I3D-Shufflenet Based Human Action Recognition

Abstract
:1. Introduction
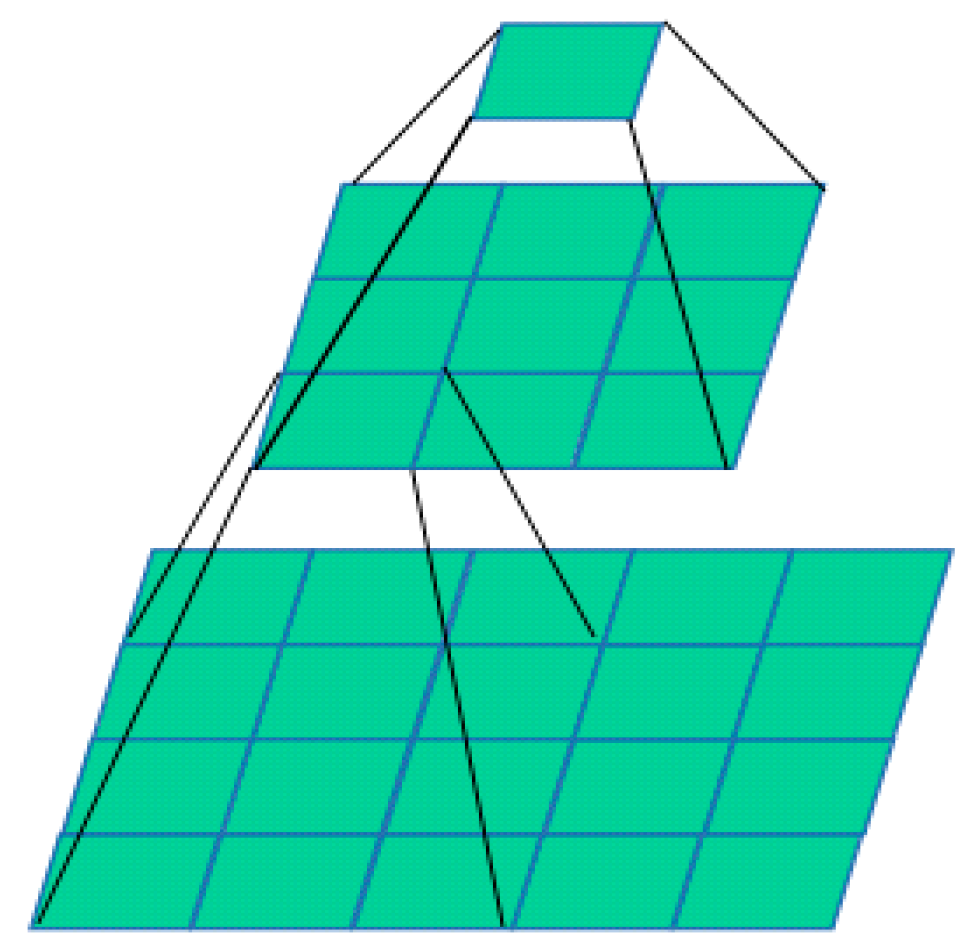
2. 3D Convolutional Network
3. I3D-Shufflenet
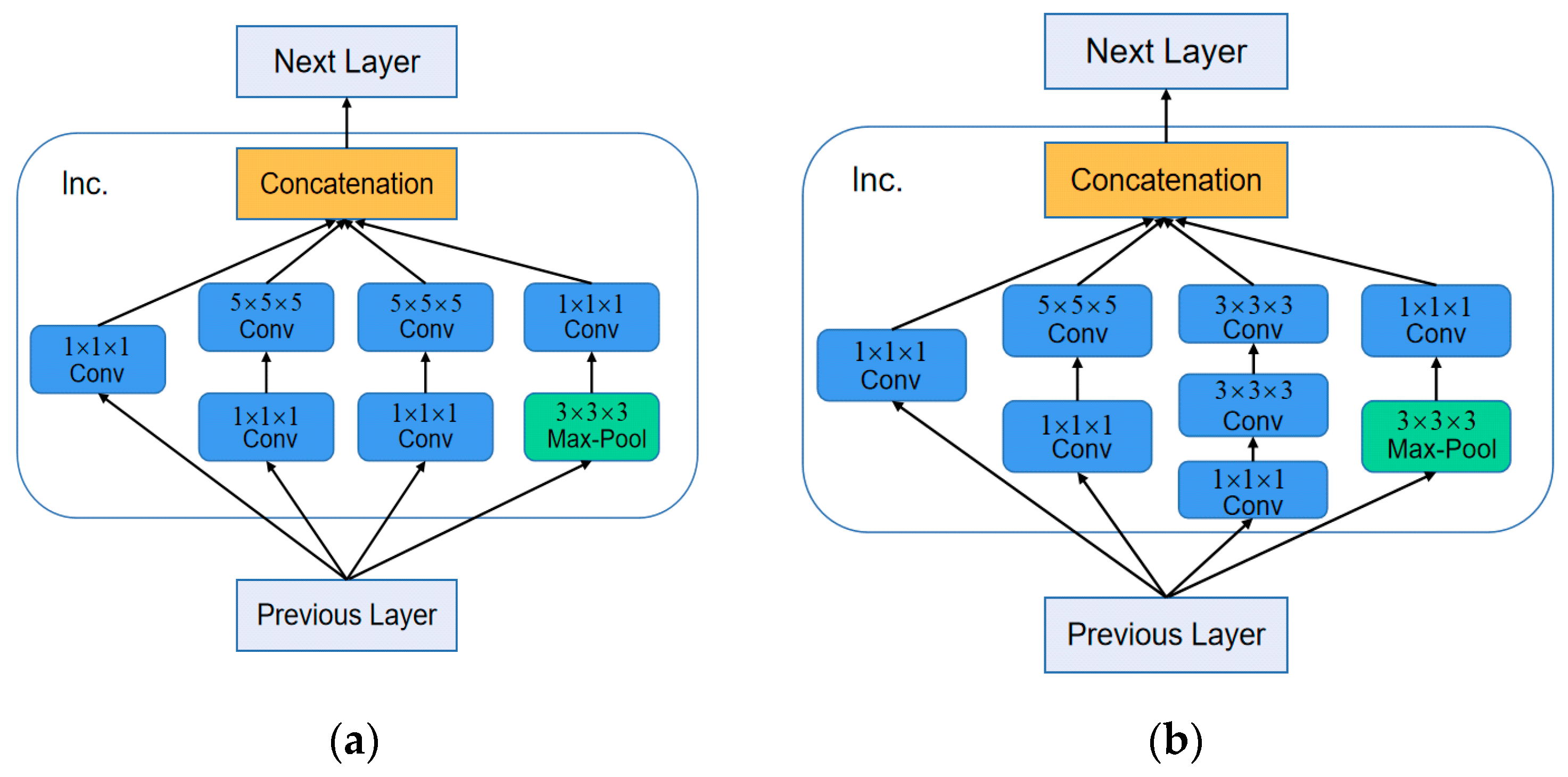
3.1. 3D Convolution Kernel Design
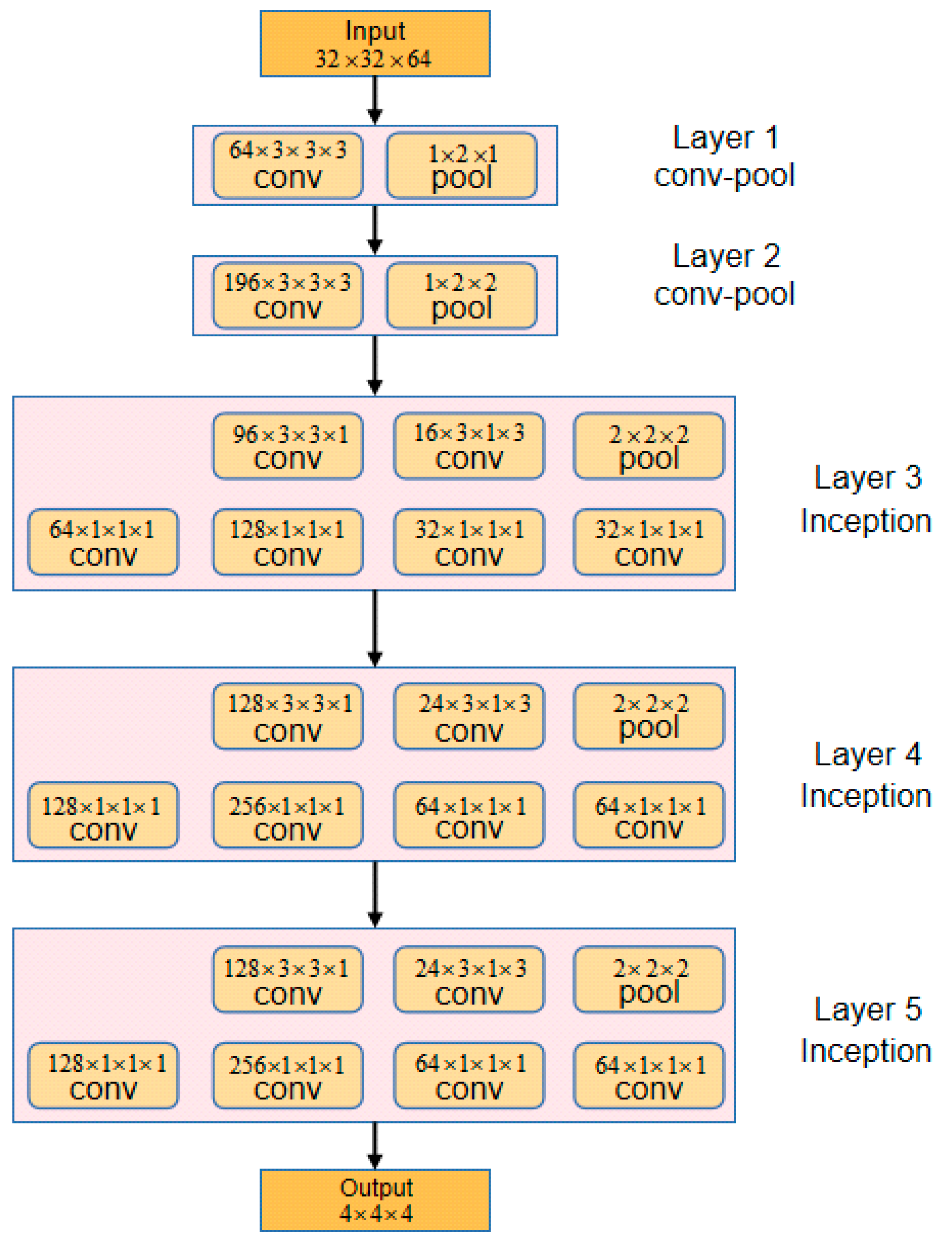
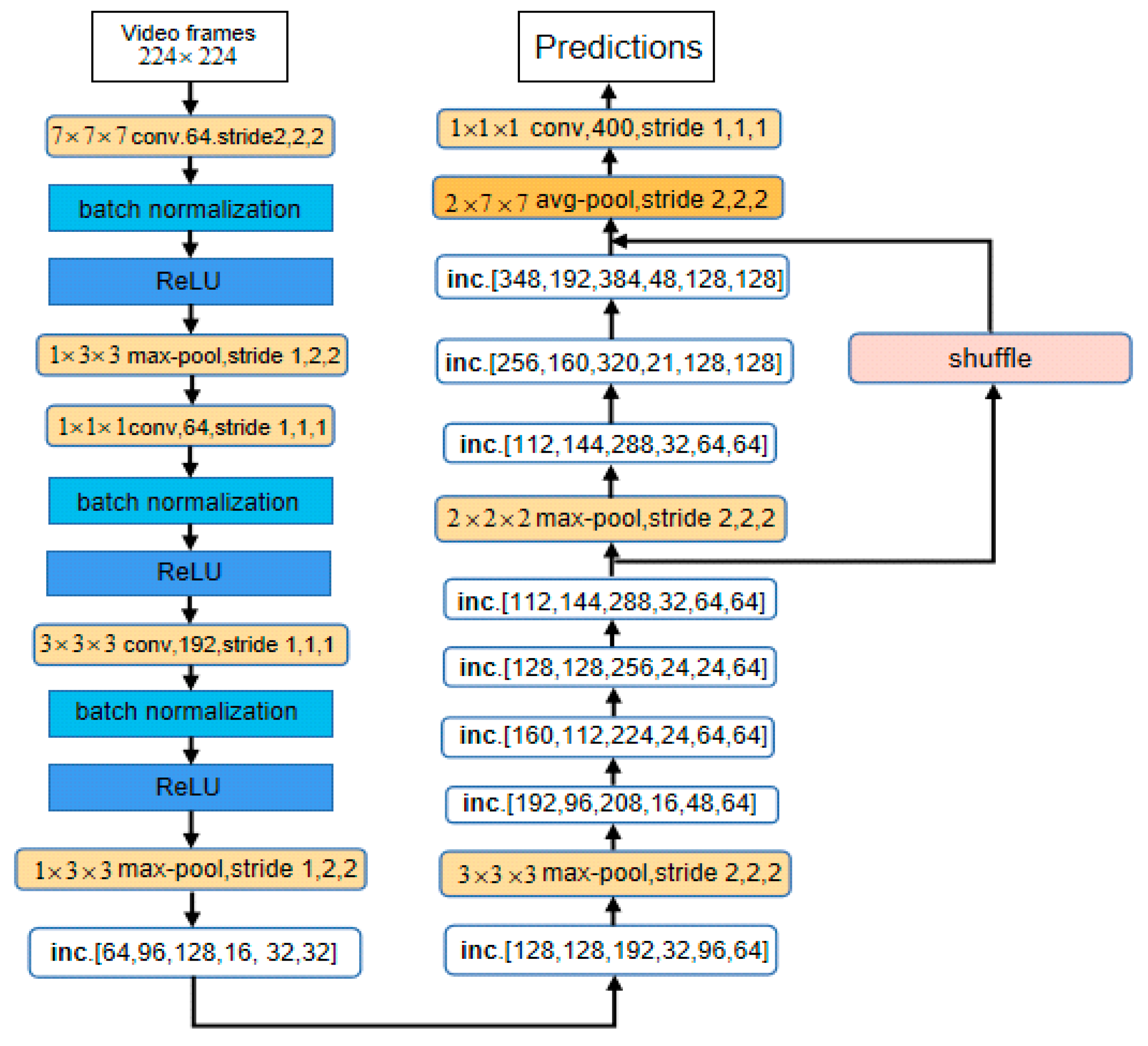
3.2. I3D-Shufflenet Network Framework
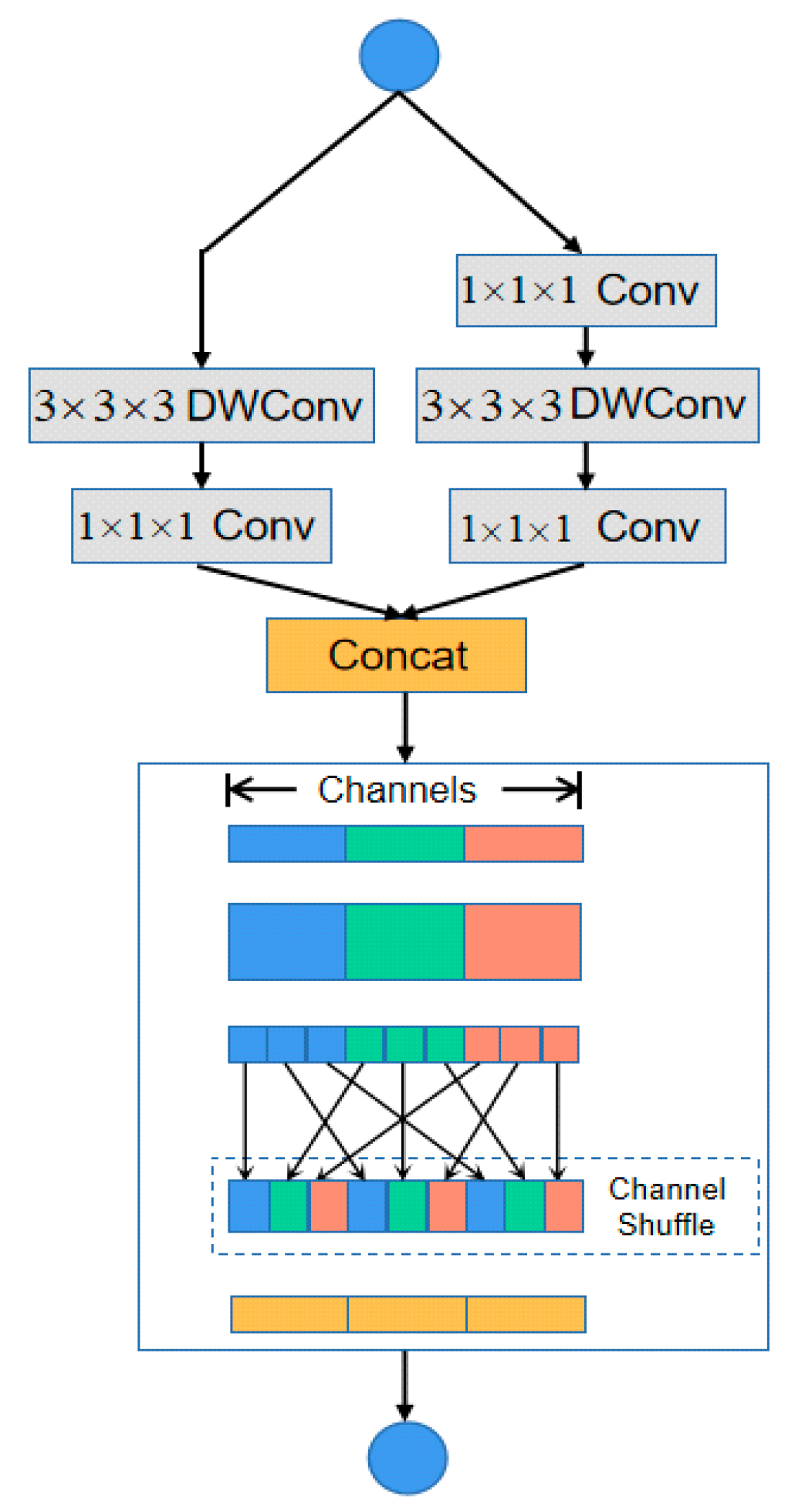
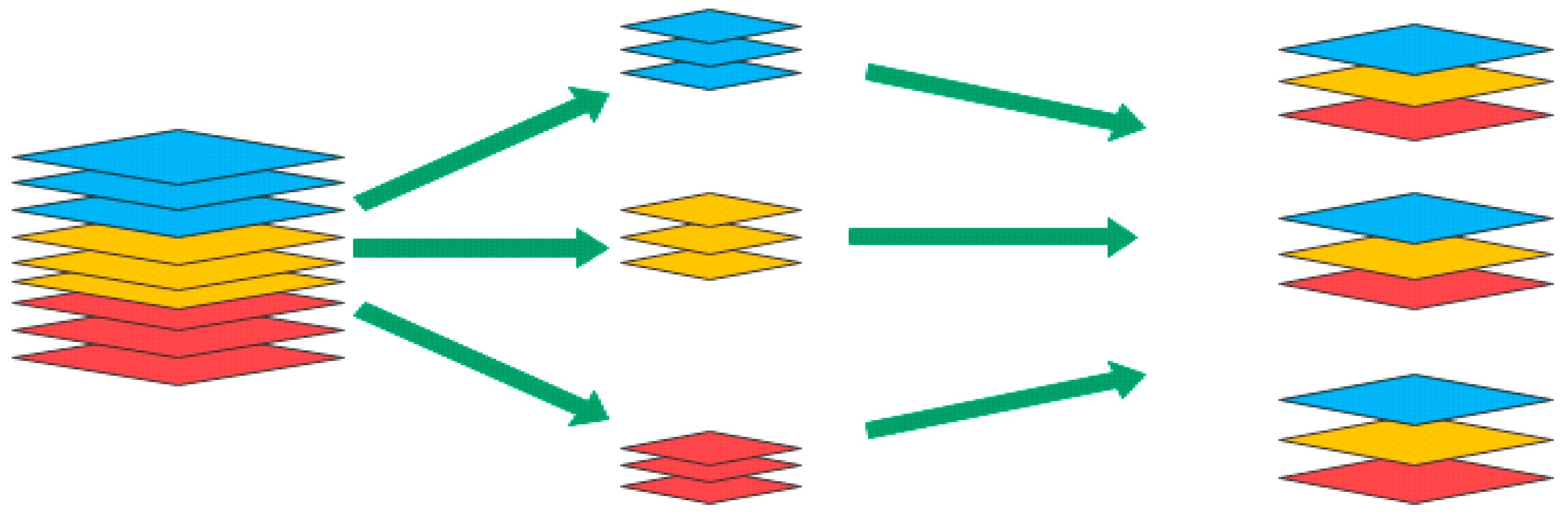
3.2.1. Channel Shuffle
3.2.2. I3D-Shufflenet Structure
4. Experiment
4.1. Data Set for Behavior Recognition
4.2. Hyperparameter Settings
4.3. Channel Shuffle
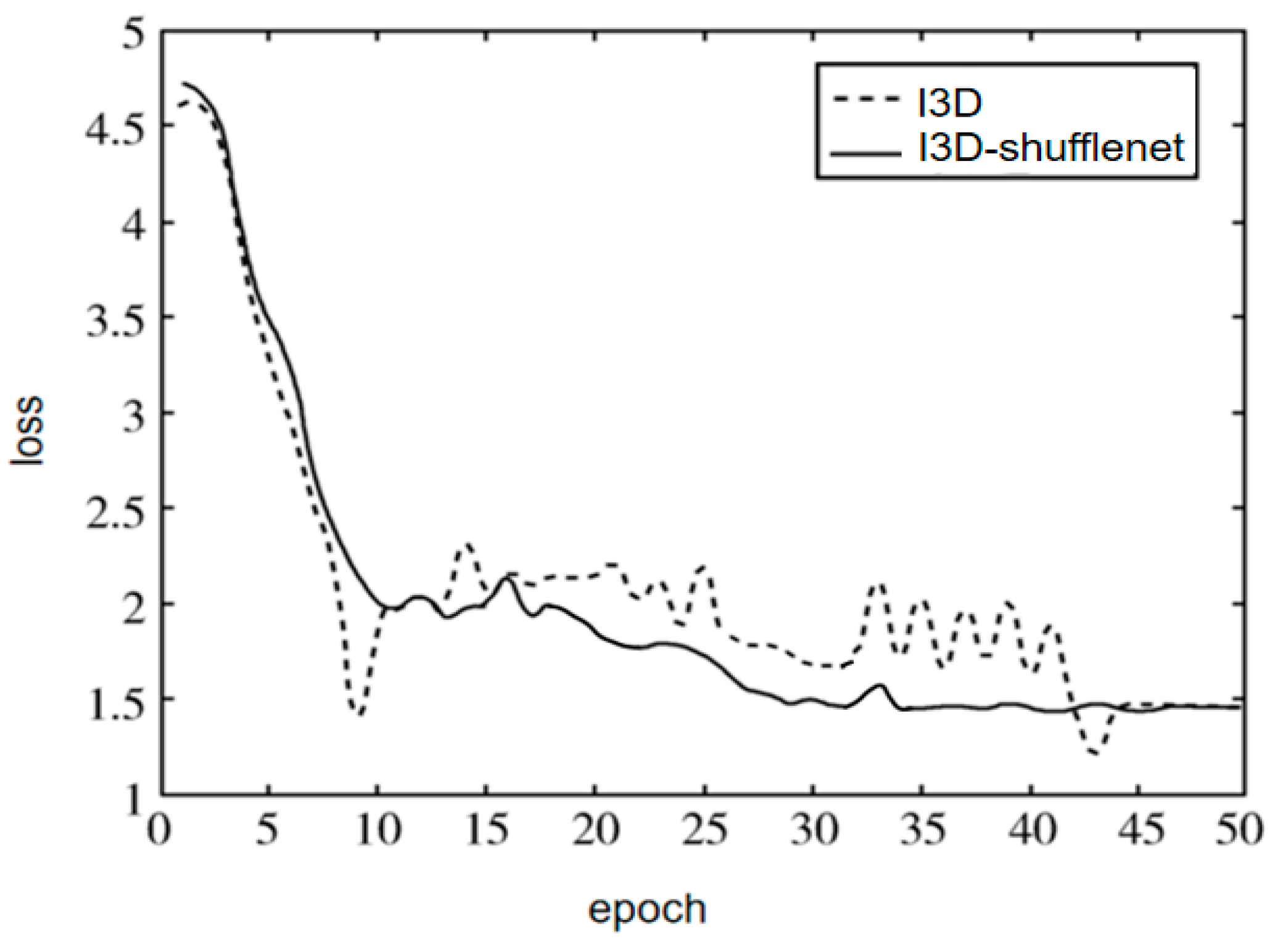
4.4. Loss Function
4.5. Learning Rate Setting
4.6. Feature Map Output
4.7. Class Activation Mapping
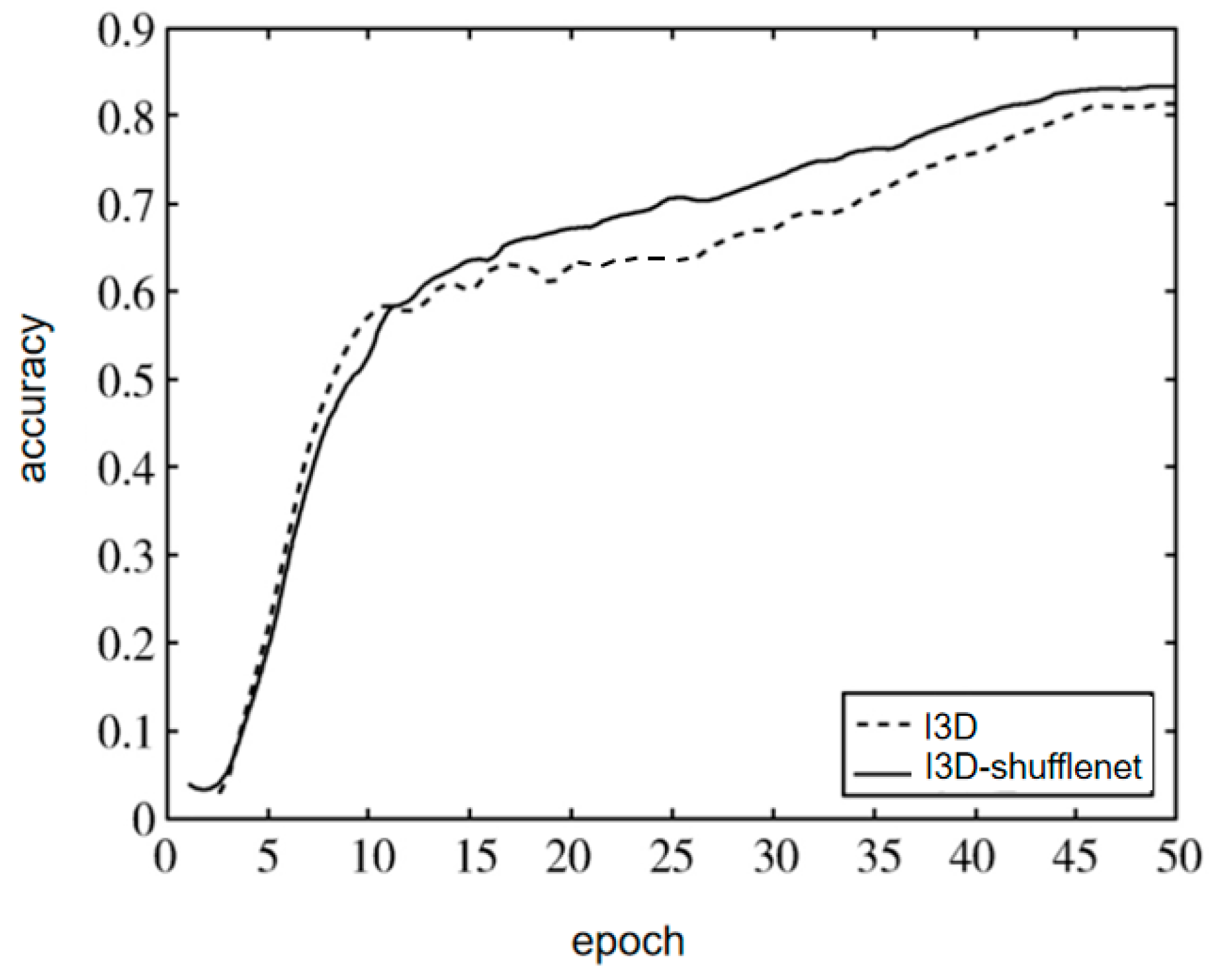
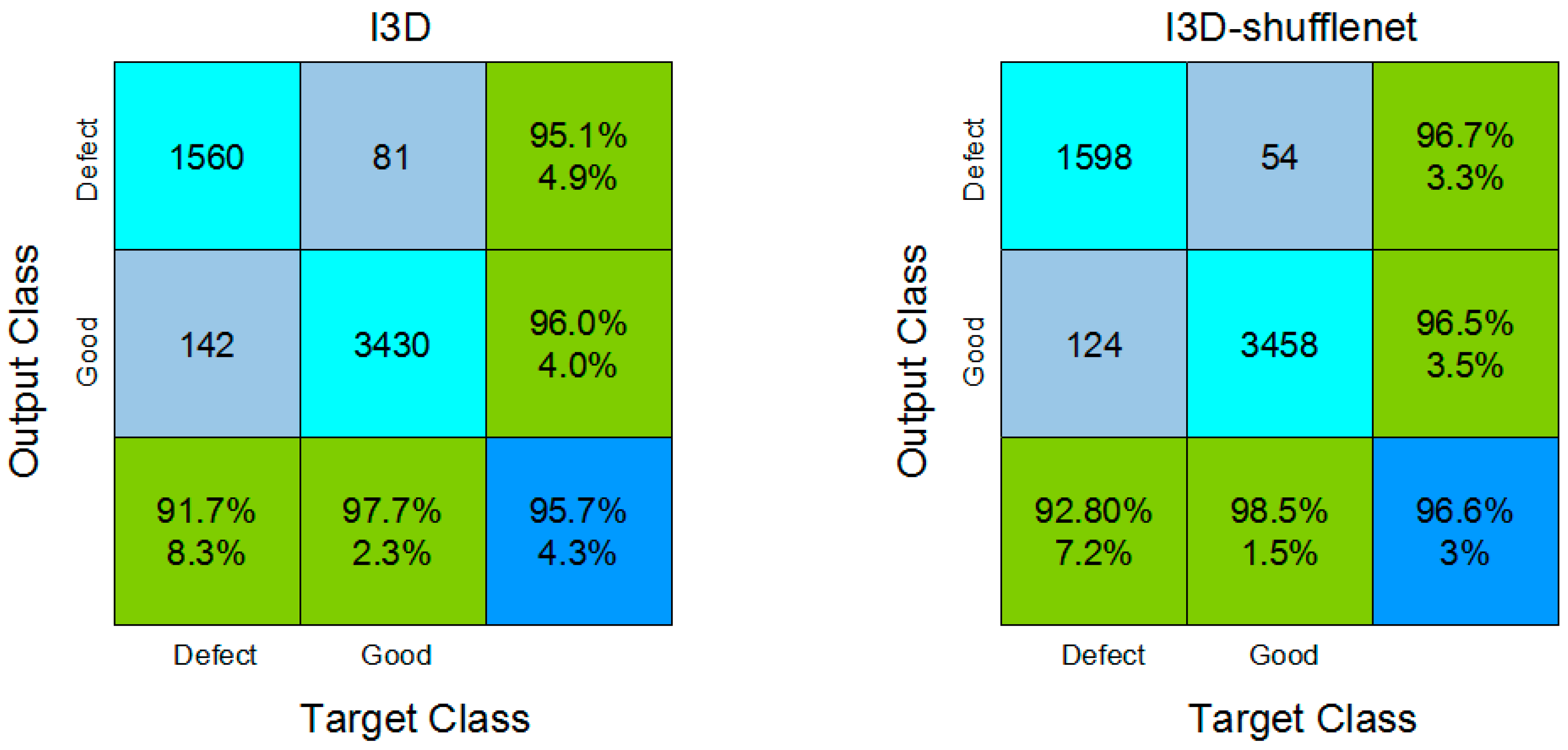
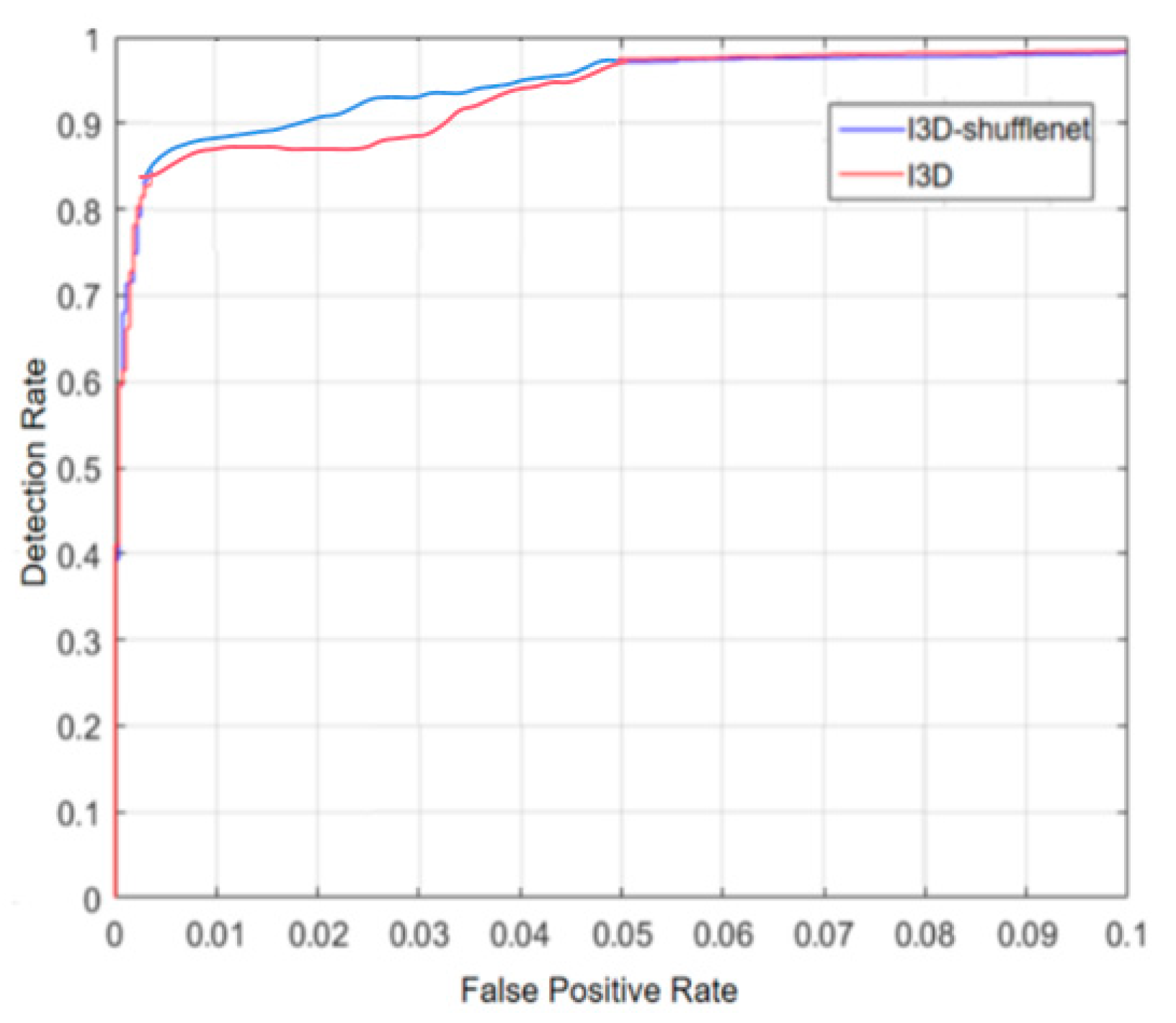
4.8. Comparisons
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Johansson, G. Visual motion perception. Sci. Am. 1975, 232, 76–89. [Google Scholar] [CrossRef] [PubMed]
- Žemgulys, J.; Raudonis, V.; Maskeliūnas, R.; Damaševičius, R. Recognition of basketball referee signals from videos using Histogram of Oriented Gradients (HOG) and Support Vector Machine (SVM). Procedia Comput. Sci. 2018, 130, 953–960. [Google Scholar] [CrossRef]
- Li, T.; Chang, H.; Wang, M.; Ni, B.; Hong, R.; Yan, S. Crowded Scene Analysis: A Survey. IEEE Trans. Circ. Syst. Vid. 2015, 25, 367–386. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Klaser, A.; Schmid, C.; Liu, C. Action Recognition by Dense Trajectories. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 3169–3176. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A New Model for Learning in Graph Domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; pp. 729–734. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P.B.I. Spatiotemporal Multiplier Networks for Video Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7445–7454. [Google Scholar]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the 15th European Conference. Proceedings: Lecture Notes in Computer Science (LNCS 11219), Tokyo, Japan, 29 October–2 November 2018; pp. 318–335. [Google Scholar]
- Chen, Y.; Kalantidis, Y.; Li, J.; Yan, S.; Feng, J. Multi-Fiber Networks for Video Recognition; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 364–380. [Google Scholar]
- Bilen, H.; Fernando, B.; Gavves, E.; Vedaldi, A. Action Recognition with Dynamic Image Networks. IEEE T Pattern Anal. 2018, 40, 2799–2813. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, L.; Tran, D.; Sevilla-Lara, L.; Yang, Y.; Feiszli, M.; Wang, H. FASTER Recurrent Networks for Efficient Video Classification. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13098–13105. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes from Videos in the Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Narayanan, B.N.; Beigh, K.; Loughnane, G.; Powar, N. Support Vector Machine and Convolutional Neural Network Based Approaches for Defect Detection in Fused Filament Fabrication. Int. Soc. Opt. Photonic 2019, 11139, 1113913. [Google Scholar]
- Narayanan, B.N.; Ali, R.; Hardie, R.C. Performance Analysis of Machine Learning and Deep Learning Architectures for Malaria Detection on Cell Images. Int. Soc. Opt. Photonic 2019, 11139, 111390W. [Google Scholar]
- Narayanan, B.N.; De Silva, M.S.; Hardie, R.C.; Kueterman, N.K.; Ali, R. Understanding Deep Neural Network Predictions for Medical Imaging Applications. arXiv 2019, arXiv:1912.09621. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Wang, L.; Li, W.; Van Gool, L. Appearance-and-Relation Networks for Video Classification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1430–1439. [Google Scholar]
- Bonanomi, C.; Balletti, S.; Lecca, M.; Anisetti, M.; Rizzi, A.; Damiani, E. I3D: A new dataset for testing denoising and demosaicing algorithms. Multimed. Tools Appl. 2018, 79, 8599–8626. [Google Scholar] [CrossRef]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 20–36. [Google Scholar]
- Kalfaoglu, M.E.; Alkan, S.; Alatan, A.A. Late Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition. arXiv 2020, arXiv:2008.01232v3. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Overall Accuracy | Precision (Defect Class) | Recall (Defect Class) | F1 Score (Defect Class) | AUC (Defect Class) |
|---|---|---|---|---|---|
| I3D | 95.7 | 0.9506 | 0.9166 | 0.9336 | 0.9463 |
| I3D-shufflenet | 96.6 | 0.9673 | 0.9280 | 0.9477 | 0.9641 |
| Model | UCF101 |
|---|---|
| C3D | 16.5 |
| P3D | 29.2 |
| R3D | 30.7 |
| I3D | 26.1 |
| I3D-shufflenet | 22.3 |
| Algorithm | Accuracy |
|---|---|
| Two-stream [10] | 88.0 |
| Motion stream(ResNet--50) [11] | 87.0 |
| S3D-G [12] | 96.8 |
| MFNet [13] | 96.0 |
| ARTNet [14] | 93.5 |
| FASTER32 [15] | 96.9 |
| Two-stream(conv fusion) [22] | 92.5 |
| Two-stream(SI+OF) [23] | 93.9 |
| C3D [16] | 82.3 |
| IDT [24] | 85.9 |
| TSN [25] | 94.9 |
| R(2+1)D BERT [26] | 98.7 |
| I3D | 95.6 |
| I3D-shufflenet | 96.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, G.; Zhang, C.; Xu, Q.; Cheng, R.; Song, Y.; Yuan, X.; Sun, J. I3D-Shufflenet Based Human Action Recognition. Algorithms 2020, 13, 301. https://doi.org/10.3390/a13110301
Liu G, Zhang C, Xu Q, Cheng R, Song Y, Yuan X, Sun J. I3D-Shufflenet Based Human Action Recognition. Algorithms. 2020; 13(11):301. https://doi.org/10.3390/a13110301
Chicago/Turabian StyleLiu, Guocheng, Caixia Zhang, Qingyang Xu, Ruoshi Cheng, Yong Song, Xianfeng Yuan, and Jie Sun. 2020. "I3D-Shufflenet Based Human Action Recognition" Algorithms 13, no. 11: 301. https://doi.org/10.3390/a13110301