
Probabilistic Peak Demand Estimation Using Members of the Clayton Generalized Gamma Copula Family

Abstract
:1. Introduction
2. Copula Function
2.1. Inverse Compound Archimedean Copula
2.2. Clayton Generalized Gamma Family
3. Value-at-Risk of Electricity Demand
4. Statistical Process
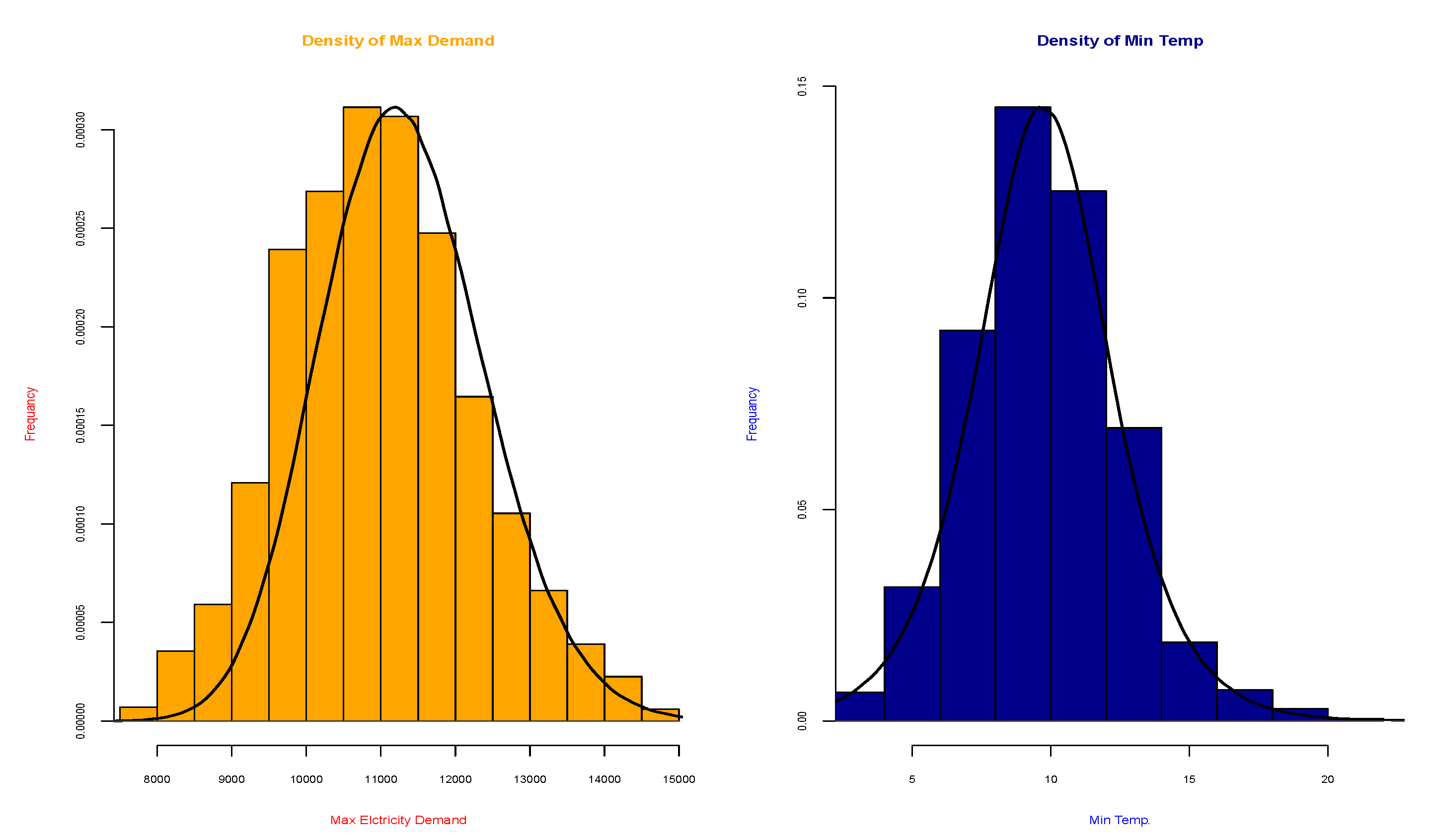
4.1. Identification of the Marginal Distributions
4.2. Estimation of the Parameters for Members of the CGG Family
4.3. Calculation of Confidence Intervals of Electricity Peak Demand
4.4. Finding the Best Copula Function
4.4.1. The Conditional Coverage Measure
4.4.2. Example
4.4.3. The Economic Cost Measure
5. Experiment with Real Data
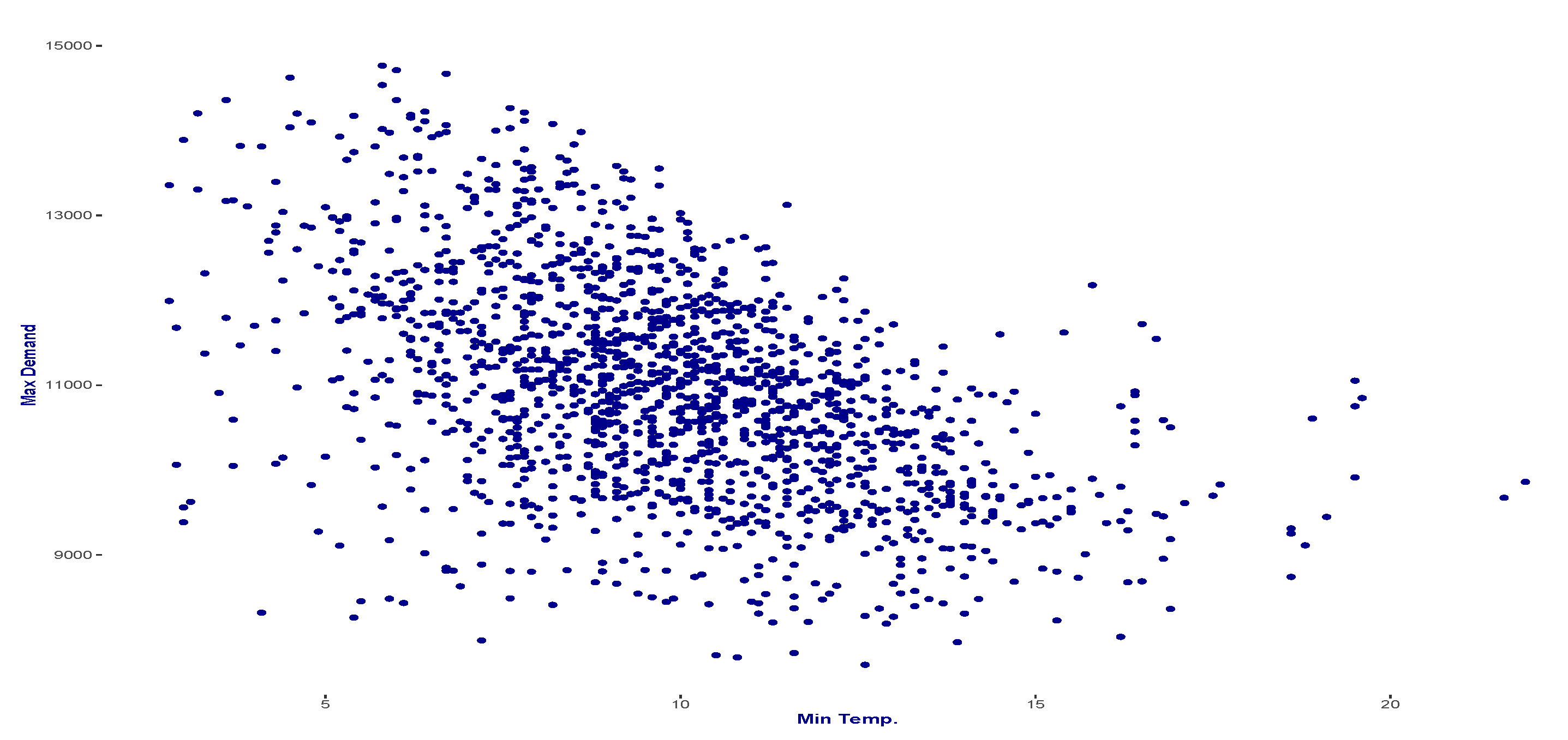
5.1. Data Description
5.2. The Experiment
5.3. Major Contributions
- ∗
- The confidence interval of the peak demand based on temperature was estimated, and a probabilistic copula family, the Clayton generalized Gamma, which is comprised of several copula functions and aims at characterizing the dependence structure, was suggested.
- ∗
- This innovative three-parameter family enhances flexibility in adjusting the dependence structure between peak demand and temperature, thus allowing a more accurate estimation of the former.
- ∗
- The superiority of the Clayton Gamma copula over other members of the Clayton generalized Gamma family, as well as popular one-dimensional copulas such as the Clayton and Gumbel copulas was demonstrated in the numerical study provided.
- ∗
- The proposed methodology significantly enriches the number of candidate copulas available for peak demand estimation and, thus, reduces the probability of unmet demand with its dramatic consequences.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ruth, M.; Lin, A.-C. Regional energy demand and adaptations to climate change: Methodology and application to the state of Maryland, USA. Energy Policy 2006, 34, 2820–2833. [Google Scholar] [CrossRef]
- Miller, N.L.; Hayhoe, K.; Jin, J.; Auffhammer, M.C. extreme heat, and electricity demand in California. J. Appl. Meteorol. Climatol. 2008, 6, 1834–1844. [Google Scholar] [CrossRef]
- Parkpoom, S.; Harrison, G.P.; Bialek, J.W. Climate change impacts on electricity demand. In Proceedings of the 39th International Universities Power Engineering Conference, Bristol, UK, 6–8 September 2004; pp. 1342–1346. [Google Scholar]
- Buys, L.; Vine, D.; Ledwich, G.; Bell, J.; Mengersen, K.; Morris, P.; Lewis, J.T. A framework for understanding and generating integrated solutions for residential peak energy demand. PLoS ONE 2015, 10, e0121195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Narayanan, A.; Morgan, M.G. Sustaining critical social services during extended regional power blackouts. Risk Anal. 2012, 32, 1183–1193. [Google Scholar] [CrossRef] [PubMed]
- Gerlak, A.K.; Weston, J.; McMahan, B.; Murray, R.L.; Mills-Novoa, M. Climate risk management and the electricity sector. Clim. Risk Manag. 2018, 19, 12–22. [Google Scholar] [CrossRef]
- Sachdev, M.S.; Billinton, R.; Peterson, C.A. Representative bibliography on load forecasting. IEEE Trans. Power Appar. Syst. 1977, 96, 697–700. [Google Scholar] [CrossRef]
- Hagan, M.T.; Behr, S.M. The time series approach to short term load forecasting. IEEE Trans. Power Syst. 1987, 2, 785–791. [Google Scholar] [CrossRef]
- Hong, T.; Fan, S. Probabilistic electric load forecasting: A tutorial review. Int. J. Forecast. 2016, 32, 914–938. [Google Scholar] [CrossRef]
- Emodi, N.V.; Chaiechi, T.; Alam, B. ABM Rabiul The impact of climate change on electricity demand in Australia. Energy Environ. 2018, 29, 1263–1297. [Google Scholar] [CrossRef]
- Auffhammer, M.; Baylis, P.; Hausman, C.H. Climate change is projected to have severe impacts on the frequency and intensity of peak electricity demand across the United States. Proc. Natl. Acad. Sci. USA 2017, 114, 1886–1891. [Google Scholar] [CrossRef] [Green Version]
- Debnath, K.B.; Mourshed, M. Forecasting methods in energy planning models. Renew. Sustain. Energy Rev. 2018, 88, 297–325. [Google Scholar] [CrossRef] [Green Version]
- Saman, T.; Ali, R. A novel probabilistic regression model for electrical peak demand estimate of commercial and manufacturing buildings. Sustain. Cities Soc. 2022, 77, 103544. [Google Scholar]
- Lee, G.-C. Regression-Based Methods for Daily Peak Load Forecasting in South Korea. Sustainability 2022, 14, 3984. [Google Scholar] [CrossRef]
- Fernández-Martínez, D.; Jaramillo-Morán, M.A. Multi-Step Hourly Power Consumption Forecasting in a Healthcare Building with Recurrent Neural Networks and Empirical Mode Decomposition. Sensors 2022, 22, 3664. [Google Scholar] [CrossRef]
- Lucas Segarra, E.; Ramos Ruiz, G.; Fernández Bandera, C. Probabilistic load forecasting for building energy models. Sensors 2020, 20, 6525. [Google Scholar] [CrossRef]
- Brusaferri, A.; Matteucci, M.; Spinelli, S.; Vitali, A. Probabilistic electric load forecasting through Bayesian Mixture Density Networks. Appl. Energy 2022, 309, 118–341. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Sanchez-Esguevillas, A.; Hernandez-Callejo, L.; Arribas, J.I.; Carro, B. Additive ensemble neural network with constrained weighted quantile loss for probabilistic electric-load forecasting. Sensors 2021, 21, 2979. [Google Scholar] [CrossRef]
- Ahmed Mohammed, A.; Aung, Z. Ensemble learning approach for probabilistic forecasting of solar power generation. Energies 2016, 9, 1017. [Google Scholar] [CrossRef]
- Sun, M.; Wang, Y.; Strbac, G.; Kang, C. Probabilistic peak load estimation in smart cities using smart meter data. IEEE Trans. Ind. Electron. 2018, 66, 1608–1618. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, T.; He, Y.; Li, H.; Sun, Z.; Baek, S. Modeling and forecasting short-term power load with copula model and deep belief network. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 3, 127–136. [Google Scholar] [CrossRef] [Green Version]
- Kelner, M.; Landsman, Z.; Makov, U.E. Fitting Compound Archimedean Copulas to Data for Modeling Electricity Demand. Int. J. Stat. Probab. 2021, 10, 1–20. [Google Scholar] [CrossRef]
- Bernards, R.; Morren, J.; Slootweg, H. Statistical modeling of load profiles incorporating correlations using Copula. In Proceedings of the 2017 IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT-Europe), Turin, Italy, 26–29 September 2017. [Google Scholar]
- Tian, S.; Huang, W.; Yan, T.; Yang, X.; Fu, Y. Electricity-heat-gas integrated demand response dependency assessment based on BOXCOX-Pair Copula model. IET Energy Syst. Integr. 2022, 4, 131–142. [Google Scholar] [CrossRef]
- Lin, S.; Liu, C.; Shen, Y.; Li, F.; Li, D.; Fu, Y. Stochastic Planning of Integrated Energy System via Frank-Copula Function and Scenario Reduction. IEEE Trans. Smart Grid 2021, 13, 202–212. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, X.; Trajcevski, G.; Zhang, K.; Zhong, T.; Zhou, F. PrEF: Probabilistic Electricity Forecasting via Copula-Augmented State Space Model; AAAI: Menlo Park, CA, USA, 2022. [Google Scholar]
- Chen, B.; Huang, W. Short-Term Load Forecasting Method Based on Copula Correlation Measurement Combined With Attention Mechanism. In Proceedings of the 2021 IEEE 4th International Electrical and Energy Conference (CIEEC), Wuhan, China, 28–30 May 2021. [Google Scholar]
- Ebrahimi, S.R.; Rahimiyan, M.; Assili, M.; Hajizadeh, A. Home energy management under correlated uncertainties: A statistical analysis through Copula. Appl. Energy 2022, 305, 117753. [Google Scholar] [CrossRef]
- Kelner, M.; Landsman, Z.; Makov, U.E. New Approach to Multivariate Archimedean Copula Generation. J. Stat. Plan. Inference, 2022; Under Review. [Google Scholar]
- Genest, C.; Favre, A.-C. Everything you always wanted to know about copula modeling but were afraid to ask. J. Hydrol. Eng. 2007, 12, 347–368. [Google Scholar] [CrossRef]
- Sklar, M. Fonctions de repartition an dimensions et leurs marges. Publ. Inst. Statist. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Joe, H. Multivariate Models and Multivariate Dependence Concepts, 1st ed.; CRC Press: Boca Raton, FL, USA, 1997. [Google Scholar]
- Kotz, S.; Drouet, D. Correlation and Dependence, 1st ed.; World Scientific: Singapore, 2001. [Google Scholar]
- Nelsen, R.B. An Introduction to Copulas, 1st ed.; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Kelner, M.; Landsman, Z.; Makov, U.E. Compound Archimedean Copulas. Int. J. Stat. Probab. 2021, 10, 126–139. [Google Scholar] [CrossRef]
- Silva, R.B.; Bourguignon, M.; Cordeiro, G.M. A new compounding family of distributions: The generalized Gamma power series distributions. J. Comput. Appl. Math. 2016, 303, 119–139. [Google Scholar] [CrossRef]
- Genest, C.; Nešlehová, J.; Ben Ghorbal, N. Spearman’s footrule and Gini’s Gamma: A review with complements. J. Nonparametric Stat. 2010, 22, 937–954. [Google Scholar] [CrossRef]
- Nelsen, R.B. Concordance and Gini’s measure of association. J. Nonparametric Stat. 1998, 9, 227–238. [Google Scholar] [CrossRef]
- Blomqvist, N. On a measure of dependence between two random variables. Ann. Math. Stat. 1950, 21, 593–600. [Google Scholar] [CrossRef]
- Genest, C.; Rivest, L.-P. Statistical inference procedures for bivariate Archimedean copulas. J. Am. Stat. Assoc. 1993, 88, 1034–1043. [Google Scholar] [CrossRef]
- Frees, E.W.; Valdez, E.A. Understanding relationships using copulas. N. Am. Actuar. J. 1998, 2, 1–25. [Google Scholar] [CrossRef]
- Durrleman, V.; Nikeghbali, A.; Roncalli, T. Which Copula Is the Right One; Researchgate: Berlin, Germany, 2020. [Google Scholar]
- Najafi, M.; Akhavein, A.; Akbari, A.; Dashtdar, M. Value of the lost load with consideration of the failure probability. Ain Shams Eng. J. 2021, 12, 659–663. [Google Scholar] [CrossRef]
- Van Der Welle, A.; Van Der Zwaan, B. An Overview of Selected Studies on the Value of Lost Load (VOLL); Energy Research Centre of the Netherlands (ECN): Petten, The Netherlands, 2007. [Google Scholar]
- Heinrich, C.; Ziras, C.; Jensen, T.V.; Bindner, H.W.; Kazempour, J. A local flexibility market mechanism with capacity limitation services. Energy Policy 2021, 156, 112335. [Google Scholar] [CrossRef]
- Schmalensee, R. Competitive Energy Storage and the Duck Curve. Energy J. 2022, 43. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Family | p | d | |
|---|---|---|---|
| Gamma | 1 | a | d |
| Standard Gamma | 1 | 1 | d |
| Wein | 1 | a | 4 |
| Nakagami | 2 | a | d |
| Half Normal | 2 | a | 1 |
| Folded Normal | 2 | 1 | |
| Rayleigh | 2 | a | 2 |
| Maxwell–Boltzmann | 2 | a | 3 |
| Wilson–Hilferty | 3 | a | |
| Weibull | p | a |
| Pearson’s Correlation | Spearman’s Rho | Gini’s Gamma | Kendall’s Tau | Blomqvist’s Beta |
|---|---|---|---|---|
| Variable | Distribution | Kolmogorov–Smirnov | Anderson–Darling | p Value |
|---|---|---|---|---|
| X | Gamma | |||
| Y | Logistic |
| Family | p | a | d |
|---|---|---|---|
| Gamma | 1 | ||
| Standard Gamma | 1 | 1 | |
| Wien | 1 | 4 | |
| Nakagami | 2 | ||
| Half Normal | 2 | 1 | |
| Folded Normal | 2 | 1 | |
| Rayleigh | 2 | 2 | |
| Maxwell–Boltzmann | 2 | 3 | |
| Wilson–Hilferty | 3 | ||
| Weibull | 10 |
| Family | ||
|---|---|---|
| Gamma | ||
| Standard-Gamma | ||
| Wien | ||
| Nakagami | ||
| Half Normal | ||
| Folded Normal | ||
| Rayleigh | ||
| Maxwell–Boltzmann | ||
| Wilson–Hilferty | ||
| Weibull | ||
| Clayton | ||
| Gumbel |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kelner, M.; Landsman, Z.; Makov, U.E. Probabilistic Peak Demand Estimation Using Members of the Clayton Generalized Gamma Copula Family. Energies 2022, 15, 6081. https://doi.org/10.3390/en15166081
Kelner M, Landsman Z, Makov UE. Probabilistic Peak Demand Estimation Using Members of the Clayton Generalized Gamma Copula Family. Energies. 2022; 15(16):6081. https://doi.org/10.3390/en15166081
Chicago/Turabian StyleKelner, Moshe, Zinoviy Landsman, and Udi E. Makov. 2022. "Probabilistic Peak Demand Estimation Using Members of the Clayton Generalized Gamma Copula Family" Energies 15, no. 16: 6081. https://doi.org/10.3390/en15166081