1. Introduction
Deep Generative Modeling involves training a deep neural network to approximate the high-dimensional probability distribution of the training data, enabling the generation of new examples from that distribution. There are various approaches to deep generative modeling, such as Generative Adversarial Networks (GANs) [
1], Variational AutoEncoders (VAEs) [
2], and Normalizing Flow models [
3]. A comprehensive review of deep generative modeling can be found in [
4].
In some cases, the architecture includes both an encoding and a decoding scheme, as is the case with models such as VAEs. The encoding process is typically used to obtain compact representations of the data distribution, often achieved through pooling operations that reduce the dimensionality of the data. The creation of a “bottleneck” by embedding the input samples in lower and lower dimensional spaces enables the extraction of essential features of the data. The decoding scheme, on the other hand, often employs reverse techniques used in the encoding, such as un-pooling operations, to restore the original dimensionality of the data.
In recent years, there has been a growing interest in utilizing Deep Learning in the field of Medical Physics. Specifically, in Radiotherapy (RT), Deep Generative modeling presents a valuable opportunity to streamline the calculation of deposited dose distributions by radiation in a given medium. These data, which are currently computed using more resource-intensive methods, can be utilized to optimize and validate RT treatment plans. Little effort has been made so far in this area, except for in the works of [
5,
6]. Models for this application should possess two key properties. Firstly, a high resolution in dose prediction is crucial and requires the ability to process large data efficiently. Secondly, models should be lightweight to enable their use in resource-constrained medical devices and for online training. In the future, real-time imaging may enable real-time treatment planning optimization, making it imperative to use fast Deep Learning models during both training and inference.
Deep Learning applications can find a role in specialised hardware for both resource efficient deployment and fast inference tasks. These models are referred to as Lightweight models and they are designed to be small and efficient, making them well-suited for use on resource-constrained devices. Notable applications are embedded software in Internet of Things (IoT) devices [
7], wearable medical devices [
8], and real-time applications such as online video analysis, e.g., online crowd control [
9]. A similar need is also present for models developed for fast inference on accelerated hardware, for which a keypoint example is the trigger analysis in high energy physics experiments [
10]. These models are typically smaller and less complex than traditional deep learning models, which allow them to run on devices with limited computational power and memory. Moreover, designing them often involves trade-offs between computational resources and performance.
Deep Generative Modeling is commonly based on Convolutional Neural Networks (CNNs) for many applications, as they are one of the most powerful tools for processing grid-like data in Deep Learning frameworks. However, a significant amount of real-world data is better described by more flexible data structures, such as graphs.
A graph is defined by a pair = . is a set of N vertices, or nodes, while is the set of edges, which carry the relational information between nodes. The edge set E can be organised into the adjacency matrix A, an binary matrix, whose elements are equal to 1 if a link between i-th and j-th node exists and is equal to 0 otherwise.
To address learning tasks on graphs, there has been an increasing interest in Graph Neural Networks (GNNs). These architectures typically use Graph Convolutional layers (GCNs), which allow for the processing of data on graphs, generalizing the concept of convolutions in CNNs. There are currently several types of GCNs available, ranging from the simplest models [
11,
12], to those based on graph spectral properties [
13], and those that include attention mechanisms [
14]. Although it is currently possible to achieve excellent results in solving various problems of classification, regression, or link prediction on graphs, graph generation remains an open challenge [
15].
Unlike images, graphs often have complex geometric structures that are difficult to reproduce, particularly in an encoder–decoder framework. Despite various approaches existing, there is currently no standard method for addressing this class of problems. Standard classes of models for graph generation are Graph AutoEncoders (GAEs) and Variational Graph AutoEncoders (VGAEs) [
16], which apply the concepts of AutoEncoders and Variational AutoEncoders (VAEs) to graphs. However, these architectures can only reconstruct or generate the adjacency matrix of the graphs, not the features of their nodes. Additionally, while these models can learn meaningful embeddings of node features, the graph structure and number of nodes remain fixed during the encoding process, resulting in no compression of input data through pooling operations and no bottleneck.
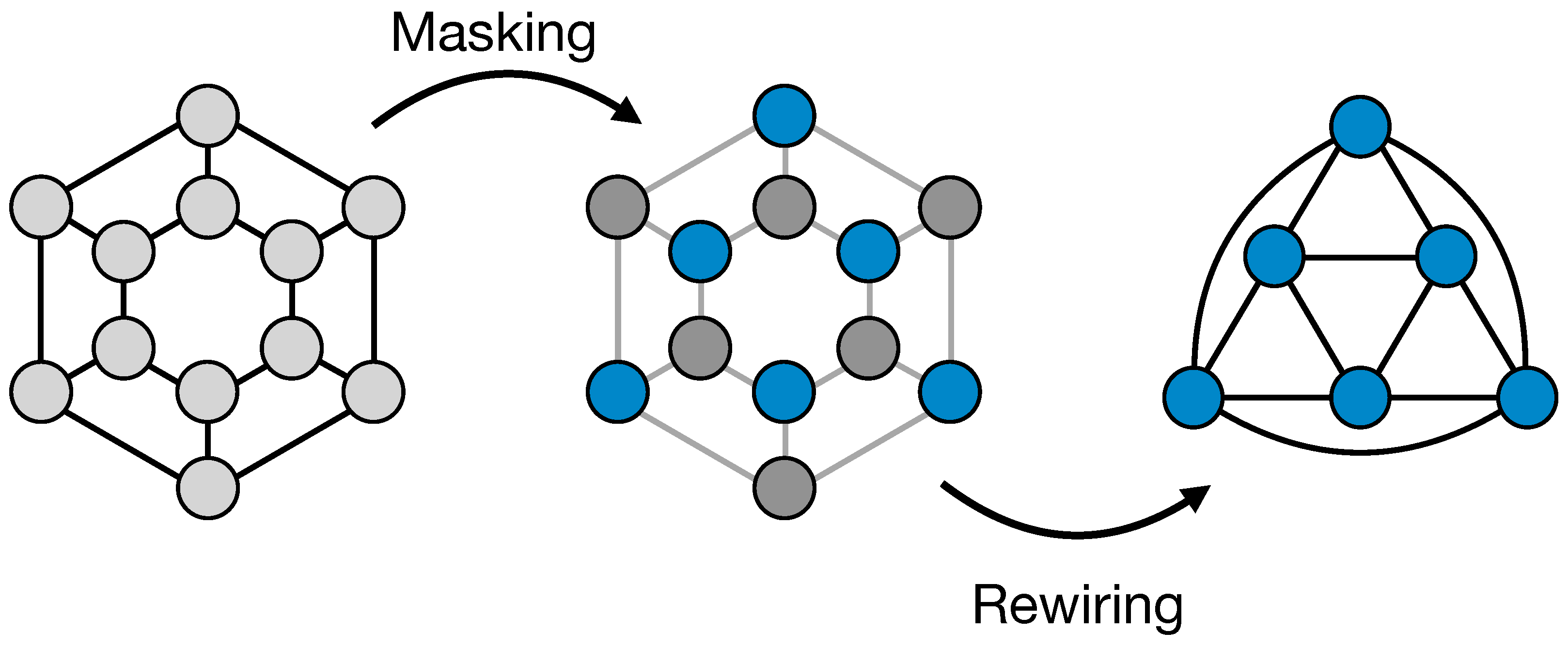
Different strategies have been developed for pooling operations on graphs. Early works used the eigen-decomposition for graph coarsening operations based on the graph topological structure, but these methods are often computationally expensive. An alternative algorithm is the Graclus algorithm [
17], used in [
13] and later adopted in other works on GNNs. Approaches like this aim to define a clustering scheme on graphs, on top of which it is possible to apply a standard max or mean pooling. Other approaches, such as SortPooling [
18], select nodes to pool based on their importance in the network. There is also a stream of literature that bases pooling operations on spectral theory [
19,
20]. Finally, state-of-the-art approaches rely on learnable operators that, such as message-passing layers, can adapt to a specific task to compute the optimal pooling, such as DiffPool [
21], Top-K pooling [
22], and ASAPooling [
23]. These pooling methods have been demonstrated to perform well when integrated into GNN models for graph classification, but all have limitations. For example, DiffPool learns a dense matrix to assign nodes to clusters, thus it is not scalable to large graphs. Top-k pooling samples the top-k aligned nodes with a learnable vector, not considering the graph connectivity. In this way, after the pooling, a good connectivity between the surviving nodes is not guaranteed. ASAPooling uses a self-attention mechanism for cluster formation and a top-k scoring algorithm for cluster selection, also taking into account graph connectivity. While overcoming some limitations of previous methods, this pooling requires more computations, which can lead to high computing needs for large graphs.
In contrast to pooling procedures, there is currently a lack of solutions for un-pooling operations for graphs that can be considered the inverse of pooling. The only works that attempt to define such operations are described in [
22,
24]. Other decoding schemes for graph generation are designed in different ways, most of which are task-specific. For example, in many algorithms for protein or drug structure generation, decoding is conducted by adding nodes and edges sequentially [
25,
26]. On the other hand, there are also works on “one-shot” graph generation, with decoding architectures that can output the node and edge features in a single step [
27,
28]. However, in various works that use this approach, the decoding of nodes and edges are considered separately and do not take into account the structure of the graphs. For example, in [
29], a 1D-CNN is used to decode node features and a 2D-CNN is used for edge features.
In summary, we found that the current literature lacks:
A pooling operation for graph data that takes into account graph connectivity and, at the same time, is lightweight and scalable to a large graph;
A graph generative model based on an encoder–decoder architecture;
A decoding solution that is based on the message passing algorithm.
In this study, we propose a model for graph generation based on Variational AutoEncoders. We focus on the case of graph data with a fixed, regular, and known geometric structure. To this end, we have developed:
Simple, symmetrical, and geometry-based pooling and unpooling operations on graphs, which allow for the creation of bottlenecks in neural network architectures and that are scalable to large graphs;
A Variational AutoEncoder for regular graph data, where both the encoding and decoding modules use graph convolutional layers to fully exploit the graph structure during the learning process.
The remainderof the study is organized as follows. In
Section 2, we describe our proposed deep learning architecture and the datasets used. First, in
Section 2.1, we introduce our Nearest Neighbors Graph VAE, describing how the developed pooling and unpooling techniques work and how they are integrated into the generative model. Then, in
Section 2.2, we describe the benchmark sprite dataset and present our own set of cylindrical-shaped graph data for a Medical Physics application. In
Section 3, we present the results of applying our Graph VAE to the described datasets. We also conduct an ablation study to compare the performance of our model using different pooling and unpooling techniques. The paper concludes with a final discussion in
Section 4.
4. Discussion
In this work, we presented our Nearest Neighbour Graph VAE, a Variational AutoEncoder that can generate graph data with a regular geometry. Such a model fully takes advantage of the Graph convolutional layers in both encoding and decoding phases. For the encoding, we introduced a pooling technique (ReNN-Pool), based on the graph connectivity that allows us to sub-sample graph nodes in a spatially uniform way and to alter the graph adjacency matrix consequently. The decoding is carried out using a symmetrical un-pooling operation to retrieve the original graphs. We demonstrated how our model can reconstruct well the cylindrical-shaped graph data of energy deposition distributions of a particle beam in a medium.
We also evaluated the performance of the model on the sprite benchmark dataset, after transforming the image data into graphs. Although it can not be directly compared with more sophisticated and task specific algorithms for image synthesis, our model has the ability to generate good quality images, create disentangled representations of features, and interpolate through samples as well as a standard CNN VAE. Finally, we performed an ablation study on pooling. The results show how, on our task on large regular graphs, using the ReNN-Pool is more efficient and leads to better performances versus using a state-of-the-art technique, such as Top-k Pool.
Finally, we believe that ReNN-Pool represents a simple, lightweight and efficient solution to pool regular graphs. It requires no computation during either the training or inference of models because node masks and adjacency matrices can be computed and stored early on. Thus, it is directly scalable to graphs of any size, contrarily to state-of-the-art pooling techniques. Moreover, the definition of a symmetrical un-pooling technique enables the construction of graph decoding modules, which can take advantage of graph convolutional layers. The current limitation of our pooling is that it has been only tested on regular graphs. However, a test on irregular graphs is among our future research directions. Although ReNN-Pool is not directly usable on all types of graphs, such as fully or highly connected ones, we believe that it could also be an efficient solution for irregular graphs with small to medium-sized node neighbourhoods. We also plan to test our method on graph U-Net architectures, where the symmetry between encoding and decoding is needed.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








