
A Machine Learning-Based Gradient Boosting Regression Approach for Wind Power Production Forecasting: A Step towards Smart Grid Environments



Abstract
:1. Introduction
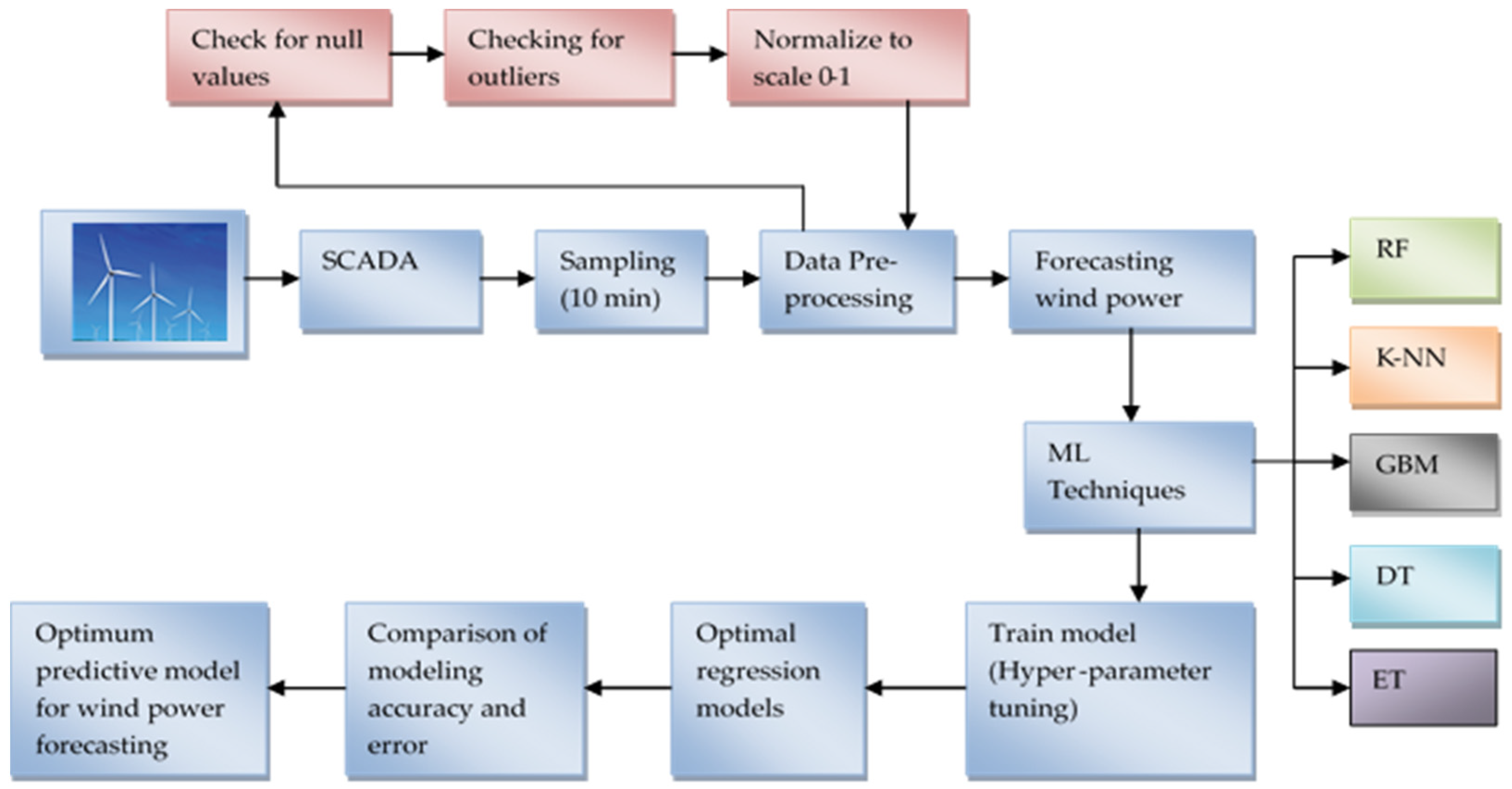
2. Proposed Model
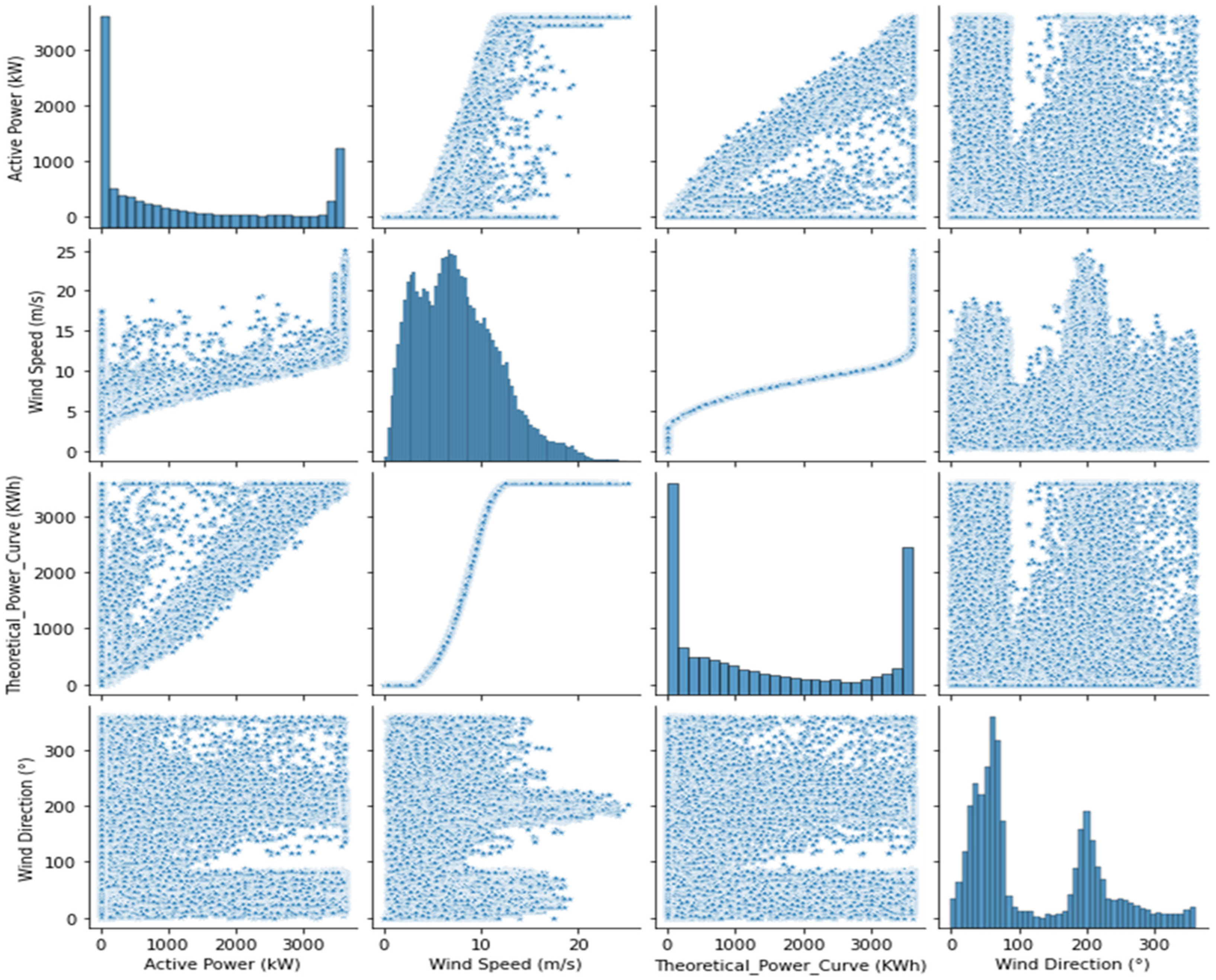
2.1. Input Metrological Parameters
2.2. Predictive Analysis
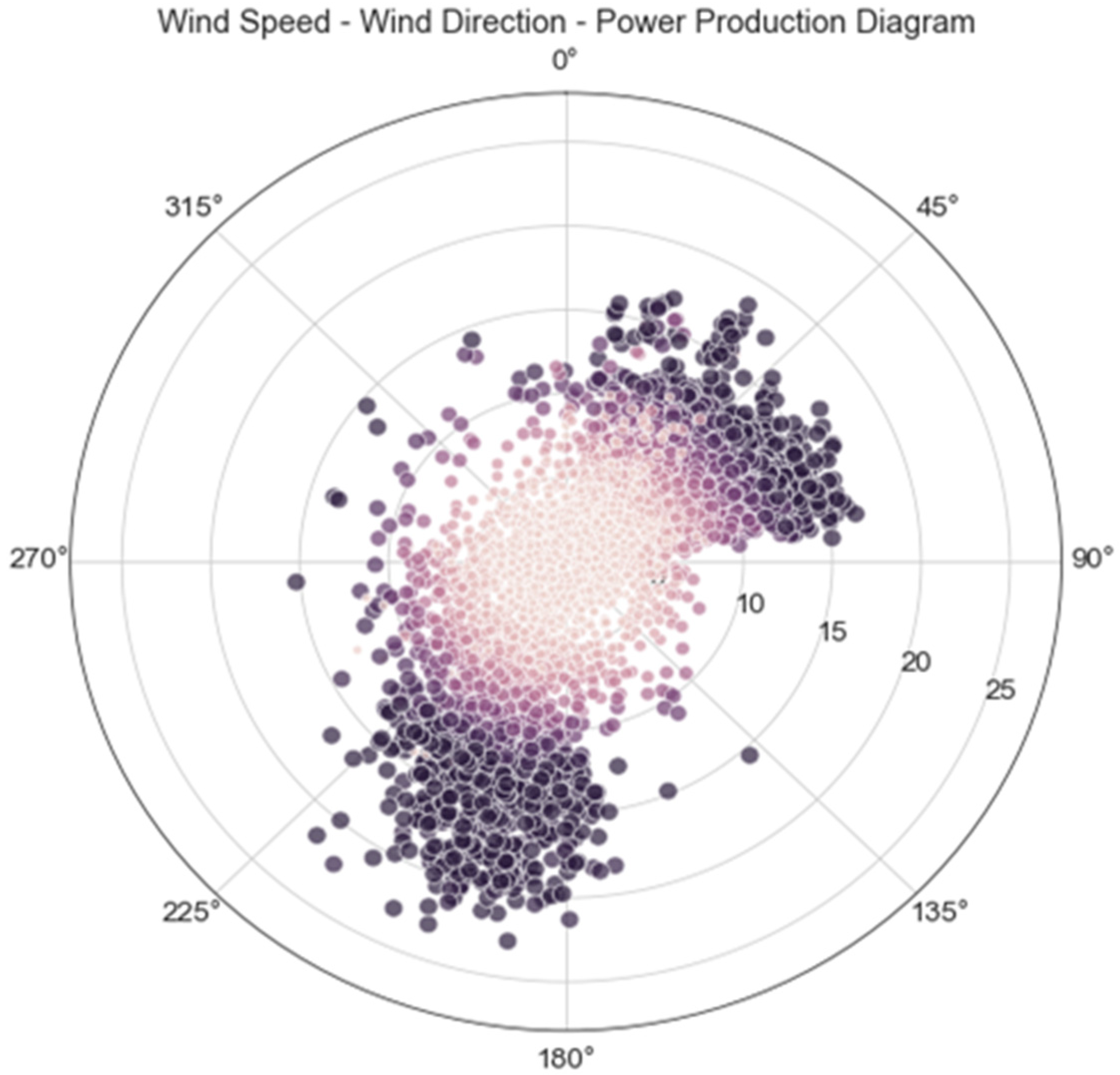
2.3. Analysis in Polar Coordinates
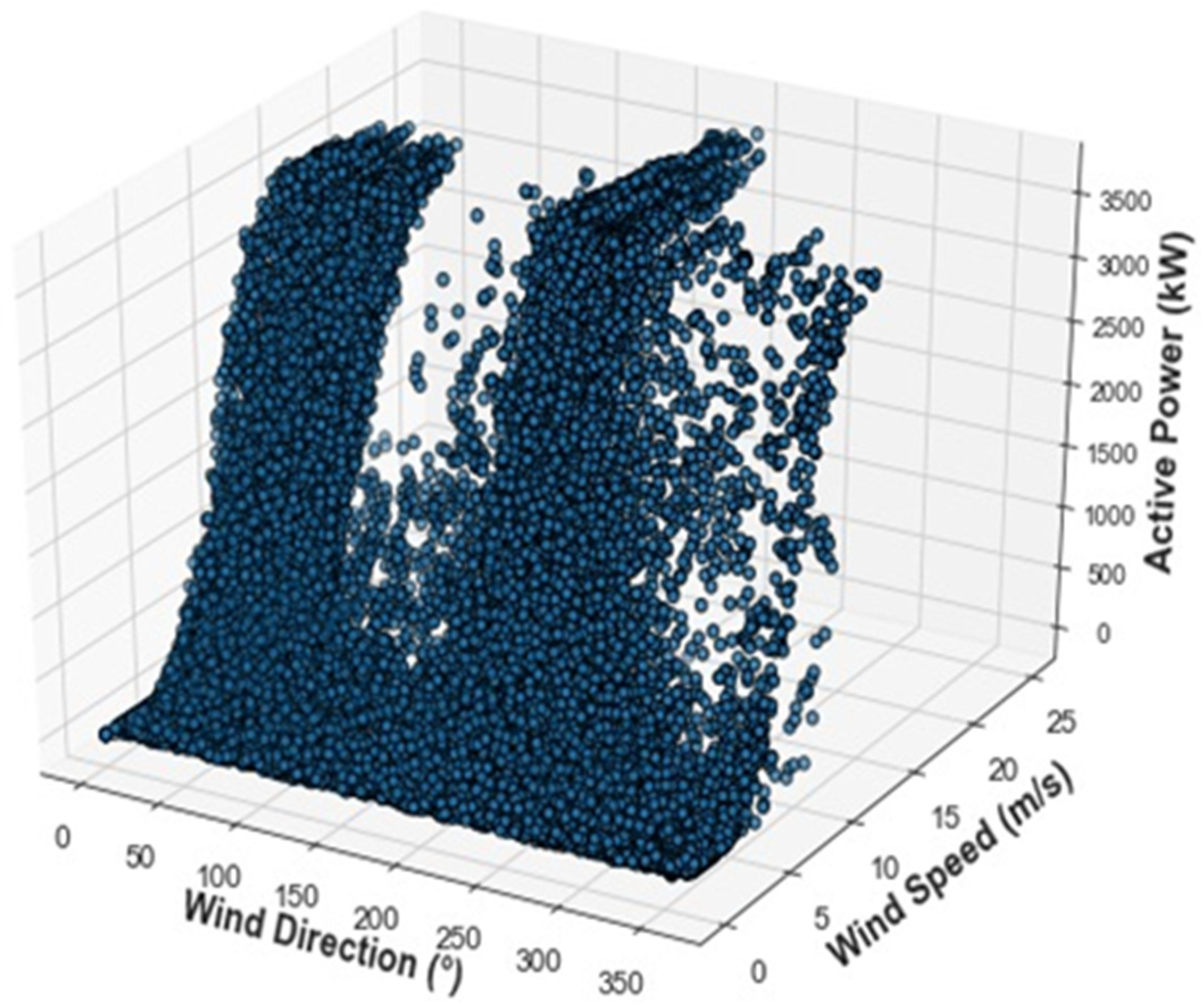
2.4. Analysis in Cartesian Coordinates
3. SCADA Pre-Processing
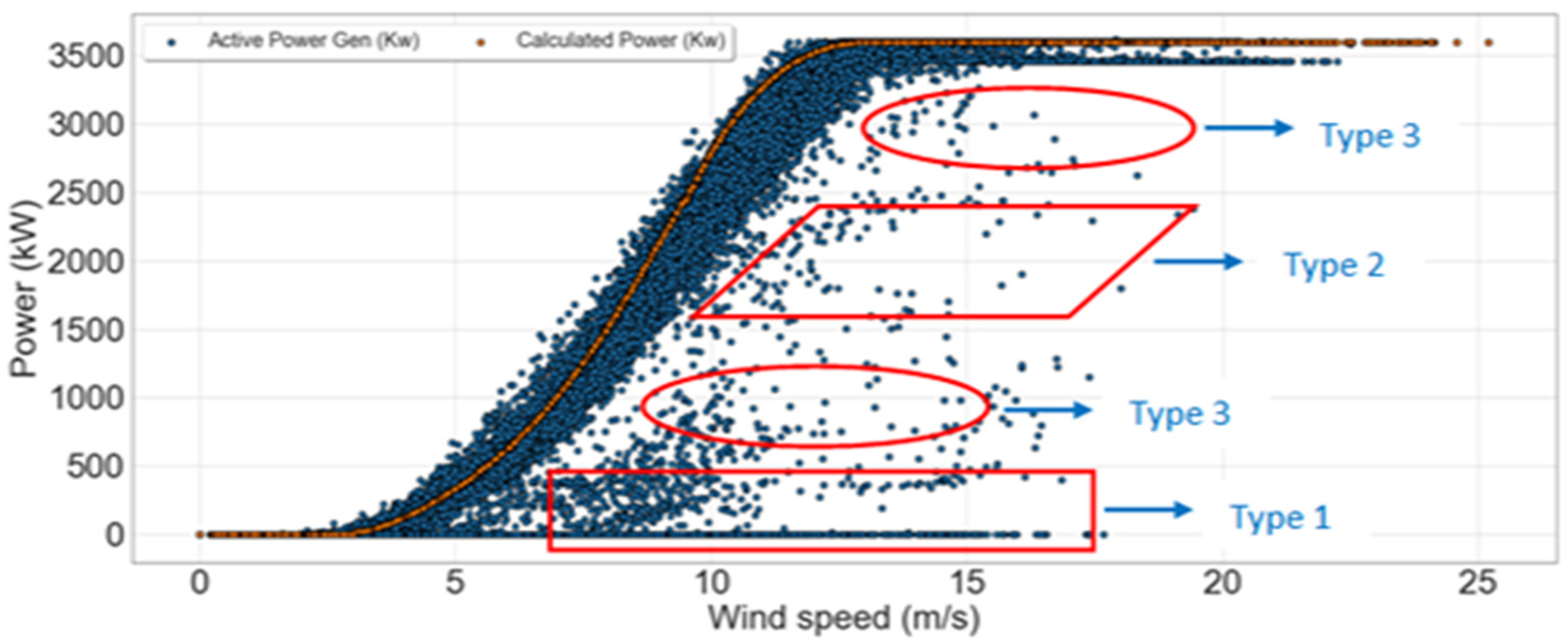
- Outlier removal: The procedure of cleaning and preparing the raw data to make it compatible for training or developing machine learning models is called data preprocessing. To limit the impact of noise and turbulence, a sampling rate of 10 min was used when processing the SCADA data; however, deep analysis of individual parameters identified certain errors in the SCADA data, such as, power production being zero above the cut-in speed (i.e., 3 m/s), negative values of wind speed, or active power and missing data at some timestamps. These results carry no practical significance in terms of the generation of power. As such, to prevent a negative impact on the forecasting, data points belonging to the same timestamp have been removed. Such erroneous data points are commonly the result of wind farm maintenance, sensor malfunction, degradation, or system processing errors. It is crucial that the SCADA data are pre-processed prior to developing the forecasting models.
- Normalization of dataset: The input parameters of the wind power forecasting model incorporate the wind speed and wind direction, but their dimensions are not of the same order of magnitude. Hence, it is essential to regulate these input vectors to be within in the same order of magnitude. As such, a min-max approach was used to normalize the input vectors as follows:where the actual data is given by and and represent the minimum and maximum values of the dataset. The result remains within the range of [0,1].
4. Machine Learning
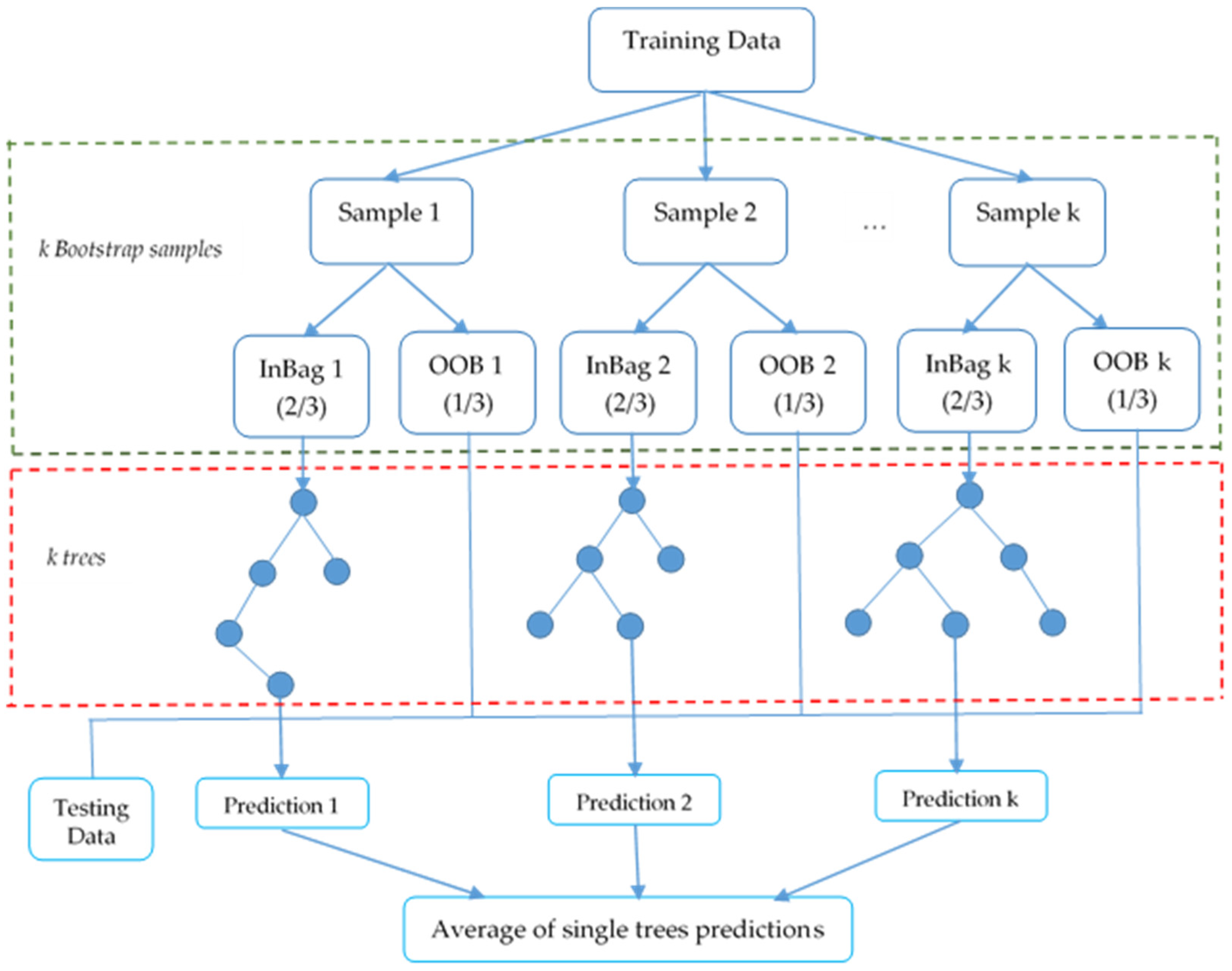
4.1. Random Forest Regression
- Produce ntree bootstrap samples from the actual input dataset;
- For individual bootstrap samples, expand an unpruned regression tree, including subsequent alteration at every node, instead of selecting the best split among all predictors. Arbitrarily sample mtry predictors and then select the best split from those variables. (“Bagging” can be considered a special case of RF and where mtry = p predictors. Bagging refers to bootstrap aggregating, i.e., building multiple distinct decision trees from training dataset by frequently utilizing multiple bootstrapped subsets of the dataset after averaging the models);
- Estimate new data values by averaging the predictions of the ntree, decision trees (i.e., “average” in case of problems of regression and the “majority of votes” for classification problems);
- Based on the training data, the error rate can be anticipated using the following steps:
- At each bootstrap iteration, predict data not in the bootstrap sample (as Breiman calls “out of bag” data) by utilizing the tree developed with the bootstrap sample.
- Averaging the out of bag predictions, on the aggregate, where each data value would be out of bag around 36% of the times and hence averaging those predictions.
- Compute the error rate and name it the “out of bag” estimate of the error rate.
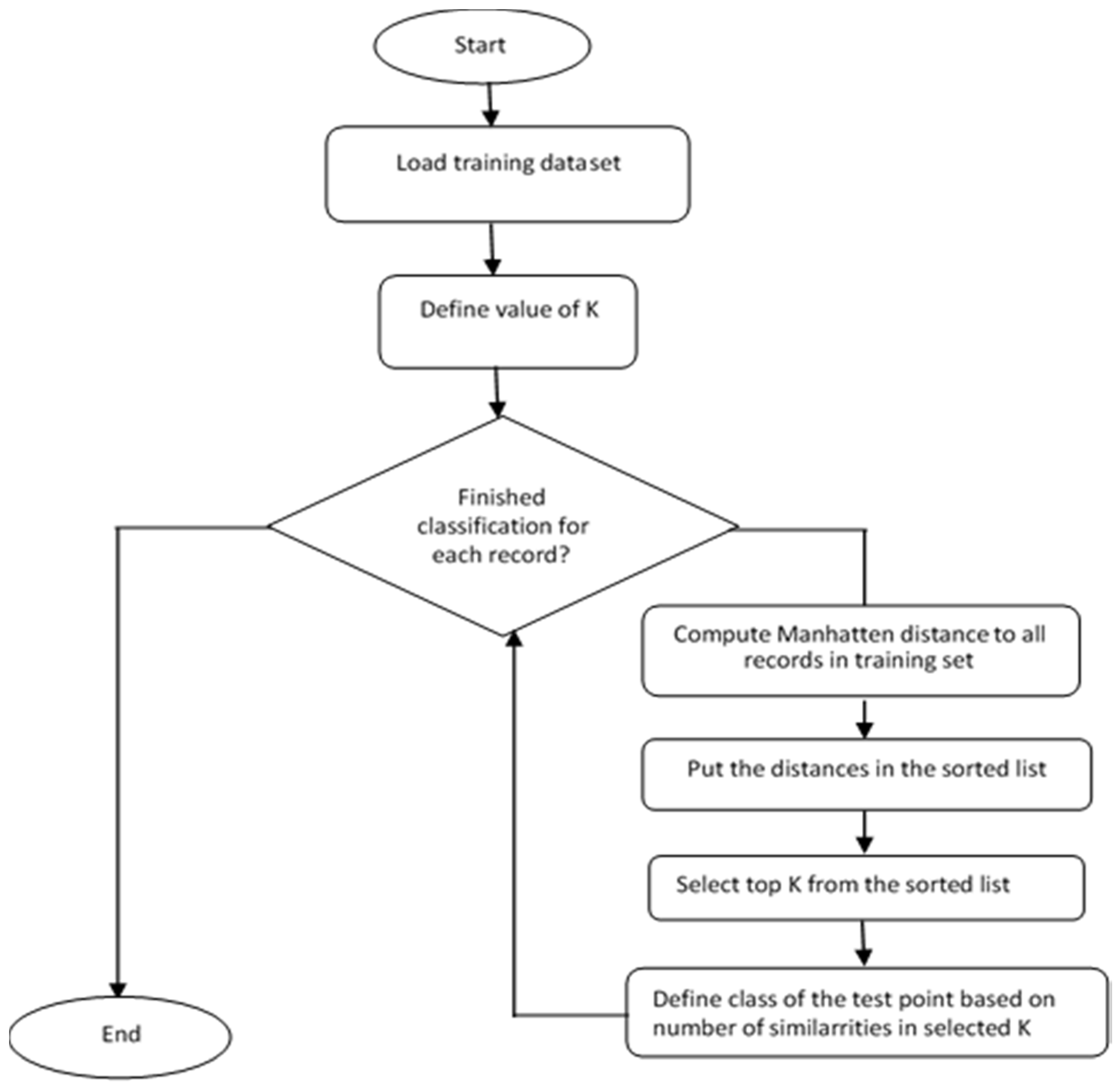
4.2. k-Nearest Neighbor Regression
- Compute the predefined distance between the testing dataset and training dataset;
- Select k-nearest neighbors with k-minimum distances from the training dataset;
- Predict the final renewable energy output based on a weighted averaging approach.
4.3. Gradient Boosting Trees
4.4. Decision Regression Trees
| Algorithm 1. Tree Growth (, ). |
| 1. if stopping _cond (, ) = then |
| 2. leaf = createNode() |
| 3. Classify() |
| 4. return |
| 5. else |
| 6. = create Node() |
| 7. = find_best_split(, ) |
| 8. let is a possible outcome of |
| 9. for each do |
| 10. |
| 11. TreeGrowth () |
| 12. add as descendent of and label the edge () as |
| 13. end for |
| 14. end if |
| 15. return root |
4.5. Extra Tree Regression
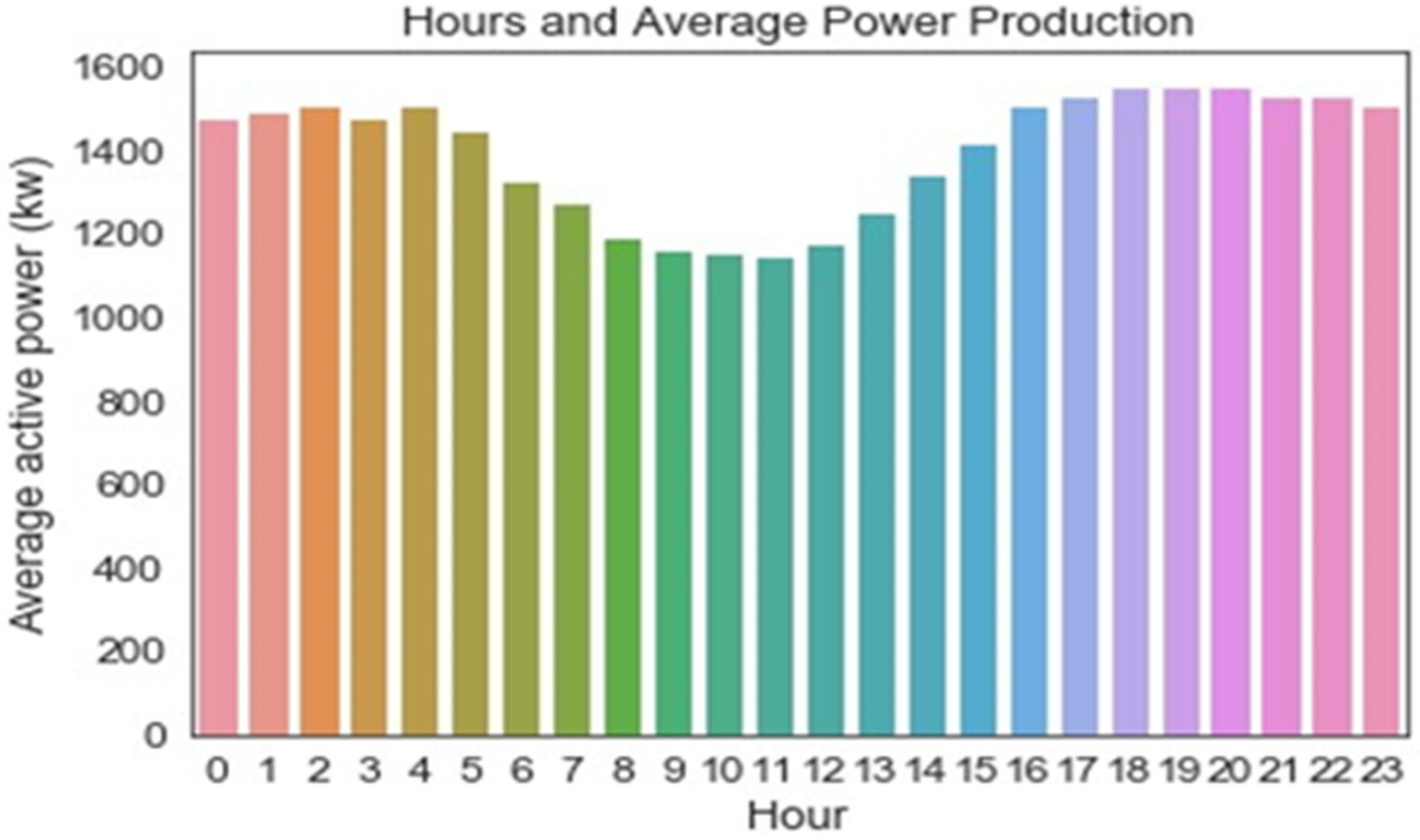
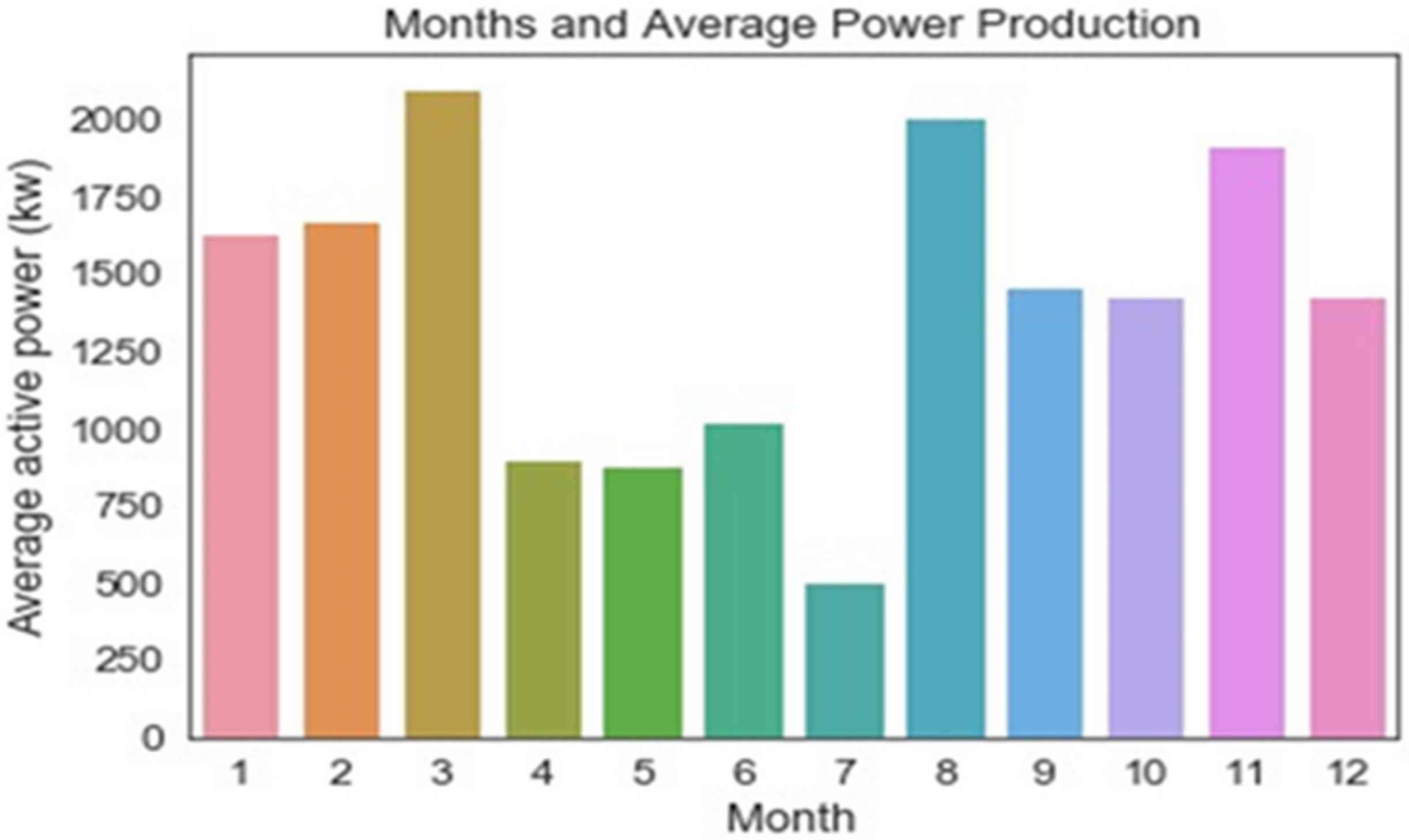
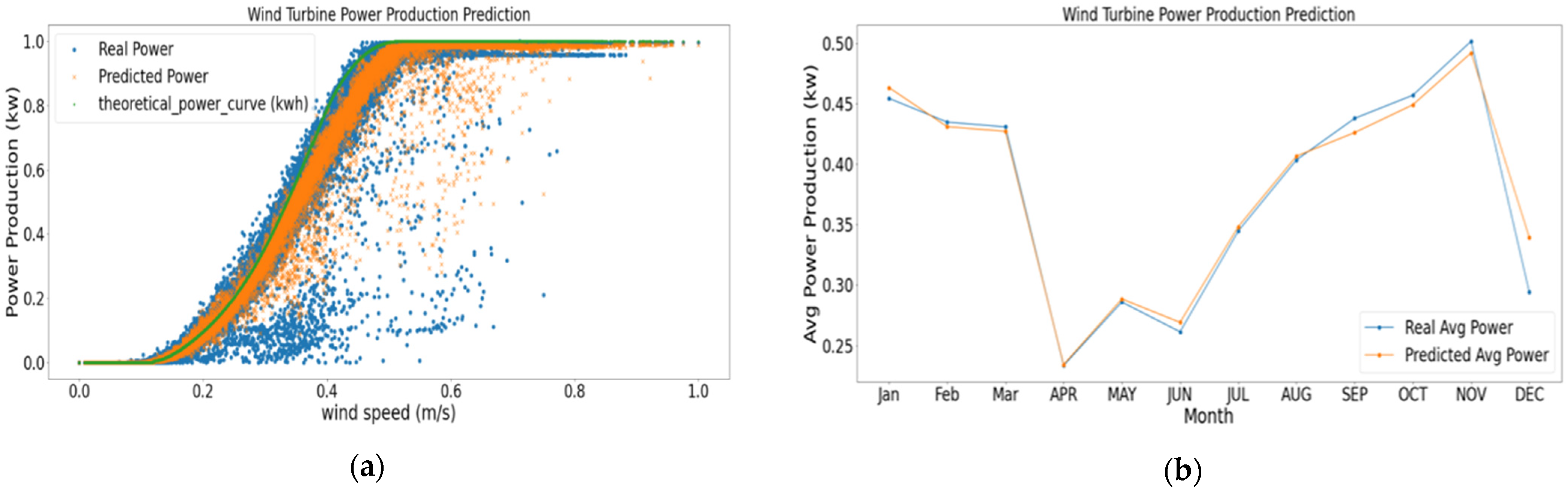
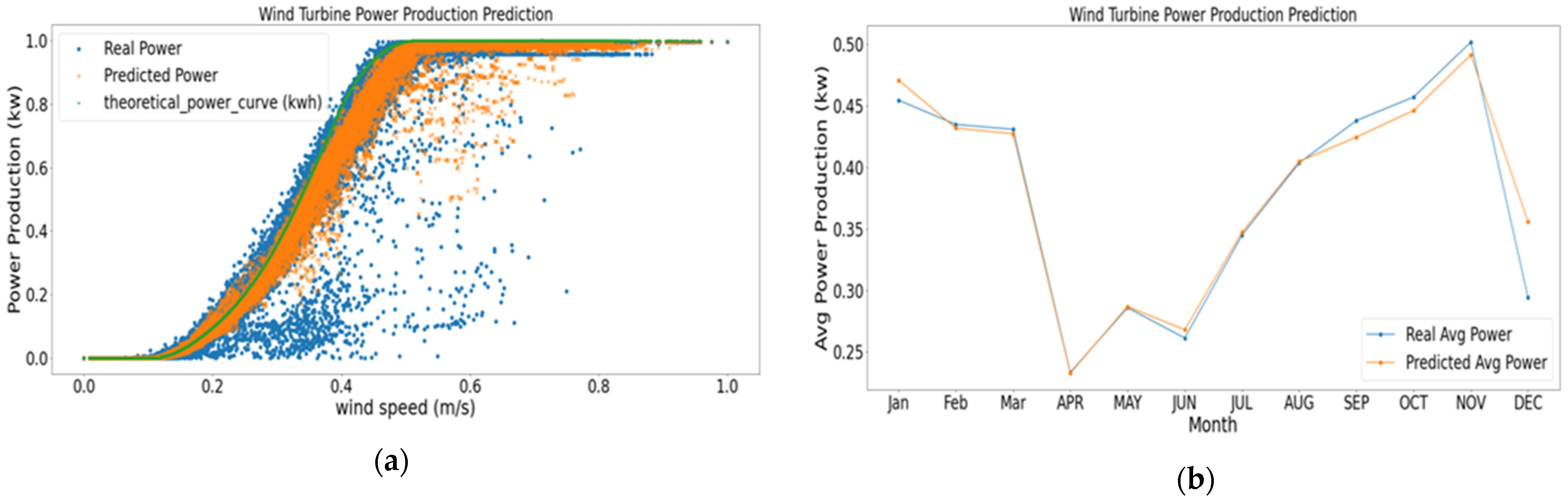
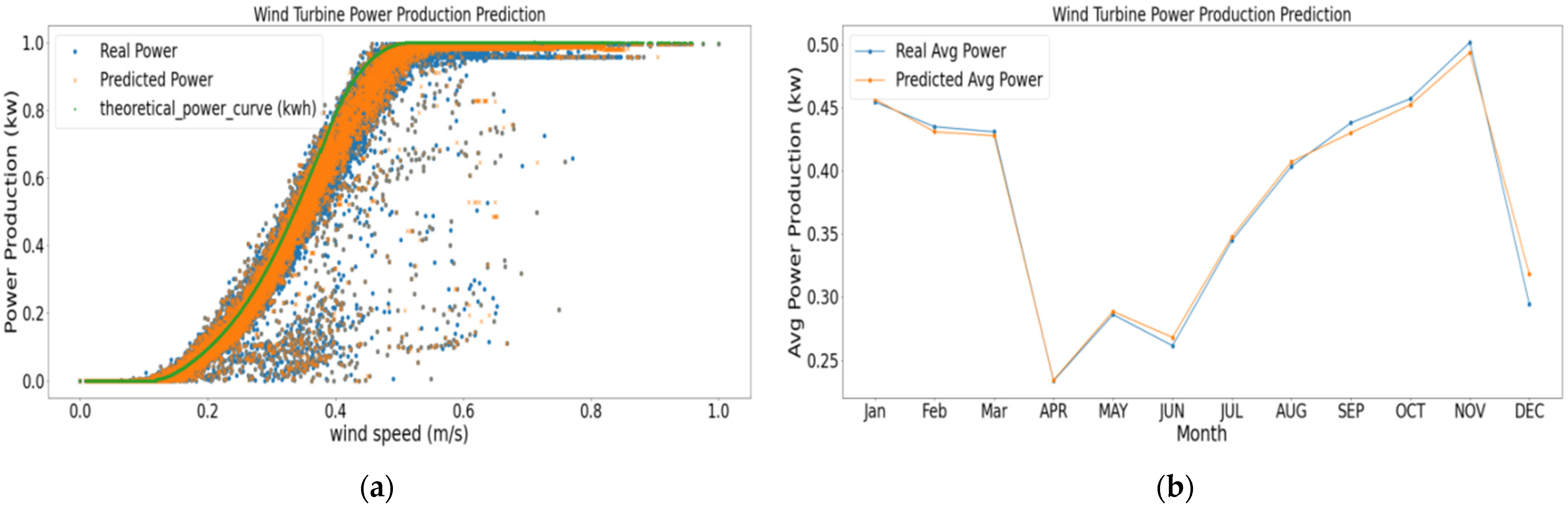
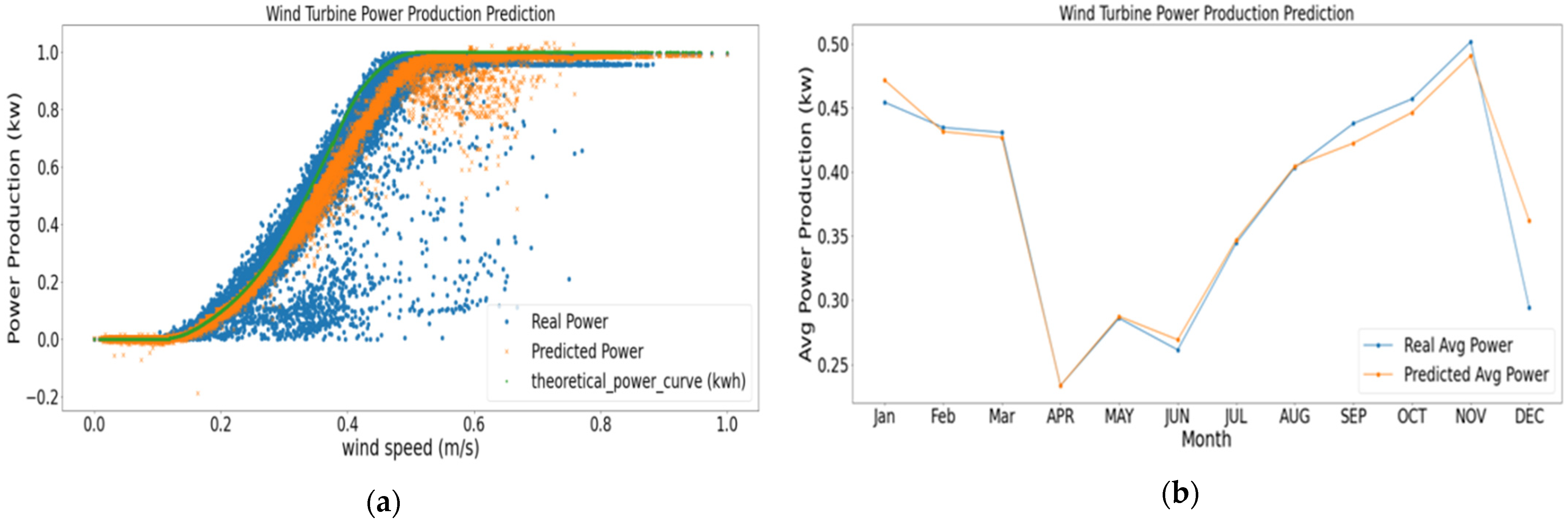
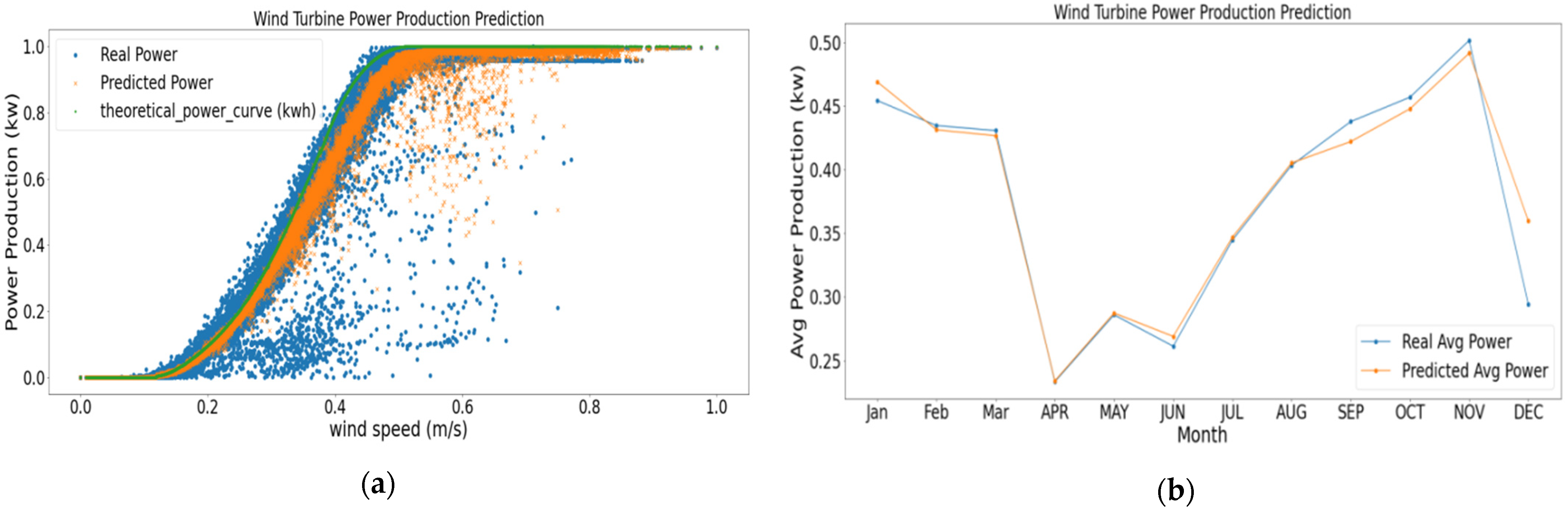
5. Results and Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kosovic, B.; Haupt, S.E.; Adriaansen, D.; Alessandrini, S.; Wiener, G.; Monache, L.D.; Liu, Y.; Linden, S.; Jensen, T.; Cheng, W.; et al. A Comprehensive Wind Power Forecasting System Integrating Artificial Intelligence and Numerical Weather Prediction. Energies 2020, 13, 1372. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Huang, Z.; Tian, L.; Zhu, Y.; Wang, H.; Feng, S. Enhancing Wind Turbine Power Forecast via Convolutional Neural Network. Electronics 2021, 10, 261. [Google Scholar] [CrossRef]
- Wang, G.; Jia, R.; Liu, J.; Zhang, H. A hybrid wind power forecasting approach based on Bayesian model averaging and en-semble learning. Renew. Energy 2020, 145, 2426–2434. [Google Scholar] [CrossRef]
- Nagy, G.I.; Barta, G.; Kazi, S.; Borbély, G.; Simon, G. GEFCom2014: Probabilistic solar and wind power forecasting using a generalized additive tree ensemble approach. Int. J. Forecast. 2016, 32, 1087–1093. [Google Scholar] [CrossRef]
- Hanifi, S.; Liu, X.; Lin, Z.; Lotfian, S. A Critical Review of Wind Power Forecasting Methods—Past, Present and Future. Energies 2020, 13, 3764. [Google Scholar] [CrossRef]
- Lai, J.-P.; Chang, Y.-M.; Chen, C.-H.; Pai, P.-F. A Survey of Machine Learning Models in Renewable Energy Predictions. Appl. Sci. 2020, 10, 5975. [Google Scholar] [CrossRef]
- Juban, R.; Ohlsson, H.; Maasoumy, M.; Poirier, L.; Kolter, J.Z. A multiple quantile regression approach to the wind, solar, and price tracks of GEFCom2014. Int. J. Forecast. 2016, 32, 1094–1102. [Google Scholar] [CrossRef]
- Treiber, N.A.; Heinermann, J.; Kramer, O. Wind Power Prediction with Machine Learning. In Computational Sustainability. Studies in Computational Intelligence; Lässig, J., Kersting, K., Morik, K., Eds.; Springer: Cham, Germany, 2016; Volume 645, pp. 13–29. [Google Scholar] [CrossRef]
- Hu, Q.; Zhang, S.; Yu, M.; Xie, Z. Short-term wind speed or power forecasting with heteroscedastic support vector regres-sion. IEEE Trans. Sustain. Energy 2015, 7, 241–249. [Google Scholar] [CrossRef]
- Pathak, R.; Wadhwa, A.; Khetarpal, P.; Kumar, N. Comparative Assessment of Regression Techniques for Wind Power Forecasting. IETE J. Res. 2021, 1–10. [Google Scholar] [CrossRef]
- Chaudhary, A.; Sharma, A.; Kumar, A.; Dikshit, K.; Kumar, N. Short term wind power forecasting using machine learning techniques. J. Stat. Manag. Syst. 2020, 23, 145–156. [Google Scholar] [CrossRef]
- Zameer, A.; Khan, A.; Javed, S.G. Machine Learning based short term wind power prediction using a hybrid learning model. Comput. Electr. Eng. 2015, 45, 122–133. [Google Scholar]
- Higashiyama, K.; Fujimoto, Y.; Hayashi, Y. Feature Extraction of NWP Data for Wind Power Forecasting Using 3D-Convolutional Neural Networks. Energy Procedia 2018, 155, 350–358. [Google Scholar] [CrossRef]
- Fan, G.-F.; Qing, S.; Wang, H.; Hong, W.-C.; Li, H.-J. Support Vector Regression Model Based on Empirical Mode Decomposition and Auto Regression for Electric Load Forecasting. Energies 2013, 6, 1887–1901. [Google Scholar] [CrossRef]
- Chen, Y.H.; Hong, W.-C.; Shen, W.; Huang, N.N. Electric Load Forecasting Based on a Least Squares Support Vector Machine with Fuzzy Time Series and Global Harmony Search Algorithm. Energies 2016, 9, 70. [Google Scholar] [CrossRef]
- Li, M.-W.; Wang, Y.-T.; Geng, J.; Hong, W.-C. Chaos cloud quantum bat hybrid optimization algorithm. Nonlinear Dyn. 2021, 103, 1167–1193. [Google Scholar] [CrossRef]
- Azimi, R.; Ghofrani, M.; Ghayekhloo, M. A hybrid wind power forecasting model based on data mining and wavelets analysis. Energy Convers. Manag. 2016, 127, 208–225. [Google Scholar] [CrossRef]
- Shabbir, N.; AhmadiAhangar, R.; Kütt, L.; Iqbal, M.N.; Rosin, A. Forecasting short term wind energy generation using machine learning. In Proceedings of the 2019 IEEE 60th International Scientific Conference on Power and Electrical Engineering of Riga Technical University (RTUCON), Riga, Latvia, 7–9 October 2019; pp. 1–4. [Google Scholar]
- Wu, Q.; Guan, F.; Lv, C.; Huang, Y. Ultra-short-term multi-step wind power forecasting based on CNN-LSTM. IET Renew. Power Gener. 2021, 15, 1019–1029. [Google Scholar] [CrossRef]
- Yang, M.; Shi, C.; Liu, H. Day-ahead wind power forecasting based on the clustering of equivalent power curves. Energy 2020, 218, 119515. [Google Scholar] [CrossRef]
- Li, L.-L.; Zhao, X.; Tseng, M.-L.; Tan, R.R. Short-term wind power forecasting based on support vector machine with improved dragonfly algorithm. J. Clean. Prod. 2019, 242, 118447. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, X. Wind power forecasting of an offshore wind turbine based on high-frequency SCADA data and deep learning neural network. Energy 2020, 201, 117693. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, H.; Ma, P. Wind power forecasting based on singular spectrum analysis and a new hybrid Laguerre neural network. Appl. Energy 2019, 259, 114139. [Google Scholar] [CrossRef]
- Wang, K.; Qi, X.; Liu, H.; Song, J. Deep belief network based k-means cluster approach for short-term wind power forecasting. Energy 2018, 165, 840–852. [Google Scholar] [CrossRef]
- Dolara, A.; Gandelli, A.; Grimaccia, F.; Leva, S.; Mussetta, M. Weather-based machine learning technique for Day-Ahead wind power forecasting. In Proceedings of the 2017 IEEE 6th International Conference on Renewable Energy Research and Applications (ICRERA), San Diego, CA, USA, 5–8 November 2017; pp. 206–209. [Google Scholar]
- Abhinav, R.; Pindoriya, N.M.; Wu, J.; Long, C. Short-term wind power forecasting using wavelet-based neural net-work. Energy Procedia 2017, 142, 455–460. [Google Scholar] [CrossRef]
- Yu, R.; Gao, J.; Yu, M.; Lu, W.; Xu, T.; Zhao, M.; Zhang, J.; Zhang, R.; Zhang, Z. LSTM-EFG for wind power forecasting based on sequential correlation features. Future Gener. Comput. Syst. 2018, 93, 33–42. [Google Scholar] [CrossRef]
- Zheng, D.; Eseye, A.T.; Zhang, J.; Li, H. Short-term wind power forecasting using a double-stage hierarchical ANFIS approach for energy management in microgrids. Prot. Control. Mod. Power Syst. 2017, 2, 13. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Xingying, C.H.E.N.; Kun, Y.U.; Yingchen, L.I.A.O. Short-term wind power forecasting using hybrid method based on enhanced boosting algorithm. J. Mod. Power Syst. Clean Energy 2017, 5, 126–133. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Li, P.-C.; Gao, L.; Liu, Y.-Q.; Ren, X.-Y. Application of autoregressive dynamic adaptive (ARDA) model in real-time wind power forecasting. Renew. Energy 2021, 169, 129–143. [Google Scholar] [CrossRef]
- Qin, G.; Yan, Q.; Zhu, J.; Xu, C.; Kammen, D.M. Day-Ahead Wind Power Forecasting Based on Wind Load Data Using Hybrid Optimization Algorithm. Sustainability 2021, 13, 1164. [Google Scholar] [CrossRef]
- Huang, B.; Liang, Y.; Qiu, X. Wind Power Forecasting Using Attention-Based Recurrent Neural Networks: A Comparative Study. IEEE Access 2021, 9, 40432–40444. [Google Scholar] [CrossRef]
- Wang, H.; Han, S.; Liu, Y.; Yan, J.; Li, L. Sequence transfer correction algorithm for numerical weather prediction wind speed and its application in a wind power forecasting system. Appl. Energy 2019, 237, 1–10. [Google Scholar] [CrossRef]
- Ayyavu, S.; Maragatham, G.; Prabu, M.R.; Boopathi, K. Short-Term Wind Power Forecasting Using R-LSTM. Int. J. Renew. Energy Res. 2021, 11, 392–406. [Google Scholar]
- Akhtar, I.; Kirmani, S.; Ahmad, M.; Ahmad, S. Average Monthly Wind Power Forecasting Using Fuzzy Approach. IEEE Access 2021, 9, 30426–30440. [Google Scholar] [CrossRef]
- Aly, H.H. A novel deep learning intelligent clustered hybrid models for wind speed and power forecasting. Energy 2020, 213, 118773. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, J.; Infield, D.; Liu, Y.; Lien, F.-S. Short-term forecasting and uncertainty analysis of wind turbine power based on long short-term memory network and Gaussian mixture model. Appl. Energy 2019, 241, 229–244. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Wang, P.; Goel, L. Wind Power Forecasting Using Neural Network Ensembles with Feature Selection. IEEE Trans. Sustain. Energy 2015, 6, 1447–1456. [Google Scholar] [CrossRef]
- Colak, I.; Sagiroglu, S.; Yesilbudak, M.; Kabalci, E.; Bulbul, H.I. Multi-time series and-time scale modeling for wind speed and wind power forecasting part I: Statistical methods, very short-term and short-term applications. In Proceedings of the 2015 International Conference on Renewable Energy Research and Applications (ICRERA), Palermo, Italy, 22–25 November 2015; pp. 209–214. [Google Scholar]
- Maroufpoor, S.; Sanikhani, H.; Kisi, O.; Deo, R.C.; Yaseen, Z.M. Long-term modelling of wind speeds using six different heuristic artificial intelligence approaches. Int. J. Climatol. 2019, 39, 3543–3557. [Google Scholar] [CrossRef]
- Yan, J.; Ouyang, T. Advanced wind power prediction based on data-driven error correction. Energy Convers. Manag. 2018, 180, 302–311. [Google Scholar] [CrossRef]
- Peng, T.; Zhou, J.; Zhang, C.; Zheng, Y. Multi-step ahead wind speed forecasting using a hybrid model based on two-stage decomposition technique and AdaBoost-extreme learning machine. Energy Convers. Manag. 2017, 153, 589–602. [Google Scholar] [CrossRef]
- Qin, Y.; Li, K.; Liang, Z.; Lee, B.; Zhang, F.; Gu, Y.; Zhang, L.; Wu, F.; Rodriguez, D. Hybrid forecasting model based on long short term memory network and deep learning neural network for wind signal. Appl. Energy 2018, 236, 262–272. [Google Scholar] [CrossRef]
- Wang, H.Z.; Li, G.Q.; Wang, G.B.; Peng, J.C.; Jiang, H.; Liu, Y.T. Deep leaning based ensemble approach for probabilistic wind power forecasting. Appl. Energy 2017, 188, 56–70. [Google Scholar]
- Erisen, B. Wind Turbine Scada Dataset. 2018. Available online: http//www.kaggle.com/berkerisen/wind-turbine-scada-dataset (accessed on 18 May 2020).
- Manwell, J.F.; McCowan, J.G.; Rogers, A.L. Wind energy explained: Theory, design and application. Wind. Eng. 2006, 30, 169. [Google Scholar]
- Yao, F.; Bansal, R.C.; Dong, Z.Y.; Saket, R.K.; Shakya, J.S. Wind energy resources: Theory, design and applications. In Handbook of Renewable Energy Technology; World Scientific: Singapore, 2011; pp. 3–20. [Google Scholar] [CrossRef]
- Jenkins, N. Wind Energy Explained: Theory, Design and Application. Int. J. Electr. Eng. Educ. 2004, 41, 181. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, S.; Li, T. Review of Evaluation Criteria and Main Methods of Wind Power Forecasting. Energy Procedia 2011, 12, 761–769. [Google Scholar] [CrossRef] [Green Version]
- Gökgöz, F.; Filiz, F. Deep Learning for Renewable Power Forecasting: An Approach Using LSTM Neural Net-works. Int. J. Energy Power Eng. 2018, 12, 416–420. [Google Scholar]
- Kisvari, A.; Lin, Z.; Liu, X. Wind power forecasting–A data-driven method along with gated recurrent neural net-work. Renew. Energy 2021, 163, 1895–1909. [Google Scholar] [CrossRef]
- Devi, M.R.; SriDevi, S. Probabilistic wind power forecasting using fuzzy logic. Int. J. Sci. Res. Manag. 2017, 5, 6497–6500. [Google Scholar]
- Wang, F.; Zhen, Z.; Wang, B.; Mi, Z. Comparative Study on KNN and SVM Based Weather Classification Models for Day Ahead Short Term Solar PV Power Forecasting. Appl. Sci. 2017, 8, 28. [Google Scholar] [CrossRef] [Green Version]
- Gilbert, C.; Browell, J.; McMillan, D. Leveraging Turbine-Level Data for Improved Probabilistic Wind Power Forecasting. IEEE Trans. Sustain. Energy 2019, 11, 1152–1160. [Google Scholar] [CrossRef] [Green Version]
- Zhao, C.; Wan, C.; Song, Y. Operating reserve quantification using prediction intervals of wind power: An integrated probabilistic forecasting and decision methodology. IEEE Trans. Power Syst. 2021, 36, 3701–3714. [Google Scholar] [CrossRef]
- Ahmad, M.W.; Mourshed, M.; Rezgui, Y. Tree-based ensemble methods for predicting PV power generation and their comparison with support vector regression. Energy 2018, 164, 465–474. [Google Scholar] [CrossRef]
- Gu, B.; Zhang, T.; Meng, H.; Zhang, J. Short-term forecasting and uncertainty analysis of wind power based on long short-term memory, cloud model and non-parametric kernel density estimation. Renew. Energy 2020, 164, 687–708. [Google Scholar] [CrossRef]
- Dong, Y.; Zhang, H.; Wang, C.; Zhou, X. A novel hybrid model based on Bernstein polynomial with mixture of Gaussians for wind power forecasting. Appl. Energy 2021, 286, 116545. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Variables | Wind Speed, Wind Direction, Theoretical Power, Active Power |
|---|---|
| Draft Frequency | 10 min |
| Start Period | 1 January 2018 |
| End Period | 31 December 2018 |
| Characteristics | Wind Turbine |
|---|---|
| SINOVEL (turbine manufacturer) | SL1500/90 (Turbine model) |
| Rated Power | 1.5 MW |
| Hub Height | 100 m |
| Rotor Diameter | 90 m |
| Swept Area | 6362 m2 |
| Blades | 3 |
| Cut-in Speed of Wind | 3 m/s |
| Rated Speed of Wind | 10 m/s |
| Cut-off Speed of Wind | 22 m/s |
| Regression Models | Performance Evaluation on Training Dataset | Performance Evaluation on Testing Dataset | Training Time (s) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | MAPE | RMSE | MSE | R2 | MAE | MAPE | RMSE | MSE | R2 | ||
| Random Forest | 0.0186 | 0.2966 | 0.0588 | 0.0040 | 0.9888 | 0.0277 | 0.3310 | 0.0672 | 0.0045 | 0.9651 | 11.9 |
| K-NN | 0.0278 | 0.2960 | 0.0580 | 0.0036 | 0.9742 | 0.0286 | 0.3248 | 0.0667 | 0.0044 | 0.9656 | 0.08 |
| GBM | 0.0260 | 0.0555 | 0.0228 | 0.0031 | 0.9897 | 0.0264 | 0.3012 | 0.0634 | 0.0040 | 0.9690 | 5.83 |
| Decision Tree | 0.0325 | 0.3213 | 0.0592 | 0.0055 | 0.9660 | 0.0336 | 0.3349 | 0.0884 | 0.0078 | 0.9497 | 0.22 |
| Extra Tree | 0.0274 | 0.2915 | 0.0522 | 0.0036 | 0.9782 | 0.0276 | 0.3243 | 0.0655 | 0.0041 | 0.9678 | 3.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, U.; Rizwan, M.; Alaraj, M.; Alsaidan, I. A Machine Learning-Based Gradient Boosting Regression Approach for Wind Power Production Forecasting: A Step towards Smart Grid Environments. Energies 2021, 14, 5196. https://doi.org/10.3390/en14165196
Singh U, Rizwan M, Alaraj M, Alsaidan I. A Machine Learning-Based Gradient Boosting Regression Approach for Wind Power Production Forecasting: A Step towards Smart Grid Environments. Energies. 2021; 14(16):5196. https://doi.org/10.3390/en14165196
Chicago/Turabian StyleSingh, Upma, Mohammad Rizwan, Muhannad Alaraj, and Ibrahim Alsaidan. 2021. "A Machine Learning-Based Gradient Boosting Regression Approach for Wind Power Production Forecasting: A Step towards Smart Grid Environments" Energies 14, no. 16: 5196. https://doi.org/10.3390/en14165196