
Reliability Prediction of Distribution Network Using IAO-Optimized Mixed-Kernel LSSVM
Abstract
:1. Introduction
2. Aquila Optimizer and Its Improvements
2.1. Aquila Optimizer (AO)
2.1.1. Expanded Exploration
2.1.2. Narrowed Exploration
2.1.3. Expanded Exploitation
2.1.4. Narrowed Exploitation
2.2. Improved Aquila Optimizer (IAO)
- Improved tent chaos mapping
- Generate a random number x0 between (0,1), = 0.
- As in Equation (18), an sequence is generated, and increases by 1
- When i reaches the maximum number of iterations, the sequence is saved
- As shown in Formula (19), the elements of sequence are mapped to the Aquila individual so as to obtain
- Wherein, UB and LB represent the upper and lower bounds of the search space, respectively.
- 2.
- Adaptive t-distribution strategy
2.3. IAO Performance Evaluation
2.3.1. Parameter Setting and Benchmarking Function Selection
2.3.2. Comparative Analysis of Algorithm Performance Results
2.3.3. Comparative Analysis of Algorithm Convergence Curves
3. Mixed Kernel IAO-LSSVM Prediction Model
3.1. Mixed Kernel LSSVM Model
3.2. Establishment of Mixed Kernel IAO-LSSVM Model
- Initialize the parameters. Set the optimization intervals of C, λ, q, and , as well as relevant parameter values of the IAO algorithm. Formulas (18) and (19) are adopted to initialize the Aquila population.
- Select the fitness function. The MSE of the predicted value and the true value of the training sample are taken as the fitness value of the Aquila individual, where is calculated by Formula (25). The calculation formula of MSE is as shown below:
- 3.
- The fitness values of Aquila individuals are calculated, based on what current best position Xbest(k) is determined. XM(k), G1, G2, Levy(d) are updated
- 4.
- When k ≤ (2/3)K and rand ≤ 0.5, refer to the Formula (2) for the location update of the Aquila individual; otherwise, refer to the Formula (4).
- 5.
- When (2/3)Kk ≤ K, and rand ≤ 0.5, the Formula (10) is used to update the location of the Aquila individual; otherwise, the Formula (11) will be used.
- 6.
- In accordance with Equation (20), the t-distribution mutation operation is conducted on the Aquila position.
- 7.
- Calculate the fitness value of each Aquila after t-distribution variation. Update individual fitness values as well as global optimal information.
- 8.
- Termination condition. The parameters corresponding to the optimal Aquila individual position (C,,q,) are output if the maximum number of iterations K has been reached. Thus, the mixed kernel IAO-LSSVM distribution network reliability prediction model is established. Otherwise, return to Step 3
- 9.
- The grey relational analysis method is used for analyzing the data. Firstly, the distribution network data are processed in a dimensionless manner. Secondly, the entropy weight correlation degree of influencing factors of power supply reliability is calculated. Finally, the influencing factors are sorted in accordance with the grey correlation degree, and the entropy weight correlation degrees higher than the set threshold are selected as the input of the mixed kernel IAO-LSSVM model.
- 10.
- Data set division. The influencing factors selected in step 9 are taken as the input of the model, while the distribution network reliability index is taken as the output of the model. Then, the distribution network reliability data are divided into training set and test set, and are normalized.
- 11.
- The established mixed kernel IAO-LSSVM model is used for the distribution network reliability prediction.
3.3. Model Evaluation Index
4. Case Analysis
4.1. Analyze Influencing Factors
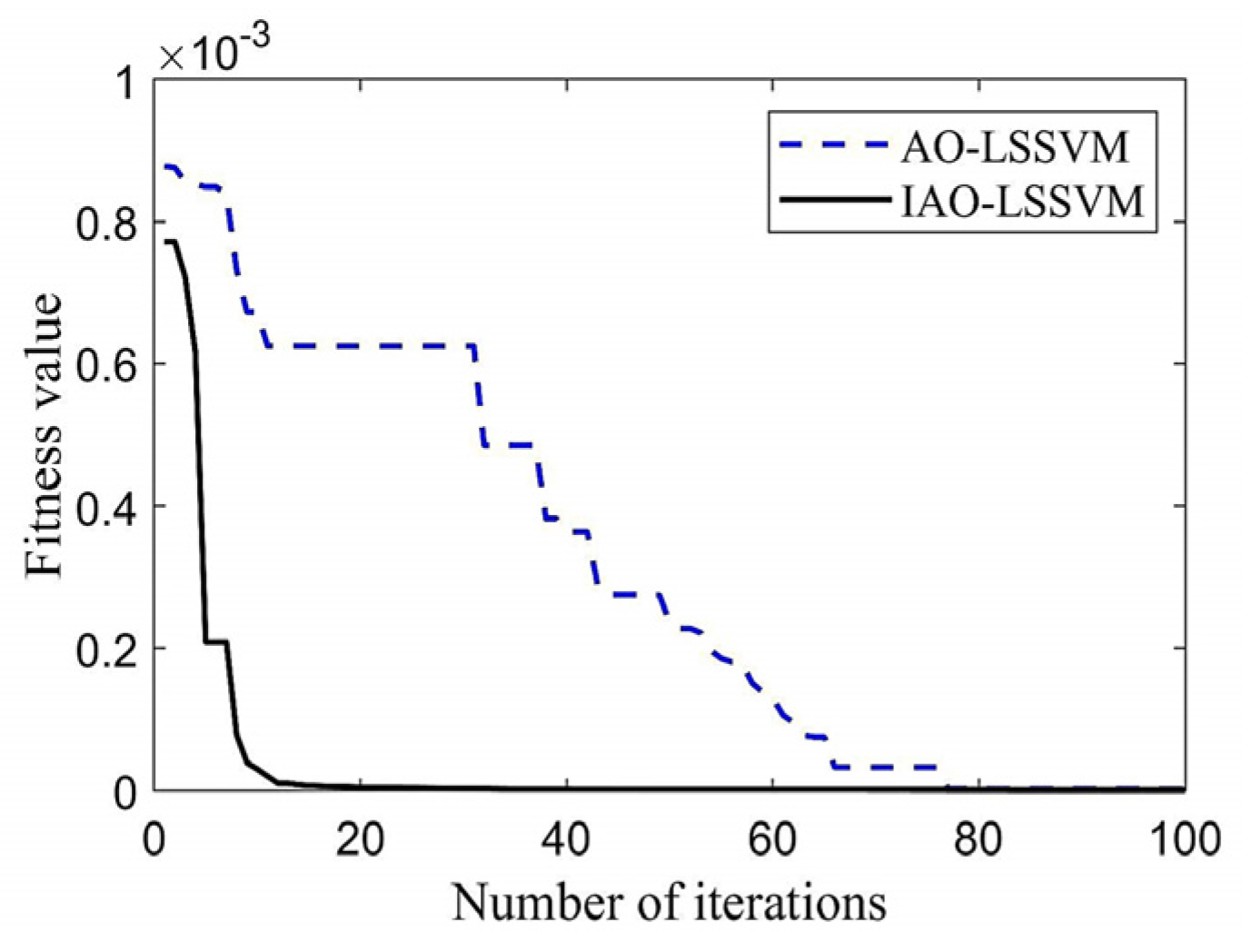
4.2. Model Parameter Determination
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, M.; Luan, Y.; Lu, X.; Hu, J.L.; Wu, D. Summary of Power Supply Reliability Forecast of Distribution Network, Technology ed.; China Electric Power: Beijing, China, 2012; pp. 40–42. [Google Scholar]
- Munoz-Delgado, G.; Contreras, J.; Arroyo, J.M. Distribution Network Expansion Planning with an Explicit Formulation for Reliability Assessment. Trans. Power Syst. 2017, 99, 95–99. [Google Scholar]
- Billinton, R.; Wang, P. Reliability network equivalent approach to Distribution System Reliability Evaluation. IEEE Proc.-Gener. Transm. Distrib. 1998, 145, 149–153. [Google Scholar] [CrossRef]
- Billinton, R.; Billinton, J.E. Distribution System Reliability Indices. IEEE Trans. Deliv. 1989, 4, 561–568. [Google Scholar] [CrossRef]
- Yan, Z.; Zhangchao, C. Evaluation of a 35/10 kV Electric Distribution System Reliability Level. J. Shanghai Jiaotong Univ. 1995, 29, 198–201. [Google Scholar]
- Wang, Y.X.; Pan, X. Reality evaluation of distribution network based on improved-elman feedback dynamic neural network. Water Resour. Power 2019, 37, 177–180. [Google Scholar]
- Zhan, C.Y. Research on Model Optimization of Distribution Network Reliability Prediction; Anhui University of Science & Technology: Huainan, China, 2020. [Google Scholar]
- Liu, Q.; Lu, H.; Wang, Q.; Zhang, H.L. A regional traffic volume rolling prediction model based on support vector machine. J. Harbin Inst. Technol. 2011, 43, 138–143. [Google Scholar]
- Suykens, J.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293. [Google Scholar] [CrossRef]
- Dong, H.; Shi, L.S.; Zhao, P.C. Reliability Prediction of Urban Power Network Based on PSO-LSSVM Model. Proc. CSU-EPSA 2014, 26, 82–86. [Google Scholar]
- Deng, H.; Zhu, X.; Zhang, Q.; Zhao, J. Prediction of Short-term Pubic Transportation Flow Based on Multiple-kernel Least Square Support Vector Machine. J. Transp. Eng. Inf. 2012, 10, 84–88. [Google Scholar]
- Abualigah, L.; Yousri, D.; Abd Elaziz, M.; Ewees, A.A.; Al-Qaness, M.A.; Gandomi, A.H. Aquila Optimizer: A novel meta-heuristic optimization algorithm. Comput. Ind. Eng. 2021, 157, 107250. [Google Scholar] [CrossRef]
- Liu, L.; Sun, S.Z.; Yu, H.; Yue, X.; Zhang, D. A Modified Fuzzy C-means (FCM) Clustering Algorithm and its Application on Carbonate Fluid Identification. J. Appl. Geophys. 2016, 129, 28–35. [Google Scholar] [CrossRef]
- Zhang, N.; Zhao, Z.D.; Bao, X.A.; Qian, J.; Wu, B. Gravitational Search Algorithm Based on Improved Tent Chaos. Control. Decis. 2020, 35, 893–900. [Google Scholar]
- Chen, X.; Zhao, S.; Liu, F. Robust identification of Linear ARX Models with Recursive EM Algorithm Based on Student’s T-Distribution. J. Frankl. Inst. 2021, 358, 1103–1121. [Google Scholar] [CrossRef]
- Li, H.; Peng, Y.; Deng, C.; G, D.Q. Review of Hybrids of GA and PSO. Comput. Eng. Appl. 2018, 54, 20–28+39. [Google Scholar]
- Li, X.; Deng, D.; Liao, D.; Chen, J.H. A Review on Application of Particle Swarm Optimization in Electric Power Systems. Power Syst. Prot. Control. 2007, 23, 77–84. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. A Novel Swarm Intelligence Optimization Approach: Sparrow Search Algorithm. Syst. Sci. Control. Eng. Open Access J. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Zhang, J.; Tang, Z.H.; Gui, W.H.; Chen, Q.; Liu, J.P. Interactive image segmentation with a regression based ensemble learning paradigm. Front. Inf. Technol. Electron. Eng. 2017, 18, 1002–1021. [Google Scholar] [CrossRef]
- Allan, R.N.; Billinton, R. Bibliography on the application of probability methods in power system reliability evaluation. IEEE Trans. Power Syst. Publ. Power Eng. Soc. 1999, 14, 51–57. [Google Scholar] [CrossRef]
- Xiong, Y. Improved FCM-LSSVM Prediction Model for Penicillin Fed-batch Fermentation. Control. Eng. China 2017, 24, 2237–2242. [Google Scholar]
- Yuan, K.; Luo, P.; Wang, G.; Jin, D.M.; Yao, L.Y. A New Method of Power System False Data Attack Detection Based on Grey Analysis. Adv. Technol. Electr. Eng. Energy 2019, 38, 17–23. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Parameter Settings |
|---|---|
| GA | Crossover probability is 0.7, and Mutation probability is 0.2 |
| PSO | Learning factor: c1 = c2 = 1.5, Initial weight: W = 0.729 |
| GWO | a linearly decreases from 2 to 0, r1,r2 ∈ [0,1] |
| SSA | Safety threshold: ST = 0.6, Finder ratio: PD = 0.2, Investigator ratio: SD = 0.1 |
| AO | U = 0.00565, = 0.005, s = 0.01, = 1.5, = 0.1, = 0.1, r1 ∈ [0,20], u,v ∈ [0,1] |
| IAO | Same as AO |
| Function | Range of Values | Optimal Value |
|---|---|---|
| Sphere | [100,100] | 0 |
| Ackley | [32.768,32.768] | 0 |
| Function | Algorithm | d = 10 | d = 30 | d = 50 | |||
|---|---|---|---|---|---|---|---|
| Average | Standard Deviation | Average | Standard Deviation | Average | Standard Deviation | ||
| Sphere | GA | 1.64 × 10−1 | 7.14 × 10−1 | 3.14 × 100 | 4.16 × 10−1 | 4.535 × 101 | 1.356 × 100 |
| PSO | 3.02 × 10−2 | 3.55 × 10−2 | 5.13 × 10−1 | 3.56 × 10−1 | 2.877 × 101 | 3.935 × 100 | |
| GWO | 4.14 × 10−4 | 3.76 × 10−4 | 7.54 × 10−2 | 5.16 × 10−2 | 3.854 × 10−1 | 2.857 × 100 | |
| SSA | 2.63 × 10−8 | 1.14 × 10−8 | 3.18 × 10−6 | 4.14 × 10−6 | 5.455 × 10−7 | 6.732 × 10−7 | |
| AO | 6.14 × 10−17 | 5.33 × 10−17 | 5.48 × 10−15 | 6.19 × 10−15 | 7.55 × 10−12 | 3.55 × 10−12 | |
| IAO | 7.14 × 10−130 | 0 | 7.36 × 10−159 | 0 | 3.55 × 10−190 | 0 | |
| Ackley | GA | 3.64 × 100 | 4.56 × 100 | 8.18 × 101 | 6.14 × 10−1 | 7.593 × 101 | 8.479 × 101 |
| PSO | 5.02 × 10−1 | 7.57 × 10−1 | 1.55 × 100 | 5.38 × 10−1 | 9.258 × 101 | 3.398 × 100 | |
| GWO | 5.37 × 10−2 | 7.86 × 10−2 | 6.26 × 10−1 | 7.41 × 10−1 | 7.398 × 100 | 6.985 × 100 | |
| SSA | 2.83 × 10−8 | 4.14 × 10−8 | 9.14 × 10−7 | 6.29 × 10−7 | 4.698 × 10−7 | 9.874 × 10−7 | |
| AO | 3.67 × 10−17 | 8.35 × 10−17 | 5.33 × 10−16 | 3.84 × 10−16 | 9.683 × 10−16 | 8.489 × 10−16 | |
| IAO | 7.17 × 10−68 | 0 | 7.22 × 10−68 | 0 | 7.19 × 10−68 | 0 | |
| 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1.56 | 1.63 | 1.72 | 1.8 | 1.95 | 2.04 | 2.82 | 3.01 | 3.35 | 3.68 | |
| 38.55 | 40.93 | 42.7 | 45.1 | 48.5 | 50.8 | 53.6 | 56.9 | 59.2 | 61.6 | |
| 1.95 | 2.03 | 2.1 2 | 2.1 5 | 2.25 | 2.37 | 2.06 | 2.1 2 | 2.35 | 2.61 | |
| 37.98 | 40.79 | 43.52 | 46.11 | 48.97 | 51.13 | 54.22 | 57.63 | 61.4 | 64.35 | |
| 51.03 | 54.52 | 57.86 | 61.03 | 65.22 | 69.09 | 73.76 | 78.57 | 84.4 | 87.78 | |
| 36.75 | 38.97 | 42.02 | 40.55 | 45.6 | 44.7 | 43.5 | 44.2 | 43.27 | 42.3 | |
| 41.25 | 39.87 | 37.99 | 36.4 | 34.3 | 33.7 | 32.8 | 29.7 | 28.9 | 27.8 | |
| 10.02 | 8.62 | 7.93 | 7.5 | 6.92 | 6.87 | 6.66 | 6.38 | 6.01 | 5.83 | |
| 0.1 1 | 0.14 | 0.1 7 | 0.22 | 0.35 | 0.51 | 0.62 | 0.73 | 0.79 | 0.82 | |
| 32.61 | 35.72 | 37.85 | 39.87 | 44.76 | 46.29 | 49.88 | 52.37 | 54.87 | 57.99 | |
| 1.83 | 1.92 | 1.98 | 2.03 | 2.06 | 2.08 | 1.84 | 1.95 | 2.33 | 2.61 | |
| 39.05 | 41.06 | 43.27 | 45.2 | 47.3 | 49.85 | 51.03 | 53.29 | 55.35 | 59.81 | |
| 38.98 | 40.97 | 42.65 | 43.07 | 48.7 | 53.6 | 55.46 | 57.12 | 59.85 | 62.53 | |
| 45.09 | 44.72 | 44.56 | 43.13 | 42.89 | 41.87 | 42.24 | 41.95 | 41.66 | 40.51 | |
| 33.87 | 32.95 | 32.06 | 31.68 | 31.05 | 30.27 | 30.73 | 30.44 | 30.15 | 29.93 | |
| 10.36 | 9.79 | 9.05 | 8.1 9 | 7.83 | 7.55 | 6.92 | 6.61 | 6.33 | 6.02 | |
| 17.25 | 18.02 | 18.98 | 19.31 | 19.77 | 20.33 | 20.82 | 21.36 | 21.89 | 22.3 | |
| 2.17 | 2.36 | 2.75 | 3.01 | 3.55 | 4.84 | 5.68 | 6.33 | 7.1 8 | 8.67 | |
| 29.76 | 31.87 | 33.87 | 35.76 | 40.65 | 42.18 | 45.77 | 48.26 | 50.76 | 53.88 | |
| 38.75 | 39.86 | 41.27 | 43.76 | 46.98 | 48.25 | 49.78 | 55.98 | 58.98 | 61.25 | |
| 15.98 | 15.27 | 14.98 | 14.36 | 13.65 | 12.67 | 11.81 | 10.08 | 8.96 | 7.6 | |
| 0 | 0 | 0 | 0 | 0.03 | 0.12 | 0.36 | 0.57 | 2.13 | 4.36 | |
| 37.021 | 35.098 | 33.54 | 31.52 | 29.87 | 27.986 | 25.40 | 23.016 | 20.825 | 18.007 | |
| 11.57 | 12.93 | 14.75 | 16.23 | 17.55 | 19.86 | 22.13 | 26.36 | 30.01 | 36.99 | |
| 14.19 | 13.28 | 12.05 | 11.68 | 11.03 | 10.75 | 9.21 | 7.98 | 5.39 | 5.02 | |
| 59.02 | 57.98 | 55.76 | 53.73 | 49.85 | 45.9 | 42.13 | 37.31 | 32.29 | 30.13 | |
| 6.9 | 7.3 | 9.8 | 11.3 | 20.5 | 31.6 | 42.3 | 48.5 | 57.1 | 65.3 | |
| 0.99823 | 0.99842 | 0.99863 | 0.99897 | 0.99918 | 0.99927 | 0.99938 | 0.99947 | 0.99955 | 0.99938 |
| 110 KV | Influencing Factor | 35 KV | Ifluencing Factor | 10 KV | Influencing Factor |
|---|---|---|---|---|---|
| Cabling rate | 0.9011 | Cabling rate | 0.6540 | Insulation rate of overhead lines | 0.9642 |
| Main structure ratio | 0.9374 | Main structure ratio | 0.9191 | Cabling rate | 0.8125 |
| Capacity–load ratio | 0.9711 | Capacity–load ratio | 0.9717 | Main structure ratio of the overhead network | 0.9194 |
| N − 1 security main transformer ratio | 0.9294 | N − 1 security main transformer ratio | 0.9471 | Main structure ratio of cable network | 0.9458 |
| N − 1 security line ratio | 0.9284 | N − 1 security line ratio | 0.9379 | Average power supply radius | 0.9527 |
| Mean value of maximum load rate of Main transformer | 0.9666 | Mean value of maximum load rate of the Main transformer | 0.9883 | Effective coverage of distribution automation | 0.9642 |
| Mean value of maximum line load rate | 0.9619 | Mean value of the maximum line load rate | 0.9823 | High-loss distribution transformers | 0.9479 |
| Heavy-load line ratio | 0.9397 | Heavy-load line ratio | 0.9468 | N − 1 security line ratio | 0.8547 |
| ─ | ─ | Heavy-load line ratio | 0.9374 | ||
| ─ | ─ | Mean value of maximum line load rate | 0.9531 | ||
| ─ | ─ | Non-power-cut maintenance working ratio | 0.6555 |
| Optimization Algorithm | Parameter C | Parameter | Parameter q | Parameter |
|---|---|---|---|---|
| GA | 216.74 | 0.39 | 1.21 | 4.17 |
| PSO | 291.81 | 0.49 | 0.98 | 3.95 |
| GWO | 247.90 | 0.37 | 0.99 | 4.70 |
| SSA | 244.65 | 0.19 | 1.07 | 4.24 |
| AO | 223.38 | 0.14 | 1.02 | 3.34 |
| IAO | 286.72 | 0.29 | 1.10 | 4.37 |
| Prediction Model | RMSE | MAPE/% | MAE | Running Time (s) |
|---|---|---|---|---|
| RBF-LSSVM | 0.0494 | 0.0487 | 0.0486 | 2.539 |
| LSSVM | 0.0241 | 0.0182 | 0.0184 | 3.305 |
| GA-LSSVM | 1.0305 × 10−3 | 9.8324 × 10−4 | 9.8629 × 10−4 | 2.243 |
| PSO-LSSVM | 7.9773 × 10−4 | 7.6437 × 10−4 | 7.6398 × 10−4 | 1.450 |
| GWO-LSSVM | 2.6909 × 10−4 | 2.1875 × 10−4 | 2.1864 × 10−4 | 0.8050 |
| SSA-LSSVM | 1.7178 × 10−4 | 1.7032 × 10−4 | 1.7023 × 10−4 | 0540 |
| AO-LSSVM | 2.8671 × 10−4 | 2.8317 × 10−4 | 2.8301 × 10−4 | 0.445 |
| IAO-LSSVM | 5.8567 × 10−5 | 4.8856 × 10−5 | 4.8832 × 10−5 | 0.118 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, C.; Ren, L.; Wan, J. Reliability Prediction of Distribution Network Using IAO-Optimized Mixed-Kernel LSSVM. Energies 2023, 16, 7448. https://doi.org/10.3390/en16217448
Pan C, Ren L, Wan J. Reliability Prediction of Distribution Network Using IAO-Optimized Mixed-Kernel LSSVM. Energies. 2023; 16(21):7448. https://doi.org/10.3390/en16217448
Chicago/Turabian StylePan, Chen, Lijia Ren, and Junjie Wan. 2023. "Reliability Prediction of Distribution Network Using IAO-Optimized Mixed-Kernel LSSVM" Energies 16, no. 21: 7448. https://doi.org/10.3390/en16217448