

Advanced Spatial and Technological Aggregation Scheme for Energy System Models


Abstract
:1. Introduction
1.1. Background: Spatiotemporal Energy System Optimization Models
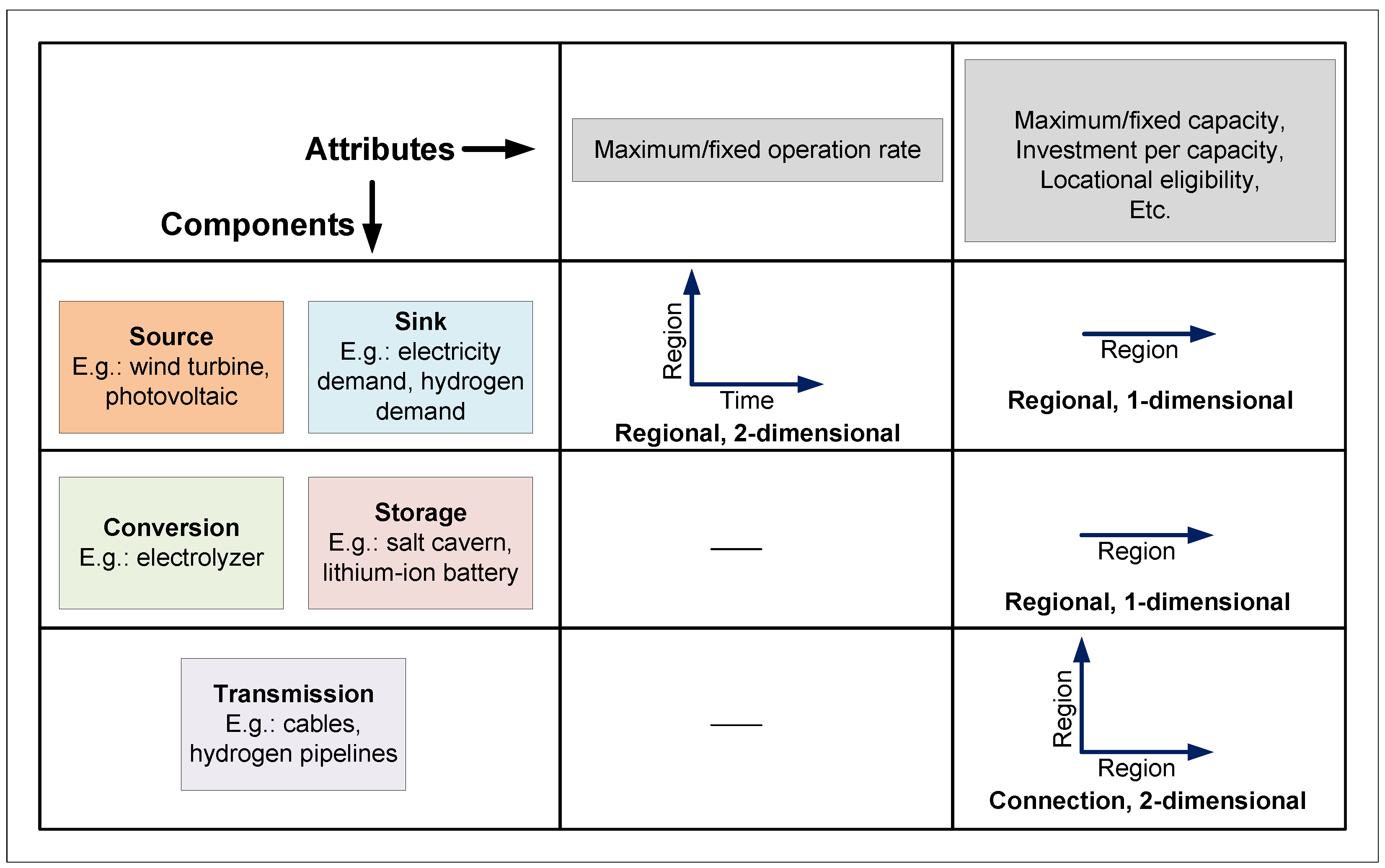
- Spatial description: Geographical area and the network of regions within it. Each region in this network is treated as a single node with transmission connections to neighboring regions.Note: Each region is assumed to be a lossless copper plate. Under this assumption, the infrastructure and restrictions of energy transport, within the region, are disregarded [4].
- A set of technologies within each region:
- -
- Different generation, storage, conversion, and transmission technologies.
- -
- Minimum and maximum capacity of each.
- -
- Capital, operating, maintenance costs, etc.
- The energy demand.
- Resource availability and its maximum operation limit.
- Capacity and location of different technologies.
- Operation (defined in terms of capacity factor (CF) time series) of each technology.
1.2. The Computational Complexity Issue
- Mathematical complexity: Mathematical formulation of the model and its ability to take the stochastic behavior of the system into consideration.
- Temporal complexity: Temporal resolution and scope of the model.
- Spatial complexity: Spatial resolution and scope of the model.
- System scope: System’s parts and level of detail that the model considers.
1.3. Data Aggregation for Complexity Reduction
1.4. Objective
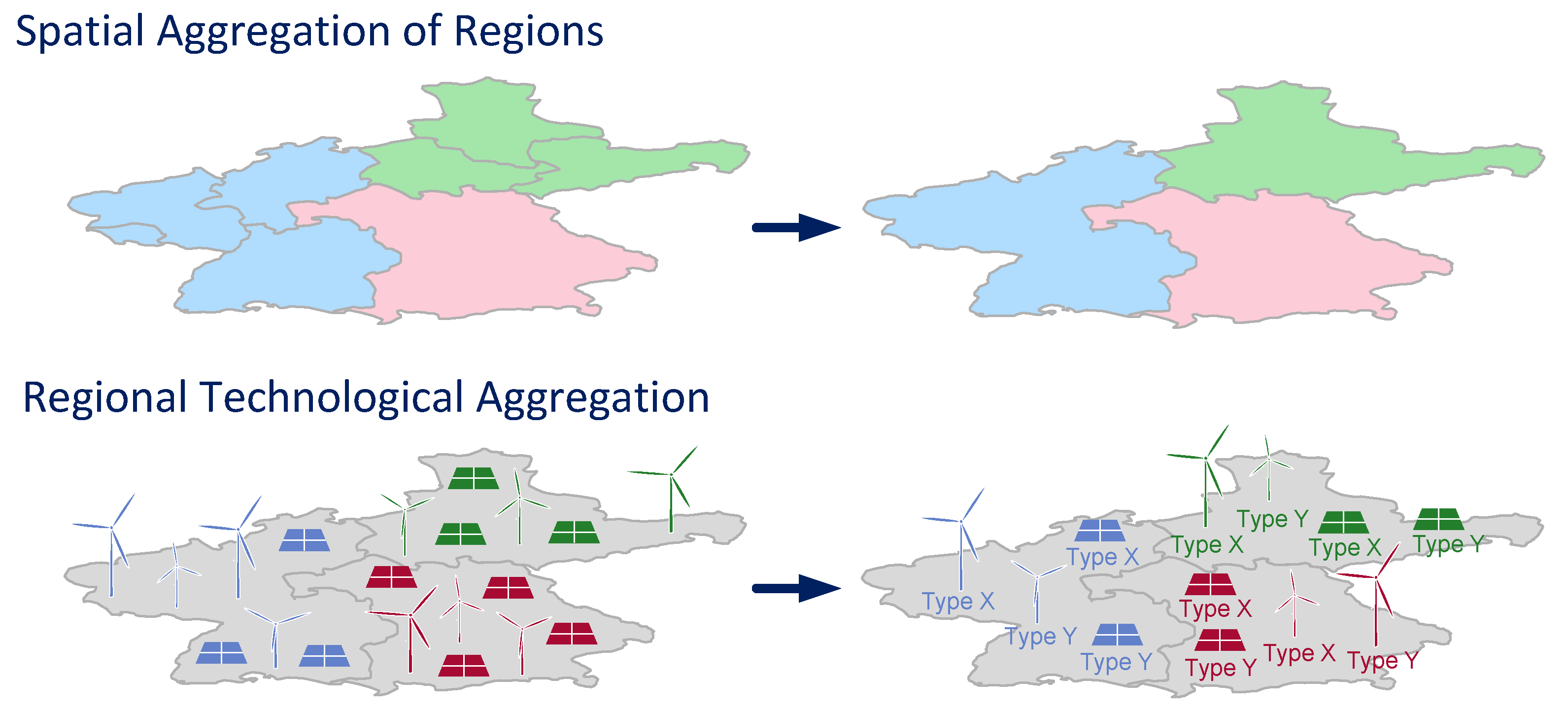
- First, the model regions are aggregated.
- Next, the CF time series of variable renewable energy source (VRES) (i.e., wind turbine and photovoltaic) are aggregated within each newly-defined region.
2. State of Research
2.1. Spatial Aggregation of Regions
2.2. Technological Aggregation
2.3. Research Gaps and Challenges
3. Methodology
3.1. Energy System Optimization Model Details
- Regional attributes: These attributes are region-specific. They can be one-dimensional (region) or two-dimensional (region × time). Examples of one- and two-dimensional regional attributes are the maximum capacity and CF time series of a wind turbine, respectively.
- Connection attributes: These attributes characterize the connections between regions. They are always two-dimensional (region × region). An example of a connection attribute is the capacity of a DC cable between two regions.
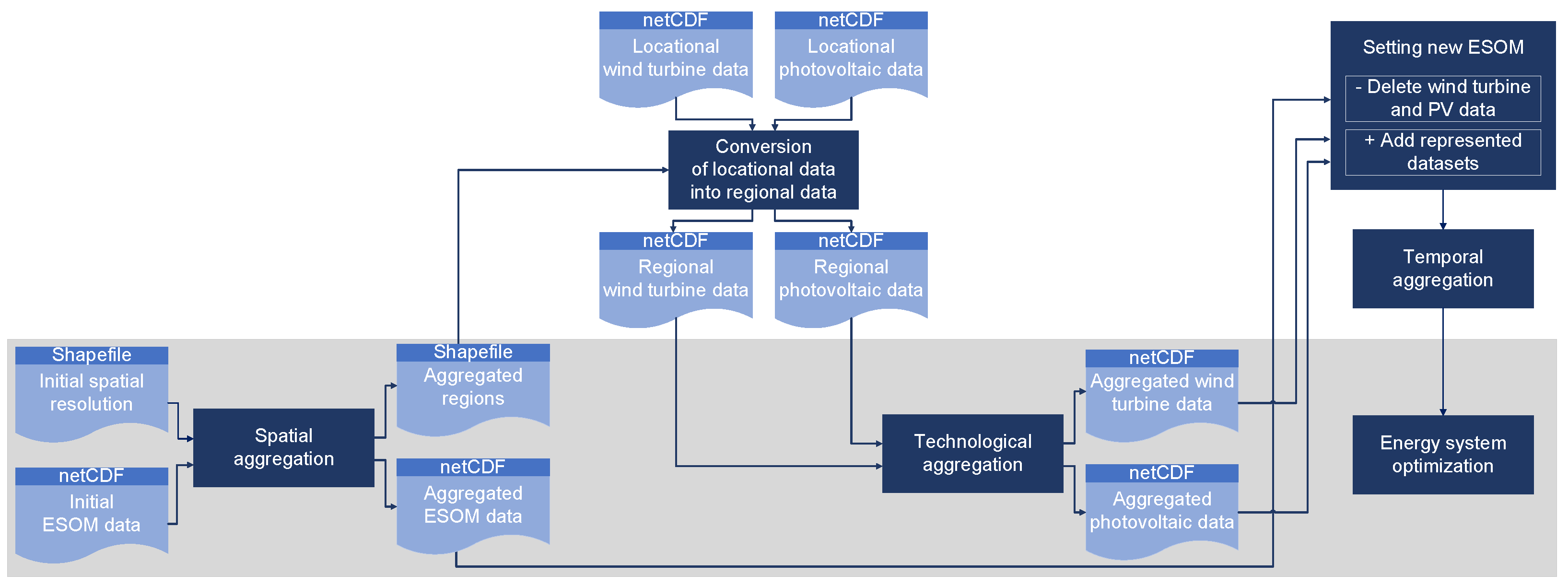
3.2. General Workflow
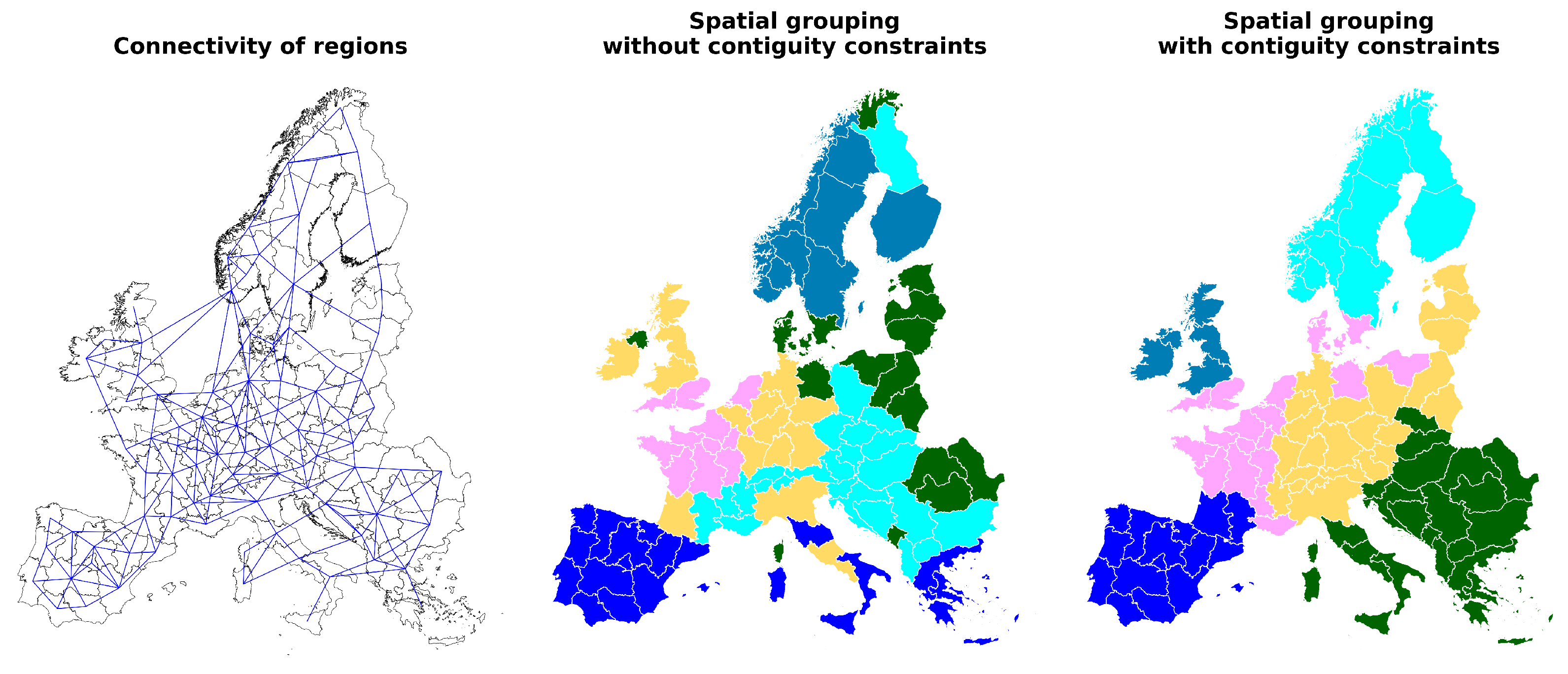
3.3. Spatial Aggregation
3.3.1. Algorithm
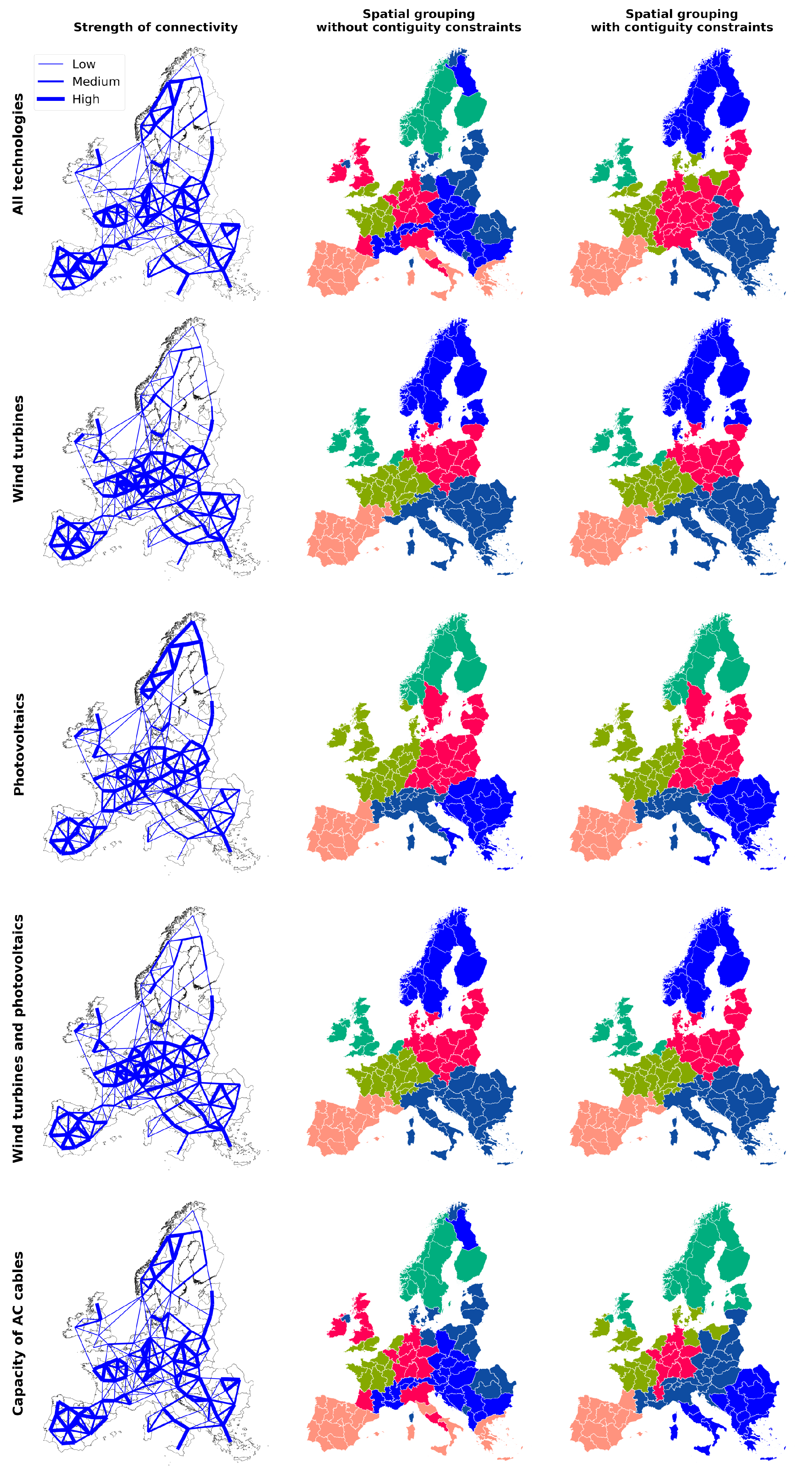
3.3.2. Distance Measure
3.3.3. Connectivity Matrix
- Their borders touch at least at one point;
- One of the regions is an island and the other its nearest mainland region;
- There is a transmission line or pipeline running between them.
3.3.4. Data Aggregation
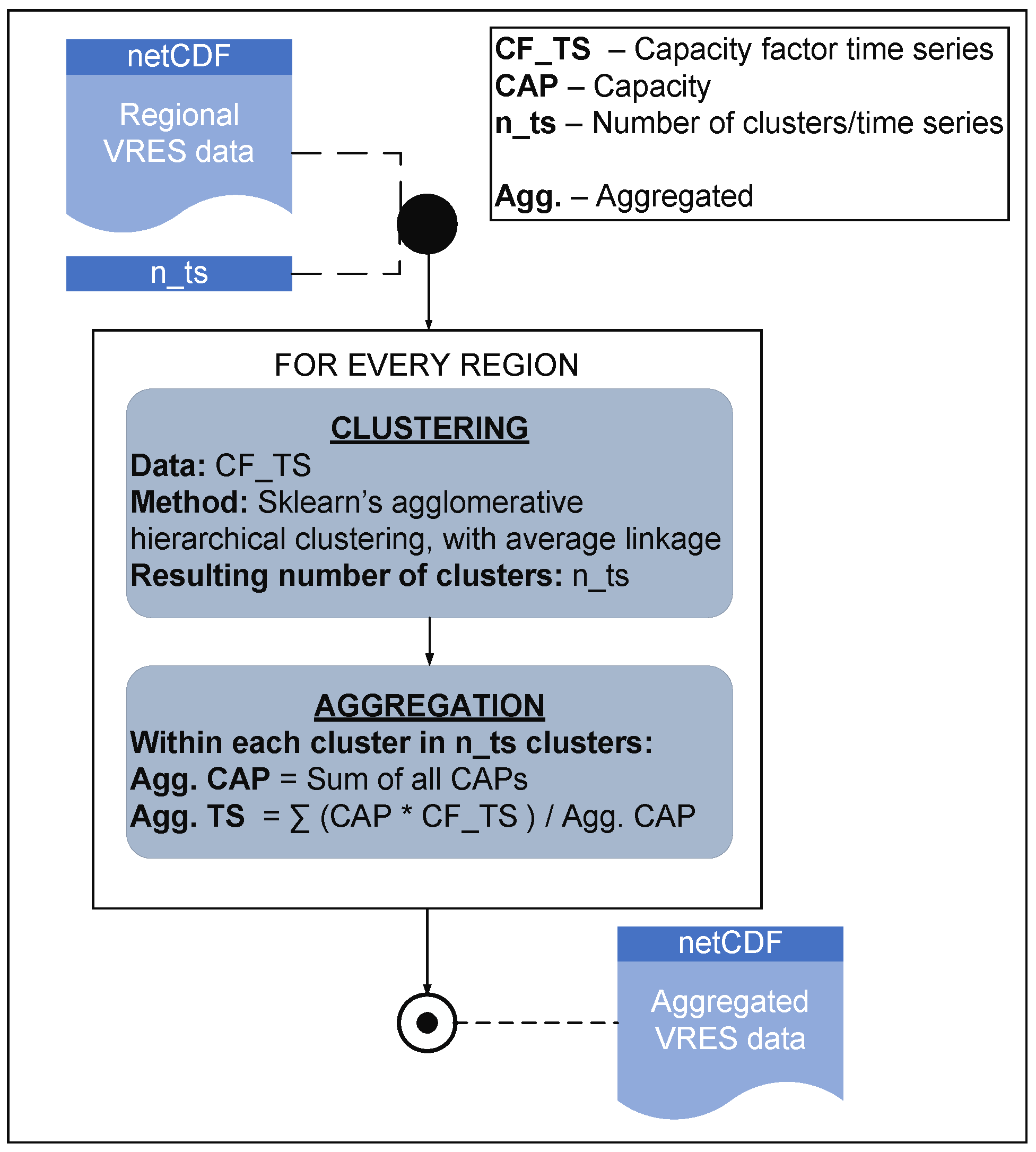
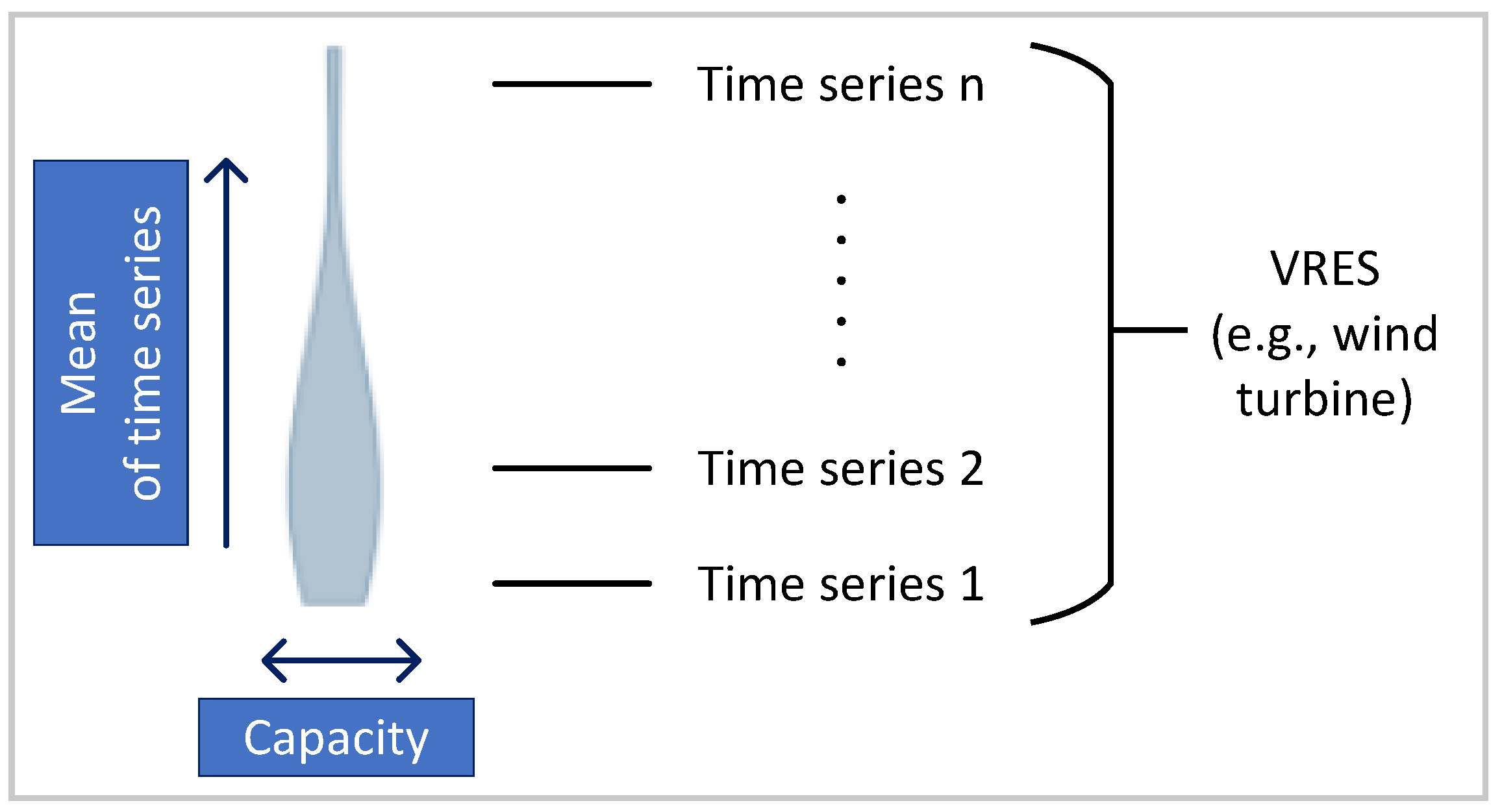
3.4. Technological Aggregation
3.5. Experimental Design
3.5.1. Attributes Chosen for Spatial Aggregation
3.5.2. Spatial, Technological, and Temporal Scopes and Resolutions of ESOM
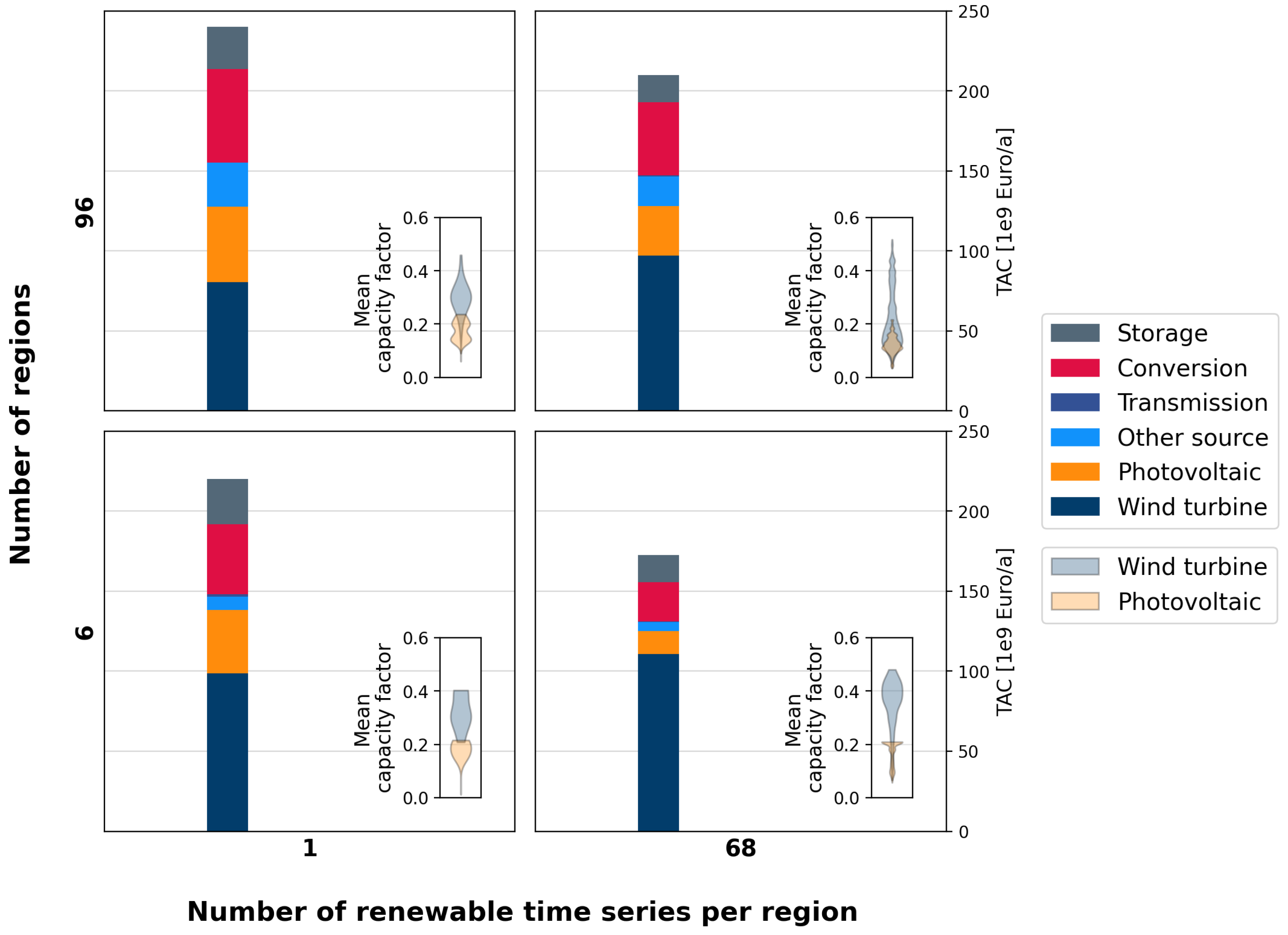
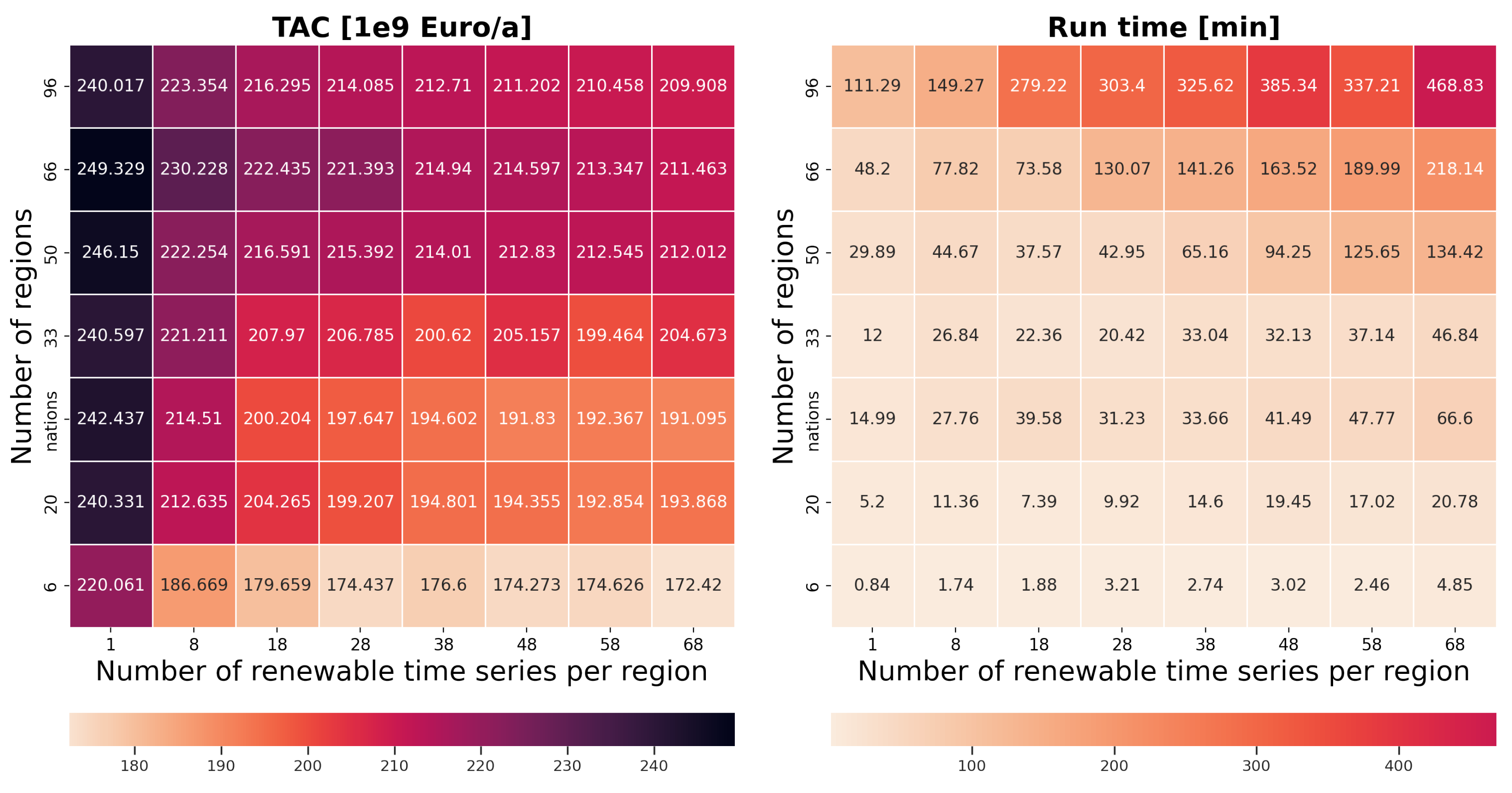
- Spatial scope and resolution: A European energy system scenario [35] is considered in this paper. The ESOM is set up for the same. As for the spatial resolution, the region definition suggested in the e-highway study is considered. In this study, the geographical area of Europe is divided into 96 regions.
- Technological scope and resolution: The wind turbines and photovoltaics are simulated for all of Europe. The result contains approximately 840,000 wind turbines and photovoltaics.
- Temporal scope and resolution: The data of one year are considered. They have an hourly temporal resolution, with 8760 time steps for one year. Prior to optimization, temporal aggregation is performed. The resolution is reduced to 40 typical days with eight segments within each typical day. For this purpose, the method developed by Hoffmann et al. [45] is employed.In order to accurately assess the impact of spatial and technological aggregations on the optimization results, the effects of temporal aggregation should be nullified across all experimental runs. Here, it is accomplished by performing temporal aggregation only for the highest spatial and technological resolution. The resulting temporal clusters are saved and in all the successive runs, the data are temporally aggregated to obtain the same clusters. This ensures that, in each case, the time series are reduced temporally to obtain the same set of typical days, with the same segments in each typical day.
3.5.3. Evaluation Method
4. Results
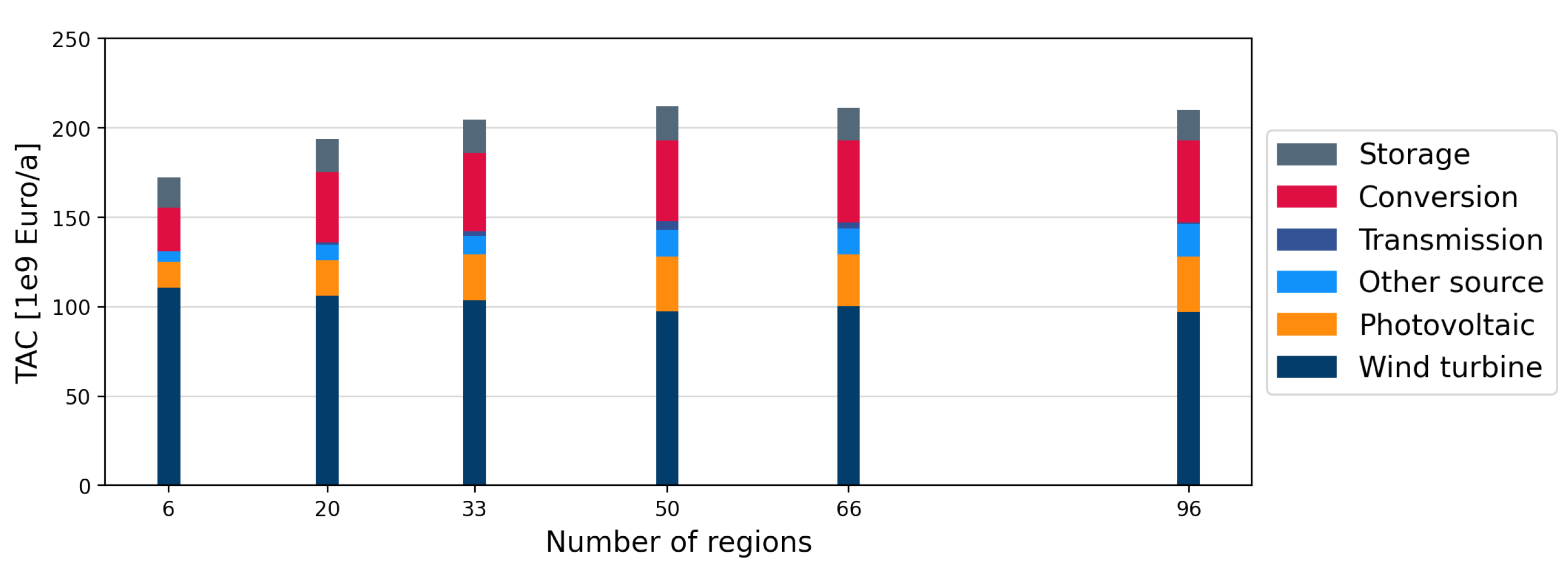
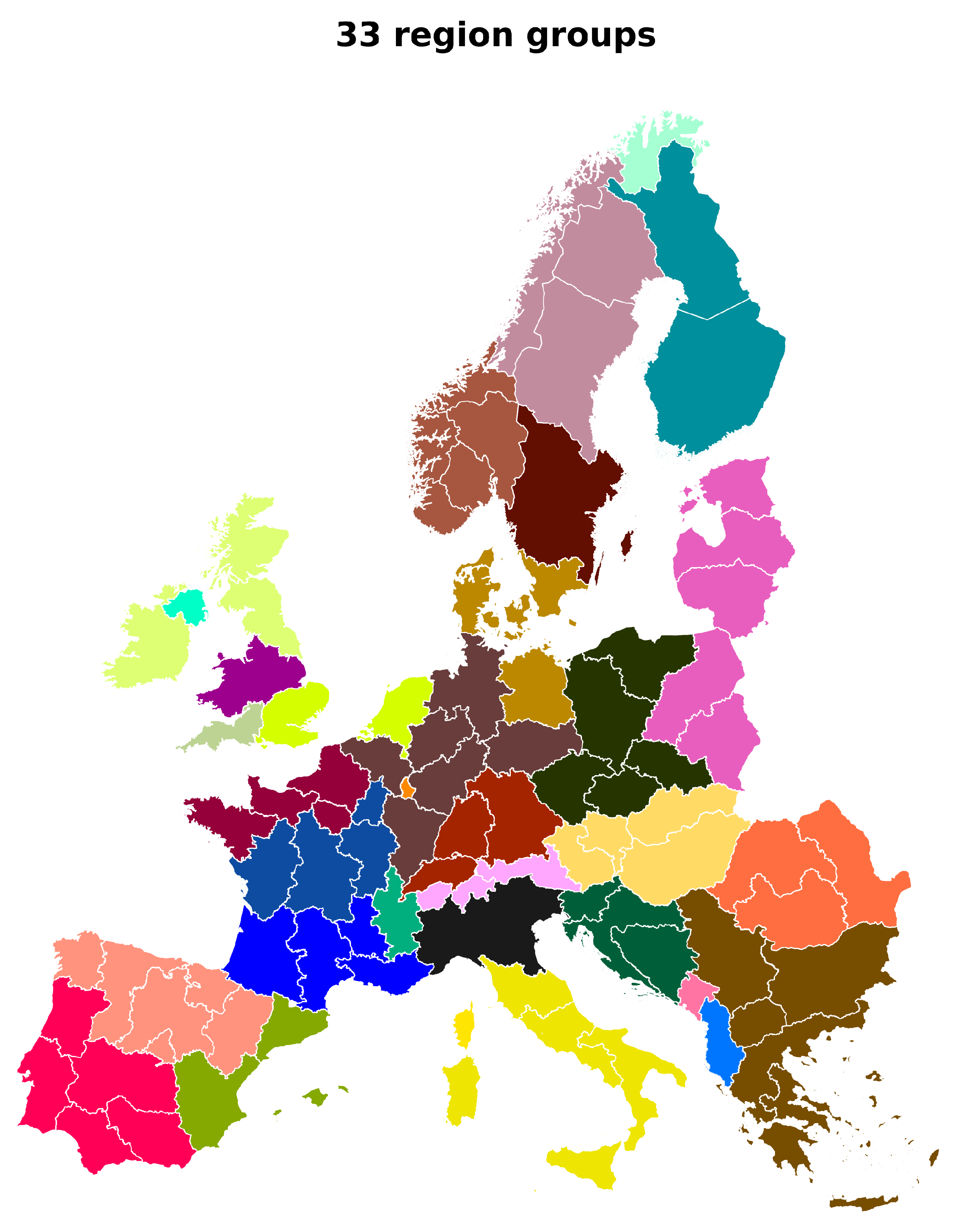
4.1. Spatial Aggregation
4.2. Technological Aggregation
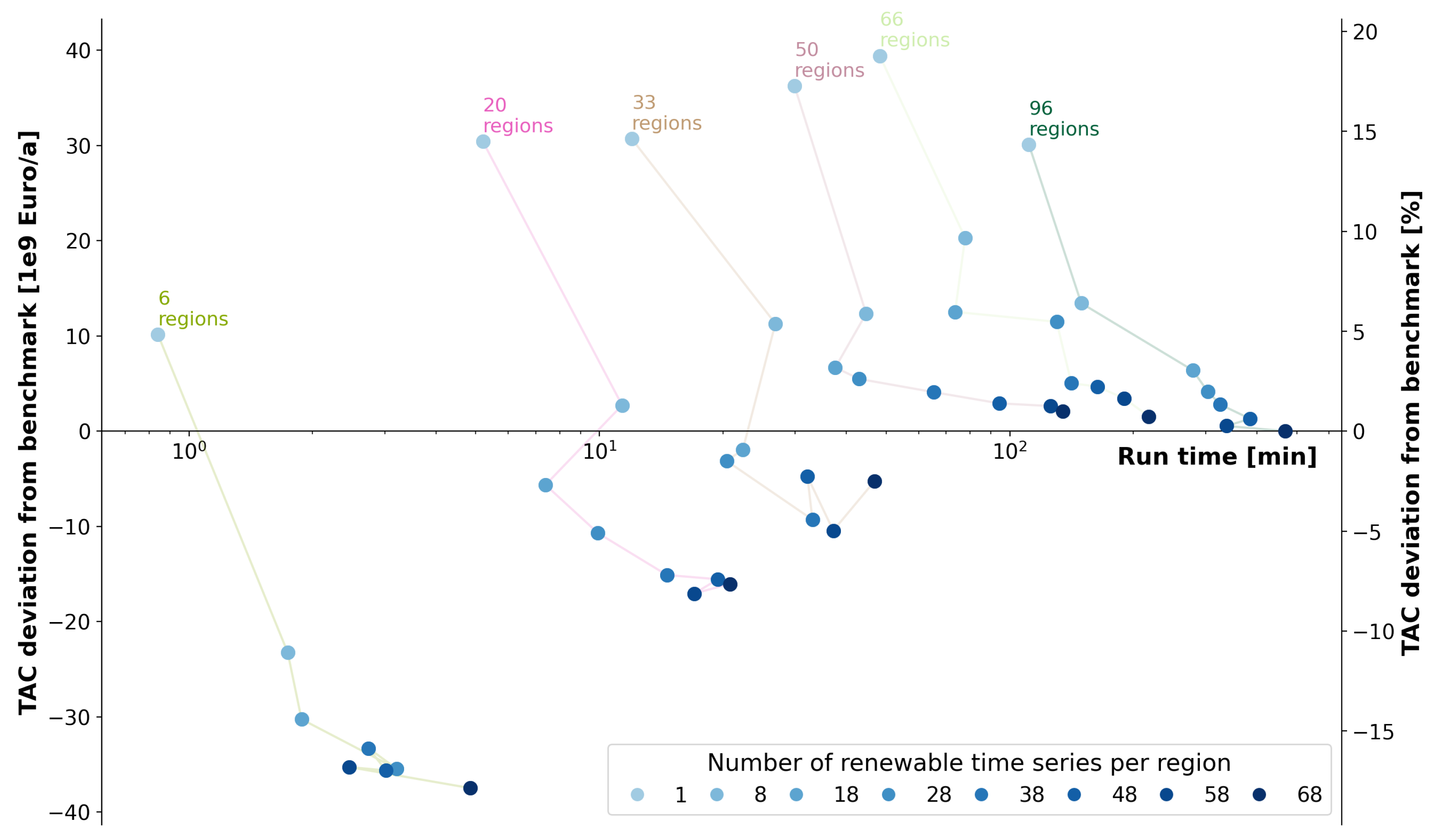
4.3. Impact of Spatial and Technological Aggregation on Optimization Results
5. Summary and Discussion
6. Conclusions
7. Outlook
- In our analysis, we consider all the model parameters for spatial aggregation. In Appendix B, we show how the region groups differ when different sets of attributes are chosen for spatial aggregation. However, it would be interesting to perform a detailed sensitivity analysis.
- Our focus in this paper was to sufficiently represent variable renewable energy sources in each region. It would also be interesting to increase the spatial details of other components, such as storage technologies, and investigate the extent of their influence on energy system design.
- Certain combinations of spatial and technological aggregations would also be worth investigating. For example, spatial aggregation based on electricity grid, and maintaining the spatial resolution of both source and storage technologies sufficiently high in each region.
- We performed a spatial and technological aggregation and then a temporal aggregation in our experiments reported herein. It would be worth investigating the effect of a switch in this order and to determine an optimal combination of spatial, technological, and temporal resolutions.
8. Code Availability
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| RES | Renewable energy source |
| VRES | Variable renewable energy source |
| ESOM | Energy system optimization model |
| TAC | Total annual cost |
| FINE | Framework for Integrated Energy System Assessment |
| RESKit | Renewable Energy Simulation toolkit |
| GLAES | Geospatial Land Availability for Energy Systems |
| CF | Capacity factor |
| LCOE | Levelized cost of electricity |
| GHG | Greenhouse gas |
Appendix A. Optimization Formulation
- Energy balance constraints: These constraints ensure that the electricity demand is satisfied at all time steps in all regions . The energy balance for a region r during a time step t is given by:where is the demand, is the generated power, is the operation of a conversion technology, and represents the conversion factor.
- Power generation constraints: These constraints ensure that the quantity of built renewable technology does not exceed the maximum permitted quantity. If and are the built and permissible quantities, respectively, of a renewable technology p in a region r, then this is mathematically expressed as follows:Furthermore, in a region r during a time step t, the amount of generated power is limited by:where is the power output of a single unit of the technology during a time step t.
- Conversion technologies constraints: The maximum operation of a conversion technology c in a region r during a time step t is limited by:where is the maximum operating limit of a single unit of the technology and is the quantity of technology built in the region.
- Storage technologies constraints: There are three types of constraints that are imposed on storage technologies. These are:
- Constraints related to availability and placement capacity: If represents a set of placement-restricted storage technologies, then these constraints are represented by:where and are the built and permissible quantities, respectively, of a placement-restricted storage technology in a region r.
- Constraints related to storage inventories: The inventory of a storage technology s, during any given time t, in a region r is limited by the maximum possible inventory of a single unit and the number of built units , in the region. This is mathematically expressed as follows:
- Constraints related to injection and withdrawal rates: The injection and withdrawal rates of a storage technology s in a given region r are limited by the permissible injection and withdrawal rates () and () for a single unit of the technology. If is the quantity of the technology built in region r, then the difference in inventory levels between any two consecutive time steps is limited by:
- Transmission technologies constraints: Energy flow is only permitted between adjacent regions. Further, energy flow cannot exceed the maximum operating limit of a transmission technology. The energy flow between regions r and using a transmission technology l during time step t is constrained by:where is 1 if the two regions are connected, and 0 otherwise. is 1 if the technology is built, and 0 otherwise. Finally, is the maximum operating limit.Furthermore, the transmission technologies are assumed to be bidirectional. Therefore, is the same as and is formulated as follows:
Appendix B. Impact of the Chosen Set of Attributes on Spatial Grouping Result

References
- Agreement, P. Paris agreement. In Proceedings of the Report of the Conference of the Parties to the United Nations Framework Convention on Climate Change (21st Session, 2015: Paris), Retrived December, HeinOnline, Paris, France, 30 November–15 December 2015; Volume 4, p. 2017. [Google Scholar]
- Samsatli, S.; Samsatli, N.J. A general spatio-temporal model of energy systems with a detailed account of transport and storage. Comput. Chem. Eng. 2015, 80, 155–176. [Google Scholar] [CrossRef]
- DeCarolis, J.; Daly, H.; Dodds, P.; Keppo, I.; Li, F.; McDowall, W.; Pye, S.; Strachan, N.; Trutnevyte, E.; Usher, W.; et al. Formalizing best practice for energy system optimization modelling. Appl. Energy 2017, 194, 184–198. [Google Scholar] [CrossRef] [Green Version]
- Cao, K.K.; Metzdorf, J.; Birbalta, S. Incorporating power transmission bottlenecks into aggregated energy system models. Sustainability 2018, 10, 1916. [Google Scholar] [CrossRef] [Green Version]
- Welder, L.; Ryberg, D.S.; Kotzur, L.; Grube, T.; Robinius, M.; Stolten, D. Spatio-temporal optimization of a future energy system for power-to-hydrogen applications in Germany. Energy 2018, 158, 1130–1149. [Google Scholar] [CrossRef]
- Samsatli, S.; Samsatli, N.J. A multi-objective MILP model for the design and operation of future integrated multi-vector energy networks capturing detailed spatio-temporal dependencies. Appl. Energy 2018, 220, 893–920. [Google Scholar] [CrossRef]
- Pfenninger, S.; Hawkes, A.; Keirstead, J. Energy systems modeling for twenty-first century energy challenges. Renew. Sustain. Energy Rev. 2014, 33, 74–86. [Google Scholar] [CrossRef]
- Ridha, E.; Nolting, L.; Praktiknjo, A. Complexity profiles: A large-scale review of energy system models in terms of complexity. Energy Strategy Rev. 2020, 30, 100515. [Google Scholar] [CrossRef]
- Priesmann, J.; Nolting, L.; Praktiknjo, A. Are complex energy system models more accurate? An intra-model comparison of power system optimization models. Appl. Energy 2019, 255, 113783. [Google Scholar] [CrossRef]
- Frew, B.A.; Jacobson, M.Z. Temporal and spatial tradeoffs in power system modeling with assumptions about storage: An application of the POWER model. Energy 2016, 117, 198–213. [Google Scholar] [CrossRef] [Green Version]
- Kotzur, L.; Nolting, L.; Hoffmann, M.; Groß, T.; Smolenko, A.; Priesmann, J.; Büsing, H.; Beer, R.; Kullmann, F.; Singh, B.; et al. A modeler’s guide to handle complexity in energy system optimization. arXiv 2020, arXiv:2009.07216. [Google Scholar] [CrossRef]
- Cao, K.K.; von Krbek, K.; Wetzel, M.; Cebulla, F.; Schreck, S. Classification and evaluation of concepts for improving the performance of applied energy system optimization models. Energies 2019, 12, 4656. [Google Scholar] [CrossRef] [Green Version]
- Grubesic, T.H.; Wei, R.; Murray, A.T. Spatial clustering overview and comparison: Accuracy, sensitivity, and computational expense. Ann. Assoc. Am. Geogr. 2014, 104, 1134–1156. [Google Scholar] [CrossRef]
- Siala, K.; Mahfouz, M.Y. Impact of the choice of regions on energy system models. Energy Strategy Rev. 2019, 25, 75–85. [Google Scholar] [CrossRef]
- Fischer, M.M. Regional taxonomy: A comparison of some hierarchic and non-hierarchic strategies. Reg. Sci. Urban Econ. 1980, 10, 503–537. [Google Scholar] [CrossRef]
- Duque, J.C.; Anselin, L.; Rey, S.J. The max-p-regions problem. J. Reg. Sci. 2012, 52, 397–419. [Google Scholar] [CrossRef]
- Hörsch, J.; Brown, T. The role of spatial scale in joint optimisations of generation and transmission for European highly renewable scenarios. In Proceedings of the 2017 14th International Conference on the European Energy Market (EEM), IEEE, Dresden, Germany, 6–9 June 2017; pp. 1–7. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef] [Green Version]
- Biener, W.; Rosas, K.R.G. Grid reduction for energy system analysis. Electr. Power Syst. Res. 2020, 185, 106349. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheng, H.; Yu, J.X. Graph clustering based on structural/attribute similarities. Proc. Vldb Endow. 2009, 2, 718–729. [Google Scholar] [CrossRef] [Green Version]
- Ward, J.H., Jr. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Fiedler, M. Algebraic connectivity of graphs. Czechoslov. Math. J. 1973, 23, 298–305. [Google Scholar] [CrossRef]
- Scaramuzzino, C.; Garegnani, G.; Zambelli, P. Integrated approach for the identification of spatial patterns related to renewable energy potential in European territories. Renew. Sustain. Energy Rev. 2019, 101, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Eurostat, N. Nomenclature of Territorial Units for Statistics; Eurostat: Luxembourg, 1995. [Google Scholar]
- Malika, C.; Ghazzali, N.; Boiteau, V.; Niknafs, A. NbClust: An R package for determining the relevant number of clusters in a data Set. J. Stat. Softw. 2014, 61, 1–36. [Google Scholar]
- Anderski, T.; Surmann, Y.; Stemmer, S.; Grisey, N.; Momot, E.; Leger, A.; Betraoui, B.; van Roy, P. European Cluster Model of the Pan-European Transmission Grid: E-HIGHWAY 2050: Modular Development Plan of the Pan-European Transmission System 2050; Technical Report; Rte Reseau De Transport D’Electricite: Paris, France, 2015. [Google Scholar]
- Duque, J.; Dev, B.; Betancourt, A.; Franco, J. ClusterPy: Library of Spatially Constrained Clustering Algorithms; Version 0.9.9; RiSE-group (Research in Spatial Economics), EAFIT University: Medellín, Colombia, 2011. [Google Scholar]
- Vassilvitskii, S.; Arthur, D. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LO, USA, 7–9 January 2006; pp. 1027–1035. [Google Scholar]
- De Greve, Z.; Lecron, F.; Vallee, F.; Mor, G.; Perez, D.; Danov, S.; Cipriano, J. Comparing time-series clustering approaches for individual electrical load patterns. Cired-Open Access Proc. J. 2017, 2017, 2165–2168. [Google Scholar] [CrossRef]
- Räsänen, T.; Kolehmainen, M. Feature-based clustering for electricity use time series data. In Proceedings of the International Conference on Adaptive and Natural Computing Algorithms, Kuopio, Finland, 23–25 April 2009; pp. 401–412. [Google Scholar]
- Sun, M.; Konstantelos, I.; Strbac, G. C-vine copula mixture model for clustering of residential electrical load pattern data. IEEE Trans. Power Syst. 2016, 32, 2382–2393. [Google Scholar] [CrossRef] [Green Version]
- Joubert, C.J.; Vermeulen, H.J. Optimisation of wind farm location using mean-variance portfolio theory and time series clustering. In Proceedings of the 2016 IEEE International Conference on Power and Energy (PECon), IEEE, Melaka City, Malaysia, 28–29 November 2016; pp. 637–642. [Google Scholar]
- Munshi, A.A.; Yasser, A.R.M. Photovoltaic power pattern clustering based on conventional and swarm clustering methods. Sol. Energy 2016, 124, 39–56. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithms; Pearson Education India: Sholinganallur, India, 2006. [Google Scholar]
- Caglayan, D.G.; Heinrichs, H.U.; Robinius, M.; Stolten, D. Robust design of a future 100% renewable european energy supply system with hydrogen infrastructure. Int. J. Hydrogen. Energy 2021, 46, 29376–29390. [Google Scholar] [CrossRef]
- Radu, D.; Dubois, A.; Berger, M.; Ernst, D. Model Reduction in Capacity Expansion Planning Problems via Renewable Generation Site Selection. arXiv 2021, arXiv:2104.05792. [Google Scholar]
- Frysztacki, M.M.; Hörsch, J.; Hagenmeyer, V.; Brown, T. The strong effect of network resolution on electricity system models with high shares of wind and solar. Appl. Energy 2021, 291, 116726. [Google Scholar] [CrossRef]
- Validi, H.; Buchanan, A.; Lykhovyd, E. Imposing Contiguity Constraints in Political Districting Models. 2020. Available online: http://www.optimization-online.org/DB_HTML/2020/01/7582.html (accessed on 5 November 2021).
- Hoyer, S.; Hamman, J. Xarray: N-D labeled arrays and datasets in Python. J. Open Res. Softw. 2017, 5, 10. [Google Scholar] [CrossRef] [Green Version]
- Ryberg, D.S.; Heinrichs, H.; Robinius, M.; Stolten, D. RESKit-Renewable Energy Simulation Toolkit for Python. 2019. Available online: https://github.com/FZJ-IEK3-VSA/RESKit (accessed on 19 April 2020).
- Ryberg, D.; Robinius, M.; Stolten, D. Evaluating Land Eligibility Constraints of Renewable Energy Sources in Europe. Energies 2018, 11, 1246. [Google Scholar] [CrossRef] [Green Version]
- Hess, S.W.; Weaver, J.; Siegfeldt, H.; Whelan, J.; Zitlau, P. Nonpartisan political redistricting by computer. Oper. Res. 1965, 13, 998–1006. [Google Scholar] [CrossRef]
- Oehrlein, J.; Haunert, J.H. A cutting-plane method for contiguity-constrained spatial aggregation. J. Spat. Inf. Sci. 2017, 15, 89–120. [Google Scholar] [CrossRef]
- Ferreira, L.; Hitchcock, D.B. A comparison of hierarchical methods for clustering functional data. Commun. Stat. Simul. Comput. 2009, 38, 1925–1949. [Google Scholar] [CrossRef] [Green Version]
- Hoffmann, M.; Kotzur, L.; Stolten, D.; Robinius, M. A review on time series aggregation methods for energy system models. Energies 2020, 13, 641. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
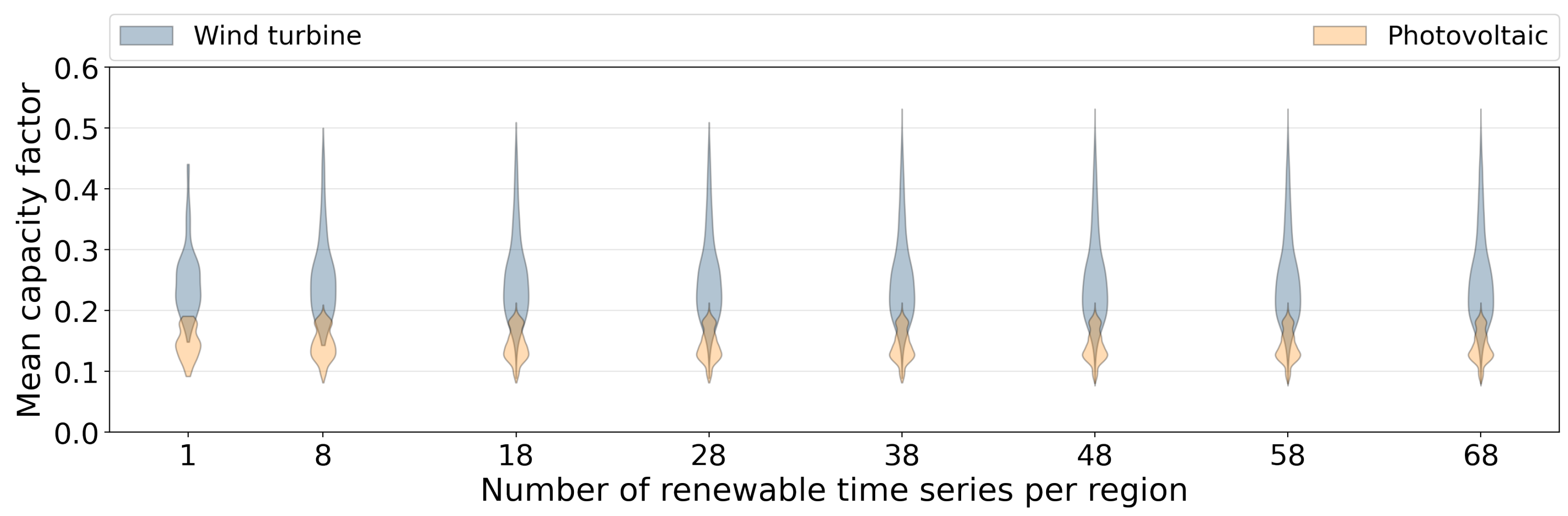{kind=link}
{kind=link}
{kind=link}
{kind=link}
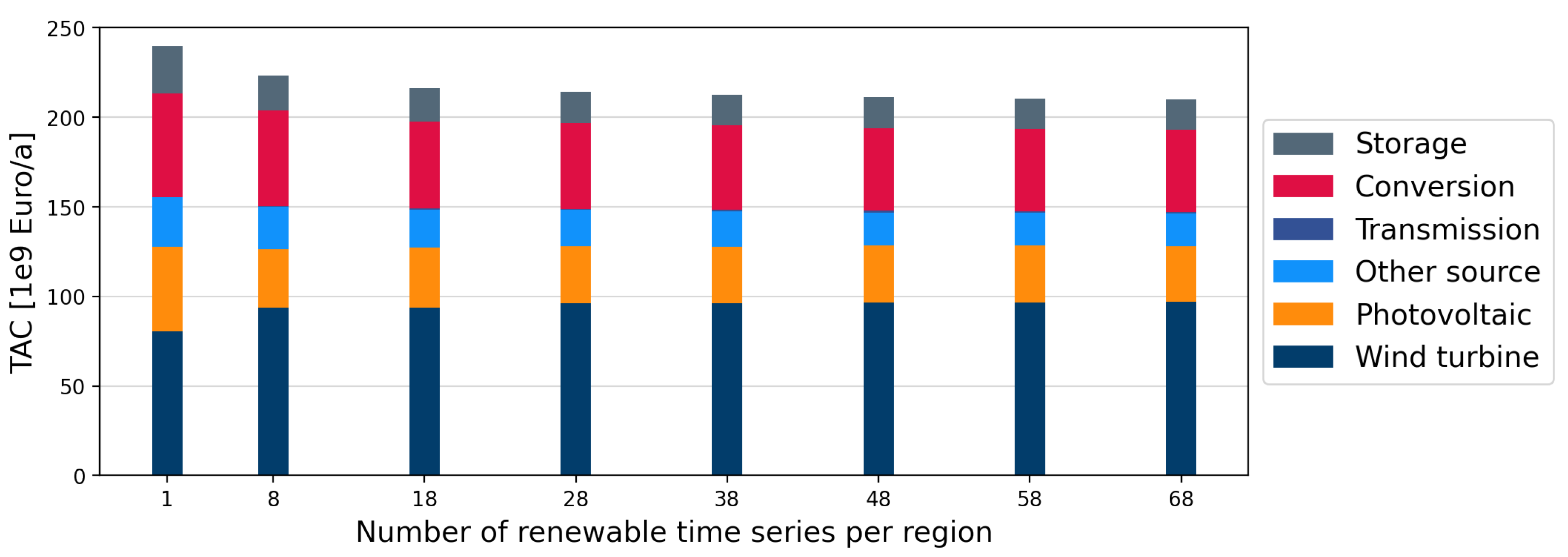{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Publication | Attributes Considered |
|---|---|
| [17] | Demand and generation capacities |
| Geographic locations of the regions | |
| [19] | Electrical distances between regions |
| [4] | Marginal costs of the total power supply |
| [23] | Energy potentials (e.g., wind, solar, agricultural residues potentials, etc.) |
| Economic (e.g., electricity and gas prices) | |
| Sociodemographic (e.g., population and GDP) | |
| Geographic locations of the regions | |
| [26] | Population |
| Mean wind speed and solar irradiation | |
| Installed thermal and hydro capacity | |
| Agricultural areas and natural grasslands, etc. | |
| Geographic locations of the regions | |
| [14] | Wind potential or photovoltaic potential or electricity demand |
| Publication | VRES Resolution Reduction Approach (within Each Region) |
|---|---|
| [5,11,12,14] | Simply aggregating all the generation sites |
| [35] | Clustering based on levelized cost of electricity (LCOE) of each generation site |
| [36] | Running a simplified version of the ESOM to identify relevant generation sites |
| [37] | Simply aggregating all the generation sites within subregion groups |
| Publication | One-Dimensional Regional Attributes Considered? | Two-Dimensional Regional Attributes Considered? | Two-Dimensional Connection Attributes Considered? | Spatial Contiguity Ensured? |
|---|---|---|---|---|
| [17,37] | ✓ | ✗ | ✗ | ✓ |
| [19] | ✗ | ✗ | ✓ | ✓ |
| [4] | ✓ | ✗ | ✗ | ✓ |
| [23] | ✓ | ✗ | ✗ | ✗ |
| [26] | ✓ | ✗ | ✗ | ✓ |
| [14] | ✓ | ✗ | ✗ | ✓ |
| This paper | ✓ | ✓ | ✓ | ✓ |
| Attribute | Aggregation Method |
|---|---|
| Maximum time series | Weighted mean |
| (weights: corresponding maximum capacity) | |
| Fixed time series | Sum |
| Maximum capacity | Sum |
| Fixed capacity | Sum |
| Locational eligibility | Boolean OR |
| Investment per capacity | Mean |
| Investment if built | Boolean OR |
| Opex per operation | Mean |
| Opex per capacity | Mean |
| Opex if built | Boolean OR |
| Interest rate | Mean |
| Economic lifetime | Mean |
| Losses | Mean |
| Distances | Mean |
| Commodity cost | Mean |
| Commodity revenue | Mean |
| Opex per charge operation | Mean |
| Opex per discharge operation | Mean |
| Technical lifetime | Sum |
| Reactances | Sum |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patil, S.; Kotzur, L.; Stolten, D. Advanced Spatial and Technological Aggregation Scheme for Energy System Models. Energies 2022, 15, 9517. https://doi.org/10.3390/en15249517
Patil S, Kotzur L, Stolten D. Advanced Spatial and Technological Aggregation Scheme for Energy System Models. Energies. 2022; 15(24):9517. https://doi.org/10.3390/en15249517
Chicago/Turabian StylePatil, Shruthi, Leander Kotzur, and Detlef Stolten. 2022. "Advanced Spatial and Technological Aggregation Scheme for Energy System Models" Energies 15, no. 24: 9517. https://doi.org/10.3390/en15249517