
Performance Evaluation of Forecasting Strategies for Electricity Consumption in Buildings

Abstract
:1. Introduction
- Investigation of the three approaches, univariate, multivariate and multistep, for efficient load forecasting.
- A comparative analysis of three representative algorithms: LSTM, SARIMA and XGBOOST, have been examined in terms of accuracy and computational time/complexity.
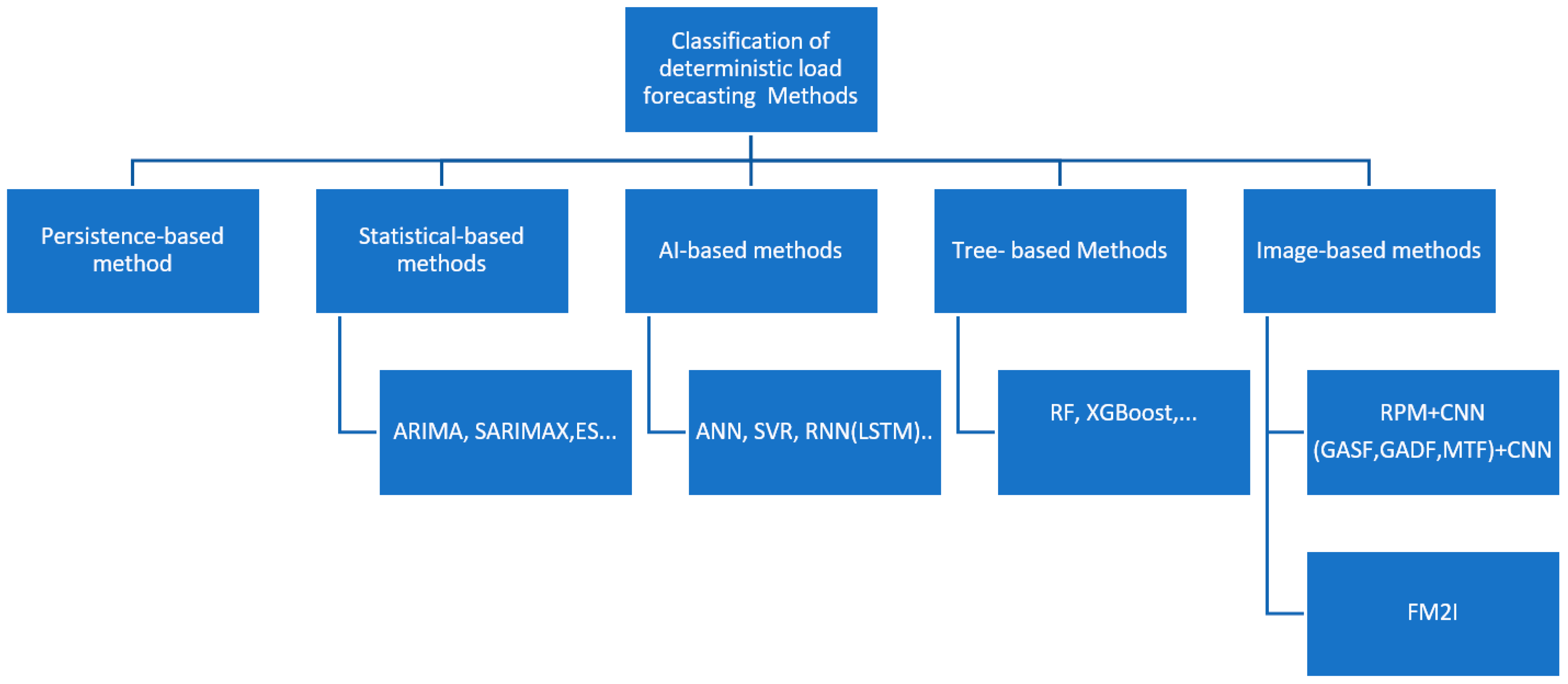
2. Forecasting Methods: An Overview
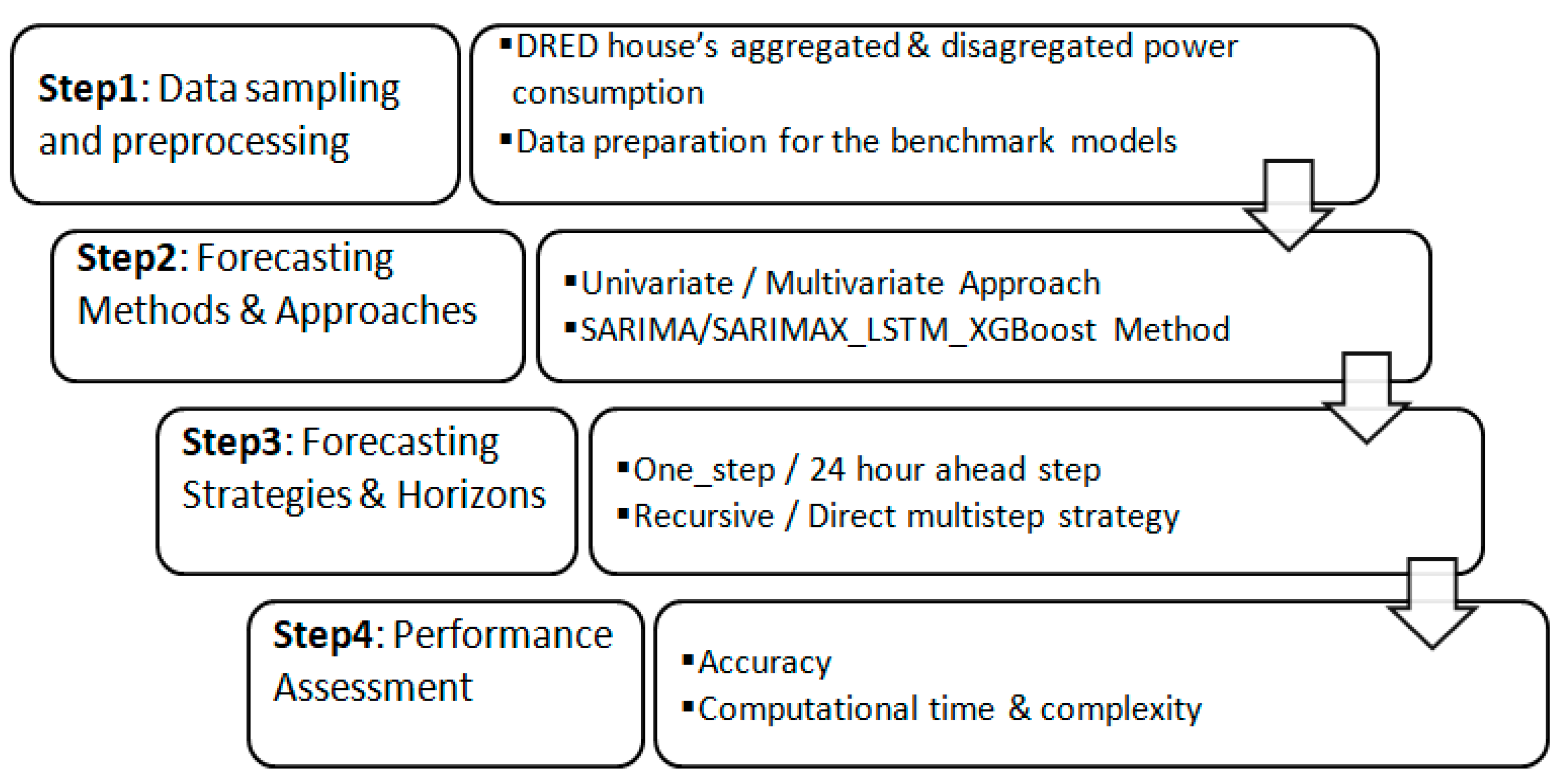
3. Materials and Methods
3.1. Power Consumption Dataset
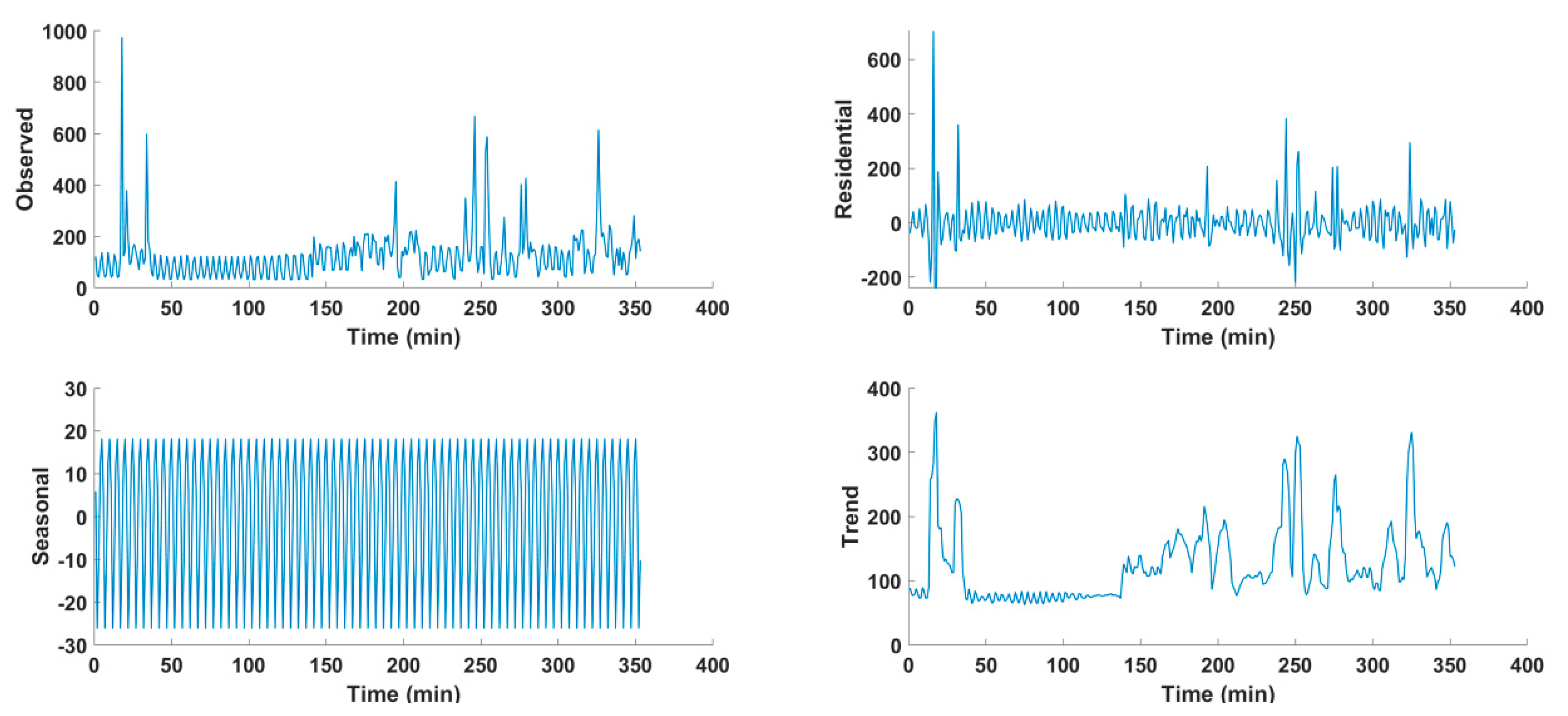
3.2. Dataset Sample Preprocessing and Feature Engineering
3.3. SARIMA, LSTM and XGBOOST
4. Results and Discussion
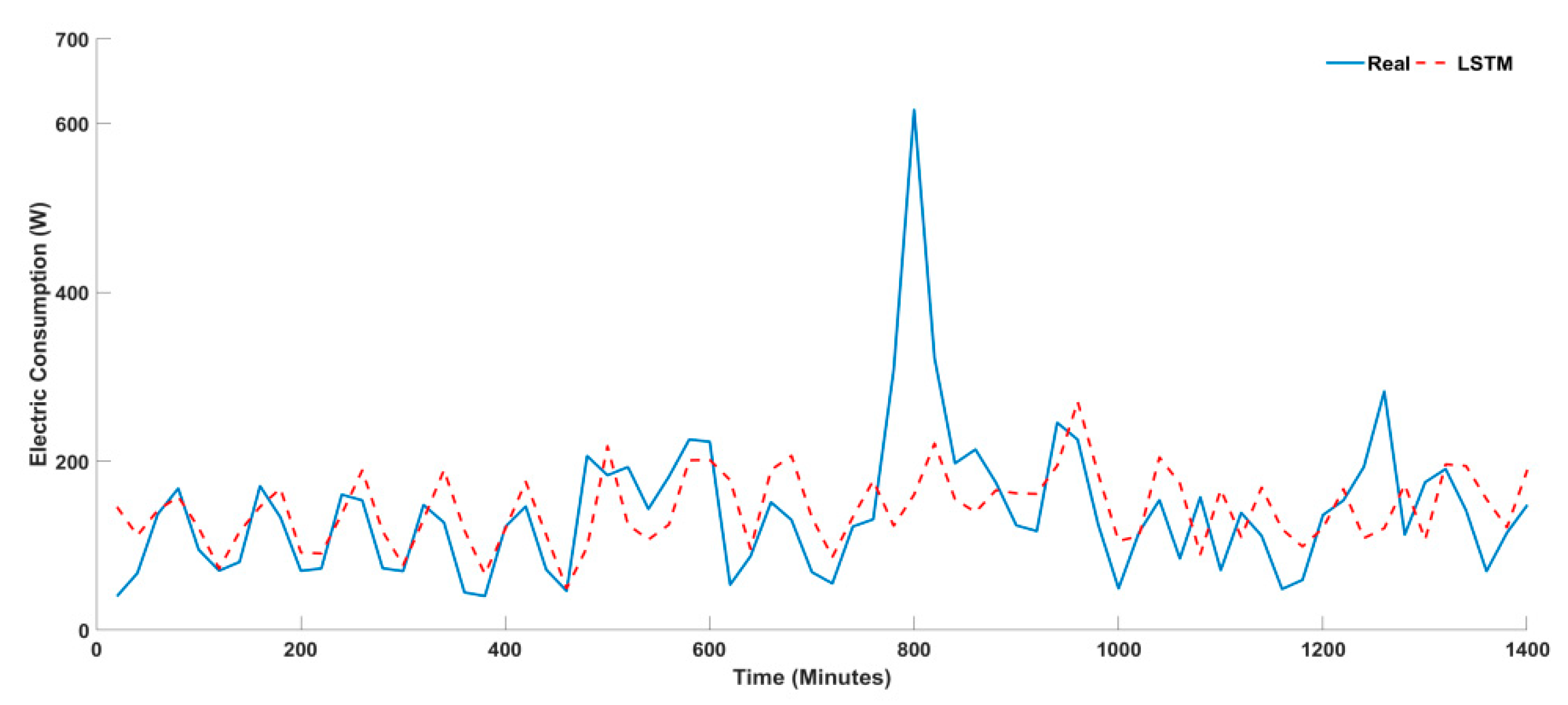
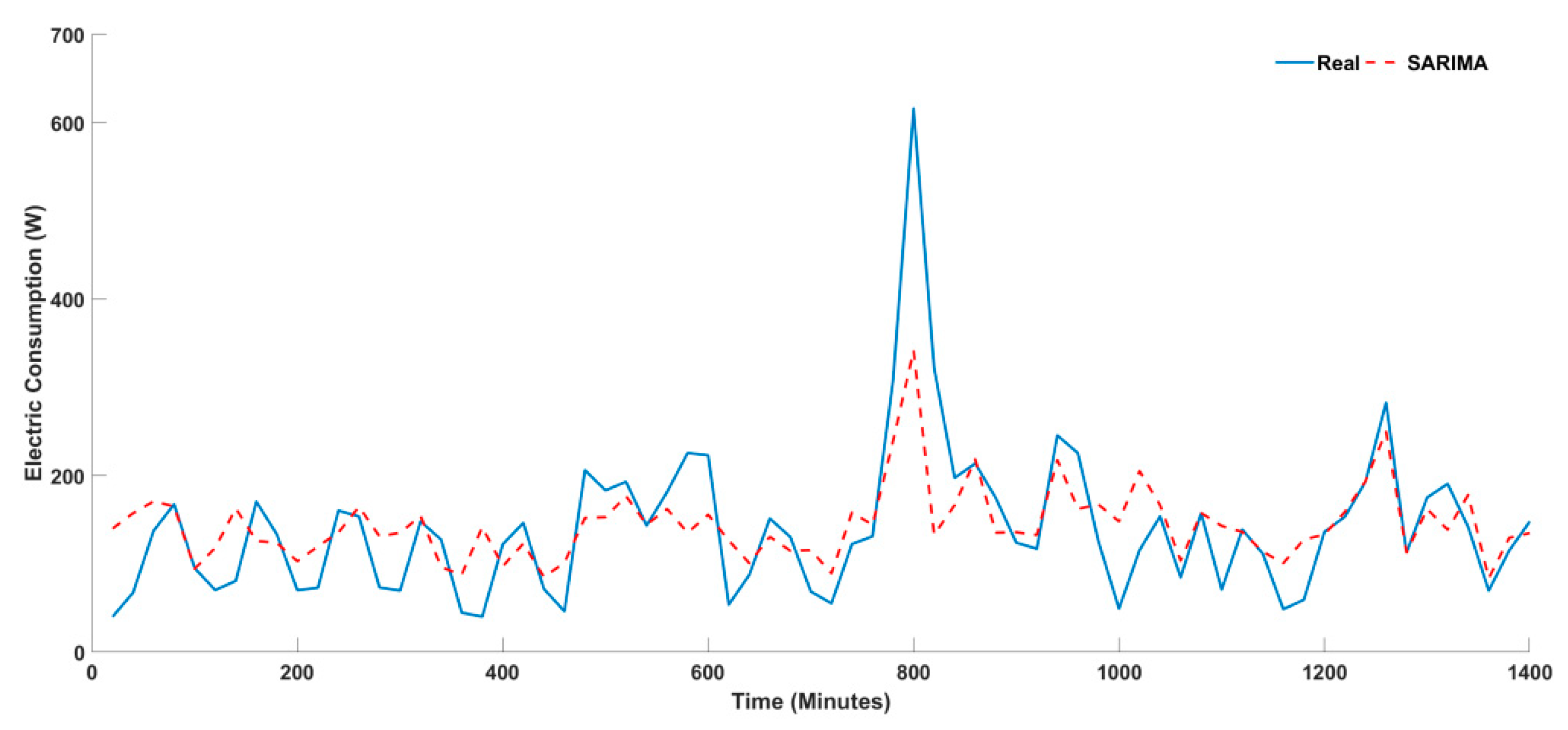
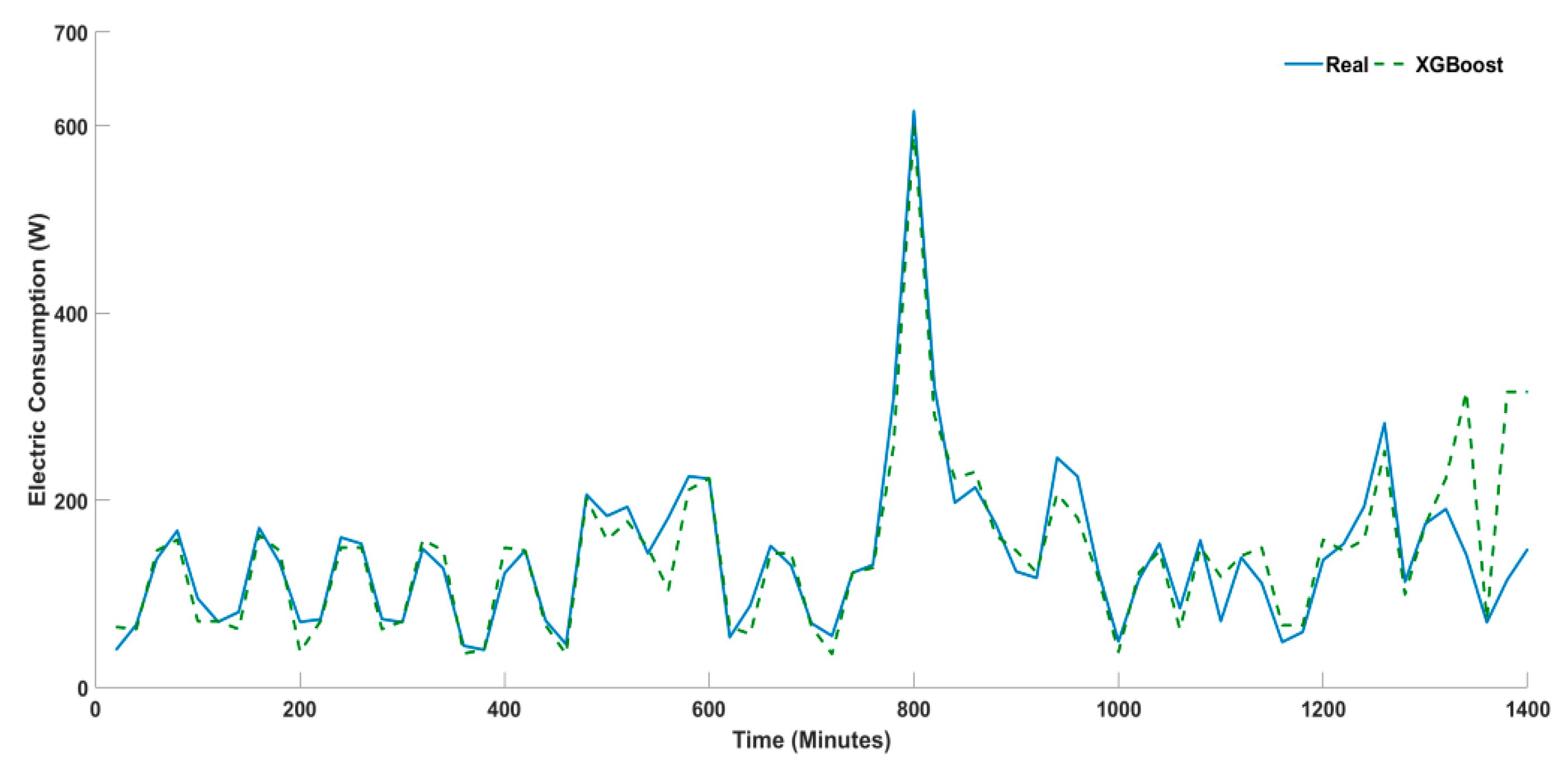
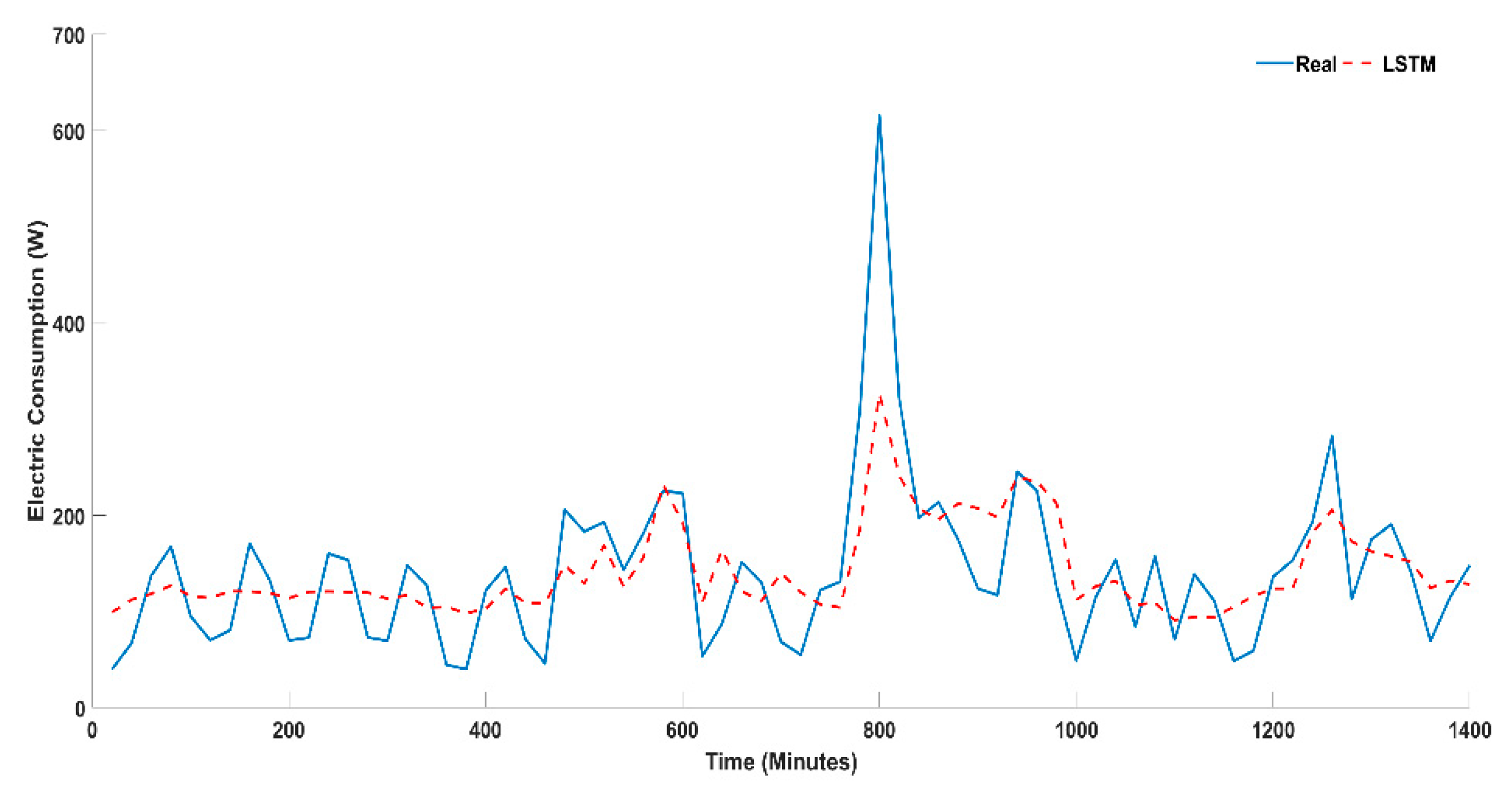
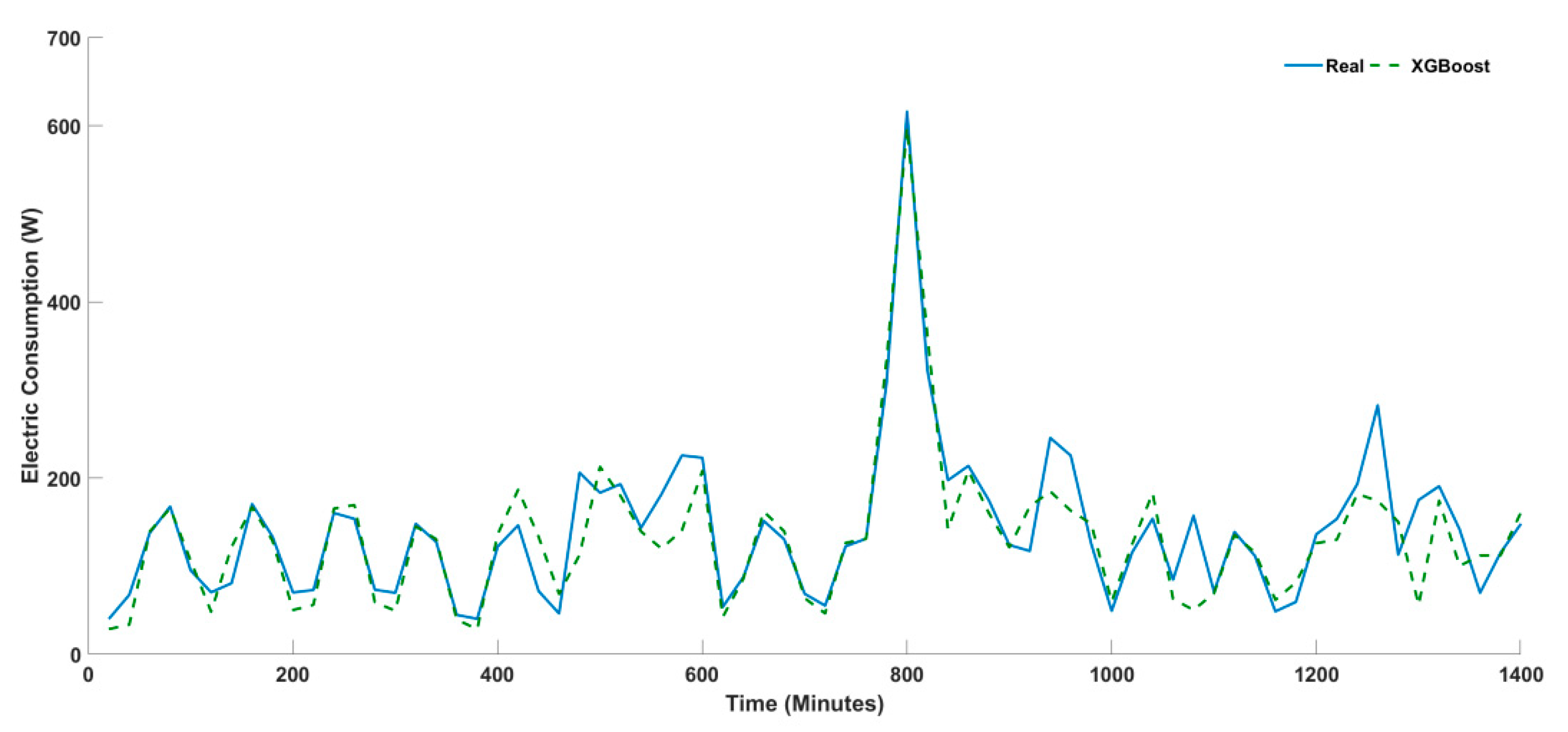
4.1. Univariate Timeseries Forecasting
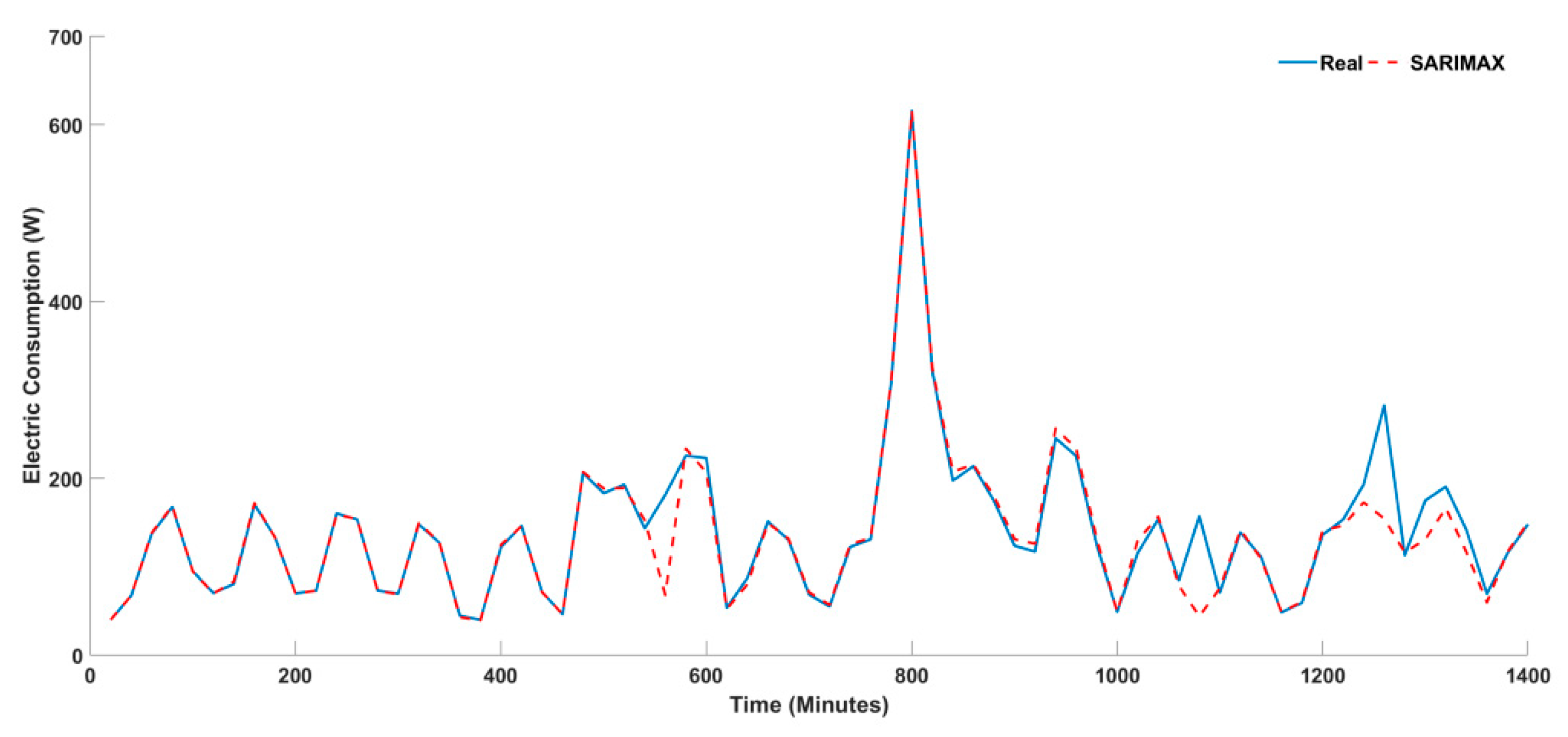
4.2. Multivariate Timeseries Forecasting
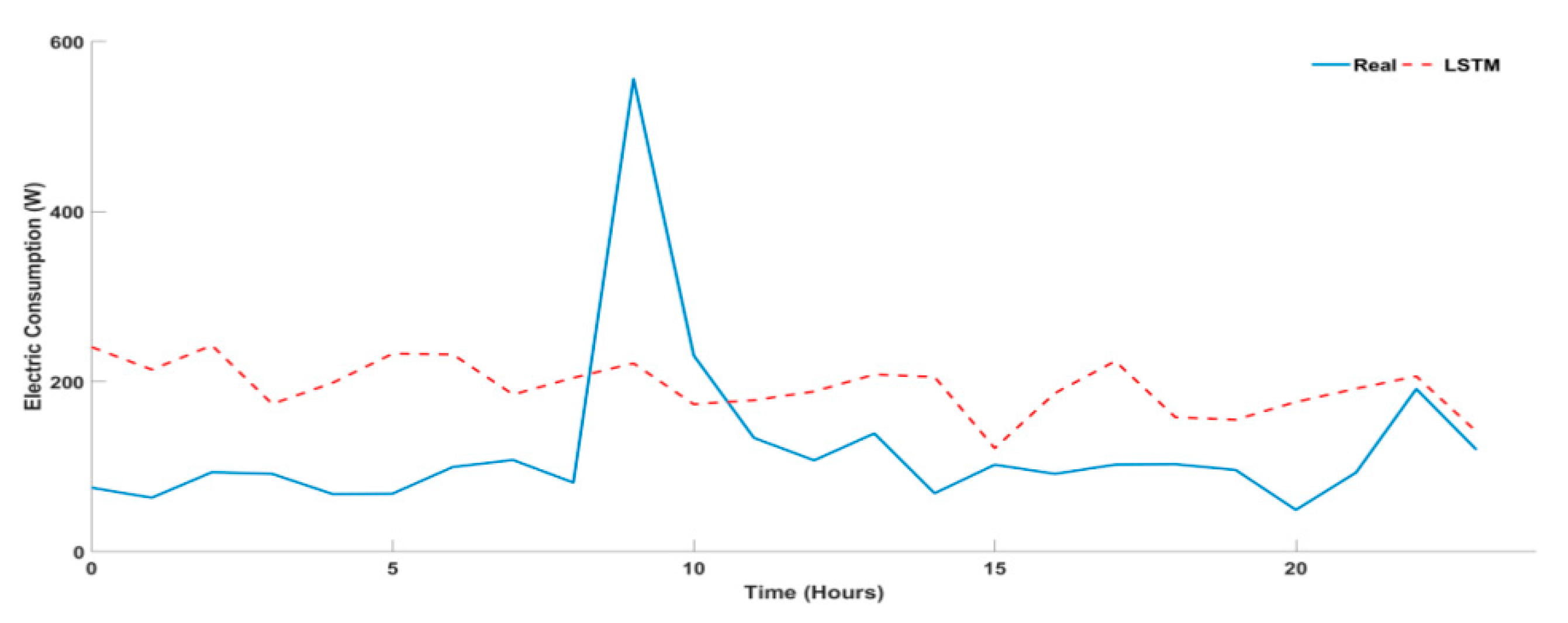
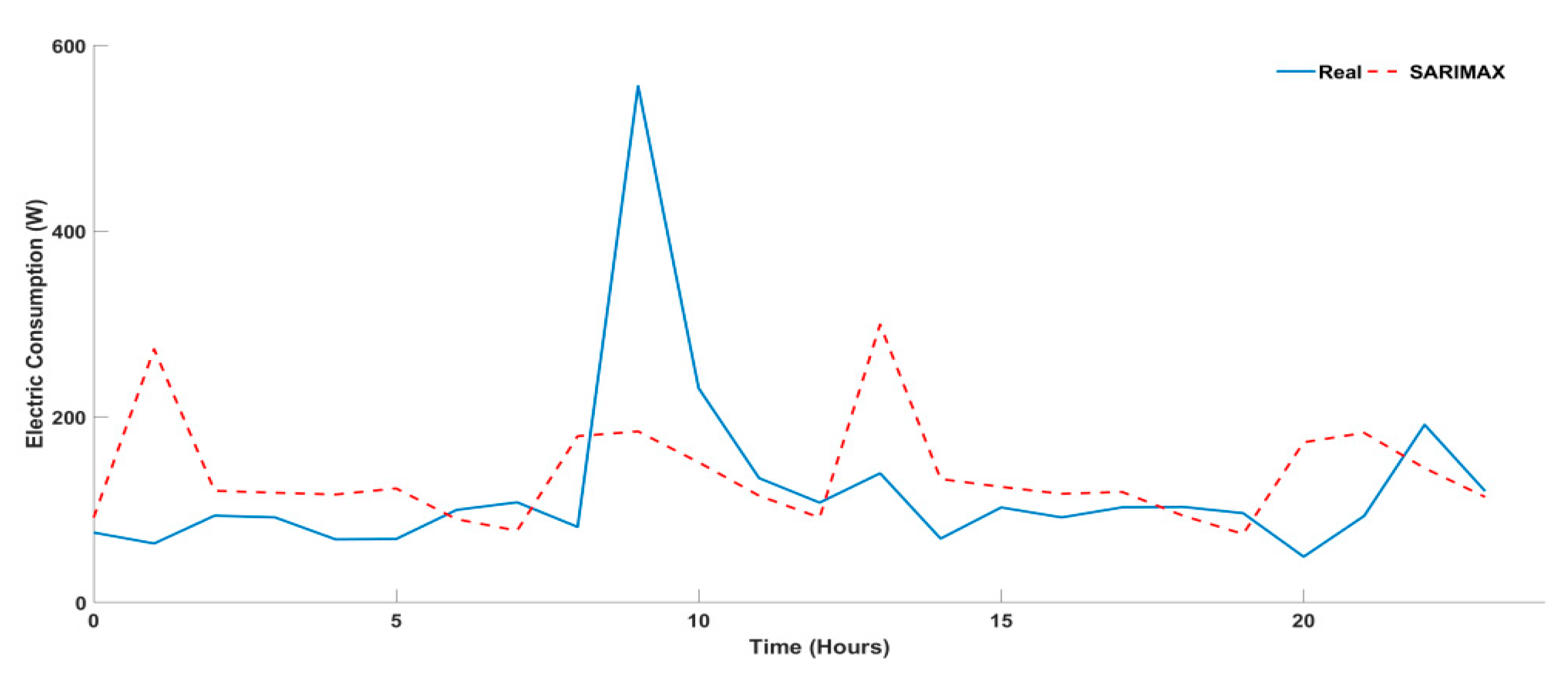
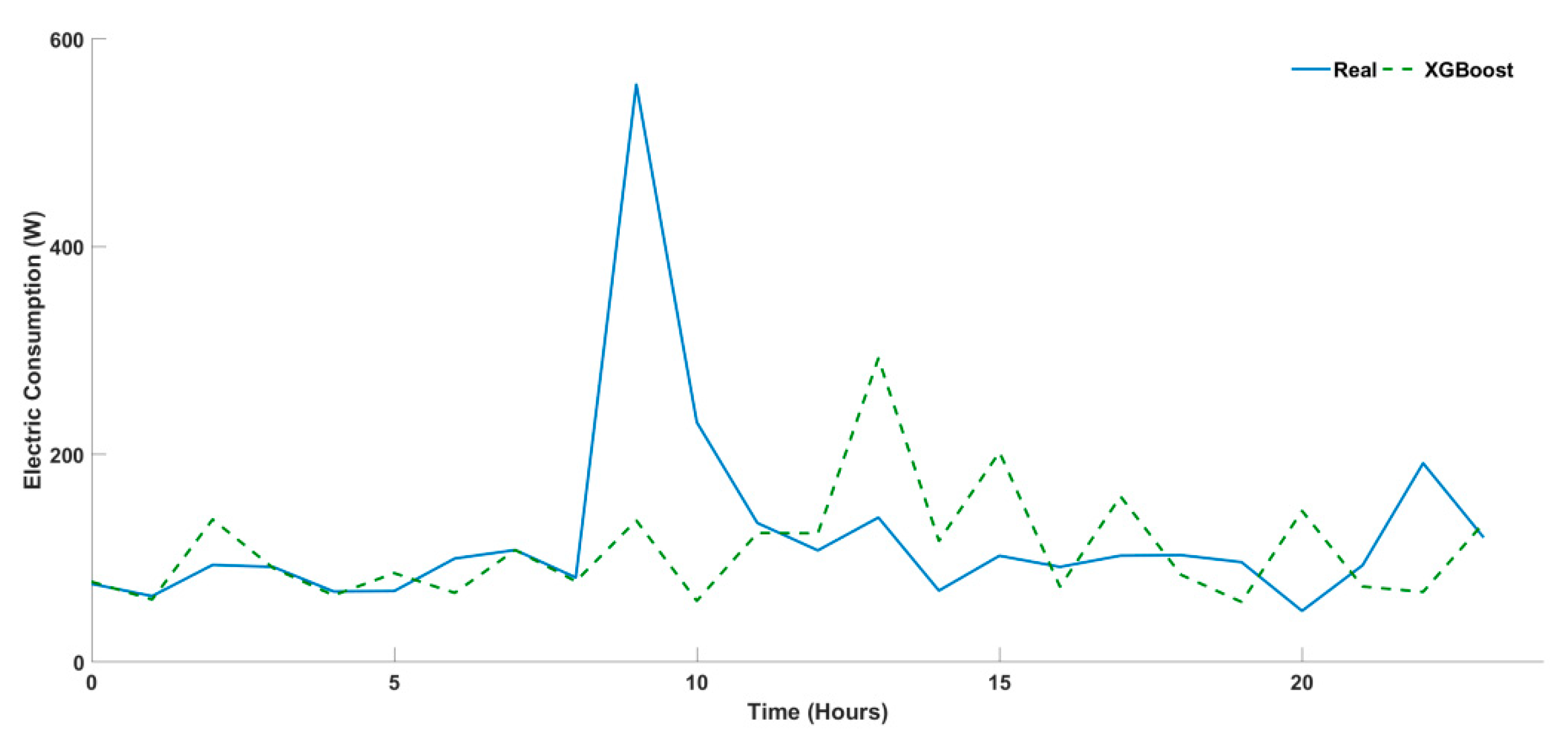
4.3. Univariate Time Series for Multi-Step Approach
5. Conclusions and Perspectives
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Iwafune, Y.; Yagita, Y.; Ikegami, T.; Ogimoto, K. Short-term forecasting of residential building load for distributed energy management. In Proceedings of the 2014 IEEE International Energy Conference (ENERGYCON), Cavtat, Croatia, 13–16 May 2014; pp. 1197–1204. [Google Scholar]
- Gajowniczek, K.; Za̧bkowski, T.; Szupiluk, R. Blind Source Separation for Improved Load Forecasting on Individual Household Level. Adv. Intell. Syst. Comput. 2016, 403, 181–190. [Google Scholar]
- Malekizadeh, M.; Karami, H.; Karimi, M.; Moshari, A.; Sanjari, M.J. Short-term load forecast using ensemble neuro-fuzzy model. Energy 2020, 196, 117127. [Google Scholar] [CrossRef]
- Lusis, P.; Khalilpour, R.; Andrew, L.; Liebman, A. Short-term residential load forecasting: Impact of calendar effects and forecast granularity. Appl. Energy 2017, 205, 654–669. [Google Scholar] [CrossRef]
- Dumas, J.; Cornélusse, B. Classification of load forecasting studies by forecasting problem to select load forecasting techniques and methodologies. arXiv 2018, arXiv:1901.05052. [Google Scholar]
- Hong, T.; Fan, S. Probabilistic electric load forecasting: A tutorial review. Int. J. Forecast. 2016, 32, 914–938. [Google Scholar] [CrossRef]
- Haq, I.; Ullah, A.; Khan, S.; Khan, N.; Lee, M.; Rho, S.; Baik, S. Sequential Learning-Based Energy Consumption Prediction Model for Residential and Commercial Sectors. Mathematics 2021, 9, 605. [Google Scholar] [CrossRef]
- Chakhchoukh, Y.; Panciatici, P.; Mili, L. Electric Load Forecasting Based on Statistical Robust Methods. IEEE Trans. Power Syst. 2011, 26, 982–991. [Google Scholar] [CrossRef]
- Yuce, B.; Mourshed, M.; Rezgui, Y. A Smart Forecasting Approach to District Energy Management. Energies 2017, 10, 1073. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, A.; Khalid, M. Multi-step Ahead Wind Forecasting Using Nonlinear Autoregressive Neural Networks. Energy Procedia 2017, 134, 192–204. [Google Scholar] [CrossRef]
- Majidpour, M.; Nazaripouya, H.; Chu, P.; Pota, H.R.; Gadh, R. Fast Univariate Time Series Prediction of Solar Power for Real-Time Control of Energy Storage System. Forecasting 2018, 1, 107–120. [Google Scholar] [CrossRef] [Green Version]
- Elmouatamid, A.; NaitMalek, Y.; Bakhouya, M.; Ouladsine, R.; Elkamoun, N.; Zine-Dine, K.; Khaidar, M. An energy management platform for micro-grid systems using Internet of Things and Big-data technologies. Proc. Inst. Mech. Eng. Part I J. Syst. Control. Eng. 2019, 233, 904–917. [Google Scholar] [CrossRef]
- Cai, M.; Pipattanasomporn, M.; Rahman, S. Day-ahead building-level load forecasts using deep learning vs. traditional time-series techniques. Appl. Energy 2019, 236, 1078–1088. [Google Scholar] [CrossRef]
- Mtibaa, F.; Nguyen, K.-K.; Azam, M.; Papachristou, A.; Venne, J.-S.; Cheriet, M. LSTM-based indoor air temperature prediction framework for HVAC systems in smart buildings. Neural Comput. Appl. 2020, 32, 1–17. [Google Scholar] [CrossRef]
- Xue, P.; Jiang, Y.; Zhou, Z.; Chen, X.; Fang, X.; Liu, J. Multi-step ahead forecasting of heat load in district heating systems using machine learning algorithms. Energy 2019, 188, 116085. [Google Scholar] [CrossRef]
- Abdel-Aal, R. Univariate modeling and forecasting of monthly energy demand time series using abductive and neural networks. Comput. Ind. Eng. 2008, 54, 903–917. [Google Scholar] [CrossRef]
- Chaouch, M. Clustering-Based Improvement of Nonparametric Functional Time Series Forecasting: Application to Intra-Day Household-Level Load Curves. IEEE Trans. Smart Grid 2014, 5, 411–419. [Google Scholar] [CrossRef]
- Ghofrani, M.; Hassanzadeh, M.; Etezadi-Amoli, M.; Fadali, M.S. Smart meter based short-term load forecasting for residential customers. In Proceedings of the North American Power Symposium, Boston, MA, USA, 4–6 August 2011; pp. 1–5. [Google Scholar] [CrossRef]
- Teeraratkul, T.; O’Neill, D.; Lall, S. Shape-Based Approach to Household Electric Load Curve Clustering and Prediction. IEEE Trans. Smart Grid 2018, 9, 5196–5206. [Google Scholar] [CrossRef]
- Haben, S.; Ward, J.; Greetham, D.V.; Singleton, C.; Grindrod, P. A new error measure for forecasts of household-level, high resolution electrical energy consumption. Int. J. Forecast. 2014, 30, 246–256. [Google Scholar] [CrossRef] [Green Version]
- Quilumba, F.; Lee, W.-J.; Huang, H.; Wang, D.Y.; Szabados, R.L. Using Smart Meter Data to Improve the Accuracy of Intraday Load Forecasting Considering Customer Behavior Similarities. IEEE Trans. Smart Grid 2015, 6, 911–918. [Google Scholar] [CrossRef]
- Da Silva, P.G.; Ilic, D.; Karnouskos, S. The Impact of Smart Grid Prosumer Grouping on Forecasting Accuracy and Its Benefits for Local Electricity Market Trading. IEEE Trans. Smart Grid 2013, 5, 402–410. [Google Scholar] [CrossRef]
- Chen, Y.; Luh, P.B.; Guan, C.; Zhao, Y.; Michel, L.D.; Coolbeth, M.A.; Friedland, P.B.; Rourke, S.J. Short-Term Load Forecasting: Similar Day-Based Wavelet Neural Networks. IEEE Trans. Power Syst. 2010, 25, 322–330. [Google Scholar] [CrossRef]
- Alotaibi, R.; Jin, N.; Wilcox, T.; Flach, P. Feature Construction and Calibration for Clustering Daily Load Curves from Smart-Meter Data. IEEE Trans. Ind. Inform. 2016, 12, 645–654. [Google Scholar] [CrossRef] [Green Version]
- Basu, K.; Hawarah, L.; Arghira, N.; Joumaa, H.; Ploix, S. A prediction system for home appliance usage. Energy Build. 2013, 67, 668–679. [Google Scholar] [CrossRef]
- Dinesh, C.; Makonin, S.; Bajic, I.V. Residential Power Forecasting Using Load Identification and Graph Spectral Clustering. IEEE Trans. Circuits Syst. II Express Briefs 2019, 66, 1900–1904. [Google Scholar] [CrossRef]
- Dutta, S.; Li, Y.; Venkataraman, A.; Costa, L.M.; Jiang, T.; Plana, R.; Tordjman, P.; Choo, F.H.; Foo, C.F.; Puttgen, H.B. Load and Renewable Energy Forecasting for a Microgrid using Persistence Technique. Energy Procedia 2017, 143, 617–622. [Google Scholar] [CrossRef]
- Hinman, J.; Hickey, E. Modeling and Forecasting Short-Term Electricity Load Using Regression Analysis; Illinois State University: Normal, IL, USA, 2009; pp. 1–51. [Google Scholar]
- Christiaanse, W.R. Short-Term Load Forecasting Using General Exponential Smoothing. IEEE Trans. Power Appar. Syst. 1971, 90, 900–911. [Google Scholar] [CrossRef]
- Chan, S.-C.; Tsui, K.M.; Wu, H.C.; Hou, Y.; Wu, Y.C.; Wu, F.F. Load/Price Forecasting and Managing Demand Response for Smart Grids: Methodologies and Challenges. IEEE Signal Process. Mag. 2012, 29, 68–85. [Google Scholar] [CrossRef]
- Khashei, M.; Bijari, M. An artificial neural network (p,d,q) model for timeseries forecasting. Expert Syst. Appl. 2010, 37, 479–489. [Google Scholar] [CrossRef]
- Yunpeng, L.; Hou, D.; Junpeng, B.; Yong, Q. Multi-step Ahead Time Series Forecasting for Different Data Patterns Based on LSTM Recurrent Neural Network. In Proceedings of the 2017 14th Web Information Systems and Applications Conference (WISA), Liuzhou, China, 11–12 November 2017; pp. 305–310. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Optimal Deep Learning LSTM Model for Electric Load Forecasting using Feature Selection and Genetic Algorithm: Comparison with Machine Learning Approaches. Energies 2018, 11, 1636. [Google Scholar] [CrossRef] [Green Version]
- Guolin, K.; Qi, M.; Thomas, F.; Taifeng, W.; Wei, C.; Weidong, M.; Qiwei, Y.; Tie-Yan, L. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Papadopoulos, S.; Azar, E.; Woon, W.L.; Kontokosta, C. Evaluation of tree-based ensemble learning algorithms for building energy performance estimation. J. Build. Perform. Simul. 2017, 11, 322–332. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery Data Mining KDD ’16, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Li, G.; Wenjia, L.; Tian, X.; Yifeng, C. Short-Term Electricity Load Forecasting Based on the XGBOOST Algorithm. Smart Grid 2017, 7, 274–285. [Google Scholar] [CrossRef]
- Song, Y.-Y.; Lu, Y. Decision tree methods: Applications for classification and prediction. Shanghai Arch Psychiatry 2015, 27, 130–135. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Kang, Y.; Li, F. Forecasting with time series imaging. Expert Syst. Appl. 2020, 160, 113680. [Google Scholar] [CrossRef]
- Yang, C.-L.; Zhi-Xuan, C.; Chen-Yi, Y. Sensor Classification Using Convolutional Neural Network by En-coding Multivariate Time Series as Two-Dimensional Colored Images. Sensors 2020, 20, 168. [Google Scholar] [CrossRef] [Green Version]
- Maaroufi, N.; Mehdi, N.; Mohamed, B. Predicting the Future is like Completing a Painting! arXiv 2020, arXiv:2011.04750. [Google Scholar]
- Nambi, A.S.N.U.; Lua, A.R.; Prasad, V.R. LocED: Location-aware Energy Dis-aggregation Framework. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments (BuildSys’15), Seoul, Korea, 4–5 November 2015; Association for Computing Machinery: New York, NY, USA, 2019; pp. 45–54. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Data Preprocessing for Supervised Learning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Mushtaq, R. Augmented Dickey Fuller Test. Econometrics: Mathematical Methods & Programming Ejournal; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference Learn. Represent. (ICLR), San Diego, CA, USA, 5–8 May 2015. [Google Scholar]
- Yan, K.; Wang, X.; Du, Y.; Jin, N.; Huang, H.; Zhou, H. Multi-Step Short-Term Power Consumption Forecasting with a Hybrid Deep Learning Strategy. Energies 2018, 11, 3089. [Google Scholar] [CrossRef] [Green Version]
- Taieb, S.B.; Hyndman, R.J. Recursive and Direct Multi-Step Forecasting: The Best of Both Worlds; Monash University, Department of Econometrics and Business Statistics: Clayton, Australia, 2012. [Google Scholar]
- Sorjamaa, A.; Lendasse, A. Time Series Prediction using DirRec Strategy. In Proceedings of the 2006 European Symposium on Artificial Neural Networks, Bruges, Belgium, 26–28 April 2006; pp. 143–148. [Google Scholar]
- Ben Taieb, S.; Sorjamaa, A.; Bontempi, G. Multiple-output modeling for multi-step-ahead time series forecasting. Neurocomputing 2010, 73, 1950–1957. [Google Scholar] [CrossRef]
- Bao, Y.; Xiong, T.; Hu, Z. PSO-MISMO modeling strategy for multistep-ahead time series prediction. IEEE Trans. Cybern. 2013, 44, 655–668. [Google Scholar]
- Botchkarev, A. Performance metrics (error measures) in machine learning regression, forecasting and prognostics: Properties and typology. Interdiscip. JInfo. Knowl. Manag. 2018, 14, 45–79. [Google Scholar] [CrossRef] [Green Version]
- Divina, F.; Torres, M.G.; Vela, F.A.G.; Noguera, J.L.V. A Comparative Study of Time Series Forecasting Methods for Short Term Electric Energy Consumption Prediction in Smart Buildings. Energies 2019, 12, 1934. [Google Scholar] [CrossRef] [Green Version]
- Alden, R.E.; Gong, H.; Ababei, C.; Ionel, D.M. LSTM Forecasts for Smart Home Electricity Usage. In Proceedings of the 2020 9th International Conference on Renewable Energy Research and Application (ICRERA), Ankaya, Turkey, 26–29 September 2020; pp. 434–438. [Google Scholar]
- Hyndman, R.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef] [Green Version]
- Kong, W.; Dong, Z.Y.; Hill, D.J.; Luo, F.; Xu, Y. Short-Term Residential Load Forecasting Based on Resident Behaviour Learning. IEEE Trans. Power Syst. 2018, 33, 1087–1088. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, S.; Yuan, M.; Zeng, J.; Yao, J.; Lyu, M.R.; King, I. Traffic Prediction Based Power Saving in Cellular Networks. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; p. 29. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Forecasting Method | Application Domain | |||
|---|---|---|---|---|---|
| Univariate | Multivariate | One-Step | Multistep | ||
| [8] | SARIMA | Electricity consumption | |||
| [9] | ANN | District energy management | |||
| [10] | Nonlinear ANN | Wind Forecasting | |||
| [11] | ARIMA_KNN SVR_RF | Solar power generation | |||
| [12] | ARIMA | Micro-Grid Systems | |||
| [13] | RNN_CNN SARIMAX | Commercial buildings load | |||
| [14] | LSTM (MISO) & (MIMO) | HVAC systems | |||
| [15] | SVR XGBOOST | District heat systems | |||
| [16] | ANN | Energy demand forecasting | |||
| Method | RMSE | MAE | MAPE | MPE | sMAPE | MASE | Ranking | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | MAPE | MPE | sMAPE | MASE | |||||||
| LSTM | 35.412 | 10.304 | 8.930 | 5.146 | 36.712 | 0.852 | 3 | 3 | 3 | 3 | 3 | 3 |
| SARIMA | 26.375 | 7.988 | 8.319 | −5.355 | 31.075 | 0.656 | 2 | 2 | 2 | 1 | 2 | 2 |
| XGBOOST | 19.030 | 4.495 | 3.716 | −0.789 | 16.886 | 0.372 | 1 | 1 | 1 | 2 | 1 | 1 |
| Method | Computational Time (s) | CC |
|---|---|---|
| SARIMA | 5.85 | 83.58 |
| LSTM | 2.85 | 40.72 |
| XGBOOST | 0.12 | 1.72 |
| Method | RMSE | MAE | MAPE | MPE | sMAPE | MASE | Ranking | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | MAPE | MPE | sMAPE | MASE | |||||||
| LSTM | 25.296 | 8.365 | 8.268 | −4.448 | 33.610 | 0.692 | 3 | 3 | 3 | 1 | 3 | 3 |
| XGBOOST | 16.332 | 4.918 | 3.952 | 0.687 | 21.266 | 0.402 | 2 | 2 | 2 | 3 | 2 | 2 |
| SARIMAX | 11.471 | 1.905 | 1.162 | 0.544 | 7.217 | 0.157 | 1 | 1 | 1 | 2 | 1 | 1 |
| Method | Computational Time (s) | CC |
|---|---|---|
| SARIMAX | 11.83 | 131.45 |
| LSTM | 3.36 | 37.34 |
| XGBOOST | 0.24 | 2.67 |
| Method | RMSE | MAE | MAPE | MPE | sMAPE | MASE | Ranking | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | MAPE | MPE | sMAPE | MASE | |||||||
| LSTM | 50.453 | 17.439 | 18.635 | 17.454 | 65.925 | 1.623 | 3 | 3 | 3 | 3 | 3 | 3 |
| XGBOOST | 43.787 | 9.827 | 6.964 | −1.789 | 39.028 | 0.915 | 2 | 1 | 1 | 1 | 1 | 1 |
| SARIMAX | 42.826 | 11.066 | 10.638 | 7.427 | 43.211 | 1.029 | 1 | 2 | 2 | 2 | 2 | 2 |
| Method | Computational Time (s) | CC |
|---|---|---|
| SARIMAX | 14.05 | 8.363 |
| LSTM | 23.36 | 13.904 |
| XGBOOST (Recursive) | 2.67 | 1.589 |
| XGBOOST(With hyperparameter optimization function) | 52.03 | 30.970 |
| XGBOOST(Direct) | 612.63 | 364.661 |
| Forecast Horizon (H) | Computational Time for XGBOOST (Direct Strategy) (s) | CC | sMAPE (%) |  |
| 4 steps | 110.46 | 65.75 | 39.53 | |
| 8 steps | 234.95 | 139.85 | 33.11 | |
| 12 steps | 325.09 | 193.51 | 40.07 | |
| 16 steps | 401.58 | 239.04 | 38.35 | |
| 20 steps | 512.03 | 304.78 | 45.58 | |
| 24 steps | 612.63 | 364.67 | 39.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hadri, S.; Najib, M.; Bakhouya, M.; Fakhri, Y.; El Arroussi, M. Performance Evaluation of Forecasting Strategies for Electricity Consumption in Buildings. Energies 2021, 14, 5831. https://doi.org/10.3390/en14185831
Hadri S, Najib M, Bakhouya M, Fakhri Y, El Arroussi M. Performance Evaluation of Forecasting Strategies for Electricity Consumption in Buildings. Energies. 2021; 14(18):5831. https://doi.org/10.3390/en14185831
Chicago/Turabian StyleHadri, Sarah, Mehdi Najib, Mohamed Bakhouya, Youssef Fakhri, and Mohamed El Arroussi. 2021. "Performance Evaluation of Forecasting Strategies for Electricity Consumption in Buildings" Energies 14, no. 18: 5831. https://doi.org/10.3390/en14185831