

WT-YOLOX: An Efficient Detection Algorithm for Wind Turbine Blade Damage Based on YOLOX

Abstract
:1. Introduction
- Introducing the RepVGG into the backbone of the YOLOX so that it can be re-parameterized to further increase the network feature representation power and balance the model’s speed and accuracy;
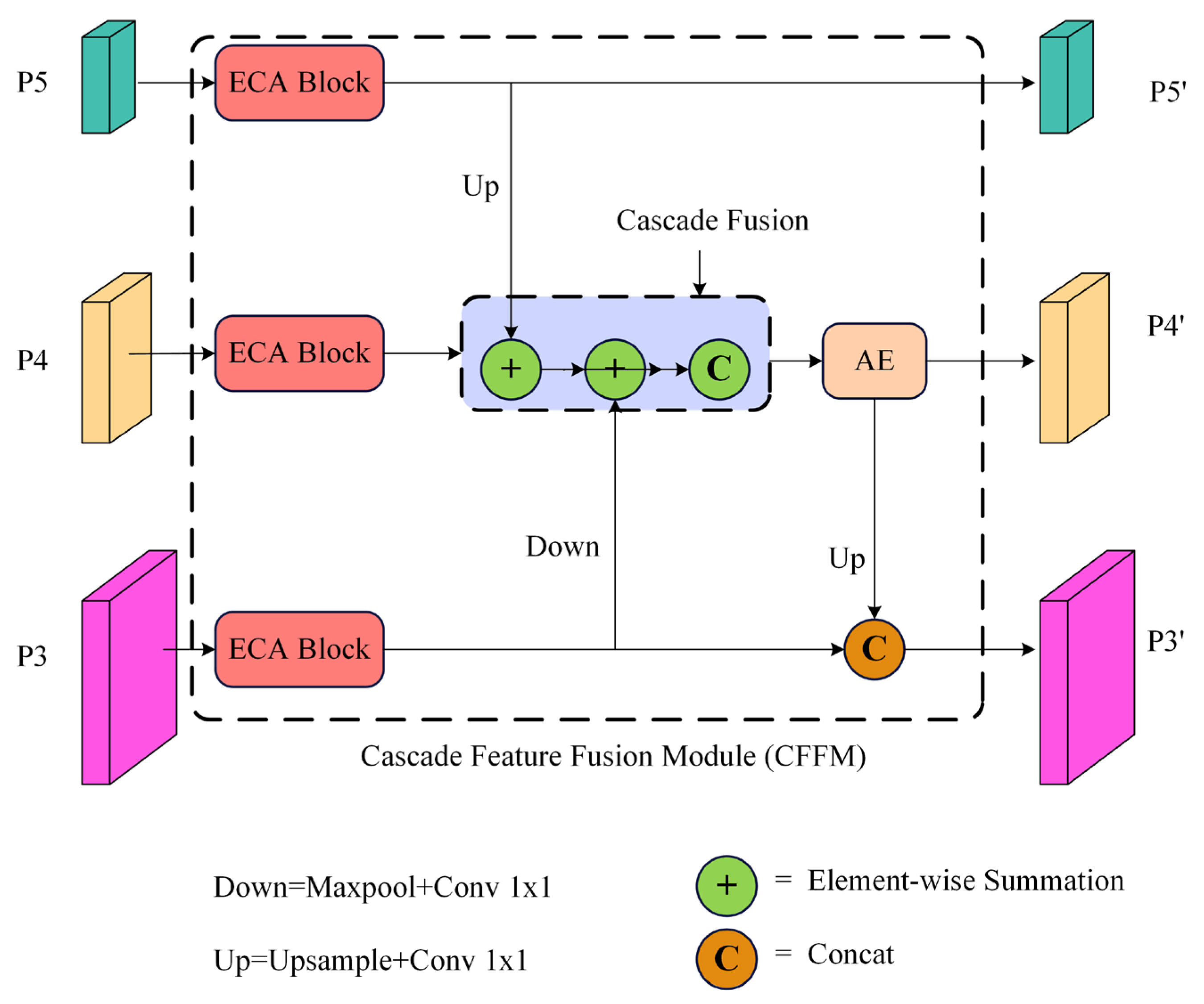
- A cascade feature fusion module is designed to perform a new cascade fusion of the neck’s multiscale input features, thereby enriching the deep semantic information of small targets and increasing feature utilization between the network layers;
- The focal loss is introduced to increase the network model’s focus on difficult positive samples and its learning capacity.
2. Models and Datasets
2.1. Dataset
- Pollution: The long-term operation of the wind turbine will cause the body oil to flow to the blade’s surface and then volatilize to produce oil and dirt. If oil stains exist on the blade’s surface for a long time, the blade will be more susceptible to erosion by external environmental factors such as wind, sand, and rain, which will cause more severe failures;
- Fix: In the field data collection process of the wind field, it is found that a large proportion of wind turbine blades have edge repairs, and repaired areas are more prone to damage than unrepaired areas, so they are called potential damage areas;
- Crack: Cracks are a common surface damage type of wind turbine blades during their operation. The blades will be interacted with by inertial forces during the working process, resulting in vibration. Cracks are generally produced by vibration. The size of the crack is small when it first appears, but after years of wind, sand, rain, and lightning erosion, the size of the crack will further expand. If it cannot be found and repaired in time, it will develop into a fracture under the action of alternating loads;
- Break: After the fan has been in continuous operation for many years, the protective layer on the surface of the blade may be broken due to wind and sand erosion, air corrosion, and strong ultraviolet radiation, resulting in wear and tear of the coating and further increasing the brittleness of the blade. Continuing to run for a long time is very likely to cause the blade to break.
2.2. Network Models
2.2.1. YOLOX Network Model
2.2.2. RepVGG Network Model
- Parameter fusion of the BN and convolutional layers in the multi-branch residual structure is performed, as shown in Equations (1) and (2):
- 2.
- The identity residual mapping branch equivalent to a 1 × 1 unit convolution is converted to a 3 × 3 unit convolution using a complementary zero-filling operation;
- 3.
- The three branches’ convolution layers and bias correspondences are added together to obtain a 3 × 3 convolution.
2.3. Methods
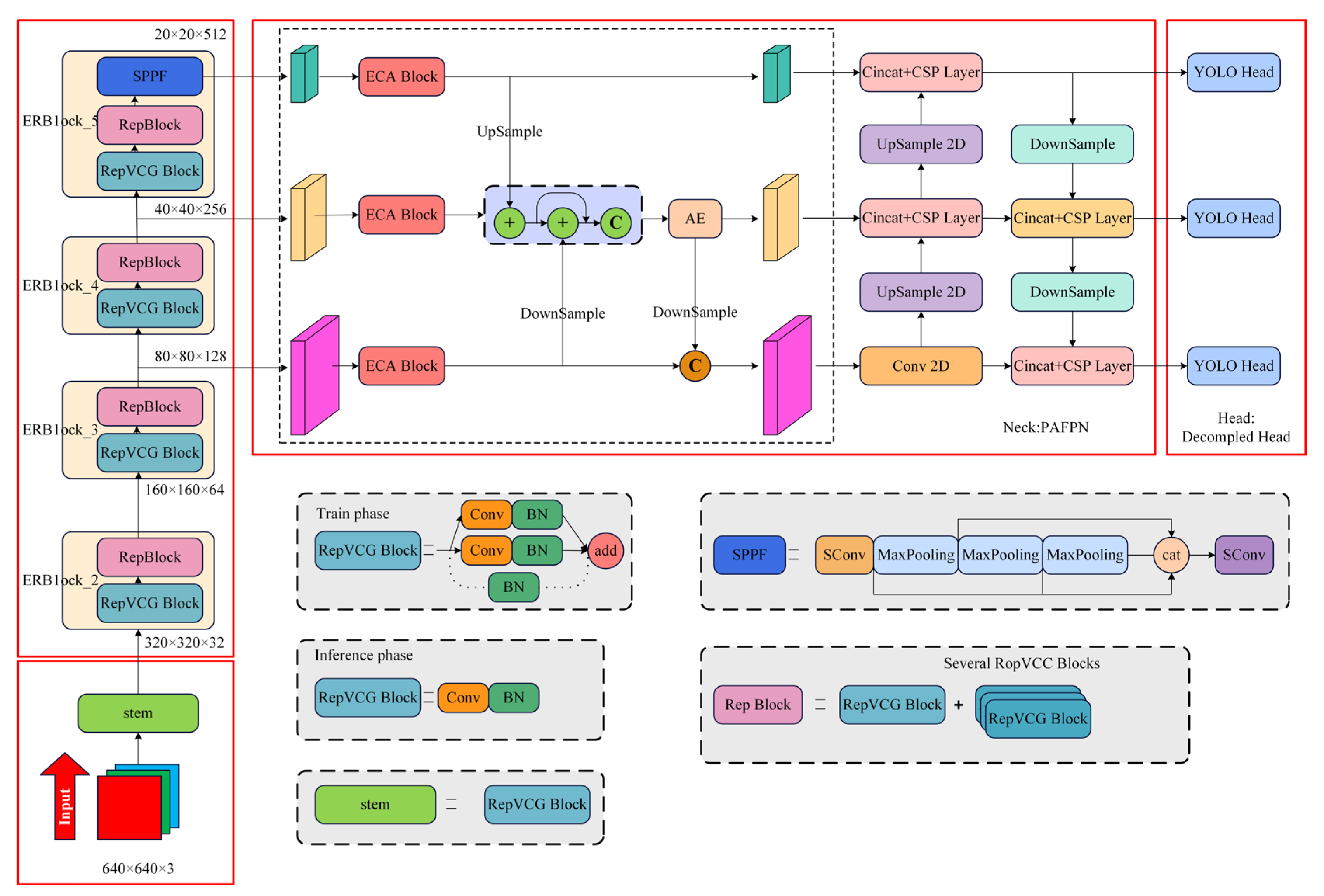
2.3.1. Backbone Improvements
2.3.2. Neck Improvements
2.3.3. Loss Function Improvements
3. Results
3.1. Evaluation Metrics
3.2. Experimental Setups
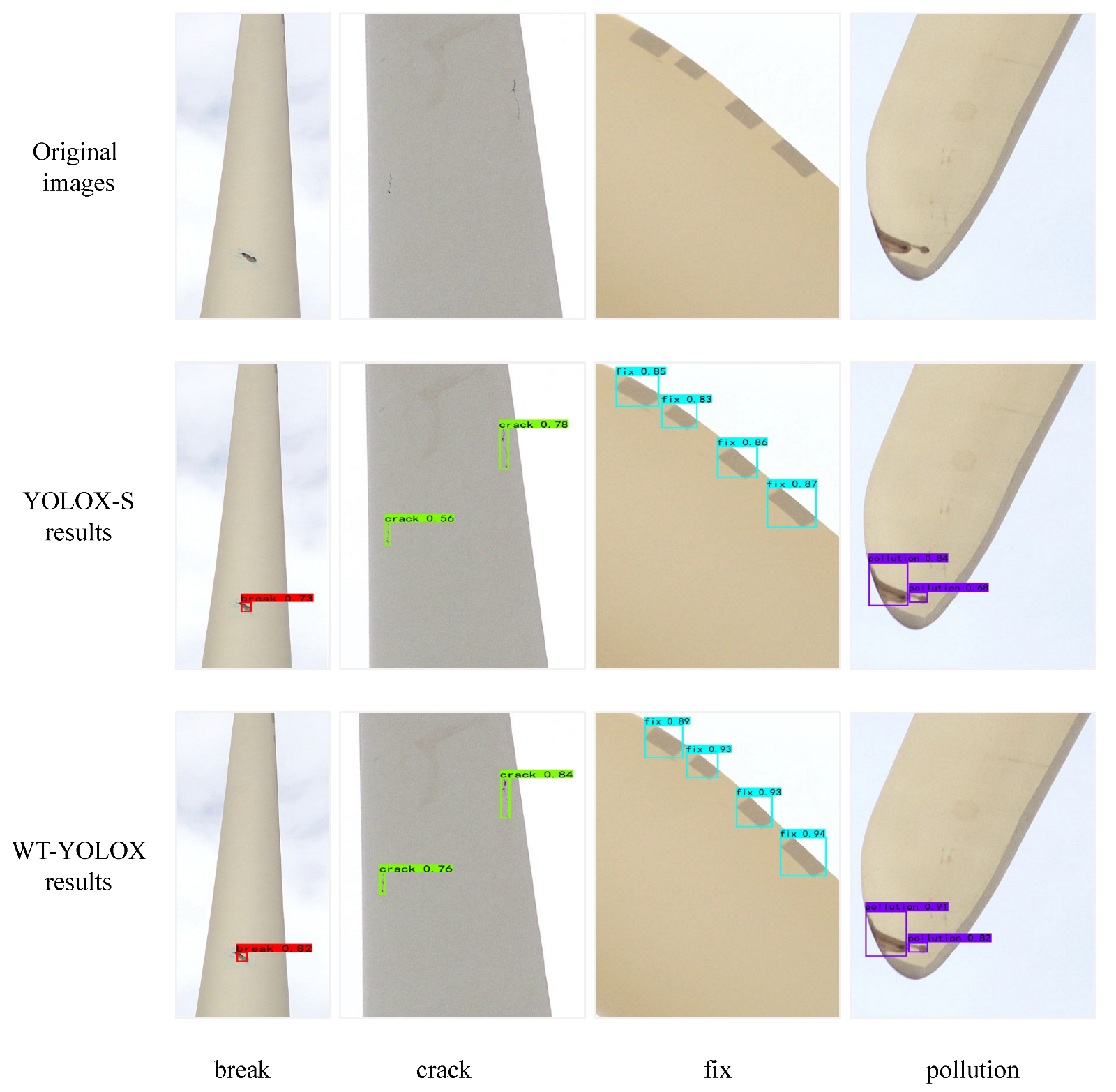
3.3. Analysis
4. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Roga, S.; Bardhan, S.; Kumar, Y.; Dubey, S.K. Recent technology and challenges of wind energy generation: A review. Sustain. Energy Technol. Assess. 2022, 52, 102239. [Google Scholar] [CrossRef]
- Cheng, S.; Elgendi, M.; Lu, F.; Chamorro, L.P. On the Wind Turbine Wake and Forest Terrain Interaction. Energies 2021, 14, 7204. [Google Scholar] [CrossRef]
- Elgendi, M.; AlMallahi, M.; Abdelkhalig, A.; Selim, M.Y. A review of wind turbines in complex terrain. Int. J. Thermofluids 2023, 17, 100289. [Google Scholar] [CrossRef]
- Wang, W.; Xue, Y.; He, C.; Zhao, Y. Review of the typical damage and damage-detection methods of large wind turbine blades. Energies 2022, 15, 5672. [Google Scholar] [CrossRef]
- Márquez, F.P.G.; Chacón, A.M.P. A review of non-destructive testing on wind turbines blades. Renew. Energy 2020, 161, 998–1010. [Google Scholar] [CrossRef]
- Márquez, F.P.G.; Tobias, A.M.; Pérez, J.M.P.; Papaelias, M. Condition monitoring of wind turbines: Techniques and methods. Renew. Energy 2012, 46, 169–178. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430v2. [Google Scholar]
- Yi, C.; Xu, B.; Chen, J.; Chen, Q.; Zhang, L. An Improved YOLOX Model for Detecting Strip Surface Defects. Steel Res. Int. 2022, 93, 2200505. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Shen, C.; Ma, C.; Gao, W. Multiple Attention Mechanism Enhanced YOLOX for Remote Sensing Object Detection. Sensors 2023, 23, 1261. [Google Scholar] [CrossRef] [PubMed]
- Tang, R.; Sun, H.; Liu, D.; Xu, H.; Qi, M.; Kong, J. EYOLOX: An Efficient One-Stage Object Detection Network Based on YOLOX. Appl. Sci. 2023, 13, 1506. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking classification and localization for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10186–10195. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Veit, A.; Wilber, M.J.; Belongie, S. Residual networks behave like ensembles of relatively shallow networks. Adv. Neural Inf. Process. Syst. 2016. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Oyedotun, O.K.; Aouada, D.; Ottersten, B. Going deeper with neural networks without skip connections. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1756–1760. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Sullivan, A.; Lu, X. ASPP: A new family of oncogenes and tumour suppressor genes. Br. J. Cancer 2007, 96, 196–200. [Google Scholar] [CrossRef] [PubMed]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Zhang, Y.-M.; Lee, C.-C.; Hsieh, J.-W.; Fan, K.-C. CSL-YOLO: A new lightweight object detection system for edge computing. arXiv 2021, arXiv:2107.04829. [Google Scholar]
- Zhang, R.; Wen, C. SOD-YOLO: A Small Target Defect Detection Algorithm for Wind Turbine Blades Based on Improved YOLOv5. Adv. Theory Simul. 2022, 5, 2100631. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Damage Types | Break | Pollution | Crack | Fix | Total Number |
|---|---|---|---|---|---|
| Before | 182 | 151 | 180 | 212 | 725 |
| Now | 1456 | 1208 | 1440 | 1696 | 5600 |
| Parameter | = 0.25 | = 0.50 | = 0.75 |
|---|---|---|---|
| = 1 | 92.75 | 92.84 | 92.90 |
| = 2 | 94.29 | 92.76 | 92.62 |
| = 3 | 91.54 | 91.45 | 92.75 |
| Strategy | Group 1 | Group 2 | Group 3 | Group 3 |
|---|---|---|---|---|
| YOLOX-S | √ | √ | √ | √ |
| +SimRepVGG | × | √ | √ | √ |
| +CFFM | × | × | √ | √ |
| +FLs | × | × | × | √ |
| mAP50(%) | 91.34 (+0) | 91.54 (+0.2) | 93.69 (+2.15) | 94.29 (+0.6) |
| Params(M) | 9.00 | 7.45 | 12.15 | 12.15 |
| FPS | 42.12 | 45.80 | 44.28 | 43.18 |
| Methods | Backbone | mAP50 (%) | FPS |
|---|---|---|---|
| SSD | VGG | 84.90 | 21.10 |
| Faster-RCNN | Resnet101 | 73.65 | 8.35 |
| YOLOv3 | CSPDarknet53 | 89.50 | 38.84 |
| YOLOX-S | CSPDarknet53 | 91.34 | 42.12 |
| WT-YOLOX | SimRepVGG | 94.29 | 43.18 |
| Methods | AP50 | Recall |
|---|---|---|
| YOLOX-S | Break: 0.911 Crack: 0.914 Fix: 0.937 Pollution: 0.901 | Break: 0.873 Crack: 0.980 Fix: 0.994 Pollution: 0.903 |
| WT-YOLOX | Break: 0.942 Crack: 0.954 Fix: 0.970 Pollution: 0.943 | Break: 0.891 Crack: 0.968 Fix: 0.987 Pollution: 0.890 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Y.; Wang, G.; Fan, J. WT-YOLOX: An Efficient Detection Algorithm for Wind Turbine Blade Damage Based on YOLOX. Energies 2023, 16, 3776. https://doi.org/10.3390/en16093776
Yao Y, Wang G, Fan J. WT-YOLOX: An Efficient Detection Algorithm for Wind Turbine Blade Damage Based on YOLOX. Energies. 2023; 16(9):3776. https://doi.org/10.3390/en16093776
Chicago/Turabian StyleYao, Yuan, Guozhong Wang, and Jinhui Fan. 2023. "WT-YOLOX: An Efficient Detection Algorithm for Wind Turbine Blade Damage Based on YOLOX" Energies 16, no. 9: 3776. https://doi.org/10.3390/en16093776