
Development of Prediction Model to Predict the Compressive Strength of Eco-Friendly Concrete Using Multivariate Polynomial Regression Combined with Stepwise Method

 , , , and
, , , and
Abstract
:1. Introduction
2. Research Significance
3. Materials and Methods
3.1. System Methodology
3.2. Dataset
3.3. Data-Splitting Procedure
3.4. MPR Model Development
- An intercept (average of the dependent variable values) was always the first step in the model. Depending on the permissible exponents and multiplicands selected by the user, the software created terms that best interacted with existing model terms. The terms were ranked by the fit data’s best t-statistics.
- For a term to be included in the model, two criteria must be met. First, the candidate term should be statistically significant variables of fit. Second, the overall RMSE value of different cross-correlation dataset should be improved. This method lowered the likelihood of overfitting and enhanced the model’s generalizability.
- After any item was added to the model, the statistical significance of the previously included terms was assessed, and if they were not, they were eliminated.
- For more possible terms, the above procedure was done iteratively.
- The model was created using an iterative procedure of introducing and eliminating potential terms from a list of statistically significant terms based on the fit dataset, which also enhanced the RMSE of the test dataset, until the model could no longer be enhanced by introducing or eliminating any individual term.
3.5. Cross-Validation
- Randomly shuffle the database.
- Construct k-groups out of the data.
- For each distinct group:
- As a holdout or test data set, use the group.
- As a training data set, use the remaining groups.
- Apply a model over the training set and assess it against the test set.
- Keep the assessment score but discard the model.
- Using a sample of the model assessment results, summarize the model’s ability.
3.6. Performance Metrics
4. Model Result
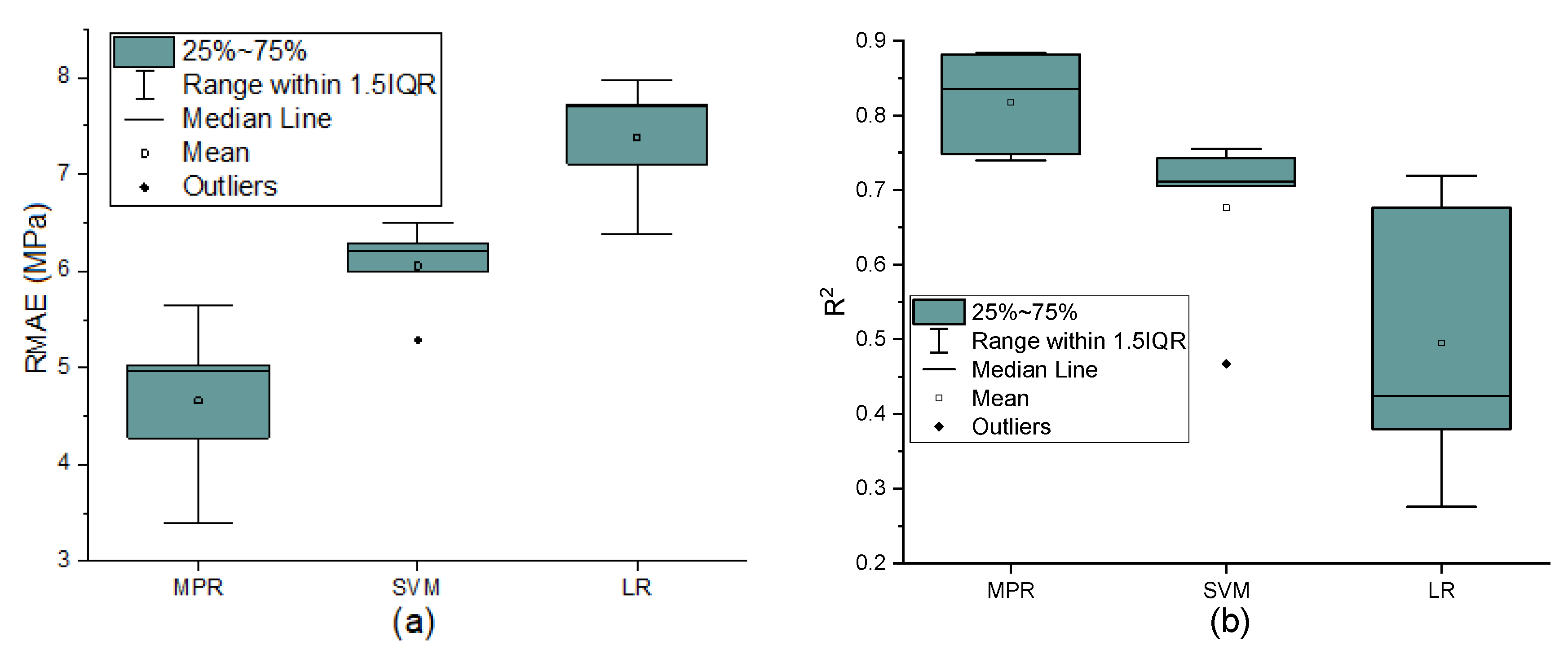
4.1. K-Fold Cross-Validation
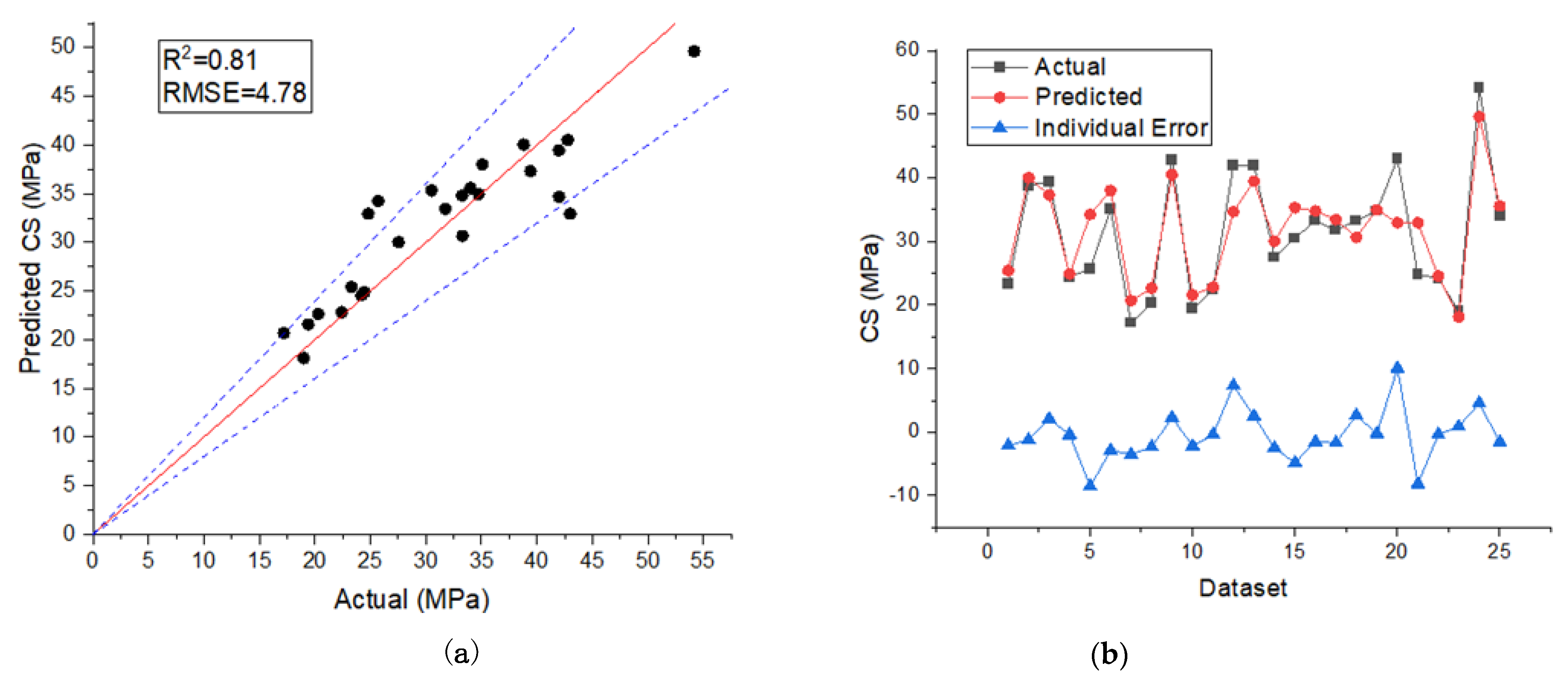
4.2. Model Validation
(34.78562674882411) + (−0.04850685145004892 × (W/C)−1 × RCA%) + (7.39980447082911 × 10−8 × (W/C)−1 ×
(RCA%)−3 × GGBFS%) + (0.000005453293244435137 × (W/C)−2 × (Age)3) + (0.21181781054751617 × (W/C)−3 ×
(Sp)2);
4.3. Parametric Study
4.4. Sensitivity Study
5. Limitation for Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hammoudi, A.; Moussaceb, K.; Belebchouche, C.; Dahmoune, F. Comparison of artificial neural network (ANN) and response surface methodology (RSM) prediction in compressive strength of recycled concrete aggregates. Constr. Build. Mater. 2019, 209, 425–436. [Google Scholar] [CrossRef]
- Zhang, Q.; Feng, X.; Chen, X.; Lu, K. Mix design for recycled aggregate pervious concrete based on response surface methodology. Constr. Build. Mater. 2020, 259, 119776. [Google Scholar] [CrossRef]
- Younis, K.H.; Jirjees, F.F.; Khoshnaw, G.; Ali, B.H. Experimental study on performance of recycled aggregate concrete: Effect of reactive mineral admixtures. Int. J. Civ. Eng. Technol. 2019, 10, 2566–2576. [Google Scholar]
- Tiwari, P.K.; Sharma, P.; Sharma, N.; Verma, M. An experimental investigation on metakaoline GGBS based concrete with recycled coarse aggregate. Mater. Today Proc. 2021, 43, 1025–1030. [Google Scholar] [CrossRef]
- Nedunuri, S.S.S.A.; Sertse, S.G.; Muhammad, S. Microstructural study of Portland cement partially replaced with fly ash, ground granulated blast furnace slag and silica fume as determined by pozzolanic activity. Constr. Build. Mater. 2020, 238, 117561. [Google Scholar] [CrossRef]
- Chore, H.S.; Joshi, M.P. Strength characterization of concrete using industrial waste as cement replacing materials for rigid pavement. Innov. Infrastruct. Solut. 2020, 5, 1–9. [Google Scholar] [CrossRef]
- Aydın, S.; Baradan, B. Sulfate resistance of alkali-activated slag and Portland cement based reactive powder concrete. J. Build. Eng. 2021, 43, 103205. [Google Scholar] [CrossRef]
- Karthik, S.; Mohan, K.S.R. A Taguchi Approach for Optimizing Design Mixture of Geopolymer Concrete Incorporating Fly Ash, Ground Granulated Blast Furnace Slag and Silica Fume. Crystals 2021, 11, 1279. [Google Scholar] [CrossRef]
- Ahmad, S.; Kumar, A.; Kumar, K. Axial performance of GGBFS concrete filled steel tubes. In Proceedings of the Structures, St. Louis, MO, USA, 5–8 April 2020; pp. 539–550. [Google Scholar]
- Al-Abdaly, N.M.; Al-Taai, S.R.; Imran, H.; Ibrahim, M. Development of prediction model of steel fiber-reinforced concrete compressive strength using random forest algorithm combined with hyperparameter tuning and k-fold cross-validation. East.-Eur. J. Enterp. Technol. 2021, 5, 113. [Google Scholar] [CrossRef]
- Su, S.; Zhi, J.; Lou, L.; Huang, F.; Chen, X.; Wu, J. Spatio-temporal patterns and source apportionment of pollution in Qiantang River (China) using neural-based modeling and multivariate statistical techniques. Phys. Chem. Earth Parts A/B/C 2011, 36, 379–386. [Google Scholar] [CrossRef]
- DeRousseau, M.; Laftchiev, E.; Kasprzyk, J.; Rajagopalan, B.; Srubar, W., III. A comparison of machine learning methods for predicting the compressive strength of field-placed concrete. Constr. Build. Mater. 2019, 228, 116661. [Google Scholar] [CrossRef]
- Arshian, A.H.; Morgenthal, G. Probabilistic assessment of the ultimate load-bearing capacity in laterally restrained two-way reinforced concrete slabs. Eng. Struct. 2017, 150, 52–63. [Google Scholar] [CrossRef]
- Ouyang, B.; Song, Y.; Li, Y.; Wu, F.; Yu, H.; Wang, Y.; Yin, Z.; Luo, X.; Sant, G.; Bauchy, M. Using machine learning to predict concrete’s strength: Learning from small datasets. Eng. Res. Express 2021, 3, 015022. [Google Scholar] [CrossRef]
- Golafshani, E.M.; Behnood, A.; Hosseinikebria, S.S.; Arashpour, M. Novel metaheuristic-based type-2 fuzzy inference system for predicting the compressive strength of recycled aggregate concrete. J. Clean. Prod. 2021, 320, 128771. [Google Scholar] [CrossRef]
- Duan, J.; Asteris, P.G.; Nguyen, H.; Bui, X.-N.; Moayedi, H. A novel artificial intelligence technique to predict compressive strength of recycled aggregate concrete using ICA-XGBoost model. Eng. Comput. 2021, 37, 3329–3346. [Google Scholar] [CrossRef]
- Nunez, I.; Marani, A.; Nehdi, M.L. Mixture Optimization of Recycled Aggregate Concrete Using Hybrid Machine Learning Model. Materials 2020, 13, 4331. [Google Scholar] [CrossRef] [PubMed]
- Topçu, İ.B.; Sarıdemir, M. Prediction of mechanical properties of recycled aggregate concretes containing silica fume using artificial neural networks and fuzzy logic. Comput. Mater. Sci. 2008, 42, 74–82. [Google Scholar] [CrossRef]
- Salimbahrami, S.R.; Shakeri, R. Experimental investigation and comparative machine-learning prediction of compressive strength of recycled aggregate concrete. Soft Comput. 2021, 25, 919–932. [Google Scholar] [CrossRef]
- Mohana, M.H. The determination of ground granulated concrete compressive strength based machine learning models. Period. Eng. Nat. Sci. (PEN) 2020, 8, 1011–1023. [Google Scholar]
- Mai, H.-V.T.; Nguyen, T.-A.; Ly, H.-B.; Tran, V.Q. Prediction Compressive Strength of Concrete Containing GGBFS using Random Forest Model. Adv. Civ. Eng. 2021, 2021. [Google Scholar] [CrossRef]
- Sarıdemir, M.; Topçu, İ.B.; Özcan, F.; Severcan, M.H. Prediction of long-term effects of GGBFS on compressive strength of concrete by artificial neural networks and fuzzy logic. Constr. Build. Mater. 2009, 23, 1279–1286. [Google Scholar] [CrossRef]
- Kou, S.-C.; Poon, C.-S.; Agrela, F. Comparisons of natural and recycled aggregate concretes prepared with the addition of different mineral admixtures. Cem. Concr. Compos. 2011, 33, 788–795. [Google Scholar] [CrossRef]
- Moghadam, A.S.; Omidinasab, F.; Goodarzi, S.M. Characterization of concrete containing RCA and GGBFS: Mechanical, microstructural and environmental properties. Constr. Build. Mater. 2021, 289, 123134. [Google Scholar] [CrossRef]
- Elchalakani, M.; Basarir, H.; Karrech, A. Green concrete with high-volume fly ash and slag with recycled aggregate and recycled water to build future sustainable cities. J. Mater. Civ. Eng. 2017, 29, 04016219. [Google Scholar] [CrossRef]
- Majhi, R.; Nayak, A.; Mukharjee, B. Development of sustainable concrete using recycled coarse aggregate and ground granulated blast furnace slag. Constr. Build. Mater. 2018, 159, 417–430. [Google Scholar] [CrossRef]
- Tüfekçi, M.M.; Çakır, Ö. An investigation on mechanical and physical properties of recycled coarse aggregate (RCA) concrete with GGBFS. Int. J. Civ. Eng. 2017, 15, 549–563. [Google Scholar] [CrossRef]
- Subarkah, M.; Sjah, J.; Maknun, I. Effects of Ground Granulated Blast Furnace Slag and Recycled Coarse Aggregates in Compressive Strength of Concrete. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Changchun, China, 21–23 August 2020; p. 012045. [Google Scholar]
- Wei, J.; Chen, T.; Liu, G.; Yang, J. Higher-order multivariable polynomial regression to estimate human affective states. Sci. Rep. 2016, 6, 1–13. [Google Scholar]
- Vaccari, D.A. TaylorFit Response Surface Analysis- with Stepwise Multivariate Polynomial Regression. Available online: http://www.taylorfit-rsa.com/ (accessed on 15 August 2018).
- Ling, H.; Qian, C.; Kang, W.; Liang, C.; Chen, H. Combination of Support Vector Machine and K-Fold cross validation to predict compressive strength of concrete in marine environment. Constr. Build. Mater. 2019, 206, 355–363. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112. [Google Scholar]
- Yang, K.; Xu, X.; Yang, B.; Cook, B.; Ramos, H.; Krishnan, N.A.; Smedskjaer, M.M.; Hoover, C.; Bauchy, M. Predicting the Young’s modulus of silicate glasses using high-throughput molecular dynamics simulations and machine learning. Sci. Rep. 2019, 9, 1–11. [Google Scholar]
- Mirzahosseini, M.; Najjar, Y.; Alavi, A.H.; Gandomi, A.H. ANN-Based prediction model for rutting propensity of asphalt mixtures. In Proceedings of the 92nd Annual Meeting of Transportation Research Board, Washington, DC, USA, 13–17 January 2013. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
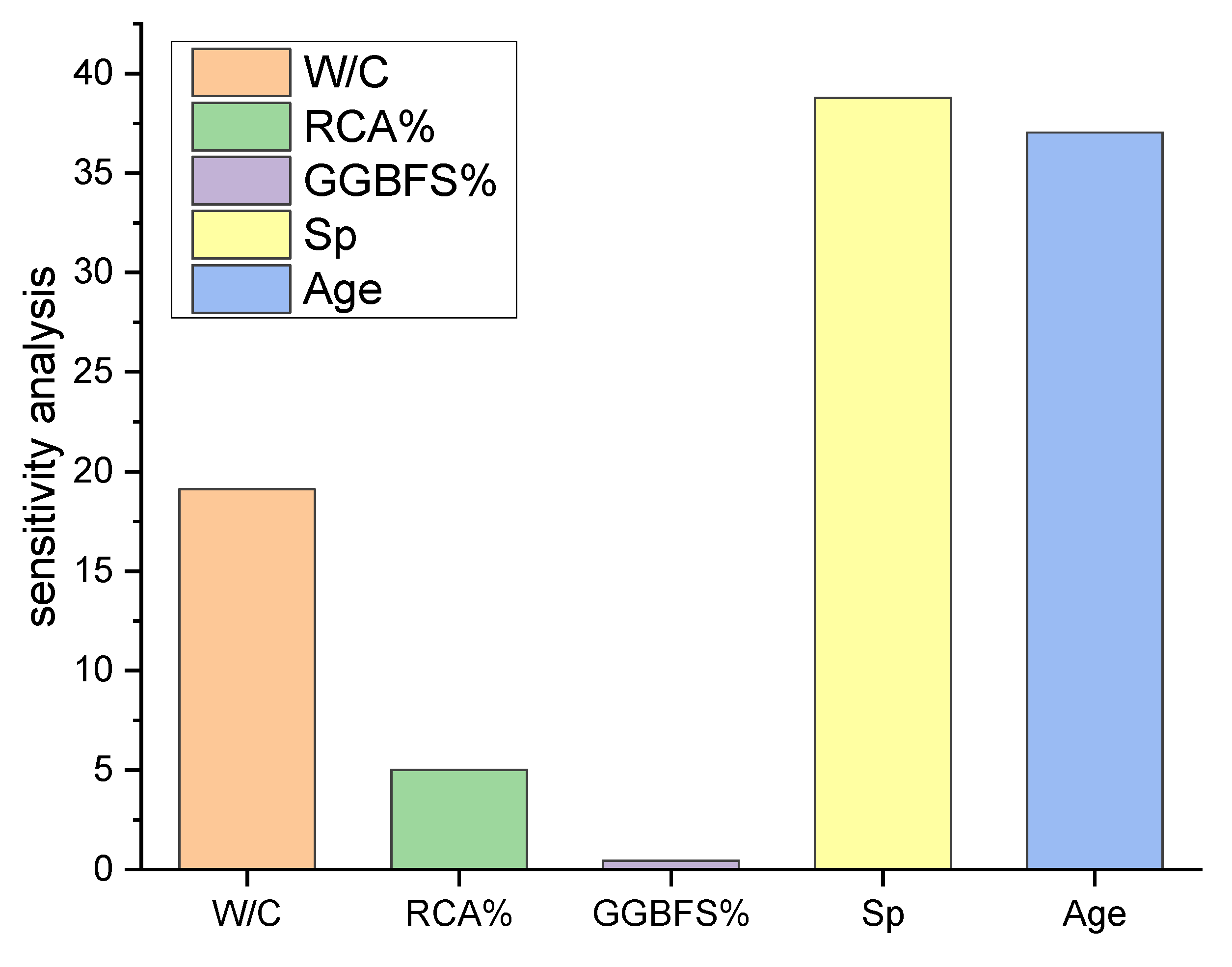{kind=link}
| Statistics | W/C | RCA% | GGBFS% | Sp (kg) | Age (days) | CS (MPa) |
|---|---|---|---|---|---|---|
| Median | 0.71 | 50 | 40 | 1.15 | 28 | 34.05 |
| Mean | 0.92 | 51.20 | 35.64 | 1.88 | 32.66 | 34.44 |
| Minimum | 0.4 | 0 | 0 | 0 | 7 | 12.4 |
| Maximum | 3.7 | 100 | 90 | 7.8 | 90 | 56.63 |
| Range | 3.3 | 100 | 90 | 7.8 | 83 | 44.23 |
| Standard deviation | 0.57 | 37.14 | 25.82 | 2.36 | 27.50 | 10.15 |
| Statistics | MPR | SVM | LR | |||
|---|---|---|---|---|---|---|
| R2 | RMSE | R2 | RMSE | R2 | RMSE | |
| Median | 0.835 | 4.958 | 0.712 | 6.202 | 0.424 | 7.7083 |
| Mean | 0.818 | 4.659 | 0.676 | 6.053 | 0.495 | 7.38138 |
| Minimum | 0.740 | 3.391 | 0.467 | 5.290 | 0.276 | 6.3806 |
| Maximum | 0.884 | 5.638 | 0.755 | 6.493 | 0.720 | 7.9816 |
| Point | W/C | RCA% | GGBFS% | Sp (kg) | Age (days) | Actual CS (MPa) | Predicted CS (MPa) | Individual Error (MPa) |
|---|---|---|---|---|---|---|---|---|
| 1 [28] | 0.568 | 50 | 25 | 1.15 | 7 | 23.30 | 25.41 | −2.11 |
| 2 [27] | 0.714 | 25 | 30 | 3.42 | 28 | 38.80 | 40.03 | −1.23 |
| 3 [26] | 1.250 | 0 | 60 | 0 | 90 | 39.42 | 37.32 | 2.10 |
| 4 [26] | 0.651 | 25 | 20 | 0 | 7 | 24.45 | 24.88 | −0.43 |
| 5 [28] | 0.852 | 50 | 50 | 1.15 | 56 | 25.70 | 34.23 | −8.53 |
| 6 [28] | 0.426 | 50 | 0 | 1.15 | 56 | 35.10 | 37.99 | −2.89 |
| 7 [27] | 1.250 | 25 | 60 | 3.42 | 7 | 17.20 | 20.68 | −3.48 |
| 8 [28] | 0.852 | 50 | 50 | 1.15 | 7 | 20.30 | 22.64 | −2.34 |
| 9 [26] | 0.833 | 0 | 40 | 0 | 90 | 42.78 | 40.51 | 2.27 |
| 10 [27] | 1.250 | 100 | 60 | 3.8 | 7 | 19.40 | 21.56 | −2.16 |
| 11 [26] | 0.868 | 25 | 40 | 0 | 7 | 22.41 | 22.81 | −0.39 |
| 12 [23] | 1.111 | 0 | 55 | 0 | 28 | 42.00 | 34.68 | 7.32 |
| 13 [24] | 0.464 | 75 | 15 | 2.28 | 28 | 41.99 | 39.45 | 2.54 |
| 14 [26] | 0.689 | 100 | 20 | 0 | 28 | 27.54 | 30.01 | −2.47 |
| 15 [25] | 3.700 | 100 | 90 | 7.8 | 28 | 30.50 | 35.32 | −4.82 |
| 16 [26] | 0.833 | 0 | 40 | 0 | 28 | 33.26 | 34.80 | −1.54 |
| 17 [26] | 0.868 | 25 | 40 | 0 | 28 | 31.75 | 33.43 | −1.68 |
| 18 [27] | 0.714 | 100 | 30 | 3.8 | 7 | 33.30 | 30.66 | 2.64 |
| 19 [26] | 0.625 | 0 | 20 | 0 | 28 | 34.76 | 34.97 | −0.21 |
| 20 [23] | 1.111 | 50 | 55 | 0 | 28 | 43.00 | 32.95 | 10.05 |
| 21 [28] | 0.852 | 50 | 50 | 1.15 | 28 | 24.80 | 32.94 | −8.14 |
| 22 [26] | 0.833 | 0 | 40 | 0 | 7 | 24.19 | 24.56 | −0.38 |
| 23 [26] | 1.327 | 50 | 60 | 0 | 7 | 19.00 | 18.10 | 0.90 |
| 24 [24] | 0.400 | 25 | 0 | 2.28 | 28 | 54.17 | 49.63 | 4.54 |
| 25 [25] | 3.700 | 100 | 90 | 7.8 | 56 | 34.00 | 35.57 | −1.57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Imran, H.; Al-Abdaly, N.M.; Shamsa, M.H.; Shatnawi, A.; Ibrahim, M.; Ostrowski, K.A. Development of Prediction Model to Predict the Compressive Strength of Eco-Friendly Concrete Using Multivariate Polynomial Regression Combined with Stepwise Method. Materials 2022, 15, 317. https://doi.org/10.3390/ma15010317
Imran H, Al-Abdaly NM, Shamsa MH, Shatnawi A, Ibrahim M, Ostrowski KA. Development of Prediction Model to Predict the Compressive Strength of Eco-Friendly Concrete Using Multivariate Polynomial Regression Combined with Stepwise Method. Materials. 2022; 15(1):317. https://doi.org/10.3390/ma15010317
Chicago/Turabian StyleImran, Hamza, Nadia Moneem Al-Abdaly, Mohammed Hammodi Shamsa, Amjed Shatnawi, Majed Ibrahim, and Krzysztof Adam Ostrowski. 2022. "Development of Prediction Model to Predict the Compressive Strength of Eco-Friendly Concrete Using Multivariate Polynomial Regression Combined with Stepwise Method" Materials 15, no. 1: 317. https://doi.org/10.3390/ma15010317