1. Introduction
Methane is a common byproduct of the mining industry [
1]. It remains trapped inside coal seams and is gradually released during mining. Methane leakage from the working face can lead to asphyxiation, fire, coal and gas outbursts, and other accidents [
2]. In the first half of 2021, there were several accidents caused by high methane concentrations [
3] in various mines across China. These accidents led to severe injuries, high casualty rates, and considerable economic loss. Therefore, it is necessary to predict the methane concentration in mines efficiently and robustly, to prevent the occurrence of such accidents.
During mining, significant amounts of methane and other gases are released into the air from the working face [
4,
5]. Generally, numerous transducers are inserted in the working face of the mine to monitor various types of data, as shown in
Figure 1, such as the methane concentration, temperature, wind speed, etc., in real time [
6]. These sensor values are stored as time-series data that reflect the real-time situation of the mine. Analyzing this data can help prevent methane-related accidents.
Several researchers have studied the problem of methane release from working faces. Gao [
7] used a combination of information fusion and chaotic time series analysis to predict gas emissions in tunnels. Zhang [
8] developed a prediction model for coal-mine gas concentration using a time series and an adaptive neuro-fuzzy inference system (ANFIS). Fu [
9] proposed a dynamic fuzzy neural network (IGA-DFNN) method optimized with an immunogenetic algorithm to accurately predict the gas concentration in coal seams. Karacan [
10] proposed principal component analysis (PCA) and an artificial neural network (ANN)-based approach to predict the methane ventilation emission rates from US longwall mines. Yang [
11] constructed a multivariate time series prediction model based on massive coal-mine gas monitoring data and a multivariate distribution lag model. Yang [
12] developed a hybrid prediction model incorporating the wavelet transform and an extreme learning machine (ELM), Their proposed method is referred to as wavelet-based ELM (WELM) and is intended for predicting coal-mine gas concentrations. Zhang [
13] used a pattern recognition method to predict the sub-unit probability of coal seam protrusion hazards and classified the coal and gas outburst levels of coal seams into three zones—the danger zone, threat zone, and safety zone. Dong [
14] proposed a new coal and gas outburst prediction model based on the mechanism of the occurrence of coal and gas protrusions, related to coal strength, gas pressure, and in situ stress. Li [
15] proposed a novel model based on multi-source information fusion to predict sudden-onset coal and gas disasters. Li [
16] proposed a risk assessment of gas explosions based on fuzzy AHP and a Bayesian network.
Although these studies have resulted in significant advances and provided a reference for subsequent studies, the suggested methods have certain limitations. There are several aspects of methane concentration data that can influence the accuracy of methane prediction:
- (1)
The transducers at the working face do not collect data at even time intervals. Some transducers record data once every minute, whereas others record data ten times a second.
- (2)
The transducers need to be adjusted at regular intervals, and other human factors can also affect the acquisition of data, which can lead to sudden variations in the recorded data.
- (3)
Each transducer can record vast amounts of data over a few months, which can translate to millions of pieces of data for the entire working face.
Traditional statistical models, such as the autoregressive integrated moving average model (ARIMA) [
17], can be overwhelmed by the large volume of generated data and face problems related to the accuracy and robustness of the model and its generalization to different mines.
Deep learning is a relatively new technique that offers significant potential in addressing these problems. As deep learning is highly flexible, it allows the model to handle high-dimensional nonlinear problems without the need to ascertain the model parameters in advance. Consequently, deep learning models, such as recurrent neural network (RNN)-based models [
18], offer several advantages when addressing methane concentration prediction problems. Song [
19] constructed an RNN-based multi-parameter fusion prediction model for coal-seam gas concentration to improve the accuracy of gas concentration prediction. Lyu [
20] proposed a multi-step prediction method for a gas concentration time series based on the ARMA, CHAOS, and encoder–decoder models (single-sensor and multi-sensor). Zhang [
21] proposed a long short-term memory (LSTM) RNN prediction method, based on actual coal-mine production monitoring data, to effectively reduce the prediction error. Li [
22] predicted the hazard potential of coal and gas outbursts using neural networks and clustering algorithms. Jia [
23] proposed a gated recurrent unit (GRU)-based coal-mine gas concentration prediction model. The proposed model not only has a simple structure but also offers a high prediction accuracy and can make full use of the time series characteristics of coal-mine gas concentration data. In recent years, several deep learning-based models have been developed to analyze methane concentration data and the impact on mining safety as they are more sophisticated, can handle non-linear data, and can fit methane concentration trends.
Data play an increasingly important part in mining practice, with dozens of sensors in a single working face monitoring various features such as gas concentration, wind speed, temperature, carbon monoxide concentration, etc. Those data are stored as a time series; analysis of these data can uncover a variety of characteristics and achieve meaningful results, such as in [
24], where the simulation of gas contamination of groundwater in mining excavations allows us to address environmental issues such as the groundwater-quality impacts of oil and gas extraction [
25].
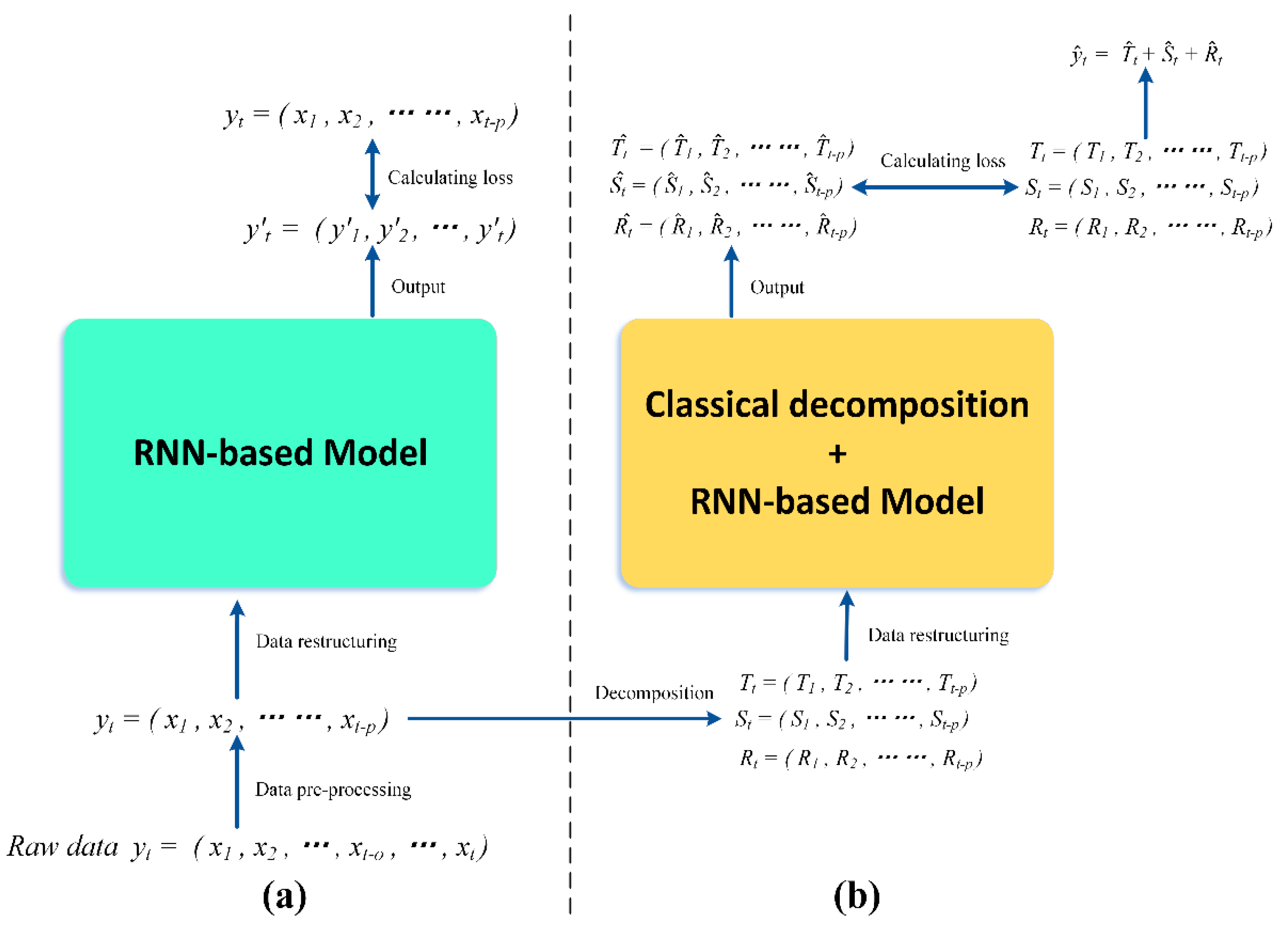
In this study, we combine deep learning with a traditional time series analysis method to train and evaluate multiple RNN-based models, namely, a classical RNN [
18], LSTM [
26], and GRU [
27]. The data used to train the models were obtained from real working face sensors and were recorded over nearly three months. The performance of the models was evaluated through various experiments. Furthermore, we propose a novel approach that combines statistical analysis methods with deep learning to improve the prediction accuracy of the models. The efficacy of our proposed approach was evaluated experimentally, which can help build emergency plans [
28] and reduce the probability of emergencies. By applying this research to a central server in an actual mine, we found that we could predict trends in methane concentration very well, which meant that we learned the inherent patterns of methane levels that can help us to identify potential gas accidents and improve mining safety.
2. Methods and Calculation
In this section, we describe the methods used herein, including those used to measure the performance of the models. Various forecasting and analysis methods, called time-series analyses [
29], are used to predict methane concentrations in other fields. The process of analyzing these data requires expertise and the data must be suitably adjusted to achieve the best results.
2.1. Classical Decomposition
Time series decomposition [
30] is a classical time series analysis method that has two models: the additive decomposition model and the multiplicative decomposition model, which decomposes a time series
into three components: the trend-cycle component, seasonal component, and remainder component [
31]. The additive decomposition model can be expressed as:
The multiplicative decomposition model can be expressed as:
As shown in Equation (3), the multiplicative model can be converted into an additive representation. The decomposition model provides an abstraction for analyzing the data and is suitable for prediction methods related to specific problems, such as methane concentration. The first step in the decomposition of time series data is to estimate the trend cycle using the moving averages method. A moving average of the order of
can be expressed as:
where
is the trend and
. That is, the estimate of the trend period in time
is obtained by averaging the time series values over
periods of time
. Thus, averaging removes some of the randomness from the data, leaving a smooth component of the trend cycle. This is referred to as
, which denotes a moving average of order
. For additive decomposition, the general time series decomposition steps are as follows. (1) Seeking
: If the total length of the time series is even,
(moving average) is used to calculate the trend; if the total length is odd,
is used to calculate the trend. (2) Determine the detrending series:
. (3) Seeking
:
. (4) Seeking
: The remainder can be obtained by subtracting the seasonal and trend components from the series
.
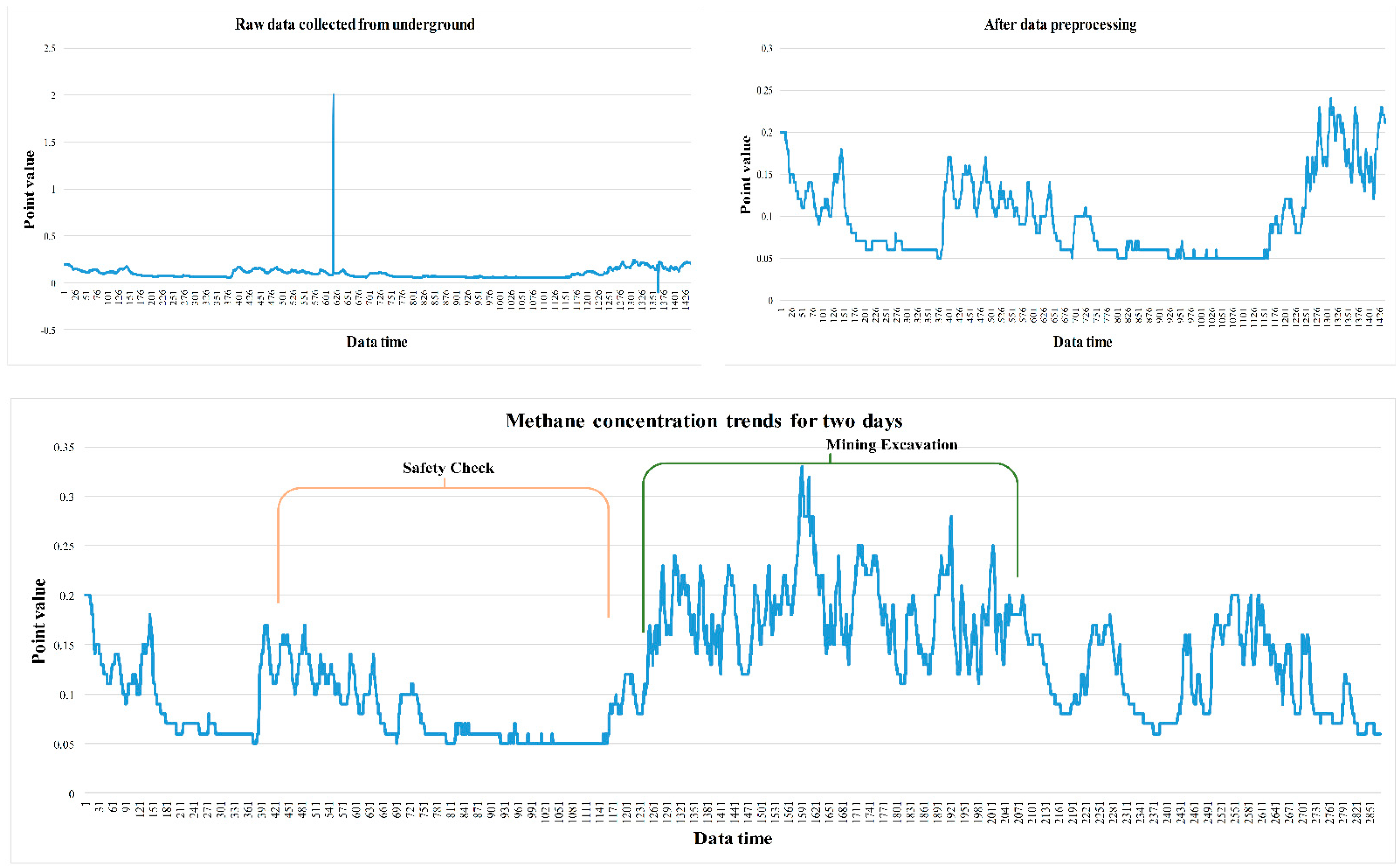
Multiplicative decomposition is similar to additive decomposition, except that addition and subtraction are replaced by multiplication and division. Classical decomposition is relatively easy and intuitive, but crucially, it provides unique and extremely useful a priori knowledge for building complex models such as deep neural networks and for dealing with non-linear data. This is particularly true for data that are clearly cyclical in nature, such as the methane released from the working face, which is characterized by a zig-zag increase during mining operations [
32] and a gradual decrease during stoppages for safety checks, as shown in
Figure 2.
The transducers in the working face must be calibrated regularly.
Figure 2 illustrates the changes in methane values on the day of the calibration. As shown, the values at calibration point 2 are significantly higher than those normally acquired by the transducer, which affects the data analysis process.
Figure 2 illustrates the methane concentration trend after data pre-processing and shows the methane concentration over two days. Mining activities are performed on a shift-work schedule, which includes regular stoppages in the work to perform various safety checks and remove any potential safety hazards. Consequently, methane levels gradually decrease during the safety checks and increase in a zig-zag manner when work restarts. The work schedule provided by the Qianyingzi coal mine confirms this trend.
Although some understanding of the general data trend is required to make forecasts using time series decomposition, there are obvious drawbacks to this approach: (1) estimates of the trend period for the first and last few observations are not available—that is, some values will inevitably be dropped to obtain a moving average; (2) estimates of trend cycles tend to smooth over sudden changes in the data; (3) the classical decomposition method assumes that the seasonal component repeats itself annually—although this is a reasonable assumption for several time-series data types, it does not apply to longer time-series data, such as the methane released from mines during the year (tens of billions of data points).
2.2. Deep Learning Models
Deep learning models have evolved rapidly in recent years and have achieved excellent results in many areas, such as computer vision (CV) [
33], natural language processing (NLP) [
34], and autopilot systems [
35]. Consequently, the application of deep learning methods to methane prediction has good potential.
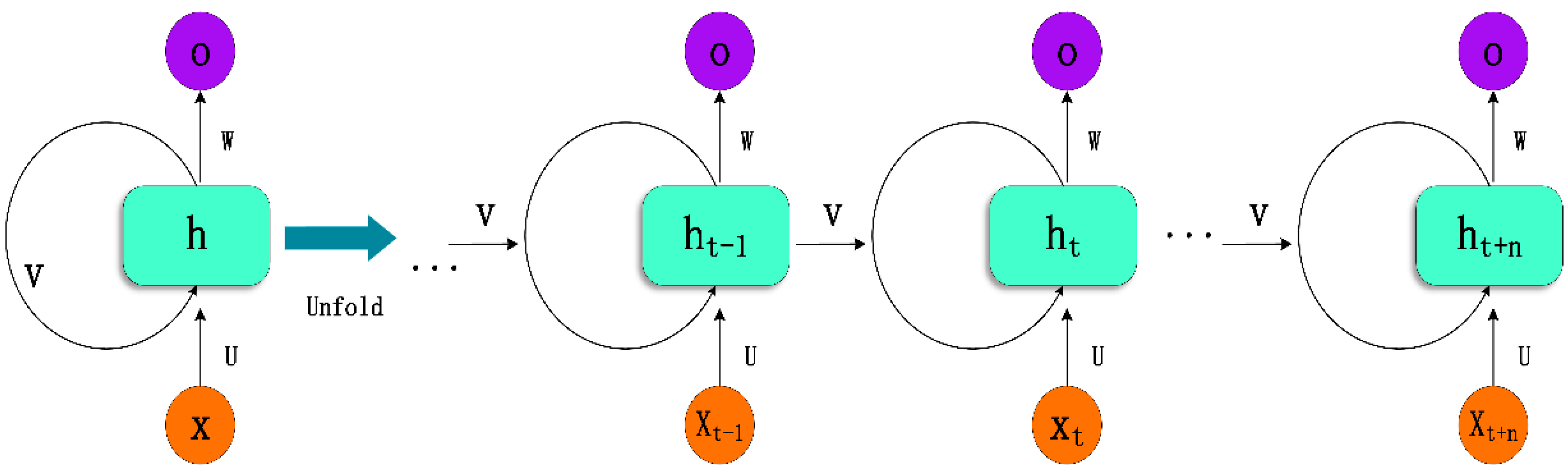
An RNN model, as shown in
Figure 3, is a cell-based neural network, wherein each cell comprises three parts: an input layer, a hidden layer, and an output layer. The result of the output layer is determined not only by the input
or the weights
but also by the previous input
and the previous weights. The output is controlled by an activation function and is connected by the weights between cells. The parameters are updated by a backpropagation through time algorithm for each calculation, which can be expressed as:
where
and
are the input and output,
is the hidden layer vector, and
,
, and
are the weights between the input and hidden layers. The advantages of an RNN are: 1) they are specifically designed to handle time-series data, as the weight of the previous time affects the subsequent time, and the data in the time series are correlated in time; 2) theoretically, RNNs can simulate infinite stacks through activation and weighting; 3) RNNs allow complex nonlinear relationships and high dimensionality between the response variables; 4) compared to traditional models, RNNs do not require parameters to be determined in advance as the parameters are calculated in the model itself through backpropagation [
36].
The short-term memory of a classical RNN is a double-edged sword, and the problems of vanishing [
37] and exploding gradients often occur during model training [
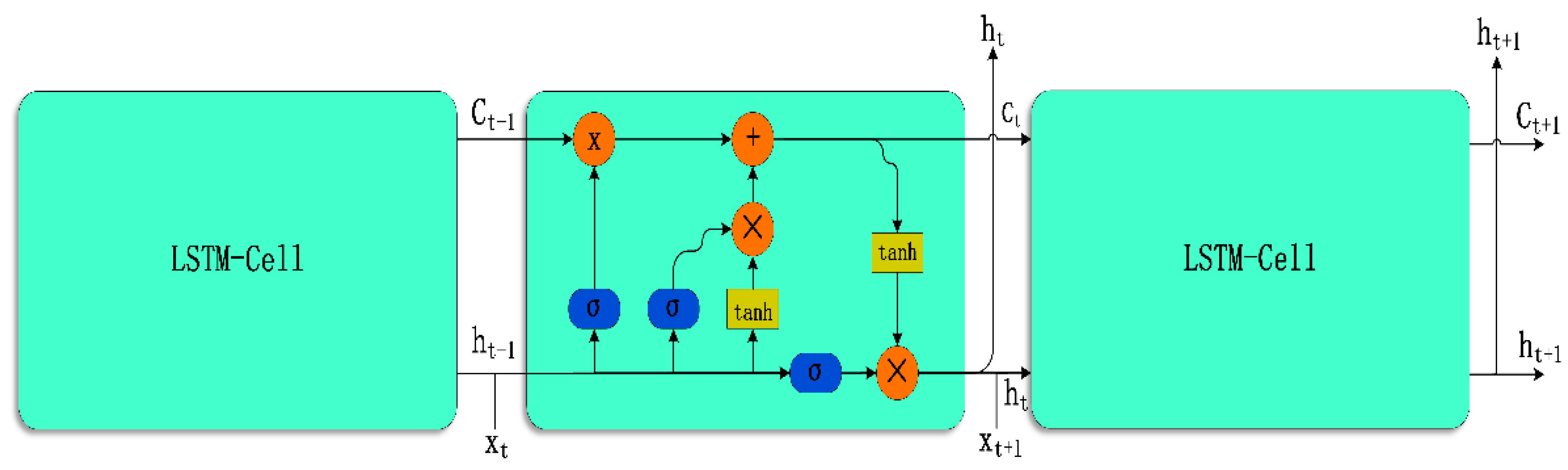
38]. Consequently, superior RNN models, such as the long short-term memory (LSTM) model, have been developed. LSTM is a special type of RNN that is primarily used to solve the problem of vanishing and exploding gradients while training long sequences. LSTM performs better in longer sequences compared to ordinary RNNs. The LSTM model can be expressed as:
where
,
, and
are the forget gate, input gate, and output gate, as shown in
Figure 4;
are the matrices for storing the weights in the training model;
is the input;
is the hidden state; and
and
denote the sigmoid and tan h functions, respectively. In the forget gate, the previous hidden state, which is a sigmoid function, enters the gate together with the current input. The closer the result is to 1, the greater its importance, and the closer it is to 0, the greater the need for it to be forgotten, thereby achieving the function of the forget gate. The LSTM parameters can be updated as:
The most important function of these gates is to learn what is important and what is not important and needs to be dropped at a given moment in the time-series data. An unimportant input is never important, which is well suited to the prediction of methane concentration, as we wish to maximize the attention put on higher methane values such as 0.36 and 0.45, rather than on smaller values such as 0.01, 0.05, or even 0.
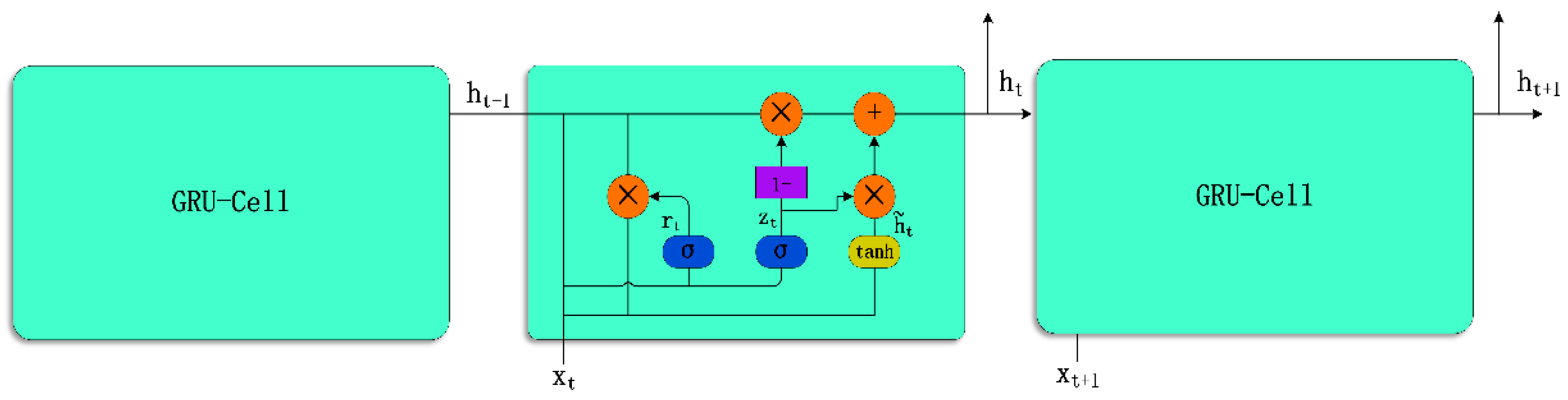
The GRU model is like an LSTM model with a forget gate, but has fewer parameters, such as the lack of an output gate, as shown in
Figure 5. GRU outperforms LSTM on certain repetitive tasks such as tone music modeling, speech signal modeling, and natural language processing. However, although the performance of GRU is better than that of LSTM, it is relatively more time-consuming. In general, GRU can be expressed as:
where
is the input vector,
is the update gate vector,
is the reset gate vector, and
and
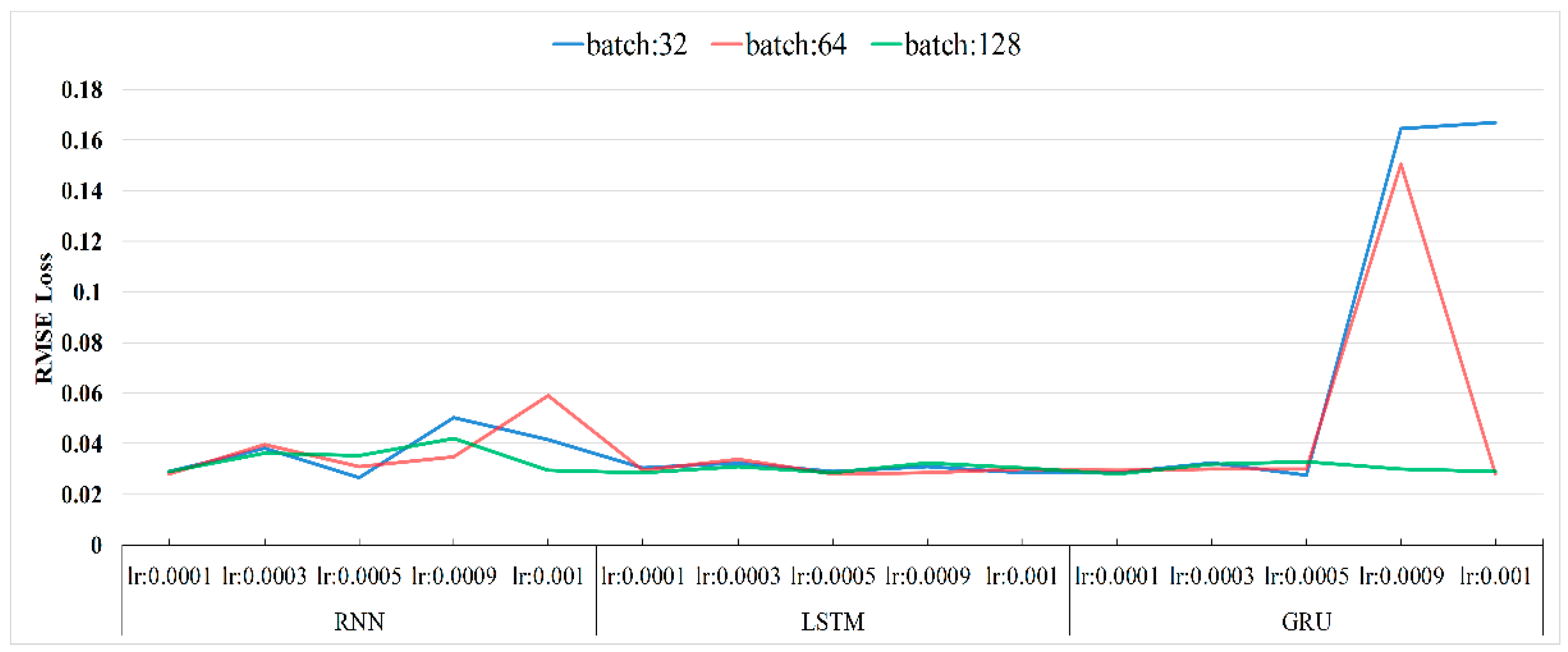
are the output and candidate activation vectors, respectively. In this study, we trained different RNN models using real-world methane data and measured their performance, considering loss, time complexity, and memory usage.
The developments in deep learning models have impacted various fields and have resulted in significant achievements. In coal mines, the significance of collecting and analyzing data from mines in real time is aided by information, pattern recognition, and trend prediction to ensure mine safety.
2.3. Loss Function and Optimization
The mean square error (
MSE) is used as a metric in this study to measure the accuracy of the values predicted by the deep learning models compared to the actual methane concentration.
MSE, which is also called the L2 loss function, optimizes the loss function for deep learning models by reducing its derivative to zero; it can also be used to evaluate the performance of the traditional model.
MSE can be expressed as:
MSE primarily calculates the error between the predicted value of the model and the true value. Another measure of the prediction accuracy is the root mean square error (
RMSE), which is expressed as:
The advantage of
RMSE is that the calculated loss can be normalized to the predicted value, allowing a more intuitive view of the performance of the model. The correlation between the predicted and true values of methane can be measured using the coefficient of determination:
where
is the true value, and
and
are the predicted value and the average of the true values, respectively.
The adaptive moment estimation (Adam) [
39] is a deep learning model optimizer and represents an optimization of the stochastic gradient descent (SGD), which is widely used in computer vision and natural language processing. Combined with the momentum and root mean square propagation (RMSProp), Adam can be described as:
where
is the first-order momentum and
is the momentum factor. The concept of momentum is borrowed from physics; the true gradient is replaced by the previously accumulated momentum and
is the second-order momentum:
The updated parameters can be expressed as:
where
is a small value that prevents the gradient from being divided by zero. As an integrated optimization method, Adam offers many advantages: (1) simple and straightforward calculation; (2) efficiency; (3) reduced memory usage; (4) it is suitable for non-smooth targets; and (5) offers hyperparameters with intuitive interpretation. Therefore, it is well suited for optimizing the models used herein.
2.4. The Data
In this paper, the training data used to construct the deep learning models (RNN, LSTM, and GRU) were obtained from the methane sensors in the W3220 working face of the Qianyingzi coal mine in Suzhou, Anhui Province, China, and were recorded over nearly three months. The data were recorded from 1 May 2021 to 20 July 2021, with a total of 160,412 data points.
Our data comprise raw data extracted directly from the central server at the mine, which will then be deployed to the server to test the performance of the model once it has been trained.
4. Discussion
Methane concentration is an important consideration for ensuring the safety of coal mines as it has been known to cause hazardous accidents, such as coal and gas outbursts. Traditional methane-concentration prediction methods have encountered limitations in dealing with large data volumes and excessive dimensions. However, modern deep-learning approaches, such as RNN-based neural networks, can effectively solve these problems. Nonetheless, these advanced methods also face gradient and overfitting problems.
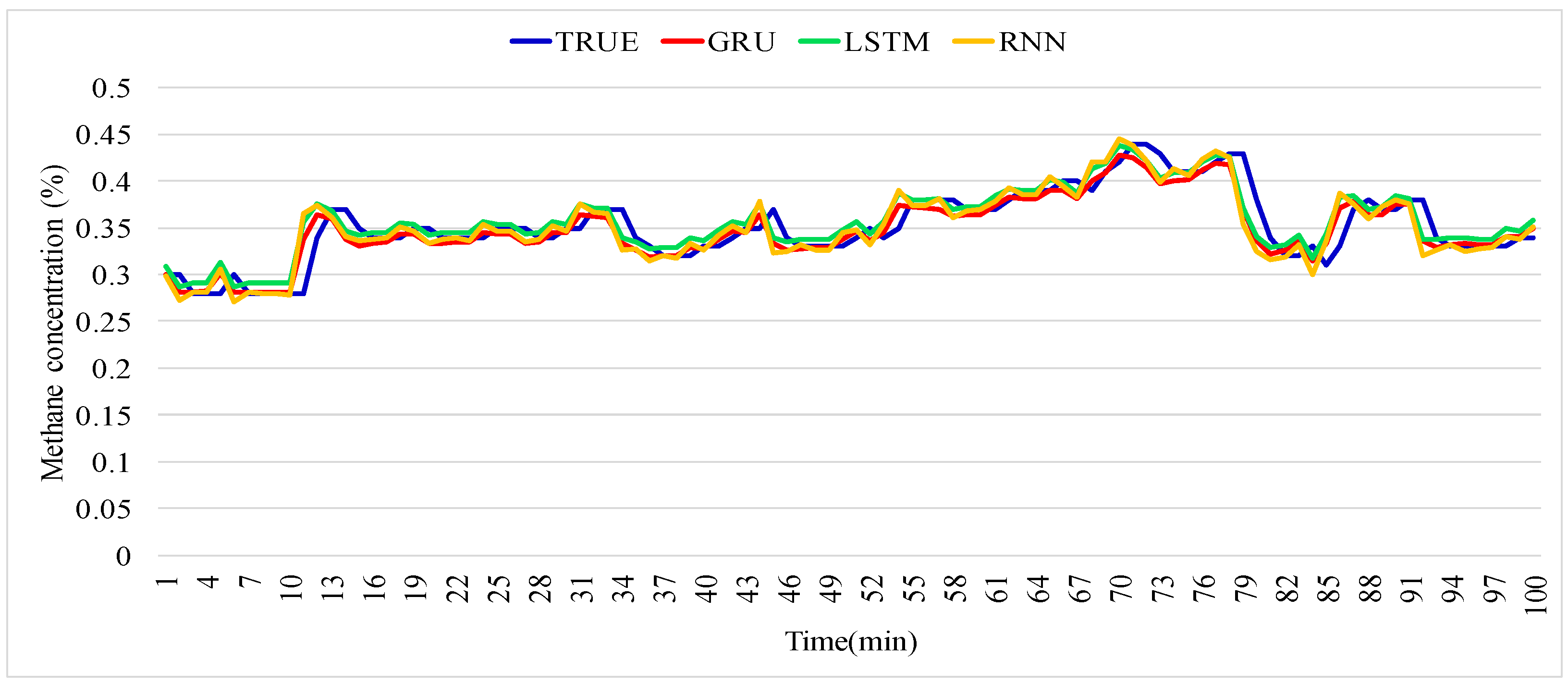
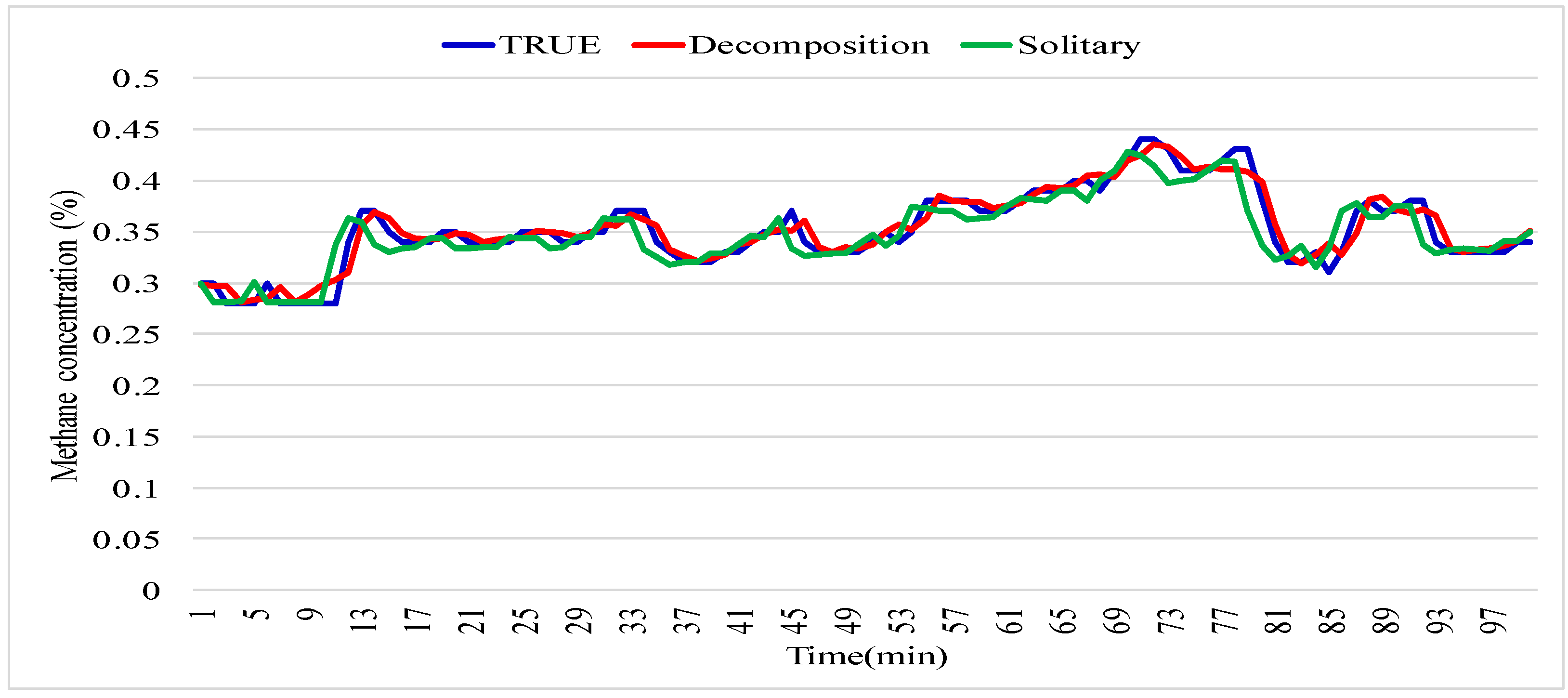
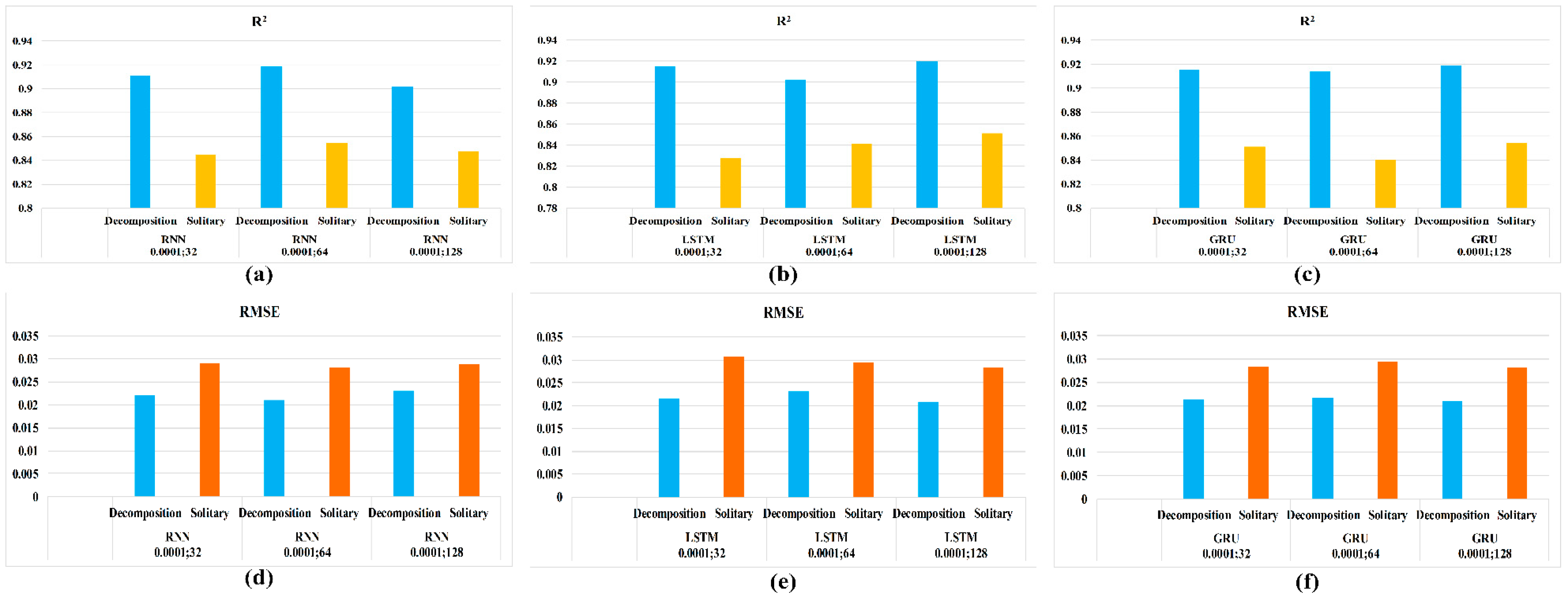
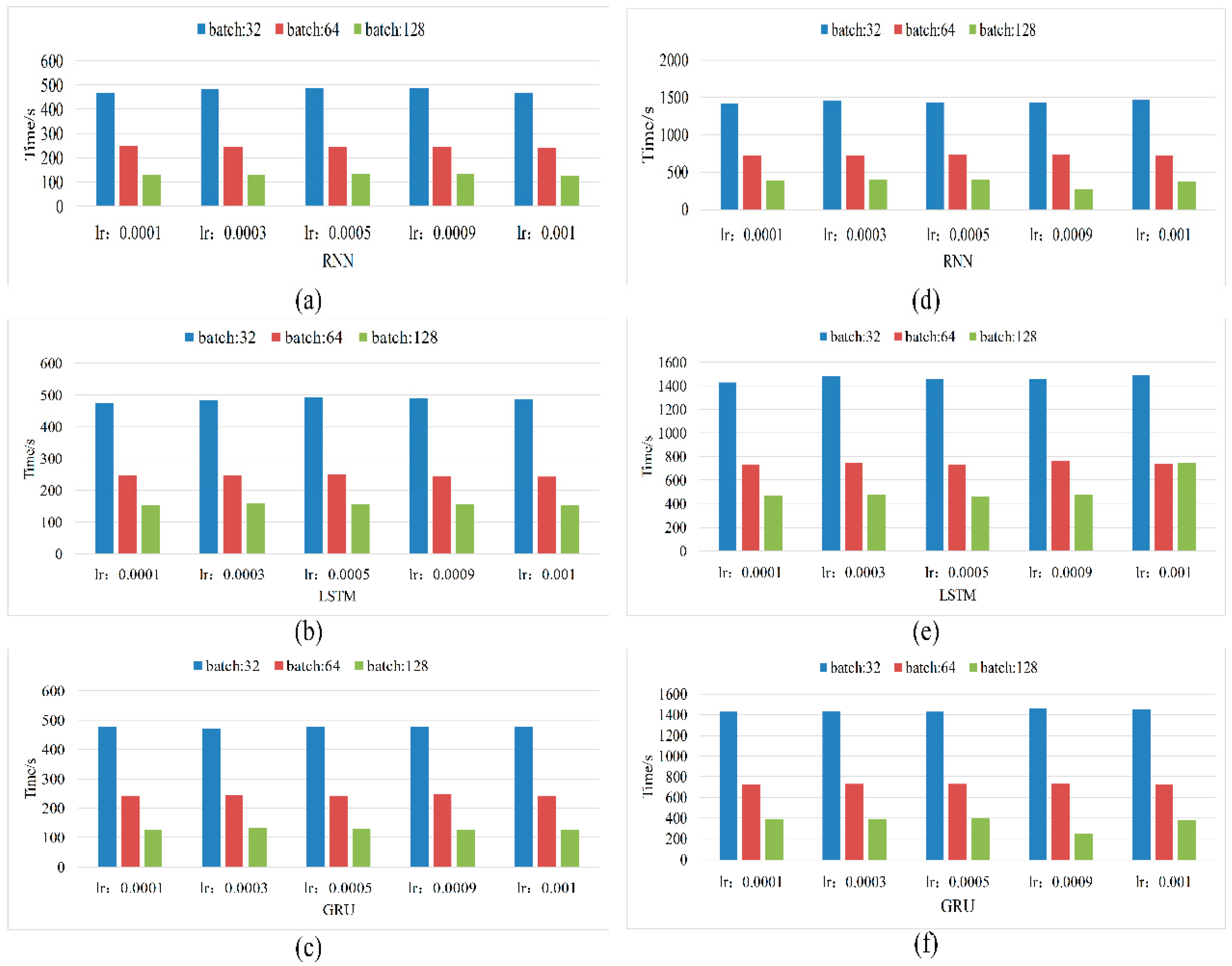
In this study, we employed three deep learning methods—RNN, LSTM, and GRU—to facilitate methane-concentration prediction and evaluated their efficacy. The experimental results obtained in this study reveal that the deep learning methods demonstrate great potential for use in applications related to ensuring mining safety. Moreover, it is observed that combining deep learning methods with classical time-series analysis approaches can further reduce the loss encountered by RNN-based models and improve the forecast accuracy. Unfortunately, this improvement in prediction accuracy is realized at the cost of an increased computational time because the combined approach takes approximately three times longer compared to pure RNN. However, the gas patterns in mine faces are never constant and change from one location to another as mining progresses. Therefore, gas-data sampling is limited to a few months rather than a few years, which reduces the computational burden. According to the Coal Mine Safety Regulations in China, the maximum methane concentration in the working face must not exceed 1%. This leads to an insignificant trend in methane concentration. Consequently, the application of deep-learning methods for ensuring the safety of coal-mining operations has become an important area of research in recent years. This means that we can systematically analyze the vast amount of underground data; learning the working patterns gives us the ability to recognize abnormal conditions, allowing us to detect and prevent catastrophic accidents in advance.
In future studies, we will analyze the correlation between transducers in the working face, such that even if one sensor fails, the methane concentration in the location of the failed sensor can be analyzed and predicted by the other transducers. This method can be used to analyze the change in methane concentration in mines where coal and gas outbursts have occurred. During coal and gas outburst accidents, the change in methane concentration differs from that recorded during normal operations. This change in methane concentration is either sudden or gradual but always occurs in a different pattern from that of the usual gas concentration, as demonstrated by the data obtained herein. Consequently, the deep learning methods proposed herein can provide an early warning of possible accidents, thereby improving mine safety and alleviating the loss of life.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










