1. Introduction
Wind clustering plays an important role in determining the various aspects of the research objective, such as energy, engineering, and public safety. Therefore, the usage of the relevant clustering method is basically determined by the objective of the study and the parameters involved in the study. The sensitivity of the data also plays an important role in determining the method of clustering. It is important for the researcher to have an expectation of what the result should be and will be so that the method can be used efficiently.
This paper focuses on a comparison of the clustering methods used by researchers in terms of wind speed clustering. The areas considered in this paper are in Malaysia, Qatar, France, Iran, Turkey, the United States, India, South Africa, Switzerland, and Columbia.
The winds in Malaysia are influenced by two monsoon seasons: the southwest monsoon from late May to September and the northeast monsoon of Peninsular Malaysia from November to March. The heavy rain to the east of Peninsular Malaysia and of western Sarawak is caused by the northeast monsoon, whereas the southwest brings drought to the nation [
1].
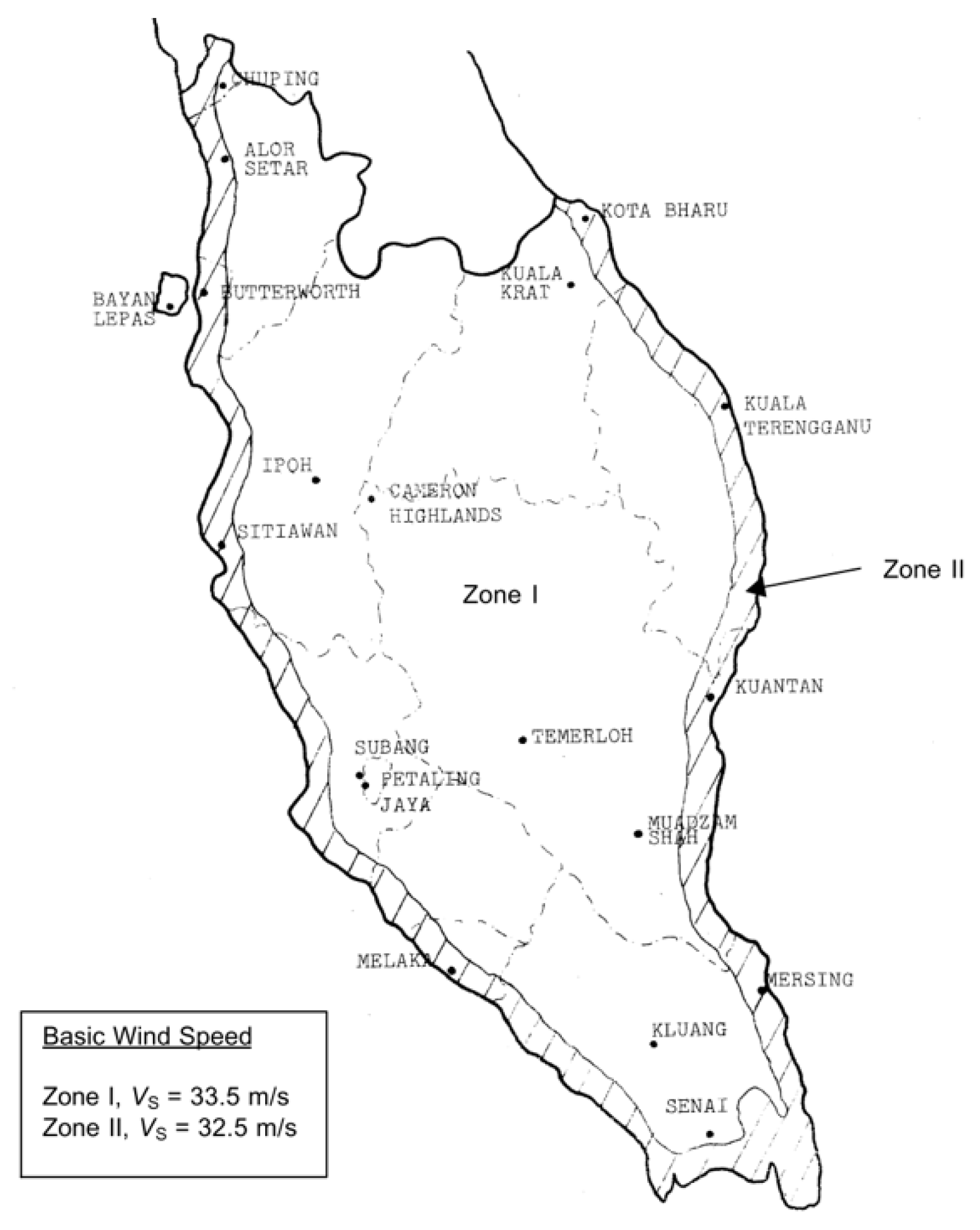
Figure 1 shows the northeast monsoon storms; the east of Peninsular Malaysia and Mersing are the windiest areas of Peninsular Malaysia. Therefore, according to various wind energy potential research studies in Malaysia, Mersing is often the best location for wind farming [
2].
The monitoring of the wind speed trend is crucial for the prediction of future events or in seeing the continuity of the wind supply in certain areas. For example, the mapping conducted and adopted by the Malaysian Standard Code of Practice on Wind Loading for Building Structure uses mean wind speed. The standard is used by engineers in Malaysia, especially mechanical engineers and those involved with civil structures, to predict the wind speed in such areas as telecommunication antenna deployment. The mean wind speed usage may increase in a given year, as previously reported by Young in 2011.
Figure 2 shows the recommendation by the Malaysian Standard on Basic Wind Speed with regard to a mean wind speed of 33.5 m/s [
3].
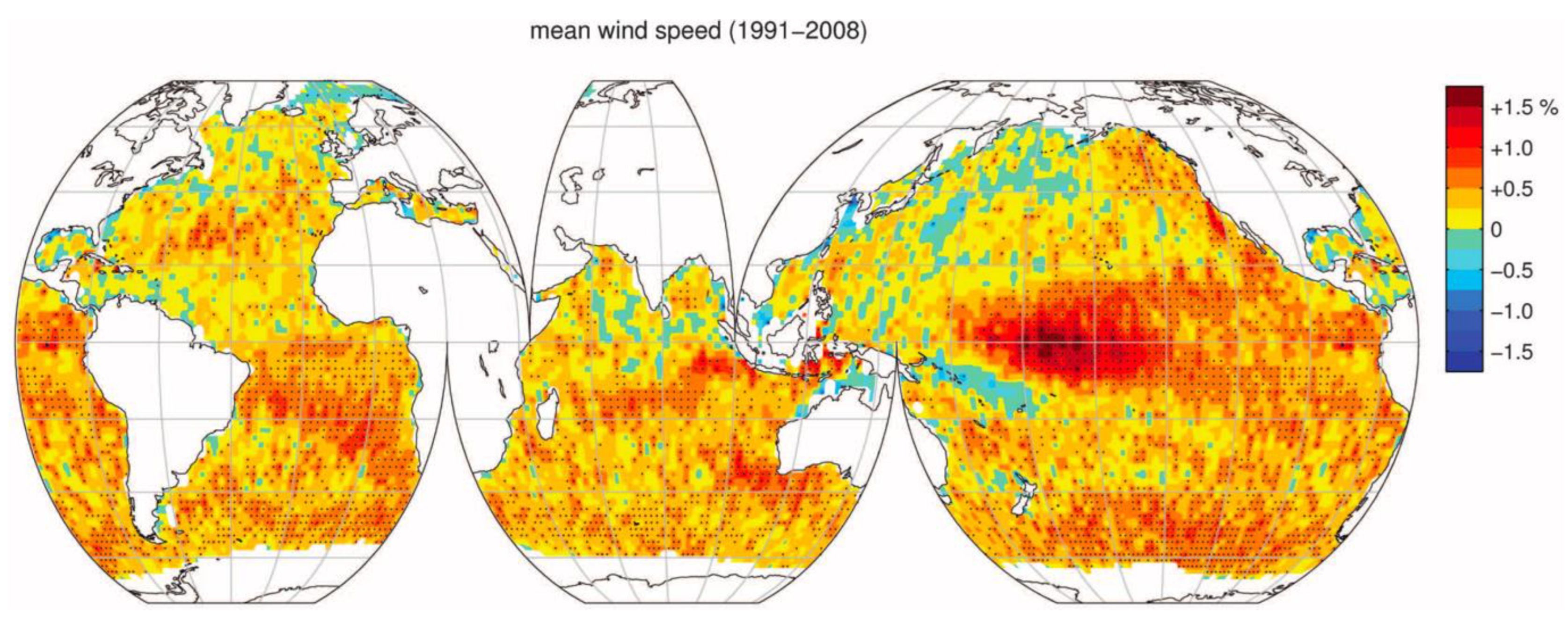
The global trends show that wind speed is increasing. Based on research in 2011, the global wind speed is increasing, indicating that extreme events are growing faster than the mean condition. The wind speed of most of the world’s oceans has increased by at least 0.25% to 0.5% per year. The strongest increasing trend was found in the southern hemisphere, and the northern hemisphere, especially the central North Pacific, shows a negative trend in wind speed. The wind speed increase in the central North Pacific was less than 0.25%, and some areas show a negative trend. As shown in
Figure 3 below, the area surrounding Malaysia is also experiencing an increasing trend, especially in the southwest of Malaysia, where the southern Indian Ocean is located [
4].
A study conducted in 2019 confirmed the above research by Young in 2011. As shown in
Figure 4a, the research found that the global mean annual wind speed had increased for the previous ten years and that the pattern was increasing yearly. The Asian mean annual wind speed is also showing an increasing pattern. However, the wind speed in the Asian region began to increase earlier than the global speed. As shown in
Figure 4b, the increase in wind speed in the Asian region started as early as 2002, whereas the global mean annual wind speed has been increasing since 2010. The research uses the diagnostic statistic for regression, which includes the goodness of fit, R
2, and the Pearson correlation coefficient, P. A Pearson correlation coefficient of less than 0.001 was considered be satisfactory in this study. However, the research found oscillation patterns that decreased the global wind speed; therefore, according to this research, wind energy production may decrease in the future [
5].
In 2003, a study was conducted on the coastline of Peninsular Malaysia. The study focuses on analyzing the annual vector mean wind speed and direction according to two seasons, i.e., the northeast and southwest monsoons. The wind direction was northeast during the northeast monsoon season and southwest during the southwest monsoon season [
6].
Research conducted in 2015 by Kok et al. found that the dynamics of the wind stress system had an important influence on the physical characteristics of the sea. The study used a wind stress curl to examine the mechanism responsible for the formation of the thermal front during both Malaysian monsoon seasons [
7].
The positive and negative values of the wind stress curl cause cyclonic and anti-cyclonic motion in the northern hemisphere. This action causes divergence of the convergence in the surface layer of seawater. Therefore, the cooler or warmer water from the deep rises and replaces the diverging or converging water. This results in the upwelling and downwelling of the seawater. This upwelling is caused by the wind, which makes the water close to shore cooler [
8].
Therefore, with regard to all of the wind characteristics mentioned, there is a need for wind trend monitoring and clustering, especially in Malaysia. Factors such as global warming have increased the temperature of the sea, causing the fluctuation in the global wind speed [
9]. When wind standards commenced in 2002 in Malaysia, the need for wind clustering was foreseen; wind clustering can increase the accuracy of wind mapping and wind forecasting in Malaysia.
It is important for engineers and wind experts to able to see the wind trend and clustering according to objectives such as those considering area or demand. Each objective can show different results, which also depend on the method of clustering used. This paper aims to investigate the best method to cluster the wind trend. The specific objective is to determine the best method to cluster the wind trend in relation to the Peninsular Malaysia and Borneo regions.
3. Recommendation and Conclusions
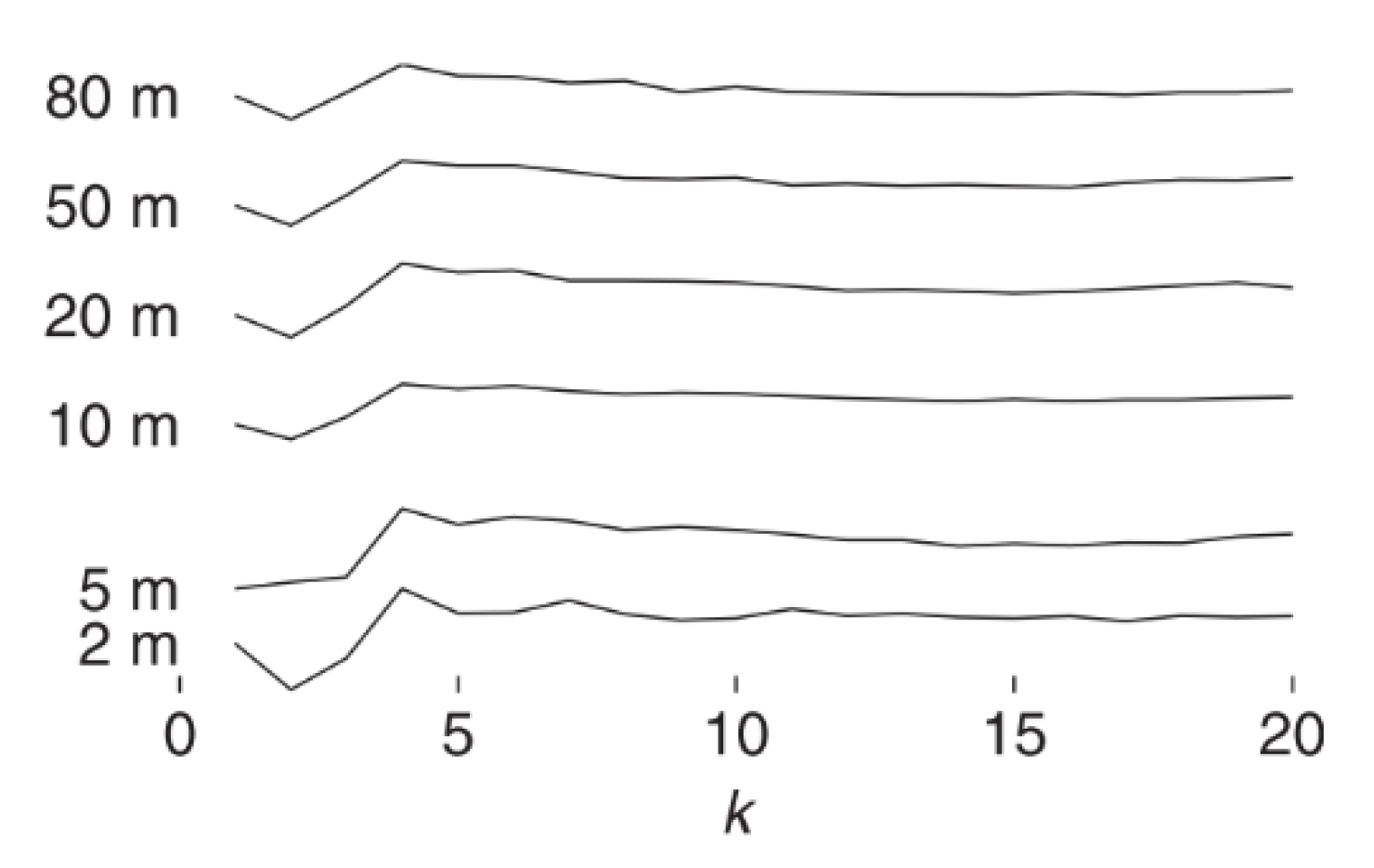
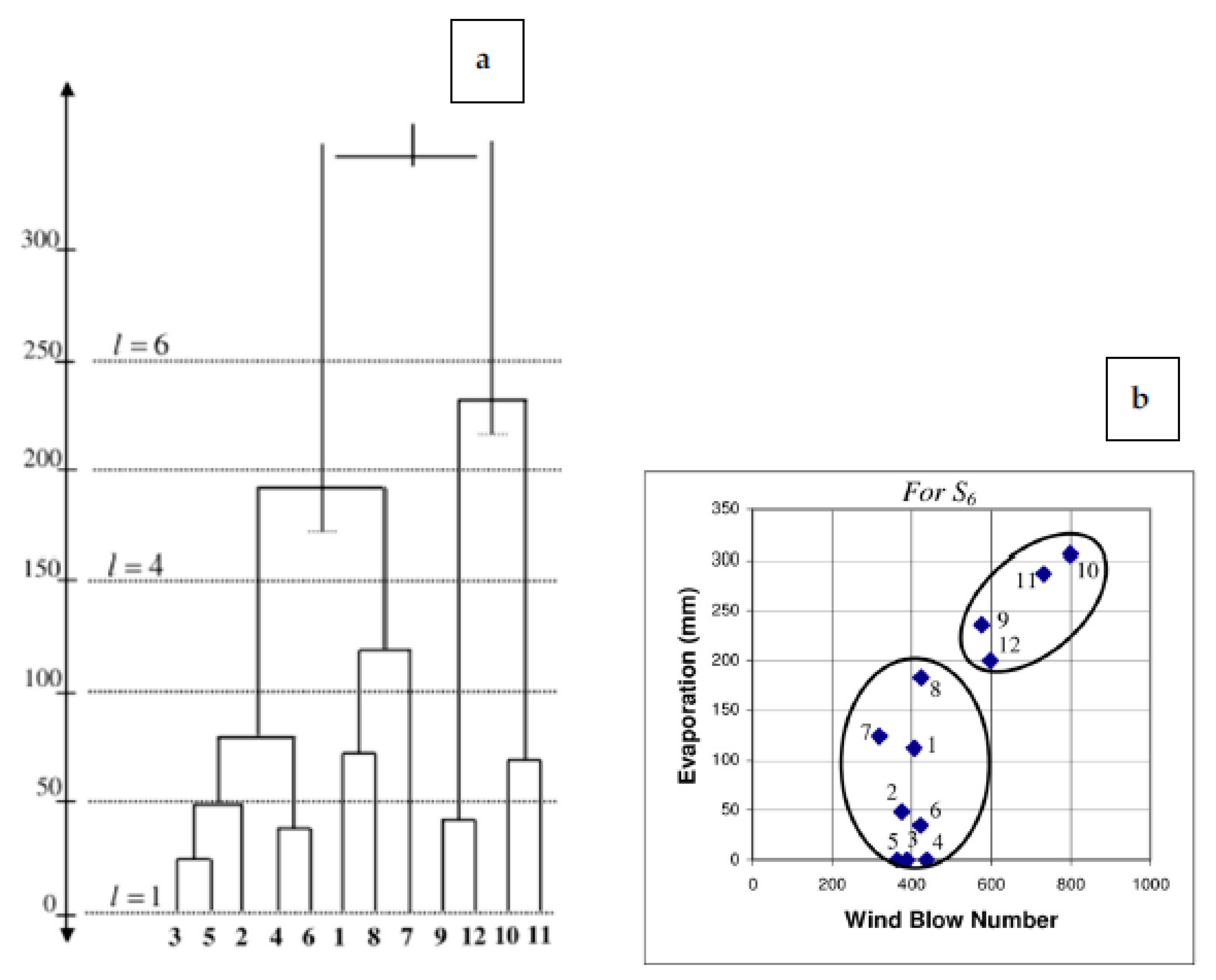
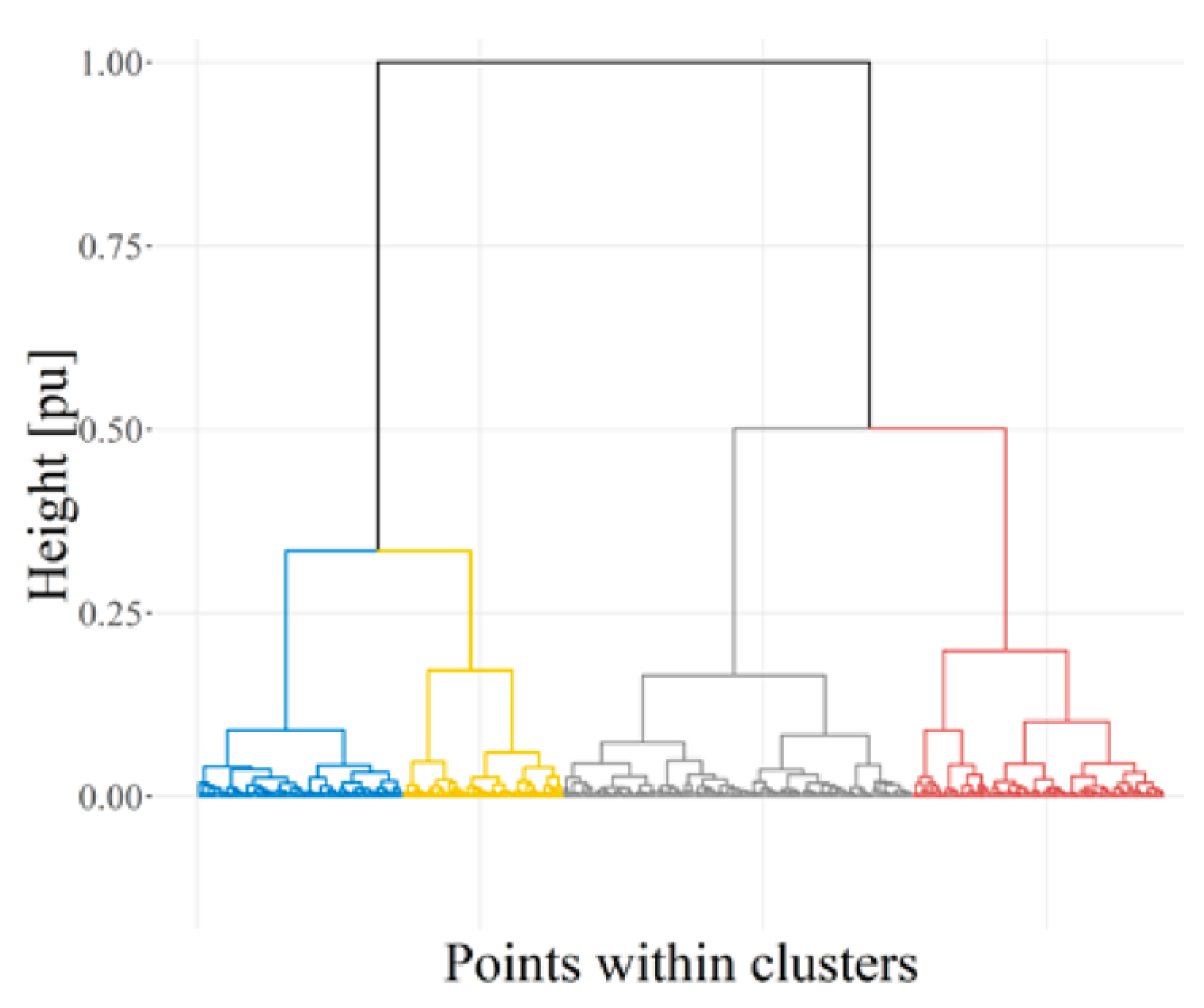
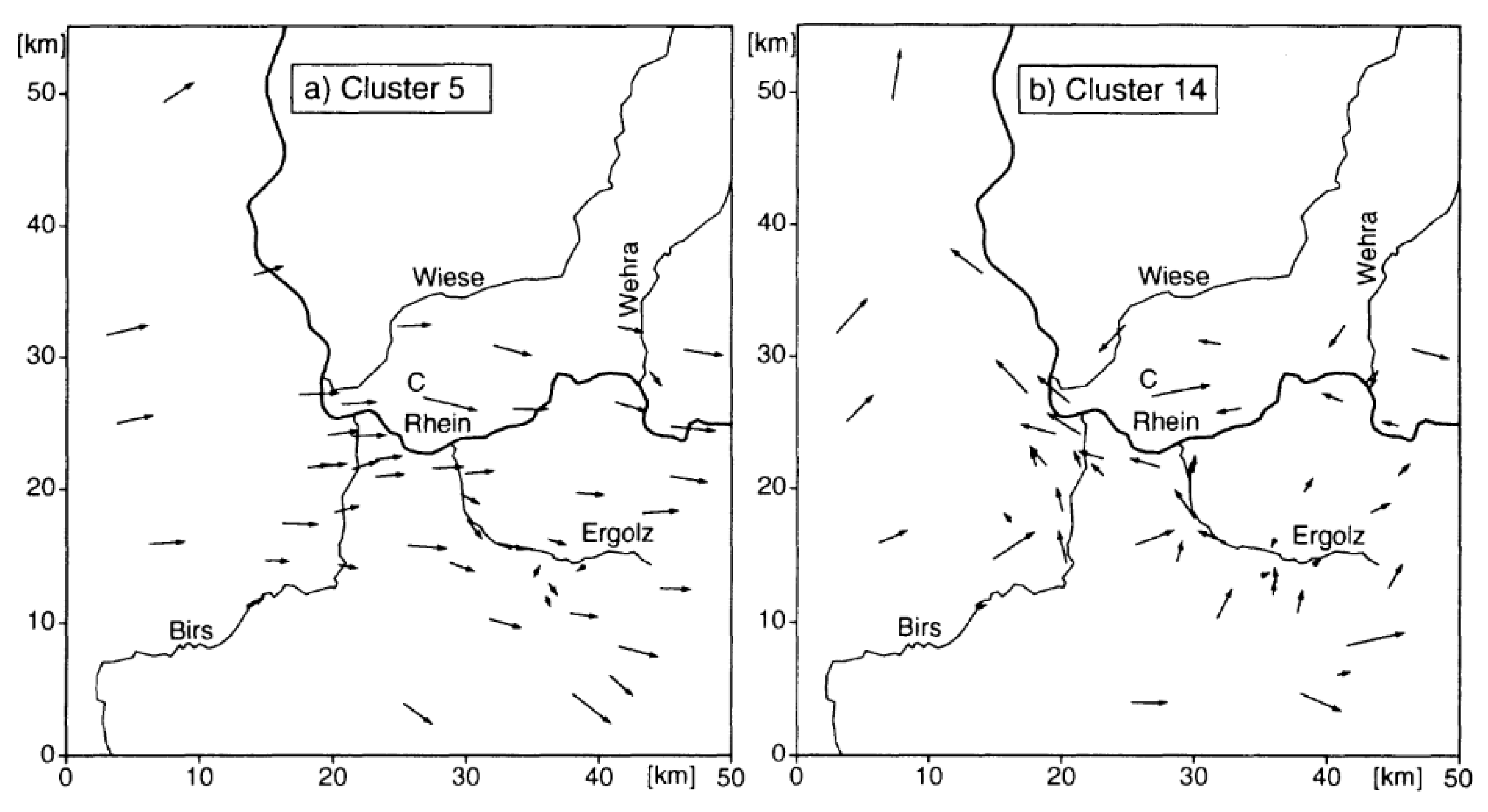
As mentioned in the above topics, there are many methods of clustering used to cluster wind speed. The non-parametric hierarchical clustering using the mutual neighbor distance algorithm shows a complex method of clustering and an acceptable result. The method showed an efficient operating decision and made accurate predictions during research [
20].
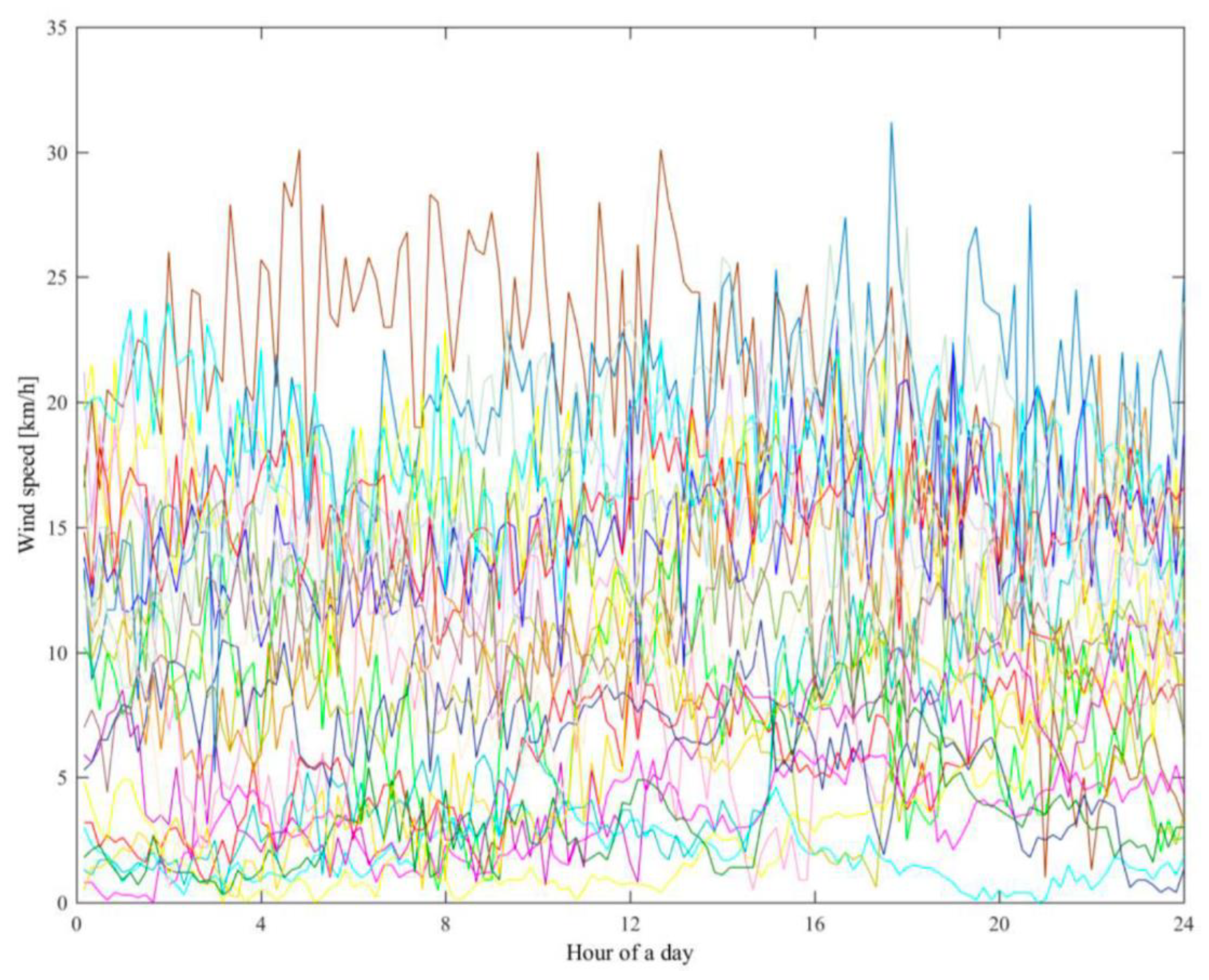
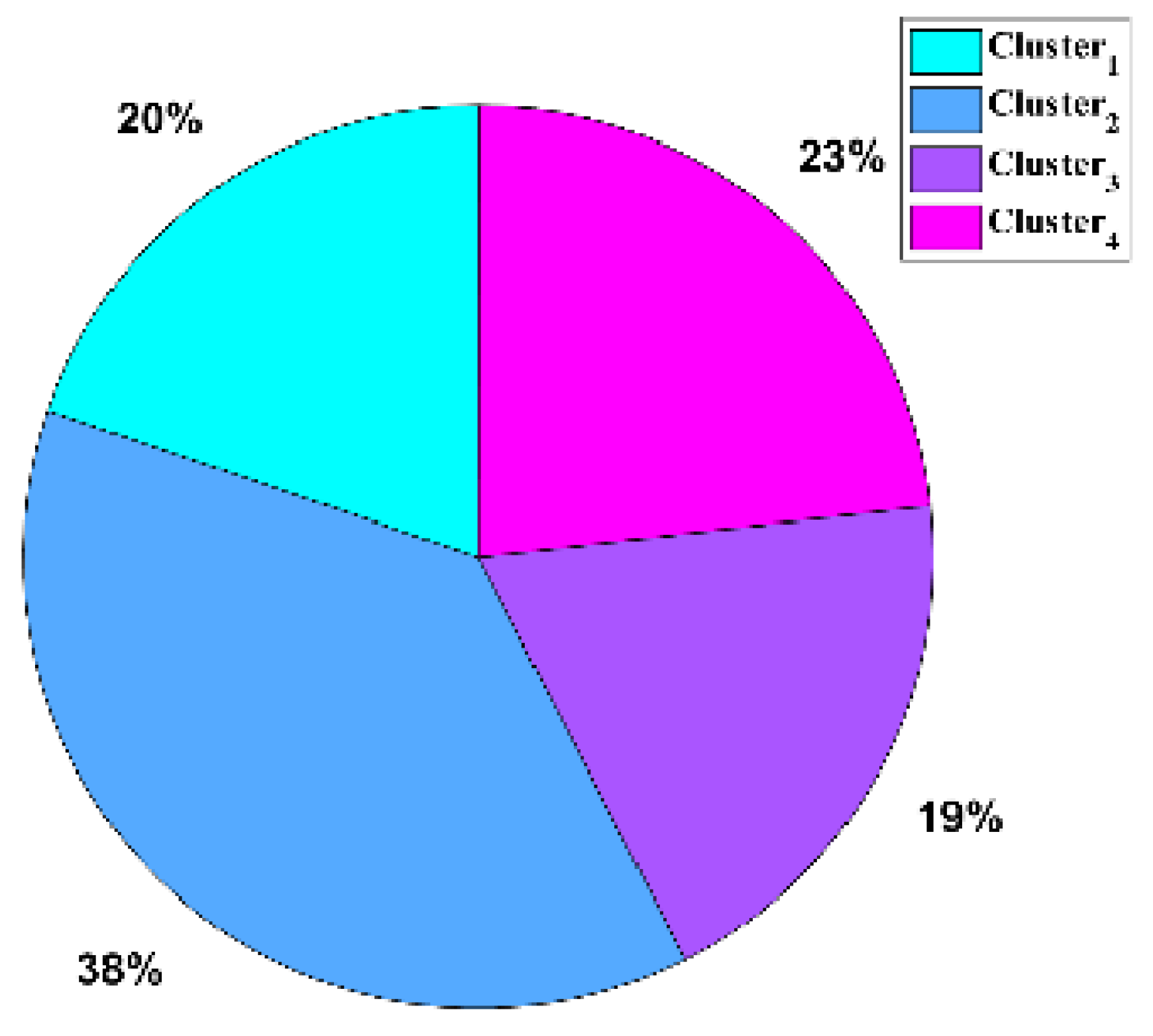
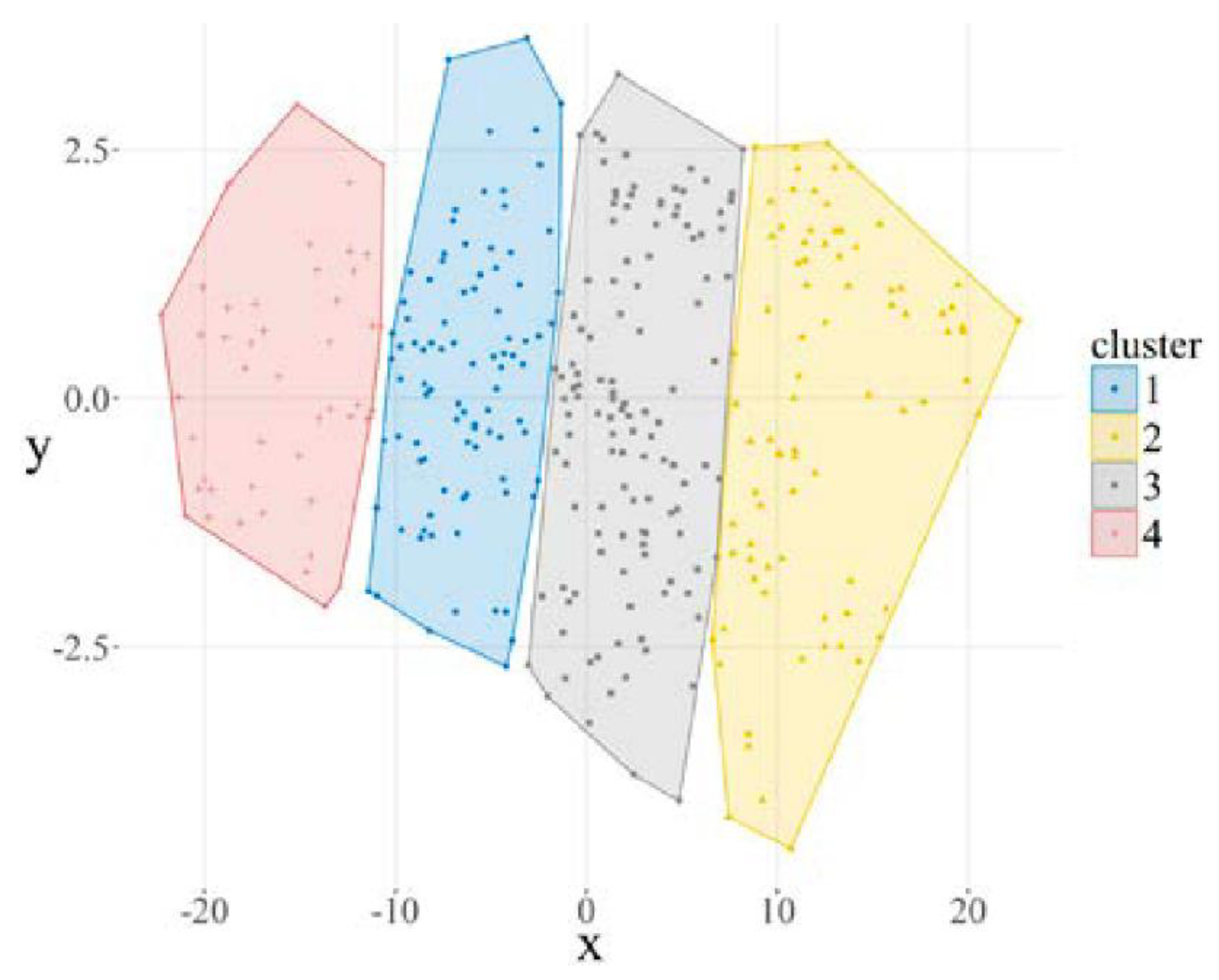
The trend-based time series clustering shows that the method produces excellent accuracy. Even though the research focuses on forecasting the wind speed, the study shows that the wind speed can be clustered according to its trend. This was shown in the research of Kushwah et al. for the yearly trend. Therefore, the trend can be predicted as it follows a seasonal pattern, and the application of this research is good for research with a localized wind speed trend prediction. The clustering using the trend-based method was successfully shown in the research of Vuuren et al., where the researchers successfully clustered the mean daily wind speeds for the high demand season using the clustering large application algorithm (CLARA).
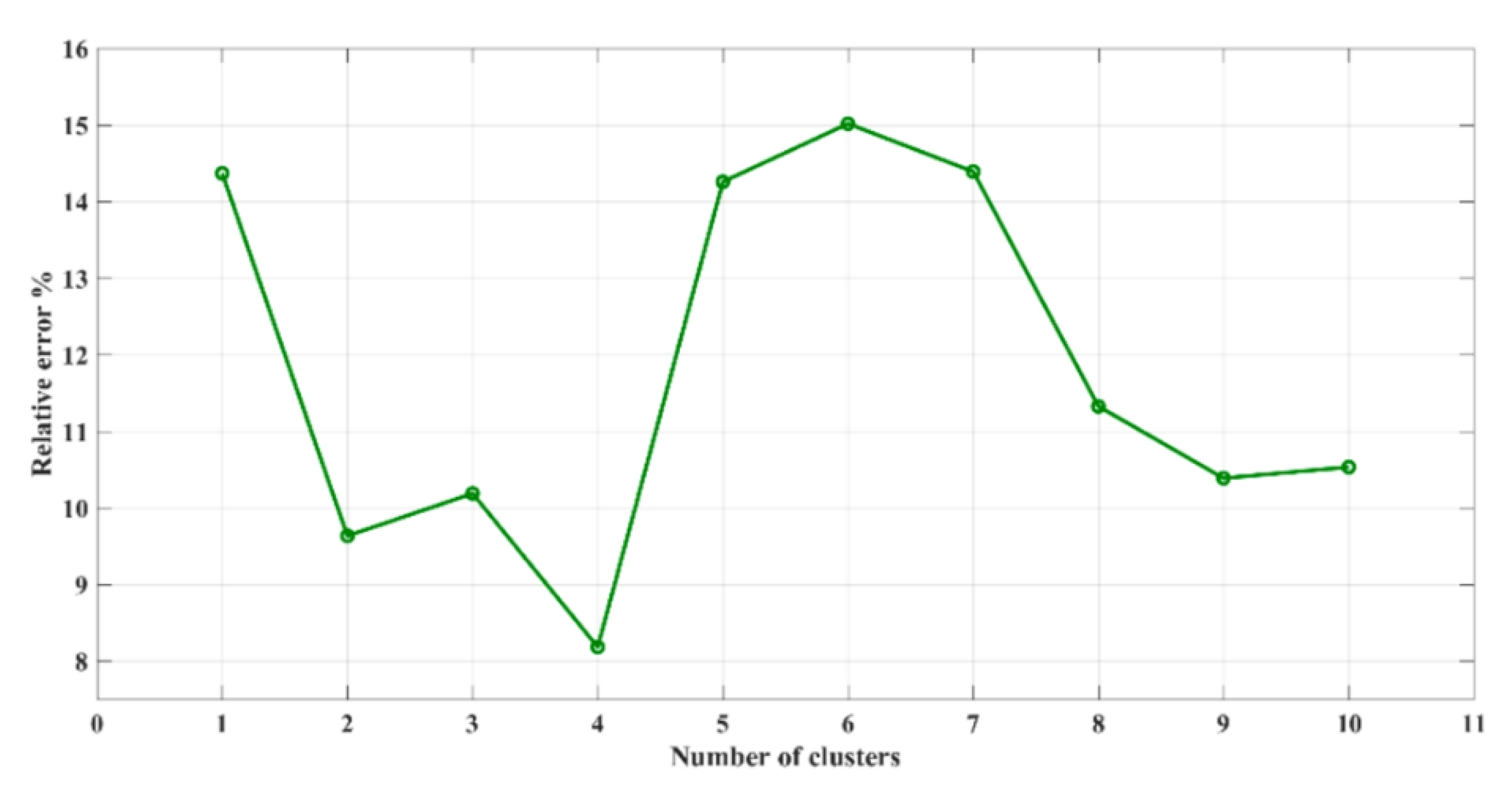
However, there are two main methods that the wind clustering researcher usually uses: the k-means and the Ward methods. Both methods are based on the k-value to determine the partition size of the cluster. The cluster size is important to the researcher when determining the number of desired clusters according to the research objective.
For the k-means method, the algorithm gives no guidance for the numbers of k. However, Ward’s method gives some partition sizes of k, which should be within the partition size of k + 1. Therefore, Ward’s method does not produce a sum of squares as small as that of the k-means method. Between the k-means method and Ward’s method, Ward’s method gives more accurate results compared to the k-means method. The trade-off for this accuracy aspect is that due to its complexity, Ward’s method takes more time to be calculated and shows less error, as shown in the
Table 8 and
Table 9 below, produced by the Azizi et al. in 2019.
Therefore, with regard to the essence of the accuracy of wind clustering, Ward’s method shows higher precision compared to the other clustering methods. The method is also easily applied to numerous parameters, such as speed, direction, frequency, and others, to suit the researcher’s target objectives. This paper focuses on the best method of wind clustering according to wind speed. Therefore, it was found that to cluster wind speed at a particular location and a period of time, the clustering should be able to segregate a timelapse, such as with wind speed trend clustering.
Table 10 below shows the comparison of each method discussed in this research.
It concluded that in terms of accuracy, readability in machine learning software, and larger datasets, the most suitable method to cluster the wind trend nationally is the Linkage–Ward clustering method. The selection of the Linkage–Ward clustering method is due to the impact of the result and its accuracy. Although the calculations using Ward’s method are more complex than those of the other methods, due to impact of the result the complexity can be ignored. The result of the research aims to create a guideline for researchers, engineers, and wind experts to improve the knowledge and design, especially regarding wind speed trends. The impact of the finding will be on the civil design, wind harvesting, and weather safety sectors.


































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}