1. Introduction
In recent years, with the rapid development of industry, the world is facing increasingly serious energy shortages and environmental pollution problems [
1]. To alleviate these serious problems, the use of integrated energy systems (IESs) that can combine the advantages of safety, stability, high efficiency, and low carbon emissions has become an inevitable trend [
2,
3]. IESs can integrate multiple energy types and energy equipment to promote the coordinated supply of different energy sources [
4]. In addition, IESs can also achieve cascade energy utilization, thereby improving the efficiency of renewable energy and reducing environmental pollution [
5].
Advanced energy management technology is a fundamental prerequisite for the efficient and stable operation of IESs [
6], and it has become the focus of current academic research [
7]. Many scholars use heuristic algorithms, such as the genetic algorithm (GA) or particle swarm optimization, to solve the optimal operation problems. Zhang et al. [
8] presented a two-stage operation optimization method of IESs by using GA to optimize demand curves within customer comfort requirements. Compared with the traditional method, this method reduced operating costs by 3.6%. Jiang et al. [
9] used GA with an elite retention strategy to solve an IES operation optimization model to minimize operating costs. This could reduce the system cost by 7.85% without causing environmental pollution, as well as improve the energy efficiency. To optimize the energy cost of building operation, Kamal et al. [
10] used a multi-objective GA to find the best operating strategy, enabling consumers to save 10–17% of their costs each year. Li et al. [
11] proposed a hybrid optimization method, using GA to optimize the hourly set value of power generation equipment. The results showed that the overall performance of this method was 1.92% better in summer and 1.91% better in winter compared with the traditional GA. Liu et al. [
12] developed an IES dynamic optimization strategy based on GA, which can find the optimal transient coefficient of performance. However, this method is relatively complex, and takes 4980 s in the preprocessing stage. Zhao et al. [
13] proposed a power system scheduling strategy based on a heuristic algorithm, and it can significantly reduce carbon dioxide emissions, primary energy consumption, and operating costs. This method needs to perform approximately 2,304,000 cooling and power generation simulations for 24 h, and there are cases that need more simulations and time. These optimal scheduling strategies can basically realize the stable and efficient operation of IESs. However, almost any heuristic algorithm uses a randomly generated initial solution set and requires constant iterative calculation until convergence. The optimal scheduling of IESs is characterized by complex nonlinear constraints and a large number of optimization variables. In particular, the energy storage unit also aggravates the complexity of IESs to a higher level and increases the difficulty of operation optimization [
14]. These characteristics mean that the above methods take a longer time to solve optimization problems.
At present, to increase the convergence speed of optimization algorithms, many scholars use the historical data of typical or extreme periods (e.g., days or weeks) as the initial solution set of heuristic algorithms [
15]. The clustering algorithm is an effective method for selecting typical and extreme periods. It divides similar profiles into clusters according to periods and then defines a representative period for each cluster [
16].
To find typical periods (common values in historical data), Elsido et al. [
17] used heating demand and ambient temperature to find typical periods for a heating network problem in medium-scale areas, and used them as a reference factor to evaluate annual operating costs. Li et al. [
18] studied a regional IES partition optimization design method based on the clustering algorithm. This method used k-means to cluster the electricity, heating, and cooling demands, as well as the gas loads, of each building. Yeganefar et al. [
19] used electricity load and electricity demand as reference factors for screening typical periods and improved the selection of the typical days of a power system. Poncelet et al. [
20] first selected a small number of required representative periods and then used clustering methods to calculate and derive typical periods based on electrical load, photovoltaic power, and wind power, thus reducing the computational cost of selecting typical periods. Its accuracy is not high, because the number of original datasets in this method is small and artificially selected. The typical period selection methods used in most studies only use 2–3 influencing factors. For IESs, optimal scheduling is not only affected by the demands of cooling, heating, and power on the user side, but also has a lot to do with new energy power generation. If more clustering reference conditions and appropriate clustering methods are used, the speed and accuracy of optimization can be improved [
21].
Some researchers chose the cycles with special data (e.g., peak values) as the extreme periods (abnormal values in historical data) [
22]. This method only considers the peak values of a certain factor as extreme periods, and is more effective for single-factor clustering algorithms. However, it is not suitable for multi-factor clustering. Thus, the influence of other clustering factors on the results is ignored. For the multi-factor clustering algorithm, some researchers have developed algorithms that could add extreme periods to input datasets in an iterative manner [
23]. For cases with a large amount of data, this iterative extreme period search method may take a lot of time because the actual extreme period may be only found in the last iteration. Zatti et al. [
24] proposed an optimization-based method whose purpose is to select typical and extreme periods more accurately and systematically; the influencing factors included power, cooling, and heating. Due to the relative limitations of the considered factors, the method’s accuracy may be relatively poor in special scenarios. Li et al. [
25] predicted the long-term maximum power demand of substations and conducted extreme daily searches of the forecasting process. The authors used clustering to model three common factors required by utility companies: number of customers, average demand, and installed photovoltaic capacity. In the images generated using this processing method, the points at which uneven areas appear were defined as extreme days. Sigauke et al. [
26] analyzed the frequency of non-winter extreme electricity consumption peaks in South Africa. To improve the screening speed, the authors only clustered the excess parts that exceeded the power threshold on the basis of considering the demands of cooling, heating, and electricity. Although the optimization speed was significantly improved, the optimization accuracy was reduced due to a relatively small amount of data. Similar to the choice of typical periods, the choice of extreme periods also has the problem of fewer reference factors. According to current studies, most researchers tended to use the empirical method to select extreme periods, so the influence of subjective factors is relatively large.
In conclusion, at this stage, there are not enough clustering reference attributes to select the typical and extreme periods of IESs. At the same time, the selection of extreme periods mostly uses the peak value method or empirical method, making the results less comprehensive or subject to human influence. In addition, the calculation speed and accuracy of some optimization methods are not balanced, resulting in poor overall results.
This paper attempts an increase in optimizing speed without losing accuracy for the scheduling method for complex IESs. The optimization model is established based on energy, economic, and environmental evaluation indicators. An improved GA is proposed to solve this and obtain the optimal operation plan of each device. More specifically, the historical operation data of an IES are clustered using the k-means combined with box plots (Imk-means) clustering method, considering both the source (photovoltaic power and wind power) and load (cooling, heating, and electricity demands) factors. Its cluster results are used as a part of the initial feasible solution set of the GA to accelerate the convergence speed of the optimization process. At the same time, some random initial feasible solutions are employed to prevent the optimization from falling into local optima. Case studies are conducted to verify the effectiveness of the proposed method.
3. Formulation of the Optimization Problem
The main function of optimal scheduling considered in this paper can be described as follows.
Given: Optimized objective function; scheduling constraints; target area parameters; device parameters; hourly profiles within a selected period of 24 h, including predicted energy consumption, natural resources, and energy prices; historical data of the target area, including energy consumption, natural resources, and relevant weather parameters.
Determine: Maximize the optimized objective function and obtain the hourly output plan of each device within 24 h.
3.1. Objective Function
Energy, economic, and environmental indices are usually used to evaluate the performance of IESs. These three aspects correspond to the primary energy saving ratio (PESR), cost-saving ratio (CSR), and carbon dioxide emission reduction ratio (CDERR) of IESs compared with separate production (SP) systems, respectively [
28,
29]. Usually, the optimal scheduling method takes each day as a cycle, so the three indices also take a day as their units.
The energy objective is defined as follows:
where
and
denote the daily energy consumptions of the SP system and IES, respectively, and they can be calculated by:
where
and
denote the purchased electrical power of the IES and SP system, respectively;
is the power generation efficiency of the power station;
is the line transmission efficiency of the grid;
is a standard coal conversion factor; and
is the fuel consumption of IES in period
t.
can be expressed as:
The economic objective is defined as follows:
where
and
are the daily operating costs of the SP system and IES, respectively. They can be calculated by:
where
and
denote the prices of the purchased and sold electricity by the grid at a time
t;
is the input power of the GB in the SP system;
is the natural gas consumption of the IES; and
is the price of natural gas.
The environmental objective is defined as follows:
where
and
denote the daily CO
2 emissions of the SP system and IES, respectively, and they can be calculated by:
where
is the CO
2 emission coefficient of the coal-fired power grid, and
is the CO
2 emission coefficient of natural gas.
Each of the above energy, economy, and environment indices can be defined as the optimization objective independently. In this study, to improve the energy, economic, and environmental performance of IESs simultaneously, the weighted objective
for all three indices is defined as [
29]:
where
,
, and
denote the weights of the energy, economic, and environmental objectives, respectively. They need to meet the following conditions:
Without loss of generality, the coefficients can be set at
[
18,
29].
3.2. Constrains
Considering the limitations of the device input and output, the following inequalities must be satisfied:
where
,
, and
denote the minimum load ratios of the PGU, GB, and AC, respectively. This is to prevent the light load operation of the equipment.
is the maximum input/output of the TES, and
,
,
,
, and
are the rated capacities of PGU, EC, GB, AC, and TES, respectively.
3.3. Optimization Variables
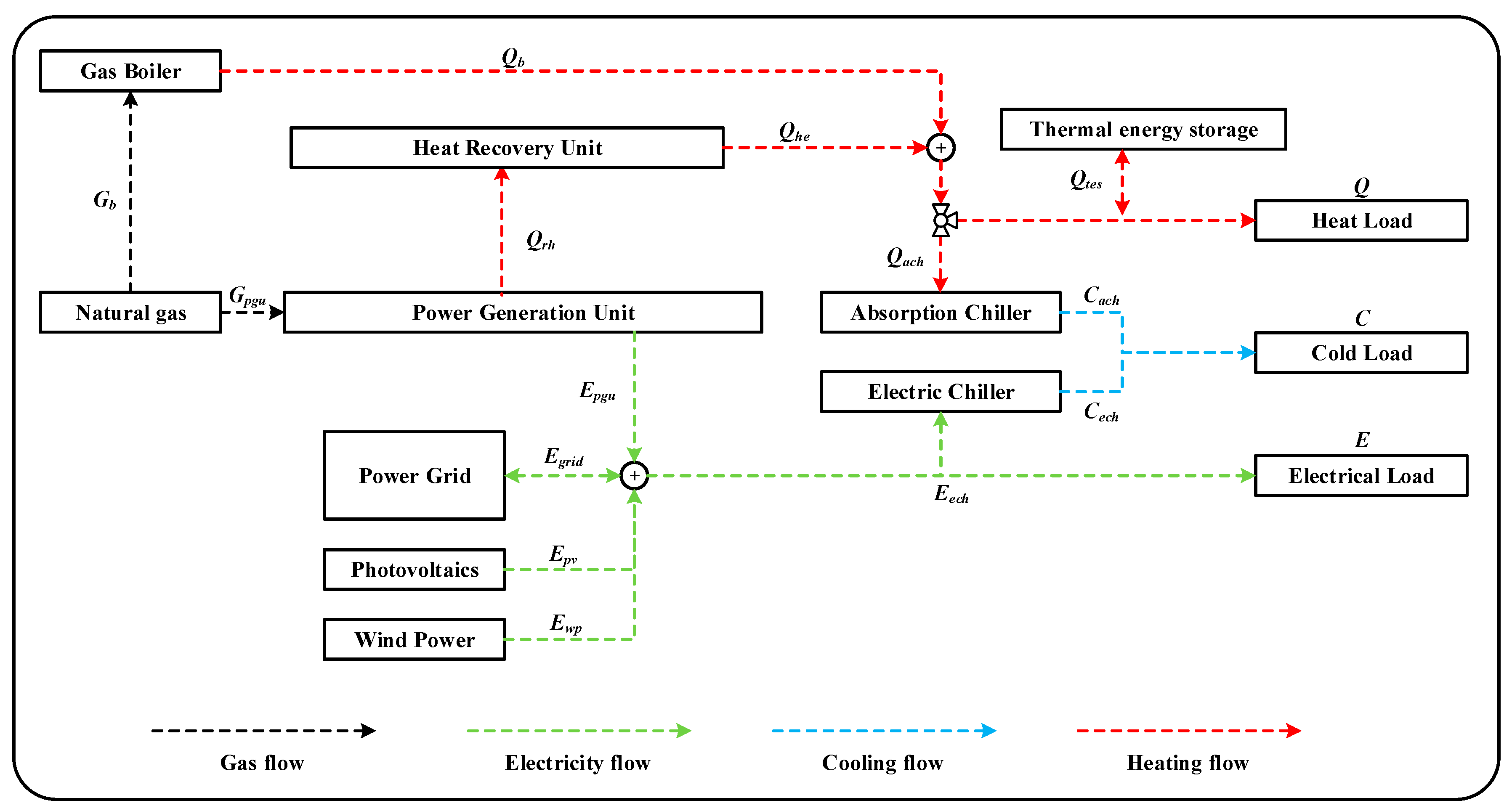
To ensure that the day-ahead optimal scheduling problem can be solved with high speed, it is extremely important to select appropriate optimization variables. The energy supply devices of the system include PGU, GB, AC, EC, and TES. If they are all regarded as optimization variables, the calculation time of the optimization algorithm will be very long. Therefore, we only selected a part of this as the optimization variables and obtained the rest of the results according to the energy flow relationship. The main energy supply equipment PGU and more controllable EC were chosen as the optimized equipment, meaning that and are the optimization variables.
4. Optimal Scheduling Method with High Speed
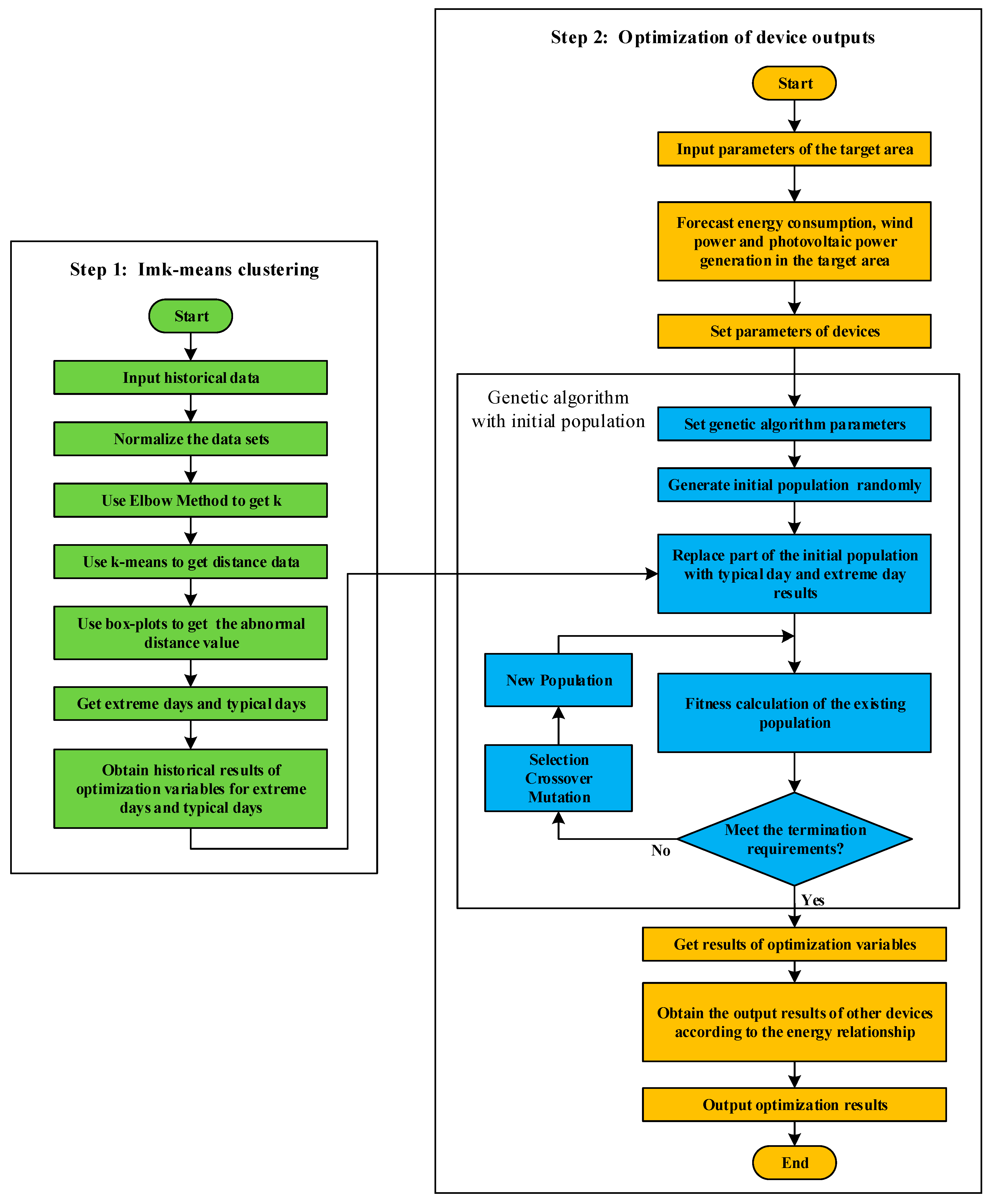
Figure 2 shows the flow chart of the proposed optimal scheduling method, which is divided into two steps. In the first step, the Imk-means is used to determine the typical and extreme periods of the historical data. Then, in the second step, the GA is employed to solve the above optimization problem, in which a part of the initial population is specified using the results of the first step. It should be noted that the historical optimization results of the typical and extreme periods determined in the first step are used to replace a small part of the randomly generated initial population. This part of the initial population can ensure the rapid convergence of the algorithm, while the remaining random population can also prevent the optimization from falling into a local optimum [
30,
31]. Thus, the convergence of the optimal scheduling algorithm can be accelerated without loss of accuracy. The optimization process of the second step is closed to a typical GA. The fitness of the GA is calculated using Equation (21). Therefore, the proposed Imk-means method is explained detailly in this section.
The optimal scheduling algorithm is to arrange the operation set point of each device in the next stage within a certain time step. Therefore, when accelerating the optimal scheduling algorithm, a reasonable selection of typical and extreme periods is very important. Before the next period, the operation plan of each device is obtained. In this study, we take day-ahead optimization as an example, meaning that the optimal scheduling is based on daily cycles with hourly intervals. To match the day-ahead optimal scheduling, the typical and extreme periods should also be 24 h periods. In other words, typical days and extreme days need to be found. Notably, this research method is a general method that can be used in optimization at any time interval, such as rolling optimization (optimize every 5 min), and is not limited to day-ahead optimization. If the interval time is different, only the time step in the formula needs to be adjusted. The optimal scheduling of the IESs is affected by the cooling, heating, and electricity demands, and the electricity produced by renewable energy. Therefore, the factors affecting the selection of typical days and extreme days are load (cooling, heating, and electricity demands) and source (photovoltaic power generation and WP generation). These factors are our clustering attributes.
4.1. k-Means Algorithm: Traditional Clustering Method
The k-means algorithm divides all candidates into a given number of categories by minimizing the distance between the cluster center and the other candidates [
32]. This clustering method has been widely used in the optimization of IESs, especially in the case of large datasets [
19]. The clustering object studied in this paper is the annual energy consumption and resource data of a certain area, so the k-means algorithm is suitable for this purpose. To eliminate the influence of different units of different clustering attributes, all data need to be standardized, as shown in Equation (30). Then, the Euclidean distance is used to calculate the distance
between the candidates, as shown in Equation (31):
where
is the normalized value,
is the original value;
represents the
k-th clustering centroid point, and
represents each attribute point; subscript
is one hour within 24 h;
is a clustering attribute (here,
= 5).
Then, the k-means algorithm can be described as follows:
where
is the number of clusters;
is the number of candidates;
is a binary variable that is equal to 1 if the candidate
is assigned to the
k-th cluster (0 otherwise). To make sure that each candidate is exactly assigned to a cluster, constraint (33) is added.
In the k-means algorithm, different values of
result in different clustering results. Therefore, a reasonable choice of
is very important. The elbow method is a reliable way to choose
. It trains multiple k-means models and makes calculations within the cluster sum of squared errors (SSE) by selecting different values of
. If the SSE has a sudden inflection point, the corresponding
is the optimal number of clusters. SSE can be written as in Equation (34):
where
is the average of candidates in the
k-th cluster.
In this work, the days reaching the peak value of each attribute are set as extreme days, while the other days corresponding to the clustering centroid points are set as typical days. In this algorithm, the selection of extreme days only considers a certain clustering attribute without a comprehensive consideration of all clustering attributes. This means that the k-means algorithm cannot automatically select typical days and extreme days at the same time.
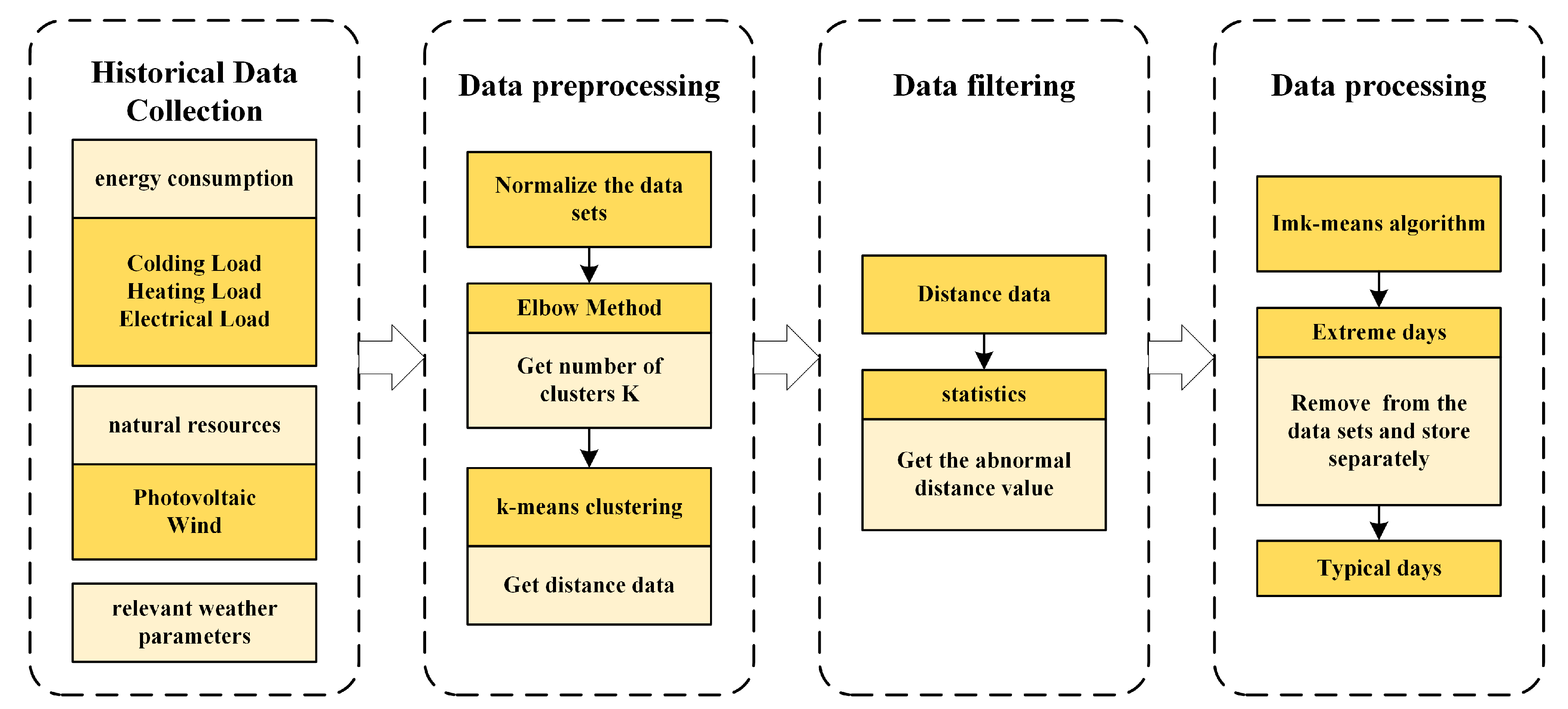
4.2. Imk-Means Algorithm: A Clustering Method for Automatically Identifying Typical and Extreme Days
We developed the Imk-means algorithm that can automatically find typical and extreme days at the same time. It is essentially an improvement and adjustment of the traditional k-means algorithm combined using box plots. First, to ensure that the method can automatically select outliers (extreme days) from all candidates, constraint (33) should be changed as follows:
where
is a binary variable that is equal to 1 if the candidate
is assigned to the
k-th cluster (0 otherwise). The constraint in Equation (35) means that each candidate does not have to be assigned to a certain cluster, where the extreme days are the candidates corresponding to
(equal to 0). Second, the extreme days need to be determined. The k-means algorithm is used to obtain the distance data for all candidates. The number of distance data is
where
is the number of clusters produced by the k-means algorithm. The distance data are arranged in order of size to determine the positions of
and
as follows:
where
is the 1st quartile corresponding to the position
, and
is the 3rd quartile corresponding to the position
. In statistics, based on Tukey’s test, the abnormal distance value of a dataset is defined as:
The candidates corresponding to the abnormal distance values are the extreme days. In addition, Equation (40) defines the ultra-abnormal distance values of a dataset as follows:
The candidates corresponding to the ultra-abnormal distance values are the ultra-extreme days. To exclude the extreme days from the cluster candidates, constraint (41) needs to be added:
where
is the number of candidates that need to be clustered, from which the typical days are selected;
is the number of extreme days. Then, the selection of typical days can be expressed by:
Equation (42) is used to determine , and the clustering centroid points selected by Equation (43) are typical days.
Therefore, the Imk-means method can automatically find typical days and extreme days at the same time. Unlike the traditional k-means algorithm, the calculation of
includes all the clustering attributes, so the extreme days found based on
also fully consider the impact of all the clustering attributes, which makes the choice of extreme days more reasonable.
Figure 3 shows the process of the Imk-means method.
5. Case Study
5.1. Description of the Datasets
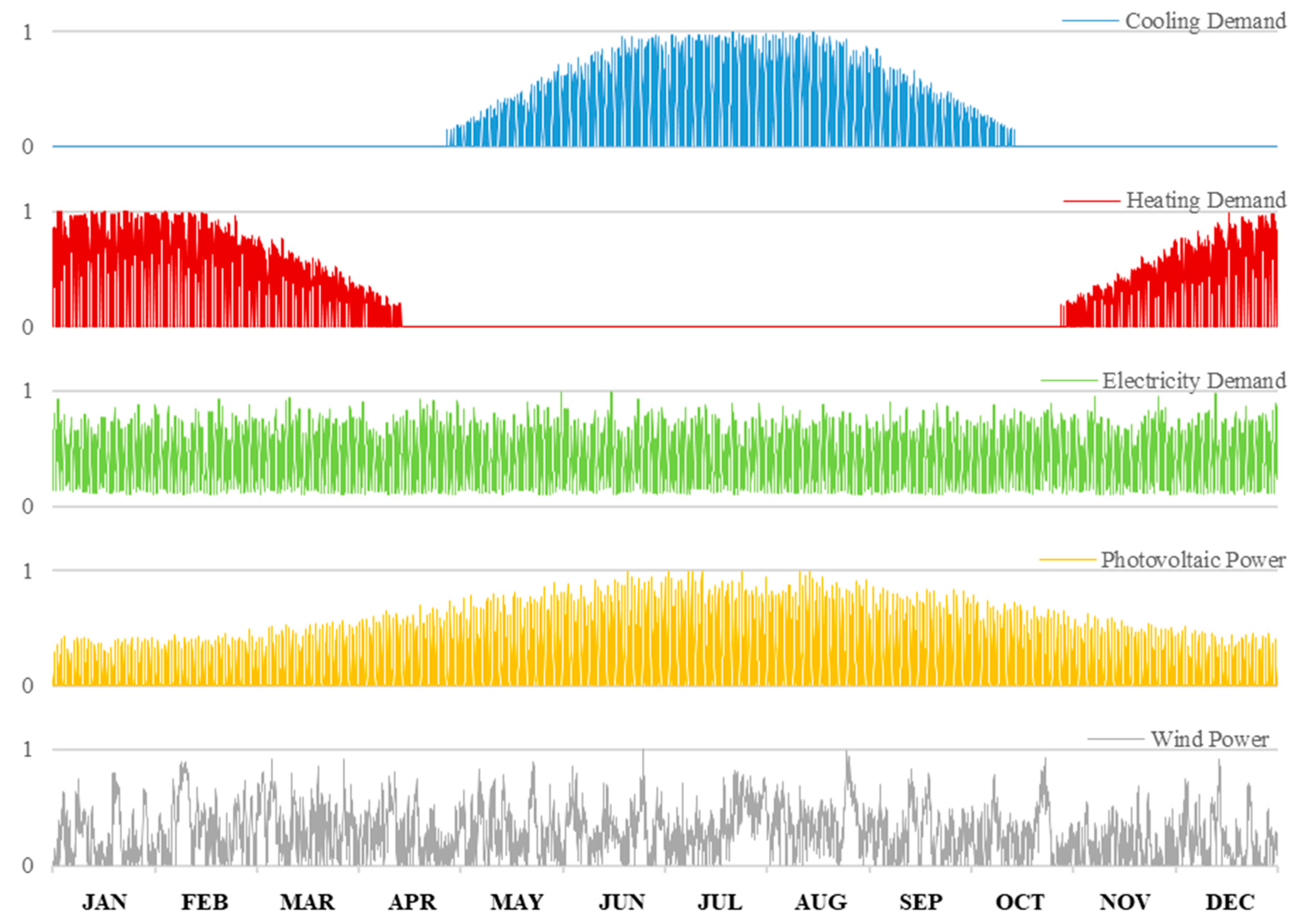
A hypothetical building in Jinan City was used to verify the proposed optimal scheduling method with high speed. The one-year time series of the relevant attributes (normalized between 0 and 1) is shown in
Figure 4. The data collection interval was 1 h. These data were simulated using EnergyPlus (a software for building energy usage simulations) [
33]. The following three major remarks can be made on these time series. The total electricity demand is relatively stable compared with the other attributes due to the office’s properties and the geographic characteristics of the building. Since Jinan has four distinct seasons, the seasonality of the cooling and heating demands is obvious. Photovoltaic power generation reaches its peak in summer and supplements the electricity demand for cooling. The five types of relevant attributes are divided by day, and the daily data are composed of these relevant attributes, which are combined into 120-dimensional variables as input variables for clustering.
5.2. Resource Data Clustering and Analysis
This section analyzes the processed source data. First, the number of clusters was determined by the SSE curve, and then the typical days and extreme days were determined using the proposed Imk-means algorithm.
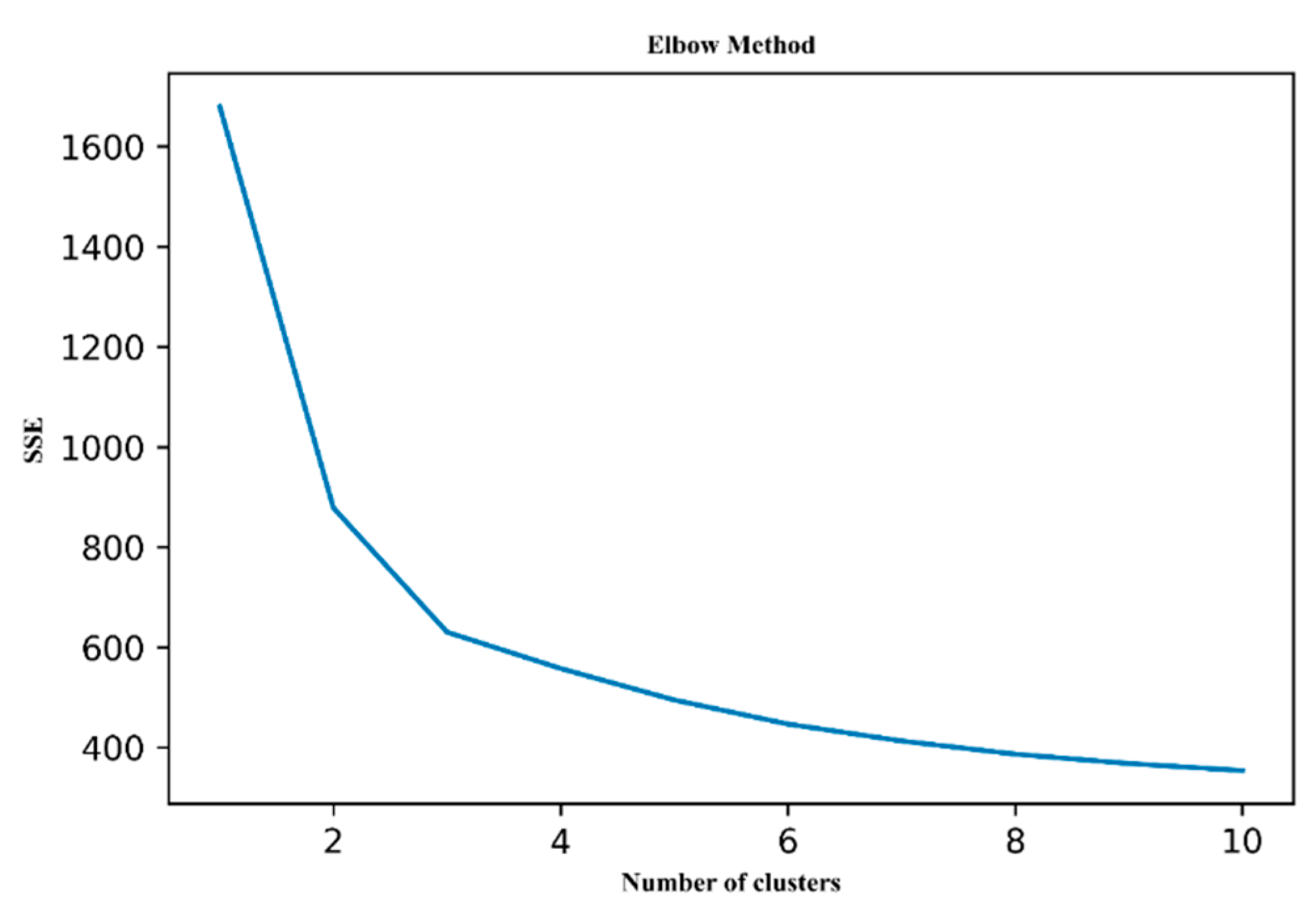
Figure 5 shows the SSE curve of the resource data. The sudden inflection point appears at
n = 3, and then the curve flattens out. Therefore, when the k-means algorithm was used for clustering to obtain distance data, the initial centroid of mass was set to 3.
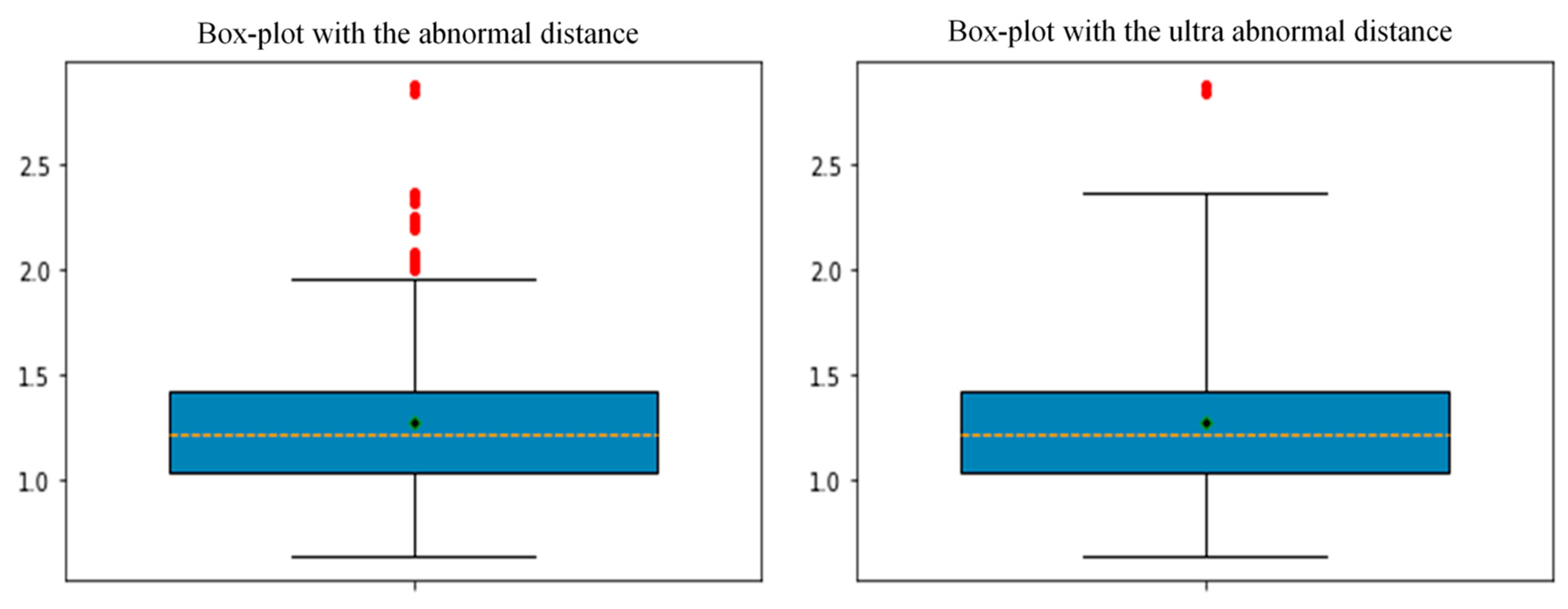
Box plots were used to process the distance data, as shown in
Figure 6 and
Table 1.
Through the data in
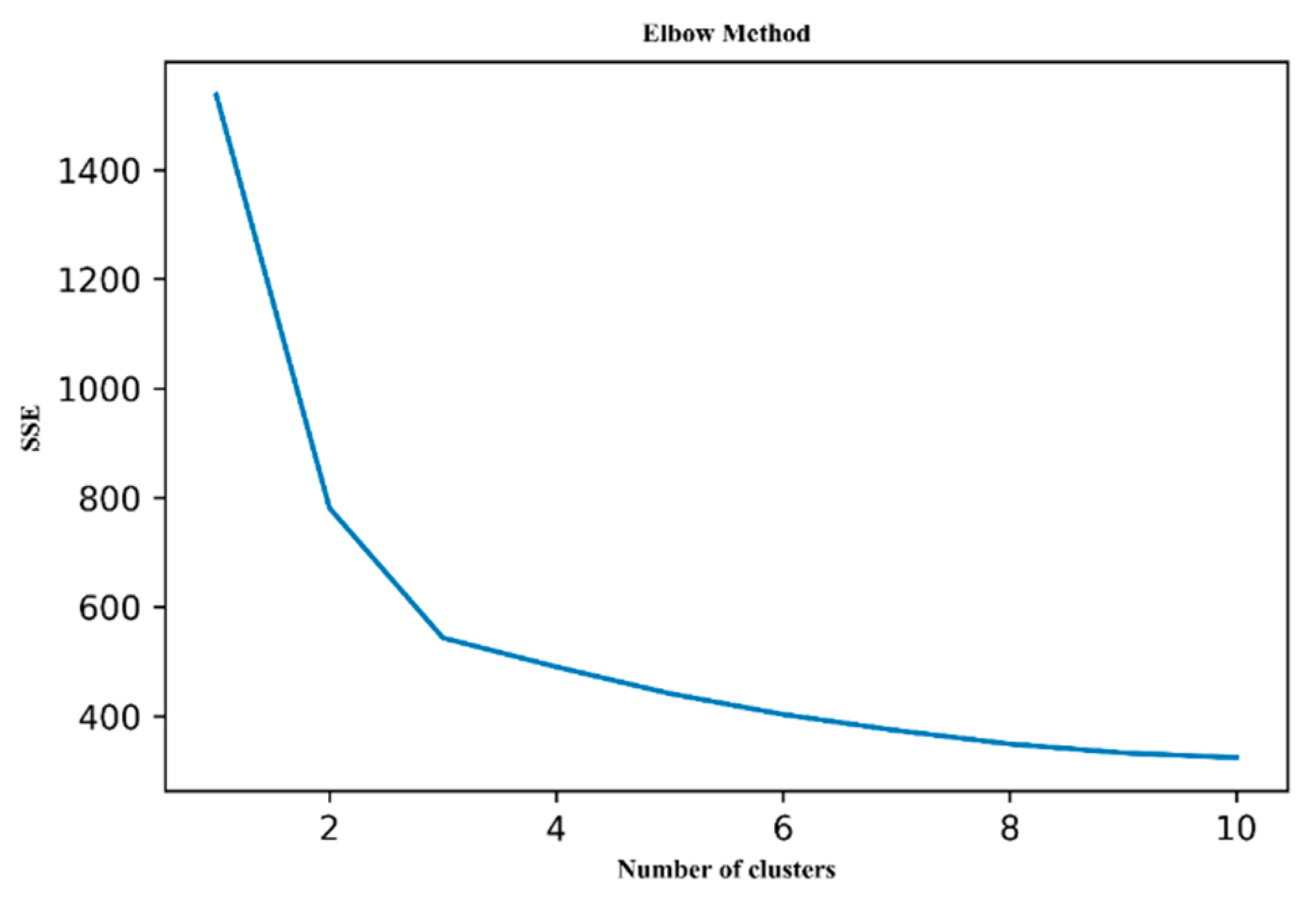
Table 1, the distance threshold could be obtained to filter out the extreme days. After removing the extreme days from the original database, the SSE curve was recalculated, as shown in
Figure 7.
As shown in
Figure 7, the sudden inflection point appears at
n = 3. Therefore, when the Imk-means algorithm was used for clustering to obtain typical and extreme days, the initial centroid of mass was set to 3.
Table 2 lists the size of each cluster and the extreme days.
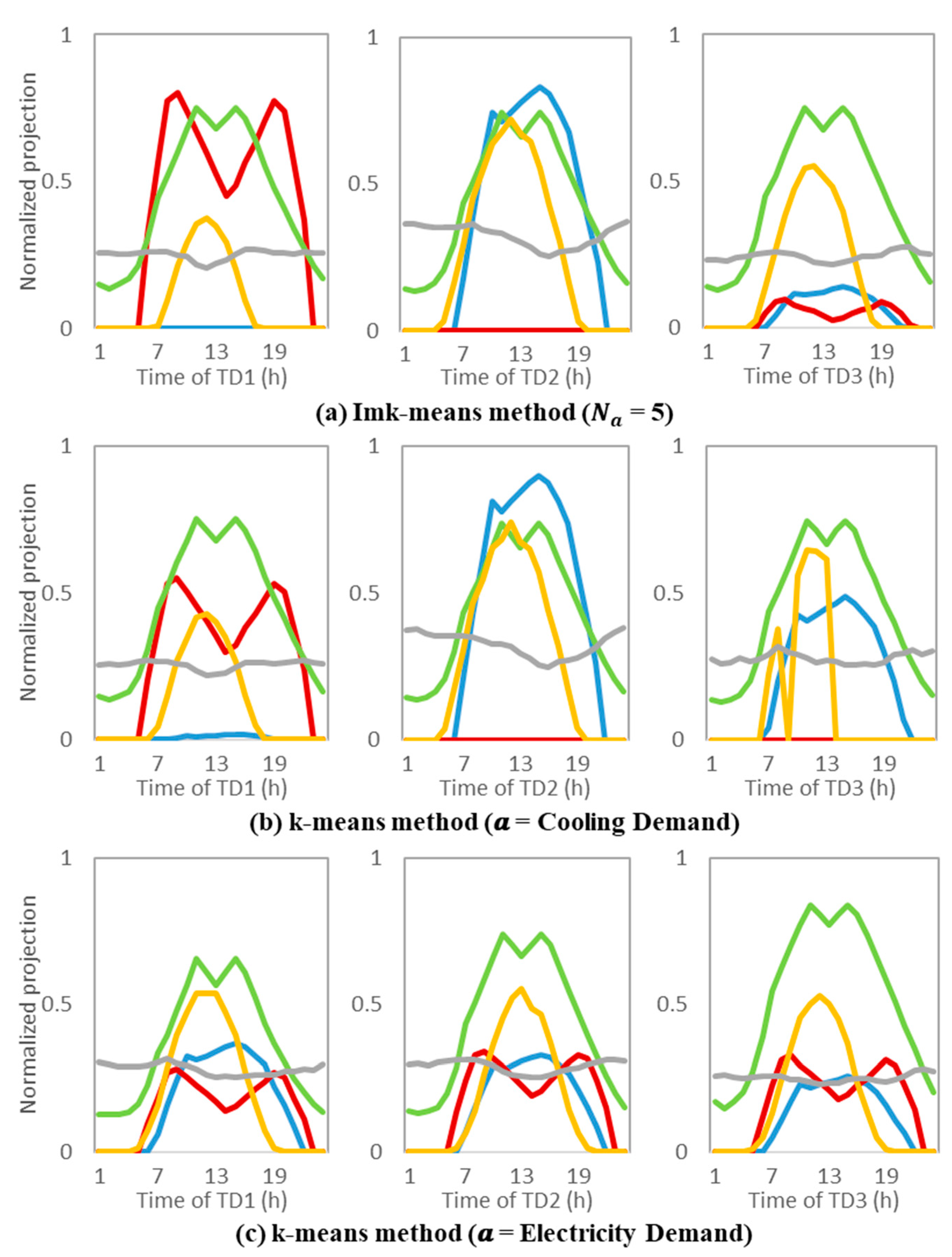
Figure 8 shows the normalized plots of the typical days selected by different approaches. The proposed Imk-means clustering algorithm in this paper is compared with the other two clustering methods, which only consider a single factor. Among them, there are three typical days: TD1–TD3. The selection of typical days used three methods from top to bottom as follows: (a) Imk-means clustering algorithm: the clustering attributes include cooling, heating, and electricity demands, as well as photovoltaic and WP; (b) K-means clustering algorithm where the clustering attribute is the cooling demand only; (c) K-means clustering algorithm where the clustering attribute is the electricity demand only.
Since both the cooling and heating demands have very obvious seasonal variation characteristics, we do not analyze the typical day selections that only considered the heating demand. It can be seen that, in a typical day obtained using the Imk-means algorithm, TD1 has a strong heat demand but no cold demand, TD2 has a strong cold demand but no heat demand, and TD3 has both cold and heat demands. This meets the three seasonal characteristics (winter, summer, and transitional seasons), which is in line with the four distinct seasons of Jinan. The typical days selected by the other two comparison methods have very sharp fluctuations, but in view of the results of a variety of factors considered together, their various attributes change relatively smoothly. From a practical point of view, under normal circumstances, none of the factors has a very obvious turning point.
Since the electricity demand of the building is relatively stable throughout the year, there are no significant differences in the electricity demand clustering results. The same phenomenon also applies to WP; because the wind does not change much throughout the year, there are no obvious differences. For the cooling and heating demands and photovoltaic power, TD3 shows a clear difference. In transitional seasons, the cooling and heating consumptions are relatively small, but they are not completely zero. This phenomenon appears to be zero when considering only the cooling demand, but it is still slightly higher in the image where only the electricity demand is considered. In the Imk-means image, the values of the cooling and heating demands are lower but not completely zero, which is more in line with reality. The proposed method in this paper can generally obtain results that are closer to reality than the methods that only consider a single factor, and the typical days derived from this method are also more accurate.
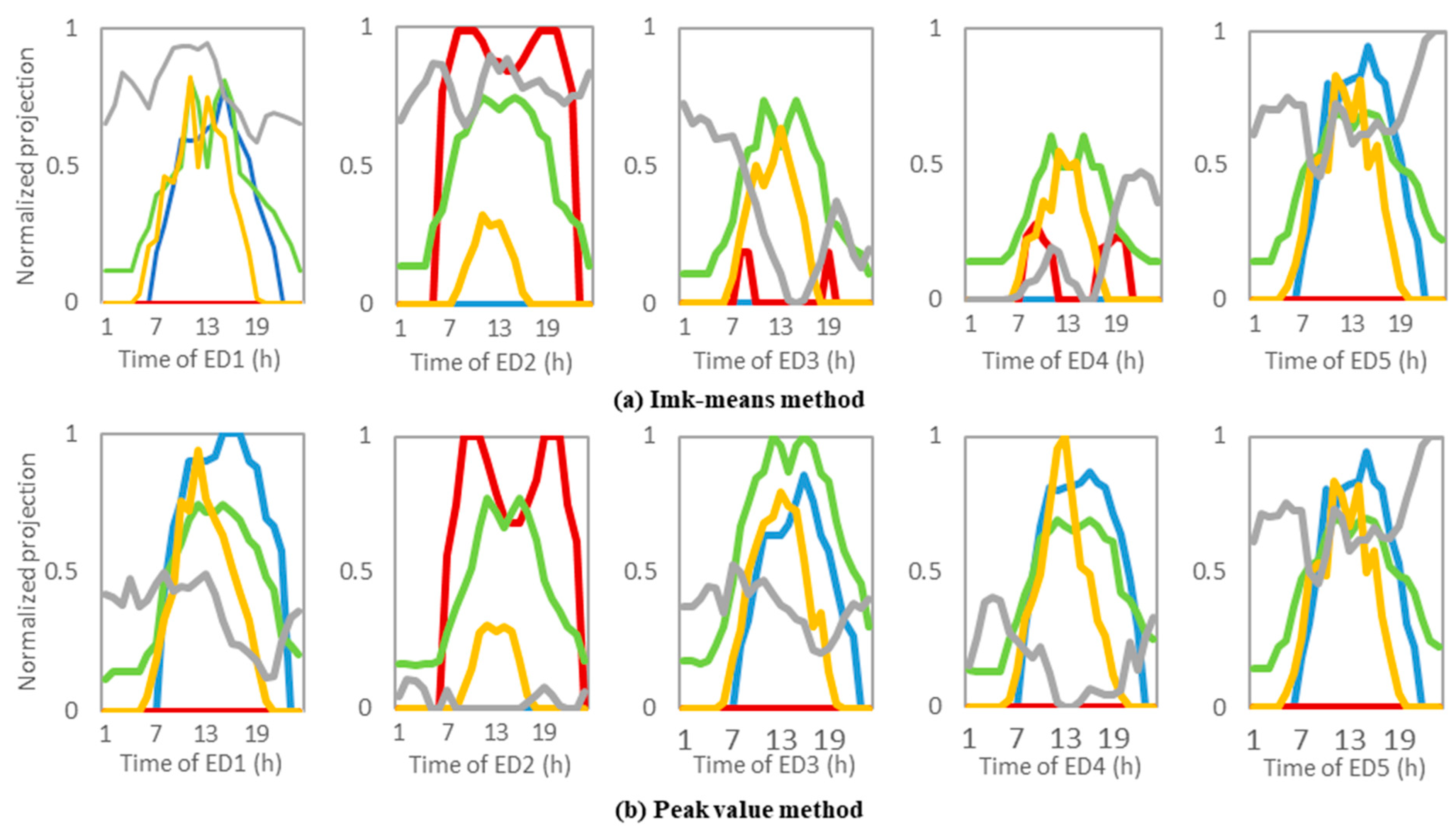
Figure 9 shows the normalized plots of the extreme days selected by different approaches. Five extreme days, ED1–5, were selected using two methods from top to bottom. The proposed Imk-means clustering algorithm clustered attributes including cooling, heating, and electricity demands, as well as photovoltaic and WP. The peak value method obtained ED1–5 when the cooling, heating, and electricity demands, as well as photovoltaic and WP, had peak values in the dataset. The extreme days obtained using the Imk-means method were slightly different from those obtained using the peak value method. The curves of selected extreme days should greatly differ from each other. If two extreme days have similar profiles, this indicates that the selection of extreme days is unreasonable. The curves of the extreme days selected by the proposed method are almost different, while some curves selected by the peak method are very similar. Compared with the extreme days selected by the peak value method, the extreme days selected considering multiple factors change more drastically, which shows that the extreme days obtained using our method are more accurate. By performing a specific analysis on a certain day, it is found that, except for ED2, the heating demands in the other four days filtered using the peak value method are all zero. However, in real life, four days with zero heat loads means that they belong to the same period (and are likely all summer days). This choice results in the cluster results being too similar to each other, and is not conducive to analysis. For the extreme days selected using the Imk-means algorithm, the types of loads that are zero in the five days are different, so they are more representative of the different conditions throughout the year. It can be seen from the ED3 and ED4 obtained using the Imk-means method that their clustering attributes fluctuate drastically and that their peak values are prominent, indicating that the days selected using this method meet the “extreme” requirements. In addition, it can be seen from ED4 using the Imk-means algorithm that, although none of the loads reach their peak during the day, each curve fluctuates sharply, satisfying the performance of extreme days. This shows that, when considering multiple factors at the same time, the extreme days are not necessarily the same days that certain data values reach peak values. The proposed method in this paper can be used to filter out such extreme days. Through comparison, the ED5s obtained by the two methods are shown to be exactly the same. The proposed method in this paper can obtain the extreme days filtered using the peak value method, and can also obtain more reasonable results under the comprehensive consideration of multiple factors. It is clear that the Imk-means clustering algorithm can automatically filter out more reasonable typical and extreme days.
5.3. Optimization Results
The GA was used as an example to analyze the speed improvement and accuracy of the designed optimization. The parameters of the equipment are shown in
Table 3 [
34]. The SP system includes the EC and GB, whose capacities are obtained from the peak cooling and heating loads. The price of natural gas is 0.27 CNY/kWh [
8]. The GA parameter settings are listed in
Table 4.
The optimization results of the typical and extreme days obtained in
Section 5.2 were used as part of the initial population of the proposed optimization program, and their iterative process was compared with the improved and traditional GA, as shown in
Figure 10. Six days were randomly selected as the test set, and we tried to ensure that these days included days from all the seasons during the extraction process. The details of comparison test methods are as follows: comparison test 1 used an accelerated GA, in which the typical and extreme days were selected based on the cooling demand and peak values, respectively; comparison test 2 used another accelerated GA, whose typical and extreme days were selected based on the electrical demand and peak values, respectively; comparison test 3 used the traditional GA without acceleration.
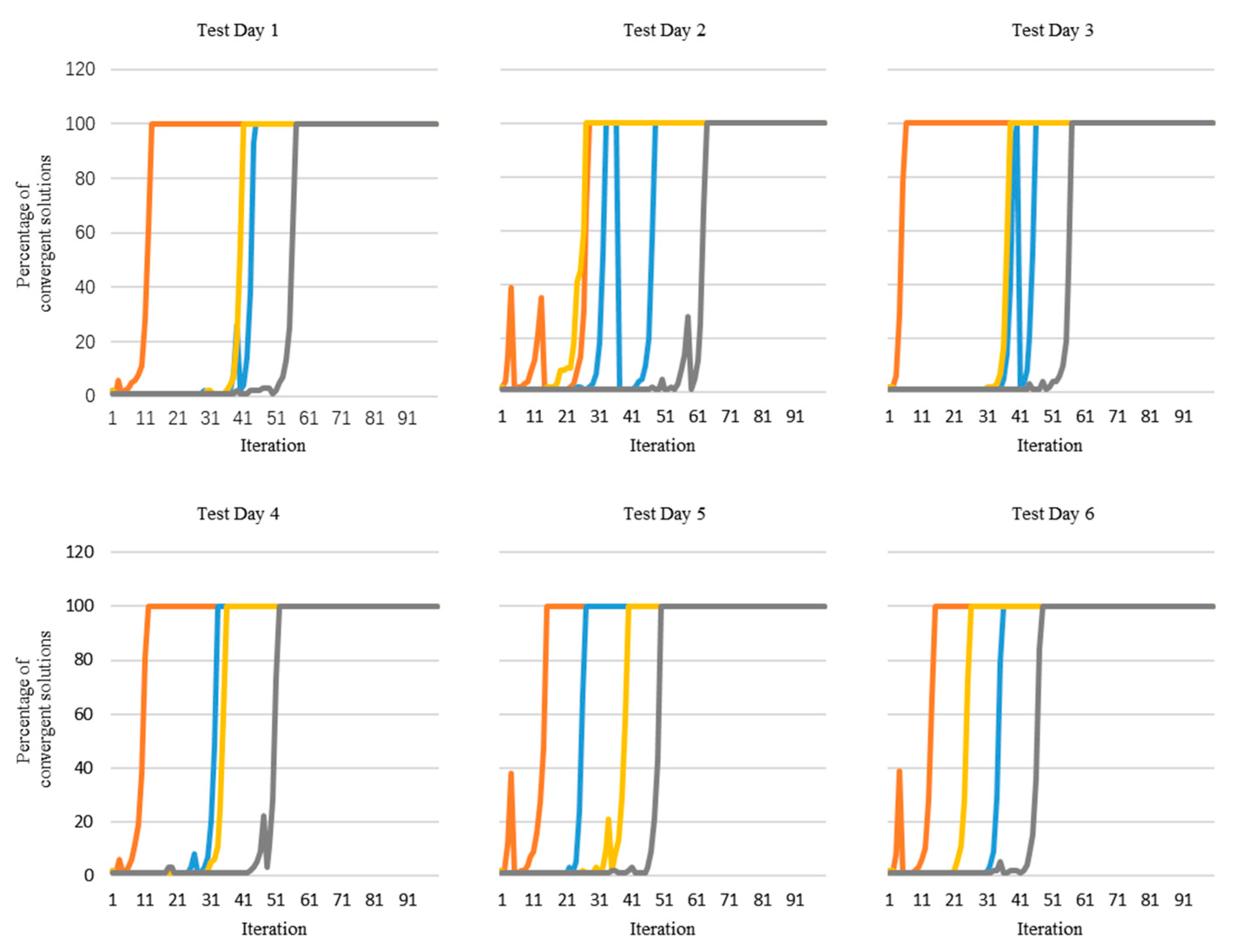
From
Figure 10, it can be seen that, compared with the three comparative tests, the proposed optimization method in this study always achieved the fastest convergence. The other optimization which replaced the initial population always converged faster than the traditional GA. Therefore, it can be concluded that a suitable replacement for the initial population can indeed accelerate the convergence of optimization algorithms, and that the proposed replacement method in this paper is a more appropriate method for accelerating optimization.
To avoid contingency of the results, we ran each method 10 times to observe the average convergence rates, as listed in
Table 5. The four different optimizations are the proposed method and the three other methods of comparison test 1, test 2, and test 3. From the data in
Table 5, it can be seen that the conclusions are the same as those obtained from
Figure 10. The proposed optimization method in this paper always converged faster.
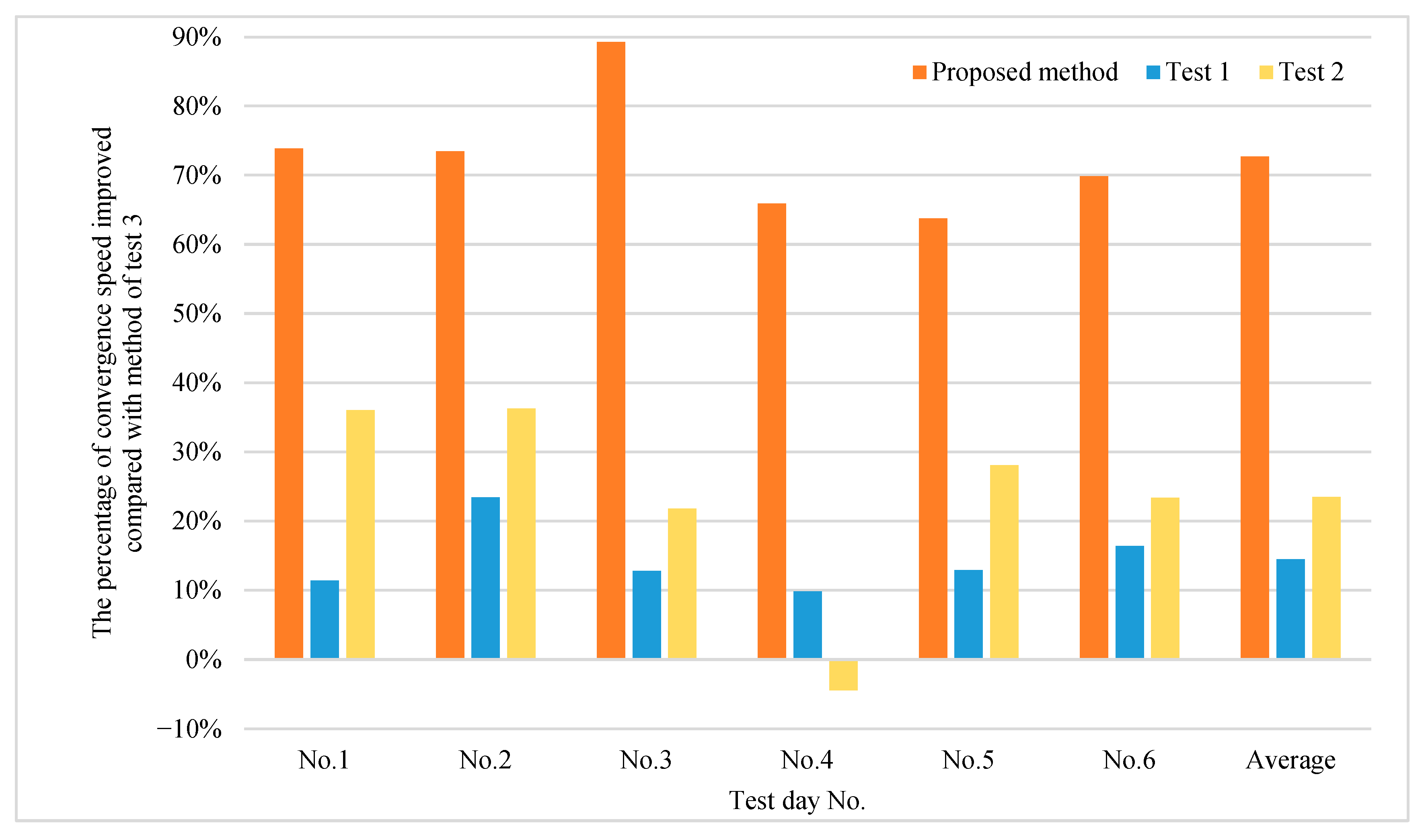
Figure 11 shows the percentage of convergence speed for the proposed method and methods of tests 1 and test 2, compared with the traditional GA used in test 3. In the randomly selected test set, the improvement in speed of the proposed method could reach up to 89.29% at best, and 72.68% on average, compared with the traditional GA. It can be seen that the proposed optimization method in this paper is, on average, 58.22% faster than the method used in test 1, and 49.17% faster than the method used in test 2. In addition, it is worth noting that the data obtained on the fourth test day in test 2 could not effectively accelerate the optimization algorithm, showing that the obtained typical and extreme days do not cover the fourth test day. This shows that the typical and extreme days obtained by the proposed method are more realistic and reliable. In summary, the proposed method can always converge faster than the other acceleration methods.
To verify that the acceleration does not lose optimization accuracy, we compared the results of the two optimizations (proposed and unaccelerated) and summarize them in
Table 6. The larger values of these parameters indicate better results.
To judge whether accuracy is lost more intuitively, we included parameter
, which is the difference between the results of the proposed optimization and traditional GA. If
, this proves that there is no loss of accuracy. Especially, if
, this indicates that the optimized result after acceleration is better, as shown in
Table 7.
By observing the parameter for the energy, economic, and environmental indexes, and the weighted objective I, it can be seen that the weighted objective values of the proposed optimization are all better than the traditional GA. Though parameters have negative values, −0.00051, −0.01406, and −0.001837, the other indices will counteract these negative values. Thus, the proposed optimization algorithm in this study does not reduce the optimization performance and even can improve it to a certain extent. Therefore, the case study demonstrates that the proposed optimization method can greatly increase the calculation speed without losing optimization accuracy. The optimization results of the improved algorithm are very close to those obtained by the traditional algorithm, and their hourly output plans are almost identical. Thus, the differences in their output plans will not be discussed in the case study of this paper.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}