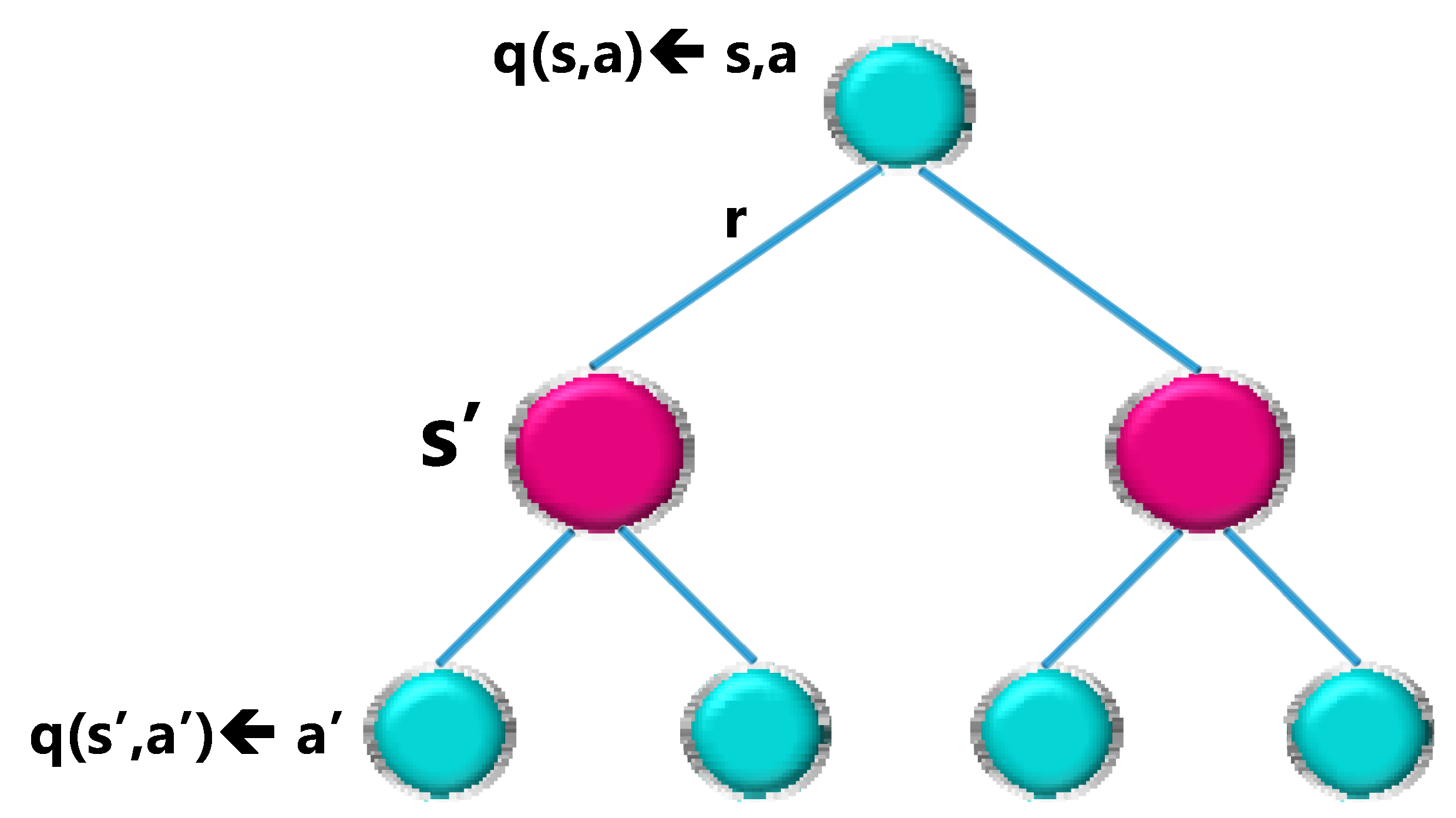
To get the action value, you need to take the discounted state values with the
probabilities in all possible states (in this case just two states) and add the immediate reward:
This recursion relation can be visualized in another binary tree, with q(s,a) ending in the next state ‘s’ with a given probability
, as an action ‘a’ is performed with the probability π and ends with the action value q(s’,a’).
Figure 11 shows the tree design with node graph.
Optimal policy
The most important issue in deep reinforcement learning is to find the optimal action-value function q*. Finding q* means that the agent knows exactly the quality of an action in each given state. Additionally, the AI agent can decide which action to take based on the desired quality.
If we want to define q*. The best possible action-value function is the one that follows the policy that maximizes the action values:
We need to maximize q(s,a) to find the best possible policy. Maximization means to select only the action an among all possible actions for which q(s,a) has the highest value. This gives the following definition for the optimal policy π:
Optimal Bellman equation
If the AI agent can solve this equation, it means that it has solved the problem in the given environment. The agent in any state or situation knows the quality of any possible action according to the goal and can act accordingly. Solving Bellman’s optimality equation will be the subject of future research in this field.
One of the DRL method’s limitations is that researchers must completely understand their environment. Not all systems can be made completely and without defects using deep reinforcement learning. In systems where the consequences of wrong decisions can be dire, deep reinforcement learning cannot work on its own.
Table 4 examines the articles that are used to control the VANET network using deep reinforcement learning methods.
In 2019, M. Saravanan et al. [
14] proposed a routing mechanism for VANETs using artificial intelligence methods and deep reinforcement learning algorithm. In this method, the vehicle’s speed and position is predicted and appropriate routing is chosen, which increases the performance of VANETs network. According to the results, this routing method has reduced the transmission delay and has been effective for routing in VANETs.
In 2018, Dajun Zhang et al. [
18] proposed a deep reinforcement learning method for connected vehicle communication. Centralized SDN controller is also used for VANETs network routing. This controller has also been used as a learning agent to learn routing in VANETs network. In addition, a deep Q-learning algorithm has been used to determine the routing policy.
The comparison between routing protocols based on machine learning and fuzzy logic depends on the evaluation criteria used and the results obtained and the specific application in the VANET network. However, in general, machine learning-based methods are more popular due to their ability to learn from data and adapt to changing conditions in a VANET network, while fuzzy logic methods are more widely used due to their ability to handle uncertainty and imprecision in the network.
In general, Methods based on machine learning, especially deep learning and reinforcement learning, can automatically learn complex algorithms and solve various problems in the VANET network, while methods based on fuzzy logic do not have this feature. On the other hand, machine learning-based methods may provide better performance than fuzzy methods due to the fact that they use previous data in the decision-making process. In addition, in some cases it is possible to use the combination of machine learning methods and fuzzy logic to cover the shortcomings of both methods.
Finally, choosing the appropriate method between machine learning and fuzzy logic depends on various factors such as the specific application, data, evaluation criteria, and specific constraints of the VANET application. When there are frequent changes in topology and traffic conditions in VANET, machine learning methods may be more suitable, while when VANET is exposed to uncertain or imprecise data, fuzzy logic methods may be more suitable. In
Table 5, there is also a review of the articles that deal with VANET network control using fuzzy logic and machine learning methods.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










