
Ensemble Learning-Based Reactive Power Optimization for Distribution Networks

Abstract
:1. Introduction
- (1)
- A fully data-driven and scalable method is proposed for reactive power optimization of distribution networks without solving complex physical models. Additionally, the proposed approach is applied to different distribution networks by simply fine-tuning the structures and parameters.
- (2)
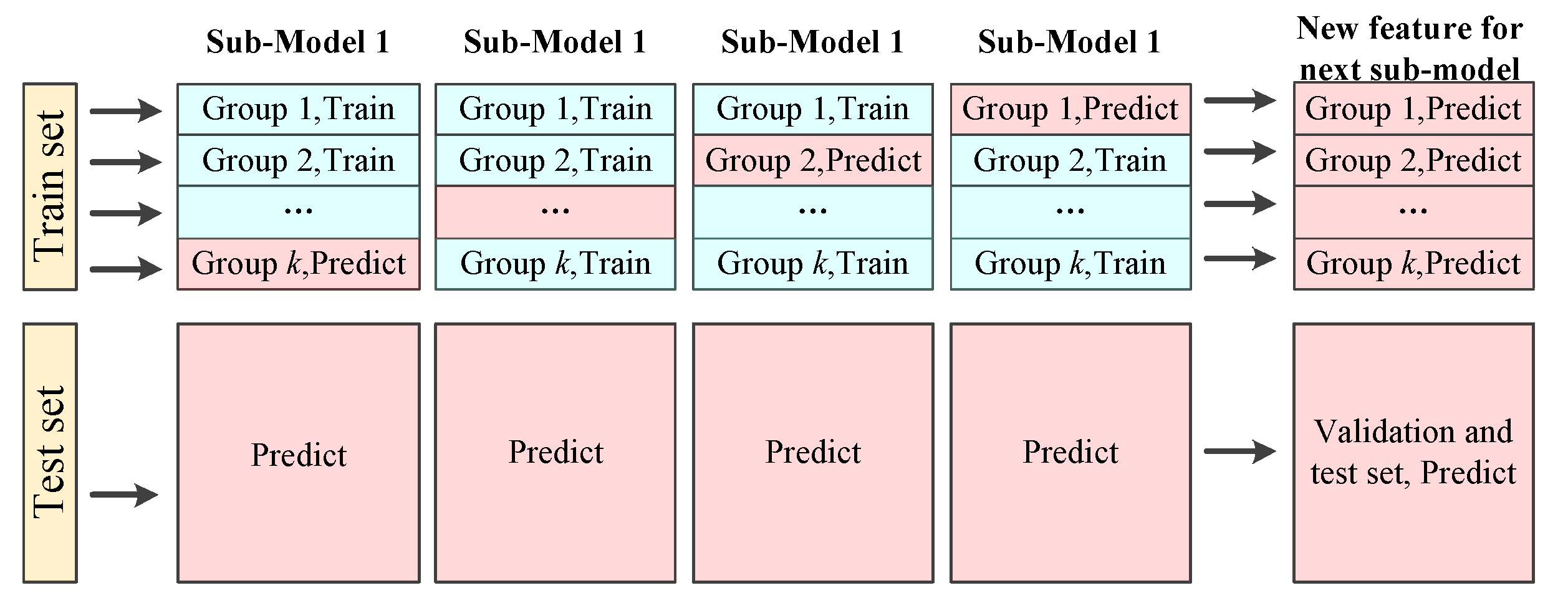
- Each method has its own advantages and disadvantages, while the proposed approach can learn widely from others’ strong points to improve the optimization accuracy. To improve the generalization of the ensemble model, k-fold cross-validation is employed to train the model.
- (3)
- Numerical experiments on the real-world dataset are performed to validate the effectiveness of the ensemble framework for reactive power optimization of distribution networks. The simulation results show that the proposed approach achieves state-of-art performance with superior accuracy. Further, the calculation time is much lower than the traditional heuristic methods, such as GA.
2. Reactive Power Optimization Model
- (1)
- Power flow constraints in distribution networkswhere is the phase difference of the voltage between node and node , is the conductance between node and node , and is the susceptance between node and node .
- (2)
- Current and voltage constraints in distribution networkswhere is the upper bound of voltage for node , is the lower bound of voltage for node , and is the upper bound of current for branch .
- (3)
- Equipment constraints in distribution networkswhere is the number of nodes with the shunt capacitor bank, is the number of nodes with OLTC, is the number of nodes with SVC, is the maximum reactive power generated by the shunt capacitor bank, is the minimum tap position of the OLTC, is the maximum tap position of the OLTC, and is the maximum reactive power generated by the SVC.
3. Methodology
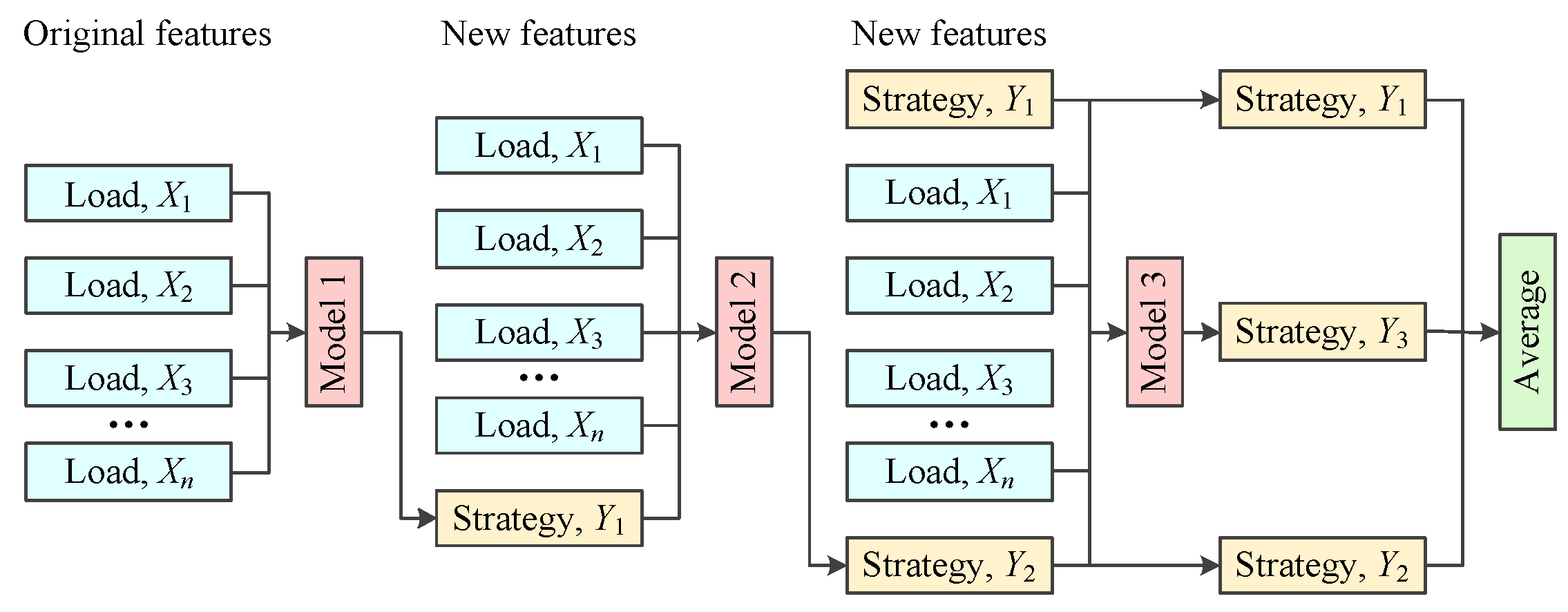
3.1. Framework of the Proposed Method
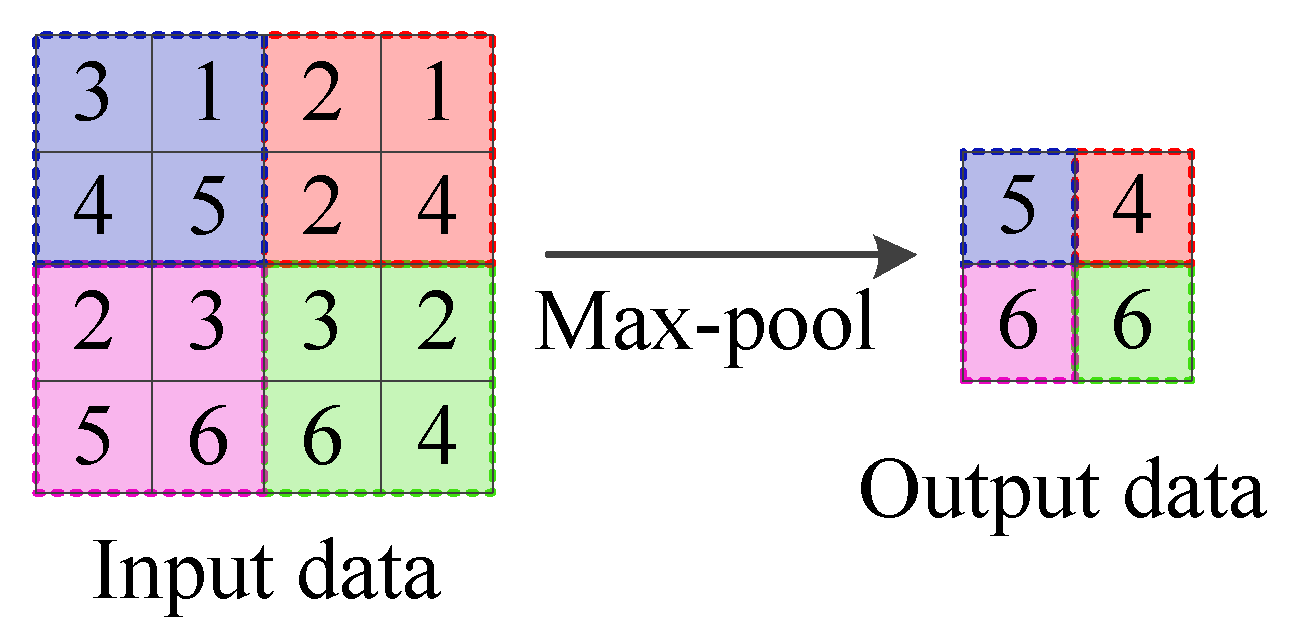
3.2. Convolutional Neural Network
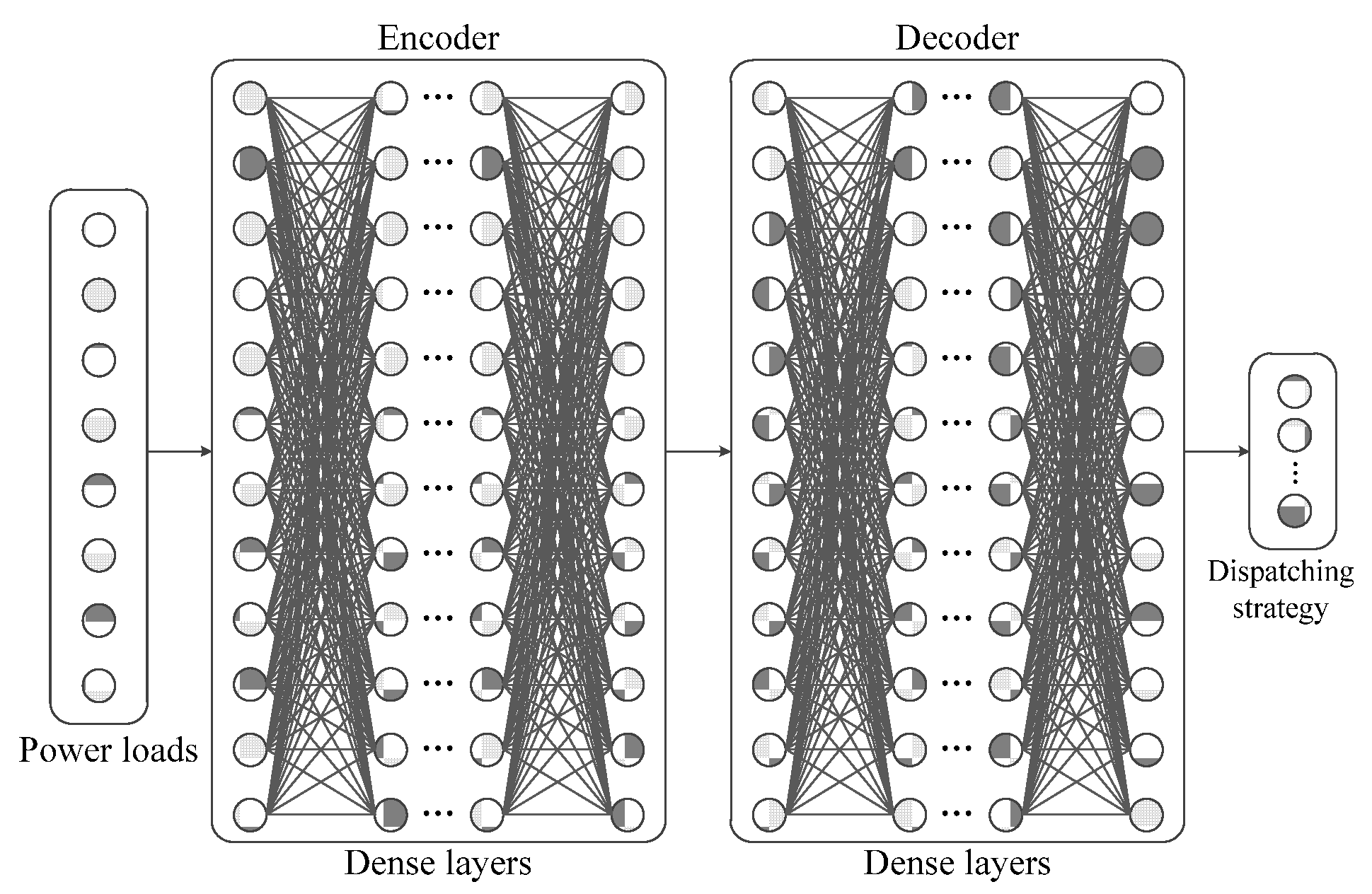
3.3. Multi-Layer Perceptron
3.4. Light Gradient Boosting Machine
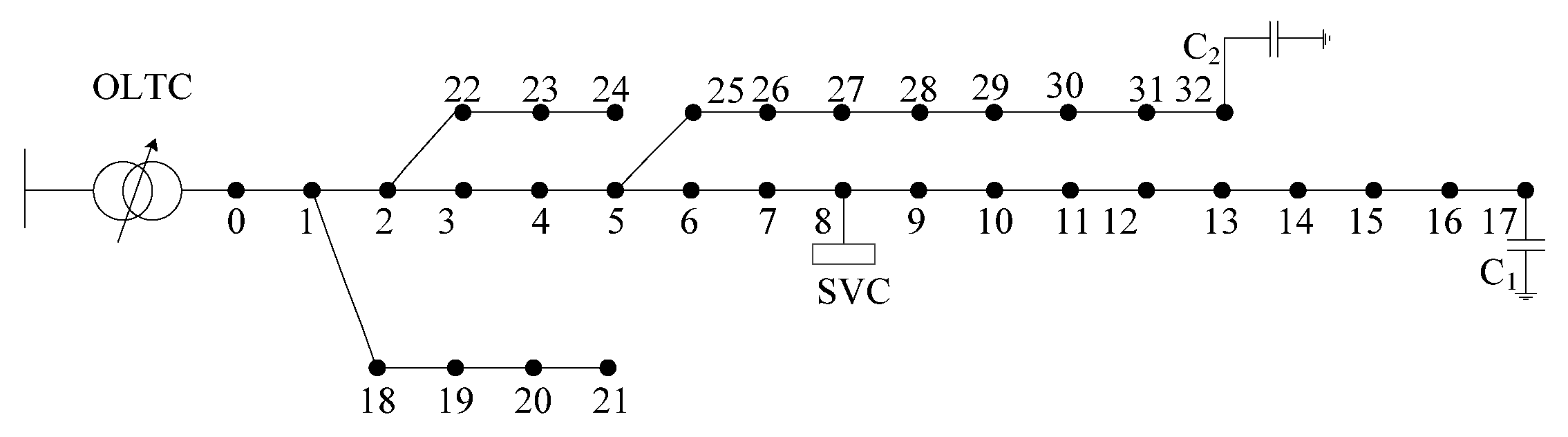
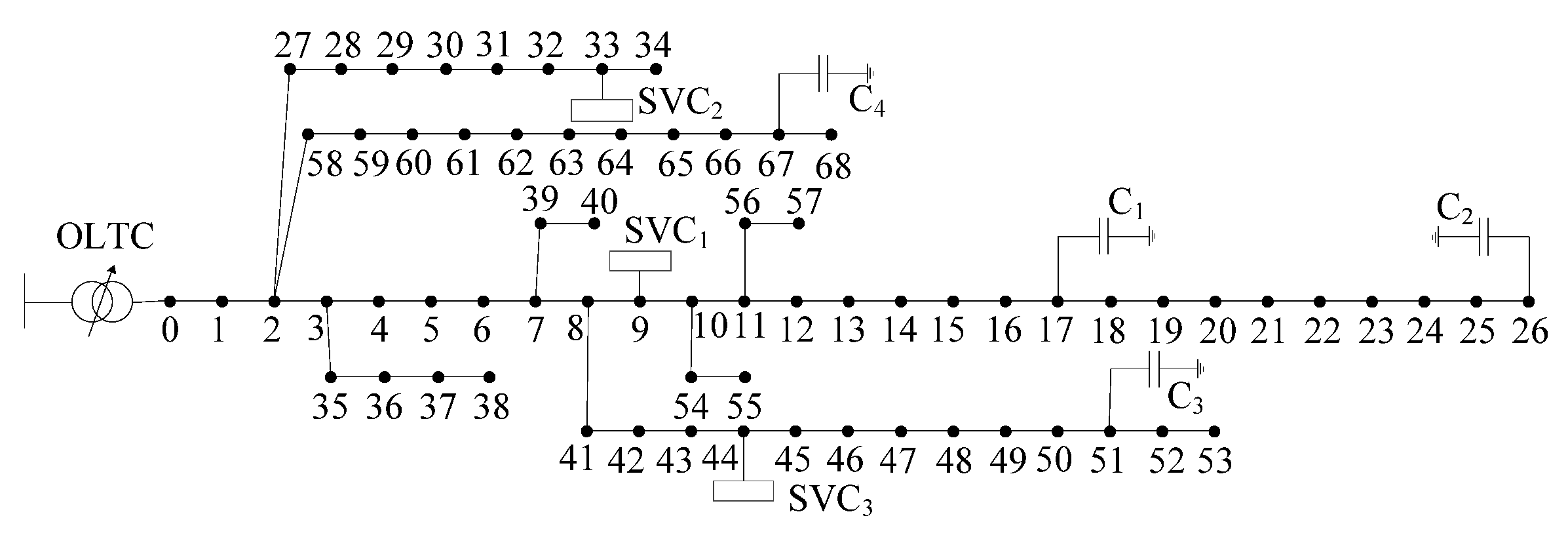
4. Case Study
4.1. Parameters and Data Description
4.2. Effect of k-Fold Cross-Validation
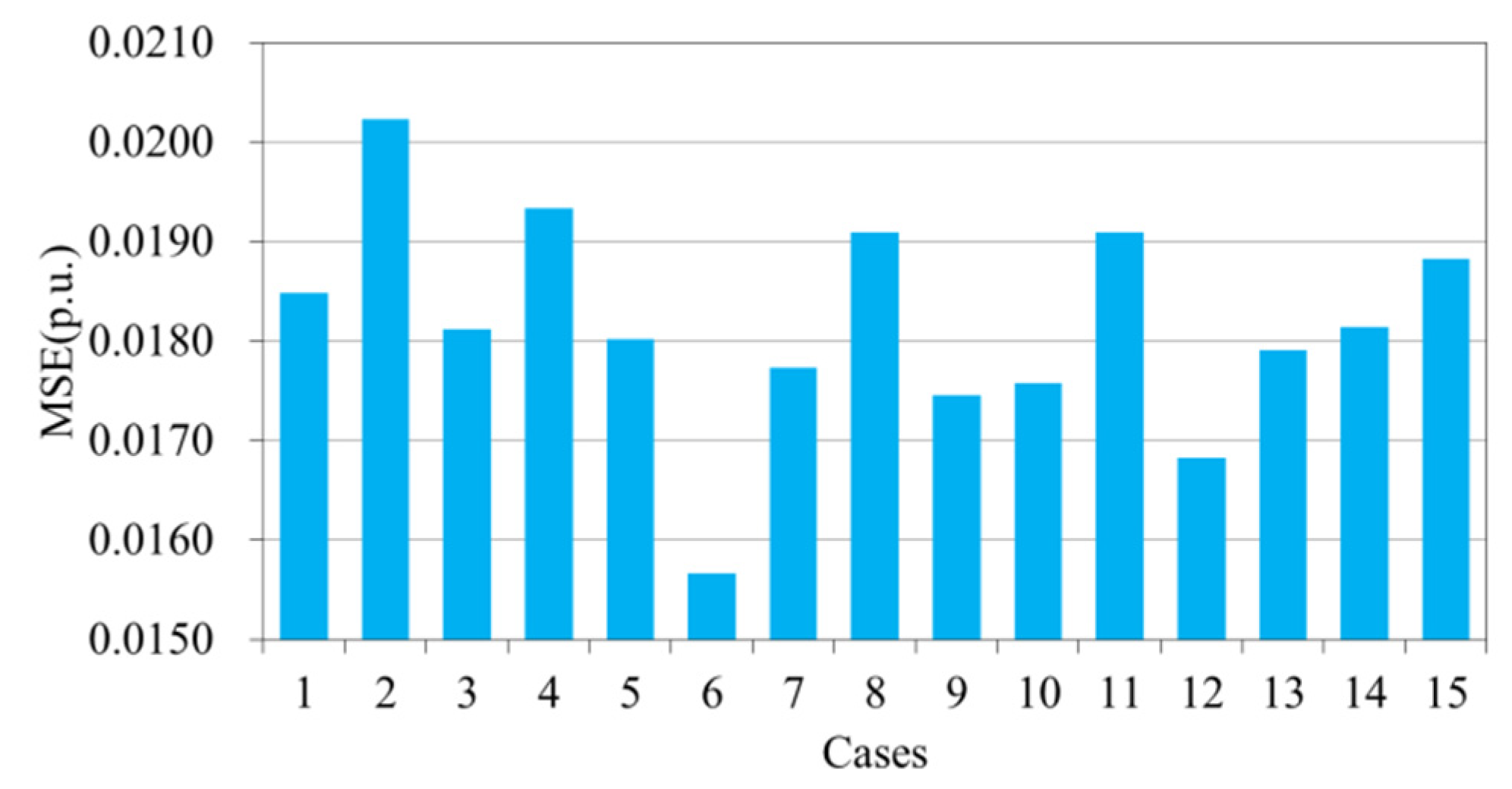
4.3. The Effect of the Order on Performance
4.4. Comparative Analysis with Baselines
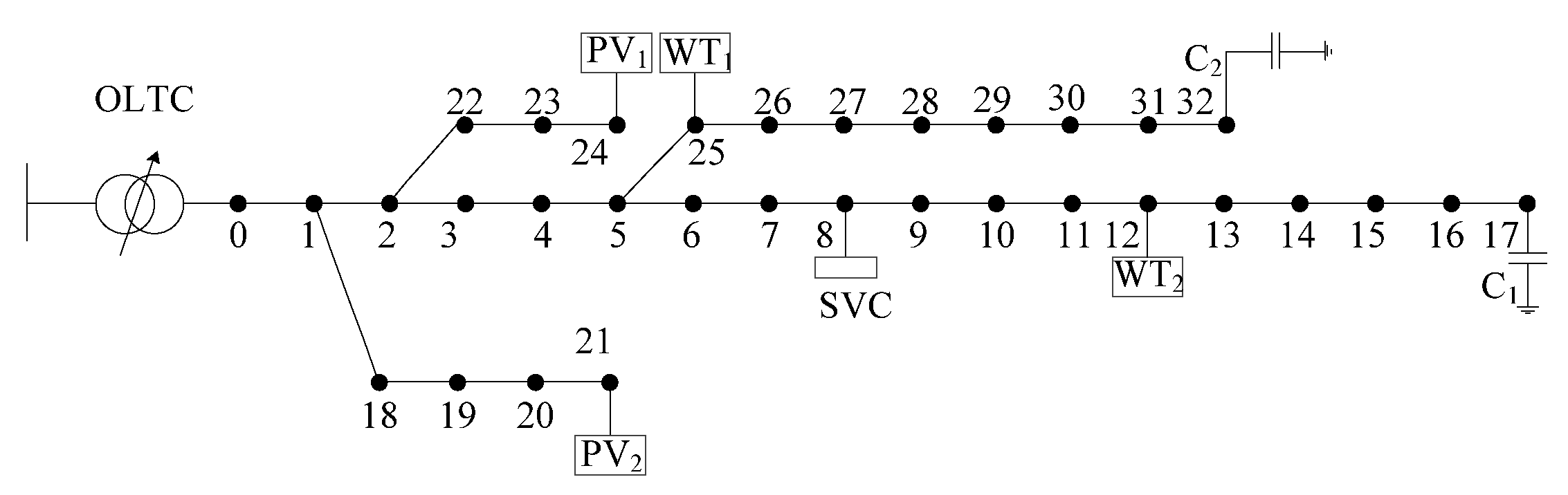
4.5. Reactive Power Optimization with Renewable Energy Sources
5. Conclusions
- (1)
- The accuracy of models trained by k-fold cross-validation is higher than that of hold-out validation. In addition, k should not be too small or too large. Four can be considered as a good starting point for k, and higher values or lower values may be fine for other data sets.
- (2)
- Multiple different sub-models are more conducive to improving the performance of the ensemble model than multiple identical sub-models. Additionally, the performance of the ensemble model is significantly affected by the order of different sub-models. Normally, different sub-models can be selected to form the proposed ensemble model, and their order should be determined by the loss function of the validation set.
- (3)
- The proposed ensemble model outperforms other data-driven-based algorithms (e.g., CNN, CBR, MLP, and LightGBM) in terms of optimization accuracy and stability. In addition, the calculation time is much lower than the traditional heuristic methods (e.g., GA), especially for large-scale distribution networks.
- (4)
- No matter how the penetration changes, the ensemble model has better performance than other data-driven-based algorithms (e.g., CNN, CBR, MLP, and LightGBM) for reactive power optimization of distribution networks.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| Abbreviations | |
| OLTC | on-load tap changer |
| SVC | static var compensator |
| PSO | particle swarm optimization |
| SA | simulated annealing |
| GA | genetic algorithm |
| GOSS | gradient-based one-side sampling |
| CBR | case-based reasoning |
| CNN | convolutional neural network |
| MLP | multi-layer perceptron |
| LightGBM | light gradient boosting machine |
| ReLU | rectified linear unit |
| Adam | adaptive moment estimation |
| Parameters | |
| W | the weight to balance the power loss and voltage offset |
| Ploss | the power loss before reactive power optimization |
| the power loss after reactive power optimization | |
| dU | the voltage offset before reactive power optimization |
| the voltage offset after reactive power optimization | |
| n | the number of nodes in distribution networks |
| N | the number of branches in distribution networks |
| U0 | the rated voltage |
| Ui | the voltage of node i |
| Rl | the resistance of branch l |
| Pl | the active power of terminal node in the branch l |
| Ql | the reactive power of terminal node in the branch l |
| Ul | the voltage of terminal node in the branch l |
| the phase difference of the voltage between node i and node j | |
| Gij | the conductance between node i and node j |
| Bij | the susceptance between node i and node j |
| Ui,max | the upper bound of voltage for node i |
| Ui,min | the lower bound of voltage for node i |
| Il,max | the upper bound of current for branch l |
| nC | the number of nodes with the shunt capacitor bank |
| nT | the number of nodes with OLTC |
| nSVC | the number of nodes with SVC |
| QC,max | the maximum reactive power generated by the shunt capacitor bank |
| Ti,min | the minimum tap position of the OLTC |
| Ti,max | the maximum tap position of the OLTC |
| QSVC,max | the maximum reactive power generated by the SVC |
| F2 | a new form of the comprehensive objective function |
| , | the penalty coefficients |
| the step function | |
| Ycon | the output data of convolutional layers |
| Xcon | the input data of convolutional layers |
| the activation function of convolutional layers | |
| Wcon | weights of convolutional layers |
| Bcon | bias vectors of convolutional layers |
| Ypool | the output data of maximum pooling layers |
| Xpool | the input data of maximum pooling layers |
| R | the domain of definition for maximum pooling layers |
| Ydense | the output data of dense layers |
| Xdense | the input data of dense layers |
| the activation function of dense layers | |
| Wdense | weights of dense layers |
| Bdense | bias vectors of dense layers |
| Yen | the output data of the encoder |
| Xen | the input data of the encoder |
| the activation function of the encoder | |
| Wen | weights of the encoder |
| Ben | bias vectors of the encoder |
| Yde | the output data of the decoder |
| Xde | the input data of the decoder |
| the activation function of the decoder | |
| Wde | weights of the decoder |
| Bde | bias vectors of the decoder |
| ntr | the number of decision trees |
| nsa | the number of samples |
| the forecasting values of the ith sample at the tth iteration | |
| the learned function of the tth decision tree | |
| a regularization | |
| the distance between current forecasts and real values | |
References
- Hui, Q.; Teng, Y.; Zuo, H.; Chen, Z. Reactive power multi-objective optimization for multi-terminal AC/DC interconnected power systems under wind power fluctuation. CSEE J. Power Energy Syst. 2020, 6, 630–637. [Google Scholar] [CrossRef]
- Zhao, Q.; Liao, S.; Pillai, J.R. Robust Voltage Control Considering Uncertainties of Renewable Energies and Loads via Improved Generative Adversarial Network. J. Mod. Power Syst. Clean Energy 2020, 8, 1104–1114. [Google Scholar] [CrossRef]
- Grudinin, N. Reactive power optimization using successive quadratic programming method. IEEE Trans. Power Syst. 1998, 13, 1219–1225. [Google Scholar] [CrossRef]
- Shaheen, A.M.; Spea, S.R.; Farrag, S.M.; Abido, M.A. A review of meta-heuristic algorithms for reactive power planning problem. Ain. Shams. Eng. J. 2018, 9, 215–231. [Google Scholar] [CrossRef] [Green Version]
- Liao, W.; Wang, S.; Liu, Q.; Shu, X. Reactive Power Optimization of Distribution Network Based on Case-Based Reasoning. In Proceedings of the 2018 IEEE Power & Energy Society General Meeting, Portland, OR, USA, 5–10 August 2018. [Google Scholar]
- Yang, Q.; Wang, G.; Sadeghi, A.; Giannakis, G.B.; Sun, J. Two-Timescale Voltage Control in Distribution Grids Using Deep Reinforcement Learning. IEEE Trans. Smart Grid. 2020, 11, 2313–2323. [Google Scholar] [CrossRef] [Green Version]
- Ding, T.; Yang, Q.; Yang, Y.; Li, C.; Bie, Z.; Blaabjerg, F. A Data-Driven Stochastic Reactive Power Optimization Considering Uncertainties in Active Distribution Networks and Decomposition Method. IEEE Trans. Smart Grid. 2018, 9, 4994–5004. [Google Scholar] [CrossRef] [Green Version]
- Krannichfeldt, L.V.; Wang, Y.; Hug, G. Online Ensemble Learning for Load Forecasting. IEEE Trans. Power Syst. 2021, 36, 545–548. [Google Scholar] [CrossRef]
- Hu, R.; Li, Q.; Lei, S. Ensemble Learning based Linear Power Flow. In Proceedings of the 2020 IEEE Power & Energy Society General Meeting, Montreal, QC, Canada, 2–6 August 2020. [Google Scholar]
- Hug, R.; Li, Q.; Qiu, F. Ensemble Learning Based Convex Approximation of Three-Phase Power Flow. IEEE Trans. Power Syst. 2021, 36, 4042–4051. [Google Scholar] [CrossRef]
- Lin, R.; Ye, Z.; Wu, B. The application of hydrogen and photovoltaic for reactive power optimization. Int. J. Hydrog. Energy 2020, 45, 10280–10291. [Google Scholar] [CrossRef]
- Hu, Z.; Wang, X. Time-interval based control strategy of reactive power optimization in distribution networks. Autom. Electr. Power Syst. 2002, 26, 45–49. [Google Scholar] [CrossRef]
- Zhu, R.; Guo, W.; Gong, X. Short-Term Photovoltaic Power Output Prediction Based on k-Fold Cross-Validation and an Ensemble Model. Energies 2019, 12, 1220. [Google Scholar] [CrossRef] [Green Version]
- Wong, T.; Yeh, P. Reliable Accuracy Estimates from k-Fold Cross Validation. IEEE Trans. Knowl. Data Eng. 2020, 32, 1586–1594. [Google Scholar] [CrossRef]
- Sarhan, M.H.; Nasseri, M.A.; Zapp, D.; Maier, M.; Lohmann, C.P.; Navab, N.; Eslami, A. Machine Learning Techniques for Ophthalmic Data Processing: A Review. IEEE J. Biomed. Health Inform. 2020, 24, 3338–3350. [Google Scholar] [CrossRef] [PubMed]
- Aslam, N.; Ramay, W.Y.; Xia, K.; Sarwar, N. Convolutional Neural Network Based Classification of App Reviews. IEEE Access 2020, 8, 185619–185628. [Google Scholar] [CrossRef]
- Chen, T.; Xun, J.; Ying, H.; Chen, X.; Feng, R.; Fang, X.; Gao, H.; Wu, J. Prediction of Extubation Failure for Intensive Care Unit Patients Using Light Gradient Boosting Machine. IEEE Access 2019, 7, 150960–150968. [Google Scholar] [CrossRef]
- Baran, M.E.; Wu, F.F. Network reconfiguration in distribution systems for loss reduction and load balancing. IEEE Trans. Power Del. 1989, 4, 1401–1407. [Google Scholar] [CrossRef]
- Baran, M.; Wu, F.F. Optimal sizing of capacitors placed on a radial distribution system. IEEE Trans. Power Del. 1989, 4, 735–743. [Google Scholar] [CrossRef]
- Low Carbon London Project. Available online: https://data.london.gov.uk/dataset/smartmeter-energyuse-data-in-london-households (accessed on 20 February 2022).
- Liao, W.; Yang, D.; Wang, Y.; Ren, X. Fault diagnosis of power transformers using graph convolutional network. CSEE J. Power Energy Syst. 2021, 7, 241–249. [Google Scholar] [CrossRef]
- Voltage Control in the Future Power Transmission Systems. Available online: https://vbn.aau.dk/ws/portalfiles/portal/254173904/ (accessed on 20 February 2022).
- Draxl, C.; Clifton, A.; Hodge, B.; McCaa, J. The Wind Integration National Dataset (WIND) Toolkit. Appl. Energy 2015, 151, 355–366. [Google Scholar] [CrossRef] [Green Version]
- Solar Integration National Dataset Toolkit. Available online: https://www.nrel.gov/grid/sind-toolkit.html (accessed on 3 March 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cases | MSE (p.u.) | Training Time (s) | Cases | MSE (p.u.) | Training Time (s) |
|---|---|---|---|---|---|
| hold-out | 0.0200 | 1414.51 | k = 8 | 0.0164 | 778.76 |
| k = 2 | 0.0173 | 108.53 | k = 9 | 0.0162 | 854.20 |
| k = 3 | 0.0159 | 206.67 | k = 10 | 0.0167 | 895.95 |
| k = 4 | 0.0157 | 294.97 | k = 11 | 0.0160 | 977.53 |
| k = 5 | 0.0165 | 386.76 | k = 12 | 0.0162 | 1100.97 |
| k = 6 | 0.0167 | 481.69 | k = 13 | 0.0170 | 1209.63 |
| k = 7 | 0.0163 | 635.90 | k = 14 | 0.0195 | 1389.93 |
| Cases | Order of Sub-Models | Cases | Order of Sub-Models |
|---|---|---|---|
| Case 1 | CNN, MLP, LightGBM | Case 9 | MLP, CNN, CNN |
| Case 2 | CNN, LightGBM, MLP | Case 10 | MLP, LightGBM, LightGBM |
| Case 3 | MLP, CNN, LightGBM | Case 11 | LightGBM, MLP, MLP |
| Case 4 | MLP, LightGBM, CNN | Case 12 | LightGBM, CNN, CNN |
| Case 5 | LightGBM, CNN, MLP | Case 13 | CNN, CNN, CNN |
| Case 6 | LightGBM, MLP, CNN | Case 14 | MLP, MLP, MLP |
| Case 7 | CNN, LightGBM, LightGBM | Case 15 | LightGBM, LightGBM, LightGBM |
| Case 8 | CNN, MLP, MLP |
| Networks | Methods | Power Loss (MW) | Voltage Offset (p.u.) | Comprehensive Objective Function (p.u.) | Calculation Time (s) | |||
|---|---|---|---|---|---|---|---|---|
| Mean Value | Variance | Mean Value | Variance | Mean Value | Variance | |||
| The modified IEEE 33-bus radial distribution network | Ensemble model | 0.2314 | 0.1290 | 0.7975 | 0.2851 | 1.1411 | 0.0291 | 0.17 |
| GA | 0.2316 | 0.1286 | 0.7942 | 0.2854 | 1.1423 | 0.0288 | 21.30 | |
| CNN | 0.2316 | 0.1292 | 0.8028 | 0.2858 | 1.1396 | 0.0292 | 0.06 | |
| MLP | 0.2318 | 0.1295 | 0.8108 | 0.2883 | 1.1383 | 0.0294 | 0.04 | |
| LightGBM | 0.2317 | 0.1292 | 0.8052 | 0.2865 | 1.1392 | 0.0292 | 0.07 | |
| CBR | 0.2317 | 0.1286 | 0.8179 | 0.2933 | 1.1339 | 0.0328 | 4.01 | |
| The modified IEEE 69-bus radial distribution network | Ensemble model | 0.6331 | 0.1284 | 3.6311 | 0.2861 | 0.8343 | 0.0349 | 0.23 |
| GA | 0.6332 | 0.1273 | 3.6278 | 0.2867 | 0.8367 | 0.0345 | 64.77 | |
| CNN | 0.6337 | 0.1287 | 3.6364 | 0.2873 | 0.8329 | 0.0352 | 0.08 | |
| MLP | 0.6334 | 0.1293 | 3.6444 | 0.2944 | 0.8317 | 0.0358 | 0.06 | |
| LightGBM | 0.6339 | 0.129 | 3.6388 | 0.2921 | 0.8323 | 0.0352 | 0.09 | |
| CBR | 0.6346 | 0.1264 | 3.6515 | 0.2977 | 0.8239 | 0.0396 | 4.37 | |
| Penetration Level (%) | Ensemble Model | CNN | MLP | LightGBM | CBR |
|---|---|---|---|---|---|
| 10% | 1.1391 | 1.1266 | 1.1258 | 1.1237 | 1.1055 |
| 20% | 1.1173 | 1.1113 | 1.1104 | 1.1097 | 1.1044 |
| 30% | 1.1095 | 1.1063 | 1.0988 | 1.0975 | 1.0953 |
| 40% | 1.0975 | 1.0944 | 1.0933 | 1.09921 | 1.087 |
| 50% | 1.0782 | 1.0677 | 1.0644 | 1.0643 | 1.064 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, R.; Tang, B.; Wei, W. Ensemble Learning-Based Reactive Power Optimization for Distribution Networks. Energies 2022, 15, 1966. https://doi.org/10.3390/en15061966
Zhu R, Tang B, Wei W. Ensemble Learning-Based Reactive Power Optimization for Distribution Networks. Energies. 2022; 15(6):1966. https://doi.org/10.3390/en15061966
Chicago/Turabian StyleZhu, Ruijin, Bo Tang, and Wenhai Wei. 2022. "Ensemble Learning-Based Reactive Power Optimization for Distribution Networks" Energies 15, no. 6: 1966. https://doi.org/10.3390/en15061966