
Global Sensitivity Analysis Applied to Train Traffic Rescheduling: A Comparative Study


Abstract
:1. Introduction
2. Problem Statement
2.1. System Description
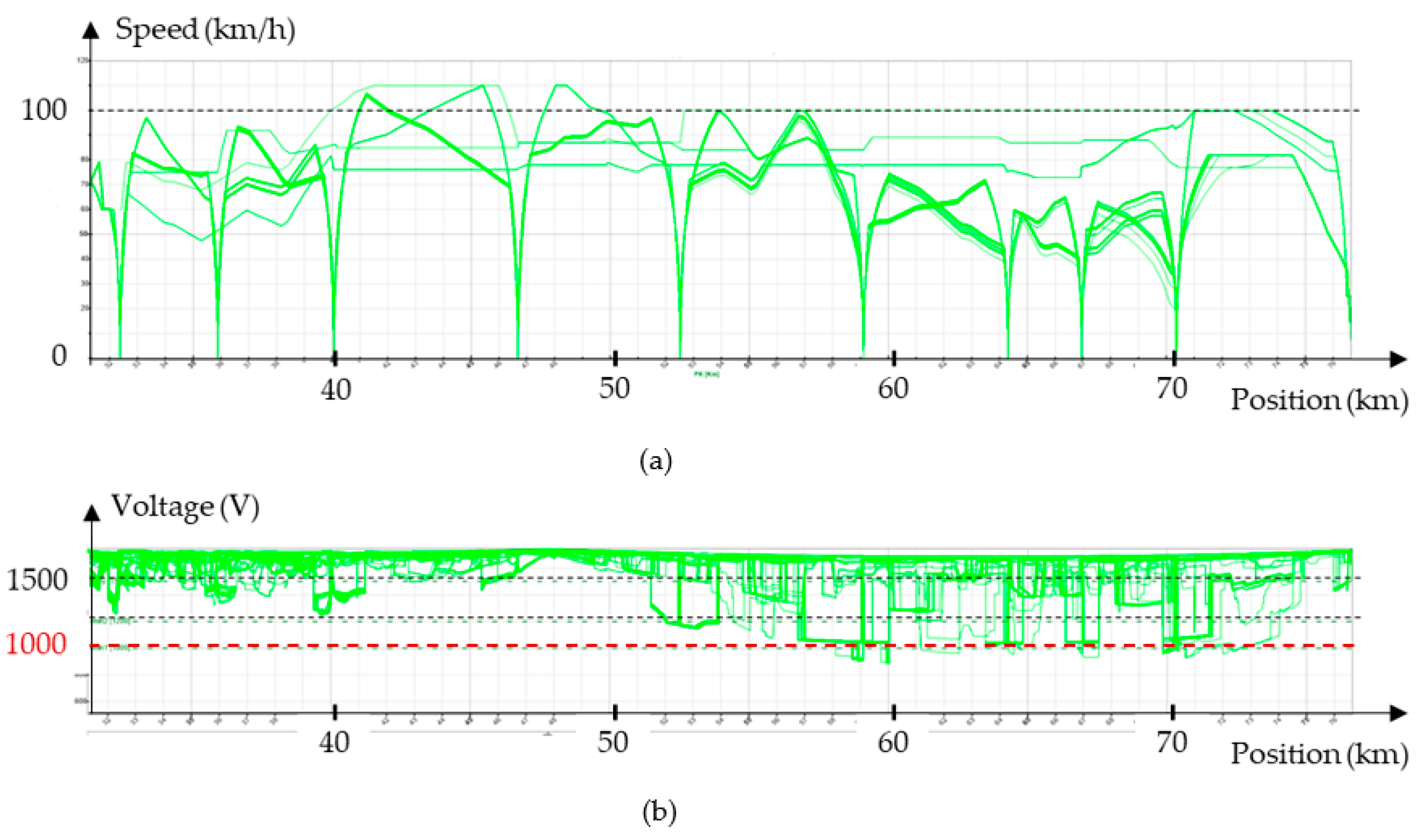
2.2. Simulator Description
2.3. Managing the Unavailability of an Electrical Equipement
2.4. Mathematical Formalization of the Traffic Adjustment Problem
2.5. Inadequacy of Classical Optimization Methods and Proposed Methodology
3. Global Sensitivity Analysis for Multivariate Outputs
3.1. Overview of Sensitivity Analysis
3.2. Sampling Phase
3.3. Generalized Sobol Indices
3.3.1. Sobol Indices for Scalar Outputs
3.3.2. Generalized Sobol Indices
3.3.3. First Order Sobol Indices Estimation
3.4. Sensitivity Analysis Based on Energy Distance between Distributions
3.4.1. Energy Distance
3.4.2. Application to Sensitivity Analysis
- -
- they belong to the interval .
- -
- if and are identically distributed, i.e., . has no influence on Y.
3.4.3. Practical Implementation
- Generate a p-input sample matrix and apply the model to calculate the corresponding m-output matrix (see Section 2.2 and Figure 3).
- For each :
- i.
- Partition the variation interval of into disjoint consecutive subintervals and estimate .
- ii.
- Partition the outputs of the model into subsets corresponding to the partition of :
- iii.
- For each , estimate the energy distance .
- iv.
- Calculate the sensitivity index .
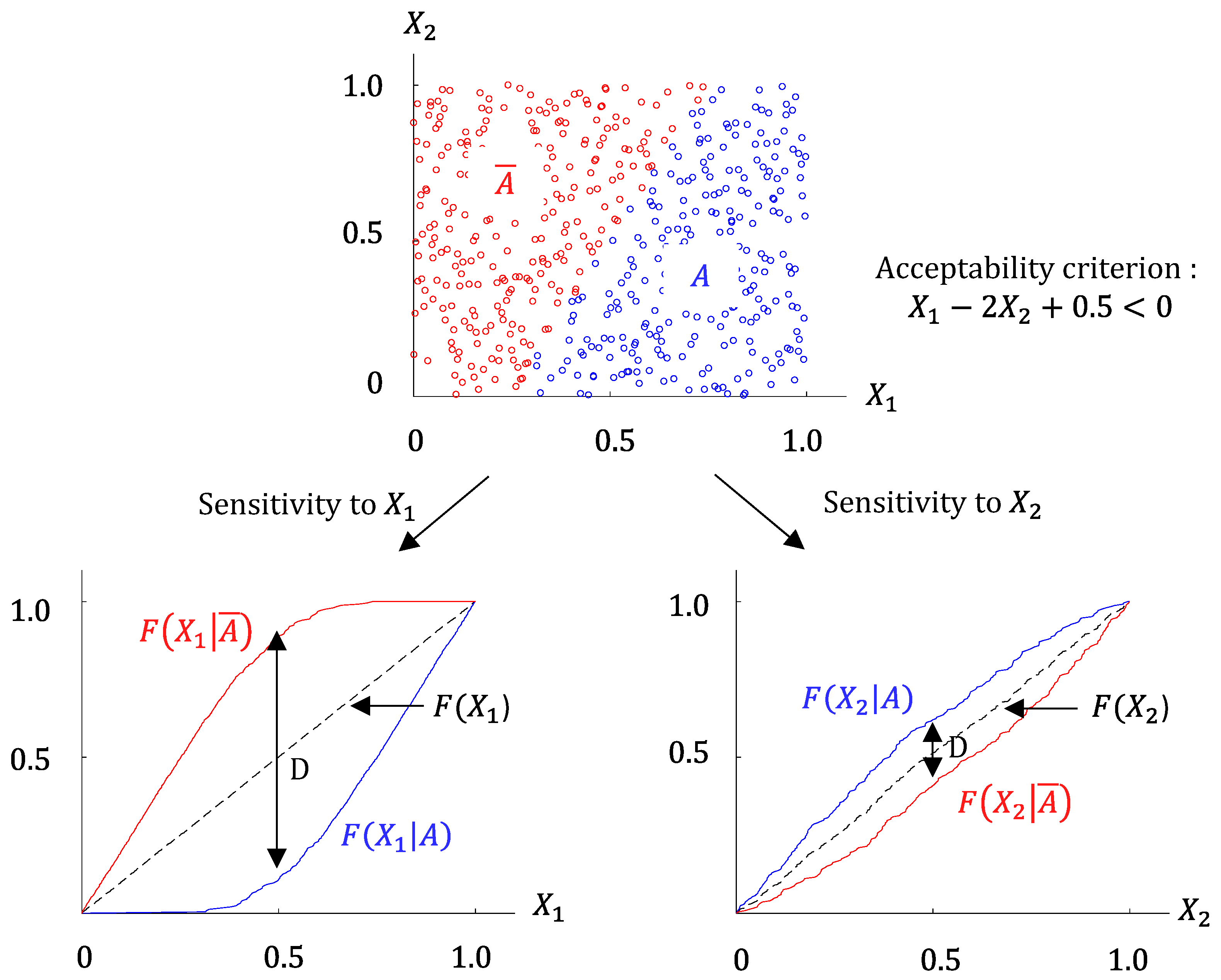
3.5. Regional Sensitivity Analysis
3.5.1. Principle of Regional Sensitivity Analysis
3.5.2. Two-Sample Kolmogorov–Smirnov Test
3.5.3. Practical Implementation and Comments
- Generate a p-input sample that properly covers the input and output spaces and apply the model to calculate the corresponding m-output set. The procedure and the notations are detailed in Section 2.2 and Figure 3. The “rules of art” are the same as for the sensitivity analysis method presented before.
- Classify the sample set into behavioral and non-behavioral subsets and , according to the operational constraints (e.g, pantograph voltages within prescribed limits at all times of simulation).
- For each :
- i.
- Sort each subset and with respect to , build and plot the distribution functions and . Proceed to qualitative visual analysis.
- ii.
- Apply the Kolmogorov–Smirnov two-sample test (two-side version) to and and calculate and the corresponding significance level .
- iii.
- Categorize as “critical”, “important”, or “insignificant”, according to the significance level [14]. is said to be a “critical” input if is below 1%. In other words, the probability of wrongly stating that and are different, and hence that is an influential variable, is less than 1%. An “insignificant” input corresponds to a significance level above 10%: the risk of wrongly rejecting H0 is deemed too high to conclude about the influence of . In between, inputs are categorized as “important”.
4. Comparative Analysis
4.1. Test Case Presentation
4.2. Adjustment Problem Specification
4.2.1. Adjustment Variables
- -
- : time interval increase between successive departures;
- -
- : speed setpoint reduction between pk40 and pk45;
- -
- : speed setpoint reduction between pk45 and pk50;
- -
- : speed setpoint reduction between pk50 and pk55;
- -
- : speed setpoint reduction between pk55 and pk60.
4.2.2. Outputs and Acceptability Criterion
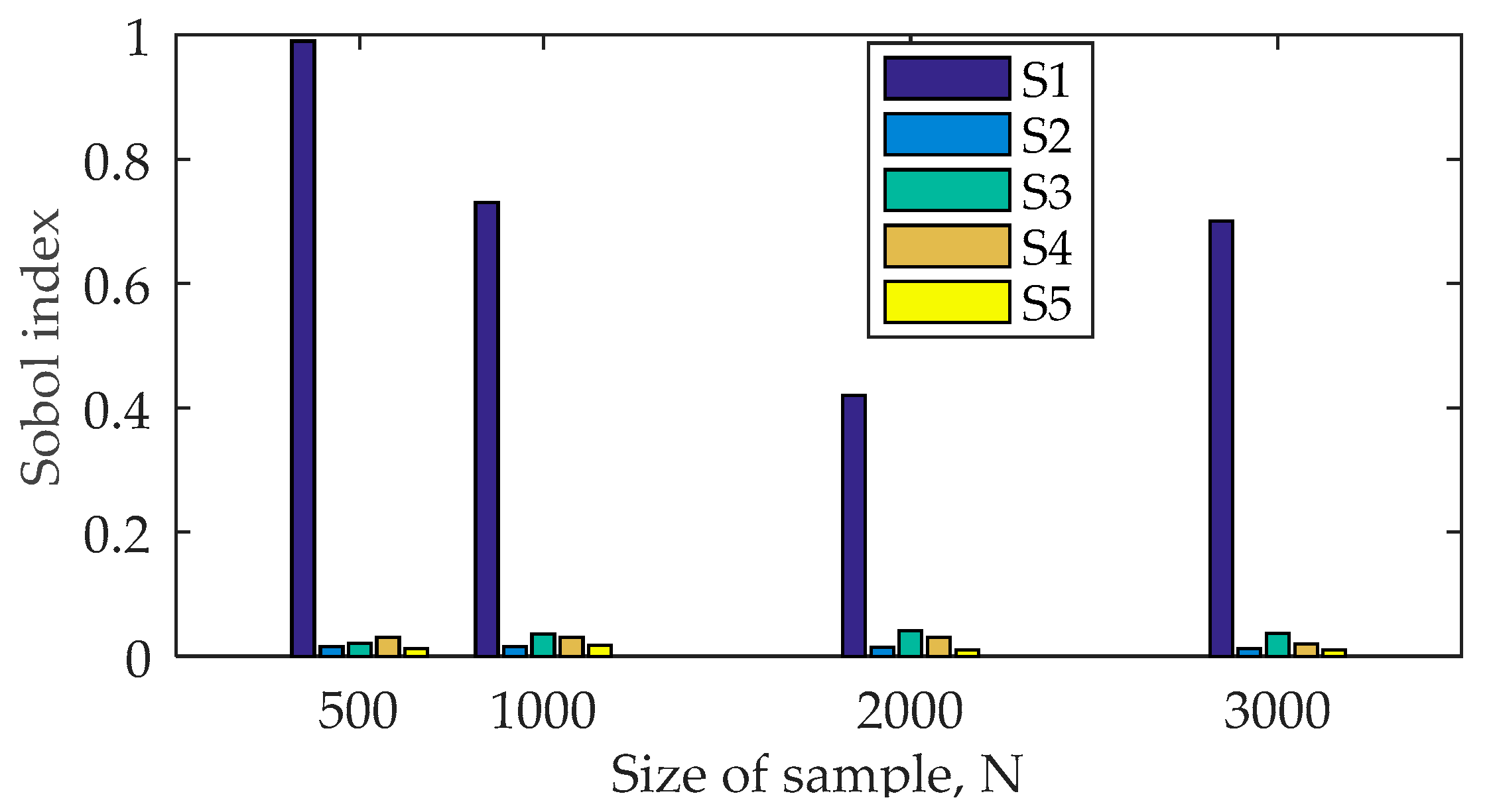
4.3. Generalized Sobol Indices
4.4. Energy Distance-Based Indices
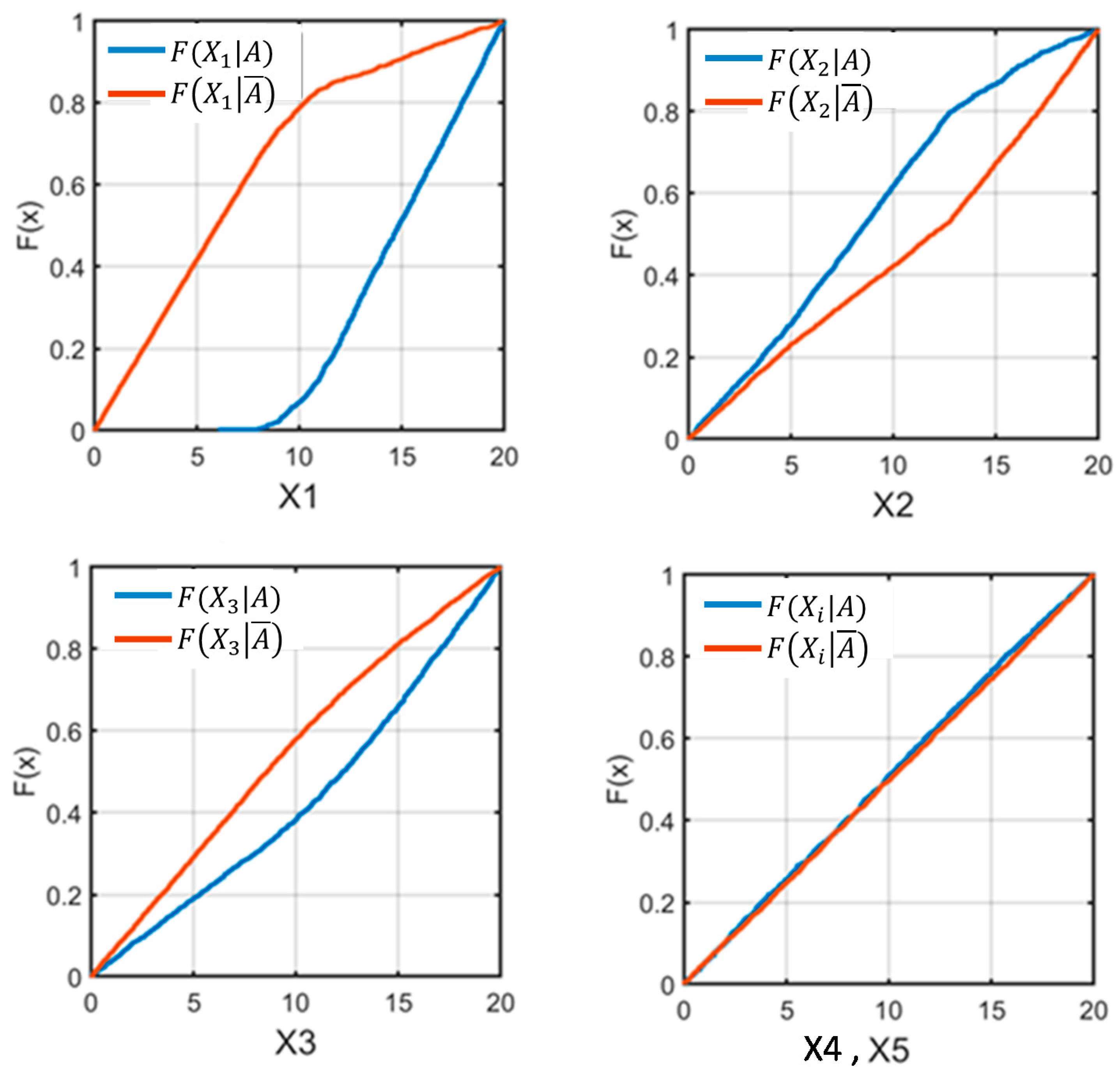
4.5. Regional Sensitivity Analysis
4.6. Assessment and Comparison of the Tested Methods
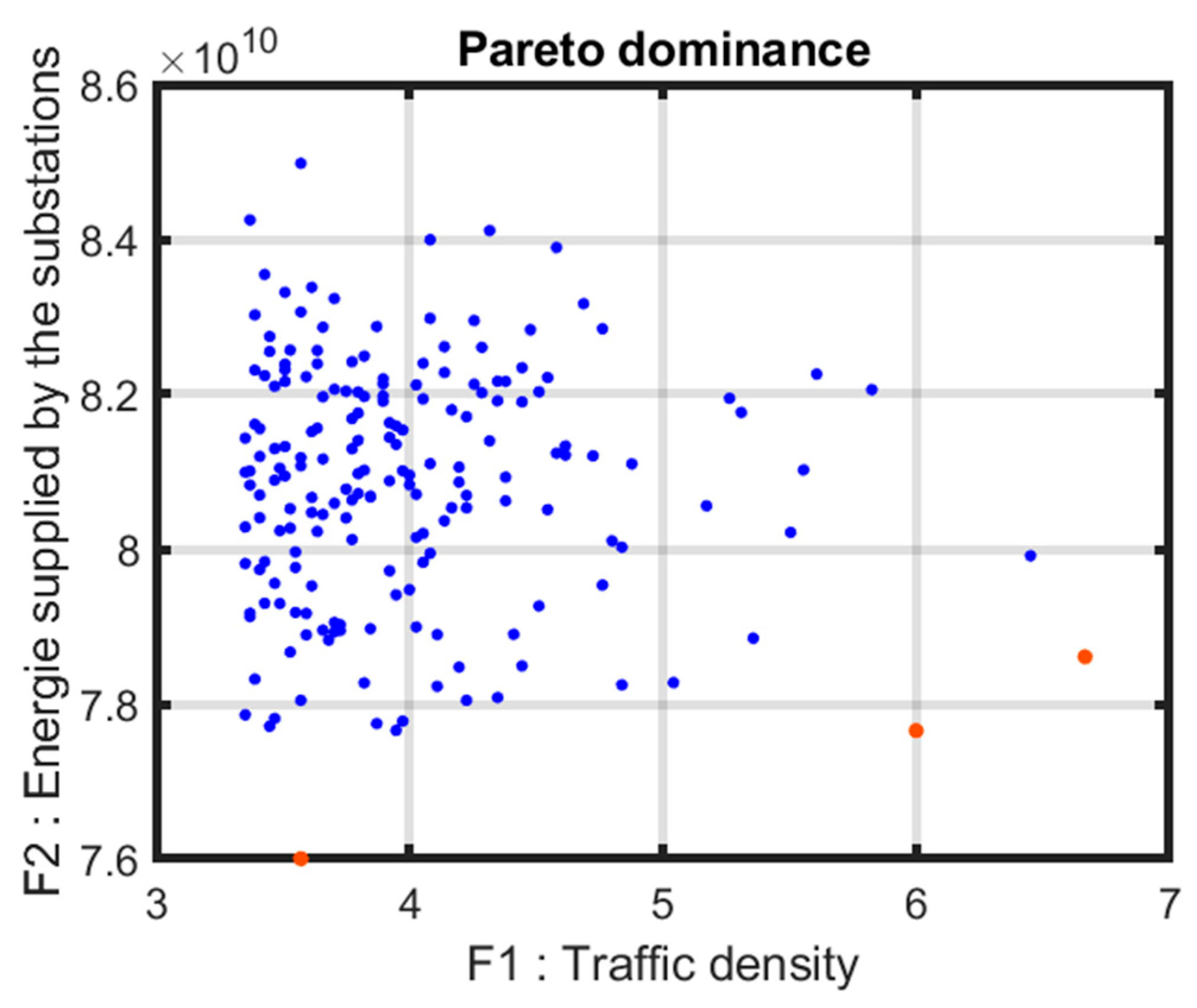
4.7. Empirical Pareto Set
- F1: traffic density.
- F2: total energy supplied by the substations.
5. Application to a Real Case
5.1. Test Case Description
5.2. Rescheduling Process
- Delete comfort auxiliaries for suburb trains, type 1;
- Delete comfort auxiliaries for suburb trains, type 2;
- Space the consecutive trains of group G1;
- Space the consecutive trains of group G2;
- Space the consecutive trains of group G3;
- Space the consecutive trains of group G6.
- Delete comfort auxiliaries for suburb trains, type 1: yes;
- Delete comfort auxiliaries for suburb trains, type 2: yes;
- Space the consecutive trains of group G1: 4 minutes;
- Space the consecutive trains of group G2: 1 minute;
- Space the consecutive trains of group G3: 11 minutes;
- Space the consecutive trains of group G6: 2 minutes.
5.3. Conclusions
6. Conclusions
- Variance-based method: Sobol indices are sensitivity indices based on the output variance. They are widespread for scalar outputs and have been generalized for vector outputs, such as time series. Second order indices can provide information about the interactions between inputs, but usually only the first-order indices are calculated. The computation of Sobol indices requires large samples in order to reach convergence, and, furthermore, the number of model evaluations is proportional to the number of tested inputs. Hence, the computation time may become prohibitive in the case of numerically intensive models.
- Energy distance-based method: The energy distance is used to quantify the distance between the output and the conditional distributions over the whole domain. This distance facilitates the definition of normalized sensitivity. The method was initially proposed for scalar outputs, but it naturally generalizes to series outputs. As this method is moment independent, it is more general than Sobol indices. Furthermore, its computation cost is significantly lower because of faster convergence of the estimates and because the number of model evaluations does not depend on the number of input variables.
- Regional sensitivity analysis: This method applies to problems involving an acceptability criterion on the output, and tests the influence of the input variables in respect to this criterion. So-called Monte Carlo filtering is used to partition the input space into an acceptable set and a non-acceptable set. Then the two sets are compared statistically in order to highlight the influence of each input variable. This method is the fastest and the easiest one to implement.
- The results of the three methods are consistent: they lead to the same input ranking of the input, but the cost of Sobol indices is much higher than the two other methods. Regional sensitivity analysis appears to be the most suitable method for the present application: it is relatively easy to implement, rather fast, and accounts for constraints on the system output, a key feature for electrical incident management.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Numerical Estimate of First Order Sobol Indices
- i.
- Two input sample matrices and (size ) are generated using a quasi-random algorithm (see Section 3.2).
- ii.
- For each parameter , a sample matrix is built by replacing the column of matrix with the column of matrix .
- iii.
- The model is applied to the sample matrices and , and one obtains the corresponding vector outputs and .
- iv.
- The expectation estimators are calculated as follows:
References
- Cacchiani, V.; Huisman, D.; Kidd, M.; Kroon, L.; Toth, P.; Veelenturf, L.; Wagenaar, J. An overview of recovery models and algorithms for real-time railway rescheduling. Transp. Res. Part B Methodol. 2014, 63, 15–37. [Google Scholar] [CrossRef] [Green Version]
- Krasemann, J. Greedy algorithm for railway traffic re-scheduling during disturbances: A Swedish case. IET Intell. Transp. Syst. 2010, 4, 375–386. [Google Scholar] [CrossRef] [Green Version]
- Dündar, S.; Şahin, I. Train re-scheduling with genetic algorithms and artificial neural networks for single-track railways. Transp. Res. Part C Emerg. Technol. 2013, 27, 1–15. [Google Scholar] [CrossRef]
- Schachtebeck, M.; Schöbel, A. To Wait or Not to Wait—And Who Goes First? Delay Management with Priority Decisions. Transp. Sci. 2010, 44, 307–321. [Google Scholar] [CrossRef]
- D’Ariano, A.; Pacciarelli, D.; Sama, M.; Corman, F. Microscopic delay management: Minimizing train delays and passenger travel times during real-time railway traffic control. In Proceedings of the 2017 5th IEEE International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Naples, Italy, 26–28 June 2017; pp. 309–314. [Google Scholar]
- Louwerse, I.; Huisman, D. Adjusting a railway timetable in case of partial or complete blockades. Eur. J. Oper. Res. 2014, 235, 583–593. [Google Scholar] [CrossRef] [Green Version]
- Ghaemi, N.; Goverde, R.; Cats, O. Railway disruption timetable: Short-turnings in case of complete blockage. In Proceedings of the 2016 IEEE International Conference on Intelligent Rail Transportation (ICIRT), Birmingham, UK, 23–25 August 2016; pp. 210–218. [Google Scholar]
- Zhan, S.; Kroon, L.G.; Veelenturf, L.P.; Wagenaar, J.C. Real-time high-speed train rescheduling in case of a complete blockage. Transp. Res. Part B Methodol. 2015, 78, 182–201. [Google Scholar] [CrossRef]
- Narayanaswami, S.; Rangaraj, N. Modelling disruptions and resolving conflicts optimally in a railway schedule. Comput. Ind. Eng. 2013, 64, 469–481. [Google Scholar] [CrossRef]
- Binder, S.; Maknoon, Y.; Bierlaire, M. The multi-objective railway timetable rescheduling problem. Transp. Res. Part C Emerg. Technol. 2017, 78, 78–94. [Google Scholar] [CrossRef] [Green Version]
- Lusby, R.M.; Larsen, J.; Ehrgott, M.; Ryan, D. Railway track allocation: Models and methods. OR Spectr. 2011, 33, 843–883. [Google Scholar] [CrossRef]
- Cacchiani, V.; Toth, P. Nominal and robust train timetabling problems. Eur. J. Oper. Res. 2012, 219, 727–737. [Google Scholar] [CrossRef]
- Desjouis, B.; Remy, G.; Ossart, F.; Marchand, C.; Bigeon, J.; Sourdille, E. A new generic problem formulation dedicated to electrified railway systems. In Proceedings of the 2015 International Conference on Electrical Systems for Aircraft, Railway, Ship Propulsion and Road Vehicles (ESARS), Aachen, Germany, 3–5 March 2015; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Saltelli, A. (Ed.) Sensitivity Analysis in Practice: A Guide to Assessing Scientific Models; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Saltelli, A.; Ratto, M.; Andres, T.; Campolongo, F.; Cariboni, J.; Gatelli, D.; Saisana, M.; Tarantola, S. Global Sensitivity Analysis: The Primer; Wiley: Hoboken, NJ, USA, 2008. [Google Scholar]
- Iooss, B.; Lemaître, P. A review on global sensitivity analysis methods. In Uncertainty Management in Simulation-Optimization of Complex Systems; Springer: Boston, MA, USA; Available online: http://arxiv.org/abs/1404.2405 (accessed on 3 June 2021).
- Becker, W.; Paruolo, P.; Saisana, M.; Salkelli, A. Weights and importance in composite indicators: Mind the gap. In Handbook of Uncertainty Quantification; Ghanem, R., Higdon, D., Owhadi, H., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 1187–1216. [Google Scholar] [CrossRef]
- Morio, J. Global and local sensitivity analysis methods for a physical system. Eur. J. Phys. 2011, 32, 1577–1583. [Google Scholar] [CrossRef]
- Morris, M.D. Factorial Sampling Plans for Preliminary Computational Experiments. Technometrics 1991, 33, 161. [Google Scholar] [CrossRef]
- Saltelli, A.; Ratto, M.; Tarantola, S.; Campolongo, F. Sensitivity analysis practices: Strategies for model-based inference. Reliab. Eng. Syst. Saf. 2006, 91, 1109–1125. [Google Scholar] [CrossRef]
- Sobol’, I.M. Sensitivity estimates for nonlinear mathematical models (translated from Russian). Math. Model. Comput. Exp. 1993, 1, 407–414. [Google Scholar]
- Sobol′, I.M. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math. Comput. Simul. 2001, 55, 271–280. [Google Scholar] [CrossRef]
- Sobol, I.M.; Kucherenko, S.S. Global sensitivity indices for nonlinear mathematical models. Review. Wilmott 2005, 2005, 56–61. [Google Scholar] [CrossRef]
- Reuter, U.; Liebscher, M. Global Sensitivity Analysis in View of Nonlinear Structural Behavior; LS-DYNA: Anwenderforum, Bamberg, 2008. [Google Scholar]
- Bolado-Lavin, R.; Castaings, W.; Tarantola, S. Contribution to the sample mean plot for graphical and numerical sensitivity analysis. Reliab. Eng. Syst. Saf. 2009, 94, 1041–1049. [Google Scholar] [CrossRef]
- Tarantola, S.; Kopustinskas, V.; Bolado-Lavin, R.; Kaliatka, A.; Ušpuras, E.; Vaišnoras, M. Sensitivity analysis using contribution to sample variance plot: Application to a water hammer model. Reliab. Eng. Syst. Saf. 2012, 99, 62–73. [Google Scholar] [CrossRef]
- Harris, T.; Yu, W. Variance decompositions of nonlinear-dynamic stochastic systems. J. Process. Control. 2010, 20, 195–205. [Google Scholar] [CrossRef]
- Li, L.; Lu, Z. Regional importance effect analysis of the input variables on failure probability and its state dependent parameter estimation. Comput. Math. Appl. 2013, 66, 2075–2091. [Google Scholar] [CrossRef]
- Campbell, K.; McKay, M.D.; Williams, B.J. Sensitivity analysis when model outputs are functions. Reliab. Eng. Syst. Saf. 2006, 91, 1468–1472. [Google Scholar] [CrossRef]
- Garcia-Cabrejo, O.; Valocchi, A. Global Sensitivity Analysis for multivariate output using Polynomial Chaos Expansion. Reliab. Eng. Syst. Saf. 2014, 126, 25–36. [Google Scholar] [CrossRef]
- Lamboni, M.; Makowski, D.; Lehuger, S.; Gabrielle, B.; Monod, H. Multivariate global sensitivity analysis for dynamic crop models. Field Crop. Res. 2009, 113, 312–320. [Google Scholar] [CrossRef]
- Lamboni, M.; Monod, H.; Makowski, D. Multivariate sensitivity analysis to measure global contribution of input factors in dynamic models. Reliab. Eng. Syst. Saf. 2011, 96, 450–459. [Google Scholar] [CrossRef]
- Gamboa, F.; Janon, A.; Klein, T.; Lagnoux, A. Sensitivity indices for multivariate outputs. Comptes Rendus Math. 2013, 351, 307–310. [Google Scholar] [CrossRef] [Green Version]
- Gamboa, F.; Janon, A.; Klein, T.; Lagnoux, A. Sensitivity analysis for multidimensional and functional outputs. Electron. J. Stat. 2014, 8, 575–603. [Google Scholar] [CrossRef]
- Lijie, C.; Bo, R.; Ze, L. Importance measures of basic variable under multiple failure modes and their solutions. In Proceedings of the 2016 IEEE Chinese Guidance, Navigation and Control Conference (CGNCC), Nanjing, China, 12–14 August 2016; pp. 1605–1611. [Google Scholar]
- Greegar, G.; Manohar, C. Global response sensitivity analysis using probability distance measures and generalization of Sobol’s analysis. Probabilit. Eng. Mech. 2015, 41, 21–33. [Google Scholar] [CrossRef]
- Pianosi, F.; Wagener, T. A simple and efficient method for global sensitivity analysis based on cumulative distribution functions. Environ. Model. Softw. 2015, 67, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Rizzo, M.L.; Székely, G.J. Energy distance. Wiley Interdiscip. Rev. Comput. Stat. 2015, 8, 27–38. [Google Scholar] [CrossRef]
- Hornberger, G. Eutrophication in peel inlet—I. The problem-defining behavior and a mathematical model for the phosphorus scenario. Water Res. 1980, 14, 29–42. [Google Scholar] [CrossRef]
- Spear, R. Eutrophication in peel inlet—II. Identification of critical uncertainties via generalized sensitivity analysis. Water Res. 1980, 14, 43–49. [Google Scholar] [CrossRef]
- Hornberger, G.M.; Spear, R.C. Approach to the preliminary analysis of environmental systems. J. Environ. Manag. 1981, 12, 7–18. [Google Scholar]
- Stratified Sampling—Research Methodology. Available online: https://research-methodology.net/sampling-in-primary-data-collection/stratified-sampling (accessed on 14 August 2021).
- McKay, M.D.; Beckman, R.J.; Conover, W.J. A Comparison of Three Methods for Selecting Values of Input Variables in the Analysis of Output from a Computer Code. Technometrics 2000, 42, 55–61. [Google Scholar] [CrossRef]
- Helton, J.; Davis, F. Latin hypercube sampling and the propagation of uncertainty in analyses of complex systems. Reliab. Eng. Syst. Saf. 2003, 81, 23–69. [Google Scholar] [CrossRef] [Green Version]
- Sobol’, I.; Levitan, Y. A pseudo-random number generator for personal computers. Comput. Math. Appl. 1999, 37, 33–40. [Google Scholar] [CrossRef] [Green Version]
- Yang, H. Quasi Random Sampling for Operations Management. Seoul J. Bus. 2006, 12, 53–72. [Google Scholar]
- Burhenne, S.; Jacob, D.; Henze, P.G. Sampling based on Sobol sequences for Monte Carlo techniques applied to building simulations. In Proceedings of the 12th Conference of the International Building Performance Simulation Association, Sydney, Australia, 14–16 November 2011; pp. 1816–1823. [Google Scholar]
- Bratley, P.; Fox, B.L. Algorithm 659. ACM Trans. Math. Softw. 1988, 14, 88–100. [Google Scholar] [CrossRef]
- Dalal, I.L.; Stefan, D.; Harwayne-Gidansky, J. Low discrepancy sequences for Monte Carlo simulations on reconfigurable platforms. In Proceedings of the 2008 International Conference on Application-Specific Systems, Architectures and Processors, Leuven, Belgium, 2–4 July 2008; pp. 108–113. [Google Scholar]
- Sobol Quasirandom Point Set—MATLAB. Available online: https://www.mathworks.com/help/stats/sobolset.html (accessed on 9 June 2021).
- GitHub—Stevengj/Sobol.jl: Generation of Sobol Low-Discrepancy Sequence (LDS) for the Julia Language. Available online: https://github.com/stevengj/Sobol.jl (accessed on 9 June 2021).
- Homma, T.; Saltelli, A. Importance measures in global sensitivity analysis of nonlinear models. Reliab. Eng. Syst. Saf. 1996, 52, 1–17. [Google Scholar] [CrossRef]
- Saltelli, A.; Annoni, P.; Azzini, I.; Campolongo, F.; Ratto, M.; Tarantola, S. Variance based sensitivity analysis of model output. Design and estimator for the total sensitivity index. Comput. Phys. Commun. 2010, 181, 259–270. [Google Scholar] [CrossRef]
- Hoeffding, W. A Class of Statistics with Asymptotically Normal Distribution. Ann. Math. Stat. 1948, 19, 293–325. [Google Scholar] [CrossRef]
- Dimov, I.; Georgieva, R. Monte Carlo algorithms for evaluating Sobol’ sensitivity indices. Math. Comput. Simul. 2010, 81, 506–514. [Google Scholar] [CrossRef]
- Owen, A.B. Variance Components and Generalized Sobol’ Indices. SIAM/ASA J. Uncertain. Quantif. 2013, 1, 19–41. [Google Scholar] [CrossRef] [Green Version]
- Székely, G.J.; Rizzo, M.L. Energy statistics: A class of statistics based on distances. J. Stat. Plan. Inference 2013, 143, 1249–1272. [Google Scholar] [CrossRef]
- Székely, G.J.; Rizzo, M.L. A new test for multivariate normality. J. Multivar. Anal. 2005, 93, 58–80. [Google Scholar] [CrossRef] [Green Version]
- Xiao, S.; Lu, Z.; Wang, P. Multivariate global sensitivity analysis for dynamic models based on energy distance. Struct. Multidiscip. Optim. 2017, 57, 279–291. [Google Scholar] [CrossRef]
- Borgonovo, E. A new uncertainty importance measure. Reliab. Eng. Syst. Saf. 2007, 92, 771–784. [Google Scholar] [CrossRef]
- Plischke, E.; Borgonovo, E.; Smith, C. Global sensitivity measures from given data. Eur. J. Oper. Res. 2013, 226, 536–550. [Google Scholar] [CrossRef]
- Borgonovo, E.; Hazen, G.B.; Plischke, E. A Common Rationale for Global Sensitivity Measures and Their Estimation. Risk Anal. 2016, 36, 1871–1895. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Lu, Z.; Wu, D. A new kind of sensitivity index for multivariate output. Reliab. Eng. Syst. Saf. 2016, 147, 123–131. [Google Scholar] [CrossRef]
- Massey, F.J. The Kolmogorov-Smirnov Test for Goodness of Fit. J. Am. Stat. Assoc. 1951, 46, 68. [Google Scholar] [CrossRef]
- Hodges, J.L. The significance probability of the smirnov two-sample test. Arkiv Matematik 1958, 3, 469–486. [Google Scholar] [CrossRef]
- Ferignac, P. Test de Kolmogorov-Smirnov sur la validité d’une fonction de distribution. Rev. Stat. Appl. 1962, 10, 13–32. [Google Scholar]
- Spear, R.C.; Grieb, T.M.; Shang, N. Parameter uncertainty and interaction in complex environmental models. Water Resour. Res. 1994, 30, 3159–3169. [Google Scholar] [CrossRef]
- Ratto, M.; Pagano, A.; Young, P. Factor Mapping and Metamodeling; JCR Scientific and Technical Reports; Joint Research Centre: Ispra, Italy, 2007. [Google Scholar]
- Borgonovo, E.; Plischke, E. Sensitivity analysis: A review of recent advances. Eur. J. Oper. Res. 2016, 248, 869–887. [Google Scholar] [CrossRef]
- Wu, Z.; Yang, X.; Sun, X. Application of Monte Carlo filtering method in regional sensitivity analysis of AASHTOWare Pavement ME design. J. Traffic Transp. Eng. 2017, 4, 185–197. [Google Scholar] [CrossRef]
- Sieber, A.; Uhlenbrook, S. Sensitivity analyses of a distributed catchment model to verify the model structure. J. Hydrol. 2005, 310, 216–235. [Google Scholar] [CrossRef]
- Brockmann, D.; Morgenroth, E. Evaluating operating conditions for outcompeting nitrite oxidizers and maintaining partial nitrification in biofilm systems using biofilm modeling and Monte Carlo filtering. Water Res. 2010, 44, 1995–2009. [Google Scholar] [CrossRef]
- Wagener, T.; Lees, M.J.; Wheater, H.S. A toolkit for the development and application of parsimonious hydrological models. In Mathematical Models of Small Watershed Hydrology; Water Resources Publications: Littleton, CO, USA, 2001; Volume 2, p. 34. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Size N | |||||
|---|---|---|---|---|---|
| 100 | 0.0 | 0.05 | 0.09 | 0.59 | 0.7 |
| 500 | 0.0 | 0.0 | 0.0 | 1.0 | 0.99 |
| 1000 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 |
| 2000 | 0.0 | 0.0 | 0.0 | 0.98 | 1.0 |
| 3000 | 0.0 | 0.0 | 0.0 | 0.7 | 1.0 |
| 4000 | 0.0 | 0.0 | 0.0 | 0.57 | 1.0 |
| Class | critical | critical | critical | insignificant | insignificant |
| N = 500 | N = 1000 | |||
|---|---|---|---|---|
| Time (Min) | Memory (MB) | Time (Min) | Memory (MB) | |
| Sobol | 256 | 495 | 901 | 907 |
| Energy distance | 40 | 340 | 150 | 611 |
| Regional | 35 | 280 | 121 | 547 |
| Calculation Time | Convergence Speed | Storage Space | Specificity | |
|---|---|---|---|---|
| Generalized Sobol | High | Slow | High | Can characterize interaction |
| Energy distance | Average | Fast | Average | Moment independant |
| Regional analysis | Low | Average | Low | Based on acceptability criterion |
| Adjustment | Distance D | Significance Level α | Class |
|---|---|---|---|
| Adjustment 1 | 0.34 | 0.0 | Critical |
| Adjustment 2 | 0.04 | 1 | Insignificant |
| Adjustment 3 | 0.08 | 0.63 | Insignificant |
| Adjustment 4 | 0.1 | 0.37 | Insignificant |
| Adjustment 5 | 0.27 | 0.0 | Critical |
| Adjustment 6 | 0.6 | 0.0 | Critical |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saad, S.; Ossart, F.; Bigeon, J.; Sourdille, E.; Gance, H. Global Sensitivity Analysis Applied to Train Traffic Rescheduling: A Comparative Study. Energies 2021, 14, 6420. https://doi.org/10.3390/en14196420
Saad S, Ossart F, Bigeon J, Sourdille E, Gance H. Global Sensitivity Analysis Applied to Train Traffic Rescheduling: A Comparative Study. Energies. 2021; 14(19):6420. https://doi.org/10.3390/en14196420
Chicago/Turabian StyleSaad, Soha, Florence Ossart, Jean Bigeon, Etienne Sourdille, and Harold Gance. 2021. "Global Sensitivity Analysis Applied to Train Traffic Rescheduling: A Comparative Study" Energies 14, no. 19: 6420. https://doi.org/10.3390/en14196420