
Equipment- and Time-Constrained Data Acquisition Protocol for Non-Intrusive Appliance Load Monitoring
 ,
,  , , and
, , and
Abstract
:1. Introduction
- Can energy disaggregation be used to produce meaningful results under significant time and equipment constraints through a dedicated protocol?
- How do different algorithms perform within such a protocol of time and equipment constraints?
- Does the lack of extensive data hamper the ability of energy disaggregation to provide tips for energy reductions through behavioural changes?
2. Methods
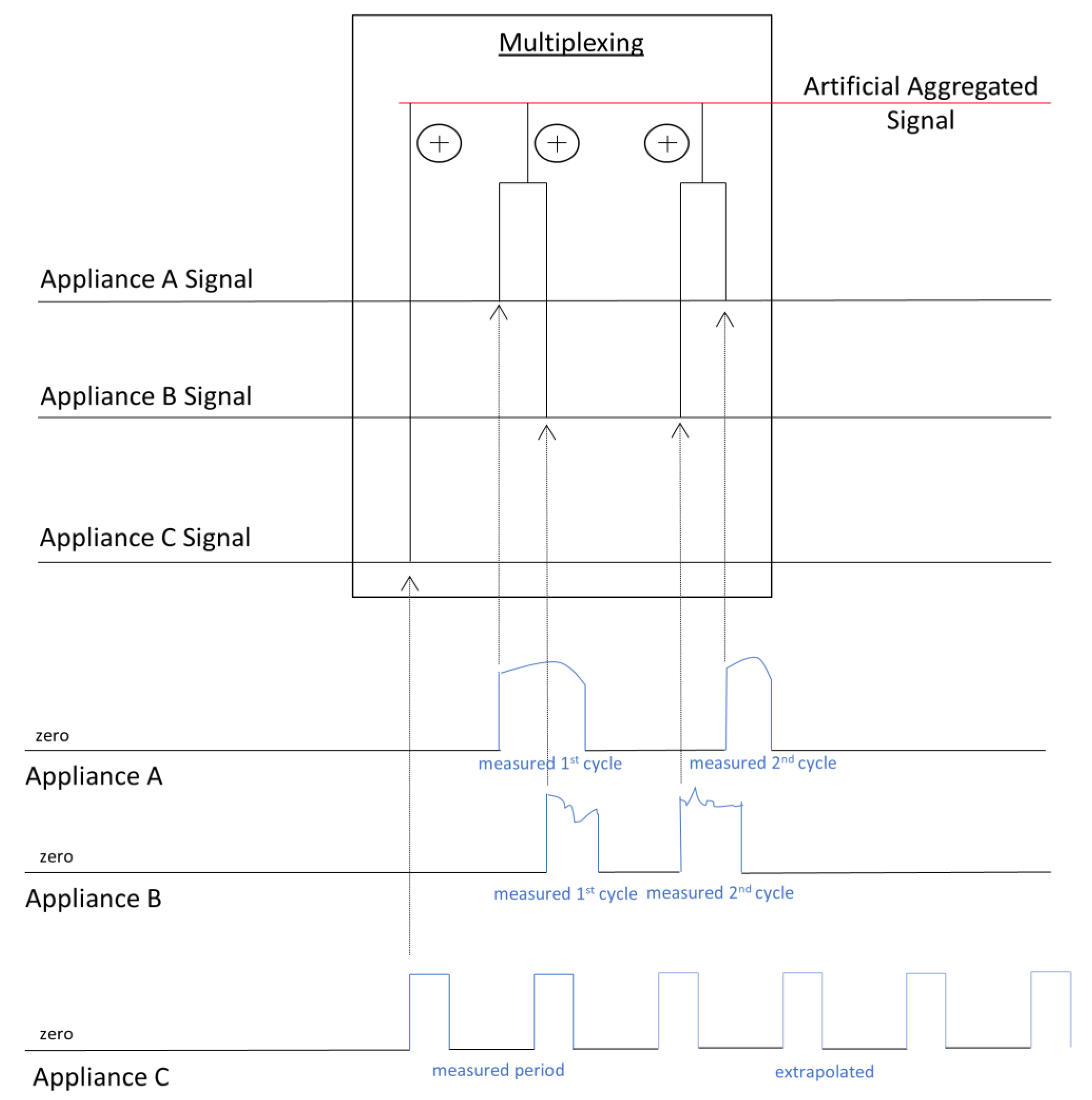
2.1. Data Acquisition Protocol
- Step 1: Using the smart meter, we gather two cycles of operation for each appliance. The argument for two cycles instead of one is based on assisting the algorithm to train based on patterns that can be generalised, similar to the two session approach followed in the ACS-F1 dataset. For appliances that operate continuously (e.g., fridge), data for a specific amount of time can be gathered instead of two cycles (e.g., here we gathered data for two hours).
- Step 2: Most machine learning algorithms require datasets that span ten days for training. To create the artificial total consumption time series, we first extrapolate the series for the appliances of continuous operation to span across the entire sample to create the base load.
- Step 3: We then combine the signals of the appliances in pairs of two appliances, each time taking one cycle for each appliance, allowing one appliance to start operating and then a couple of seconds/minutes later adding (i.e., “artificially” turning on) the next one. Based on this approach, the algorithm can understand the impact of each appliance and avoid confusing the operation with the other ones.
- Step 4: We exhaustively repeat the process of the previous step for all pairs of appliances and alternating between the appliances that go first and second.
- Step 5: Depending on how different the two cycles of each appliance are, the process can be repeated with the second pair of cycles as well.
2.2. Energy Disaggregation Algorithms
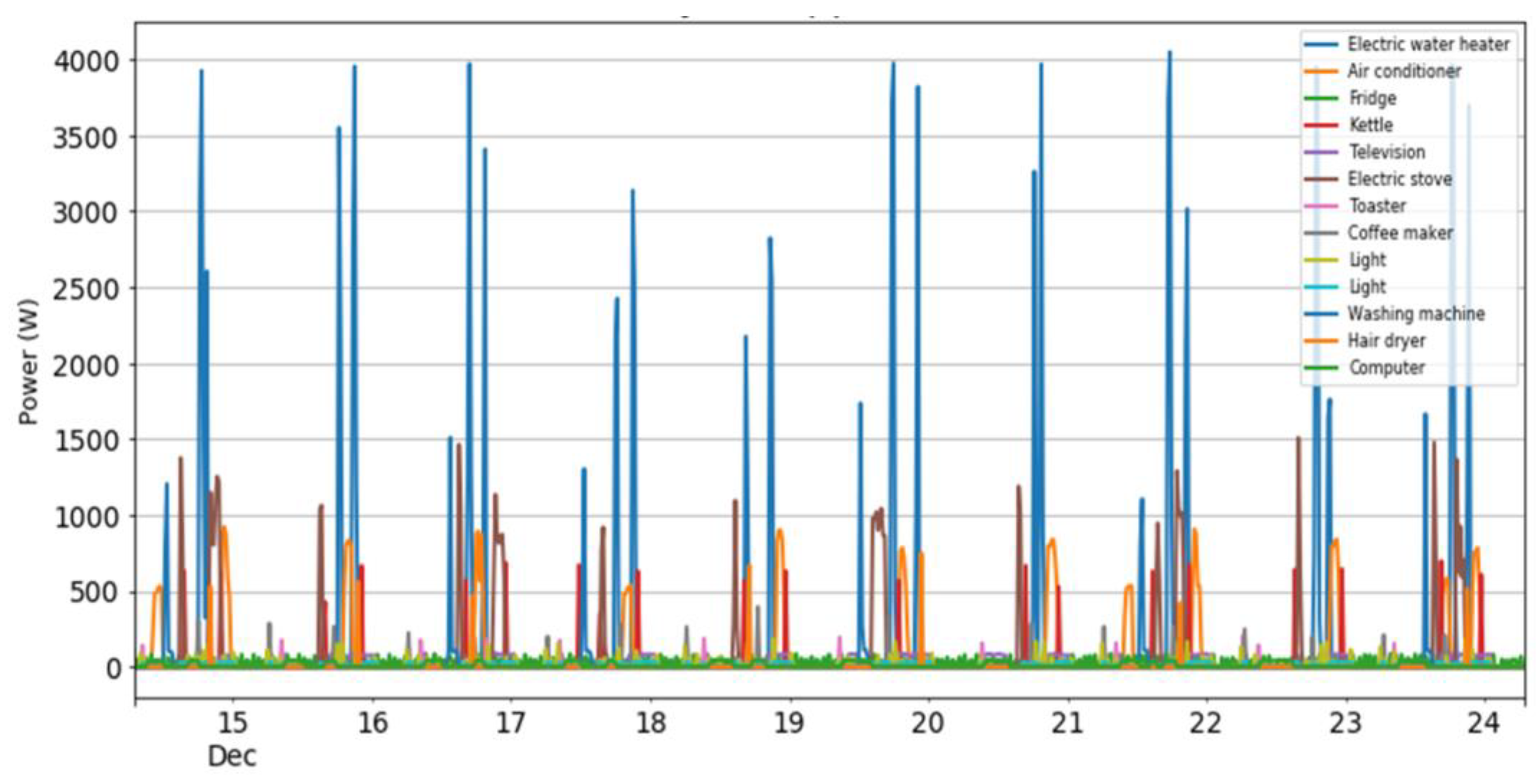
2.3. Real-Life Application in a Greek Household
3. Results
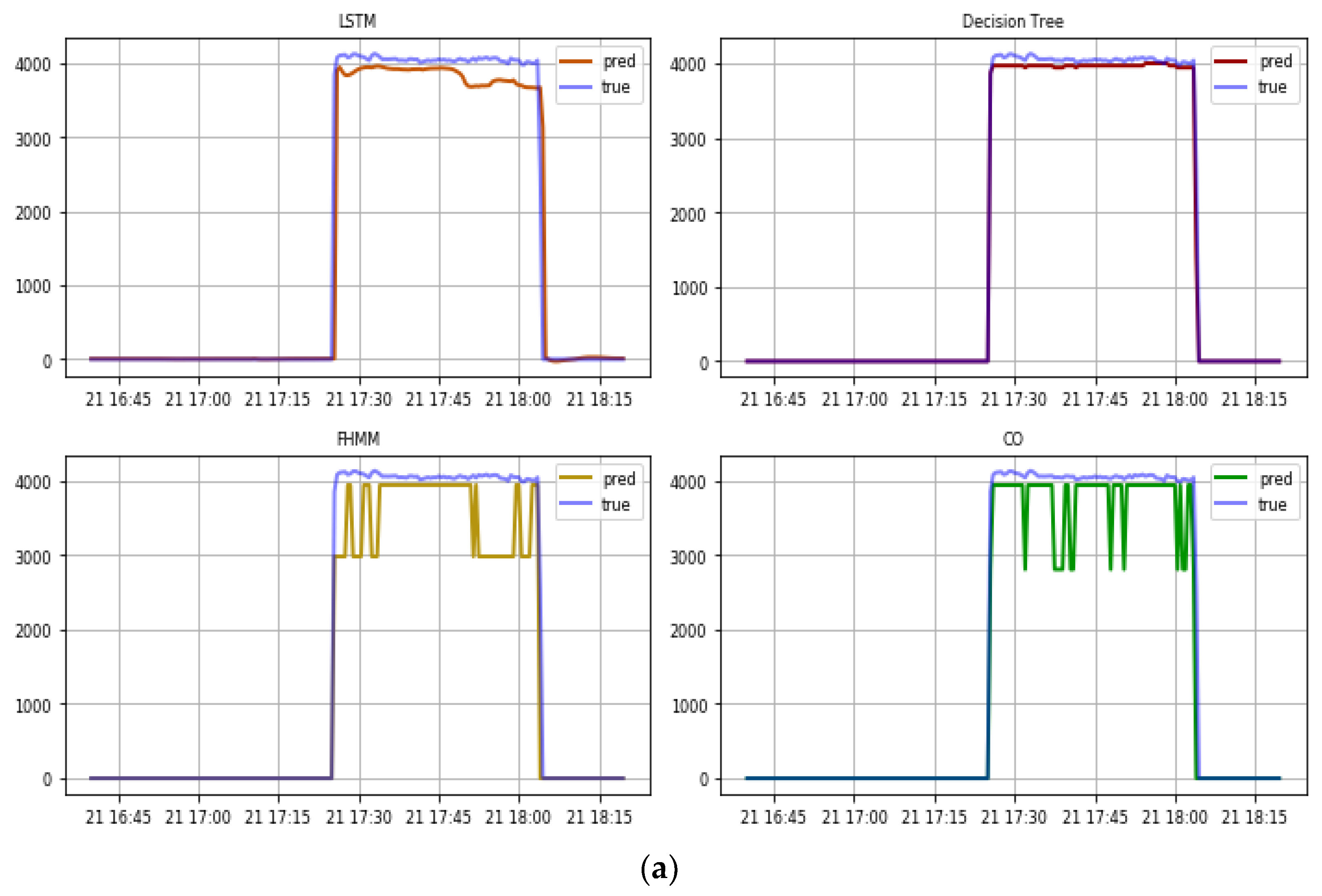
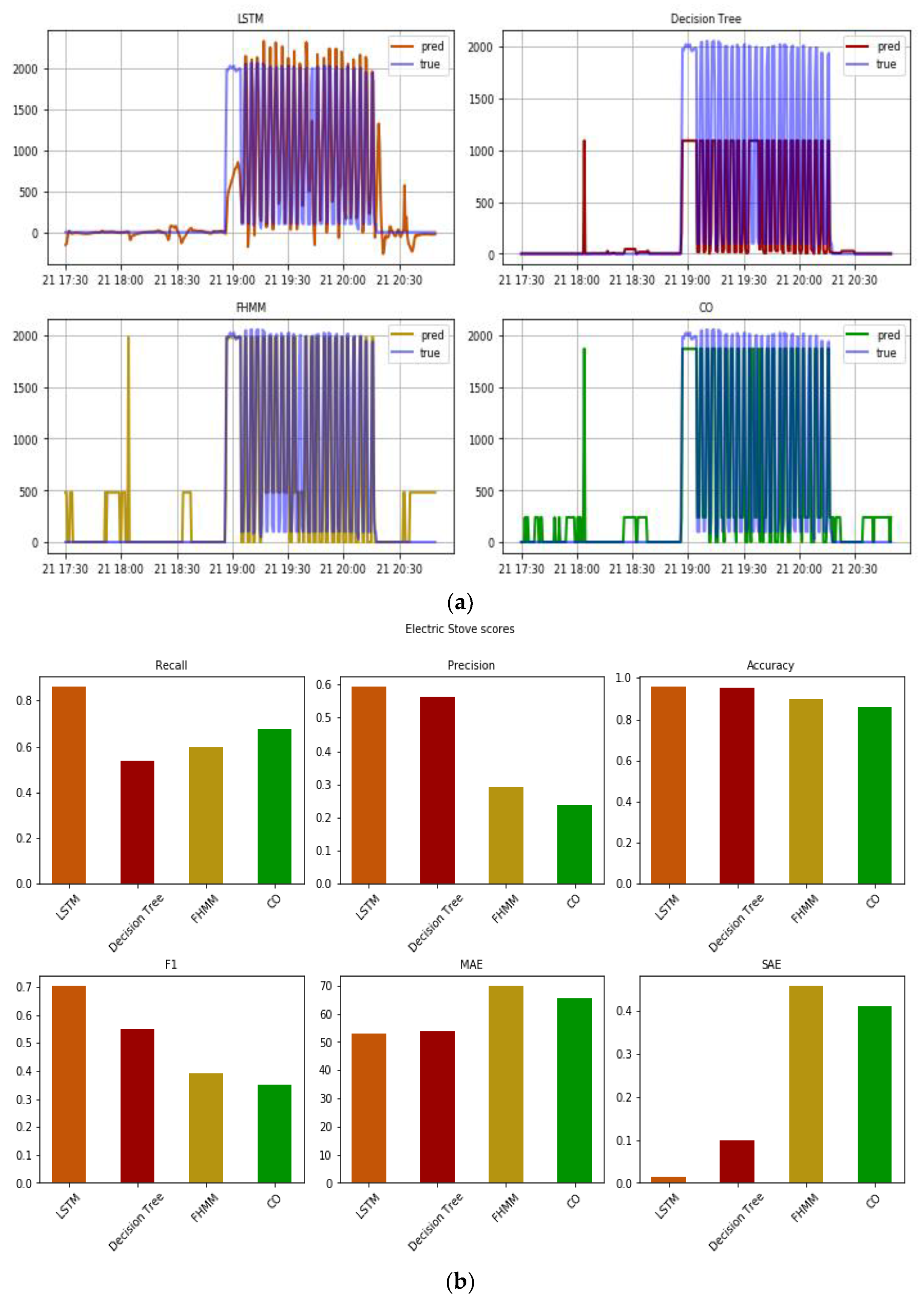
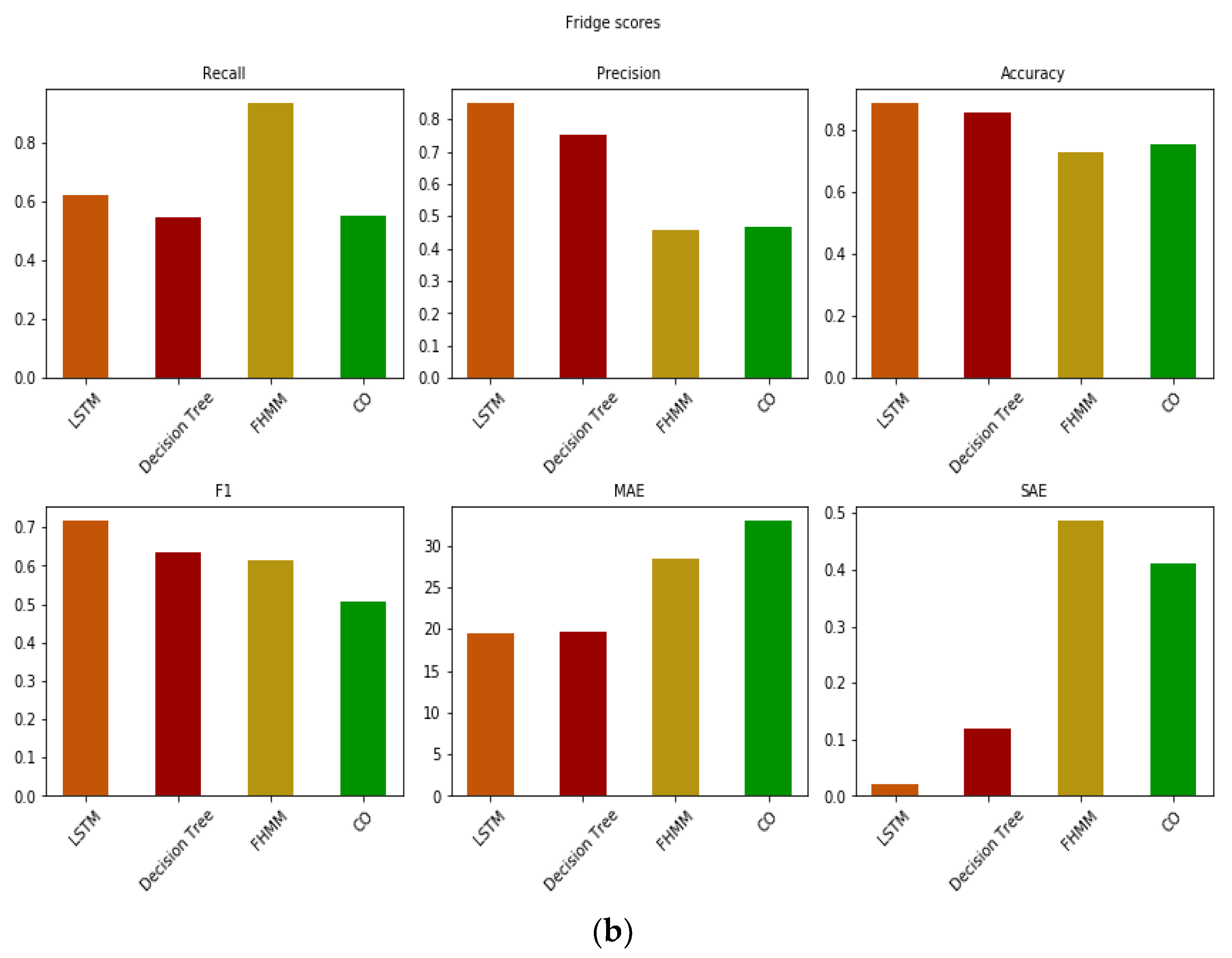
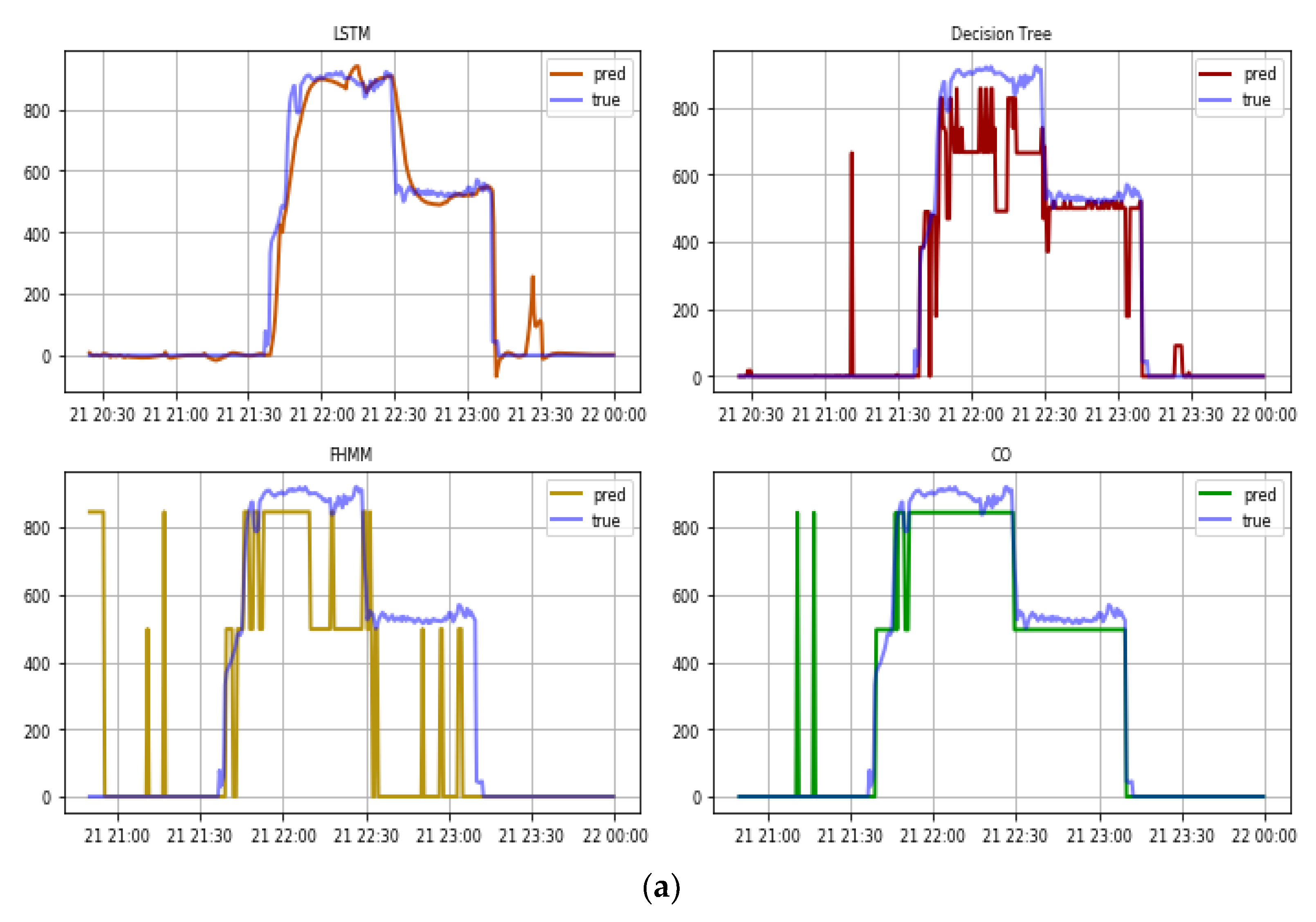
3.1. Out-of-Sample Test
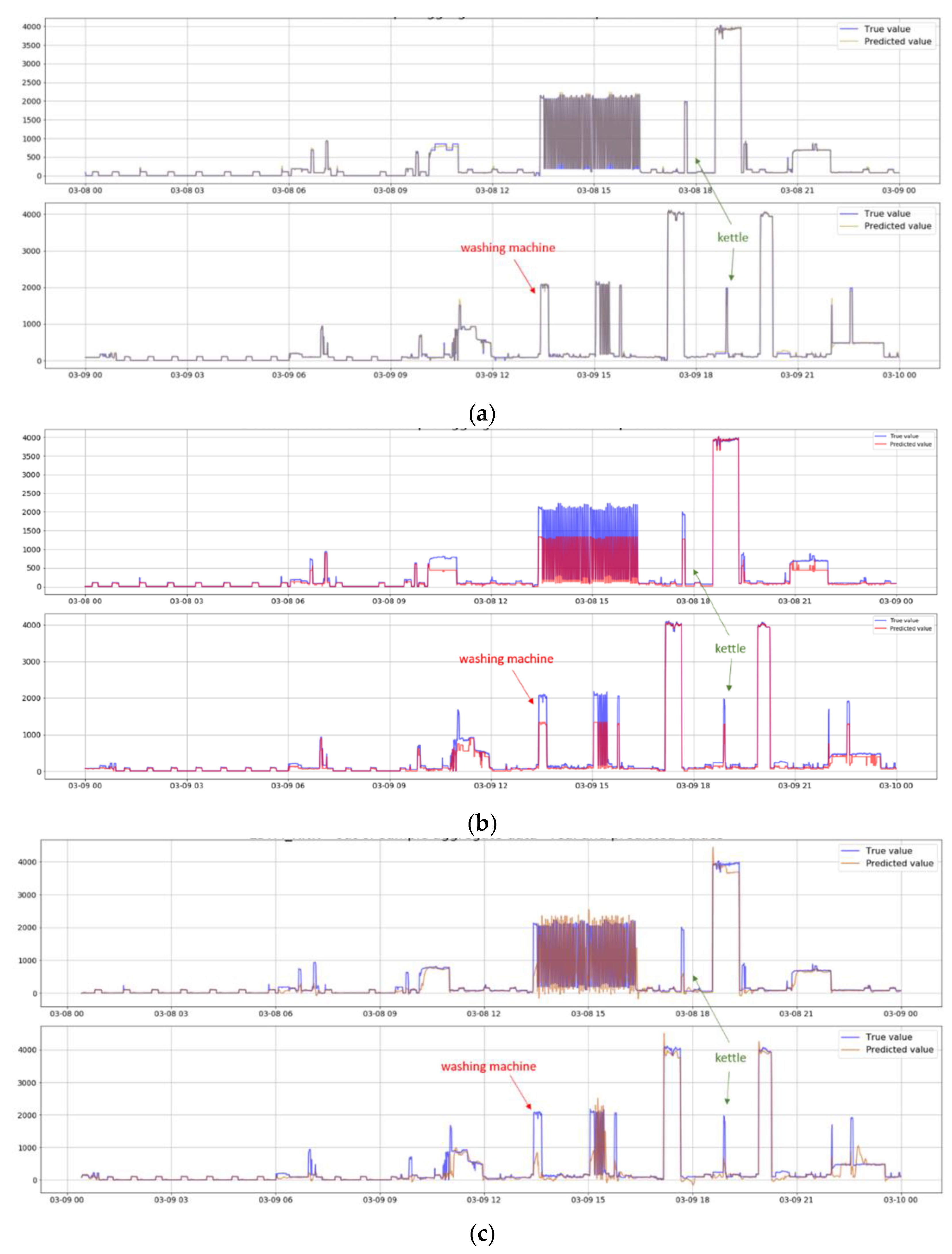
3.2. External Test in Real Total Consumption Data
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Domorenok, E.; Graziano, P. Understanding the European Green Deal: A Narrative Policy Framework Approach. Eur. Policy Anal. 2023, 9, 9–29. [Google Scholar] [CrossRef]
- Fouquet, D.; Traum, Y. Steps Forward in the Implementation of the Green Deal. Renew. Energy Law Policy Rev. 2023, 11, 33–34. [Google Scholar] [CrossRef]
- Buckley, N.; Mills, G.; Reinhart, C.; Berzolla, Z.M. Using Urban Building Energy Modelling (UBEM) to Support the New European Union’s Green Deal: Case Study of Dublin Ireland. Energy Build. 2021, 247, 111115. [Google Scholar] [CrossRef]
- Kougias, I.; Taylor, N.; Kakoulaki, G.; Jäger-Waldau, A. The Role of Photovoltaics for the European Green Deal and the Recovery Plan. Renew. Sustain. Energy Rev. 2021, 144, 111017. [Google Scholar] [CrossRef]
- Koasidis, K.; Marinakis, V.; Nikas, A.; Chira, K.; Flamos, A.; Doukas, H. Monetising Behavioural Change as a Policy Measure to Support Energy Management in the Residential Sector: A Case Study in Greece. Energy Policy 2022, 161, 112759. [Google Scholar] [CrossRef]
- Boemi, S.-N.; Papadopoulos, A.M. Energy Poverty and Energy Efficiency Improvements: A Longitudinal Approach of the Hellenic Households. Energy Build. 2019, 197, 242–250. [Google Scholar] [CrossRef]
- Kanellou, E.; Hinsch, A.; Vorkapić, V.; Torres, A.-D.; Konstantopoulos, G.; Matsagkos, N.; Doukas, H. Lessons Learnt and Policy Implications from Implementing the POWERPOOR Approach to Alleviate Energy Poverty. Sustainability 2023, 15, 8854. [Google Scholar] [CrossRef]
- Marinakis, V. Big Data for Energy Management and Energy-Efficient Buildings. Energies 2020, 13, 1555. [Google Scholar] [CrossRef]
- Pisello, A.L.; Castaldo, V.L.; Piselli, C.; Fabiani, C.; Cotana, F. How Peers’ Personal Attitudes Affect Indoor Microclimate and Energy Need in an Institutional Building: Results from a Continuous Monitoring Campaign in Summer and Winter Conditions. Energy Build. 2016, 126, 485–497. [Google Scholar] [CrossRef]
- Lopes, M.; Antunes, C.H.; Janda, K.B. Energy and Behaviour: Towards a Low Carbon Future; Academic Press: Cambridge, MA, USA, 2019; ISBN 978-0-12-818568-1. [Google Scholar]
- Mundaca, L.; Zhu, X.; Hackenfort, M. Behavioural Insights for Sustainable Energy Use. Energy Policy 2022, 171, 113292. [Google Scholar] [CrossRef]
- Grubler, A.; Wilson, C.; Bento, N.; Boza-Kiss, B.; Krey, V.; McCollum, D.L.; Rao, N.D.; Riahi, K.; Rogelj, J.; De Stercke, S.; et al. A Low Energy Demand Scenario for Meeting the 1.5 °C Target and Sustainable Development Goals without Negative Emission Technologies. Nat. Energy 2018, 3, 515–527. [Google Scholar] [CrossRef]
- Azevedo, I.; Bataille, C.; Bistline, J.; Clarke, L.; Davis, S. Net-Zero Emissions Energy Systems: What We Know and Do Not Know. Energy Clim. Chang. 2021, 2, 100049. [Google Scholar] [CrossRef]
- International Energy Agency Net Zero by 2050: A Roadmap for the Global Energy Sector 2021. Available online: https://www.iea.org/reports/net-zero-by-2050 (accessed on 1 September 2023).
- Lopes, M.A.R.; Antunes, C.H.; Martins, N. Towards More Effective Behavioural Energy Policy: An Integrative Modelling Approach to Residential Energy Consumption in Europe. Energy Res. Soc. Sci. 2015, 7, 84–98. [Google Scholar] [CrossRef]
- Hu, S.; Yan, D.; Azar, E.; Guo, F. A Systematic Review of Occupant Behavior in Building Energy Policy. Build. Environ. 2020, 175, 106807. [Google Scholar] [CrossRef]
- Perlaviciute, G. Contested Climate Policies and the Four Ds of Public Participation: From Normative Standards to What People Want. WIREs Clim. Chang. 2022, 13, e749. [Google Scholar] [CrossRef]
- Van den Broek, K.L. Household Energy Literacy: A Critical Review and a Conceptual Typology. Energy Res. Soc. Sci. 2019, 57, 101256. [Google Scholar] [CrossRef]
- Gerasopoulos, S.I.; Manousakis, N.M.; Psomopoulos, C.S. Smart Metering in EU and the Energy Theft Problem. Energy Effic. 2022, 15, 12. [Google Scholar] [CrossRef]
- Shin, C.; Rho, S.; Lee, H.; Rhee, W. Data Requirements for Applying Machine Learning to Energy Disaggregation. Energies 2019, 12, 1696. [Google Scholar] [CrossRef]
- Verma, A.; Anwar, A.; Mahmud, M.A.P.; Ahmed, M.; Kouzani, A. A Comprehensive Review on the NILM Algorithms for Energy Disaggregation. arXiv 2021, arXiv:2102.12578. [Google Scholar]
- Batra, N.; Kukunuri, R.; Pandey, A.; Malakar, R.; Kumar, R.; Krystalakos, O.; Zhong, M.; Meira, P.; Parson, O. Towards Reproducible State-of-the-Art Energy Disaggregation. In Proceedings of the 6th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, New York, NY, USA, 13–14 November 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 193–202. [Google Scholar]
- Barker, S.; Mishra, A.; Irwin, D.; Cecchet, E.; Shenoy, P.; Albrecht, J. Smart*: An Open Data Set and Tools for Enabling Research in Sustainable Homes. In Proceedings of the 2012 Workshop on Data Mining Applications in Sustainability, Beijing, China, 12 August 2012. [Google Scholar]
- Kolter, J.Z.; Johnson, M.J. REDD: A Public Data Set for Energy Disaggregation Research. Artif. Intell. 2011, 25, 59–62. [Google Scholar]
- Dash, S.; Sahoo, N.C. Electric Energy Disaggregation via Non-Intrusive Load Monitoring: A State-of-the-Art Systematic Review. Electr. Power Syst. Res. 2022, 213, 108673. [Google Scholar] [CrossRef]
- Pereira, L.; Nunes, N. Performance Evaluation in Non-Intrusive Load Monitoring: Datasets, Metrics, and Tools—A Review. WIREs Data Min. Knowl. Discov. 2018, 8, e1265. [Google Scholar] [CrossRef]
- Anderson, K.D.; Ocneanu, A.; Carlson, D.R.; Rowe, A.G.; Berges, M. BLUED: A Fully Labeled Public Dataset for Event-Based Non-Intrusive Load Monitoring Research. In Proceedings of the 2nd KDD Workshop on Data Mining Applications in Sustainability, Beijing, China, 12–16 August 2012. [Google Scholar]
- Jazizadeh, F.; Afzalan, M.; Becerik-Gerber, B.; Soibelman, L. EMBED: A Dataset for Energy Monitoring through Building Electricity Disaggregation. In Proceedings of the Ninth International Conference on Future Energy Systems, Karlsruhe, Germany, 12–15 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 230–235. [Google Scholar]
- Reinhardt, A.; Baumann, P.; Burgstahler, D.; Hollick, M.; Chonov, H.; Werner, M.; Steinmetz, R. On the Accuracy of Appliance Identification Based on Distributed Load Metering Data. In Proceedings of the 2012 Sustainable Internet and ICT for Sustainability (SustainIT), Pisa, Italy, 4–5 October 2012; pp. 1–9. [Google Scholar]
- Makonin, S.; Popowich, F.; Bartram, L.; Gill, B.; Bajić, I.V. AMPds: A Public Dataset for Load Disaggregation and Eco-Feedback Research. In Proceedings of the 2013 IEEE Electrical Power & Energy Conference, Halifax, NS, Canada, 21–23 August 2013; pp. 1–6. [Google Scholar]
- Batra, N.; Gulati, M.; Singh, A.; Srivastava, M.B. It’s Different: Insights into Home Energy Consumption in India. In Proceedings of the 5th ACM Workshop on Embedded Systems For Energy-Efficient Buildings, Roma, Italy, 13–14 November 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 1–8. [Google Scholar]
- Beckel, C.; Kleiminger, W.; Cicchetti, R.; Staake, T.; Santini, S. The ECO Data Set and the Performance of Non-Intrusive Load Monitoring Algorithms. In Proceedings of the 1st ACM Conference on Embedded Systems for Energy-Efficient Buildings, Memphis, TN, USA, 3–6 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 80–89. [Google Scholar]
- Kelly, J.; Knottenbelt, W. Neural Nilm: Deep Neural Networks Applied to Energy Disaggregation. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, Seoul, Republic of Korea, 4–5 November 2015. [Google Scholar]
- Monacchi, A.; Egarter, D.; Elmenreich, W.; D’Alessandro, S.; Tonello, A.M. GREEND: An Energy Consumption Dataset of Households in Italy and Austria. In Proceedings of the 2014 IEEE International Conference on Smart Grid Communications (SmartGridComm), Venice, Italy, 3–6 November 2014; pp. 511–516. [Google Scholar]
- Murray, D.; Liao, J.; Stankovic, L.; Stankovic, V.; Hauxwell-Baldwin, R.; Wilson, C.; Coleman, M.; Kane, T.; Firth, S. A Data Management Platform for Personalised Real-Time Energy Feedback: 8th International Conference on Energy Efficiency in Domestic Appliances and Lighting. In Proceedings of the 8th International Conference on Energy Efficiency in Domestic Appliances and Lighting, Lucerne, Switzerland, 26–28 August 2015. [Google Scholar]
- Parson, O.; Fisher, G.; Hersey, A.; Batra, N.; Kelly, J.; Singh, A.; Knottenbelt, W.; Rogers, A. Dataport and NILMTK: A Building Data Set Designed for Non-Intrusive Load Monitoring. In Proceedings of the 2015 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Orlando, FL, USA, 14–16 December 2015; pp. 210–214. [Google Scholar]
- Gisler, C.; Ridi, A.; Zufferey, D.; Khaled, O.A.; Hennebert, J. Appliance Consumption Signature Database and Recognition Test Protocols. In Proceedings of the 2013 8th International Workshop on Systems, Signal Processing and their Applications (WoSSPA), Algiers, Algeria, 12–15 May 2013; pp. 336–341. [Google Scholar]
- Makonin, S. HUE: The Hourly Usage of Energy Dataset for Buildings in British Columbia. Data Brief 2019, 23, 103744. [Google Scholar] [CrossRef] [PubMed]
- Saldanha, N.; Beausoleil-Morrison, I. Measured End-Use Electric Load Profiles for 12 Canadian Houses at High Temporal Resolution. Energy Build. 2012, 49, 519–530. [Google Scholar] [CrossRef]
- Makonin, S.; Wang, Z.J.; Tumpach, C. RAE: The Rainforest Automation Energy Dataset for Smart Grid Meter Data Analysis. Data 2018, 3, 8. [Google Scholar] [CrossRef]
- Kriechbaumer, T.; Jacobsen, H.-A. BLOND, a Building-Level Office Environment Dataset of Typical Electrical Appliances. Sci. Data 2018, 5, 180048. [Google Scholar] [CrossRef] [PubMed]
- Picon, T.; Meziane, M.N.; Ravier, P.; Lamarque, G.; Novello, C.; Bunetel, J.-C.L.; Raingeaud, Y. COOLL: Controlled On/Off Loads Library, a Public Dataset of High-Sampled Electrical Signals for Appliance Identification. arXiv 2016, arXiv:1611.05803. [Google Scholar]
- Chen, V.L.; Delmas, M.A.; Locke, S.L.; Singh, A. Dataset on Information Strategies for Energy Conservation: A Field Experiment in India. Data Brief 2018, 16, 713–716. [Google Scholar] [CrossRef]
- Uttama Nambi, A.S.N.; Reyes Lua, A.; Prasad, V.R. LocED: Location-Aware Energy Disaggregation Framework. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, Seoul, Republic of Korea, 4–5 November 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 45–54. [Google Scholar]
- Gao, J.; Giri, S.; Kara, E.C.; Bergés, M. PLAID: A Public Dataset of High-Resoultion Electrical Appliance Measurements for Load Identification Research: Demo Abstract. In Proceedings of the 1st ACM Conference on Embedded Systems for Energy-Efficient Buildings, Seoul, Republic of Korea, 4–6 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 198–199. [Google Scholar]
- Kahl, M.; Haq, A.; Kriechbaumer, T.; Jacobsen, H. WHITED-A Worldwide Household and Industry Transient Energy Data Set. In Proceedings of the 3rd International Workshop on Non-Intrusive Load Monitoring, Vancouver, BC, Canada, 14–15 May 2016. [Google Scholar]
- Shin, C.; Lee, E.; Han, J.; Yim, J.; Rhee, W.; Lee, H. The ENERTALK Dataset, 15 Hz Electricity Consumption Data from 22 Houses in Korea. Sci. Data 2019, 6, 193. [Google Scholar] [CrossRef]
- Pereira, L.; Quintal, F.; Gonçalves, R.; Nunes, N.J. SustData: A Public Dataset for ICT4S Electric Energy Research; Atlantis Press: Amsterdam, The Netherlands, 2014; pp. 359–368. [Google Scholar]
- Ribeiro, M.; Pereira, L.; Quintal, F.; Nunes, N. SustDataED: A Public Dataset for Electric Energy Disaggregation Research; Atlantis Press: Amsterdam, The Netherlands, 2016; pp. 244–245. [Google Scholar]
- Chavan, D.R.; More, D.S.; Khot, A.M. IEDL: Indian Energy Dataset with Low Frequency for NILM. Energy Rep. 2022, 8, 701–709. [Google Scholar] [CrossRef]
- Pullinger, M.; Kilgour, J.; Goddard, N.; Berliner, N.; Webb, L.; Dzikovska, M.; Lovell, H.; Mann, J.; Sutton, C.; Webb, J.; et al. The IDEAL Household Energy Dataset, Electricity, Gas, Contextual Sensor Data and Survey Data for 255 UK Homes. Sci. Data 2021, 8, 146. [Google Scholar] [CrossRef] [PubMed]
- Yan, L.; Han, J.; Xu, R.; Li, Z. LIFTED: Household Appliance-Level Load Dataset and Data Compression with Lossless Coding Considering Precision. In Proceedings of the 2020 IEEE Power & Energy Society General Meeting (PESGM), Montreal, QC, Canada, 2–6 August 2020; pp. 1–5. [Google Scholar]
- Pipattanasomporn, M.; Chitalia, G.; Songsiri, J.; Aswakul, C.; Pora, W.; Suwankawin, S.; Audomvongseree, K.; Hoonchareon, N. CU-BEMS, Smart Building Electricity Consumption and Indoor Environmental Sensor Datasets. Sci. Data 2020, 7, 241. [Google Scholar] [CrossRef] [PubMed]
- Hart, G.W. Residential Energy Monitoring and Computerized Surveillance via Utility Power Flows. IEEE Technol. Soc. Mag. 1989, 8, 12–16. [Google Scholar] [CrossRef]
- Hart, G.W. Nonintrusive Appliance Load Monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Faustine, A.; Mvungi, N.H.; Kaijage, S.; Michael, K. A Survey on Non-Intrusive Load Monitoring Methodies and Techniques for Energy Disaggregation Problem. arXiv 2017, arXiv:1703.00785. [Google Scholar]
- Mari, S.; Bucci, G.; Ciancetta, F.; Fiorucci, E.; Fioravanti, A. A Review of Non-Intrusive Load Monitoring Applications in Industrial and Residential Contexts. Energies 2022, 15, 9011. [Google Scholar] [CrossRef]
- Kaselimi, M.; Protopapadakis, E.; Voulodimos, A.; Doulamis, N.; Doulamis, A. Multi-Channel Recurrent Convolutional Neural Networks for Energy Disaggregation. IEEE Access 2019, 7, 81047–81056. [Google Scholar] [CrossRef]
- Li, D.; Li, J.; Zeng, X.; Stankovic, V.; Stankovic, L.; Shi, Q. Non-Intrusive Load Monitoring for Multi-Objects in Smart Building. In Proceedings of the 2021 International Balkan Conference on Communications and Networking (BalkanCom), Novi Sad, Serbia, 20–22 September 2021; pp. 117–121. [Google Scholar]
- Jiang, J.; Kong, Q.; Plumbley, M.D.; Gilbert, N.; Hoogendoorn, M.; Roijers, D.M. Deep Learning-Based Energy Disaggregation and On/Off Detection of Household Appliances. ACM Trans. Knowl. Discov. Data 2021, 15, 50:1–50:21. [Google Scholar] [CrossRef]
- Gawin, B.; Małkowski, R.; Rink, R. Will NILM Technology Replace Multi-Meter Telemetry Systems for Monitoring Electricity Consumption? Energies 2023, 16, 2275. [Google Scholar] [CrossRef]
- Cheng, X.; Zhao, M.; Zhang, J.; Wang, J.; Pan, X.; Liu, X. TransNILM: A Transformer-Based Deep Learning Model for Non-Intrusive Load Monitoring. In Proceedings of the 2022 International Conference on High Performance Big Data and Intelligent Systems (HDIS, Tianjin, China, 10–11 December 2022; pp. 13–20. [Google Scholar]
- Zhou, X.; Feng, J.; Li, Y. Non-Intrusive Load Decomposition Based on CNN–LSTM Hybrid Deep Learning Model. Energy Rep. 2021, 7, 5762–5771. [Google Scholar] [CrossRef]
- Linh, N.V.; Arboleya, P. Deep Learning Application to Non-Intrusive Load Monitoring. In Proceedings of the 2019 IEEE Milan PowerTech, Milan, Italy, 22–26 June 2019; pp. 1–5. [Google Scholar]
- Zoha, A.; Abbasi, Q.H.; Imran, M.A. A Non-Event Based Approach for Non-Intrusive Load Monitoring. In Wireless Automation as an Enabler for the Next Industrial Revolution; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2020; pp. 173–191. ISBN 978-1-119-55263-5. [Google Scholar]
- Wu, Z.; Wang, C.; Peng, W.; Liu, W.; Zhang, H. Non-Intrusive Load Monitoring Using Factorial Hidden Markov Model Based on Adaptive Density Peak Clustering. Energy Build. 2021, 244, 111025. [Google Scholar] [CrossRef]
- Le, T.-T.-H.; Kim, H. Non-Intrusive Load Monitoring Based on Novel Transient Signal in Household Appliances with Low Sampling Rate. Energies 2018, 11, 3409. [Google Scholar] [CrossRef]
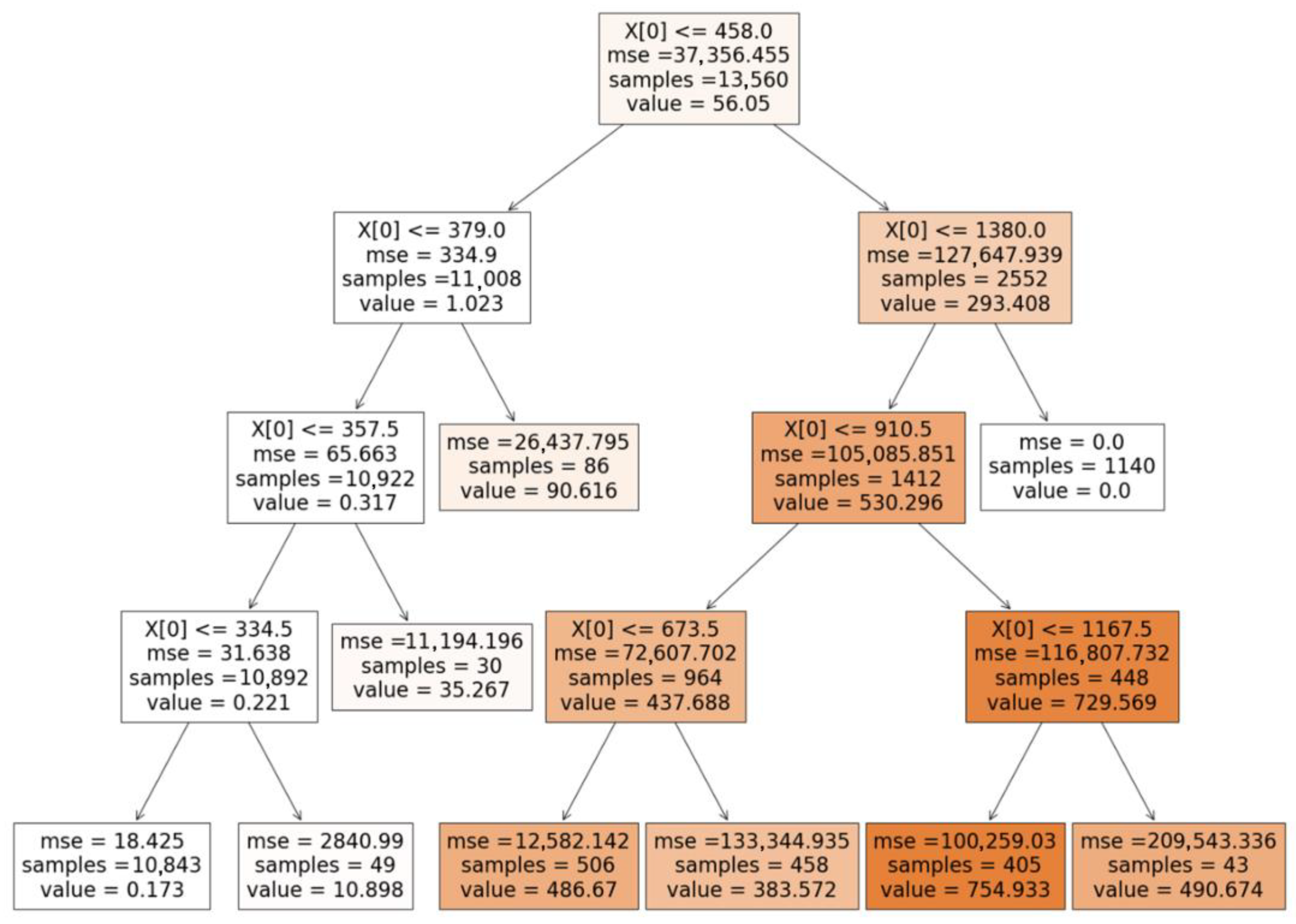
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Tree-Based Methods. In An Introduction to Statistical Learning: With Applications in R; James, G., Witten, D., Hastie, T., Tibshirani, R., Eds.; Springer Texts in Statistics; Springer: New York, NY, USA, 2021; pp. 327–365. ISBN 978-1-07-161418-1. [Google Scholar]
- Brito, R.; Wong, M.-C.; Zhang, H.C.; Da Costa Junior, M.G.; Lam, C.-S.; Wong, C.-K. Instantaneous Active and Reactive Load Signature Applied in Non-Intrusive Load Monitoring Systems. IET Smart Grid 2021, 4, 121–133. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, C.; Shen, Y.; Zhao, X.; Gao, S.; Huang, X. Non-Intrusive Energy Estimation Using Random Forest Based Multi-Label Classification and Integer Linear Programming. Energy Rep. 2021, 7, 283–291. [Google Scholar] [CrossRef]
- Zainab, A.; Ghrayeb, A.; Abu-Rub, H.; Refaat, S.S.; Bouhali, O. Distributed Tree-Based Machine Learning for Short-Term Load Forecasting with Apache Spark. IEEE Access 2021, 9, 57372–57384. [Google Scholar] [CrossRef]
- Alsabban, M.S.; Salem, N.; Malik, H.M. Long Short-Term Memory Recurrent Neural Network (LSTM-RNN) Power Forecasting. In Proceedings of the 2021 13th IEEE PES Asia Pacific Power & Energy Engineering Conference (APPEEC), Kerala, India, 21–23 November 2021; pp. 1–8. [Google Scholar]
- Kim, J.; Le, T.-T.-H.; Kim, H. Nonintrusive Load Monitoring Based on Advanced Deep Learning and Novel Signature. Comput. Intell. Neurosci. 2017, 2017, e4216281. [Google Scholar] [CrossRef] [PubMed]
- Quek, Y.T.; Woo, W.L.; Logenthiran, T. Load Disaggregation Using One-Directional Convolutional Stacked Long Short-Term Memory Recurrent Neural Network. IEEE Syst. J. 2020, 14, 1395–1404. [Google Scholar] [CrossRef]
- Biansoongnern, S.; Plangklang, B. Nonintrusive Load Monitoring (NILM) Using an Artificial Neural Network in Embedded System with Low Sampling Rate. In Proceedings of the 2016 13th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Chiang Mai, Thailand, 28 June–1 July 2016; pp. 1–4. [Google Scholar]
- Krystalakos, O.; Nalmpantis, C.; Vrakas, D. Sliding Window Approach for Online Energy Disaggregation Using Artificial Neural Networks. In Proceedings of the 10th Hellenic Conference on Artificial Intelligence, Patras Greece, 9–12 July 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Khodayar, M.; Wang, J.; Wang, Z. Energy Disaggregation via Deep Temporal Dictionary Learning. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1696–1709. [Google Scholar] [CrossRef]
- Sirojan, T.; Phung, B.T.; Ambikairajah, E. Deep Neural Network Based Energy Disaggregation. In Proceedings of the 2018 IEEE International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–15 August 2018; pp. 73–77. [Google Scholar]
- Gao, Y.; Schay, A.; Hou, D.; Ortiz, J. Home Appliance Energy Disaggregation Using Low Frequency Data and Machine Learning Classifiers. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 76–83. [Google Scholar]
- Buddhahai, B.; Wongseree, W.; Rakkwamsuk, P. An Energy Prediction Approach for a Nonintrusive Load Monitoring in Home Appliances. IEEE Trans. Consum. Electron. 2020, 66, 96–105. [Google Scholar] [CrossRef]
- Marchiori, A.; Hakkarinen, D.; Han, Q.; Earle, L. Circuit-Level Load Monitoring for Household Energy Management. IEEE Pervasive Comput. 2011, 10, 40–48. [Google Scholar] [CrossRef]
- Zoha, A.; Gluhak, A.; Imran, M.A.; Rajasegarar, S. Non-Intrusive Load Monitoring Approaches for Disaggregated Energy Sensing: A Survey. Sensors 2012, 12, 16838–16866. [Google Scholar] [CrossRef]
- Lu, M.; Li, Z. A Hybrid Event Detection Approach for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2020, 11, 528–540. [Google Scholar] [CrossRef]
- Mauch, L.; Yang, B. A Novel DNN-HMM-Based Approach for Extracting Single Loads from Aggregate Power Signals. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 2384–2388. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Study | Duration of Measurements | Smart Meters Used |
|---|---|---|---|
| REDD | [24] | 3–19 days | Up to 24 plug-level Enmetric Powerports |
| BLUED | [27] | 7 days | 28 plug-level,12 environmental sensors |
| EMBED | [28] | 14–28 days | Enmetric Powerports |
| TRACEBASE | [29] | Ν/A | 158 Plugwise submeters |
| AMPds | [30] | 365 days | 21 submeters |
| iAWE | [31] | 73 days | 10 jPlugs |
| ECO | [32] | 240 days | 45 smart plugs |
| UK-DALE | [33] | 36–655 days | 5–53 plugs/household |
| SMART * | [23] | 90 days | 29 appliance plugs, 5 circuit monitors |
| GREEND | [34] | 365 days | 9 plugs/household |
| REFIT | [35] | 213 days | 16–20 smart meters/household |
| DATAPORT | [36] | 4 years | Ν/A |
| ACS-F1 | [37] | 2 1 h cycles per appliance | 1 PLOGG meter per appliance |
| HUE | [38] | 3 years | Ν/A |
| MEULPv1 | [39] | 1 year | 8 submeters |
| RAE | [40] | 59 and 72 days | N/A |
| BLOND-50 BLOND-250 | [41] | 213 days 48 days | 15 submeters |
| COOLL | [42] | 2 h | 1 smart meter |
| Dataport | [36] | >1 month | 1 smart meter per household (capability to measure 12 circuits) |
| DISEC | [43] | 284 days | Ν/A |
| DRED | [44] | 84 days | 12 Plugwise Circle meters |
| PLAID | [45] | 90 days | 1 smart meter |
| WHITED | [46] | Ν/A | 1 smart meter (no simultaneous measurements) |
| ENERTALK | [47] | 122 days | 1–7 ENERTALK plugs/household |
| SustData | [48] | 1144 days | N/A |
| SustDataED | [49] | 10 days | 17 Plugwise meters |
| IEDL | [50] | >105 days | 5 SunStar meters |
| IDEAL | [51] | Average of 286 days | 8 smart meters |
| LIFTED | [52] | 7 days | 1 m per 15 appliances |
| CU-BEMS | [53] | 6 months | 21 power meters, 24 sensors |
| Layer Type | Layer Hyperparameters |
|---|---|
| Input Layer | Shape (50, 1) |
| 1D Convolutional Layer | Filters = 16, Filter size = 4, Stride = 1, Activation = Linear |
| Bidirectional LSTM | Size: 128, Merge = Concatenate, Activation = Linear |
| Dropout | 0.3 |
| Bidirectional LSTM | Size: 256, Merge = Concatenate, Activation = Linear |
| Dropout | 0.3 |
| Dense | Size: 128, Merge = Concatenate, Activation = tanh |
| Dropout | 0.3 |
| Dense | Size: 1, Activation = Linear |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koasidis, K.; Marinakis, V.; Doukas, H.; Doumouras, N.; Karamaneas, A.; Nikas, A. Equipment- and Time-Constrained Data Acquisition Protocol for Non-Intrusive Appliance Load Monitoring. Energies 2023, 16, 7315. https://doi.org/10.3390/en16217315
Koasidis K, Marinakis V, Doukas H, Doumouras N, Karamaneas A, Nikas A. Equipment- and Time-Constrained Data Acquisition Protocol for Non-Intrusive Appliance Load Monitoring. Energies. 2023; 16(21):7315. https://doi.org/10.3390/en16217315
Chicago/Turabian StyleKoasidis, Konstantinos, Vangelis Marinakis, Haris Doukas, Nikolaos Doumouras, Anastasios Karamaneas, and Alexandros Nikas. 2023. "Equipment- and Time-Constrained Data Acquisition Protocol for Non-Intrusive Appliance Load Monitoring" Energies 16, no. 21: 7315. https://doi.org/10.3390/en16217315