5.1. Specification of the Genetic Algorithm
A chromosome is defined as a vector of real numbers, with a size equal to 2, whose elements will be: ALKPHOS, MCV and DCH:
where the general clinical ranges for a healthy liver are between 44 ≤ ALKPHOS ≤ 200 and 80 ≤ MCV ≤ 140. On the other hand, the ideal values of DCH to accurately determine the status of the liver must be 0 ≤ DCH ≤ 160,000 (There is an equivalence between this extreme value of DCH with the maximum longitudinal value of the liver (14.5 cm)). We apply the evolving capabilities of the GA to determine whether, with these sensors, we can sense the ALKPHOS and MCV variables that define a good value of DCH to monitor possible damage in the liver. The objective function in our case determines the DCH based on the ALKPHOS and MCV variables. According to the literature, this function is [
35,
36,
37]:
where the constant 0.05 is used to remove the units of the variables. The optimization occurs when the objective function is minimized (𝑚𝑖n(𝐹𝐹)), which means that we have values sensed of the ALKPHOS and MCV that allow for determining a good value for DCH.
On the other hand, for the evolution of the chromosome, we use a directed mutation to substitute the values of the elements of the chromosome randomly with those existing in the databases of the context (monitored patient).
For the hyperparameter optimization of the GA has been used the next set of values:
Number of generations: [10, 50, 100, 150, 200]
Population size: [10, 30, 50, 70, 100]
5.2. Case Studies
In the case studies, we are going to determine if it is possible, with the sensors, to capture the two variables of interest in a patient, to obtain a DCH that allows for monitoring the status of his/her liver. To do so, we conduct several simulations for different datasets with the information of the patients, in a case of a healthy patient taken from [
15], and in others with diseased livers (cases of alcoholics (taken from [
36])) and cases of other diseases (taken from [
37])).
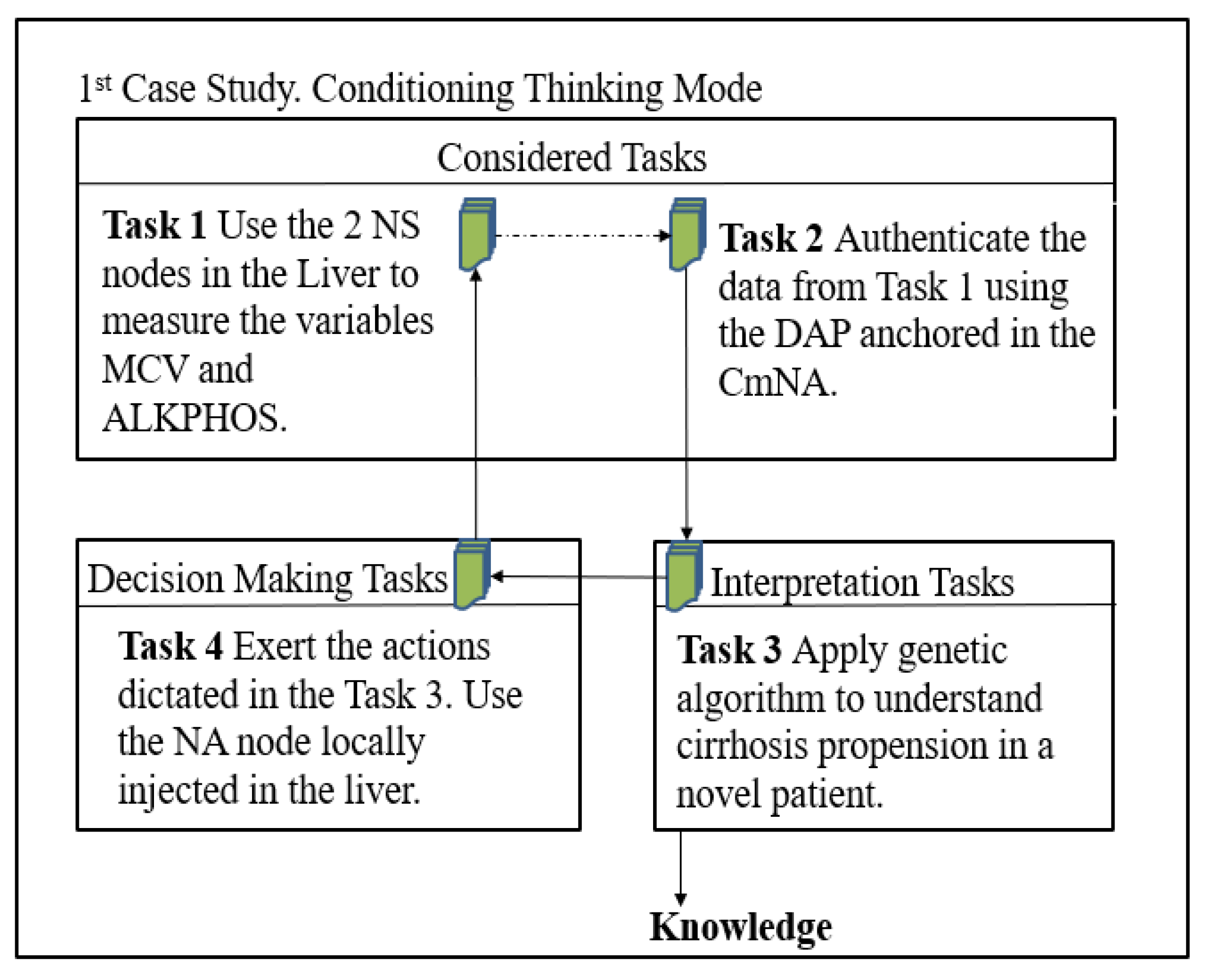
Case 1:
This is the first test case using a single sensor per variable (1 NS). We run the hyperparameter optimization every time we launch the GA. For example, the best values for each parameter for case 1 with the dataset [
15] (it is the case of non-liver sick) are shown in
Table 3.
The system with one NS was executed, and the best chromosome obtained is shown in
Table 4, with the minimum best score (DCH).
According to these results, the best distance from one end of the liver to the periphery, using the values of ALKPHOS and MCV for one of the patients in this dataset, is 24,225. This means that with one NS, the liver of that patient can be monitored without problem.
Now, we test our technique on the other two diseased liver datasets.
Table 5 shows the results obtained with our GA for one NS.
Table 5 reveals two phenomena. For the first dataset, it is possible to obtain a very large DHC for the monitored patient; that is, it obtains values on the periphery of the liver to analyze its status. This indicates that a single sensor can be injected. However, the most relevant is that, in the second dataset, our GA cannot achieve a DCH, even in its periphery, to monitor this patient, which indicates that we must try with more sensors (objective of case study 2).
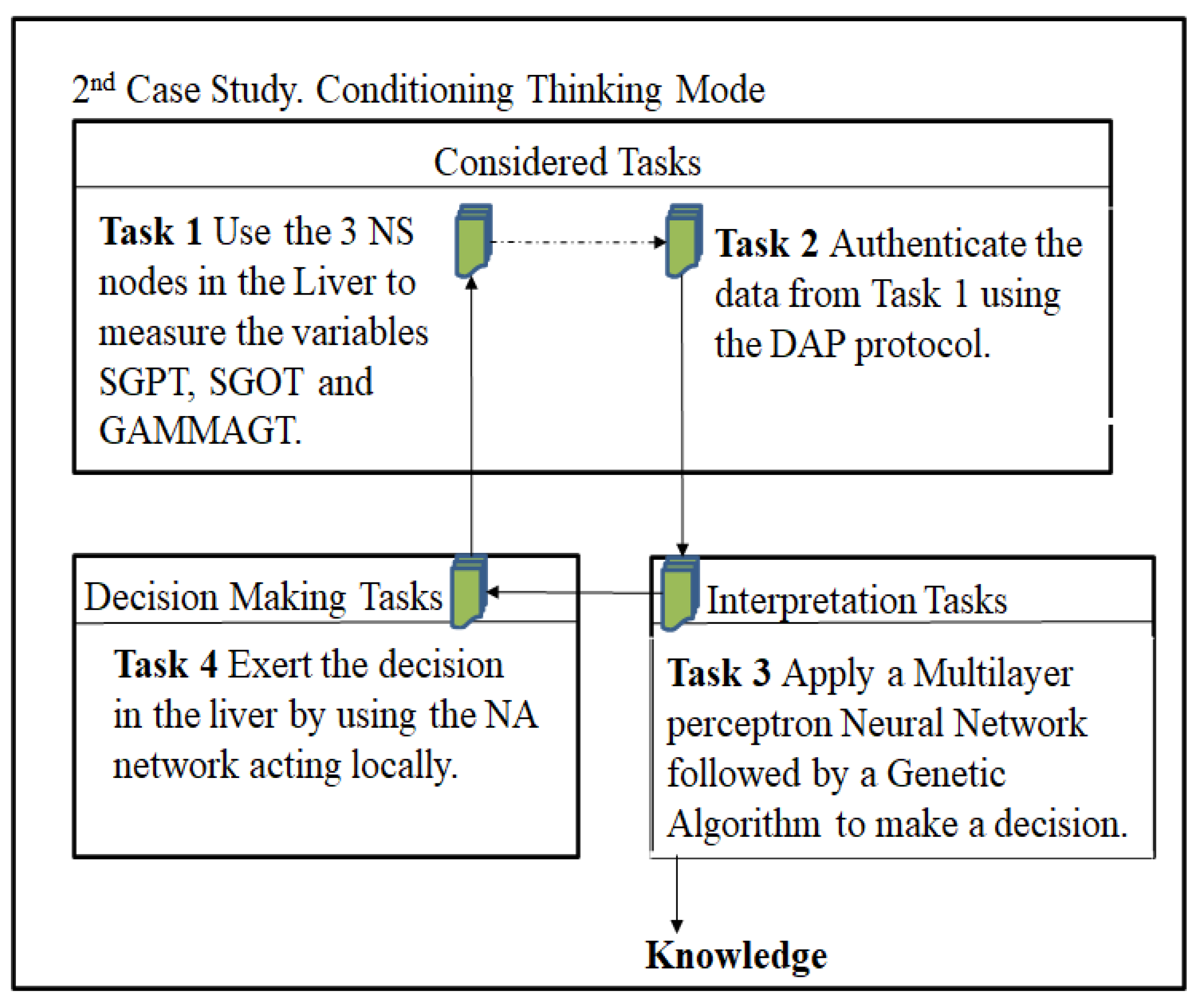
Case 2:
In this case study, the idea is to determine the appropriate number of sensors to be able to monitor a sick patient. In particular, we are going to use several patients from the dataset [
37], which could not be monitored with one NS. On the other hand, in this case, the length of the chromosome is variable, so its length n depends on the number of NS used in that GA run. Thus, the chromosome t is represented as a vector of real numbers, with a size equal to n.
The objective function, in this case, is given by:
The hyperparameter optimization of the GA is conducted for each GA run with a different
n (multisensor system) for
n equal to three NSs, five NSs, ten NSs, and twenty NSs. The best results (individual) for each run are shown in
Table 6.
Table 6 indicates that at least four sensors are required to correctly monitor the liver. In addition, it indicates that having more than five sensors does not improve the accuracy of the liver monitoring results.
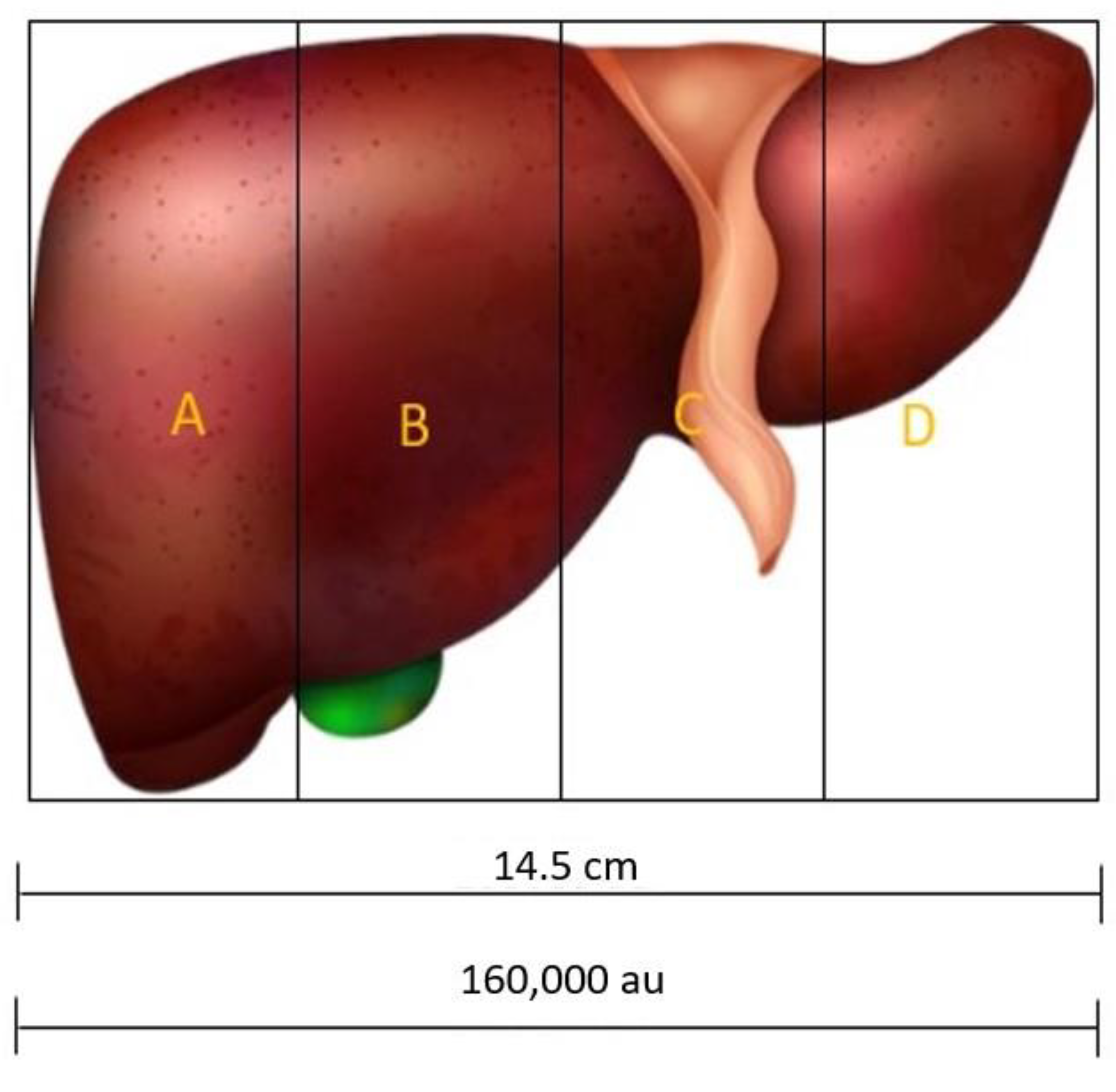
Something interesting to determine is how to implement the NS. For example, in the case of four NSs, considering the best individual, the liver can be divided into four zones (see
Figure 5): A, from 0 to 40,000; B, from 40,000 to 80,000 au; C, from 80,000 to 120,000 au; and D, from 120,000 to 156,500. Therefore, each sensor must be injected into these areas to obtain the data from the damaged area.
The behavior of a multisensor system depends on the amount of NSs that are tracking the liver. In addition, it determines the zones where the NSs will be deployed (see
Figure 5). On the other hand, a small o big number of NSs is not indicative of an optimal DCH, it is a number that must be determined (in our case, four NSs or five NSs). In our example of
Figure 5, scaling to the size of the liver in a man of 14.5 cm, the GA determines the zones in which to inject the sensors in a specific sick patient. A bigger data volume would reveal a more precise zone, but a greater amount of NSs is required.
As shown in
Table 7, we conducted a test for a group of patients from the dataset [
37] with liver diseases. We see that the minimum number of NSs required by a patient is three, but for the vast majority, five NS is enough to follow the state of their diseased livers.
In general, for a patient with more complex liver disease, a more accurate view of the liver is required (involves more NSs). With more NSs, a more precise view of the liver can be obtained (more areas can be monitored) to follow all the damaged parts of the liver.
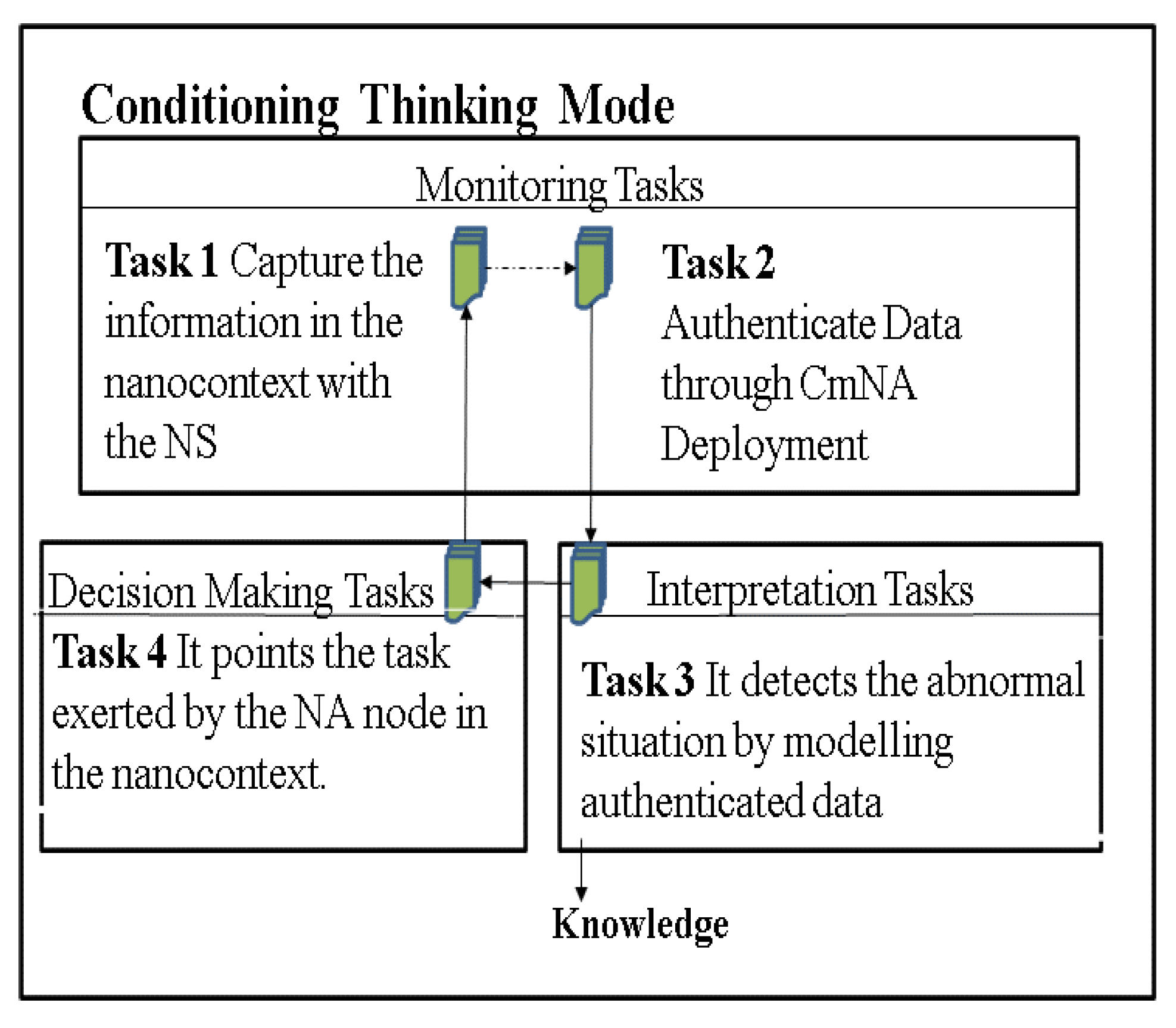
Consequently, task 4 of the CTM AC determines the NSs to be injected and in which areas of the liver. Task 4 continues to observe the liver, and if it determines that it must recalculate the NSs, then it does so in the next iteration.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}