
Evaluation of Various Tree-Based Ensemble Models for Estimating Solar Energy Resource Potential in Different Climatic Zones of China


(This article belongs to the Section B1: Energy and Climate Change)
Abstract
:1. Introduction
1.1. A Review of Empirical Models for Rs Estimation
1.2. A Review of Physical Transmission Models for Rs Estimation
1.3. A Review of Artificial Neural Network (ANN) Models for Rs Estimation
1.4. A Review of Tree-Based Ensemble Models for Rs Estimation
2. Materials and Methods
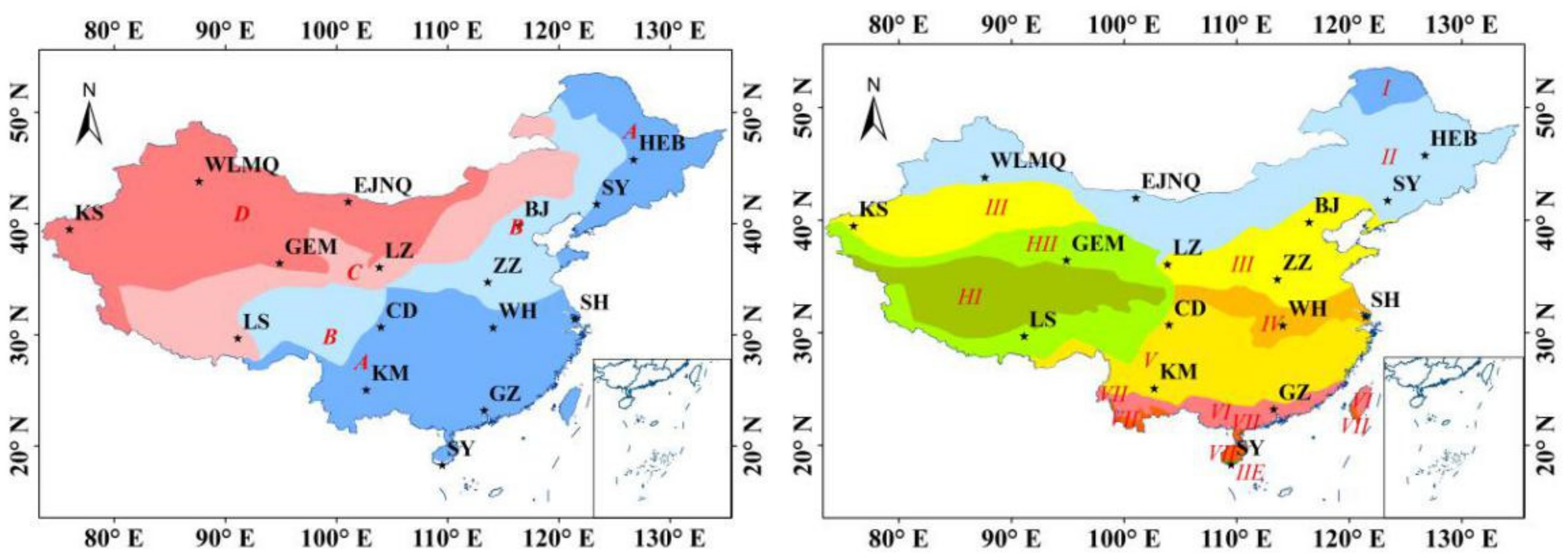
2.1. Study Area
2.2. Data Collection and Quality Control
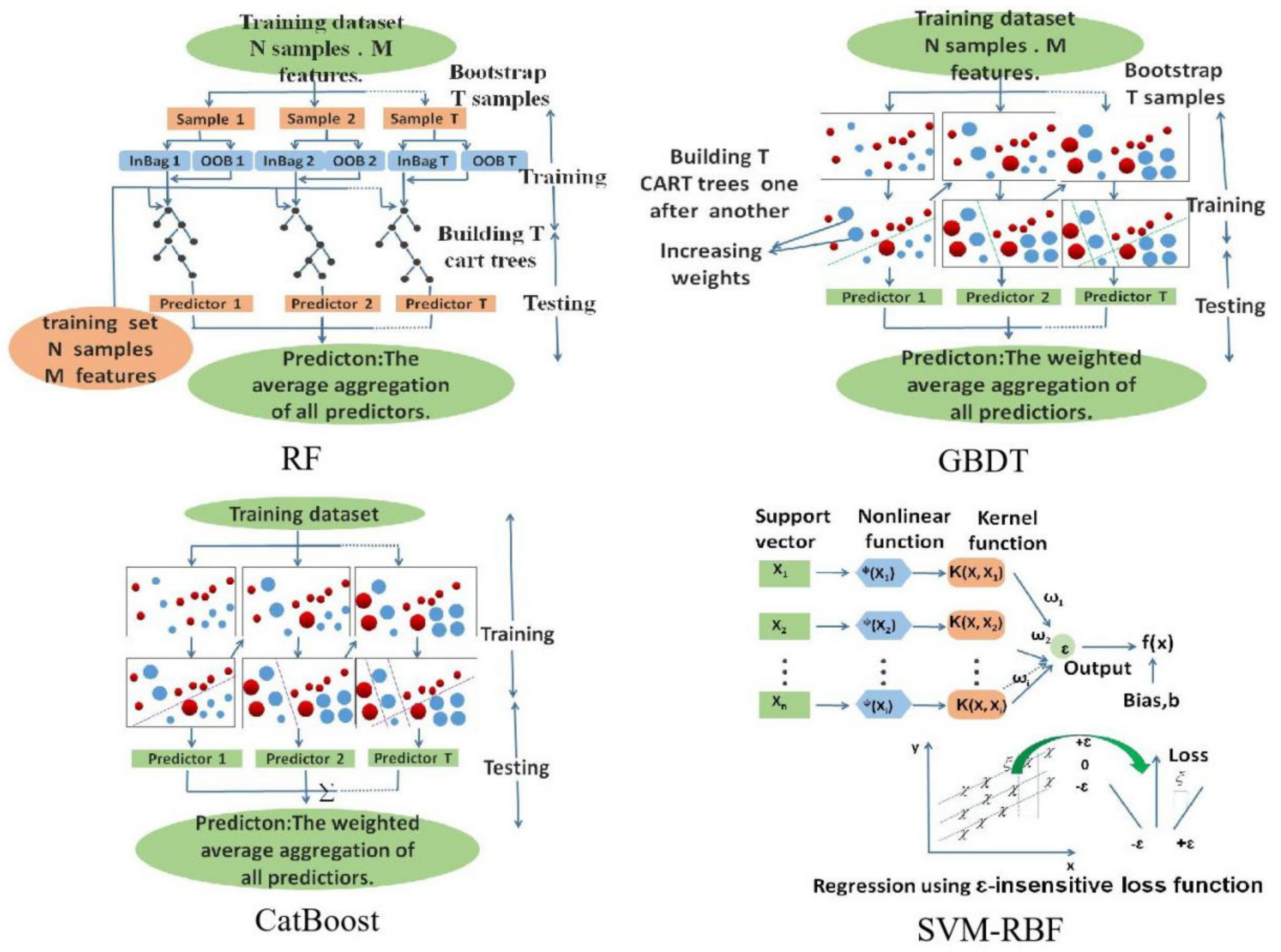
2.3. Tree-Based Ensemble Models
2.3.1. Classification and Regression Trees (CART)
2.3.2. Extremely Randomized Trees (ET)
2.3.3. Random Forest (RF)
2.3.4. Gradient Boosting Decision Tree (GBDT)
2.3.5. Extreme Gradient Boosting (XGBoost)
2.3.6. Gradient Boosting with Categorical Features Support (CatBoost)
2.3.7. Light Gradient Boosting Method (LightGBM)
2.4. Multi-Layer Perceotron (MLP)
2.5. Support Vector Machine (SVM)
2.6. Input Combinations and K-Fold Cross-Validation
2.7. Statistical Evaluation
3. Results
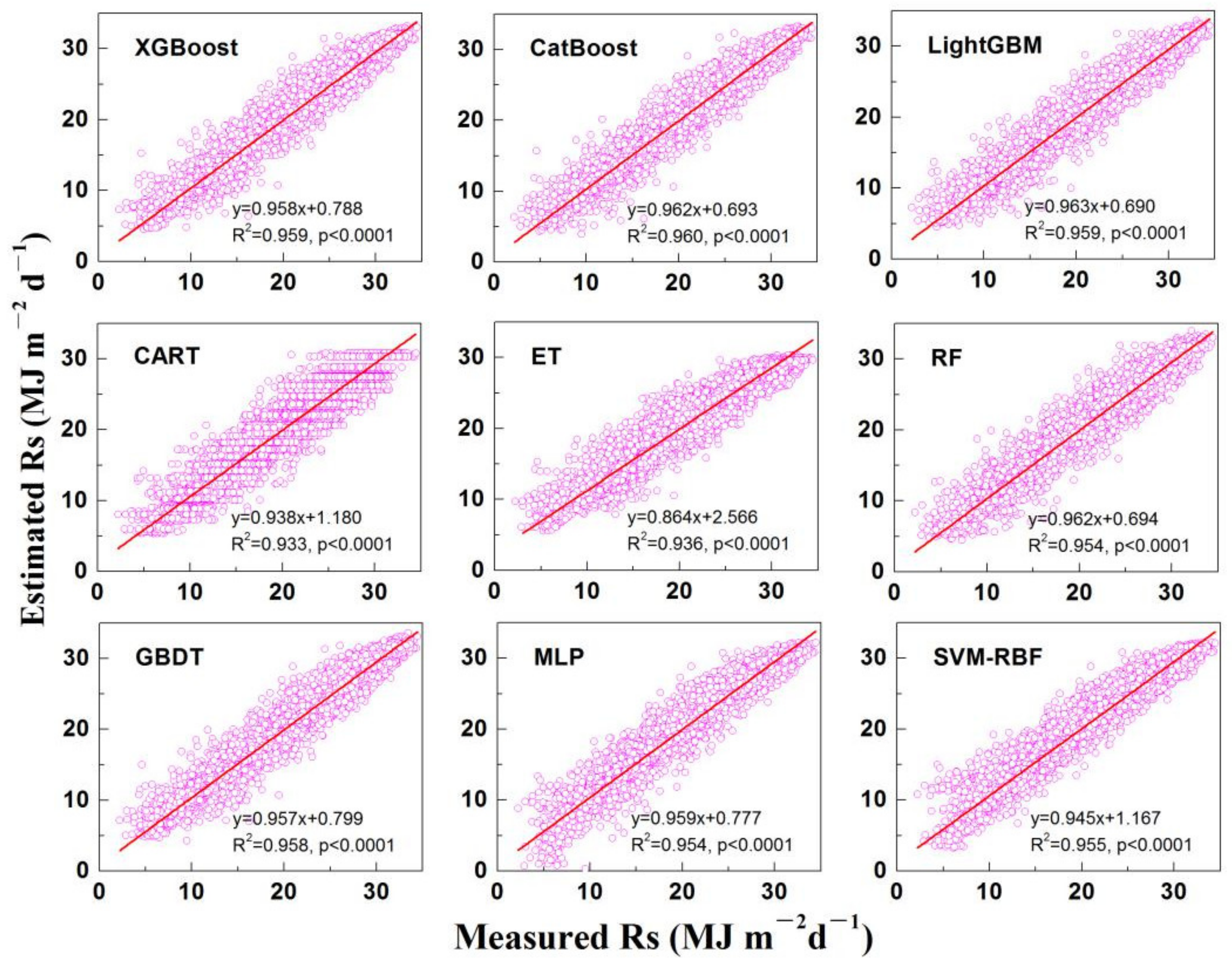
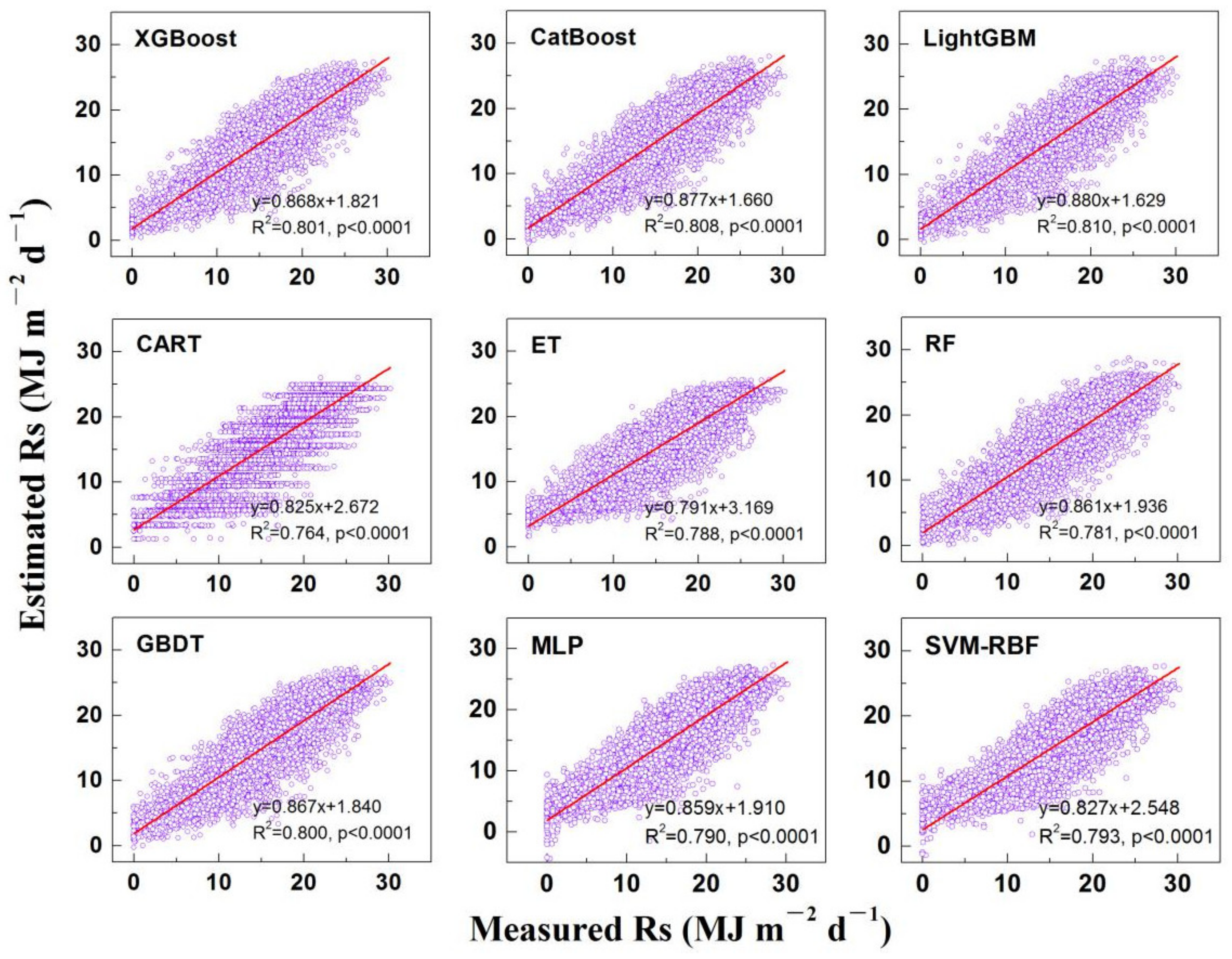
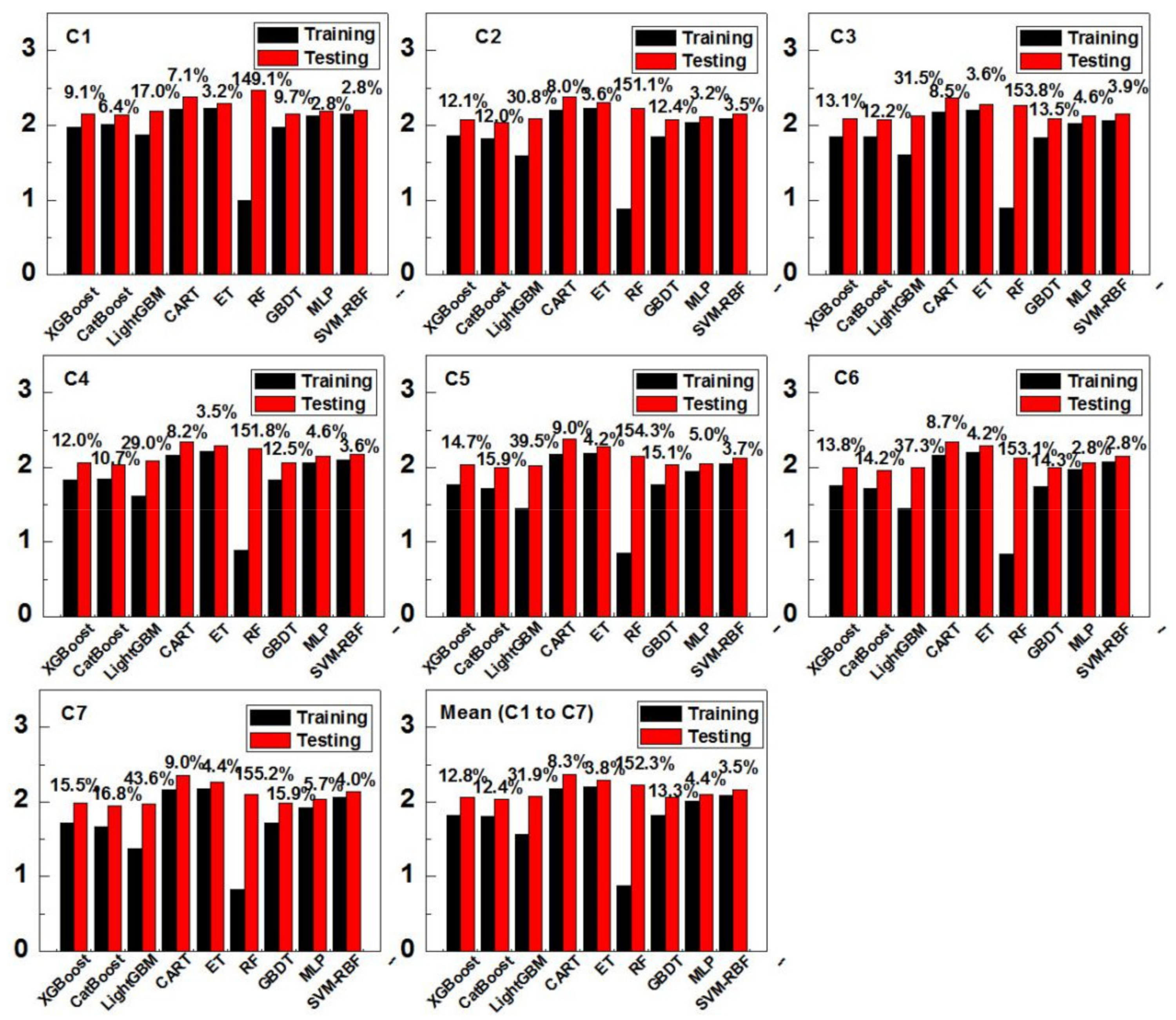
3.1. Comparison of Model Accuracy under Various Input Combinations
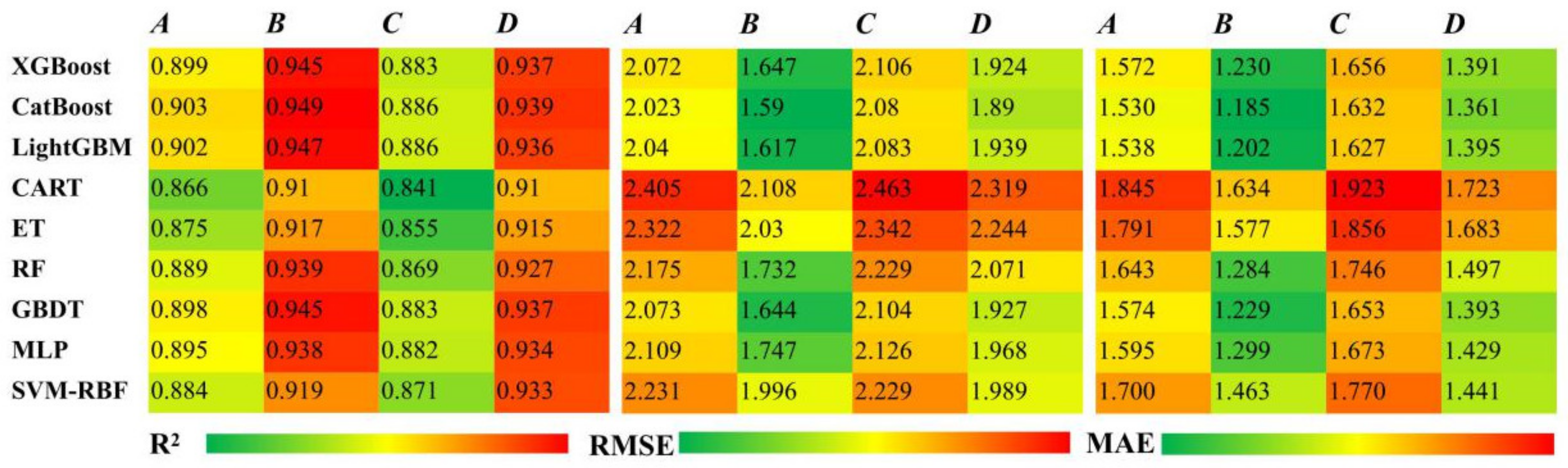
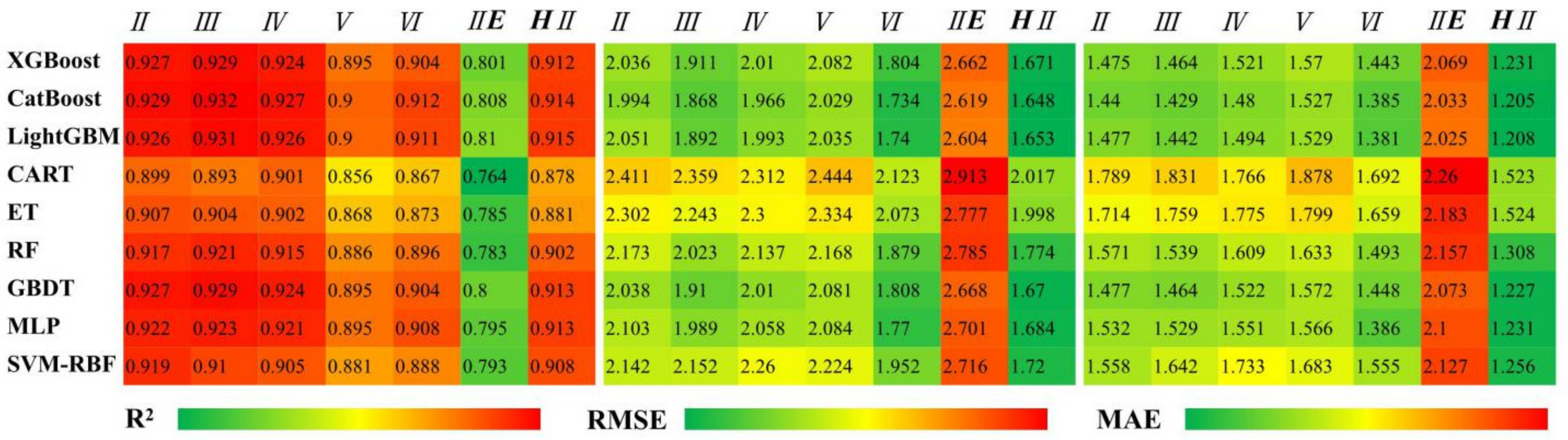
3.2. Comparison of Various Model Accuracy at Different Stations in Various Climatic Zones
3.3. Comparison of Stability of Various Models
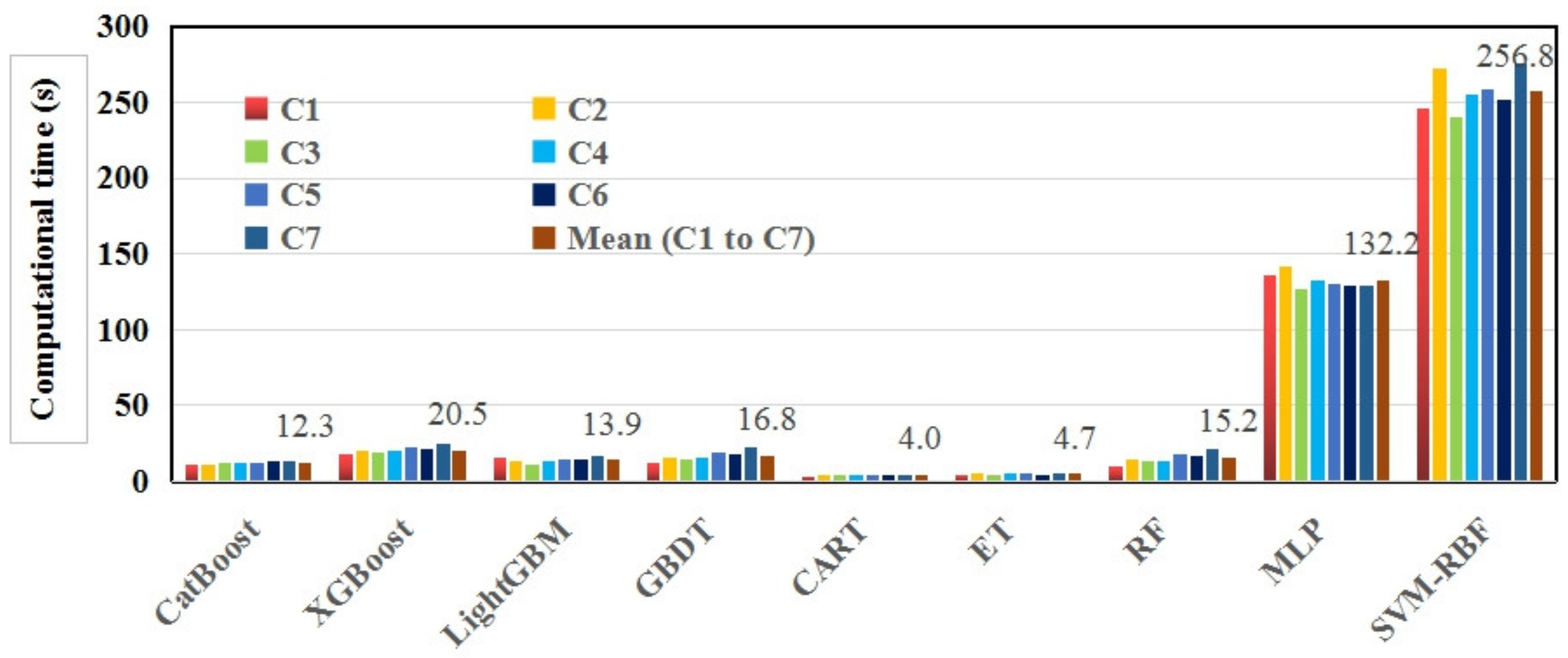
3.4. Computational Costs of Various Models
4. Discussion
4.1. Input Combination Strategy of Meteorological Parameters
4.2. Prediction Accuracy of Various Models in Various Climatic Zones
4.3. Stability of Various Models
4.4. Computational Costs of Various Models under Different Input Combinations
4.5. Comprehensive Evaluation of Various Models
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Rs | Global solar radiation/solar energy resource potential (MJ m−2) |
| Ra | Extra-terrestrial solar radiation (MJ m−2) |
| DHI | Direct horizontal irradiance (MJ m−2) |
| PAR | Photosynthetically active radiation (MJ m−2) |
| n | Observed sunshine duration (h) |
| N | Maximum possible sunshine duration (h) |
| T | Air temperature (°C) |
| Ta | Annual mean air temperature (°C) |
| Tmax | Maximum temperature (°C) |
| Tmin | Minimum temperature (°C) |
| Hr | Relative humidity (%) |
| Pre | Precipitation (mm) |
| U10 | Wind speed at 10 m height (ms−1) |
| Prs | Pressure (hpa) |
| ETo | Reference evapotranspiration (mm) |
| R | Determination coefficient |
| RMSE | Root mean square error |
| MAE | Mean absolute error |
| MBE | Mean bias error |
| SVM | Support vector machine |
| ANN | Artificial neural network |
| MLP | Multi-layer perceptron |
| ANFIS | Adaptive neuro fuzzy inference system |
| TBAM | Tree-based assemble mode |
| RF | Random forest |
| GBDT | Gradient boosting decision tree |
| XGBoost | Extreme gradient boosting |
| CatBoost | Gradient boosting with categorical features support |
| LightGBM | Light gradient boosting method |
| ANFIS-GP | ANFIS with grid partition |
| ANFIS-SC | ANFIS with subtractive clustering |
Appendix A
References
- Wild, M. Enlightening Global Dimming and Brightening. Bull. Am. Meteorol. Soc. 2012, 93, 27–37. [Google Scholar] [CrossRef]
- The International Renewable Energy Agency. Renewable Energy Statistics; IRENA: Masdar, United Arab Emirates, 2019. [Google Scholar]
- China National Renewable Energy Centre. China Wind, Solar and Bioenergy Roadmap, 2050; CNREC: Beijing, China, 2014. [Google Scholar]
- Chen, F.; Zhou, Z.; Lin, A.; Niu, J.; Qin, W.; Zhong, Y. Evaluation of Direct Horizontal Irradiance in China Using a Physically-Based Model and Machine Learning Methods. Energies 2019, 12, 150. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wild, M. A new look at solar dimming and brightening in China. Geophys. Res. Lett. 2016, 43, 11777–11785. [Google Scholar] [CrossRef]
- Fan, J.; Chen, B.; Wu, L.; Zhang, F.; Lu, X.; Xiang, Y. Evaluation and development of temperature-based empirical models for estimating daily global solar radiation in humid regions. Energy 2018, 144, 903–914. [Google Scholar] [CrossRef]
- Ehnberg, J.; Bollen, M. Simulation of global solar radiation based on cloud observations. Sol. Energy 2005, 78, 157–162. [Google Scholar] [CrossRef]
- Fan, J.; Wang, X.; Wu, L.; Zhang, F.; Bai, H. New combined models for estimating daily global solar radiation based on sunshine duration in humid regions: A case study in South China. Energy Convers. Manag. 2018, 156, 618–625. [Google Scholar] [CrossRef]
- Zang, H.; Cheng, L.; Ding, T.; Cheung, K.W.; Wang, M.; Wei, Z.; Sun, G. Estimation and validation of daily global solar radiation by day of the year-based models for different climates in China. Renew. Energy 2019, 135, 984–1003. [Google Scholar] [CrossRef]
- Chukwujindu, N.S. A comprehensive review of empirical models for estimating global solar radiation in Africa. Renew. Sustain. Energy Rev. 2017, 78, 955–995. [Google Scholar] [CrossRef]
- Chen, J.; He, L.; Yang, H.; Ma, M.; Chen, Q.; Wu, S.J.; Xiao, Z.L. Empirical models for estimating monthly global solar radiation: A most comprehensive review and comparative case study in China. Renew. Sustain. Energy Rev. 2019, 108, 91–111. [Google Scholar] [CrossRef]
- Wang, L.; Kisi, O.; Zounemat-Kermani, M.; Salazar, G.A.; Zhu, Z.; Gong, W. Solar radiation prediction using different techniques: Model evaluation and comparison. Renew. Sustain. Energy Rev. 2016, 61, 384–397. [Google Scholar] [CrossRef]
- Gueymard, C.A. Direct solar transmittance and irradiance predictions with broadband models. Part I: Detailed theoretical performance assessment. Sol. Energy 2003, 74, 355–379. [Google Scholar] [CrossRef]
- Gueymard, C.A. Direct solar transmittance and irradiance predictions with broadband models. Part II: Validation with high-quality measurements. Sol. Energy 2003, 74, 381–395. [Google Scholar] [CrossRef]
- Yang, K.; Huang, G.; Tamai, N. A hybrid model for estimating global solar radiation. Sol. Energy 2001, 70, 13–22. [Google Scholar] [CrossRef]
- Yang, K.; Koike, T.; Ye, B. Improving estimation of hourly, daily, and monthly solar radiation by importing global data sets. Agric. For. Meteorol. 2006, 137, 43–55. [Google Scholar] [CrossRef]
- Qin, J.; Tang, W.; Yang, K.; Lu, N.; Niu, X.; Liang, S. An efficient physically based parameterization to derive surface solar irradiance based on satellite atmospheric products. J. Geophys. Res. Atmos. 2015, 120, 4975–4988. [Google Scholar] [CrossRef]
- Sun, Z.; Liu, J.; Zeng, X.; Liang, H. Parameterization of instantaneous global horizontal irradiance: Cloudy-sky component. J. Geophys. Res.-Atmos. 2012, 117, D1402. [Google Scholar] [CrossRef] [Green Version]
- Sun, Z.; Liu, A. Fast scheme for estimation of instantaneous direct solar irradiance at the Earth’s surface. Sol. Energy 2013, 98, 125–137. [Google Scholar] [CrossRef]
- Tang, W.; Yang, K.; Sun, Z.; Qin, J.; Niu, X. Global Performance of a Fast Parameterization Scheme for Estimating Surface Solar Radiation from MODIS Data. IEEE Trans. Geosci. Remote 2017, 55, 3558–3571. [Google Scholar] [CrossRef]
- Qin, W.; Wang, L.; Zhang, M.; Niu, Z.; Hu, B. First Effort at Constructing a High-Density Photosynthetically Active Radiation Dataset during 1961–2014 in China. J. Clim. 2019, 32, 2761–2780. [Google Scholar] [CrossRef]
- Guermoui, M.; Melgani, F.; Danilo, C. Multi-step ahead forecasting of daily global and direct solar radiation: A review and case study of Ghardaia region. J. Clean. Prod. 2018, 201, 716–734. [Google Scholar] [CrossRef]
- Kaba, K.; Sarıgül, M.; Avcı, M.; Kandırmaz, H.M. Estimation of daily global solar radiation using deep learning model. Energy 2018, 162, 126–135. [Google Scholar] [CrossRef]
- Sun, Y.; Szucs, G.; Brandt, A.R. Solar PV output prediction from video streams using convolutional neural networks. Energy Environ. Sci. 2018, 11, 1811–1818. [Google Scholar] [CrossRef]
- Vakili, M.; Sabbagh-Yazdi, S.R.; Khosrojerdi, S.; Kalhor, K. Evaluating the effect of particulate matter pollution on estimation of daily global solar radiation using artificial neural network modeling based on meteorological data. J. Clean. Prod. 2017, 141, 1275–1285. [Google Scholar] [CrossRef]
- Yadav, A.K.; Chandel, S.S. Solar energy potential assessment of western Himalayan Indian state of Himachal Pradesh using J48 algorithm of WEKA in ANN based prediction model. Renew. Energy 2015, 75, 675–693. [Google Scholar] [CrossRef]
- Heng, J.; Wang, J.; Xiao, L.; Lu, H. Research and application of a combined model based on frequent pattern growth algorithm and multi-objective optimization for solar radiation forecasting. Appl. Energy 2017, 208, 845–866. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Mostafavi, E.S.; Jiao, P. Next generation prediction model for daily solar radiation on horizontal surface using a hybrid neural network and simulated annealing method. Energy Convers. Manag. 2017, 153, 671–682. [Google Scholar] [CrossRef]
- Deo, R.C.; Wen, X.H.; Qi, F. A wavelet-coupled support vector machine model for forecasting global incident solar radiation using limited meteorological dataset. Appl. Energy 2016, 168, 568–593. [Google Scholar] [CrossRef]
- Wang, L.; Hu, B.; Kisi, O.; Zounemat-Kermani, M.; Gong, W. Prediction of diffuse photosynthetically active radiation using different soft computing techniques. Q. J. R. Meteorol. Soc. 2017, 143, 2235–2244. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Reynolds, J.; Rezgui, Y. Predictive modelling for solar thermal energy systems: A comparison of support vector regression, random forest, extra trees and regression trees. J. Clean. Prod. 2018, 203, 810–821. [Google Scholar] [CrossRef]
- Fan, J.; Wu, L.; Zhang, F.; Cai, H.; Ma, X.; Bai, H. Evaluation and development of empirical models for estimating daily and monthly mean daily diffuse horizontal solar radiation for different climatic regions of China. Renew. Sustain. Energy Rev. 2019, 105, 168–186. [Google Scholar] [CrossRef]
- Fan, J.; Wu, L.; Zhang, F.; Cai, H.; Zeng, W.; Wang, X.; Zou, H. Empirical and machine learning models for predicting daily global solar radiation from sunshine duration: A review and case study in China. Renew. Sustain. Energy Rev. 2019, 100, 186–212. [Google Scholar] [CrossRef]
- Yagli, G.M.; Yang, D.; Srinivasan, D. Automatic hourly solar forecasting using machine learning models. Renew. Sustain. Energy Rev. 2019, 105, 487–498. [Google Scholar] [CrossRef]
- Voyant, C.; Motte, F.; Notton, G.; Fouilloy, A.; Nivet, M.L.; Duchaud, J.L. Prediction intervals for global solar irradiation forecasting using regression trees methods. Renew. Energy 2018, 126, 332–340. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Zhang, X.; Liang, S.; Yao, Y.; Jia, K.; Jia, A. Estimating Surface Downward Shortwave Radiation over China Based on the Gradient Boosting Decision Tree Method. Remote Sens. 2018, 10, 185. [Google Scholar] [CrossRef] [Green Version]
- Jumin, E.; Basaruddin, F.B.; Yusoff, Y.; Latif, S.D.; Ahmed, A.N. Solar radiation prediction using boosted decision tree regression model: A case study in Malaysia. Environ. Sci. Pollut. Res. 2021, 28, 26571–26583. [Google Scholar] [CrossRef]
- Wu, L.; Huang, G.; Fan, J.; Zhang, F.; Wang, X.; Zeng, W. Potential of kernel-based nonlinear extension of Arps decline model and gradient boosting with categorical features support for predicting daily global solar radiation in humid regions. Energy Convers. Manag. 2019, 183, 280–295. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference, San Francisco, CA, USA, 13–17 April 2016; Association for Computing Machinery: New York, NY, USA, 2016. [Google Scholar]
- Zhou, Z.; Zhao, L.; Lin, A.; Qin, W.; Lu, Y.; Li, J.; Zhong, Y.; He, L. Exploring the potential of deep factorization machine and various gradient boosting models in modeling daily reference evapotranspiration in China. Arab. J. Geosci. 2020, 13, 1287. [Google Scholar] [CrossRef]
- Fan, J.; Yue, W.; Wu, L.; Zhang, F.; Cai, H.; Wang, X.; Lu, X.; Xiang, Y. Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China. Agric. For. Meteorol. 2018, 263, 225–241. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Cao, Y.; Gui, L. Multi-Step wind power forecasting model Using LSTM networks, Similar Time Series and LightGBM. In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Wang, K. Measurement Biases Explain Discrepancies between the Observed and Simulated Decadal Variability of Surface Incident Solar Radiation. Sci. Rep. 2014, 4, 6144. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Ma, Q.; Li, Z.; Wang, J. Decadal variability of surface incident solar radiation over China: Observations, satellite retrievals, and reanalyses. J. Geophys. Res. Atmos. 2015, 120, 6500–6514. [Google Scholar] [CrossRef]
- Shi, G.Y.; Hayasaka, T.; Ohmura, A.; Chen, Z.; Wang, B.; Zhao, J.; Che, H.; Xu, L. Data Quality Assessment and the Long-Term Trend of Ground Solar Radiation in China. J. Appl. Meteorol. Clim. 2008, 47, 1006–1016. [Google Scholar] [CrossRef]
- Vamvakas, L.; Salamalikis, V.; Kazantzidis, A. Evaluation of enhancement events of global horizontal irradiance due to clouds at Patras, South-West Greece. Renew. Energy 2020, 151, 764–771. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees (CART). Biometrics 1984, 40, 358. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests—Random Features. Mach. Learn. 1999, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Huang, G.; Wu, L.; Ma, X.; Zhang, W.; Fan, J.; Yu, X.; Zeng, W.; Zhou, H. Evaluation of CatBoost method for prediction of reference evapotranspiration in humid regions. J. Hydrol. 2019, 574, 1029–1041. [Google Scholar] [CrossRef]
- Khelifi, R.; Guermoui, M.; Rabehi, A.; Lalmi, D. Multi-step-ahead forecasting of daily solar radiation components in the Saharan climate. Int. J. Ambient Energy 2020, 41, 707–715. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Quej, V.H.; Almorox, J.; Arnaldo, J.A.; Saito, L. ANFIS, SVM and ANN soft-computing techniques to estimate daily global solar radiation in a warm sub-humid environment. J. Atmos. Sol. Terr. Phys. 2017, 155, 62–70. [Google Scholar] [CrossRef] [Green Version]
- Despotovic, M.; Nedic, V.; Despotovic, D.; Cvetanovic, S. Review and statistical analysis of different global solar radiation sunshine models. Renew. Sustain. Energy Rev. 2015, 52, 1869–1880. [Google Scholar] [CrossRef]
- Almorox, J.; Hontoria, C.; Benito, M. Models for obtaining daily global solar radiation with measured air temperature data in Madrid (Spain). Appl. Energy 2011, 88, 1703–1709. [Google Scholar] [CrossRef]
- Hassan, M.A.; Khalil, A.; Kaseb, S.; Kassem, M.A. Exploring the potential of tree-based ensemble methods in solar radiation modeling. Appl. Energy 2017, 203, 897–916. [Google Scholar] [CrossRef]
- Wang, L.; Kisi, O.; Zounemat-Kermani, M.; Hu, B.; Gong, W. Modeling and comparison of hourly photosynthetically active radiation in different ecosystems. Renew. Sustain. Energy Rev. 2016, 56, 436–453. [Google Scholar] [CrossRef]
- Zou, L.; Wang, L.; Xia, L.; Lin, A.; Hu, B.; Zhu, H. Prediction and comparison of solar radiation using improved empirical models and Adaptive Neuro-Fuzzy Inference Systems. Renew. Energy 2017, 106, 343–353. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station Code | Station Name | Latitude (N) | Longitude (E) | Altitude (m) | SD (h) | Tmax (°C) | Tmin (°C) | Hr (%) | Pre (mm) yr−1) | Prs (hpa) | U10 (ms−1) | Data Omission | Climatic Zone |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 59948 | Sanya | 18.23 | 109.52 | 5.5 | 6.03 | 28.66 | 22.94 | 80.64 | 1580.57 | 996.04 | 2.85 | 0.11% | A, IIE |
| 59287 | Guangzhou | 23.17 | 113.33 | 6.6 | 4.24 | 26.91 | 19.34 | 75.33 | 1944.72 | 1009.95 | 1.78 | 0.12% | A, VI |
| 56778 | Kunming | 25.02 | 102.68 | 1891.4 | 6.02 | 21.8 | 11.81 | 68.7 | 989.11 | 812.66 | 2.09 | 1.61% | A, V |
| 57494 | Wuhan | 30.62 | 114.13 | 23.3 | 4.94 | 21.99 | 14.12 | 74.88 | 1286.63 | 1015.25 | 1.43 | 0.42% | A, IV |
| 58362 | Shanghai | 31.40 | 121.48 | 3.5 | 4.76 | 20.82 | 14.3 | 72.89 | 1189.9 | 1018.12 | 3.03 | 0.26% | A, IV |
| 56294 | Chengdu | 30.67 | 104.02 | 506.1 | 4.76 | 20.83 | 14.31 | 72.91 | 1193.55 | 1018.12 | 3.03 | 0.07% | A, V |
| 57083 | Zhengzhou | 34.72 | 113.65 | 110.4 | 5.14 | 20.78 | 10.84 | 61.57 | 639.12 | 1006 | 2.15 | 0.05% | B, III |
| 54511 | Beijing | 39.80 | 116.47 | 54 | 6.74 | 18.58 | 8.49 | 53.39 | 517.21 | 1014.95 | 2.32 | 0.07% | B, III |
| 50953 | Haerbin | 45.75 | 126.77 | 142.3 | 6.26 | 10.67 | 0.18 | 64.04 | 521.51 | 1000.02 | 2.57 | 0.05% | A, II |
| 54342 | Shenyang | 41.73 | 123.45 | 42.8 | 6.55 | 14.43 | 3.2 | 63.74 | 678.75 | 1013.03 | 2.64 | 0.7% | A, II |
| 52267 | Ejinaqi | 41.95 | 101.07 | 940.5 | 9.08 | 17.71 | 3.33 | 32.44 | 377.05 | 911.14 | 2.8 | 1.79% | D, II |
| 51463 | Wulumuqi | 43.78 | 87.65 | 917.9 | 7.29 | 13.2 | 3.7 | 56.71 | 316.46 | 914.78 | 2.34 | 0.73% | D, II |
| 51709 | Kashi | 39.47 | 75.98 | 1288.7 | 7.99 | 18.92 | 6.98 | 48.25 | 79.06 | 872.21 | 1.85 | 0.12% | D, III |
| 52889 | Lanzhou | 36.05 | 103.88 | 1517.2 | 7.64 | 14.69 | 3.51 | 56.07 | 365.73 | 813.81 | 2.07 | 0.19% | C, III |
| 55591 | Lasa | 29.67 | 91.13 | 3648.7 | 8.22 | 16.84 | 3.19 | 40.2 | 476.65 | 656.5 | 1.72 | 0.95% | C, HII |
| 52818 | Geermu | 36.42 | 94.90 | 2807.6 | 8.35 | 13.75 | 0.27 | 31.59 | 46.36 | 726.88 | 2.05 | 0.54% | D, HII |
| Specifications | Pyrheliometer | Pyranometer | ||
|---|---|---|---|---|
| 1957–1989 | 1990-Present | 1957–1989 | 1990-Present | |
| Instrument type | DFY1 | TBS2 or DFY3 | DFY2 | TBQ2 or DFY4 |
| Thermopile type | Solid black | Solid black | Black-white | Solid black |
| Thermopile coating | General-purpose lacquer | Optical lacquer | General-purpose lacquer | Optical lacquer |
| Dome | No | Quartz glass | General-purpose glass | Double quartz glass |
| Sampling frequency | First-class stations: hourly; Second-class stations: half-hourly | 60 (RYJ-2) or 360 (DRB-C) per hour | First-class stations: hourly; Second-class stations: half-hourly | 60 (RYJ-2) or 360 (DRB-C) per hour |
| Models | Input Combinations | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| XGBoost | CatBoost | LightGBM | CART | ET | RF | GBDT | MLP | SVM | ||
| XGBoost1 | CatBoost1 | LightGBM1 | CART1 | ET1 | RF1 | GBDT1 | MLP1 | SVM1 | Ra, n/N | C1 |
| XGBoost2 | CatBoost2 | LightGBM2 | CART2 | ET2 | RF2 | GBDT2 | MLP2 | SVM2 | Ra, n/N, Tmax, Tmin | C2 |
| XGBoost3 | CatBoost3 | LightGBM3 | CART3 | ET3 | RF3 | GBDT3 | MLP3 | SVM3 | Ra, n/N, Ho, U10 | C3 |
| XGBoost4 | CatBoost4 | LightGBM4 | CART4 | ET4 | RF4 | GBDT4 | MLP4 | SVM4 | Ra, n/N, Pre, Prs | C4 |
| XGBoost5 | CatBoost5 | LightGBM5 | CART5 | ET5 | RF5 | GBDT5 | MLP5 | SVM5 | Ra, n/N, Tmax, Tmin, Ho, U10 | C5 |
| XGBoost6 | CatBoost6 | LightGBM6 | CART6 | ET6 | RF6 | GBDT6 | MLP6 | SVM6 | Ra, n/N, Tmax, Tmin, Pre, Prs | C6 |
| XGBoost7 | CatBoost7 | LightGBM7 | CART7 | ET7 | RF7 | GBDT7 | MLP7 | SVM7 | Ra, n/N, Tmax, Tmin, Ho, U10, Pre, Prs | C7 |
| Cross Validation | Training Dataset | Testing Dataset |
|---|---|---|
| S1 | 1993–2010 | 2011–2016 |
| S2 | 1993–2004 and 2011–2016 | 2005–2010 |
| S3 | 1993–1998 and 2005–2016 | 1999–2004 |
| S4 | 1999–2016 | 1993–1998 |
| Model | The Selection and Used Range of Hyper-Parameters |
|---|---|
| CART | The maximum tree depth varied between 1 to 10 at 1 interval and the number of trees was 1 |
| ET | The maximum tree depth varied between 1 to 10 at 1 interval and the number of trees ranged from 10 to 100 at 10 intervals |
| RF | The number of trees ranged from 250 to 500 at 50 intervals and the maximum depth of tree ranged from 2 to 12 at 2 intervals |
| GBDT | The minimum leaf size varied between 2 to 12 at 2 intervals, and the number of rounds ranged from 1000 to 8000 at 1000 intervals |
| XGBoost | The eta was 0.01, the minimum leaf size varied from 2 to 10 at 2 intervals and the number of rounds ranged from 200 to 2000 at 200 intervals |
| LightGBM | The maximum tree depth varied between 2 to 12 at 2 intervals, and the number of trees varied between 100 to 600 at 100 intervals |
| CatBoost | The subset ratio of all datasets ranged from 0.5 to 1 at 0.05 intervals, the maximum tree depth varied between 2 and 10 at 2 intervals and the number of rounds varied from 200 to 800 at 100 intervals |
| MLP | The number of hidden neutrons ranged from 1 to 10 at 1 intervals |
| SVM | The penalty parameter cost ranged from 10 to 100 at 10 intervals, and the parameter gamma ranged from 10 to 120 at 10 intervals |
| Input/Model | Training | Testing | ||||||
|---|---|---|---|---|---|---|---|---|
| R2 | RMSE (MJm−2d−1) | MAE (MJm−2d−1) | MBE (MJm−2d−1) | R2 | RMSE (MJm−2d−1) | MAE (MJm−2d−1) | MBE (MJm−2d−1) | |
| Ra n/N (C1) | ||||||||
| XGBoost1 | 0.916 | 1.979 | 1.464 | 0.000 | 0.897 | 2.159 | 1.622 | −0.011 |
| Catboost1 | 0.913 | 2.015 | 1.488 | 0.000 | 0.898 | 2.144 | 1.606 | −0.013 |
| LightGBM1 | 0.924 | 1.876 | 1.390 | 0.000 | 0.893 | 2.195 | 1.646 | −0.011 |
| CART1 | 0.895 | 2.223 | 1.683 | 0.000 | 0.877 | 2.380 | 1.820 | −0.013 |
| ET1 | 0.894 | 2.233 | 1.692 | 0.000 | 0.884 | 2.306 | 1.768 | −0.013 |
| RF1 | 0.979 | 0.992 | 0.683 | 0.000 | 0.866 | 2.469 | 1.842 | −0.007 |
| GBDT1 | 0.916 | 1.971 | 1.460 | 0.000 | 0.897 | 2.161 | 1.623 | −0.012 |
| MLP1 | 0.901 | 2.153 | 1.608 | 0.004 | 0.892 | 2.213 | 1.673 | −0.011 |
| SVM-RBF1 | 0.900 | 2.153 | 1.587 | −0.052 | 0.891 | 2.212 | 1.663 | −0.067 |
| Mean | 0.915 | 1.955 | 1.451 | −0.005 | 0.888 | 2.249 | 1.696 | −0.017 |
| Ra n/N Tmax Tmin (C2) | ||||||||
| XGBoost2 | 0.926 | 1.857 | 1.372 | 0.000 | 0.904 | 2.081 | 1.561 | 0.009 |
| Catboost2 | 0.929 | 1.824 | 1.345 | 0.000 | 0.907 | 2.044 | 1.526 | 0.014 |
| LightGBM2 | 0.946 | 1.594 | 1.184 | 0.000 | 0.904 | 2.085 | 1.556 | 0.013 |
| CART2 | 0.897 | 2.203 | 1.669 | 0.000 | 0.877 | 2.378 | 1.817 | −0.003 |
| ET2 | 0.896 | 2.214 | 1.686 | 0.000 | 0.885 | 2.291 | 1.762 | −0.012 |
| RF2 | 0.983 | 0.889 | 0.610 | 0.002 | 0.891 | 2.224 | 1.661 | 0.015 |
| GBDT2 | 0.927 | 1.850 | 1.368 | 0.000 | 0.904 | 2.080 | 1.560 | 0.009 |
| MLP2 | 0.909 | 2.073 | 1.537 | 0.014 | 0.900 | 2.135 | 1.604 | 0.013 |
| SVM-RBF2 | 0.907 | 2.090 | 1.530 | −0.069 | 0.897 | 2.156 | 1.612 | −0.070 |
| Mean | 0.924 | 1.844 | 1.367 | −0.006 | 0.896 | 2.164 | 1.629 | −0.001 |
| Ra n/N H0U10 (C3) | ||||||||
| XGBoost3 | 0.927 | 1.848 | 1.365 | 0.000 | 0.902 | 2.090 | 1.573 | 0.031 |
| Catboost3 | 0.926 | 1.851 | 1.364 | 0.000 | 0.902 | 2.077 | 1.560 | 0.039 |
| LightGBM3 | 0.944 | 1.615 | 1.201 | 0.000 | 0.899 | 2.123 | 1.590 | 0.030 |
| CART3 | 0.899 | 2.182 | 1.650 | 0.000 | 0.878 | 2.367 | 1.806 | 0.006 |
| ET3 | 0.898 | 2.186 | 1.658 | 0.000 | 0.887 | 2.266 | 1.739 | −0.006 |
| RF3 | 0.983 | 0.894 | 0.617 | −0.001 | 0.885 | 2.275 | 1.705 | 0.026 |
| GBDT3 | 0.927 | 1.842 | 1.362 | 0.000 | 0.902 | 2.091 | 1.574 | 0.031 |
| MLP3 | 0.909 | 2.063 | 1.534 | 0.013 | 0.898 | 2.149 | 1.627 | 0.032 |
| SVM-RBF | 0.908 | 2.072 | 1.526 | −0.051 | 0.896 | 2.153 | 1.623 | −0.032 |
| Mean | 0.925 | 1.839 | 1.364 | −0.004 | 0.894 | 2.177 | 1.644 | 0.018 |
| Ra n/N Pre Prs (C4) | ||||||||
| XGBoost4 | 0.928 | 1.836 | 1.362 | 0.000 | 0.905 | 2.056 | 1.548 | 0.019 |
| Catboost4 | 0.927 | 1.842 | 1.364 | 0.000 | 0.906 | 2.040 | 1.532 | 0.023 |
| LightGBM4 | 0.944 | 1.620 | 1.212 | 0.000 | 0.902 | 2.089 | 1.567 | 0.020 |
| CART4 | 0.901 | 2.158 | 1.632 | 0.000 | 0.881 | 2.335 | 1.783 | 0.001 |
| ET4 | 0.897 | 2.206 | 1.676 | 0.000 | 0.886 | 2.284 | 1.752 | −0.003 |
| RF4 | 0.983 | 0.892 | 0.618 | 0.000 | 0.889 | 2.240 | 1.684 | 0.019 |
| GBDT4 | 0.928 | 1.829 | 1.359 | 0.000 | 0.905 | 2.058 | 1.550 | 0.019 |
| MLP4 | 0.908 | 2.075 | 1.549 | −0.008 | 0.896 | 2.159 | 1.634 | 0.009 |
| SVM-RBF4 | 0.905 | 2.098 | 1.548 | −0.058 | 0.894 | 2.174 | 1.638 | −0.040 |
| Mean | 0.925 | 1.840 | 1.369 | −0.007 | 0.896 | 2.159 | 1.632 | 0.007 |
| Ra n/N Tmax Tmin H0U10 (C5) | ||||||||
| XGBoost5 | 0.933 | 1.772 | 1.310 | 0.000 | 0.907 | 2.033 | 1.528 | 0.033 |
| Catboost5 | 0.937 | 1.723 | 1.270 | 0.000 | 0.911 | 1.996 | 1.496 | 0.046 |
| LightGBM5 | 0.955 | 1.449 | 1.081 | 0.000 | 0.909 | 2.021 | 1.510 | 0.030 |
| CART5 | 0.900 | 2.181 | 1.652 | 0.000 | 0.877 | 2.377 | 1.814 | 0.010 |
| ET5 | 0.900 | 2.175 | 1.656 | 0.000 | 0.887 | 2.266 | 1.743 | −0.002 |
| RF5 | 0.985 | 0.846 | 0.582 | 0.001 | 0.897 | 2.152 | 1.612 | 0.035 |
| GBDT5 | 0.933 | 1.767 | 1.307 | 0.000 | 0.907 | 2.034 | 1.528 | 0.032 |
| MLP5 | 0.915 | 1.992 | 1.472 | −0.005 | 0.903 | 2.086 | 1.570 | 0.020 |
| SVM-RBF5 | 0.910 | 2.050 | 1.503 | −0.068 | 0.900 | 2.125 | 1.595 | −0.049 |
| Mean | 0.930 | 1.773 | 1.315 | −0.008 | 0.900 | 2.121 | 1.600 | 0.017 |
| Ra n/N Tmax Tmin Pre Prs (C6) | ||||||||
| XGBoost6 | 0.934 | 1.755 | 1.301 | 0.000 | 0.911 | 1.996 | 1.503 | 0.025 |
| Catboost6 | 0.937 | 1.714 | 1.269 | 0.000 | 0.914 | 1.958 | 1.468 | 0.033 |
| LightGBM6 | 0.955 | 1.451 | 1.086 | 0.000 | 0.912 | 1.992 | 1.492 | 0.028 |
| CART6 | 0.901 | 2.159 | 1.635 | 0.000 | 0.880 | 2.346 | 1.792 | 0.006 |
| ET6 | 0.897 | 2.202 | 1.680 | 0.000 | 0.886 | 2.286 | 1.761 | −0.005 |
| RF6 | 0.985 | 0.840 | 0.580 | 0.001 | 0.900 | 2.123 | 1.593 | 0.026 |
| GBDT6 | 0.935 | 1.748 | 1.299 | 0.000 | 0.911 | 1.997 | 1.504 | 0.024 |
| MLP6 | 0.914 | 2.005 | 1.488 | 0.002 | 0.904 | 2.089 | 1.572 | 0.022 |
| SVM-RBF6 | 0.909 | 2.069 | 1.522 | −0.069 | 0.898 | 2.145 | 1.611 | −0.049 |
| Mean | 0.930 | 1.771 | 1.318 | −0.007 | 0.902 | 2.104 | 1.589 | 0.012 |
| Ra n/N Tmax Tmin H0U10Pre Prs (C7) | ||||||||
| XGBoost7 | 0.937 | 1.720 | 1.275 | 0.000 | 0.912 | 1.986 | 1.495 | 0.031 |
| Catboost7 | 0.941 | 1.664 | 1.230 | 0.000 | 0.916 | 1.943 | 1.457 | 0.041 |
| LightGBM7 | 0.960 | 1.370 | 1.027 | 0.000 | 0.914 | 1.967 | 1.472 | 0.030 |
| CART7 | 0.901 | 2.160 | 1.637 | 0.000 | 0.879 | 2.354 | 1.798 | 0.005 |
| ET7 | 0.899 | 2.182 | 1.663 | 0.000 | 0.887 | 2.273 | 1.749 | 0.003 |
| RF7 | 0.986 | 0.824 | 0.569 | 0.001 | 0.902 | 2.103 | 1.578 | 0.031 |
| GBDT7 | 0.937 | 1.715 | 1.273 | 0.000 | 0.912 | 1.987 | 1.496 | 0.029 |
| MLP7 | 0.917 | 1.974 | 1.463 | −0.008 | 0.906 | 2.063 | 1.552 | 0.018 |
| SVM-RBF7 | 0.910 | 2.058 | 1.517 | −0.066 | 0.899 | 2.141 | 1.614 | −0.040 |
| Mean | 0.932 | 1.741 | 1.295 | −0.008 | 0.903 | 2.091 | 1.579 | 0.016 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Lin, A.; He, L.; Wang, L. Evaluation of Various Tree-Based Ensemble Models for Estimating Solar Energy Resource Potential in Different Climatic Zones of China. Energies 2022, 15, 3463. https://doi.org/10.3390/en15093463
Zhou Z, Lin A, He L, Wang L. Evaluation of Various Tree-Based Ensemble Models for Estimating Solar Energy Resource Potential in Different Climatic Zones of China. Energies. 2022; 15(9):3463. https://doi.org/10.3390/en15093463
Chicago/Turabian StyleZhou, Zhigao, Aiwen Lin, Lijie He, and Lunche Wang. 2022. "Evaluation of Various Tree-Based Ensemble Models for Estimating Solar Energy Resource Potential in Different Climatic Zones of China" Energies 15, no. 9: 3463. https://doi.org/10.3390/en15093463