
Prediction of Hydration Heat for Diverse Cementitious Composites through a Machine Learning-Based Approach
 ,
,
Abstract
:1. Introduction
2. Methods
2.1. Design of Cementitious Composites
2.2. Hydration Heat Data Collection
2.3. Data Preprocessing
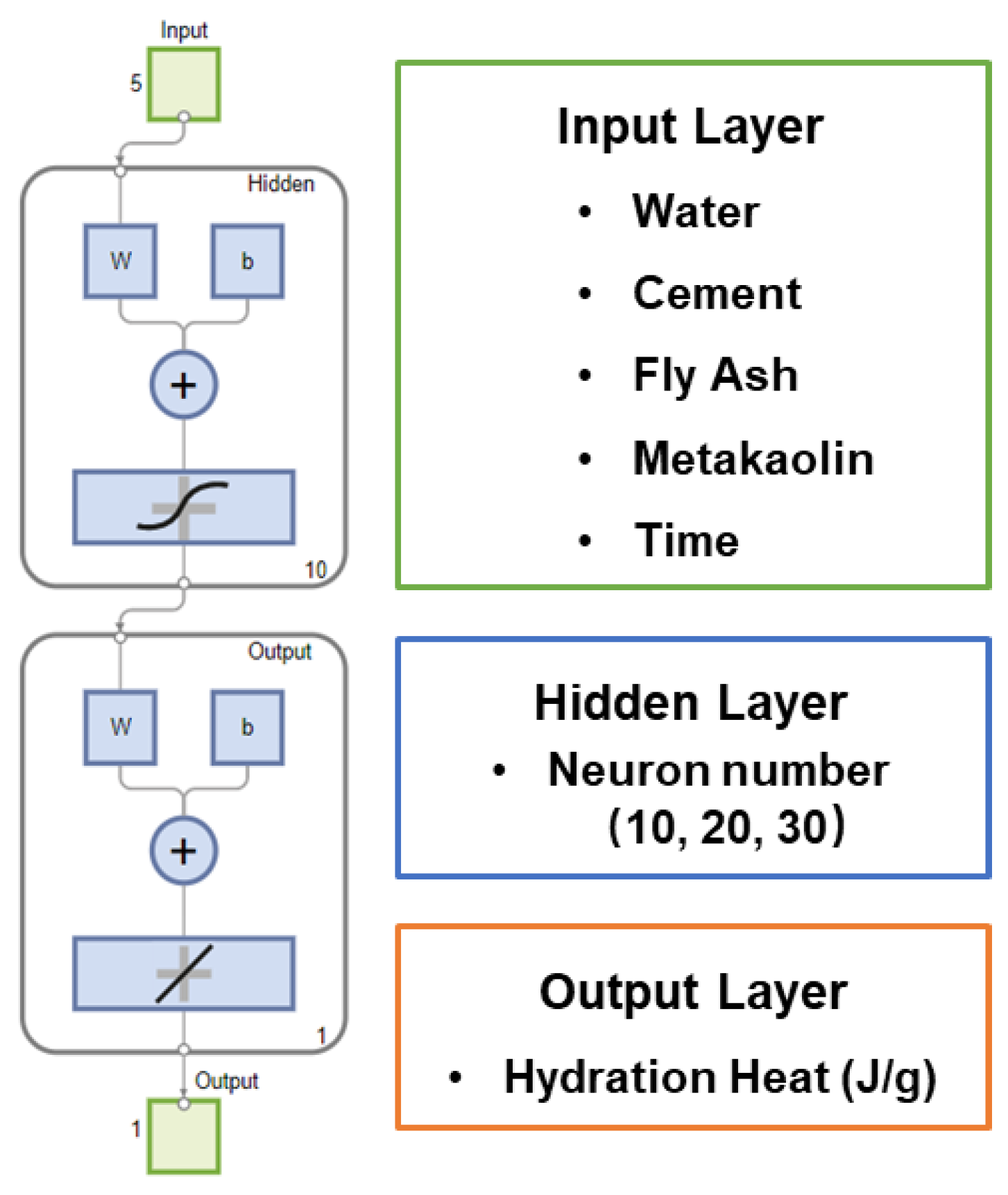
2.4. ANN Model Design and Adjustment
- (1)
- Plot a scatter diagram to compare the predicted output values (represented by Y) against the true output values (represented by T);
- (2)
- Perform a linear fitting for the scatter plot points;
- (3)
- Generate a regression (Equation (2)) relating the predicted output values (Y) and the true output values (T).
3. Results and Discussion
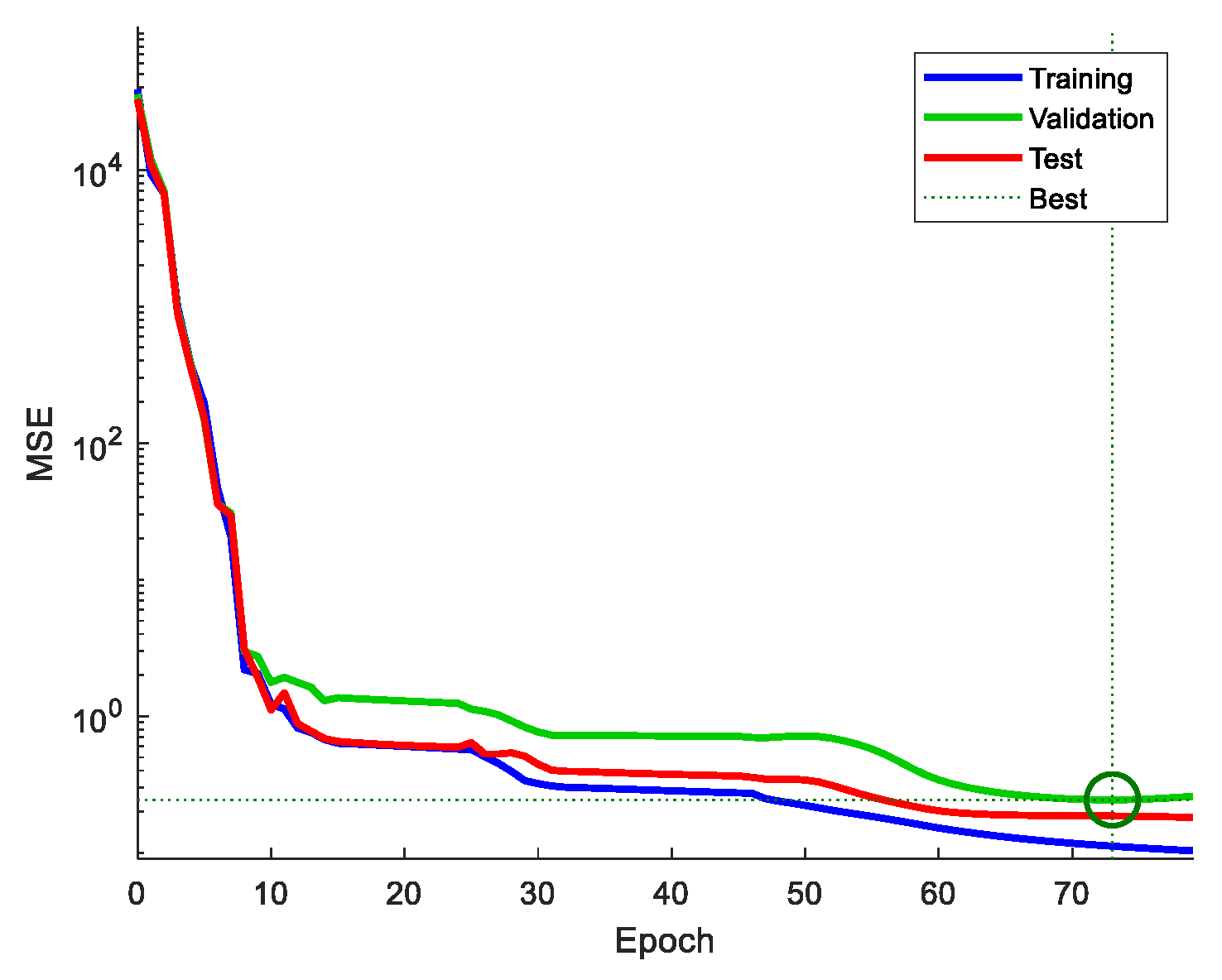
3.1. Machine Learning Process
3.2. ANN Model Performance Analysis
3.3. ANN Model Application
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Scrivener, K.; Ouzia, A.; Juilland, P.; Mohamed, A.K. Advances in understanding cement hydration mechanisms. Cem. Concr. Res. 2019, 124, 105823. [Google Scholar] [CrossRef]
- Scrivener, K.L.; Nonat, A. Hydration of cementitious materials, present and future. Cem. Concr. Res. 2011, 41, 651–665. [Google Scholar] [CrossRef]
- Scrivener, K.L.; Juilland, P.; Monteiro, P.J. Advances in understanding hydration of Portland cement. Cem. Concr. Res. 2015, 78, 38–56. [Google Scholar] [CrossRef]
- Bullard, J.W.; Jennings, H.M.; Livingston, R.A.; Nonat, A.; Scherer, G.W.; Schweitzer, J.S.; Scrivener, K.L.; Thomas, J.J. Mechanisms of cement hydration. Cem. Concr. Res. 2011, 41, 1208–1223. [Google Scholar] [CrossRef]
- Gartner, E.; Young, J.; Damidot, D.; Jawed, I. Hydration of Portland cement. Struct. Perform. Cem. 2002, 2, 57–113. [Google Scholar]
- Brown, P.W.; Franz, E.; Frohnsdorff, G.; Taylor, H. Analyses of the aqueous phase during early C3S hydration. Cem. Concr. Res. 1984, 14, 257–262. [Google Scholar] [CrossRef]
- Nicoleau, L.; Nonat, A. A new view on the kinetics of tricalcium silicate hydration. Cem. Concr. Res. 2016, 86, 1–11. [Google Scholar] [CrossRef]
- Scherer, G.W.; Zhang, J.; Thomas, J.J. Nucleation and growth models for hydration of cement. Cem. Concr. Res. 2012, 42, 982–993. [Google Scholar] [CrossRef]
- Kirby, D.M.; Biernacki, J.J. The effect of water-to-cement ratio on the hydration kinetics of tricalcium silicate cements: Testing the two-step hydration hypothesis. Cem. Concr. Res. 2012, 42, 1147–1156. [Google Scholar] [CrossRef]
- Lahalle, H.; Coumes, C.C.D.; Mercier, C.; Lambertin, D.; Cannes, C.; Delpech, S.; Gauffinet, S. Influence of the w/c ratio on the hydration process of a magnesium phosphate cement and on its retardation by boric acid. Cem. Concr. Res. 2018, 109, 159–174. [Google Scholar] [CrossRef]
- Zhang, J.; Dong, B.; Hong, S.; Teng, X.; Li, G.; Li, W.; Tang, L.; Xing, F. Investigating the influence of fly ash on the hydration behavior of cement using an electrochemical method. Constr. Build. Mater. 2019, 222, 41–48. [Google Scholar] [CrossRef]
- Kadri, E.-H.; Duval, R. Hydration heat kinetics of concrete with silica fume. Constr. Build. Mater. 2009, 23, 3388–3392. [Google Scholar] [CrossRef]
- Avet, F.; Scrivener, K. Investigation of the calcined kaolinite content on the hydration of Limestone Calcined Clay Cement (LC3). Cem. Concr. Res. 2018, 107, 124–135. [Google Scholar] [CrossRef]
- Lothenbach, B.; Scrivener, K.; Hooton, R. Supplementary cementitious materials. Cem. Concr. Res. 2011, 41, 1244–1256. [Google Scholar] [CrossRef]
- Dong, P.; Allahverdi, A.; Andrei, C.M.; Bassim, N.D. The effects of nano-silica on early-age hydration reactions of nano Portland cement. Cem. Concr. Compos. 2022, 133, 104698. [Google Scholar] [CrossRef]
- Lin, J.; Shamsaei, E.; de Souza, F.B.; Sagoe-Crentsil, K.; Duan, W.H. Dispersion of graphene oxide–silica nanohybrids in alkaline environment for improving ordinary Portland cement composites. Cem. Concr. Compos. 2020, 106, 103488. [Google Scholar] [CrossRef]
- Li, W.; Li, X.; Chen, S.J.; Liu, Y.M.; Duan, W.H.; Shah, S.P. Effects of graphene oxide on early-age hydration and electrical resistivity of Portland cement paste. Constr. Build. Mater. 2017, 136, 506–514. [Google Scholar] [CrossRef]
- Myers, R.J.; Geng, G.; Rodriguez, E.D.; da Rosa, P.; Kirchheim, A.P.; Monteiro, P.J. Solution chemistry of cubic and orthorhombic tricalcium aluminate hydration. Cem. Concr. Res. 2017, 100, 176–185. [Google Scholar] [CrossRef]
- Quennoz, A.; Scrivener, K.L. Interactions between alite and C3A-gypsum hydrations in model cements. Cem. Concr. Res. 2013, 44, 46–54. [Google Scholar] [CrossRef]
- Pustovgar, E.; Mishra, R.K.; Palacios, M.; de Lacaillerie, J.-B.d.E.; Matschei, T.; Andreev, A.S.; Heinz, H.; Verel, R.; Flatt, R.J. Influence of aluminates on the hydration kinetics of tricalcium silicate. Cem. Concr. Res. 2017, 100, 245–262. [Google Scholar] [CrossRef]
- Pustovgar, E.; Palacios, M.; de Lacaillerie, J.-B.d.E.; Matschei, T.; Ruffray, N.; Verel, R.; Flatt, R. New Insights into the Retarding Effect of Aluminates on C3S Hydration. Spec. Publ. 2017, 320, 14.11–14.12. [Google Scholar]
- Xu, Q.; Hu, J.; Ruiz, J.M.; Wang, K.; Ge, Z. Isothermal calorimetry tests and modeling of cement hydration parameters. Thermochim. Acta 2010, 499, 91–99. [Google Scholar] [CrossRef]
- Schöler, A.; Lothenbach, B.; Winnefeld, F.; Haha, M.B.; Zajac, M.; Ludwig, H.-M. Early hydration of SCM-blended Portland cements: A pore solution and isothermal calorimetry study. Cem. Concr. Res. 2017, 93, 71–82. [Google Scholar] [CrossRef]
- Thomas, J.J. The instantaneous apparent activation energy of cement hydration measured using a novel calorimetry-based method. J. Am. Ceram. Soc. 2012, 95, 3291–3296. [Google Scholar] [CrossRef]
- Jansen, D.; Naber, C.; Ectors, D.; Lu, Z.; Kong, X.-M.; Goetz-Neunhoeffer, F.; Neubauer, J. The early hydration of OPC investigated by in-situ XRD, heat flow calorimetry, pore water analysis and 1H NMR: Learning about adsorbed ions from a complete mass balance approach. Cem. Concr. Res. 2018, 109, 230–242. [Google Scholar] [CrossRef]
- Kazemi, F.; Asgarkhani, N.; Jankowski, R. Machine learning-based seismic fragility and seismic vulnerability assessment of reinforced concrete structures. Soil Dyn. Earthq. Eng. 2023, 166, 107761. [Google Scholar] [CrossRef]
- Albert, C.; Isgor, O.B.; Angst, U. Exploring machine learning to predict the pore solution composition of hardened cementitious systems. Cem. Concr. Res. 2022, 162, 107001. [Google Scholar] [CrossRef]
- Guo, P.; Meng, W.; Bao, Y. Automatic identification and quantification of dense microcracks in high-performance fiber-reinforced cementitious composites through deep learning-based computer vision. Cem. Concr. Res. 2021, 148, 106532. [Google Scholar] [CrossRef]
- Song, Y.; Huang, Z.; Shen, C.; Shi, H.; Lange, D.A. Deep learning-based automated image segmentation for concrete petrographic analysis. Cem. Concr. Res. 2020, 135, 106118. [Google Scholar] [CrossRef]
- Lin, J.; Liu, Y.; Sui, H.; Sagoe-Crentsil, K.; Duan, W. Microstructure of graphene oxide–silica-reinforced OPC composites: Image-based characterization and nano-identification through deep learning. Cem. Concr. Res. 2022, 154, 106737. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Lapeyre, J.; Han, T.; Wiles, B.; Ma, H.; Huang, J.; Sant, G.; Kumar, A. Machine learning enables prompt prediction of hydration kinetics of multicomponent cementitious systems. Sci. Rep. 2021, 11, 3922. [Google Scholar] [CrossRef]
- Guo, J.; Chen, C.P.; Wang, L.; Yang, B.; Zhang, T.; Zhang, L. Constructing Microstructural Evolution System for Cement Hydration From Observed Data Using Deep Learning. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 4576–4589. [Google Scholar] [CrossRef]
- Tong, Z.; Wang, Z.; Wang, X.; Ma, Y.; Guo, H.; Liu, C. Characterization of hydration and dry shrinkage behavior of cement emulsified asphalt composites using deep learning. Constr. Build. Mater. 2021, 274, 121898. [Google Scholar] [CrossRef]
- Bangaru, S.S.; Wang, C.; Hassan, M.; Jeon, H.W.; Ayiluri, T. Estimation of the degree of hydration of concrete through automated machine learning based microstructure analysis–A study on effect of image magnification. Adv. Eng. Inform. 2019, 42, 100975. [Google Scholar] [CrossRef]
- Han, T.; Bhat, R.; Ponduru, S.A.; Sarkar, A.; Huang, J.; Sant, G.; Ma, H.; Neithalath, N.; Kumar, A. Deep learning to predict the hydration and performance of fly ash-containing cementitious binders. Cem. Concr. Res. 2023, 165, 107093. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample No. | Water | Cement | Fly Ash | Metakaolin |
|---|---|---|---|---|
| 1 | 0.32 | 1 | 0 | 0 |
| 2 | 0.34 | 1 | 0 | 0 |
| 3 | 0.36 | 1 | 0 | 0 |
| 4 | 0.38 | 1 | 0 | 0 |
| 5 | 0.4 | 1 | 0 | 0 |
| 6 | 0.38 | 0.95 | 0.05 | 0 |
| 7 | 0.38 | 0.9 | 0.1 | 0 |
| 8 | 0.38 | 0.85 | 0.15 | 0 |
| 9 | 0.38 | 0.8 | 0.2 | 0 |
| 10 | 0.38 | 0.85 | 0.1 | 0.05 |
| 11 | 0.38 | 0.8 | 0.1 | 0.1 |
| 12 | 0.38 | 0.75 | 0.1 | 0.15 |
| 13 | 0.38 | 0.7 | 0.1 | 0.2 |
| Ratio 8:1:1 | Ratio 7:2:1 | |||||
|---|---|---|---|---|---|---|
| NN10 | NN20 | NN30 | NN10 | NN20 | NN30 | |
| Training | 1.07 | 0.11 | 0.10 | 0.31 | 0.11 | 0.13 |
| Validation | 1.17 | 0.24 | 0.18 | 0.49 | 0.27 | 0.36 |
| Test | 0.62 | 0.19 | 0.38 | 1.26 | 0.21 | 0.39 |
| Extra | 34.23 | 153.66 | 129.68 | 20.35 | 12.06 | 81.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, L.; Li, Y.; Wang, Y.; Wang, F.; Lu, Z.; Liu, Z.; Jiang, J. Prediction of Hydration Heat for Diverse Cementitious Composites through a Machine Learning-Based Approach. Materials 2024, 17, 715. https://doi.org/10.3390/ma17030715
Lu L, Li Y, Wang Y, Wang F, Lu Z, Liu Z, Jiang J. Prediction of Hydration Heat for Diverse Cementitious Composites through a Machine Learning-Based Approach. Materials. 2024; 17(3):715. https://doi.org/10.3390/ma17030715
Chicago/Turabian StyleLu, Liqun, Yingze Li, Yuncheng Wang, Fengjuan Wang, Zeyu Lu, Zhiyong Liu, and Jinyang Jiang. 2024. "Prediction of Hydration Heat for Diverse Cementitious Composites through a Machine Learning-Based Approach" Materials 17, no. 3: 715. https://doi.org/10.3390/ma17030715