
Closed-Loop Cognitive-Driven Gain Control of Competing Sounds Using Auditory Attention Decoding


Abstract
:1. Introduction
2. Methods
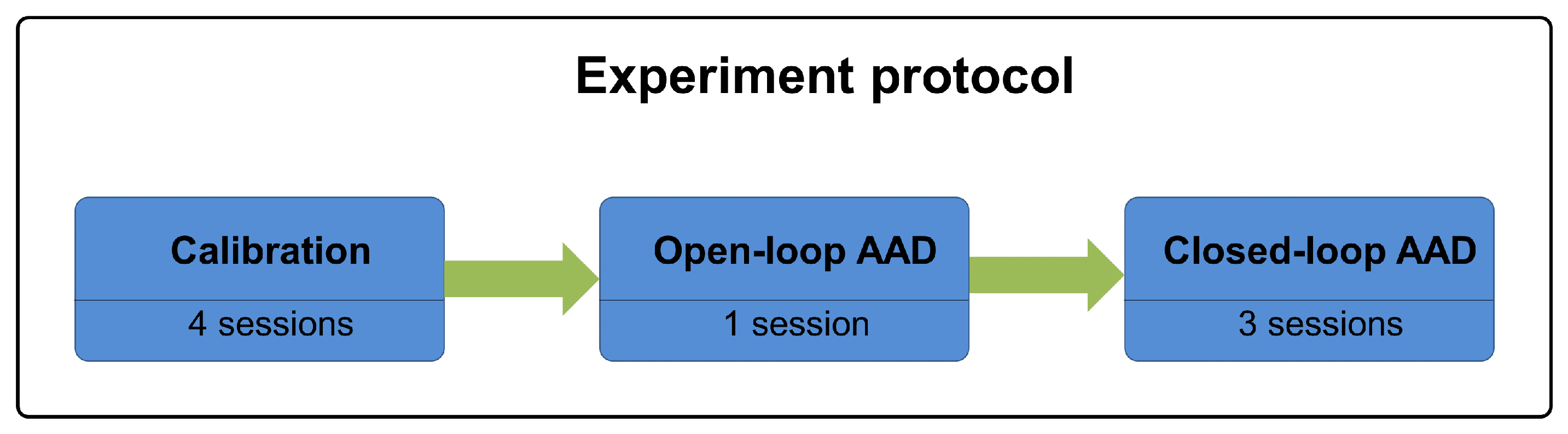
2.1. Experiment Protocol
2.1.1. Calibration Phase
2.1.2. Open-Loop AAD Phase
- LW–GLM: AAD algorithm using a generalized linear model (GLM) with a large correlation window (LW) of 15 s.
- LW–SSM: AAD algorithm using a state-space model (SSM) with a large correlation window (LW) of 15 s.
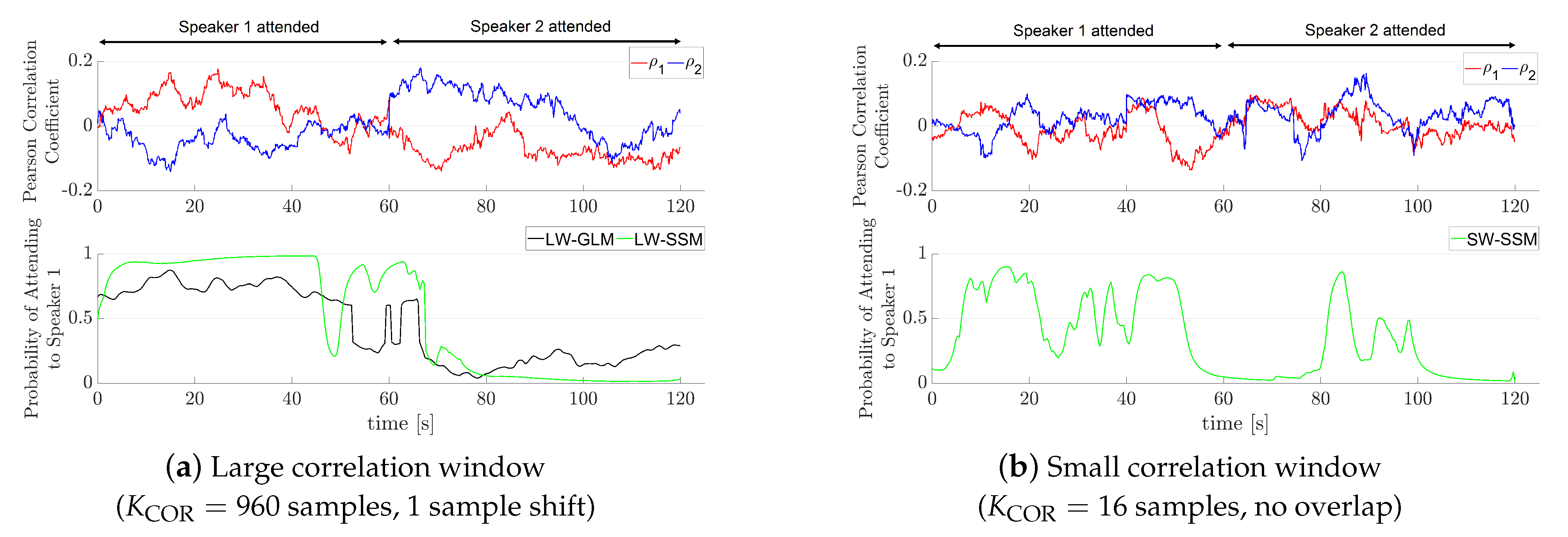
- SW–SSM: AAD algorithm using a state-space model with a small correlation window (SW) of s. Using a small correlation window was motivated by the results in Reference [9], where it was shown that the state-space model is able to translate highly fluctuating coefficients of the spatio-temporal envelope estimators into reliable probabilistic attention measures.
2.1.3. Closed-Loop AAD Phase
2.2. Participants
2.3. Stimuli
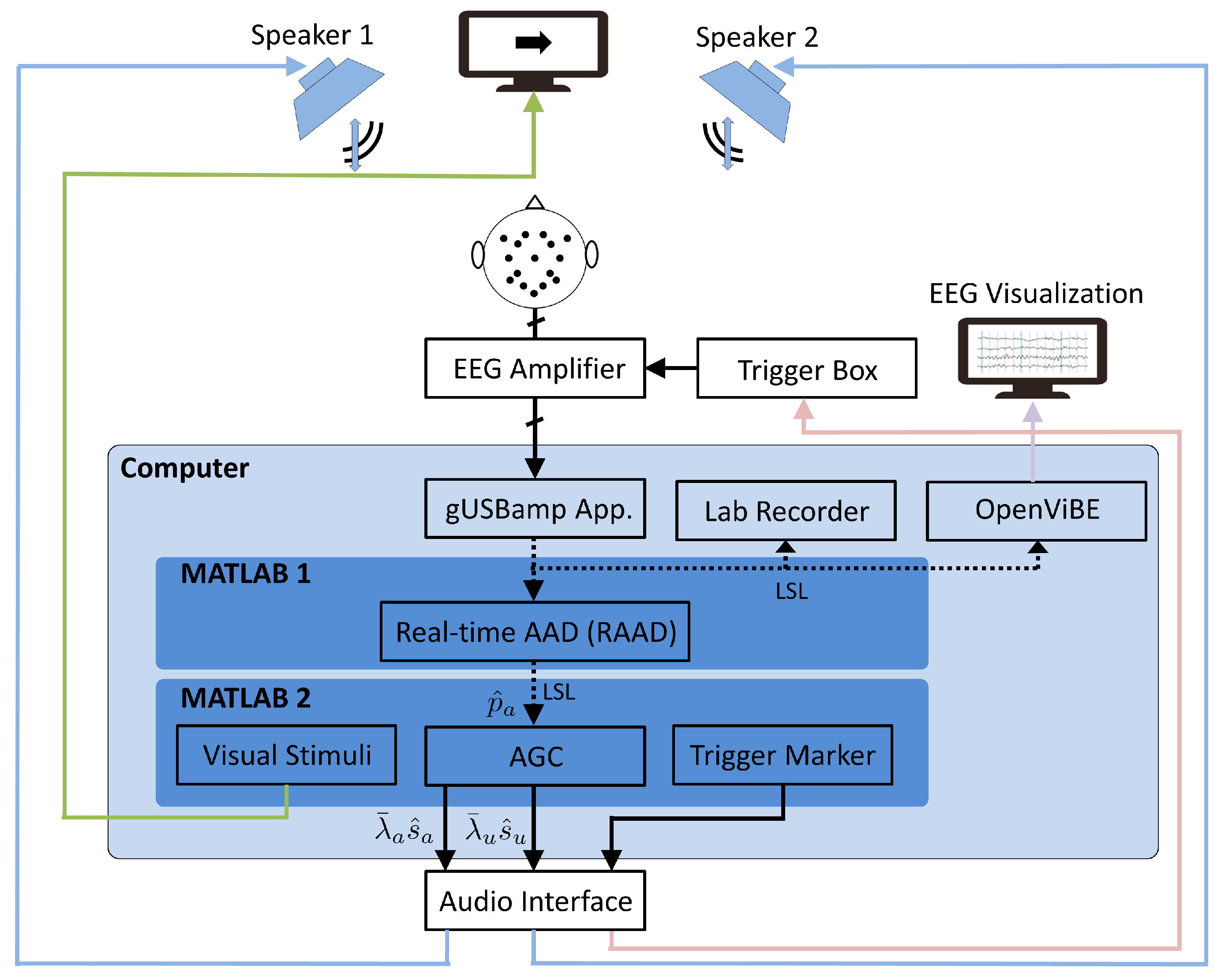
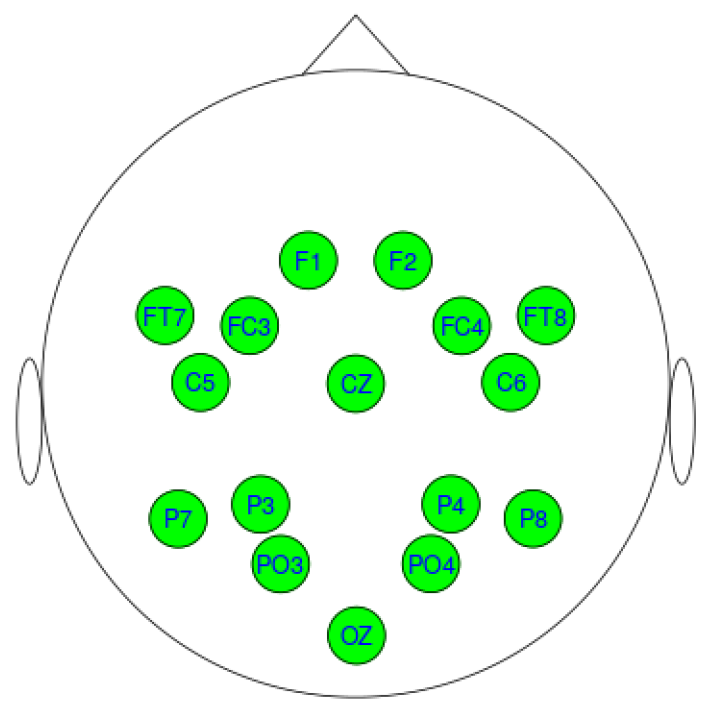
2.4. Data Acquisition
2.5. Cognitive-Driven Gain Controller System
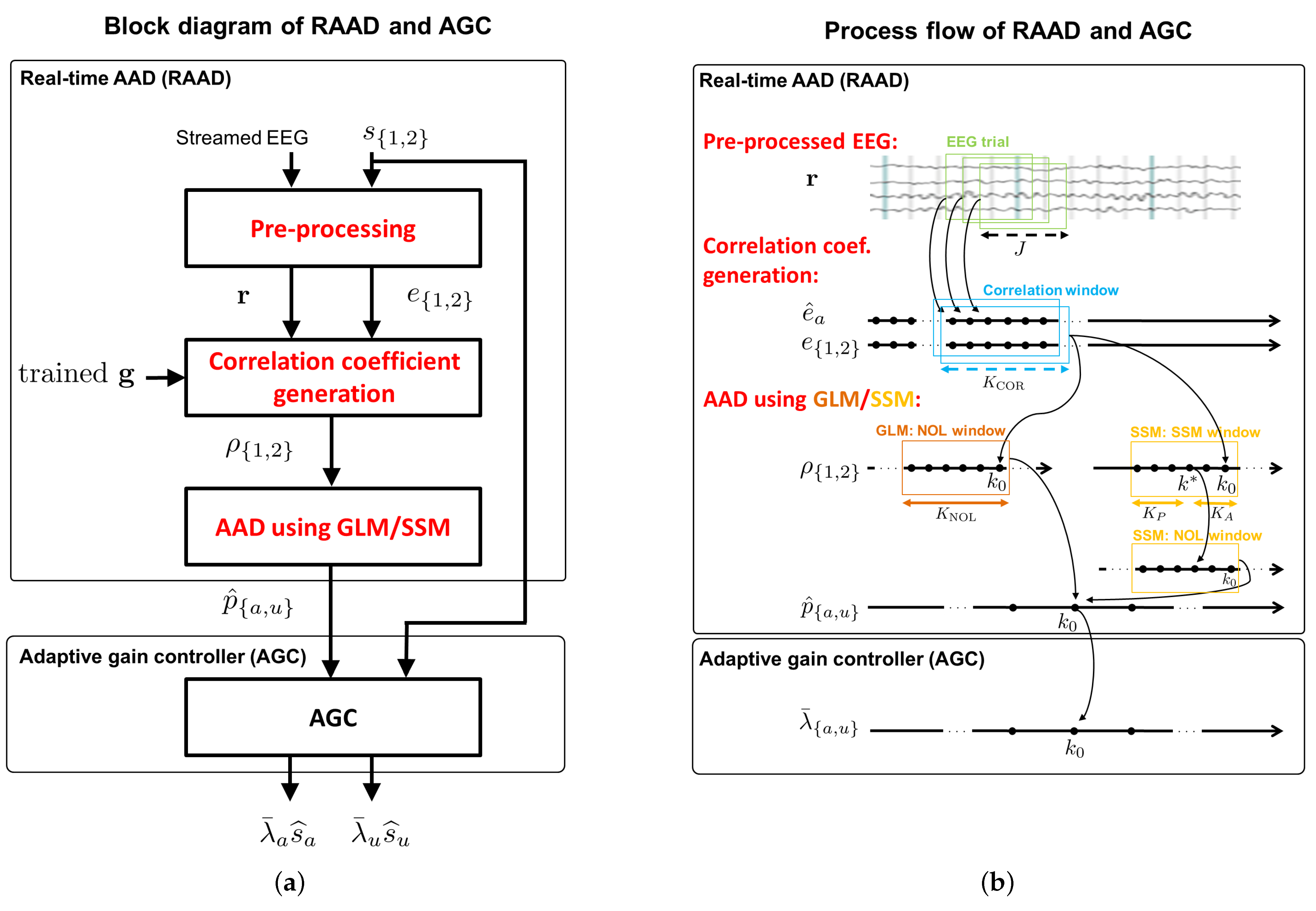
2.5.1. Real-Time Auditory Attention Decoding (RAAD)
- A.
- Pre-Processing:The streamed EEG responses from the gUSBamp application were re-referenced to a common average reference, band-pass filtered between Hz and 9 Hz using a fourth-order Butterworth band-pass filter, and, subsequently, downsampled to 64 Hz in an online fashion. Contrary to the online EEG pre-processing, the speech pre-processing was performed in an offline fashion, since the speech signal of speaker 1 and the speech signal of speaker 2, with t the discrete time index for , are available. The envelopes of both speech signals and , with k the sub-sampled time index for , were obtained using a Hilbert transform, followed by low-pass filtering at 9 Hz and downsampling to 64 Hz. The pre-processed EEG responses and the speech envelopes were then provided in an online fashion to the correlation coefficient generation block.
- B.
- Correlation Coefficient Generation:To generate the correlation coefficients of speaker 1 and speaker 2, we adopted the least-squares-based AAD method from Reference [3], which estimates the attended speech envelope from the EEG responses using a spatio-temporal envelope estimator trained during the calibration phase.
- (1)
- Training step (calibration phase): In the training step, the attended speaker is assumed to be known. The attended speech envelope is then estimated from the pre-processed EEG responses , with c the electrode index for , using a spatio-temporal envelope estimator [3], i.e.,withwhere J denotes the number of envelope estimator coefficients per electrode. The trained envelope estimator is obtained by minimizing the least-squares error between the (known) attended speech envelope and the reconstructed envelope , regularized with the squared norm of the derivative of the envelope estimator coefficients to avoid over-fitting [3,14,29], i.e.,with denoting the derivative matrix [14] and denoting a regularization parameter. The solution of (6) is equal towith the correlation matrix and the cross-correlation vector given by
- (2)
- Correlation coefficient generation step (open-loop and closed-loop AAD phase): To generate the correlation coefficients of speaker 1 and speaker 2, we compute the Pearson correlation coefficients between the estimated attended envelope in (1) and the speech envelopes and , i.e.,where denotes the stacked vector of estimated attended envelopes corresponding to a correlation window of length , i.e.,and and are defined similarly as in (10).
In the training step, the pre-processed EEG responses obtained from the calibration phase were segmented into trials of length 15 s, shifted by 1 sample (corresponding to s). The parameters J and of the envelope estimator in (3) and (7) were determined for each participant using a leave-one-trial-out cross-validation approach, similarly as in References [3,14]. Using these parameters, a trained spatio-temporal envelope estimator in (7) was then computed for each participant using all trials from the calibration phase.In the correlation coefficient generation step, the pre-processed EEG responses were segmented in the same way as in the training step. The correlation coefficients and in (9) were computed either using a large correlation window of length samples (corresponding to 15 s) with an overlap of 959 samples or using a small correlation window of length samples (corresponding to s) with no overlap. In References [4,7,9,18], it has been shown that the performance of AAD algorithms is affected by fluctuations of the correlation coefficients. In this paper, we propose two methods (GLM and SSM) to translate the fluctuating correlation coefficients into more reliable probabilistic attention measures. - C.
- Auditory Attention Decoding Using Generalized Linear Model:The AAD algorithm using the GLM consists of a training and a decoding step. The training step takes place during the calibration phase, whereas the decoding step takes place during the open-loop and the closed-loop AAD phase.
- (1)
- Training step: The correlation coefficients of speaker 1 and speaker 2 in (9) are first segmented into non-overlapping (NOL) windows of length , i.e.,with i the window index for . The mean differential correlation coefficient between speaker 1 and speaker 2 in window i is computed asWe model the attention state in window i as a binary random variable [30], i.e.,which is assumed to follow a Bernoulli distribution with probability , i.e.,Using a GLM, the probability of attending to speaker 1 is then given by [31]with the linear predictor , i.e.,where and denote the GLM parameters. Obviously, the probability of attending to speaker 1 monotonically increases from 0 to 1 for .The probability mass function in (15) can be written as an exponential distribution using the canonical link function , with , i.e.,withThe maximum likelihood (ML) estimate of the GLM parameters in (19) is then obtained by maximizing the log-likelihood function, i.e.,This estimate can be computed, for example, by using an iteratively re-weighted least-squares algorithm and Newton–Raphson method [32,33], i.e.,with r the iteration index andwhere denotes the derivative operator. Algorithm 1 summarizes the GLM parameter estimation in the training step.
Algorithm 1: GLM Training input: and for output: - (2)
- Decoding step: To decode which speaker a participant is attending to in window i, the mean differential correlation coefficient is computed using (13), based on which the linear predictor is computed using the (trained) GLM parameters in (17). The probability of attending to speaker 1, i.e., , and the probability of attending to speaker 2, i.e., , are then obtained using (16). Based on these probabilities, it is decided that the participant attended to speaker 1 if , or attended to speaker 2 otherwise.The probabilistic attention measure of the attended speaker in window i is, hence, determined asObviously, the probabilistic attention measure of the attended speaker lies between and 1. The probabilistic attention measure of the unattended speaker is determined as . The process flow of AAD using the GLM is depicted in Figure 4.
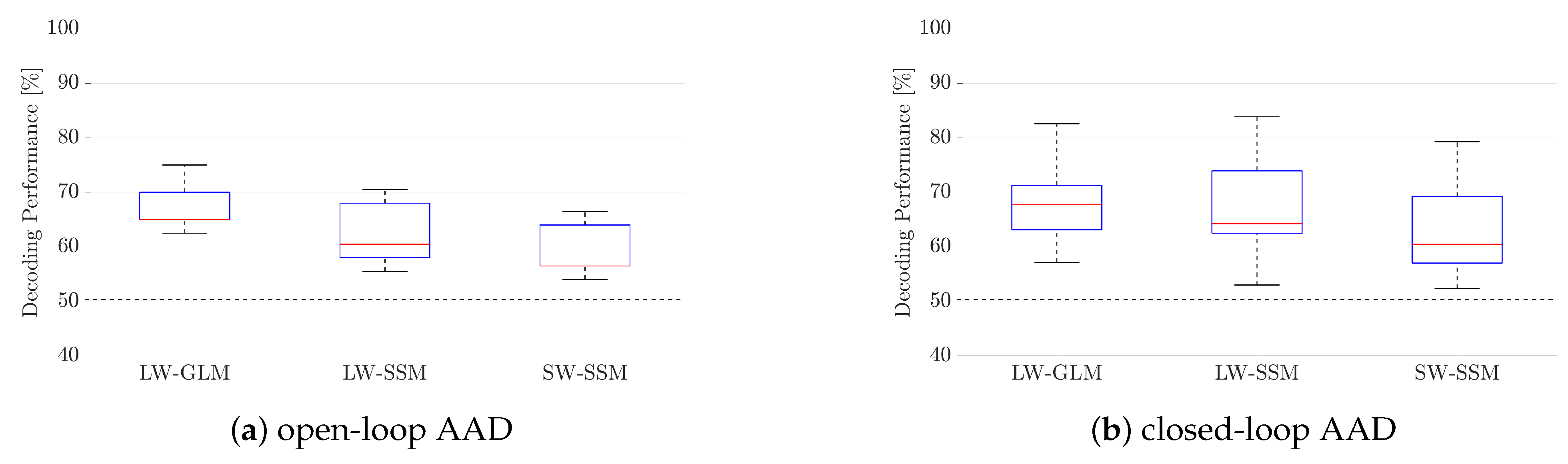
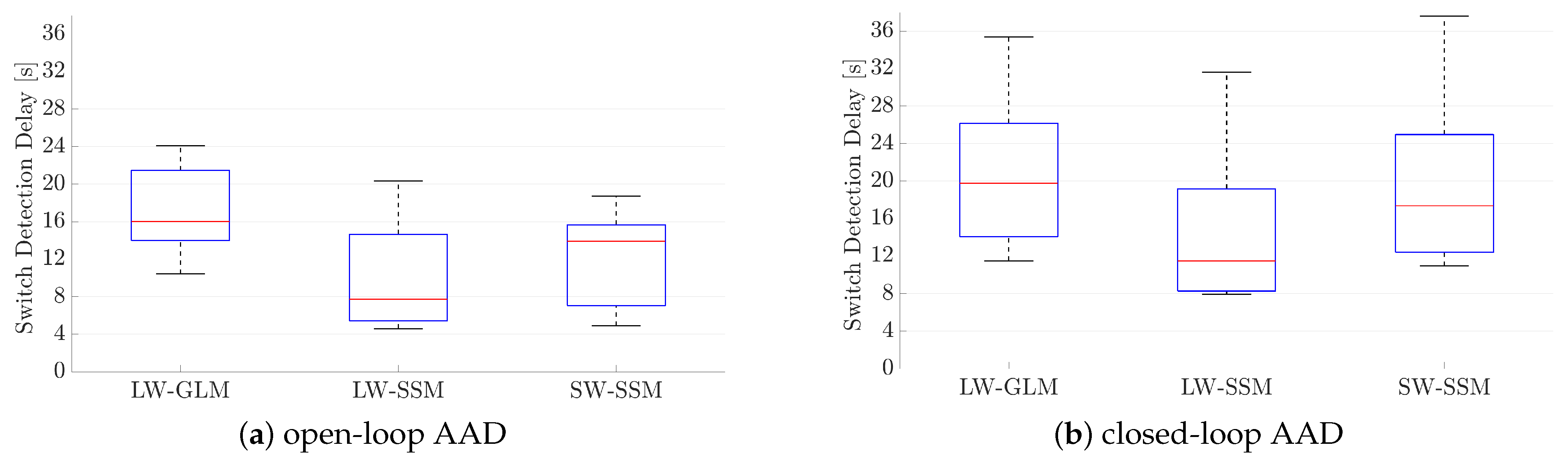
The AAD algorithm using the GLM was implemented and run using MATLAB (MATLAB 1 of RAAD in Figure 2). For the training step, Algorithm 1 was executed with iterations using the correlation coefficients obtained from the calibration phase. Both for the training and the decoding steps, the correlation coefficients were computed using the large correlation window (i.e., samples) and the mean differential correlation coefficient in (13) was computed using a window of length samples (corresponding to s). During the decoding step, the probabilistic attention measures and were forwarded to the AGC using the LSL software package (see Figure 2). Each participant’s own data were used for training the GLM parameters and for decoding. To evaluate the performance of the proposed LW–GLM algorithm, the decoding performance for each participant was computed as the percentage of correctly decoded NOL windows. To evaluate the delay to detect a cued attention switch of the proposed LW–GLM algorithm, the delay was computed as the time takes for the LW–GLM algorithm to detect an attention switch after the moment the arrow on a screen cued to switch attention. - D.
- Auditory Attention Decoding Using State-Space Model:As an alternative to the GLM, it has been proposed in Reference [9] to use a SSM to translate the absolute values of the coefficients of the spatio-temporal envelope estimator into probabilistic attention measures. Contrary to Reference [9], in this paper, we propose to use the absolute values of the correlation coefficientsinstead of the coefficients of the spatio-temporal envelope estimator, which need to be obtained for both the attended and the unattended speaker.Similarly to (14), we model the attention state at time instance k as a binary random variable, i.e.,which is assumed to follow a Bernoulli distribution with probability . Similarly to (16), the probability of attending to speaker 1 is given bywhere the variable is now modeled as an autoregressive (AR) process, i.e.,The parameter is a hyperparameter ensuring stability of the AR process, and the noise process is assumed to follow a normal distribution with variance , i.e.,where and are hyperparameters. The AR model in (35) implies that the variable at time instance k is predicted from at the previous time instance with some uncertainty, which is modeled by the noise process .To relate the correlation coefficients and in (9) to the attention state , we model the probability of the absolute values of the correlation coefficients, given attention to speaker 1 or speaker 2, using a log-normal distribution (Please note that modeling the probabilities of the absolute values of the correlation coefficients with log-normal distributions allows for a closed-form iterative solution [9], compared to modeling the probabilities of the correlation coefficients either with normal or von Mises-Fisher distributions [30].), i.e.,withwhere , and denote the hyperparameters of the attended log-normal distribution. Similarly, we model the probability of the absolute values of the correlation coefficients, given no attention to speaker 1 or speaker 2, aswithwhere , , and denote the hyperparameters of the unattended log-normal distribution. Since a small overlap between the attended and the unattended log-normal distributions is desired for a reliable decoding performance, the hyperparameters , , and are tuned to minimize the overlap.Aiming at estimating the probability of attending to speaker 1 and speaker 2 at time instance (see Figure 4), we now consider the absolute values of the correlation coefficients within a sliding window of length , with and denoting the number of correlation coefficients prior to and after , respectively. The set of parameters to be estimated in this window is given by . The maximum a posteriori (MAP) estimate is obtained by maximizing the log-posterior function, i.e.,which can be computed iteratively using the Expectation Maximization (EM) algorithm as in References [9,30].Using the estimated variable , the probability of attending to speaker 1 at time instance k is obtained using (34). These probabilities are segmented into non-overlapping windows of length , i.e.,and the probability of attending to speaker 1 in window i is then computed as the mean of the probabilities, i.e.,with the attention state in window i. The probability of attending to speaker 2 in window i is computed asBased on these probabilities, it is decided that the participant attended to speaker 1 if , or attended to speaker 2 otherwise.The probabilistic attention measure of the attended speaker in window i is, hence, determined asThe probabilistic attention measure of the unattended speaker is determined as . The process flow of AAD using the SSM is depicted in Figure 4.The AAD algorithm using the SSM was implemented and run using MATLAB (MATLAB 1 of RAAD in Figure 2). The hyperparameters in (35) and (37) were set to , and , similarly as in Reference [9]. The hyperparameters , and in (39) were set by fitting a gamma and a normal distribution to the absolute values of the correlation coefficients of the (oracle) attended speaker obtained from the calibration phase. Similarly, the hyperparameters , , and in (41) were set by fitting a gamma and a normal distribution to the absolute values of the correlation coefficients of the (oracle) unattended speaker obtained from the calibration phase. The SSM parameter set was estimated using the EM algorithm as in Reference [9] with 20 iterations. On the one hand, for the LW–SSM algorithm using a large overlapping correlation window (i.e., samples, 1 sample shift), a small SSM window of length sample (corresponding to s) with and was used. On the other hand, for the SW–SSM algorithm using a small non-overlapping correlation window (i.e., samples), a large SSM window of length samples (corresponding to 15 s) with (corresponding to s) and (corresponding to s) was used as in Reference [9]. The length of the window in (43) was set such that both algorithms generated the probabilistic attention measure of the attended speaker in (46) every s. This means that for the LW–SSM algorithm a window of length samples was used, while, for the SW–SSM algorithm, a window of length sample was used. Each participant’s own data were used for hyperparameter and parameter setting, as well as for decoding. To evaluate the performance of the proposed LW–SSM and SW–SSM algorithms, the decoding performance for each participant was computed as the percentage of correctly decoded NOL windows. To evaluate the delay to detect a cued attention switch of the proposed LW–SSM and SW–SSM algorithms, the delay was computed as the time takes for the LW–SSM and SW–SSM algorithms to detect an attention switch after the moment the arrow on a screen cued to switch attention.
2.5.2. Adaptive Gain Controller (AGC)
3. Results
3.1. Auditory Attention Decoding Performance
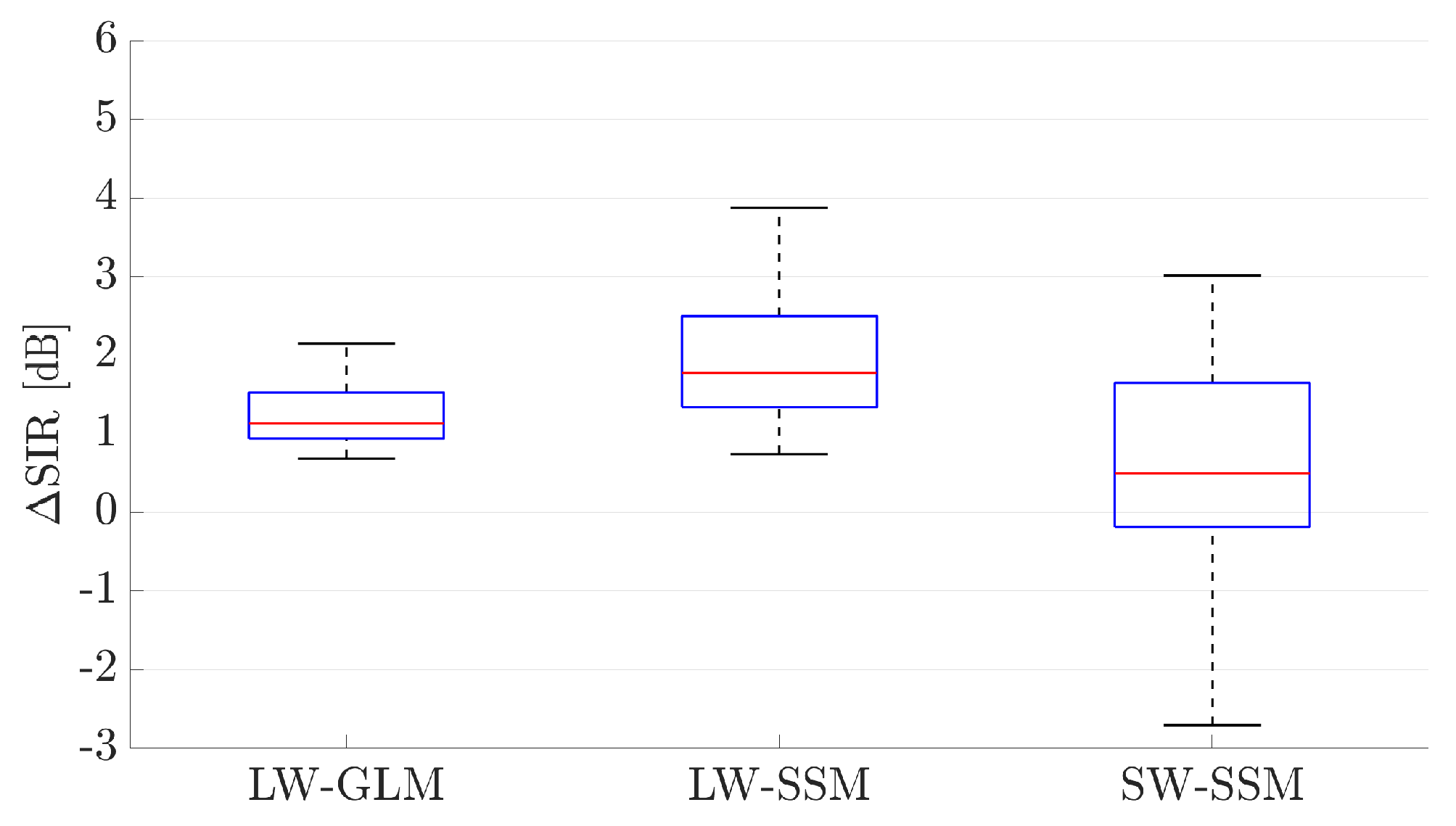
3.2. Signal-to-Interference Reduction of Adaptive Gain Controller
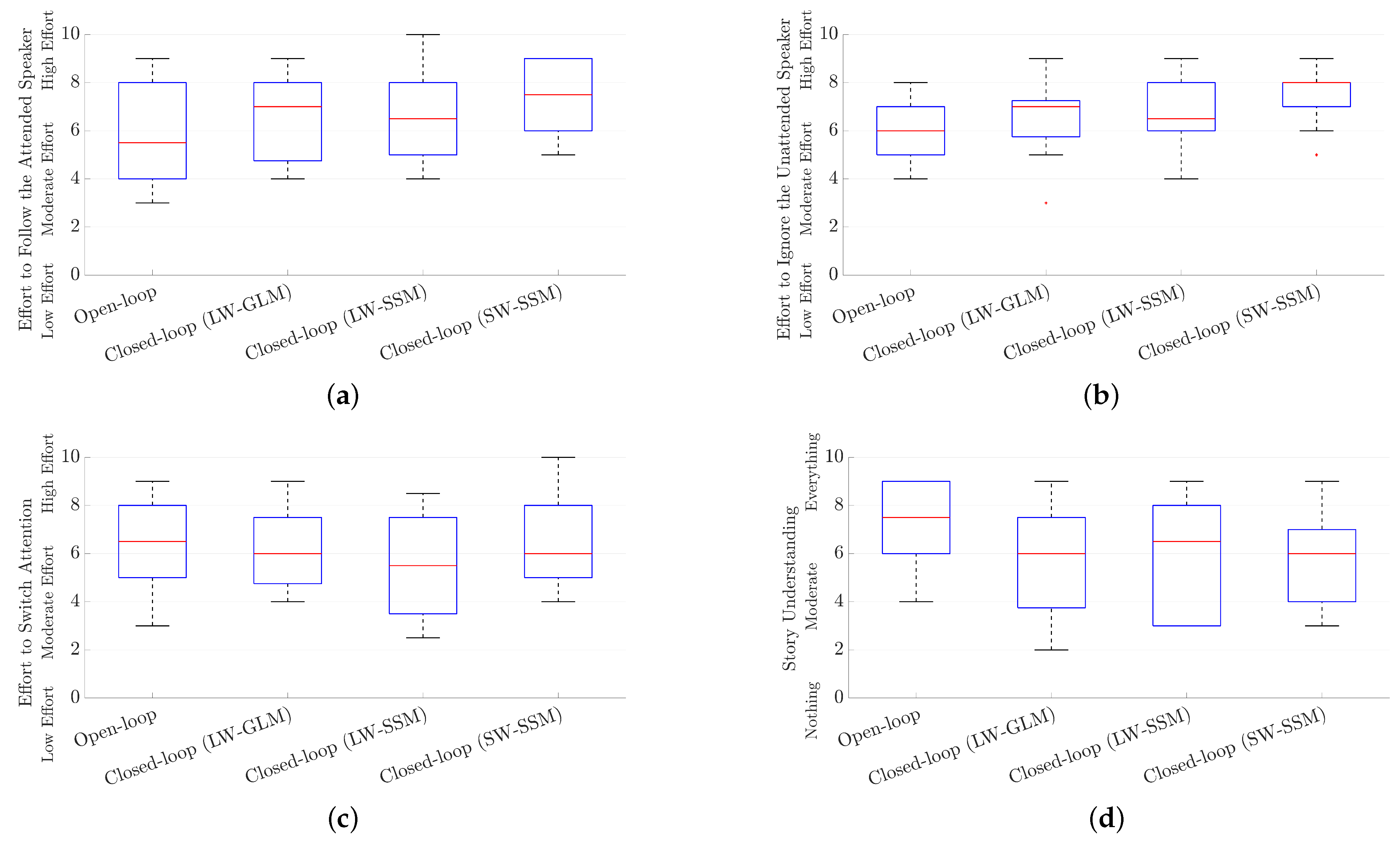
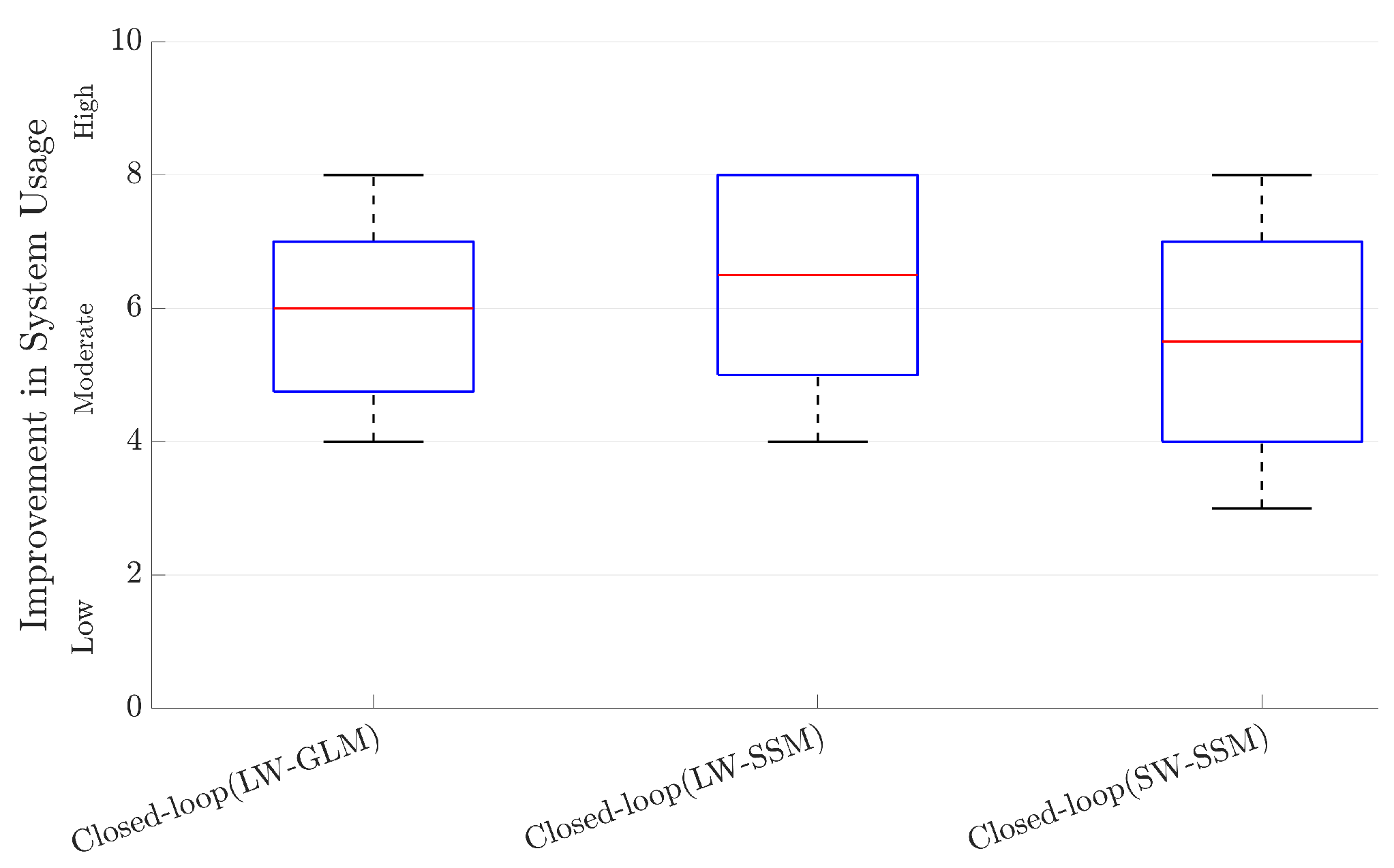
3.3. Subjective Evaluation of Open-Loop and Closed-Loop AAD
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Doclo, S.; Kellermann, W.; Makino, S.; Nordholm, S.E. Multichannel signal enhancement algorithms for assisted listening devices. IEEE Signal Process. Mag. 2015, 32, 18–30. [Google Scholar] [CrossRef] [Green Version]
- Gannot, S.; Vincent, E.; Markovich-Golan, S.; Ozerov, A. A Consolidated Perspective on Multimicrophone Speech Enhancement and Source Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 692–730. [Google Scholar] [CrossRef] [Green Version]
- O’Sullivan, J.A.; Power, A.J.; Mesgarani, N.; Rajaram, S.; Foxe, J.J.; Shinn-Cunningham, B.G.; Slaney, M.; Shamma, S.A.; Lalor, E.C. Attentional selection in a cocktail party environment can be decoded from single-trial EEG. Cereb. Cortex 2014, 25, 1697–1706. [Google Scholar] [CrossRef] [PubMed]
- Mirkovic, B.; Debener, S.; Jaeger, M.; De Vos, M. Decoding the attended speech stream with multi-channel EEG: Implications for online, daily-life applications. J. Neural Eng. 2015, 12, 46007. [Google Scholar] [CrossRef]
- Zink, R.; Baptist, A.; Bertrand, A.; Van Huffel, S.; De Vos, M. Online detection of auditory attention in a neurofeedback application. In Proceedings of the 8th International Workshop on Biosignal Interpretation, Osaka, Japan, 1–3 November 2016; pp. 1–4. [Google Scholar]
- Fuglsang, S.A.; Dau, T.; Hjortkjær, J. Noise-robust cortical tracking of attended speech in real-world acoustic scenes. NeuroImage 2017, 156, 435–444. [Google Scholar] [CrossRef] [PubMed]
- Wong, D.D.; Fuglsang, S.A.; Hjortkjær, J.; Ceolini, E.; Slaney, M.; de Cheveigné, A. A Comparison of Regularization Methods in Forward and Backward Models for Auditory Attention Decoding. Front. Neurosci. 2018, 12, 531. [Google Scholar] [CrossRef] [Green Version]
- de Cheveigné, A.; Wong, D.D.; Liberto, G.M.D.; Hjortkjær, J.; Slaney, M.; Lalor, E. Decoding the auditory brain with canonical component analysis. NeuroImage 2018, 172, 206–216. [Google Scholar] [CrossRef]
- Miran, S.; Akram, S.; Sheikhattar, A.; Simon, J.Z.; Zhang, T.; Babadi, B. Real-Time Tracking of Selective Auditory Attention From M/EEG: A Bayesian Filtering Approach. Front. Neurosci. 2018, 12, 262. [Google Scholar] [CrossRef]
- Schäfer, P.J.; Corona-Strauss, F.I.; Hannemann, R.; Hillyard, S.A.; Strauss, D.J. Testing the Limits of the Stimulus Reconstruction Approach: Auditory Attention Decoding in a Four-Speaker Free Field Environment. Trends Hear. 2018, 22, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Das, N.; Bertrand, A.; Francart, T. EEG-based auditory attention detection: Boundary conditions for background noise and speaker positions. J. Neural Eng. 2018, 15, 66017. [Google Scholar] [CrossRef]
- de Taillez, T.; Kollmeier, B.; Meyer, B.T. Machine learning for decoding listeners’ attention from electroencephalography evoked by continuous speech. Eur. J. Neurosci. 2018, 51, 1234–1241. [Google Scholar] [CrossRef] [PubMed]
- Alickovic, E.; Lunner, T.; Gustafsson, F.; Ljung, L. A Tutorial on Auditory Attention Identification Methods. Front. Neurosci. 2019, 13, 153. [Google Scholar] [CrossRef] [PubMed]
- Aroudi, A.; Mirkovic, B.; De Vos, M.; Doclo, S. Impact of Different Acoustic Components on EEG-based Auditory Attention Decoding in Noisy and Reverberant Conditions. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 652–663. [Google Scholar] [CrossRef]
- Ciccarelli, G.; Nolan, M.; Perricone, J.; Calamia, P.T.; Haro, S.; O’Sullivan, J.; Mesgarani, N.; Quatieri, T.F.; Smalt, C.J. Comparison of Two-Talker Attention Decoding from EEG with Nonlinear Neural Networks and Linear Methods. Sci. Rep. Nat. 2019, 9, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Teoh, E.S.; Lalor, E.C. EEG decoding of the target speaker in a cocktail party scenario: Considerations regarding dynamic switching of talker location. J. Neural Eng. 2019, 16, 036017. [Google Scholar] [CrossRef]
- Tian, Y.; Ma, L. Auditory attention tracking states in a cocktail party environment can be decoded by deep convolutional neural networks. J. Neural Eng. 2020, 17, 036013. [Google Scholar] [CrossRef]
- Aroudi, A.; de Taillez, T.; Doclo, S. Improving Auditory Attention Decoding Performance of Linear and Non-Linear Methods using State-Space Model. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 8703–8707. [Google Scholar]
- Geirnaert, S.; Vandecappelle, S.; Alickovic, E.; de Cheveigne, A.; Lalor, E.; Meyer, B.T.; Miran, S.; Francart, T.; Bertrand, A. Electroencephalography-Based Auditory Attention Decoding: Toward Neurosteered Hearing Devices. IEEE Signal Process. Mag. 2021, 38, 89–102. [Google Scholar] [CrossRef]
- Van Eyndhoven, S.; Francart, T.; Bertrand, A. EEG-informed attended speaker extraction from recorded speech mixtures with application in neuro-steered hearing prostheses. IEEE Trans. Biomed. Eng. 2017, 64, 1045–1056. [Google Scholar] [CrossRef] [Green Version]
- Dau, T.; Maercher Roersted, J.; Fuglsang, S.; Hjortkjær, J. Towards cognitive control of hearing instruments using EEG measures of selective attention. J. Acoust. Soc. Am. 2018, 143, 1744. [Google Scholar] [CrossRef]
- Han, C.; O’Sullivan, J.; Luo, Y.; Herrero, J.; Mehta, A.D.; Mesgarani, N. Speaker-independent auditory attention decoding without access to clean speech sources. Sci. Adv. 2019, 5, eaav6134. [Google Scholar] [CrossRef] [Green Version]
- Pu, W.; Xiao, J.; Zhang, T.; Luo, Z. A Joint Auditory Attention Decoding and Adaptive Binaural Beamforming Algorithm for Hearing Devices. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 311–315. [Google Scholar]
- Aroudi, A.; Doclo, S. Cognitive-driven binaural beamforming using EEG-based auditory attention decoding. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 862–875. [Google Scholar] [CrossRef]
- Mesgarani, N. Brain-Controlled Hearing Aids for Better Speech Perception in Noisy Settings. Hear. J. 2019, 72, 10–12. [Google Scholar] [CrossRef]
- Hering, E. Kostbarkeiten aus dem Deutschen Märchenschatz. In Audiopool Hörbuchverlag MP3 CD; BUCHFUNK Verlag: Trier, Germany, 2012; ISBN 9783868471175. [Google Scholar]
- Ohrka, H. Ohrka.de-Kostenlose Hörabenteuer für Kinderohren. Accessed Apr 2012, 30, 2015. [Google Scholar]
- Mirkovic, B.; Bleichner, M.G.; De Vos, M.; Debener, S. Target Speaker Detection with Concealed EEG Around the Ear. Front. Neurosci. 2016, 10, 349. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Biesmans, W.; Das, N.; Francart, T.; Bertrand, A. Auditory-Inspired Speech Envelope Extraction Methods for Improved EEG-Based Auditory Attention Detection in a Cocktail Party Scenario. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 402–412. [Google Scholar] [CrossRef] [PubMed]
- Akram, S.; Simon, J.Z.; Babadi, B. Dynamic Estimation of the Auditory Temporal Response Function from MEG in Competing-Speaker Environments. IEEE Trans. Biomed. Eng. 2017, 64, 1896–1905. [Google Scholar] [CrossRef]
- Collett, D. Modeling Binary Data; Chapman and Hall: New York, NY, USA, 2002. [Google Scholar]
- Nelder, J.A.; Wedderburn, R.W.M. Generalized Linear Models. J. R. Stat. Soc. 1972, 135, 370–384. [Google Scholar] [CrossRef]
- Train, K.E. Discrete Choice Methods with Simulation; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Hochberg, Y.; Tamhane, A.C. Multiple Comparison Procedures; John Wiley and Sons: Hoboken, NJ, USA, 1987. [Google Scholar]
- Lu, Y.; Wang, M.; Yao, L.; Shen, H.; Wu, W.; Zhang, Q.; Zhang, L.; Chen, M.; Liu, H.; Peng, R.; et al. Auditory attention decoding from electroencephalography based on long short-term memory networks. Biomed. Signal Process. Control 2021, 70, 102966. [Google Scholar] [CrossRef]
- Geirnaert, S.; Francart, T.; Bertrand, A. Fast EEG-Based Decoding Of The Directional Focus Of Auditory Attention Using Common Spatial Patterns. IEEE Trans. Biomed. Eng. 2021, 68, 1557–1568. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Software/Hardware | Description |
|---|---|
| Lab Streaming Layer (LSL) software 1.12 | Handles the gUSBamp application and the Lab Recorder program |
| gUSBamp application (part of LSL) | Streams EEG responses and EEG trigger markers |
| Lab Recorder program (part of LSL) | Record EEG responses |
| OpenViBE software 2.0 | Visualizes online EEG responses |
| MATLAB 11.2 | Runs RAAD algorithms, AGC algorithm, presents acoustic and visual stimuli via Fireface UC audio interface system, and generates EEG trigger marker |
| gUSBamp Research | Records EEG signals using 16 channel EEG amplifier |
| g.TRIGbox (multi-modal trigger box) | Generates EEG trigger markers synchronized with acoustic and visual stimuli |
| Fireface UC audio interface system | Presents acoustic stimuli |
| Computer | Runs MATLAB, LSL software, and OpenViBE software |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aroudi, A.; Fischer, E.; Serman, M.; Puder, H.; Doclo, S. Closed-Loop Cognitive-Driven Gain Control of Competing Sounds Using Auditory Attention Decoding. Algorithms 2021, 14, 287. https://doi.org/10.3390/a14100287
Aroudi A, Fischer E, Serman M, Puder H, Doclo S. Closed-Loop Cognitive-Driven Gain Control of Competing Sounds Using Auditory Attention Decoding. Algorithms. 2021; 14(10):287. https://doi.org/10.3390/a14100287
Chicago/Turabian StyleAroudi, Ali, Eghart Fischer, Maja Serman, Henning Puder, and Simon Doclo. 2021. "Closed-Loop Cognitive-Driven Gain Control of Competing Sounds Using Auditory Attention Decoding" Algorithms 14, no. 10: 287. https://doi.org/10.3390/a14100287