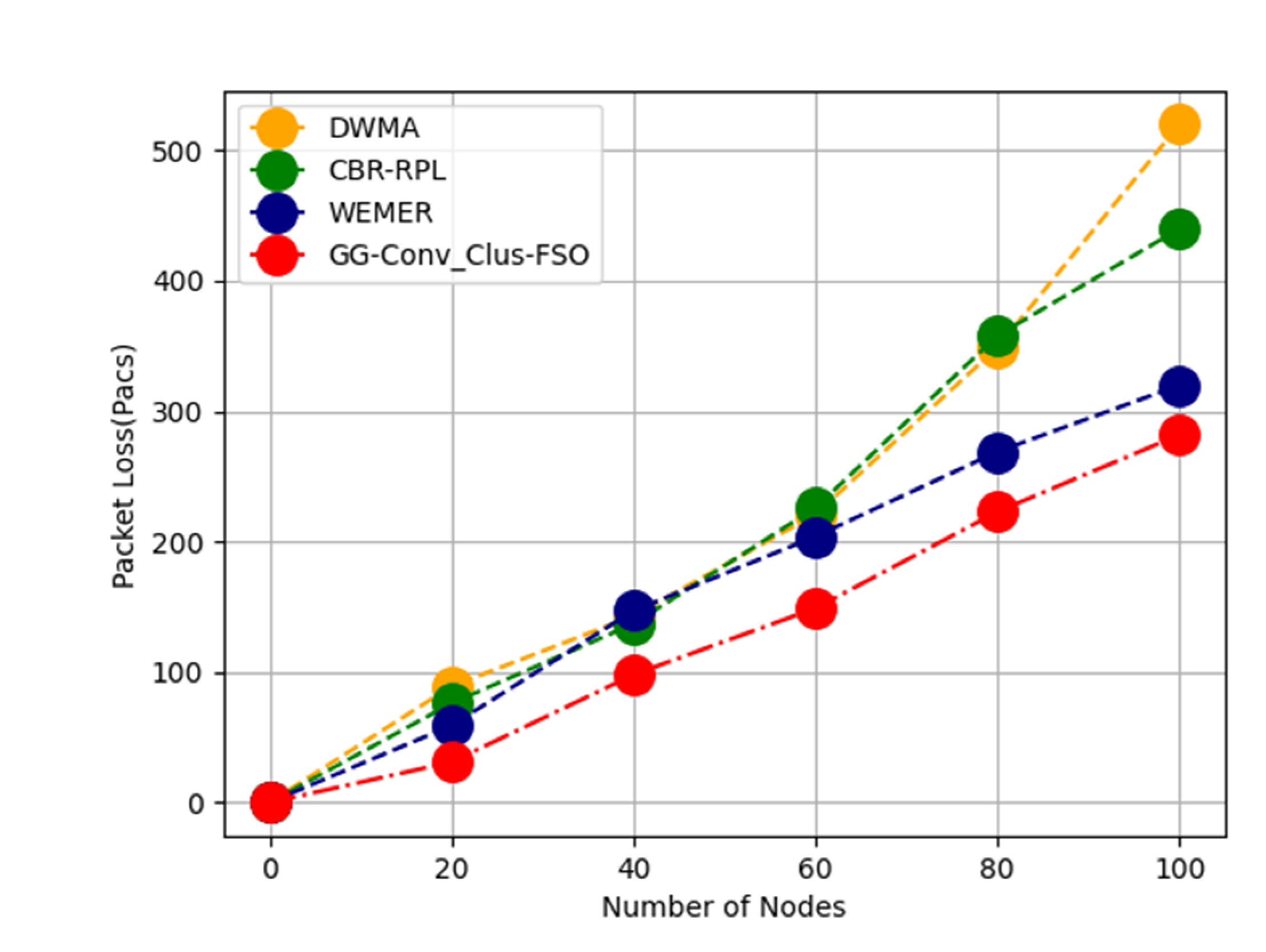
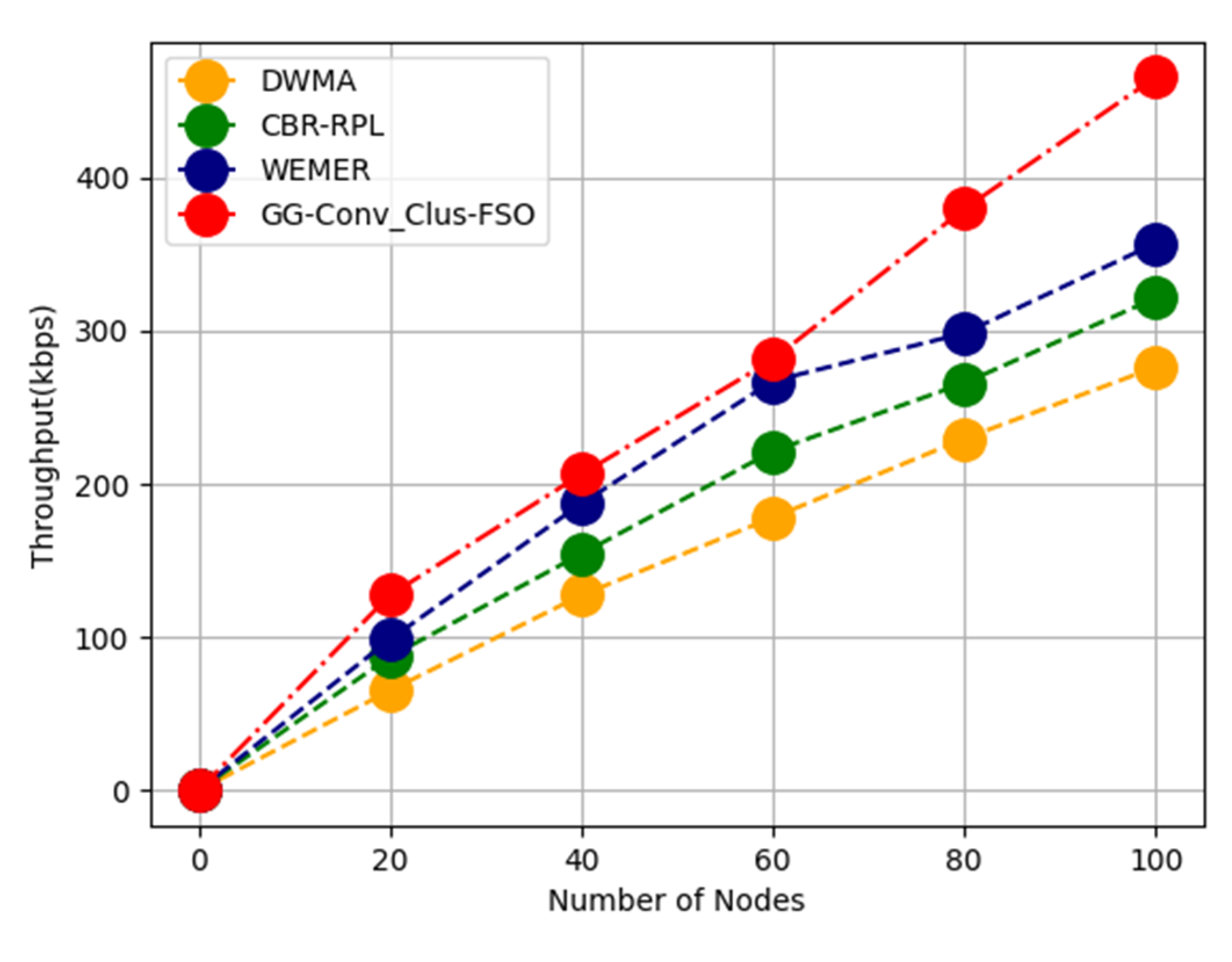
Grid cells of equal length are used to partition the whole network. Every grid cell represents the square territory. Every grid cell has only static nodes. The Sink can be either stationary or moveable for gathering data. The grid cell CH is the one that is closest to the mid-point of the grid cell. Every grid cell has a node ID as well as an associated grid ID that identifies nodes. The sink is responsible for the initial cluster setup, which includes calculating node IDs and grid IDs, establishing the CH for each grid cell and scheduling data transmission and reception for nodes in the grid cells. The GG-Conv_Clus-FSO protocol uses double disjoint anchor group nodes for packet forwarding, and node nomination is based on the clustering method. To locate holes quickly, a grid-based hole identification method is utilised. Data packets are accurately routed to the anchor and destination nodes while consuming the least amount of energy.
Grid Formation
The whole network is divided into equal-sized rectangle-shaped grid cells. Each grid keeps track of the exact location of each cell relative to its border, which is subsequently used to determine the size of the holes. In this,
Da ×
Db denotes the grid cell dimension where the length is determined by
Da and width is determined by X
b. Equation (1) [
31] indicates the grid cell generation process. The grid-building procedure is completed by
where the count of a horizontal line is indicated by g, and the count of the vertical line is indicated by r. The process of grid construction is given in Algorithm 1.
| Algorithm 1: Construction of Grid |
| for g = 0 to p = s |
| for r = 0 to r = t |
| |
| end for |
| end for |
Selection of Cluster Head (CH): In the actual world, fish can identify nutrient-rich places by searching on their own or by swimming near other fish; the region with the most fish often has the most nutrition. Artificial fish swarm optimization (AFSO) is based on mimicking fish behaviour, such as preying, swarming and tracking local fish hunts to attain global optima. The solution space and the states of other artificial fishes are generally the areas where an Artificial Fish (AF) dwells. The subsequent behaviour is determined by the current state as well as the immediate environment, such as the current quality of query responses and the status of nearby neighbours. The movements of an artificial fish, as well as the actions of its neighbours, have an impact on the ecosystem. If fish are discovered in a water area with more food, they will migrate quickly to that area. Equation (2) may be used to describe this behaviour.
During preying mode, fish behaviour is represented by Equation (3):
where rand is the random function with range [0, 1].
The behaviour of the swarm is represented in Equation (4)
In the follow stage, behaviour is given by equation
The three processes outlined above guarantee that both global and local searches are conducted, as well as a search direction that leads to the greatest food source. The suggested approach differs from the AFSA in two significant ways. The solutions are split at random and behave in one of two ways: swarming or following. The best fish are chosen via tournament selection, and preying processing begins. Fish who are very good at preying are chosen and allowed to breed amongst themselves. The best fish and the new solution are carried to the next iteration. The answers are represented as binary numbers in this study, and the distance between fish is calculated utilizing Hamming distance. The number of locations where two strings u and v differ is the hamming distance between them. The best fish are chosen by spinning the roulette wheel. The likelihood of a fish being picked on a roulette wheel is exactly proportional to its fitness. Equation (6) computes the probability of a fish,
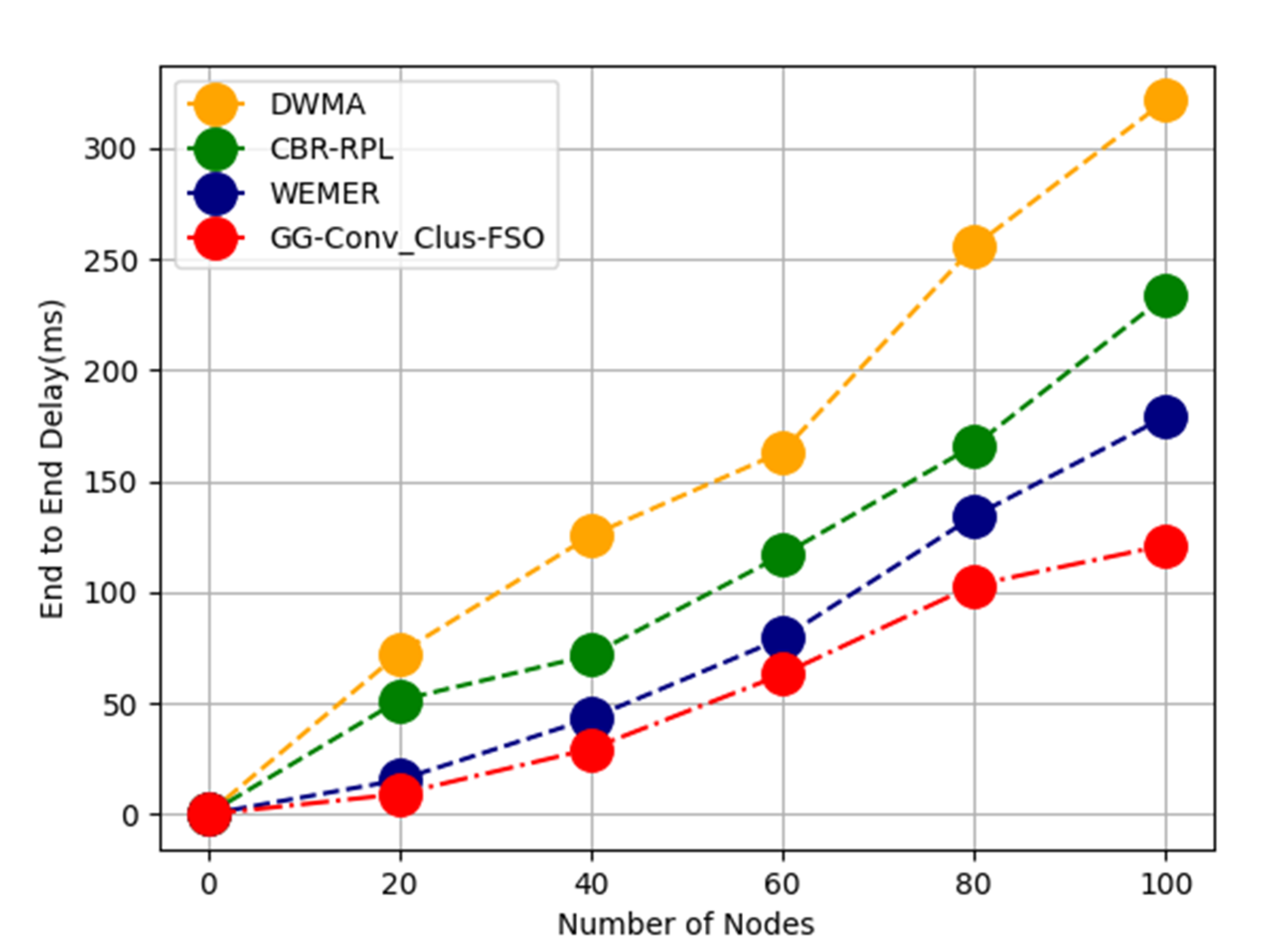
To enhance QOS, a multi-objective function based on E2E delay as well as energy is proposed and represented by Equation (7):
where
dri is the E2E delay,
Dtd is the total delay to reach BS,
Dm is the maximum delay,
Eri is the remaining energy in CH and
Ei is the initial energy.
Subsequent assumptions are made:
The nodes in the network are distributed arbitrarily;
Starting energy of every node is the similar;
In ecology, all fishes are unisex;
Because fish are unisexual, mating among any two fish is feasible;
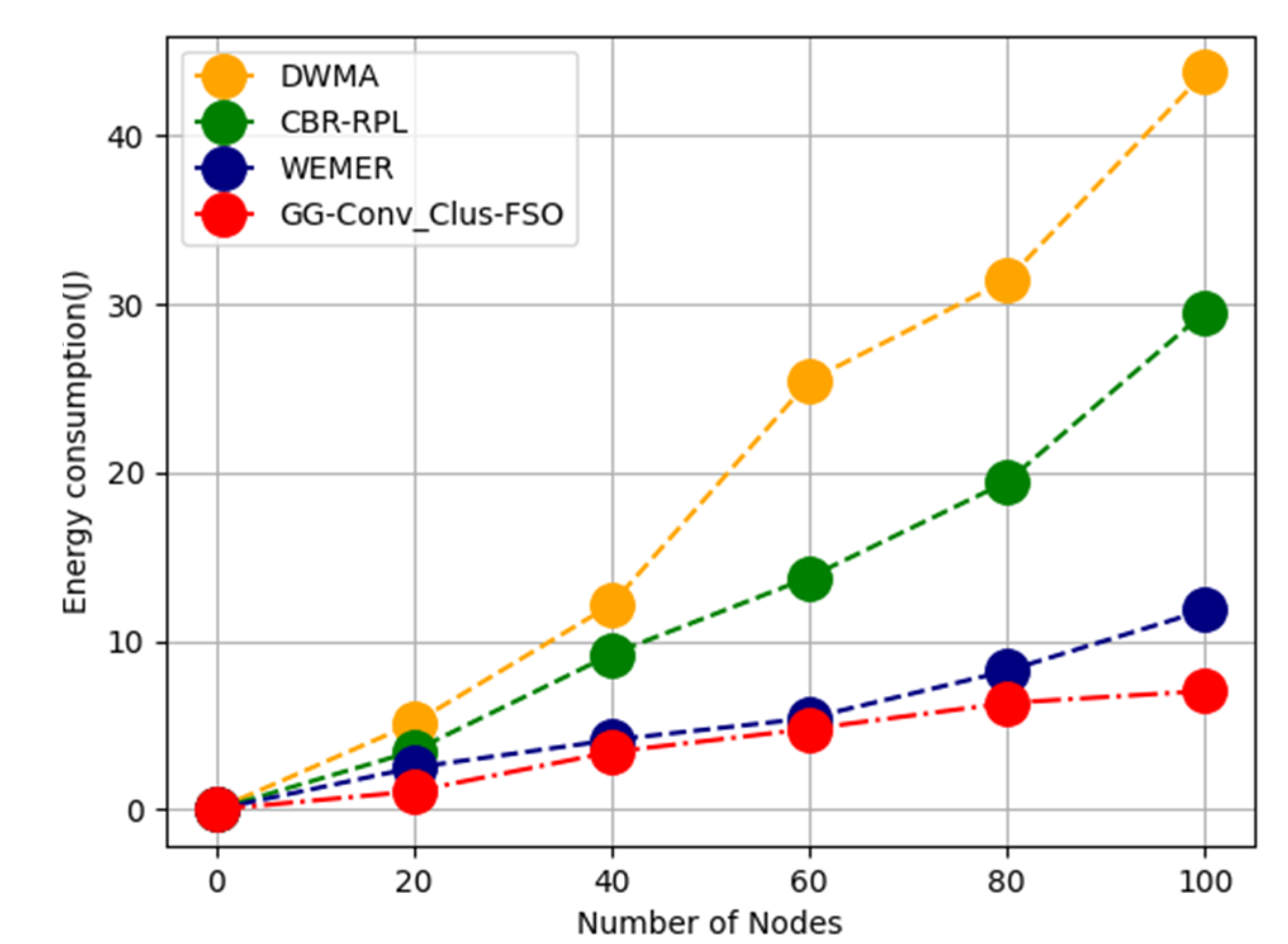
Because the free space radio method is utilised, the energy needed to transmit one bit of data grows as distance improves.
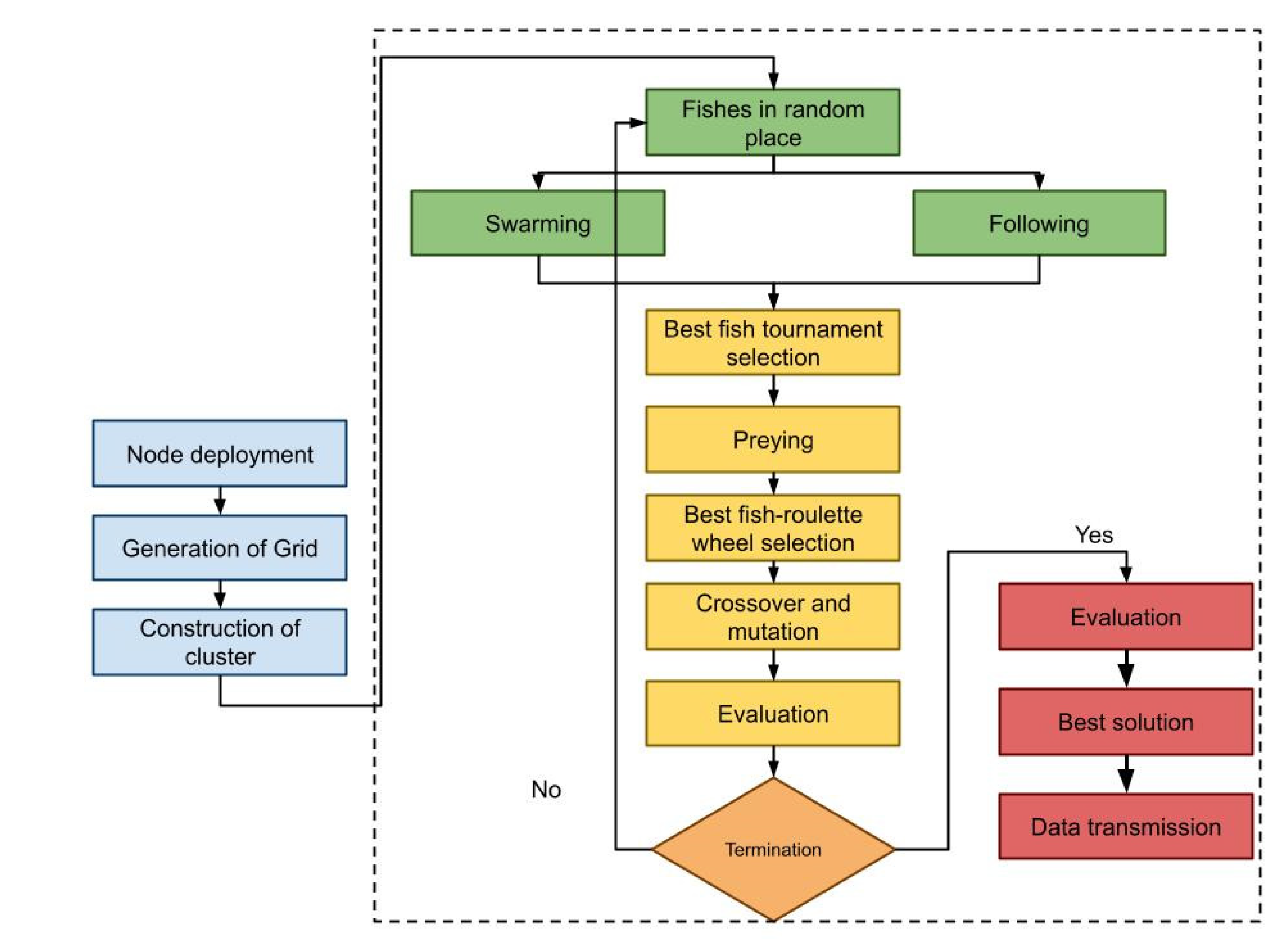
The flowchart for FSO-based CH selection is shown in
Figure 1. Because solution space is binary, a transfer function is required to fill the bit as the fish swims. In this paper, a novel transfer function for flipping the bits described by Equation (8) is,
To attain flipping, a random number between 0 and 1 is generated, and if the random number is less than the transfer function provided by Equation (8), the bit is flipped.
Hole Detection: The grid hole is found by comparing the cell coordinates to SNs radius as well as closest count (SN). SN count is closer to the sensor’s radius, which is used to determine the hole’s coverage area. The region in which a hole has developed is said to be
Bi. Equations (10) and (11) show the position of the hole in the cell and the grid.
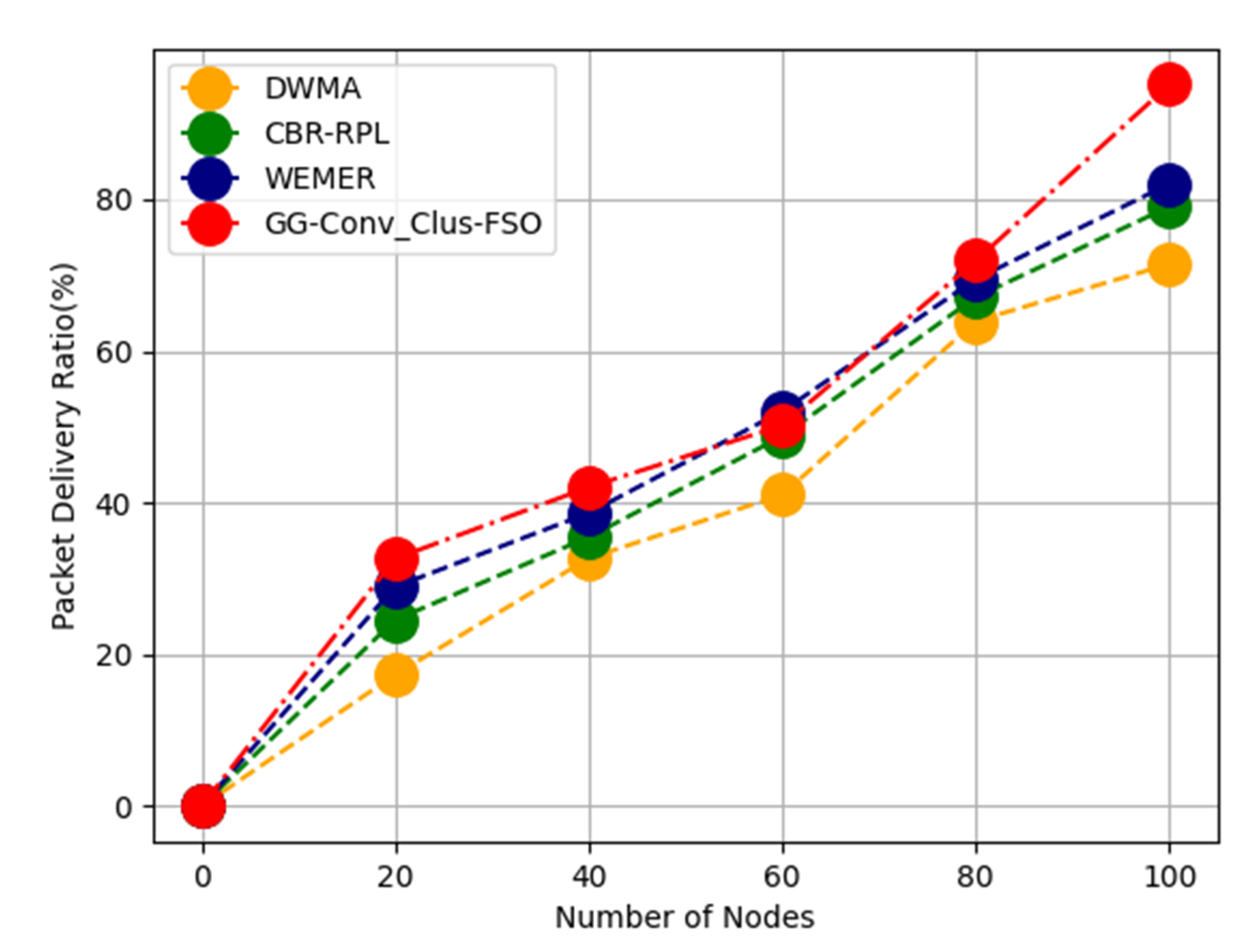
Data propagation across selected CH: Send data around the borders of the hole and transfer it to the correct location. The sensor nodes in the region are clustered, and the CH is selected as the node closest to the grid’s centre. In the GBC-SS, the Static Sink is in charge of coordination, whereas in the GBC-MS, Mobile Sink is in charge of data gathering. The information is transmitted to nearby sensor nodes, and the position is recorded for future data transfer.
where the density is indicated by
, the transmission rate of data is characterized by a dot and the determined location is shown as
gl.
is the definition of an undirected and connected graph, where V and E are finite sets of V = N vertices and edges, and is an adjacency matrix. The graph signals are represented by numerous variables in each vertex. The description indices are represented by the vertex variables in this study. The graph is given by its Laplacian matrix L, which is defined as , where is the degree matrix created by degrees of vertex i. represented as with corresponding nonnegative eigenvalues . Laplacian matrix L, is diagonalized by the eigenvector matrix so that , where is the diagonal eigenvalue matrix. is a normalised version [1, 1].
Instead of complex exponentials, the eigenvectors of the Laplacian matrix L that meet the orthogonality criterion are employed as decomposition bases for graph-structured data. On a graph, the Fourier transform of a given signal f(n) is defined as Equation (15):
Inverse Fourier transformation is represented by Equation (16):
Convolution is turned into a point-wise product in the Fourier domain as well as reconverted into the vertex domain utilizing the graph Fourier transform as well as the convolution theorem, as in Equation (17):
A convolution kernel is the graph convolution operation of two graph signals,
f(n) and
g(n), and its transform,
. A set of free parameters in the Fourier domain, i.e., Laplacian eigenspace, is used to construct this kernel. Convolution is then written as Equation (18):
as an eigenvalue polynomial function: As illustrated in Equation (19), a rapid localised convolution based on low-order polynomial approximation was proposed:
which
is the polynomial order, and
Ki is a vector of polynomial coefficients.
K is a tiny positive integer, such as 3, for example. Convolution is then rewritten as Equation (20):
The convolution is performed by K multiplications of the sparse matrix L, which speeds up computation by avoiding the composition procedure.
The following is the updated version of Equation (21) for layer
l:
where
with
relates the number of attention heads, and where
H denotes the number of heads. Note that
h l i is
i-th node’s feature at
l-th layer in Equation (22).
where
is
k-th set of a given graph,
indicates the remaining sets, except
, and
is the edge between vertices
and
. When referring to multiple sets, the cut issue is represented as Equation (23):
The issue of less cuts is extensively studied in the literature in Equation (24):
where
is the total degree of nodes from
in graph
. The normalised cut problem utilizing DL optimisation, transforming the minimum cut issue into a DL format, as in Equation (25):
A is the adjacency matrix, and, finally, Γ is evaluated by Equation (26):
where (·) relates a non-linear activation function, e.g., ReLU (·) max(0, ·) = ; Hi [ ]l indicates ith input graph;
ijk, and
bj [ ]
l are trainable F F in out × vector of K-order polynomial coefficients and 1 × Fout vector of bias in
l th layer.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}