
Forecasting of Wind and Solar Farm Output in the Australian National Electricity Market: A Review


Abstract
:1. Introduction
2. Forecasting Methods
3. Point Forecasting
- Though machine learning techniques are used a lot (note that they include ANN as an ML technique), deep learning techniques have not been utilised as much.
- Very short term, very long term and regional forecasting are subjects that are not covered well.
- Most artificial intelligence (AI) methods work well on sunny days but poorly on cloudy ones.
- Hybrid models work best.
4. Interval Forecasting
5. Ramp Forecasting
- Start with 24 h ahead forecasts that combine NWP forecasts with hour ahead forecasts.
- Add persistence forecasts and use the random forecast procedure to produce better forecasts.
- Add in the ramp rate, which is the forecast for the present hour minus the actual for the previous hour.
- Use a random forecast technique on this augmented set of forecasts.
6. Synthetic Solar Time Series
- State 1—1–21 MJ/m2. Class Mark 10.
- State 2—21–30 MJ/m2. Class Mark 25.
- State 3—30–35 MJ/m2. Class Mark 33.
- Select a random number r in using a random number generator.
- If , then the initial state is 1 and the initial solar irradiation value is 10 MJ/m2.
- If , then the initial state is 2 and the initial solar irradiation value is 25 MJ/m2.
- Otherwise, the initial state is 3 and the initial solar irradiation value is 33 MJ/m2.
- So, let us assume , so we start in state 2, in this experiment.
- Then select randomly from .
- Assume that , so we transition to state 3.
- Then select , so we transition to state 2.
- Repeat as long as is needed.
7. Additional Considerations for Wind and Solar Farms
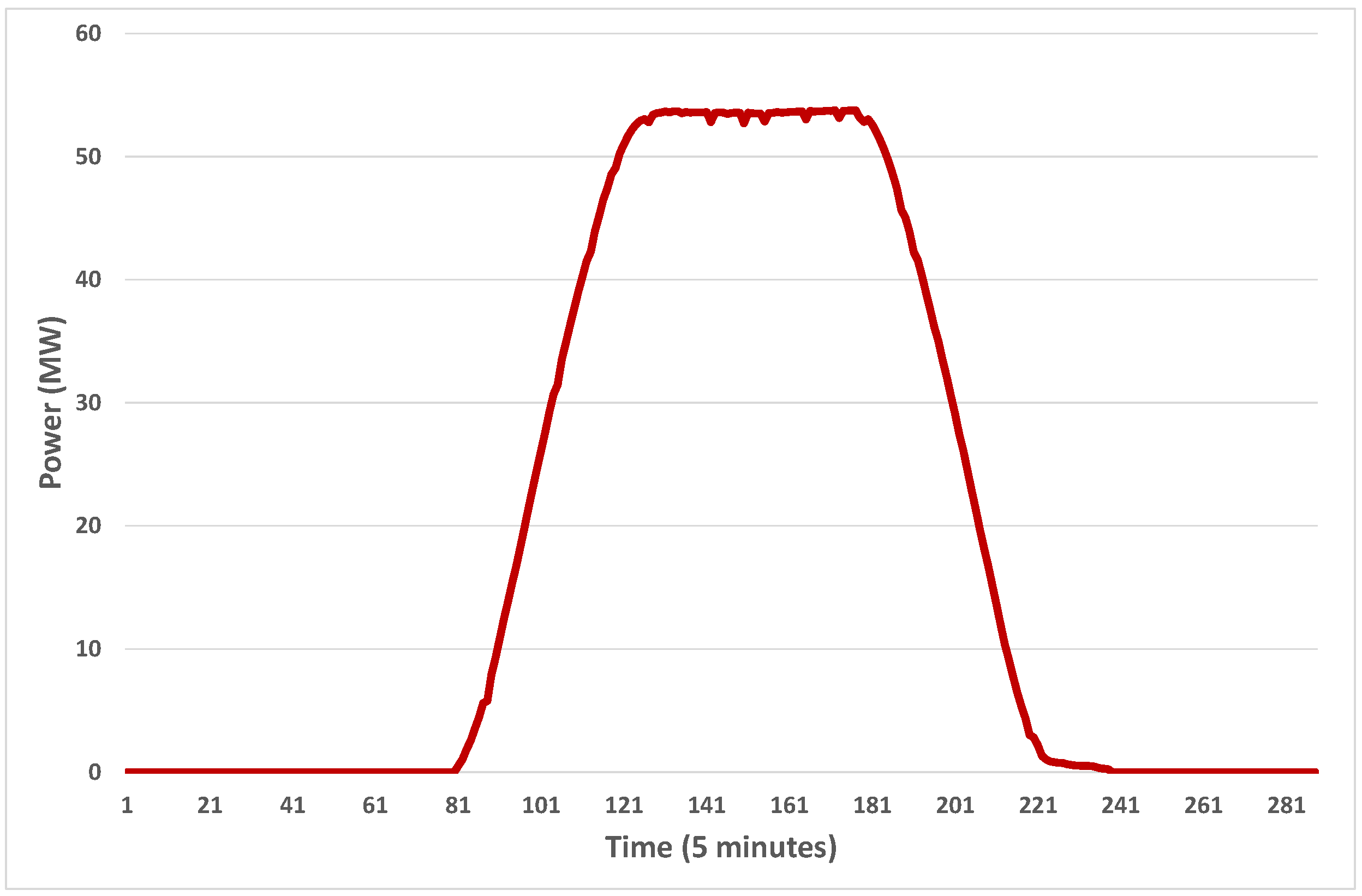
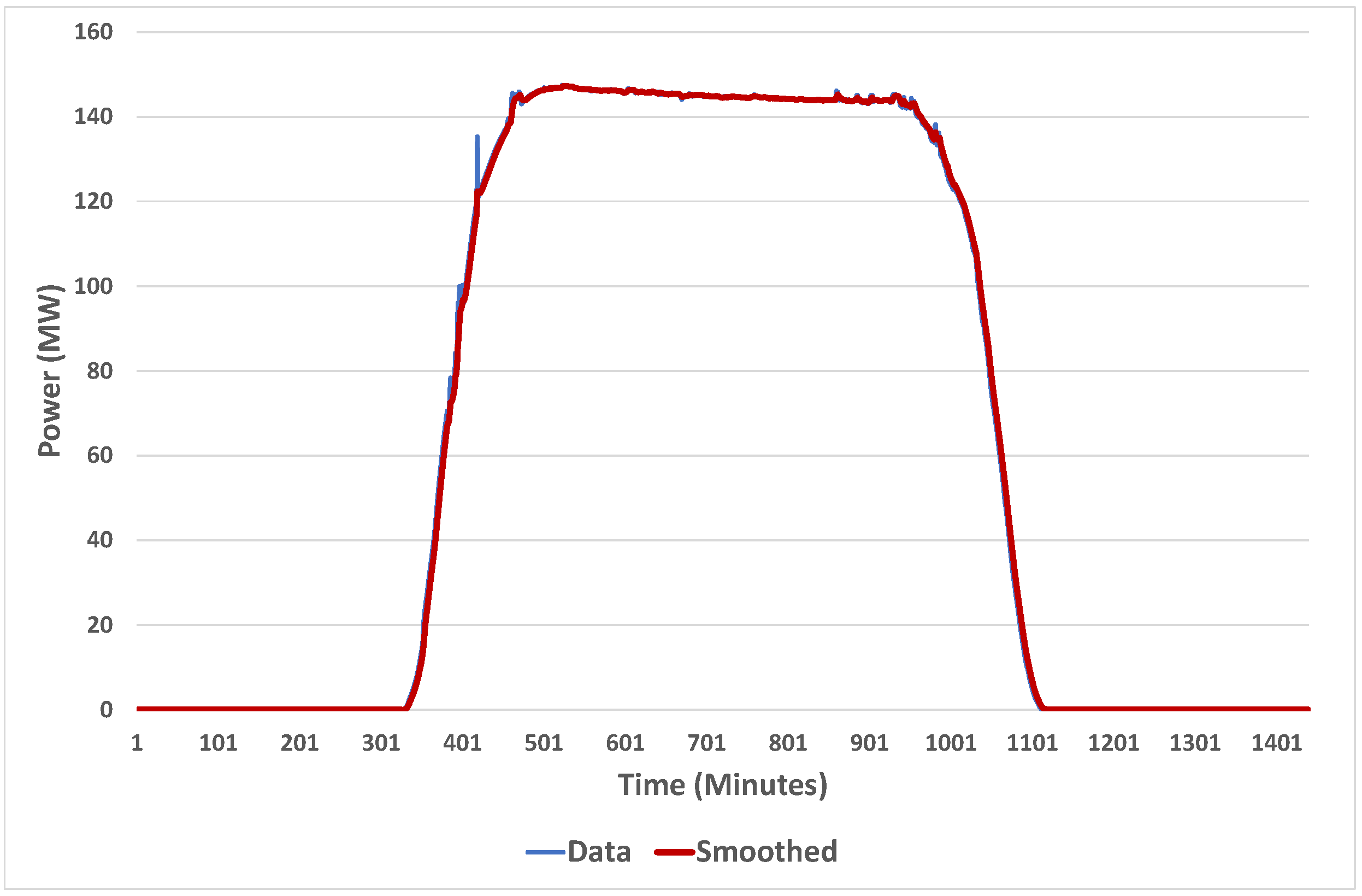
7.1. Characteristics of Power Output
7.2. Value of Forecasts
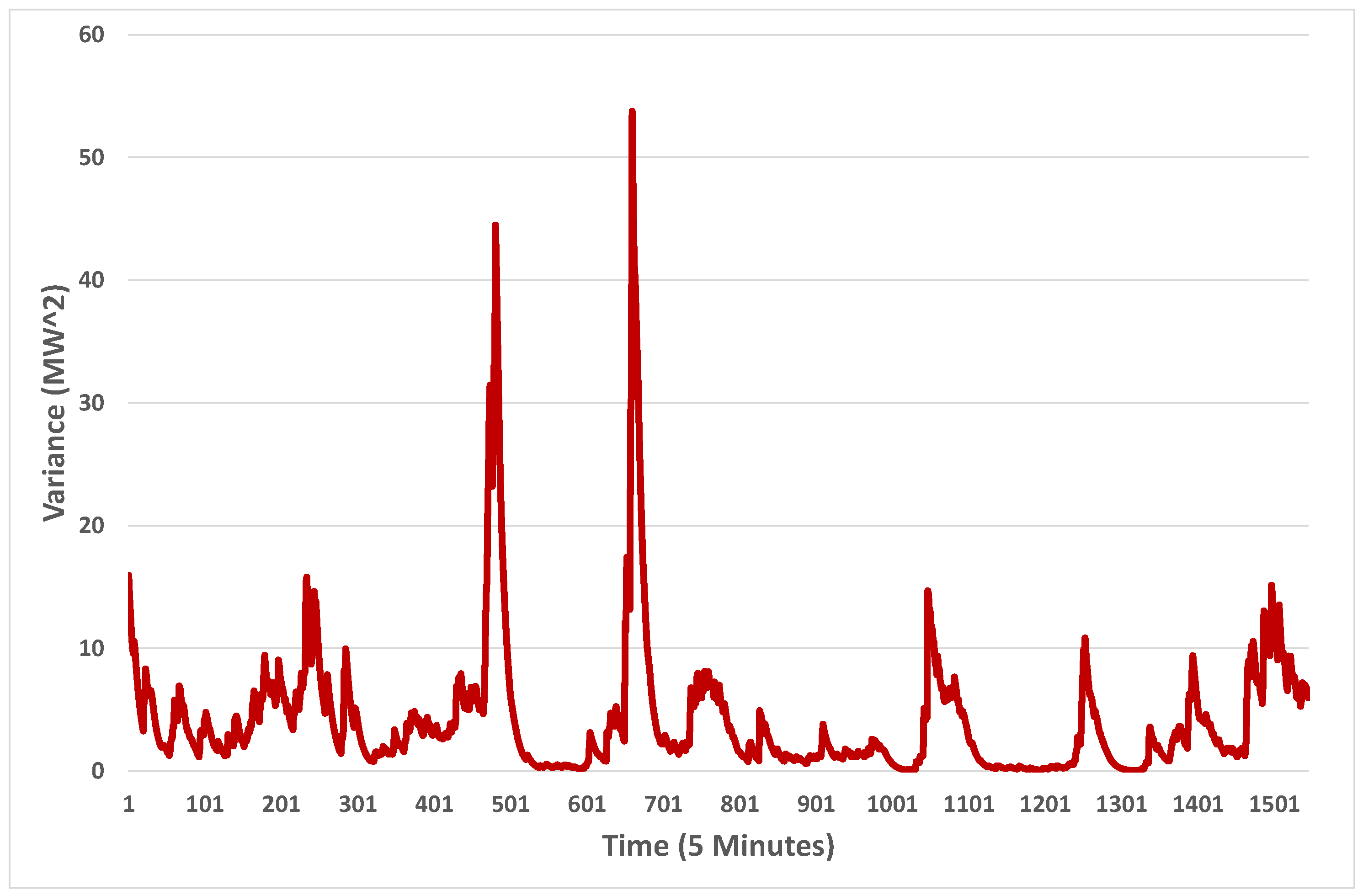
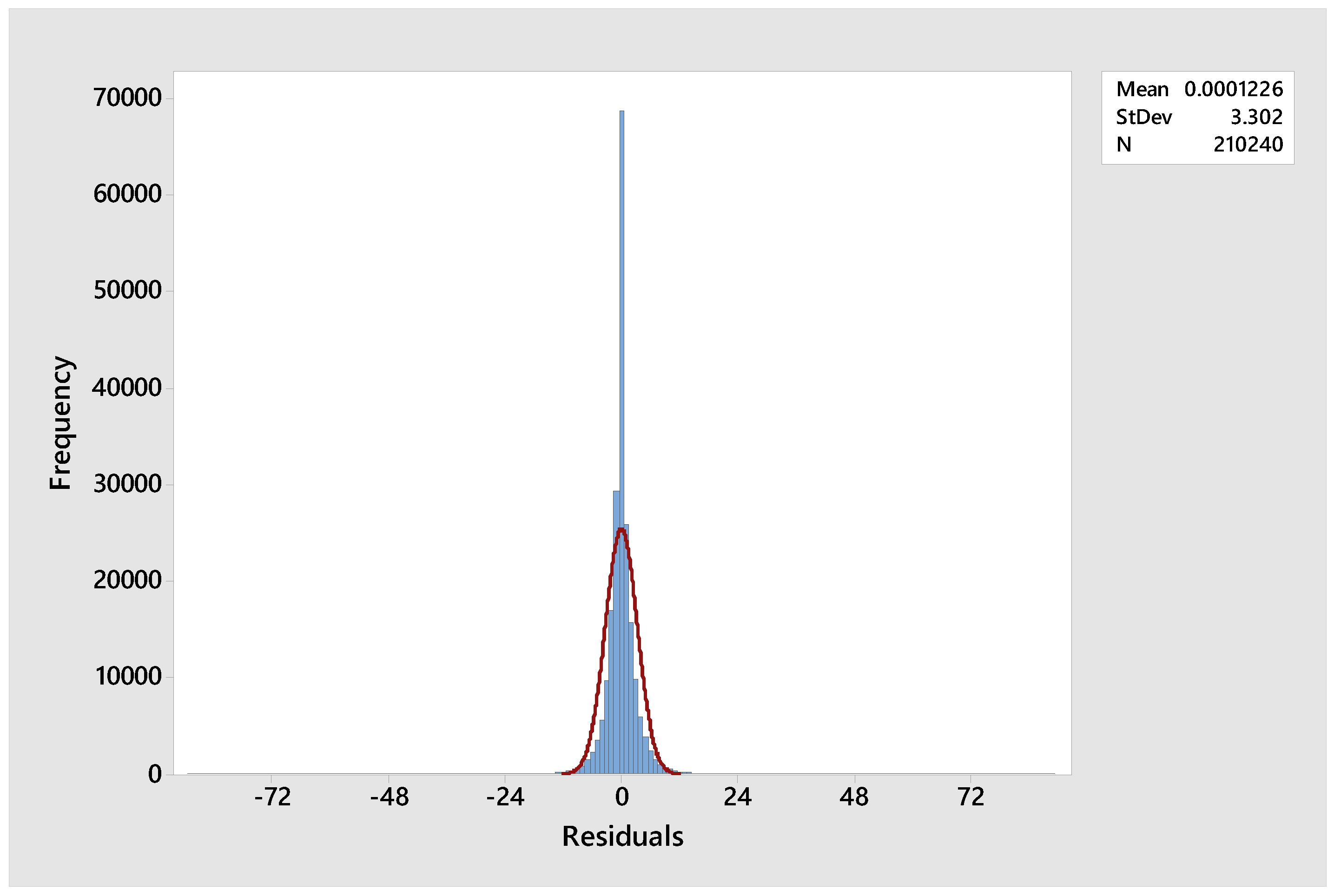
7.3. Heterogeneity of Variance
8. Conclusions
- Clear sky output from solar farms, as compared to clear sky models for solar irradiation.
- Heterogeneity of solar and wind farm output.
- The value of forecasting, as compared to the skill of forecasting.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AWEFS | Australian Wind Energy Forecasting System |
| ASEFS | Australian Solar Energy Forecasting System |
| FCAS | Frequency Control and Ancillary Services |
| NEM | Australian National Electricity Market |
| CSM | Clear Sky Model |
| CSI | Clear Sky Index |
| CSO | Clear Sky Output |
| CSOI | Clear Sky Output Index |
| AEMO | Australian Renewable Energy Agency |
| SPEF | Solar Power Ensemble Forecaster |
| ARMA | Autoregressive Moving Average |
| ANN | Artificial Neural Network |
| LSTM | Long Short Term Memory |
| RCC | Radiation classification coordinate |
| NWP | Numerical Weather Prediction |
| ARENA | Australian Renewable Energy Agency |
| RIS | AEMO Renewable Integration Study |
| SCADA | Supervisory Control and Data Acquisition |
| UIGF | Unconstrained Intermittent Generation Forecasts |
| EWMA | Exponentially Weighted Moving Average |
| EWMV | Exponentially Weighted Moving Variance |
| RMSE | Root mean square error |
| MAE | Mean absolute error |
| MBE | Mean bias error |
| SS | Skill score |
Appendix A. Error Measures
Appendix A.1. Root Mean Square Error
Appendix A.2. Mean Absolute Error
Appendix A.3. Mean Bias Error
Appendix A.4. Skill Score
References
- Diagne, M.; David, M.; Lauret, P.; Boland, J.; Schmutz, N. Review of solar irradiance forecasting methods and a proposition for small-scale insular grids. Renew. Sustain. Energy Rev. 2013, 27, 65–76. [Google Scholar] [CrossRef] [Green Version]
- Farah, S.; Boland, J. Time series model for real-time forecasting of Australian photovoltaic solar farms power output. J. Renew. Sustain. Energy 2021, 13, 046102. [Google Scholar] [CrossRef]
- Boland, J.; Farah, S. Probabilistic forecasting of wind and solar farm output. Energies 2021, 14, 5154. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Congedo, P.M.; Malvoni, M. Photovoltaic power forecasting using statistical methods: Impact of weather data. IET Sci. Meas. Technol. 2014, 8, 90–97. [Google Scholar] [CrossRef]
- Reikard, G. Predicting solar radiation at high resolutions: A comparison of time series forecasts. Sol. Energy 2009, 83, 342–349. [Google Scholar] [CrossRef]
- Durrani, S.P.; Balluff, S.; Wurzer, L.; Krauter, S. Photovoltaic yield prediction using an irradiance forecast model based on multiple neural networks. J. Mod. Power Syst. Clean Energy 2018, 6, 255–267. [Google Scholar] [CrossRef]
- De Giorgi, M.G.; Congedo, P.M.; Malvoni, M.; Laforgia, D. Error analysis of hybrid photovoltaic power forecasting models: A case study of mediterranean climate. Energy Convers. Manag. 2015, 100, 117–130. [Google Scholar] [CrossRef]
- Rana, M.; Koprinska, I.; Agelidis, V.G. Univariate and multivariate methods for very short-term solar photovoltaic power forecasting. Energy Convers. Manag. 2016, 121, 380–390. [Google Scholar] [CrossRef]
- Nespoli, A.; Ogliari, E.; Leva, S.; Massi Pavan, A.; Mellit, A.; Lughi, V.; Dolara, A. Day-Ahead Photovoltaic Forecasting: A Comparison of the Most Effective Techniques. Energies 2019, 12, 1621. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Korolkiewicz, M.; Agrawal, M.; Boland, J. Forecasting solar radiation on an hourly time scale using a Coupled AutoRegressive and Dynamical System (CARDS) model. Sol. Energy 2013, 87, 136–149. [Google Scholar] [CrossRef]
- Huang, J.; Boland, J. Performance Analysis for One-Step-Ahead Forecasting of Hybrid Solar and Wind Energy on Short Time Scales. Energies 2018, 11, 1119. [Google Scholar] [CrossRef] [Green Version]
- Colak, I.; Yesilbudak, M.; Genc, N.; Bayindir, R. Multi-period Prediction of Solar Radiation Using ARMA and ARIMA Models. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 1045–1049. [Google Scholar] [CrossRef]
- Boland, J.; David, M.; Lauret, P. Short term solar radiation forecasting: Island versus continental sites. Energy 2016, 113, 186–192. [Google Scholar] [CrossRef]
- Fernandez-Jimenez, L.A.; Muñoz-Jimenez, A.; Falces, A.; Mendoza-Villena, M.; Garcia-Garrido, E.; Lara-Santillan, P.M.; Zorzano-Alba, E.; Zorzano-Santamaria, P.J. Short-term power forecasting system for photovoltaic plants. Renew. Energy 2012, 44, 311–317. [Google Scholar] [CrossRef]
- Chu, Y.; Urquhart, B.; Gohari, S.M.I.; Pedro, H.T.C.; Kleissl, J.; Coimbra, C.F.M. Short-term reforecasting of power output from a 48 MWe solar PV plant. Sol. Energy 2015, 112, 68–77. [Google Scholar] [CrossRef]
- Yang, D.; Alessandrini, S.; Antonanzas, J.; Antonanzas-Torres, F.; Badescu, V.; Beyer, H.G.; Blaga, R.; Boland, J.; Bright, J.M.; Coimbra, C.F.; et al. Verification of deterministic solar forecasts. Sol. Energy 2020, 210, 20–37. [Google Scholar] [CrossRef]
- Grantham, A.; Gel, Y.; Boland, J. Nonparametric short-term probabilistic forecasting for solar radiation. Sol. Energy 2016, 133, 465–475. [Google Scholar] [CrossRef]
- Ni, Q.; Zhuang, S.; Sheng, H.; Kang, G.; Xiao, J. An ensemble prediction intervals approach for short-term PV power forecasting. Sol. Energy 2017, 155, 1072–1083. [Google Scholar] [CrossRef]
- Boland, J.; Grantham, A. Nonparametric Conditional Heteroscedastic Hourly Probabilistic Forecasting of Solar Radiation. J 2018, 1, 174–191. [Google Scholar] [CrossRef] [Green Version]
- Golestaneh, F.; Pinson, P.; Gooi, H.B. Very short-term nonparametric probabilistic forecasting of renewable energy generation—With application to solar energy. IEEE Trans. Power Syst. 2016, 31, 3850–3863. [Google Scholar] [CrossRef] [Green Version]
- Yagli, G.M.; Yang, D.; Srinivasan, D. Ensemble solar forecasting using data-driven models with probabilistic post-processing through GAMLSS. Sol. Energy 2020, 208, 612–622. [Google Scholar] [CrossRef]
- David, M.; Ramahatana, F.; Trombe, P.J.; Lauret, P. Probabilistic forecasting of the solar irradiance with recursive ARMA and GARCH models. Sol. Energy 2016, 133, 55–72. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, R.; Sreeram, V.; Mishra, Y.; Arif, M.D. A review and evaluation of the state-of-the-art in PV solar power forecasting: Techniques and optimization. Renew. Sustain. Energy Rev. 2020, 124, 109792. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Wang, X. Review on probabilistic forecasting of wind power generation. Renew. Sustain. Energy Rev. 2014, 32, 255–270. [Google Scholar] [CrossRef]
- Sun, M.; Feng, C.; Chartan, E.K.; Hodge, B.M.; Zhang, J. A two-step short-term probabilistic wind forecasting methodology based on predictive distribution optimization. Appl. Energy 2019, 238, 1497–1505. [Google Scholar] [CrossRef]
- Jin, H.; Shi, L.; Chen, X.; Qian, B.; Yang, B.; Jin, H. Probabilistic wind power forecasting using selective ensemble of finite mixture Gaussian process regression models. Renew. Energy 2021, 174, 1–18. [Google Scholar] [CrossRef]
- Kim, Y.; Hur, J. An ensemble forecasting model of wind power outputs based on improved statistical approaches. Energies 2020, 13, 1071. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Zheng, L.; Ding, X. Ultra-short-term prediction of photovoltaic output based on an LSTM-ARMA combined model driven by EEMD. J. Renew. Sustain. Energy 2021, 13, 1–14. [Google Scholar] [CrossRef]
- Mellit, A.; Pavan, A.M.; Ogliari, E.; Leva, S.; Lughi, V. Advanced methods for photovoltaic output power forecasting: A review. Appl. Sci. 2020, 10, 487. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Lin, P.; Lai, Y.; Cheng, S.; Chen, Z.; Wu, L. Very-Short-Term Power Prediction for PV Power Plants Using a Simple and Effective RCC-LSTM Model Based on Short Term Multivariate Historical Datasets. Electronics 2020, 9, 289. [Google Scholar] [CrossRef] [Green Version]
- AlKandari, M.; Ahmad, I. Solar power generation forecasting using ensemble approach based on deep learning and statistical methods. Appl. Comput. Inform. 2020; ahead-of-print. [Google Scholar] [CrossRef]
- Delgado, I.; Fahim, M. Wind Turbine Data Analysis and LSTM-Based Prediction in SCADA System. Energies 2020, 14, 125. [Google Scholar] [CrossRef]
- Ibrahim, M.; Alsheikh, A.; Al-Hindawi, Q.; Al-Dahidi, S.; ElMoaqet, H. Short-Time Wind Speed Forecast Using Artificial Learning-Based Algorithms. Comput. Intell. Neurosci. 2020, 2020, 1–15. [Google Scholar] [CrossRef]
- Wang, H.; Yi, H.; Peng, J.; Wang, G.; Liu, Y.; Jiang, H.; Liu, W. Deterministic and probabilistic forecasting of photovoltaic power based on deep convolutional neural network. Energy Convers. Manag. 2017, 153, 409–422. [Google Scholar] [CrossRef]
- Alessandrini, S.; Delle Monache, L.; Sperati, S.; Cervone, G. An analog ensemble for short-term probabilistic solar power forecast. Appl. Energy 2015, 157, 95–110. [Google Scholar] [CrossRef] [Green Version]
- van der Meer, D.W.; Shepero, M.; Svensson, A.; Widén, J.; Munkhammar, J. Probabilistic forecasting of electricity consumption, photovoltaic power generation and net demand of an individual building using Gaussian Processes. Appl. Energy 2018, 213, 195–207. [Google Scholar] [CrossRef]
- Pinson, P. Very-short-term probabilistic forecasting of wind power with generalized logit-normal distributions. J. R. Stat. Soc. Ser. Appl. Stat. 2012, 61, 555–576. [Google Scholar] [CrossRef]
- Tahmasebifar, R.; Moghaddam, M.P.; Sheikh-El-Eslami, M.K.; Kheirollahi, R. A new hybrid model for point and probabilistic forecasting of wind power. Energy 2020, 211, 119016. [Google Scholar] [CrossRef]
- Taylor, J.W. Probabilistic forecasting of wind power ramp events using autoregressive logit models. Eur. J. Oper. Res. 2017, 259, 703–712. [Google Scholar] [CrossRef]
- Abuella, M.; Chowdhury, B. Forecasting of solar power ramp events: A post-processing approach. Renew. Energy 2019, 133, 1380–1392. [Google Scholar] [CrossRef]
- Probst, O.; Minchala, L.I. Mitigation of short-term wind power ramps through forecast-based curtailment. Appl. Sci. 2021, 11, 4371. [Google Scholar] [CrossRef]
- Han, L.; Qiao, Y.; Li, M.; Shi, L. Wind power ramp event forecasting based on feature extraction and deep learning. Energies 2020, 13, 6449. [Google Scholar] [CrossRef]
- Australian Energy Market Operator. Renewable Integration Study Appendix C: Managing variability and uncertainty. 2020, pp. 1–77. Available online: https://aemo.com.au/en/energy-systems/major-publications/renewable-integration-study-ris (accessed on 11 June 2021).
- Brinkworth, B. Autocorrelation and stochastic modelling of insolation sequences. Sol. Energy 1977, 19, 343–347. [Google Scholar] [CrossRef]
- Balouktsis, A.; Tsalides, P. Stochastic simulation model of hourly total solar radiation. Sol. Energy 1986, 37, 119–126. [Google Scholar] [CrossRef]
- Phillips, W. Harmonic analysis of climatic data. Sol. Energy 1984, 32, 319–328. [Google Scholar] [CrossRef]
- Boland, J. Time-series analysis of climatic variables. Sol. Energy 1995, 55, 377–388. [Google Scholar] [CrossRef]
- Sfeir, A. A stochastic model for predicting solar system performance. Sol. Energy 1980, 25, 149–154. [Google Scholar] [CrossRef]
- Aguiar, R.; Collares-Pereira, M.; Conde, J. Simple procedure for generating sequences of daily radiation values using a library of Markov transition matrices. Sol. Energy 1988, 40, 269–279. [Google Scholar] [CrossRef]
- Aguiar, R.; Collares-Pereira, M. Statistical properties of hourly global radiation. Sol. Energy 1992, 48, 157–167. [Google Scholar] [CrossRef]
- Aguiar, R.; Collares-Pereira, M. TAG: A time-dependent, autoregressive, Gaussian model for generating synthetic hourly radiation. Sol. Energy 1992, 49, 167–174. [Google Scholar] [CrossRef]
- Amato, U.; Andretta, A.; Bartoli, B.; Coluzzi, B.; Cuomo, V.; Fontana, F.; Serio, C. Markov processes and Fourier analysis as a tool to describe and simulate daily solar irradiance. Sol. Energy 1986, 37, 179–194. [Google Scholar] [CrossRef]
- Graham, V.; Hollands, K. A method to generate synthetic hourly solar radiation globally. Sol. Energy 1990, 44, 333–341. [Google Scholar] [CrossRef]
- Bright, J.M. Synthetic Solar Irradiance Modeling Solar Data; AIP Publishing LLC: Melville, NY, USA, 2021. [Google Scholar]
- Boland, J.; Grantham, A. Principles and Key Applications: Principles and Applications of Synthetic Solar Irradiance; AIP Publishing LLC: Melville, NY, USA, 2021; pp. 2-1–2-32. [Google Scholar] [CrossRef]
- Grantham, A.; Pudney, P.; Ward, L.; Belusko, M.; Boland, J. Generating synthetic five-minute solar irradiance values from hourly observations. Sol. Energy 2017, 147, 209–221. [Google Scholar] [CrossRef]
- Grantham, A.; Pudney, P.; Boland, J. Generating synthetic sequences of global horizontal irradiation. Sol. Energy 2018, 162, 500–509. [Google Scholar] [CrossRef]
- Larrañeta, M.; Fernandez-Peruchena, C.; Silva-Pérez, M.A.; Lillo-bravo, I.; Grantham, A.; Boland, J. Generation of synthetic solar datasets for risk analysis. Sol. Energy 2019, 187, 212–225. [Google Scholar] [CrossRef]
- Antonanzas, J.; Pozo-Vázquez, D.; Fernandez-Jimenez, L.A.; Martinez-de Pison, F.J. The value of day-ahead forecasting for photovoltaics in the Spanish electricity market. Sol. Energy 2017, 158, 140–146. [Google Scholar] [CrossRef]
- Murphy, A.H. What is a good forecast? An essay on the nature of goodness in weather forecasting. Weather Forecast. 1993, 8, 281–293. [Google Scholar] [CrossRef] [Green Version]
- Snell, T.; Consani, S.; West, S.; Amos, M. Solar Power Ensemble Forecaster Final Report—Public; Industrial Monitoring and Control: Newcastle, Australia, 2021. [Google Scholar]
- David, M.; Boland, J.; Cirocco, L.; Lauret, P.; Voyant, C. Value of deterministic day-ahead forecasts of PV generation in PV + Storage operation for the Australian electricity market. Sol. Energy 2021, 224, 672–684. [Google Scholar] [CrossRef]
- Finch, T. Incremental Calculation of Weighted Mean and Variance; University of Cambridge: Cambridge, UK, 2009; Volume 1, pp. 1–8. [Google Scholar]
- Lauret, P.; David, M.; Pedro, H.T. Probabilistic solar forecasting using quantile regression models. Energies 2017, 10, 1591. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forecast Model | Evaluation Metrics (Best Results) | Reference |
|---|---|---|
| Elmann artificial neural network | NMBE (−0.21%), NMAE (6.50%), SD (0.11%), NRMSE (10.91%) | De Giorgi et al. [4] |
| Regressions in logs, autoregressive integrated moving average (ARIMA), unobserved components models, transfer functions, neural networks and hybrid models | MAPE (0.1263) | Reikard [5] |
| Multiple feed-forward neural networks for irradiance forecast + PV model | MAE (7.03 W/m2), MAPE (3.41%), RMSE (8.60 W/m2), R (0.99) | Durrani et al. [6] |
| Least square support vector machines (LS-SVM), LS-SVM with wavelet decomposition, ANN | NMBE (0.12%), NMAE (6.40%), NRMSE (9.60%) | De Giorgi et al. [7] |
| Correlation-based feature selection for univariate and multivariate NN ensemble and SVR | MAE (45.11 kW), MRE (3.92%) | Rana et al. [8] |
| Feed-forward neural networks and physical hybrid ANN | NMAE (<1.0%), WMAE (1.96%) | Nespoli et al. [9] |
| Fourier series with coupled autoregressive (AR) and dynamical system (CARDS) model | MeAPE (7.53%, 10.85%), MBE (0.45, 0.0002), KSI (17.92%, –), NRMSE (16.50%, 17.16%) | Huang et al. [10], Huang and Boland [11] |
| Autoregressive moving average (ARMA) and ARIMA models fitted by the log-likelihood function | MAE (37.95 W/m2), MAPE (0.1%) | Colak et al. [12] |
| Fourier series plus autoregressive models, clear sky index plus plus neural net models and clear sky index plus ARMA models | NMBE (0.08%), NRMSE (10.91%), NMAD (5.12%) | Boland et al. [13] |
| Global and mesoscale numerical weather prediction models combined with persistence model, time series models, k-nearest neighbours (KNN) models, ANN models and adaptive neuro-fuzzy models | RMSE (4243.01 Wh), NRMSE (11.79%), ME (−42.8 Wh), NME(−0.12%), MAE (2308.3 Wh), NMAE (6.41%) | Fernandez-Jimenez et al. [14] |
| Reforcasting model combined with cloud tracking, ARMA and KNN models | MBE (0.1 kW), MAE (20.7 kW), RMSE (35.5 kW), SRMSE (26.2%) | Chu et al. [15] |
| Verification of deterministic forecasts | A review paper | Yang et al. [16] |
| Forecast Model | Reference |
|---|---|
| Non-parametric predictive density of solar irradiance for probabilistic forecasting | Grantham et al. [17] |
| Probabilistic forecasting of solar radiation | Grantham et al. [17] |
| Probabilistic forecasting of PV power | Ni et al. [18] |
| Probabilistic forecasting of solar radiation | Boland and Grantham [19] |
| Probabilistic forecasting of solar radiation | Golestaneh et al. [20] |
| Ensemble solar forecasting with probabilistic post processing | Yagli et al. [21] |
| ARMA and GARCH for prediction intervals | David et al. [22] |
| Review of tools for probabilistic forecasting of PV power | Ahmed et al. [23] |
| Review of tools for probabilistic forecasting of wind power generation | Zhang et al. [24] |
| Probabilistic forecasting of wind power generation using predictive distribution optimisation | Sun et al. [25] |
| Probabilistic forecasting of wind power generation using Gaussian mixture models | Jin et al. [26] |
| Probabilistic forecasting of wind power generation using ensemble methods | Kim and Hur [27] |
| Site | Best Model (RMSE) | Skill | Best Model (MAE) | Skill |
|---|---|---|---|---|
| Darling Downs | Ensemble ML | 9.2% | Ensemble Median | 13.0% |
| Daydream | Ensemble Mean | 16.2% | Ensemble Median | 18.2% |
| Gannawarra | SkyCam | 19.3% | Smart Persistence | 16.8% |
| Emerald | Ensemble Mean | 2.8% | ASEFS | - |
| Manildra | SkyCam | 21.2% | SkyCam | 16.6% |
| Site | ASEFS Fee | Dispatch Model | Fee | Savings | Percentage Savings |
|---|---|---|---|---|---|
| Darling Downs | 432,500 | SF12 | 281,018 | 151,482 | 18% |
| Daydream | 70,793 | SF10 | 57,983 | 12,810 | 35% |
| Gannawarra | 39,778 | SF5 | 28,485 | 11,293 | 28% |
| Emerald | 50,726 | SF10 | 2129 | 48,595 | 98% |
| Average | Savings | 56,045 | 44% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boland, J.; Farah, S.; Bai, L. Forecasting of Wind and Solar Farm Output in the Australian National Electricity Market: A Review. Energies 2022, 15, 370. https://doi.org/10.3390/en15010370
Boland J, Farah S, Bai L. Forecasting of Wind and Solar Farm Output in the Australian National Electricity Market: A Review. Energies. 2022; 15(1):370. https://doi.org/10.3390/en15010370
Chicago/Turabian StyleBoland, John, Sleiman Farah, and Lei Bai. 2022. "Forecasting of Wind and Solar Farm Output in the Australian National Electricity Market: A Review" Energies 15, no. 1: 370. https://doi.org/10.3390/en15010370