
LSTM-Pearson Gas Concentration Prediction Model Feature Selection and Its Applications

Abstract
:1. Introduction
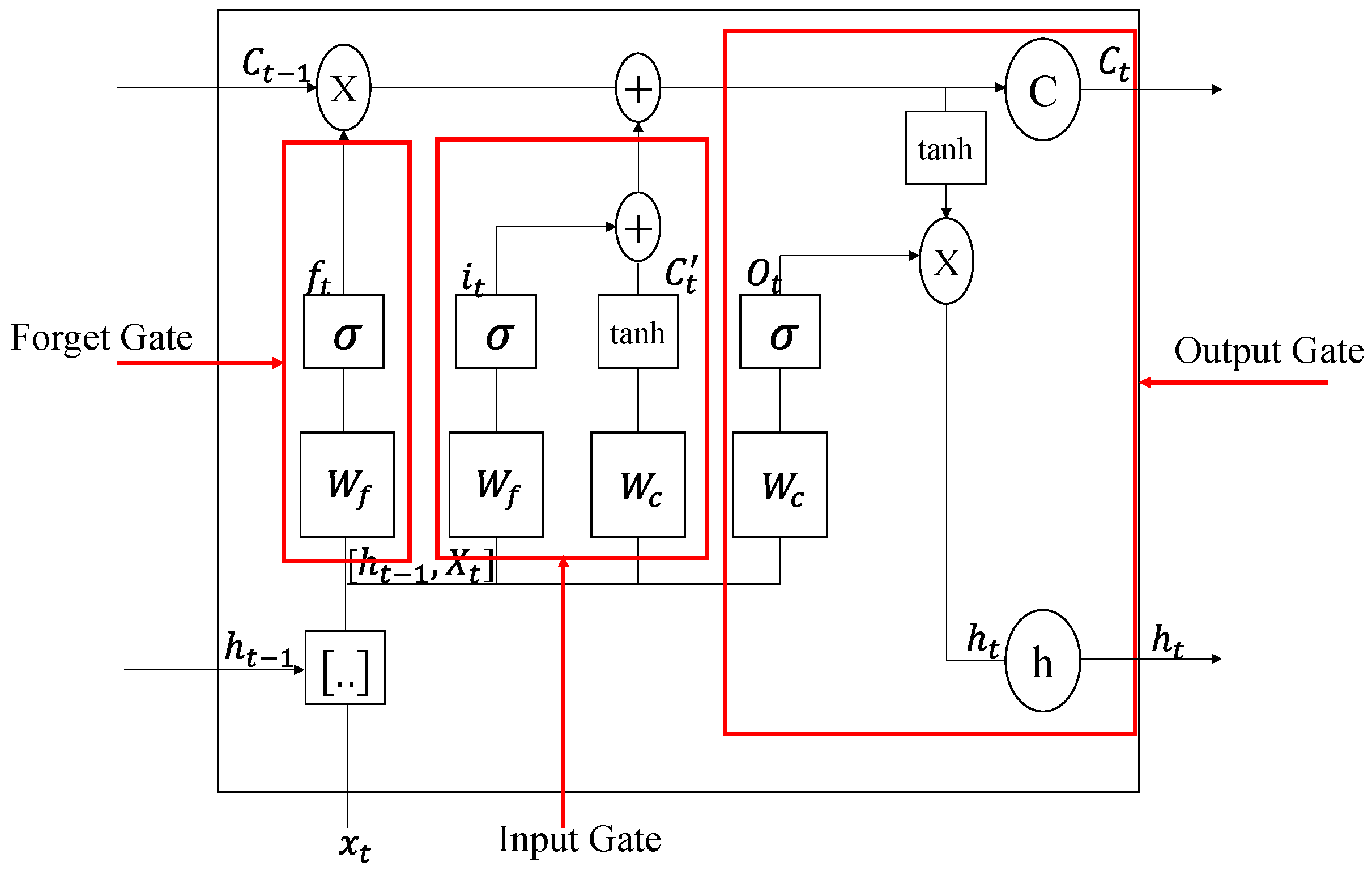
2. Long Short-Term Memory (LSTM) Neural Networks
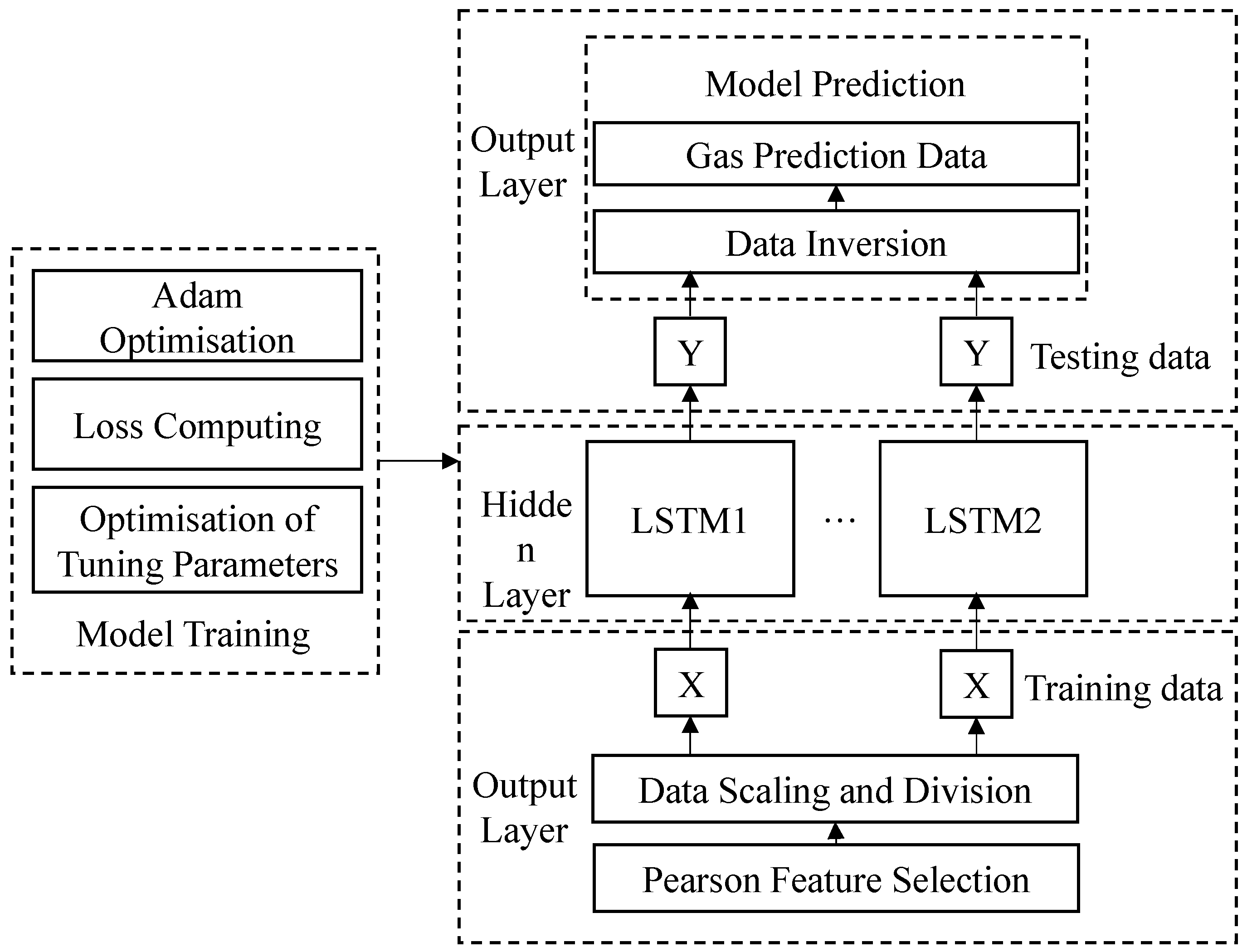
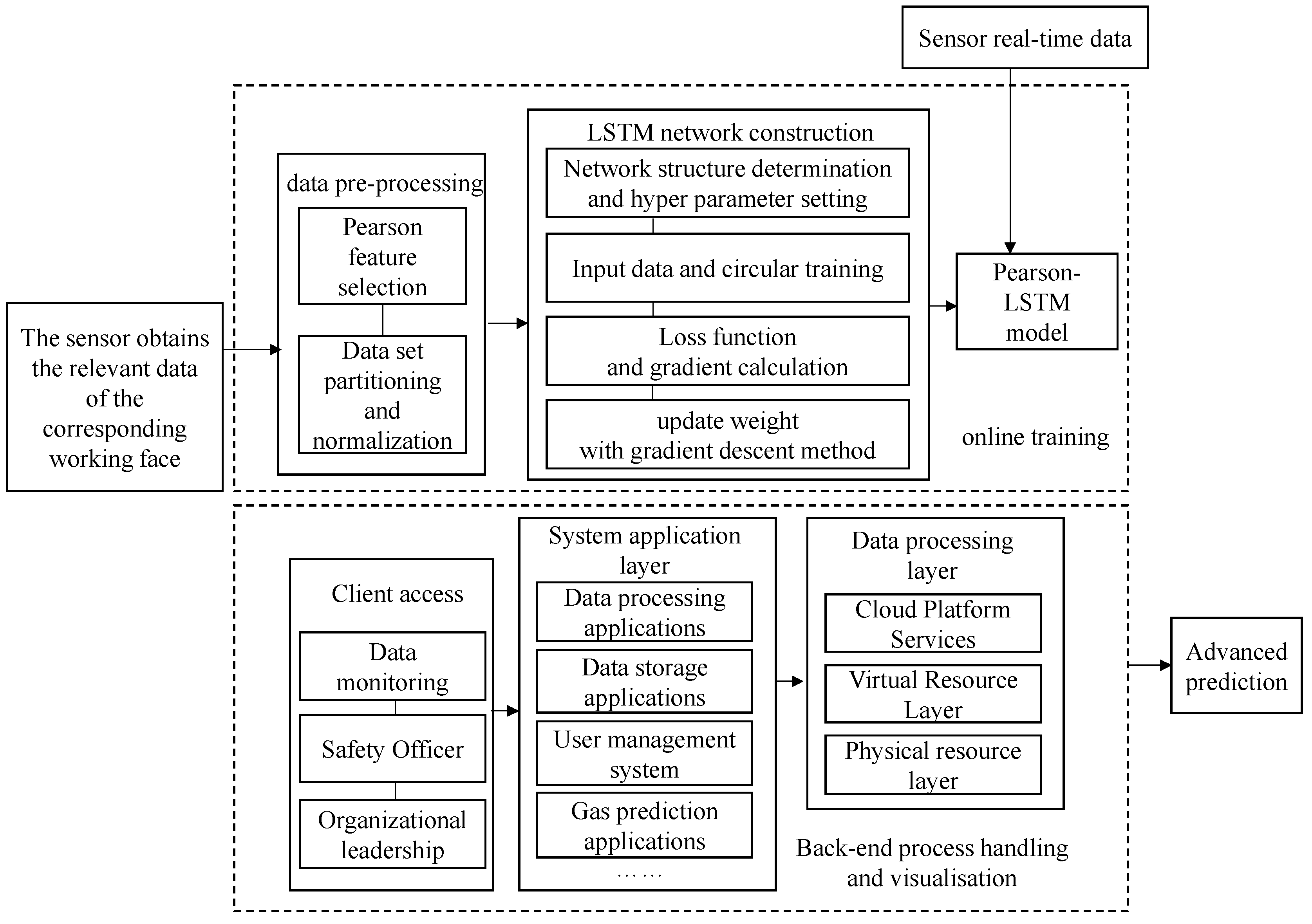
3. Construction of a Gas Concentration Prediction Model in a Working Face
4. Example Analysis
4.1. Correlation Analysis
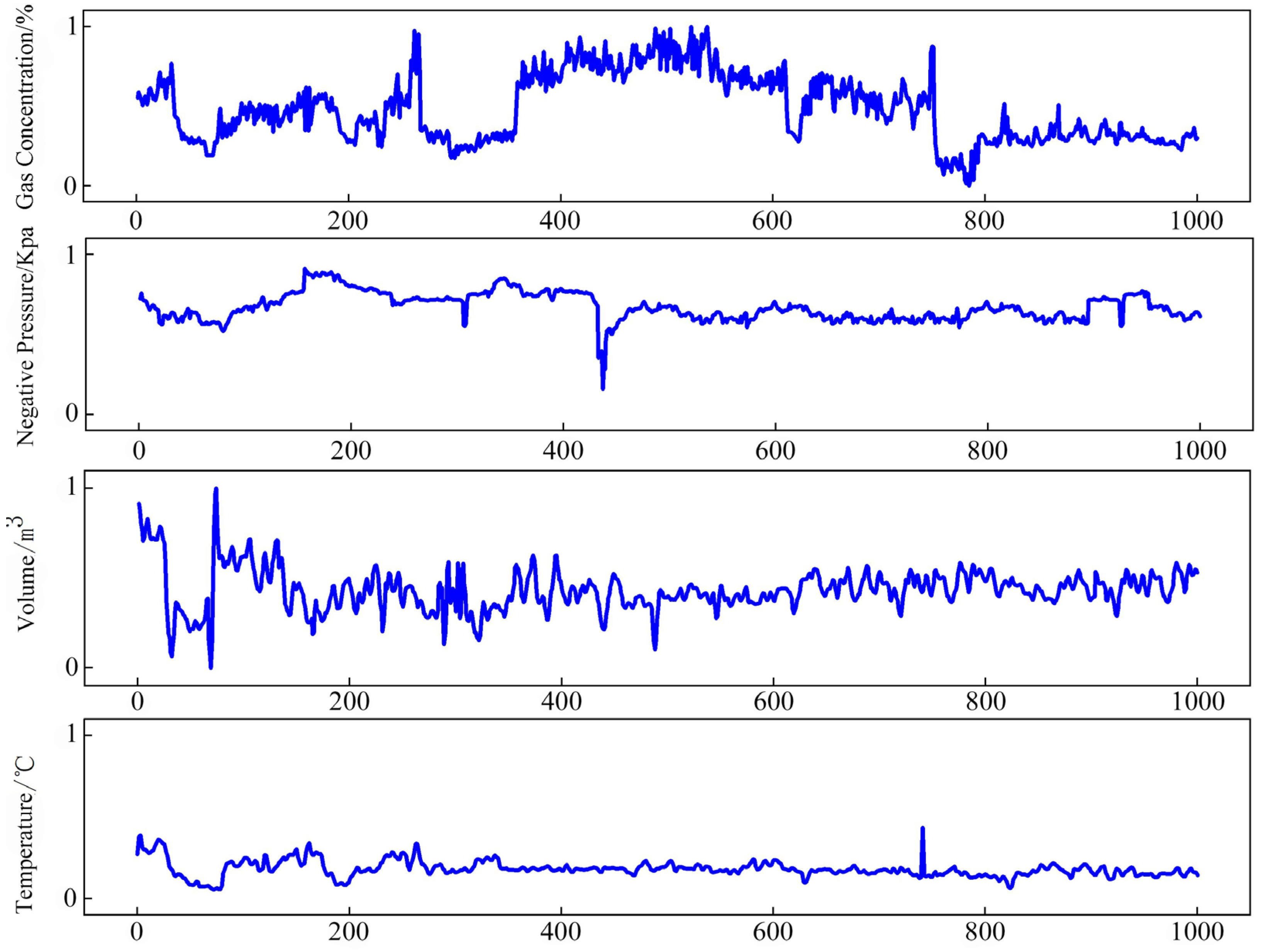
4.2. Data Preprocessing
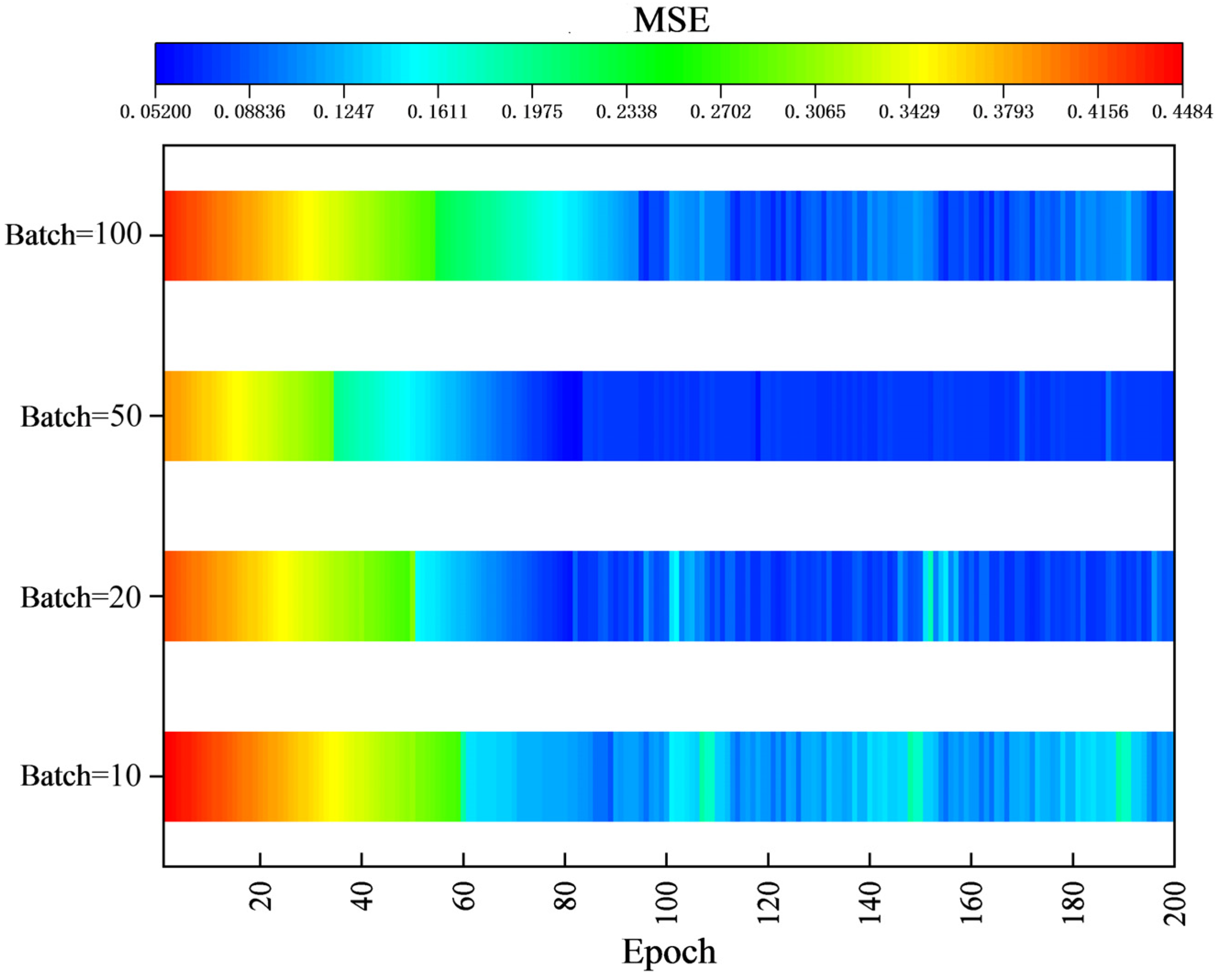
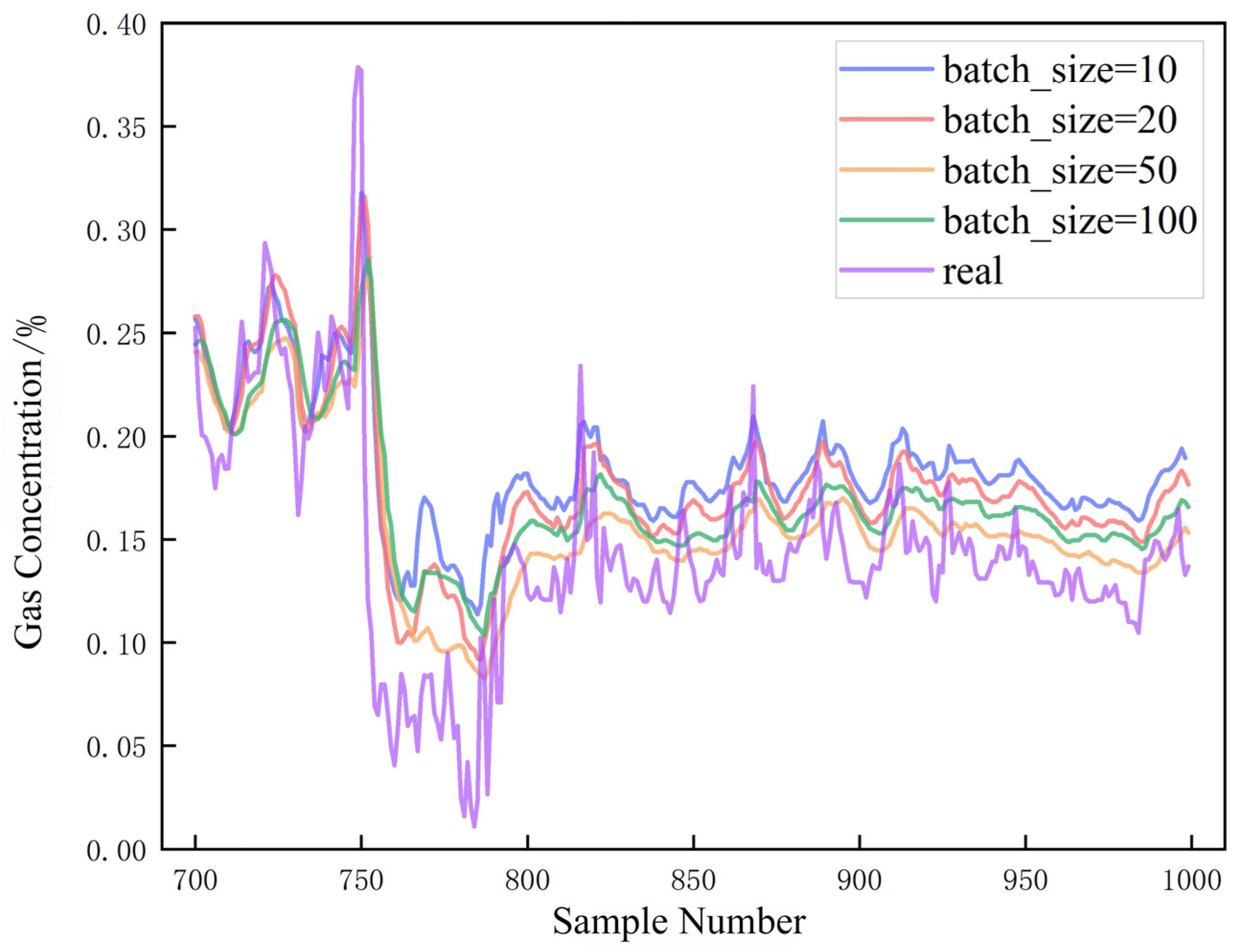
4.3. Batch Size Tuning
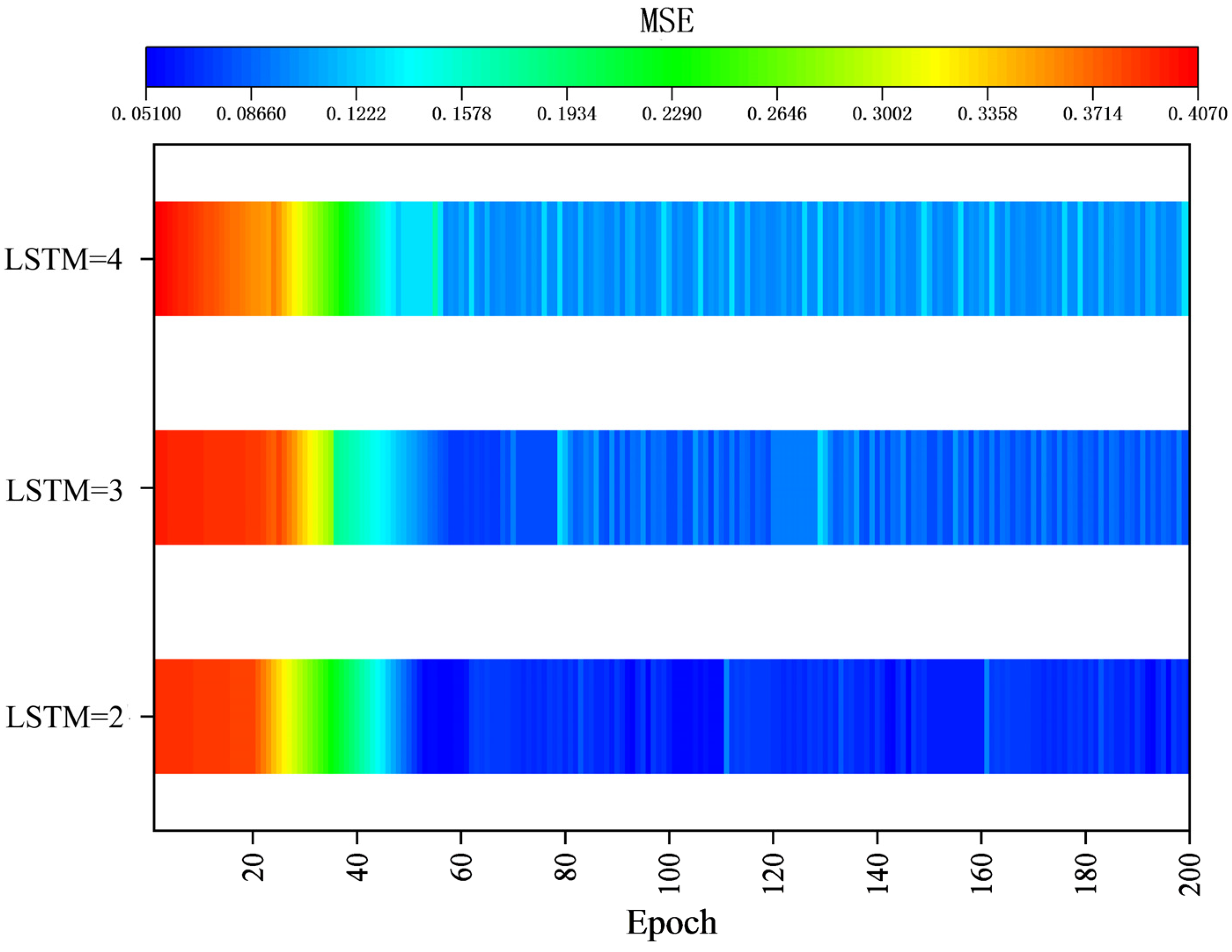
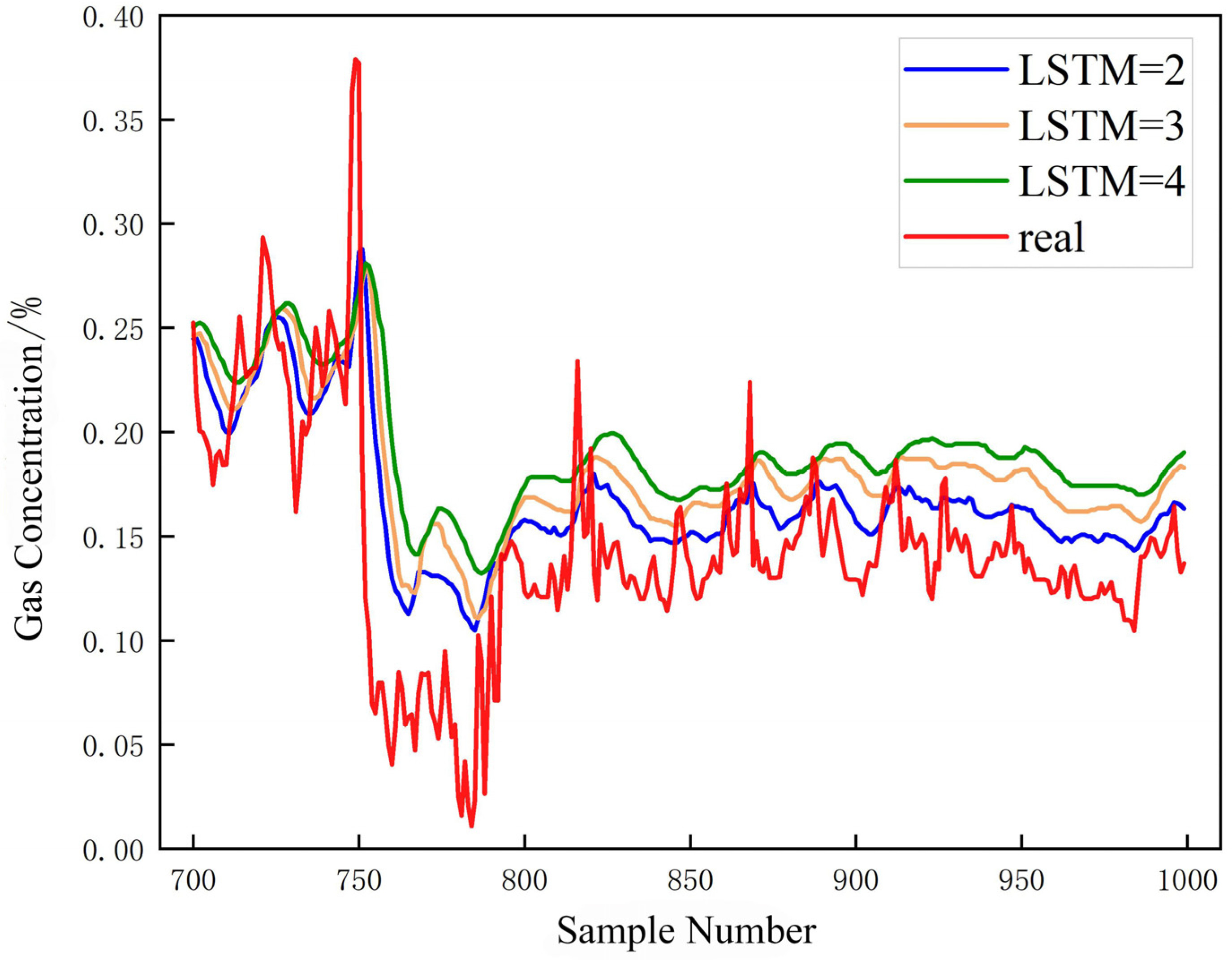
4.4. Network Layer Tuning
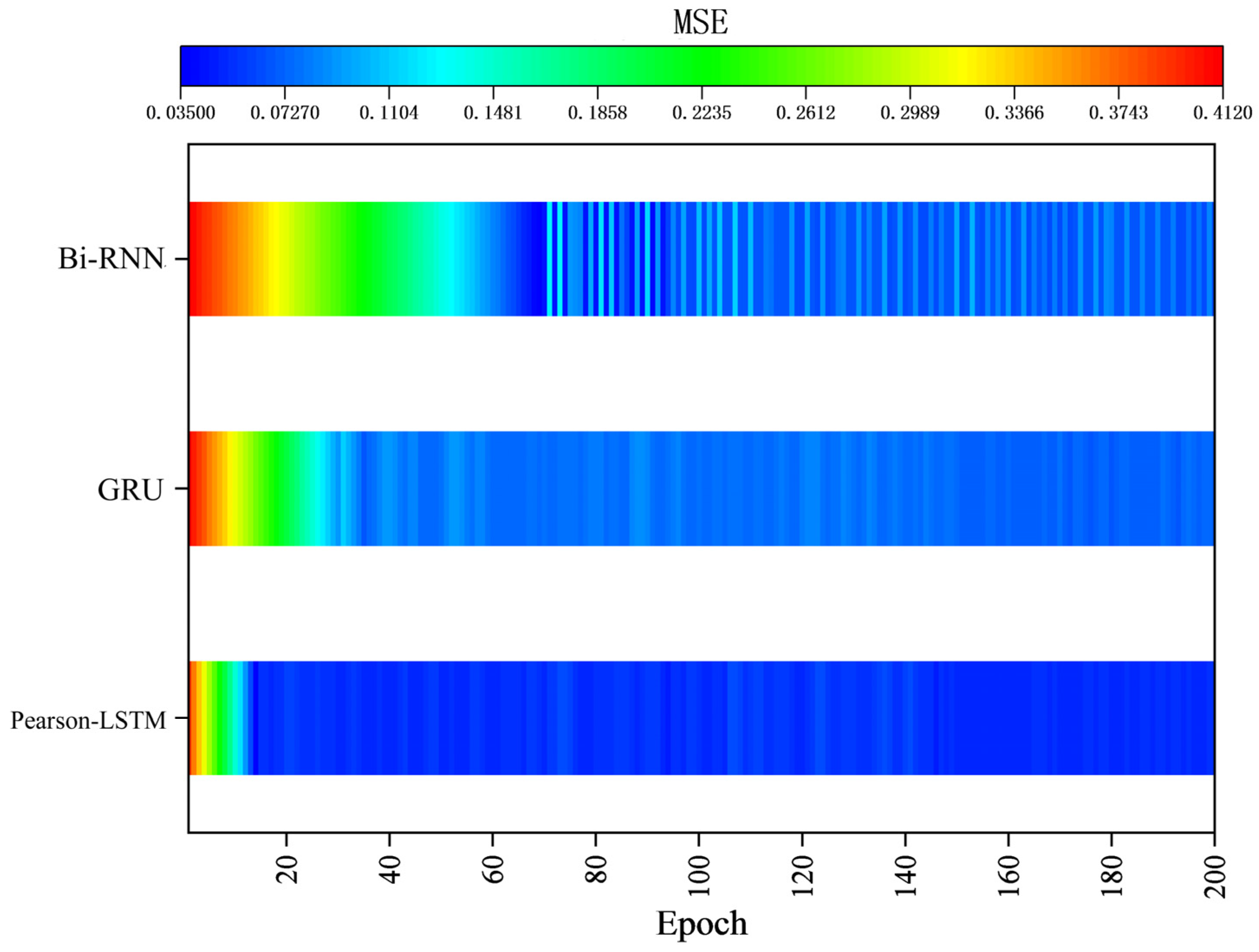
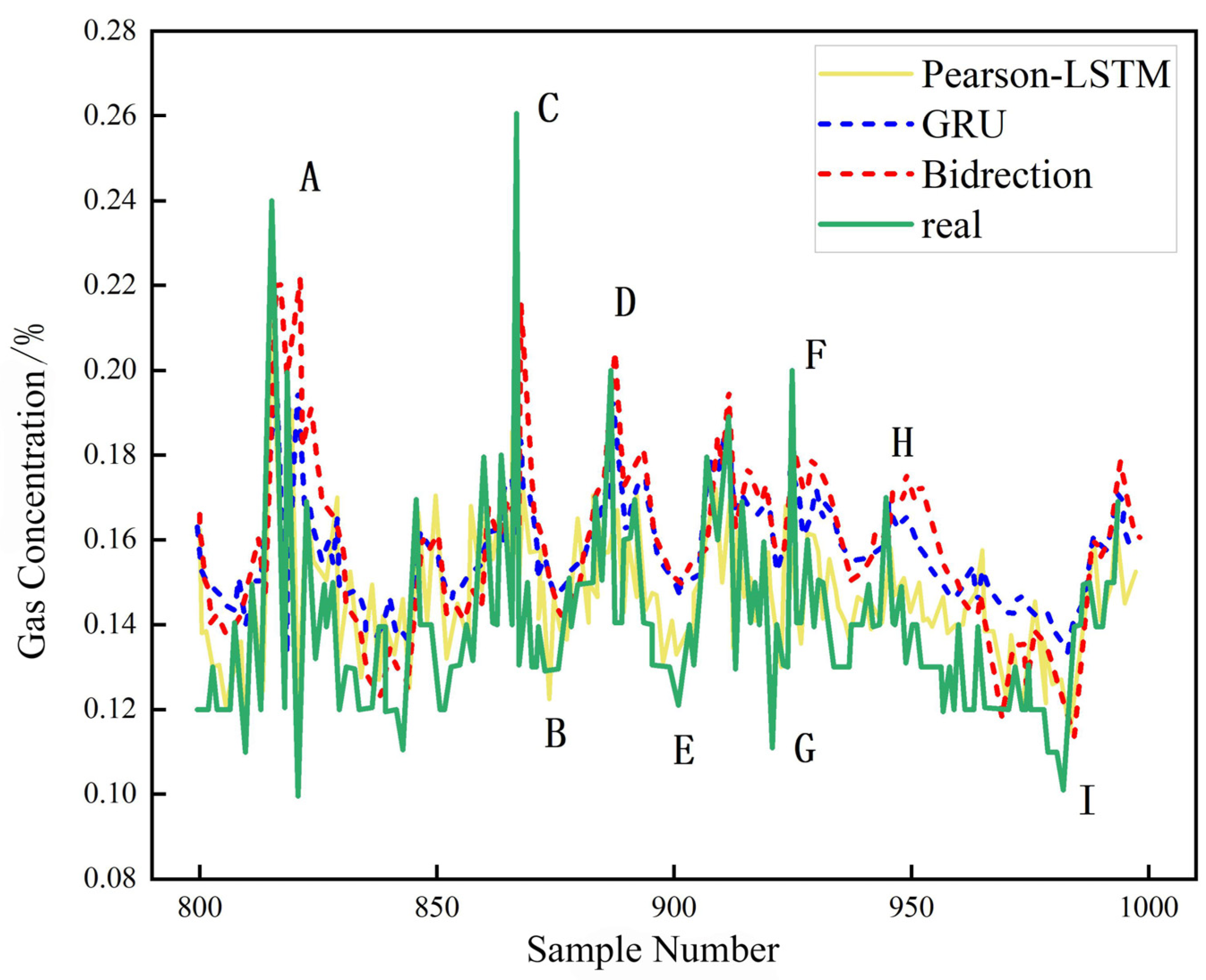
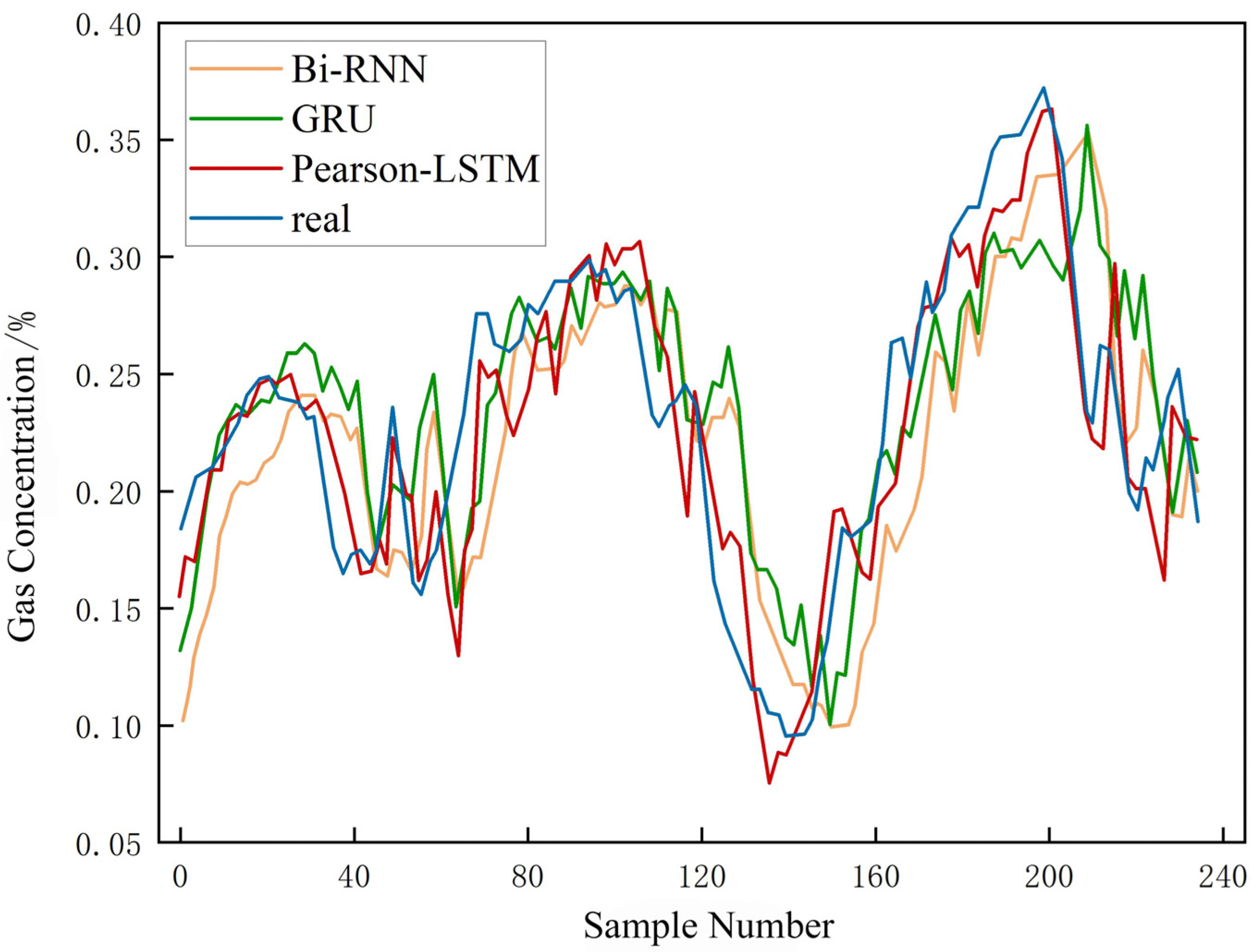
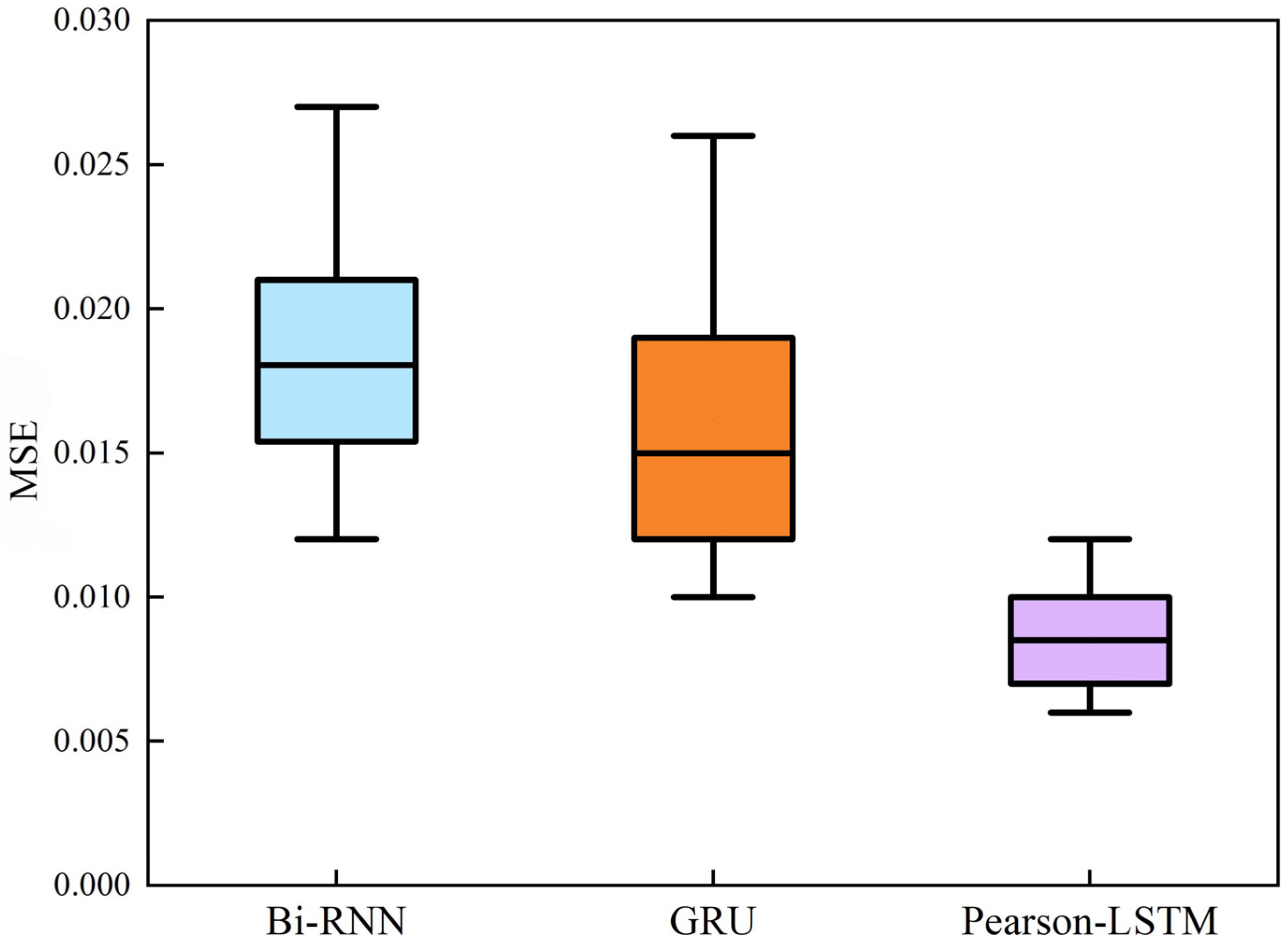
4.5. Model Comparison Analysis
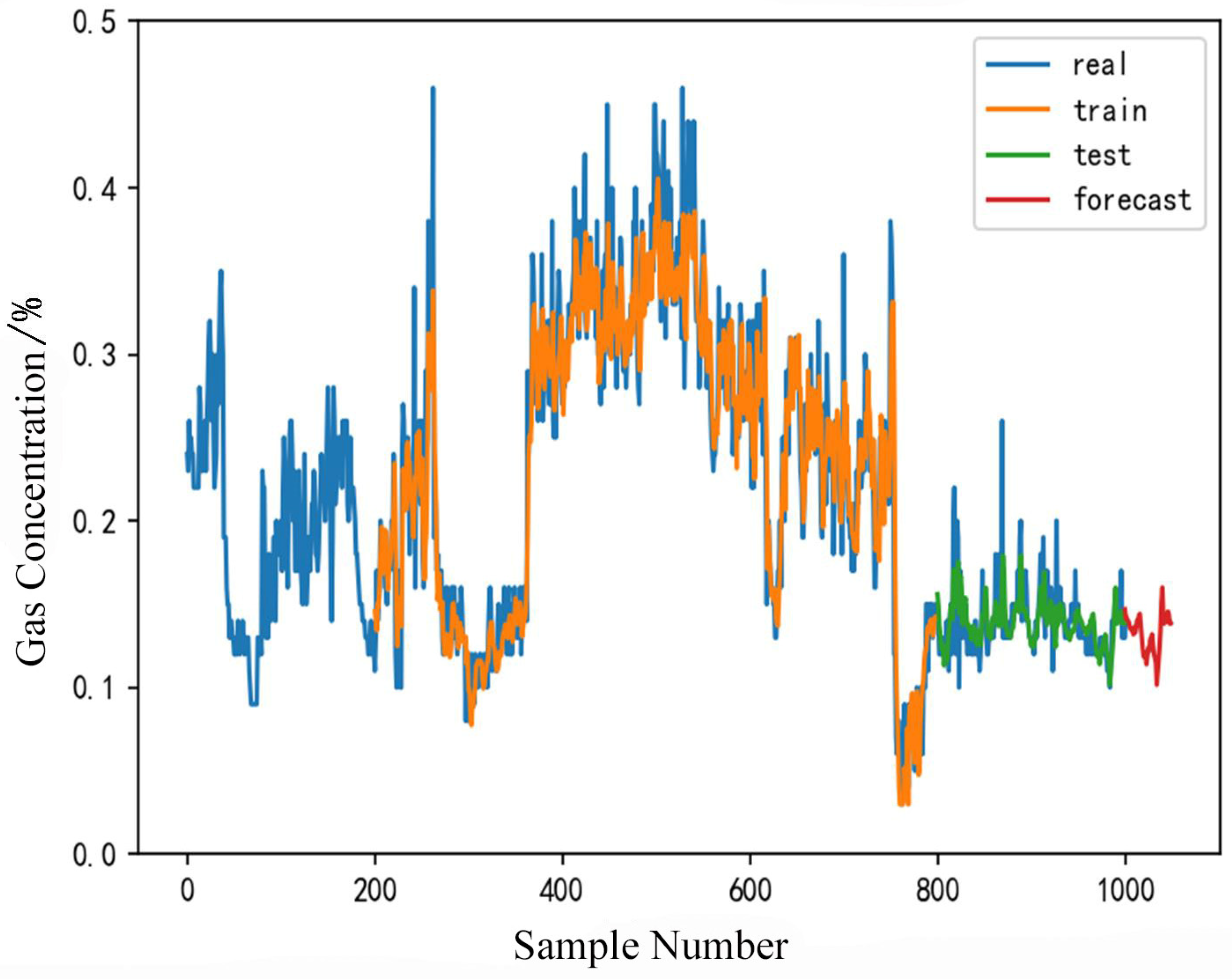
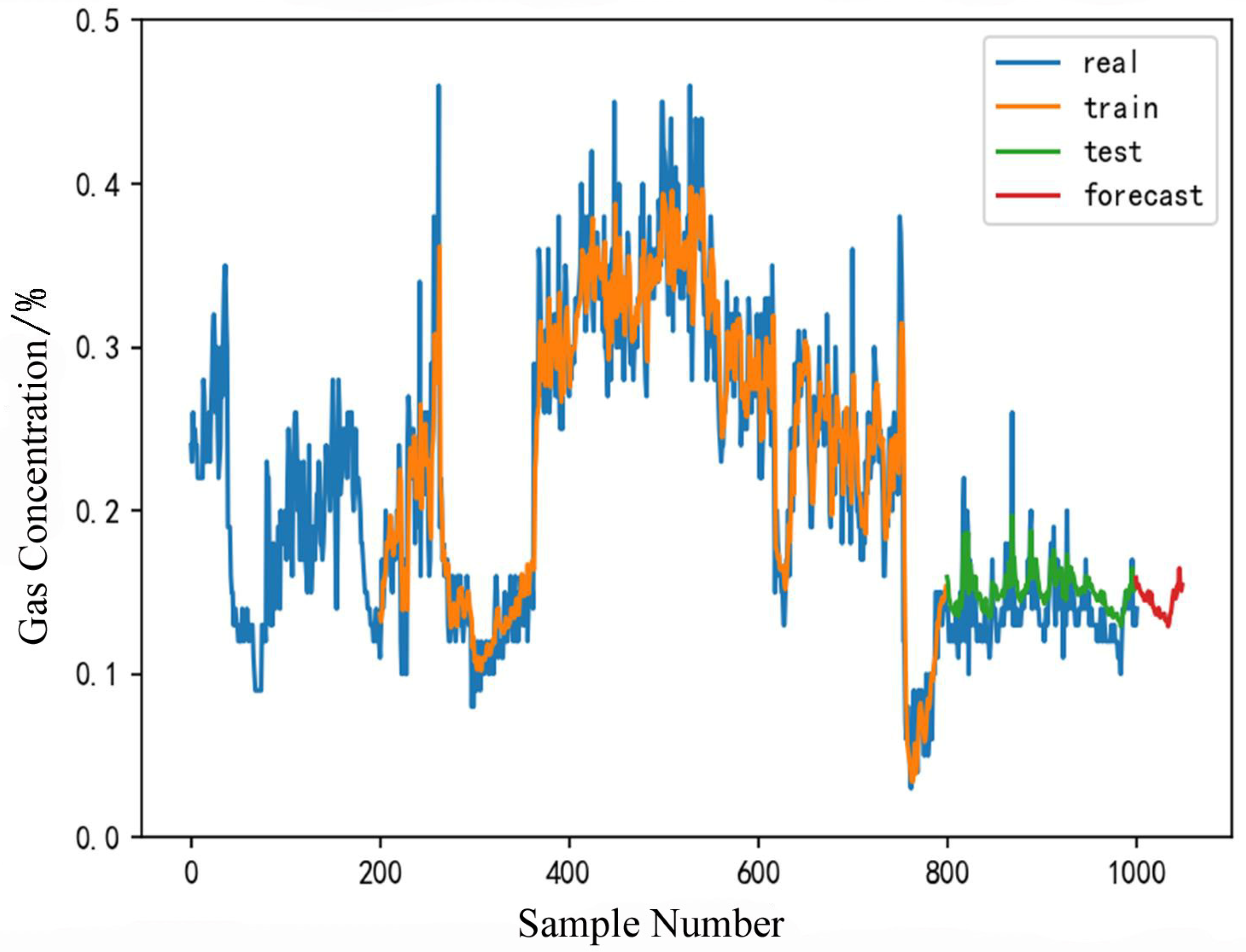
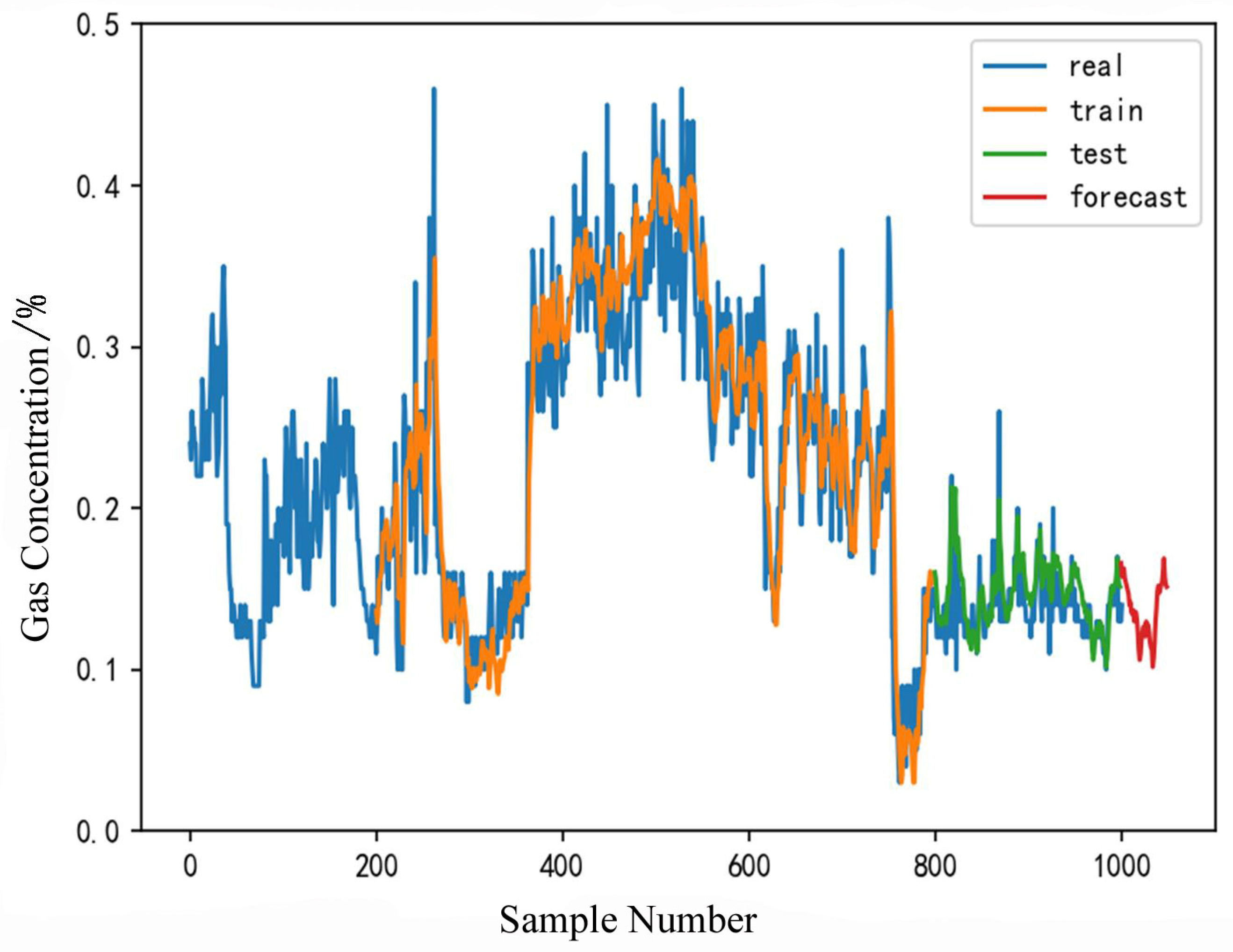
4.6. Application Effect Investigation
5. Conclusions
- (1)
- During the training process, the value of the target function, the fit, and the running time were influenced by the choice of batch size and the number of layers in the Pearson-LSTM model. An appropriate batch size and number of network layers can efficiently improve the model. An experimental Pearson-LSTM gas prediction model with a batch size of 50 and 2 hidden layers is the best combination to predict gas concentration with maximum accuracy.
- (2)
- The Pearson-LSTM model has a better predictive effect compared with traditional recurrent neural networks, such as Bi-RNN and GRU. Taking the prediction results of the 2407 working face of the Yuhua Coal Mine as an example, the average error of the model can be lowered to 0.015. The margin of error is 0.005~0.04, with high robustness.
- (3)
- The Pearson-LSTM gas concentration prediction model was employed to forecast gas concentrations at the 2409 working face of the Yuhua Coal Mine 15 min in advance, with an average error of 0.008. It demonstrated the reliability of the model and guaranteed the safety of daily coal mine operations. Thus, the reliability of the model has been fully demonstrated, proving that it can be applied to the coal mining process and can effectively predict gas concentrations. It can be promoted and applied to other coal mines to guarantee the safety of daily coal operations.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, J.; Bai, J.; Qian, J.; Li, S. Short-Term Forecasting Method of Coalmine Gas Concentration Based on Chaotic Time Series. J. China Univ. Min. Technol. 2008, 2, 231–235. [Google Scholar]
- An, M.; Du, Z.; Zhang, L. Statistical analysis of coal mine gas accidents in China from 2007 to 2010. Saf. Coal Mines 2011, 5, 177–179. [Google Scholar]
- Wang, H.; Wu, B.; Lei, B. Numerical simulation study on influence factors of gas accumulation at fully mechanized caving Face. Saf. Coal Mines 2018, 3, 151–154+159. [Google Scholar]
- Fu, H.; Dai, W. Gas concentration dynamic prediction method of mixtures kernels LSSVM based on ACPSO and PSR. Chin. J. Sens. Actuators 2016, 6, 903–908. [Google Scholar]
- Fu, H.; Feng, S.; Liu, J.; Tang, B. The modeling and simulation of gas concentration prediction based on De-Eda-Svm. Chin. J. Sens. Actuators 2016, 2, 285–289. [Google Scholar]
- Wei, L.; Bai, T.; Fu, H.; Yi, Y. New gas concentration dynamic prediction model based on the EMD-LSSVM. J. Saf. Environ. 2016, 2, 119–123. [Google Scholar]
- Fu, H.; Zi, H.; Meng, X.; Sun, L. A new method of mine gas dynamic prediction based on EKF-WLS-SVR and chaotic time series analysis. Chin. J. Sens. Actuators 2015, 1, 126–131. [Google Scholar]
- Wu, Y.; Qiu, C.; Lv, X. Prediction of gas concentration based on fuzzy information granulation and markov correction. Coal Technol. 2018, 5, 173–175. [Google Scholar]
- Yang, L.; Liu, H.; Mao, S.; Shi, C. Dynamic prediction of gas concentration based on multivariate distribution lag model. J. China Univ. Min. Technol. 2016, 3, 455–461. [Google Scholar]
- Wu, Z.; Wu, X.; Qian, J. Trend prediction of gas concentration based on interpolation trapezoidal fuzzy information granulation. J. Mine Autom. 2014, 12, 31–36. [Google Scholar]
- Wang, P.; Wu, Y.; Wang, S.; Song, C.; Wu, X. Study on Lagrange-ARIMA real-time prediction model of mine gas concentration. Coal Sci. Technol. 2019, 4, 141–146. [Google Scholar]
- Lai, X.; Xia, Y.; Zheng, W.; Cui, J.; Wu, Y.; Shi, Y. Improved grey prediction of gas concentration sequence based on integrated learning. J. Saf. Sci. Technol. 2021, 7, 16–21. [Google Scholar]
- Liang, Y.; Li, X.; Li, Q.; Mao, S.; Zheng, M.; Li, J. Research on intelligent prediction of gas concentration in working face based on CSLSTM. Min. Saf. Environ. Prot. 2022, 4, 80–86. [Google Scholar]
- Wang, D.; Zhu, G.; Wang, Y.; Wang, S. Prediction Model of Gas Concentration in Fully Mechanized Mining Face Based on GA-LSTM. Coal Technol. 2023, 1, 219–221. [Google Scholar]
- Qi, Y. Research on Coal Mine Gas Concentration Prediction Method Based on Information Fusion and GA-BP. Coal Technol. 2022, 6, 159–161. [Google Scholar]
- Fan, J.; Huang, Y.; Yan, Z.; Li, C.; Wang, C.; He, Y. Research on gas concentration prediction driven by ARIMA-SVM combined model. J. Mine Autom. 2022, 9, 134–139. [Google Scholar]
- Xu, N.; Wang, X.; Meng, X.; Chang, C. Gas Concentration Prediction Based on IWOA-LSTM-CEEMDAN Residual Correction Model. Sensors 2022, 22, 4412. [Google Scholar] [CrossRef]
- Wang, D.; Zhao, L.; Hao, T.; Du, Y.; Shen, J.; Tang, Y.; Gong, J.; Li, F.; Yan, X.; Yan, Z.; et al. Multiple Sequence Long and Short Memory Network Model for Corner Gas Concentration Prediction on Coal Mine Workings. ACS Omega 2022, 7, 37980–37987. [Google Scholar] [CrossRef]
- Jia, P.; Liu, H.; Wang, S.; Wang, P. Research on a Mine Gas Concentration Forecasting Model Based on a GRU Network. IEEE Access 2020, 8, 38023–38031. [Google Scholar] [CrossRef]
- Zhang, Z.; Ye, Y.; Dong, L. A Graph Neural Network gas concentration prediction model based on Spatio-Temporal data. J. Phys. Conf. Ser. 2021, 8, 2137. [Google Scholar] [CrossRef]
- Tian, H.; Zhang, Z.; Yu, D. Research on multi-load short-term forecasting of regional integrated energy system based on improved LSTM. Proc. CSU-EPSA 2021, 9, 130–137. [Google Scholar]
- Dai, J.; Song, H.; Sheng, G.; Jiang, X. Prediction method for power transformer running state based on LSTM network. High Volt. Eng. 2018, 4, 1099–1106. [Google Scholar]
- Zheng, Y.; Wang, H. Study on short-term road traffic flow prediction based on deep learning. Software 2020, 5, 72–74. [Google Scholar]
- Liu, Y.; Yang, C. LSTM gas concentration prediction model based on multiple factors. J. Saf. Sci. Technol. 2022, 1, 108–113. [Google Scholar]
- Park, C.; Choi, K.; Lee, C.; Lim, S. Korean coreference resolution with guided mention pair model using deep learning. Etri J. 2016, 6, 1207–1217. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Chen, Y.; Xiang, W.; Wang, J. State degradation trend prediction based on quantum weighted long short-term memory neural network. Chin. J. Sci. Instrum. 2018, 7, 217–225. [Google Scholar]
- Jian, Z.; Troyanskaya, O.G. Predicting effects of noncoding variants with deep learning-based sequence model. Nat. Methods 2015, 10, 931–934. [Google Scholar]
- Sun, B.; Li, X.; Fan, F. Precise detection technology for gas enrichment characteristics of overburden rock under pressure of strong mining in thick coal seam. Saf. Coal Mines 2022, 6, 75–82+88. [Google Scholar]
- Klyuev, R.V.; Bosikov, I.I.; Gavrina, O.A. Cluster analysis of electric energy consumption in metallurgy enterprises. In Advances in Raw Material Industries for Sustainable Development Goals; Taylor & Francis Group: London, UK, 2021; pp. 377–385. ISBN 978-0-367-75881-3. [Google Scholar]
- Hao, Z.; Hao, H.; Ruichu, C.; Ruichu, W. Fine-grained opinion analysis based on mul-ti-feature fusion and bidirectional RNN. Comput. Eng. 2018, 7, 199–204+211. [Google Scholar]
- Liang, L.; Li, J.; Zhang, S. Hyperspectral images classification method based on 3D octave convolution and Bi-RNN attention network. Acta Photonica Sinca 2021, 9, 284–296. [Google Scholar]
- Li, X.; Duan, H.; Xu, M. A gated recurrent unit neural network for chinese word segmentation. J. Xiamen Univ. 2017, 2, 237–243. [Google Scholar]
- Wang, J.; Wen, X.; He, Y.; Lan, J.; Zhang, C. Logging curve prediction based on a CNN-GRU neural network. Geophys. Prospect. Pet. 2022, 2, 276–285. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Correlation Strength | Indicators | Pearson Coefficient |
|---|---|---|
| High correlation | Temperature | 0.882 |
| Drainage negative pressure | 0.841 | |
| Pure volume | 0.802 | |
| Moderate correlation | Gas concentration in upper corner | 0.562 |
| Return air gas concentration | 0.523 | |
| Low correlation | CO concentration | 0.357 |
| CO2 concentration | 0.198 |
| Neuronal Number = 128 | ||
|---|---|---|
| Batch | Operation Time | MSE |
| 10 | 7 min | 0.1203 |
| 20 | 5 min | 0.0912 |
| 50 100 | 4 min 2 min | 0.0731 0.0913 |
| Batch Size = 50 Neuronal Number = 128 | ||
|---|---|---|
| LSTM Layers | Operation Time | MSE |
| 2 | 4min | 0.0587 |
| 3 4 | 5min 8min | 0.0801 0.1292 |
| Parameter Setting | Batch Size = 50; Layers = 2; Neuronal Number = 128 | ||
|---|---|---|---|
| model | Pearson-LSTM | GRU | Bi-RNN |
| operation time | 5569 s | 4540 s | 18,640 s |
| MSE | 0.0521 | 0.0689 | 0.0801 |
| Model | Maximum Error | Minimum Error | Mean Error |
|---|---|---|---|
| Pearson-LSTM | 0.046283 | 0.00589 | 0.015479 |
| GRU Bi-RNN | 0.063648 0.073761 | 0.00916 0.0372 | 0.04246 0.042919 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Zhang, A.; Xue, J.; Lei, C.; Zeng, X. LSTM-Pearson Gas Concentration Prediction Model Feature Selection and Its Applications. Energies 2023, 16, 2318. https://doi.org/10.3390/en16052318
Liu C, Zhang A, Xue J, Lei C, Zeng X. LSTM-Pearson Gas Concentration Prediction Model Feature Selection and Its Applications. Energies. 2023; 16(5):2318. https://doi.org/10.3390/en16052318
Chicago/Turabian StyleLiu, Chao, Ailin Zhang, Junhua Xue, Chen Lei, and Xiangzhen Zeng. 2023. "LSTM-Pearson Gas Concentration Prediction Model Feature Selection and Its Applications" Energies 16, no. 5: 2318. https://doi.org/10.3390/en16052318