1. Introduction
The theft of electric power is one of the main problems faced by distribution utilities in developing countries, in particular in many countries in Africa, Latin America, and South Asia [
1,
2,
3,
4,
5], where the current levels of the theft of electric power pose risks to not only the solvency of many electricity distribution companies in these countries but also to the security of energy supply itself [
1,
3,
4]. In Brazil, non-technical losses of electricity (NTLs) have remained relatively stable over the last decade despite the efforts of the National Electric Energy Agency (ANEEL) and utilities to combat this problem, as shown in
Figure 1 by the percentage of non-technical losses (PNTL) in the total energy injected into the utility grid.
Though the situation in Brazil is much less dramatic than that observed in other developing countries (and, overall, it is even close to the average 7% observed in the OECD countries [
4]), NTLs have a significant financial impact both for utilities and other Brazilian consumers. This is due to the fact that in addition to the costs of the generated and unpaid energy itself, consumers and utilities companies have to bear the full cost of the transmission and distribution infrastructure associated with these NTLs.
In Brazil, the NTL is an input variable for tariff calculations. The NTL is partially passed to consumers through electricity tariffs, i.e., the NTL is a cost shared among all consumers [
6]. The transference of the NTL to the tariffs is justified by the fact that the NTL depends on factors not manageable by the utilities. However, this solution does not totally solve the problem because it inflates the tariffs, and, consequently, it encourages defaults [
7] and more theft of electricity [
1]. Nowadays, the non-payment rate is another problem faced by Brazilian distribution utilities [
7]. The non-technical losses are hampering efforts to achieve lower tariffs and greater improvements in energy efficiency. Ultimately, non-technical losses deteriorate the economic and financial balance of utilities, and they jeopardize the sustainability of electric power supplies [
8].
Figure 1.
Percentage of non-technical losses in the total energy injected into the utility grids [
9].
Figure 1.
Percentage of non-technical losses in the total energy injected into the utility grids [
9].
Another aspect that makes the regulatory treatment of NTLs very complex in Brazil is the relative heterogeneity of NTLs observed among electric distribution utilities (
Figure 2). In 2018, for example, of the 54 main utilities, 25 of them registered PNTLs below 3% of the total injected energy, values very close to the PNTL values observed in countries such as the US and Canada. On the other hand, 11 of these utilities had PNTLs higher than 10% of the total injected energy [
10], reaching, in some cases, more than 30%, which are values comparable to those observed in countries like India and Bangladesh [
11].
In order to reduce the harmful effects of NTLs, the distribution utilities should invest in technology for theft detection and the inspection of consumer units to identify and punish fraudsters [
1,
8,
12,
13,
14]. However, the costs are high and they can outweigh the benefits from the non-technical loss reduction if the investments are greater than the energy losses cost reduction [
6].
NTLs will never totally be eradicated [
4]. There is a limit tolerable to NTLs, from which the costs to reduce them outweigh the benefits of their reduction. It is known that the characteristics of the environment in which the utilities are inserted can dramatically influence their outcomes in the fight against NTLs [
4,
12]. Experience has shown that combating losses in some areas is much more challenging than in others. The difference is associated with a number of variables, especially those associated with the socioeconomic characteristics of the region, such as the criminality and inequality levels, the infrastructure quality, and the strength of local Institutions [
4,
5,
11,
15]. This means that optimal the minimum level of NTLs that needs to be achieved in a more socioeconomic complex area tends to be higher than in others.
On the other hand, the level of effort undertaken by utilities in combating NTLs affects their PNTL levels. Some utilities have achieved substantial reductions in NTLs even under more adverse conditions through technological innovation, management improvements, and investments. As the socioeconomic reality of the concession areas has not substantially changed, it is possible to attribute the observed reductions to a more efficient management in the fight against non-technical losses.
If it were possible, through observation, to decompose the NTL levels of each utility into two installments, one resulting from the actions carried out by the utility (manageable portion) and the other related to the environment in which the utility is inserted (non-manageable portion), the regulator’s problem would be to determine the optimum NTL level of the manageable portion by ensuring the full transfer of the non-manageable portion—a process that could be performed quite simply. However, it is not possible to make this decomposition directly and accurately, so the regulator must define a method that allows him/her to separately estimate these parcels.
Aware of this limit and aiming to reduce losses, the ANEEL [
10] established a tolerable limit or target value to the PNTL for each utility. Any percentage of non-technical losses above the target implies burdens that must be assumed by the utilities and not by their customers.
The target value depends on the socioeconomic complexity [
10] in the concession area, which is a construct based on the following variables: the proportion of subnormal households, garbage collection coverage, income inequality (Gini Index), credit default levels, violent death rates, and the proportion of low-income clients. The level of socioeconomic complexity is achieved by fitting an econometric model for panel data in which the dependent variable is the percentage of non-technical losses and the explanatory variables correspond to the above-mentioned socioeconomic variables [
10,
16].
Despite the remarkable progress promoted by the ANEEL,
Figure 3 shows that the targets defined by the ANEEL have been unable to lead the utilities to a cycle of reductions of general NTLs in the country.
This issue is even more serious when individually analyzing utilities. From 2008 to 2018, according to data from the ANEEL, an average of 68% of the country’s 54 main utilities were unable to meet the regulatory loss targets set by the ANEEL. The situation is even more dramatic if we consider only the results of the last three years, during which 77% of utilities have been unable to meet their NTL regulatory targets, as illustrated in
Figure 4.
Thus, the search for alternative methodologies to deal with the topic seems to be necessary. A more attractive alternative to the ANEEL’s model is an efficient frontier model [
17,
18,
19,
20]. The efficiency frontier for the PNTL is a benchmark that can be identified through data envelopment analysis (DEA) [
21]. An alternative to DEA models is the stochastic frontier analysis (SFA) model [
22].
The DEA and SFA approaches aim to estimate an efficiency frontier from data, but they differ in the methods employed; DEA is a non-parametric approach based on linear programming [
23], while SFA is a parametric approach that relies on econometric modeling [
24]. Additionally, in the DEA approach, the effort undertaken by an utility to reach the benchmark (frontier) corresponds to the utility’s deviation from the efficiency frontier. On the other hand, in the SFA approach, there is the recognition that part of the deviation from the frontier is due to factors that are not manageable by utilities [
22,
24], a premise that is compatible with the reality faced by utilities in combating non-technical losses.
Aiming to improve the transparency and reproducibility of the regulatory procedures adopted by the ANEEL to control non-technical losses, the present work describes a panel data SFA model to provide the PNTL targets for all Brazilian distribution utilities as an alternative to the econometric approach used by the ANEEL in the last tariff review cycle [
16]. The choice of the SFA approach was due to the recognition that non-technical losses are determined by variables that are not manageable by utilities. Since the non-technical losses are costs, the utilities must minimize them. Thus, the SFA model proposed in this work is like a stochastic cost frontier model [
22,
24]. Recently, a similar approach based on a panel data SFA model was used to evaluate the energy and carbon efficiency for emerging countries [
25].
It is worth noting that the DEA and SFA models have been successfully applied in the economic regulation of electricity distribution and transmission utilities, particularly in the definition of the regulatory operational expenditure (OPEX) for each utility, a key element for the annual allowed revenue assessment. [
18,
19,
20,
23,
26].
This paper is organized in five sections. Next,
Section 2 outlines the basic theoretical stochastic cost frontier model for cross-section and panel data in
Section 2.1 and
Section 2.2, respectively. The specification of the proposed SFA model and the method to compute the PNTL targets are described in
Section 2.3. The proposed methodology was applied to panel data containing annual observations over 10 years of 41 distribution utilities in the Brazilian electrical power system and the achieved results are displayed and discussed in
Section 3 and
Section 4, respectively. Finally,
Section 5 summarizes the main conclusions.
2. Materials and Methods
The cost frontier indicates the minimum cost required to produce a quantity of product given inputs prices and technology. Thus, inefficient producers are located above the frontier, while efficient producers are at the cost frontier, as shown in
Figure 5.
The cost frontier is a benchmark against which the performance of producers in the same industry sector (decision making units—DMUs) can be compared; in this work, the DMUs are the Brazilian distribution utilities. A comparison with the frontier function allows for the classification of the DMUs into the categories of efficient and inefficient.
It is necessary to recognize that the analyzed problem does not belong to the field of microeconomics. The analyzed variables do not include the variables considered in the theory of production and cost. Thus, the microeconomic theory does not present prescriptions about the relationship between NTLs and their drivers.
However, it is also necessary to recognize, that despite that, the non-technical loss is a variable that must be minimized, which is why the theoretical framework of the cost frontier was adopted.
2.1. Cost Stochastic Frontier Model for Cross Section Data
The deviations from the frontier function reflect failures in management optimization. This suggests that the degree of relative efficiency of a DMU can be evaluated by its distance from the frontier, using the radial metric [
22,
24], which is a number in the interval [0,1]: the DMU is considered efficient if the metric is equal to one; otherwise, it is considered inefficient. For a DMU to produce a quantity y of product from a quantity x of inputs with unit prices w, the efficiency θ is the ratio of the minimum potential cost defined by the efficiency frontier c (y,w) and the production cost E = wx ≥ c (y,w):
By arranging the terms of Equation (1), E = c (y,w) θ
−1. Then, the following equation can be obtained after a natural logarithmic transformation:
Assuming that the cost function is linear in the natural logarithms of the variables (e.g., a Cobb–Douglas specification) and that ε = −log(θ), which is a random term, we have the following linear regression equation for each DMU i in a set with n DMUs:
In Equation (3), the random term ε
i expresses the deviation between the verified cost (log(E
i)) and the minimum cost defined by the efficiency frontier (β
0 + β
1·log(y
i) + β
2·log(w
i)). It is noteworthy that, unlike the conventional linear regression model, the random term in Equation (3) has a non-zero mean (E(ε
i) > 0) and it is not normally distributed [
22].
In general, the SFA models are specified as Cobb–Douglas (CD) or Translog (TL) forms [
17,
24]. In the case of the cost frontier, the Translog cost function has the most favorable functional properties because it is flexible, but this approach also has problems because it is not parsimonious (there are more parameters to estimate), and this may give rise to econometric difficulties such as multicollinearity and the need for larger samples.
In addition, the Translog cost function collapses to a Cobb–Douglas cost function, and the latter is a particular case of the former. The Cobb–Douglas function is less flexible than Translog, but it is parsimonious, i.e., it is the simplest functional form that “gets the job done adequately” [
17].
A good example of the application of Cobb–Douglas form is the recent comparative study of energy and carbon efficiency for emerging countries by using panel stochastic frontier analysis [
25].
In deterministic frontier models, any deviation from the frontier is attributed to inefficiency. Such models ignore the fact that costs can be affected by random shocks not manageable by the DMUs. One advance in this regard is the stochastic frontier model, whose main virtue lies in the recognition that deviations from the frontier may originate from the inefficiency of the producers or may be caused by unmanageable random shocks. In order to accommodate the two sources of deviations, the SFA decomposes the random term into two components (ε
i = v
i + u
i):
In Equation (4), vi is a normally distributed random component with zero mean that picks random shocks not manageable by the i-th DMU, while ui is a nonnegative random component that catches the effect of the degree of inefficiency of the i-th DMU. The sum of the random components defines the compound error εi = vi + ui as positively asymmetric.
The stochastic frontier has two parts: a deterministic part, common to all DMUs (β
0 + β
1·log(y
i) + β
2·log(w
i)), and a specific part of each DMU, i.e., the component v
i that captures the effects of random shocks. The efficiency measure of the i-th DMU is given by:
Equation (4) is estimated by maximum likelihood, and, given that the random variables u and v are unobservable, there is a need to make some assumptions about their probability distributions. Usually, the more common assumptions are a normal distribution for v and a half-normal distribution for u, a specification known as a normal/half-normal SFA model [
26]:
.
(half-normal).
and are independents.
and are uncorrelated with the explanatory variables.
Since u
i and v
i are independents, the joint distribution of these variables is the product of their respective marginal densities:
Given that ε
i =
vi +
ui, we obtain the joint distribution of u
i and ε
i:
Next, the marginal distribution of ε
i is achieved by the integration of the joint density function of Equation (7):
where
,
and ϕ and Φ are, respectively, the density and the cumulative distribution of an N(0,1).
Then, based on the probability density function (PDF)in Equation (8), we can compute the logarithm of the likelihood function for a sample with n DMUs:
The maximum likelihood estimates correspond to the values of σ
u, σ
v, and β that maximize the Equation (9). These estimates are asymptotically consistent [
17,
22]. It should be noted that the logarithm of the likelihood was parameterized in terms of
and
. This parameterization allowed for a better interpretation of the model, e.g., the statistic
∊ [0,1] allowed us to evaluate which of the two components of the compound error was predominant. In the model, γ = 0, the inefficiency is non-existent, since
represents the greater part of the error. In this way, the deviations between the frontier and the DMUs are random noises. Conversely, when γ = 1, the error is dominated by
, so the deviations from the frontier are due to inefficiency. Thus, through the maximum likelihood ratio test, the hypothesis H
0 γ = 0 can be tested against the alternative hypothesis H
1 γ ≠ 0 to evaluate whether the inefficiency is present in the analyzed data set. In the case of the half-normal SFA model, the same adopted in this work, the distribution of the test statistic can be approximated by a
, i.e., a chi-square distribution with 1 degree of freedom [
17].
As indicated in Equation (5), in order to estimate the efficiency of each DMU, it is necessary to have an estimate of u
i, the error component that captures the effect of inefficiency. This estimate can be obtained from the residues because ε
i = v
i + u
i. By means of the joint density in Equation (7) and the density of ε
i in Equation (8), we can define the conditional probability density of u
i given ε
i:
where
and
.
A point estimate û
i for u
i may be the mean or the mode of the conditional distribution in Equation (10). In either case, the efficiency estimate is equal to exp(−û
i); for example, the expected value of conditional density probability
[
17,
22,
27] is a point estimate of u
i:
An alternative is the efficiency measure proposed by Battese and Coelli [
17]:
The estimation from Equation (12) differed from the estimates calculated in Equation (11). The presented results are based on the assumption that the random component u
i has a half-normal distribution, but other assumptions for the probability density of u
i could be admitted, e.g., truncated normal, exponential, and gamma [
17,
28].
2.2. Cost Stochastic Frontier Model for Panel Data
A sophistication introduced by the ANEEL was the specification of a panel data econometric model to estimate the socioeconomic complexity construct [
16], i.e., the collection of observations of a set of variables over a period T for each one of the n distribution utilities.
Cross-section data are collected by observing many subjects, such as firms and countries, at one period of time, e.g., the set of annual balance sheets for the last year from each Brazilian distribution utilities. On the other hand, panel data contain observations of multiple variables obtained over multiple periods for the same subjects, e.g., the set of annual balance sheets for each Brazilian distribution utility over the last decade.
By incorporating the longitudinal character of the data, which makes it possible to treat any underlying correlation structures in a more appropriate way, studies based on panel data allow for the more efficient monitoring of individual units (in this case, utilities) than those based on cross section data.
Panel data have more observations than cross-section data, so they are expected to obtain more efficient estimators for the model parameters and efficiencies [
17,
29]. The specification of a panel data model is like the specification for the cross-sectional data model in Equation (3), but in the panel data model, the variables are indexed in time according to Equation (13):
Let u
it and v
it be independent random variables, both uncorrelated with the explanatory variables x
it; the parameters of the panel data model can be estimated in the same way as the parameters for the cross-section data model. However, the premise that u
it are independent is unrealistic, since efficiency must vary over time as a function of technological evolution and management improvement [
17,
24].
Thus, it is convenient to admit some structure for the temporal evolution of the term u
it in Equation (13), e.g., u
it = f(t)·u
i, where f(t) is a function that determines how efficiency evolves over time [
17,
29,
30]. If the inefficiency effect is constant across time, then u
it = u
i and f(t) = 1.
Battese and Coelli [
30] proposed
, where η is a parameter to be estimated. In the panel data models, the likelihood ratio test and the z test can be applied to evaluate the hypotheses of time invariant efficiency effects H
0: η = 0, i.e., the inefficiency effect is constant across time [
17,
24]. This specification for f(t) implies that the rank ordering of efficiency scores for firms remains unchanged over time [
17]. In addition, in the panel data model estimation, the terms u
it can be treated as fixed effects or random effects, with the latter option being recommended by Kumbhakar [
29] and Battese and Coelli [
30].
2.3. Calculating the PNTL Targets
For non-technical loss control purposes, a PNTL corresponds to the ratio of NTLs by low voltage market (LVM), both given in MWh:
Non-technical losses can be interpreted as a cost. Thus, for a given socioeconomic complexity, the management of the utility should reduce the PNTL at the lowest possible level, i.e., the target defined by the efficiency frontier.
The idea described above is illustrated in
Figure 6, in which the gray area is the possibility set for the PNTL values. Note that the set is lower bounded by the efficiency frontier defined as a function of the socioeconomic complexity in the utility’s area. Thus, a utility with PNTL (Y), above the frontier, should reduce its PNTL to the target level (Y * < Y) determined by the efficiency frontier. The distance to frontier reflects failures in the management of the PNTL. As such, the relative efficiency of an utility can be evaluated by the radial metric θ = Y */Y, a number in the interval [0,1] whose complement 1–θ quantifies the reduction of the PNTL to reach the target value.
The purpose of the cost SFA model is to set the target value for the percentage of non-technical losses. The proposed model follows the Cobb–Douglas form [
17]—the dependent variable is the PNTL, and the list of explanatory variables includes the same variables adopted by the ANEEL`s econometric model [
10,
16], i.e., the proportion of subnormal households, garbage collection coverage, income inequality (Gini index), credit default level, index of violent deaths, the proportion of low-income clients in the low-voltage residential market, and the percentage of people with incomes less than half a minimum wage. Additionally, the random components u
i and v
i follow the half-normal and normal distributions, respectively. Here, the same specification for the random variables u and v was adopted in [
23,
26]. In addition, the efficiencies vary in time according to the proposal of Battese and Coelli [
30].
The linearization of the Cobb–Douglas specification undergoes a logarithmic transformation; however, the PNTL is often a number in the interval [0,1] (in rare exceptions, the PNTL is equal to or greater than 1, which indicates a serious management problem), and, eventually, the PNTL can be null or very small. Then, the probability distribution of the logarithm of the dependent variable may not be compatible with the assumption of positive asymmetry for the compound error assumed by the stochastic cost frontier, as shown in
Figure 7. In order to overcome this problem, we replaced the
(PNTL) with
(1 + PNTL).
The efficiency index resulting from the SFA model is denoted by θ (θ < 1), so the utility’s management should reduce from its current value of percentage of non-technical losses (PNTL
0) to the target value, i.e., the product θ × PNTL
0 at the end of a transition period Δ established by the ANEEL, e.g., the duration of a four-year tariff review cycle (Δ = 4). In addition, annual intermediate target values can be established for each year t (1 ≤ t ≤ Δ) based on the geometric rate:
3. Application of the Proposed Methodology
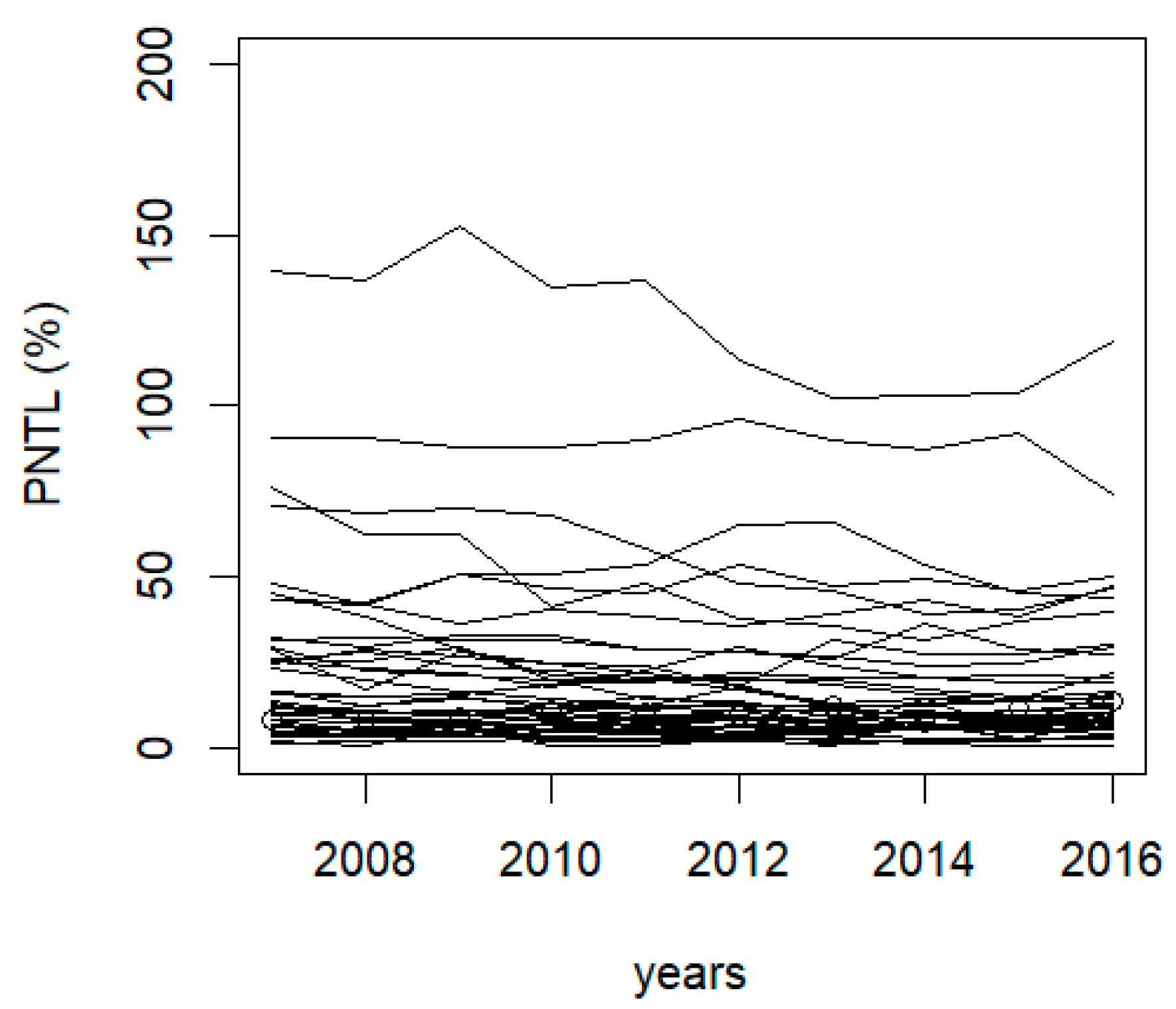
In order to illustrate the potential of the proposed methodology, the SFA model was applied on panel data with yearly observations from 2007 to 2016 (T = 10) and for 41 (n = 41) Brazilian electricity distribution utilities; therefore, the analyzed period covered two tariff review cycles. It is noteworthy that there were missing observations in two evaluated utilities, one missing observation in each one. Below,
Figure 8 shows the spatial distribution of the PNTLs among the Brazilian states at 2016. It is worth mentioning the existence of many isolated systems in the states located in the Amazon region. Next,
Figure 9 shows the trajectories of the PNTLs of the evaluated utilities during the period of 2007–2016.
Figure 9 shows the trajectories of the PNTLs in LV networks [
9], where the variability reflects the huge heterogeneity in the socioeconomic complexity and the different strategies for the non-technical losses management in the Brazilian distribution utilities; for example, the biggest losses were observed in a few companies that serve isolated systems that are not connected to the distribution network.
The explanatory variables used in the application of SFA are the same seven considered in the panel data econometric model specified by the ANEEL. One associated with violence (vio), four associated with poverty/income inequality (Gini, default, lowinc, and poor), and two associated with the infrastructure quality (sub and garbage). A brief explanation of the variables can be found in
Table 1.
The computational implementation was performed in the R programming language [
24,
31] and based on the plm [
32] and frontier [
17] packages. The plm package organizes data in a panel data framework, and the frontier package estimates the SFA model by maximum likelihood method. The regression coefficients, gamma (γ), and time (η) statistics are presented in
Figure 10.
As shown in
Figure 10, the estimate of the gamma parameter (γ) was statistically different from zero and assumed value of 0.96, very close to 1; therefore, inefficiency was present. In addition, the estimation of the time effect (η) was also statistically significant and assumed a positive value, i.e., efficiencies increased over time, as indicated by the mean efficiency of each year in
Figure 10. The estimated efficiencies for each one of the 41 utilities are presented in
Appendix A and
Figure 11, where the line in black is the average and the variability reflects the huge heterogeneity in the current levels of the non-technical losses of the Brazilian distribution utilities.
4. Results and Discussion
The results shown in
Figure 10 also indicate that the coefficients (elasticities) of the “violent death rate” (vio) and the “percentage of people with incomes less than half a minimum wage” (poor) were not statistically significant at the usual levels of significance of 1%, 5%, and 10%. The coefficients of the “collection of garbage” (garbage) and the “proportion of low-income customers in the low-voltage residential market” (lowinc) appeared with negative coefficients. Thus, the increase in these variables reduced the PNTL. The negative coefficient for the “lowinc” variable suggested that the discounts on electricity bill for the low-income families contributed to reducing the PNTL. In a similar way, the negative coefficient for the “garbage” variable indicated that better delivery conditions (lower socioeconomic complexity) could reduce the PNTL. On the other hand, the results showed that the income inequality, subnormal households, and credit default (socioeconomic complexity) contributed to increasing the PNTL.
From the efficiencies estimates, we could take the median efficiency for each utility in order to define the respective PNTL target value.
Table 1 presents the targets for the PNTL determined by the SFA model, taking the first decile of the PNTL in the period of 2007–2016 as the base value.
Figure 12 shows the PNTL boxplots over the period of 2007–2016 for each utility, with the respective target values indicated by a solid black line. Note that in some utilities, the target values fell within the range defined by the respective boxplots or were slightly below the lower fences. Therefore, the targets determined by the SFA model were feasible and could be achieved by the utilities. Additionally, in the utilities with high PNTL levels, the targets were more aggressive and were far from boxplots. More aggressive targets could be achieved by reducing the base value in
Table 2.
In order to allow for comparisons with targets from the ANEEL’s model and the verified PNTL in 2018, the targets from the SFA model (
Table 2) were updated to 2018 via Equation (15). The targets from SFA for 2018 are presented in
Table 3. Next,
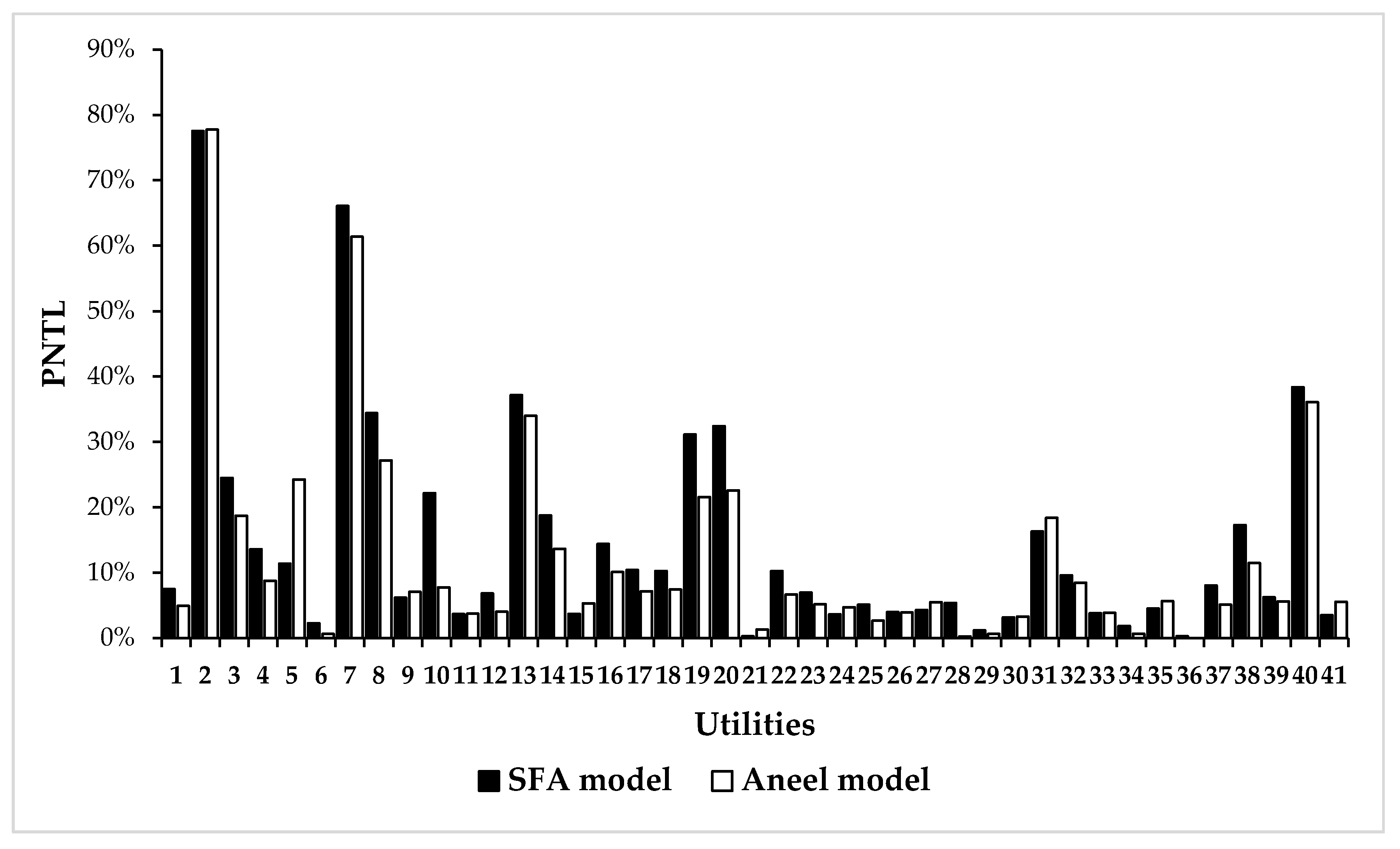
Figure 13 shows the targets from the ANEEL’s and SFA models for 2018.
In
Figure 13, the targets calculated by the ANEEL’s model to 2018 can be seen to have been more stringent than the targets from SFA approach in 28 of the 41 analyzed utilities. In addition, the verified PNTLs in 2018 were above that of the targets from the ANEEL’s model in 34 utilities, while only 22 utilities presented PNTLs above the targets from the SFA model for the same year. As illustrated in
Table 4, only seven utilities achieved the targets defined by the ANEEL’s model, while 19 utilities achieved the targets from the SFA approach. In 20 utilities, the verified PNTLs were greater than the targets defined by both methodologies.
The largest difference was of the order of 14% at utility 10, for which the ANEEL’s model suggested a reduction of the PNTL to almost 8%, while the SFA model suggested a reduction of approximately 22%. Since the base value adopted in the work was the first decile of the PNTL in the period of 2007–2016 (24.6% for utility 10), we observed that the target defined by the ANEEL for utility 10 was unattainable. In fact, in 2018, the verified PNTL in utility 10 (22.9%) was very close to the target of 22% set by the SFA model, but it was way above the target of 8% from the ANEEL’s model. The same situation was observed in utilities 19 and 20, as illustrated in
Figure 13. It is worth pointing out that unattainable targets compromised the economic balance of the utilities. The ANEEL’s approach assigned targets of less than 1% for the PNTLs of utilities 6, 28, 29, 34, and 36 (five utilities), while in the SFA approach, only utilities 21 and 36 had targets below 1%, and both presented PNTL below the targets.
On the other hand,
Figure 13 shows a different situation in utility 5, where the target from the ANEEL’s model (24.2%) was almost the double of the target from the SFA approach (11.4%). It is important to highlight that the target value defined by the ANEEL for utility 5 in 2018 was way above the PNTL values in the period of 2007–2016. One possible explanation for the high target value (24.2%) was the deterioration in the supply conditions of utility 5, which caused losses in 2018 (almost 29%) above historical levels in 2007–2016. In addition, utility 5 went through a privatization process. Therefore, the high target for company 5 may have reflected decisions from the discretionary power of the regulatory agency.
The largest deviations (>5%) between the results from models were in utilities 3, 5, 8, 10, 14, 19, 20, 28, and 38, as indicated by the bottom row of the frequency distribution in
Table 4. In this group, the targets defined by the ANEEL model tended to be lower than the targets from the SFA approach, and they were not achieved in 2018, as indicated in
Table 4. In some of these cases, the methodology employed by the ANEEL required a reduction in the NTL that was not justifiable for distributors that already had very low NTL levels. For example, utility 28 registered a very low NTL level in 2018 0.54%); however, it was above the target set by the ANEEL (0.24%). The target set by the SFA was 5.36% and therefore avoided an improper penalty of the utility.
In others cases, the methodology used by the ANEEL did not seem to correctly consider the historical performance of utilities in reducing NTLs. For example, utilities 3, 8, 14, and 19 operate in extremely complex areas (high levels of violence and social inequality); though they continue to register a high level of NTLs, these utilities have had a very positive history of NTL reductions over the past few years. In 2018, all these utilities had NTLs higher than the regulatory NTL target set by the ANEEL, which implied a financial loss for these companies. However, if these companies were compared with the goals established from the SFA, they would all have had NTL levels lower than or very close to the target. In recent years, the agency itself has recognized the limitation of his own model in relation to these utilities and has, in different ways, adjusted the regulatory target of these utilities.
Despite the differences, in nine utilities, the deviations were lower than 1%, and the two models proposed similar targets for utility 2, where the largest PNTL was observed in 2018 (almost 115%, when considering billed energy consumption). Additionally, the Pearson and Spearman correlation coefficients were 0.97 and 0.95, respectively. In addition, the targets defined by the ANEEL’s model for utilities 8, 10, 19, 20, and 38 could probably not be reached.
It is important to note that the objective of this session was only to show the feasibility of applying the proposed methodology and its possible benefits—hence the selection of only one year (2018). A deeper analysis of the NTL behavior of Brazilian distributors should cover a broader period.
5. Conclusions
Electric regulatory agencies worldwide have large experience with benchmarking methods—DEA and SFA in particular, which have been applied in the regulation of transmission and distribution sectors. For example, the ANEEL has adopted DEA models to assessment the efficiency levels of the operation expenditures for transmission and distribution utilities.
The theft of electric power is a problem faced by Brazilian distribution utilities. Aiming to guide the distribution utilities in combating NTLs, the ANEEL has adopted a regulatory strategy based on the principles of benchmarking. The ANEEL’s strategy is implemented by a panel data econometric model that provides target values for the NTLs for each utility. The econometric approach adopted by the ANEEL follows some basic principles of benchmarking and yardstick competition present in the DEA and SFA models, but it fails because it does not have a clear definition of the efficiency frontier, the main component in a benchmarking framework. In order to overcome this deficiency, we formulated the ANEEL’s econometric model like an SFA model in this work.
We highlighted that the option for SFA models maintained the econometric framework initially adopted by the ANEEL, i.e., the same dependent and explanatory variables in a panel data model. However, the SFA formulation allowed us to estimate the efficiency frontier, a tool that provides PNTL target values in a more transparent way (the current methodology adopted by the ANEEL employs complex criteria that require further clarification). The use of SFA makes the regulatory procedure transparent and reproducible.
The SFA model can take different forms. We evaluated other specifications, but the most satisfactory results were produced by the cost SFA model with the Cobb–Douglas equation and inefficiency term error with a half-normal distribution, i.e., the basic normal/half-normal SFA model.
Finally, the results from the case study with the main Brazilian electric distribution utilities showed that the proposed cost SFA model could provide feasible target values for the PNTL, i.e., targets that could be reached by the distribution utilities and that satisfy a range of economic, social, and political constraints while also keeping the focus on controlling non-technical losses.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











