Forecasting the Carbon Price Using Extreme-Point Symmetric Mode Decomposition and Extreme Learning Machine Optimized by the Grey Wolf Optimizer Algorithm


Abstract
:1. Introduction
- The extreme-point symmetric mode decomposition is applied, to decompose the carbon price to promote the prediction accuracy.
- The extreme learning machine optimized by the grey wolf algorithm could obtain a good performance with predictions.
- The proposed model ESMD-GWO-ELM significantly improves the forecasting accuracy of the carbon price, with only the historical carbon price sequence being taken into account.
2. Methodology
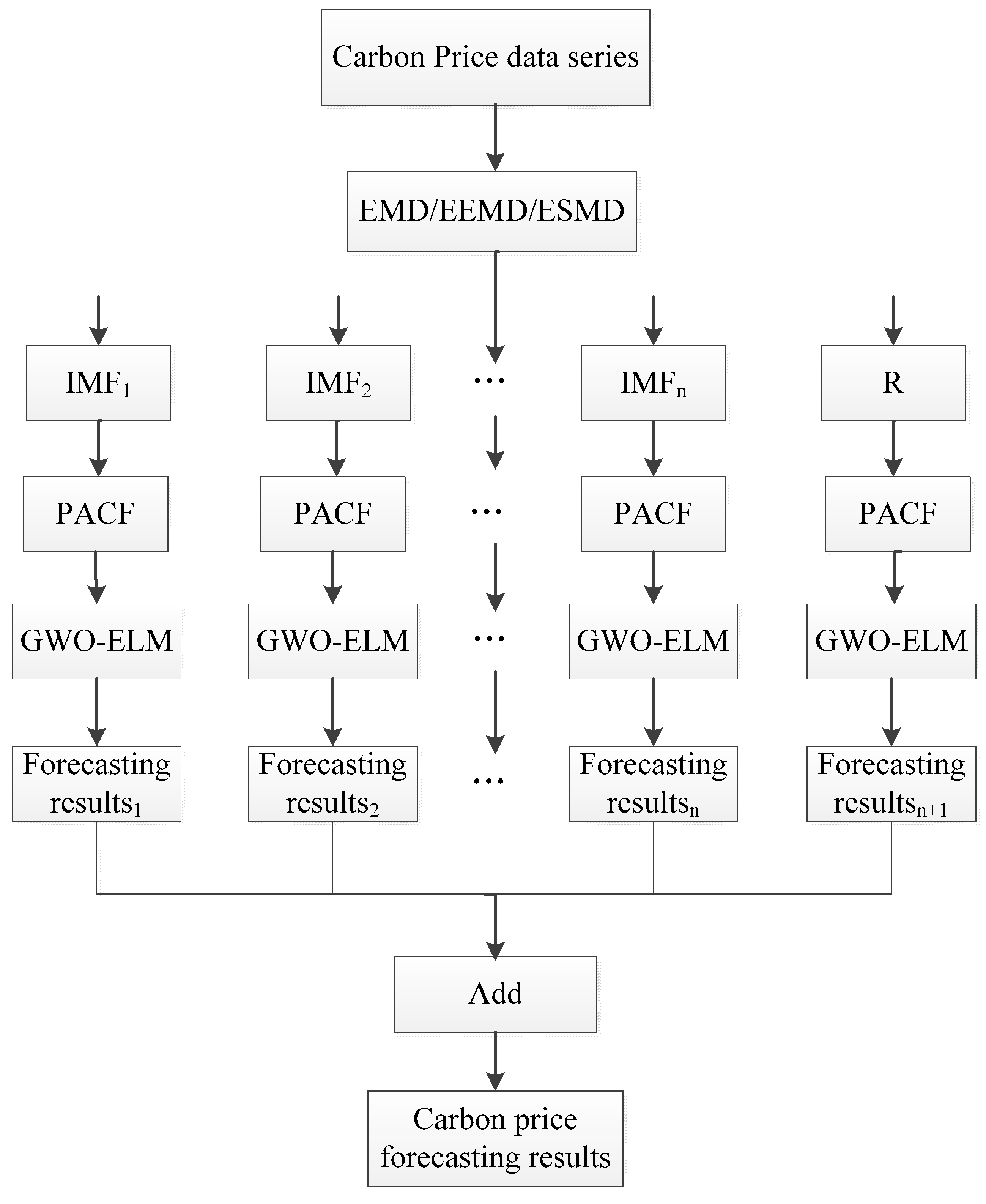
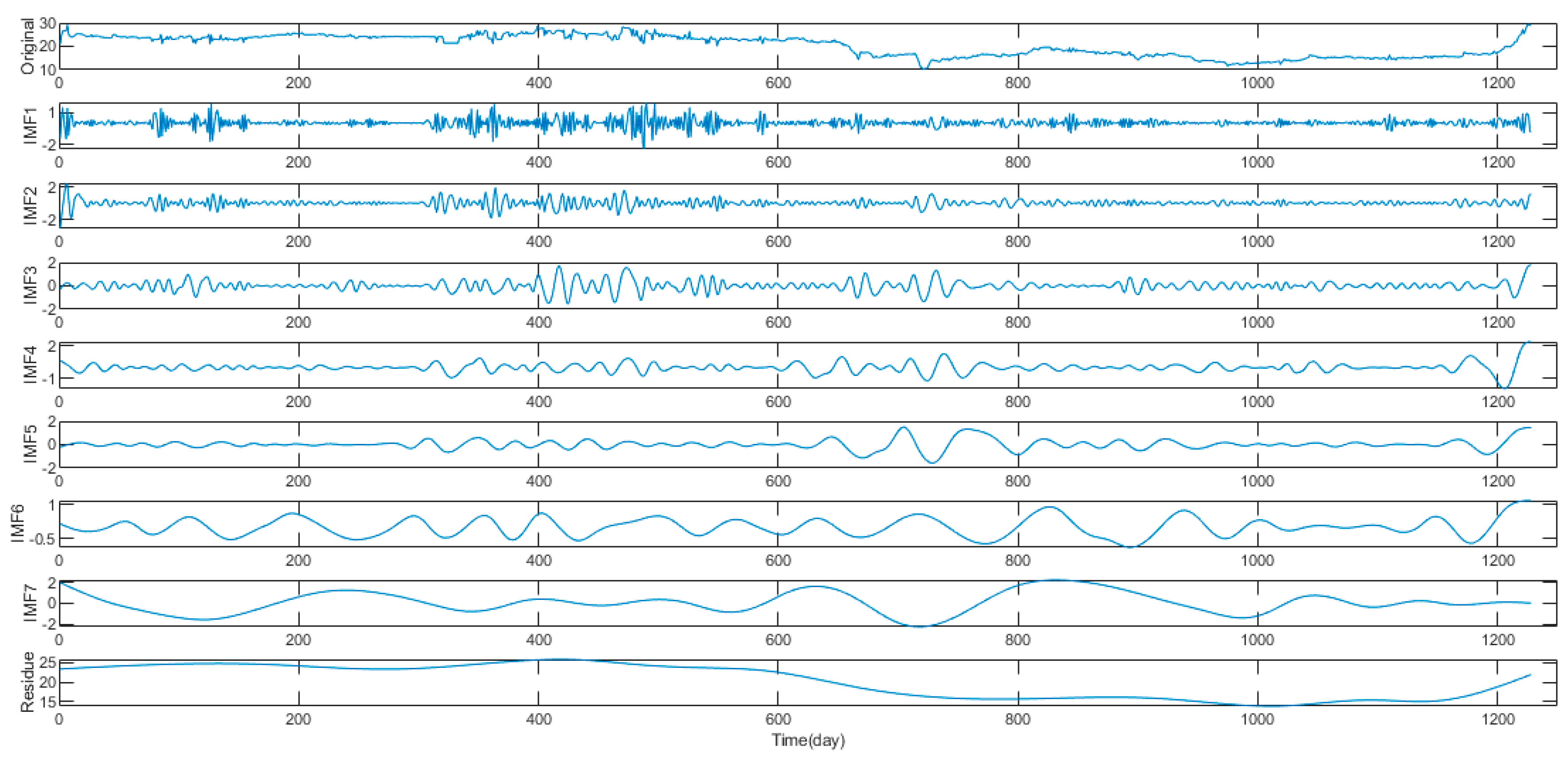
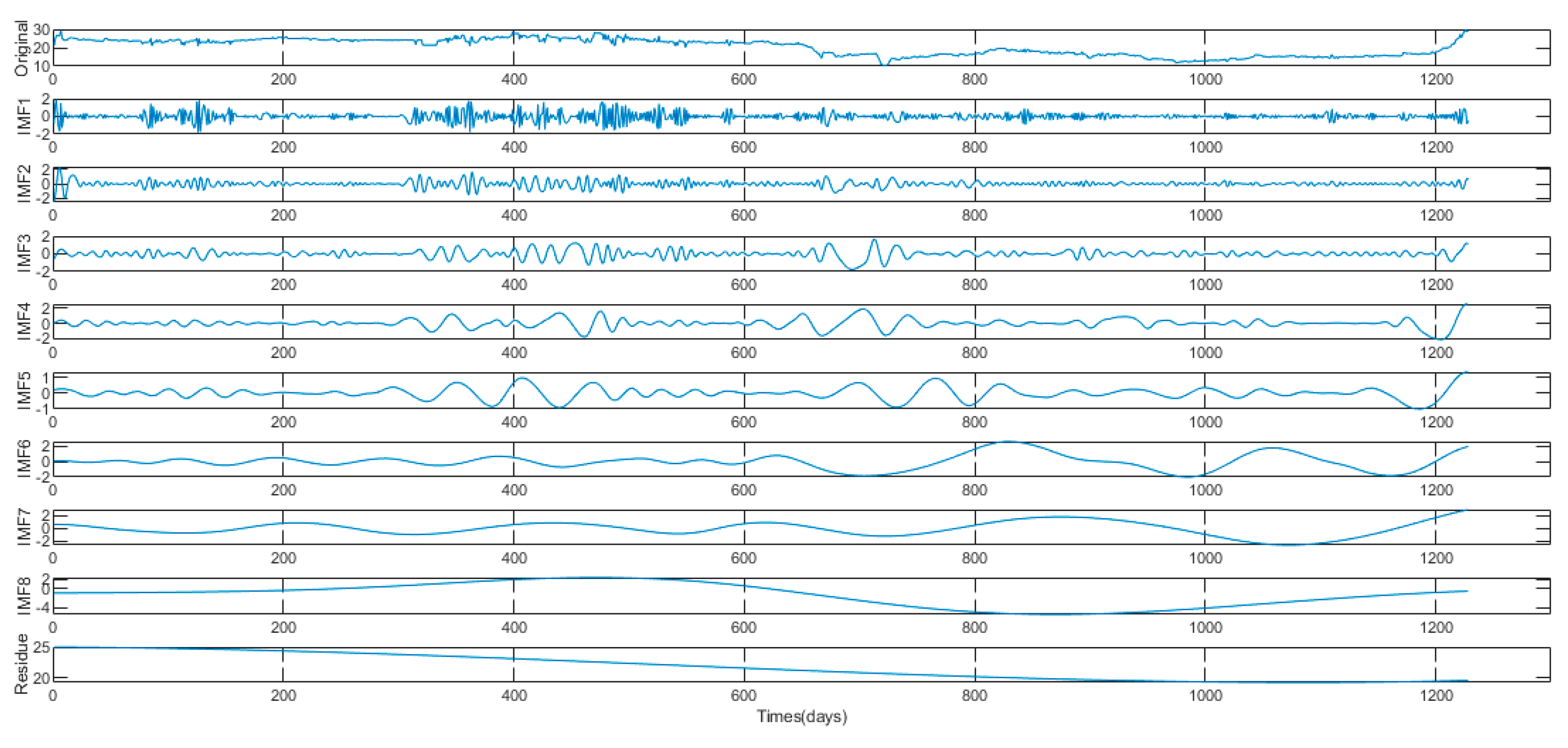
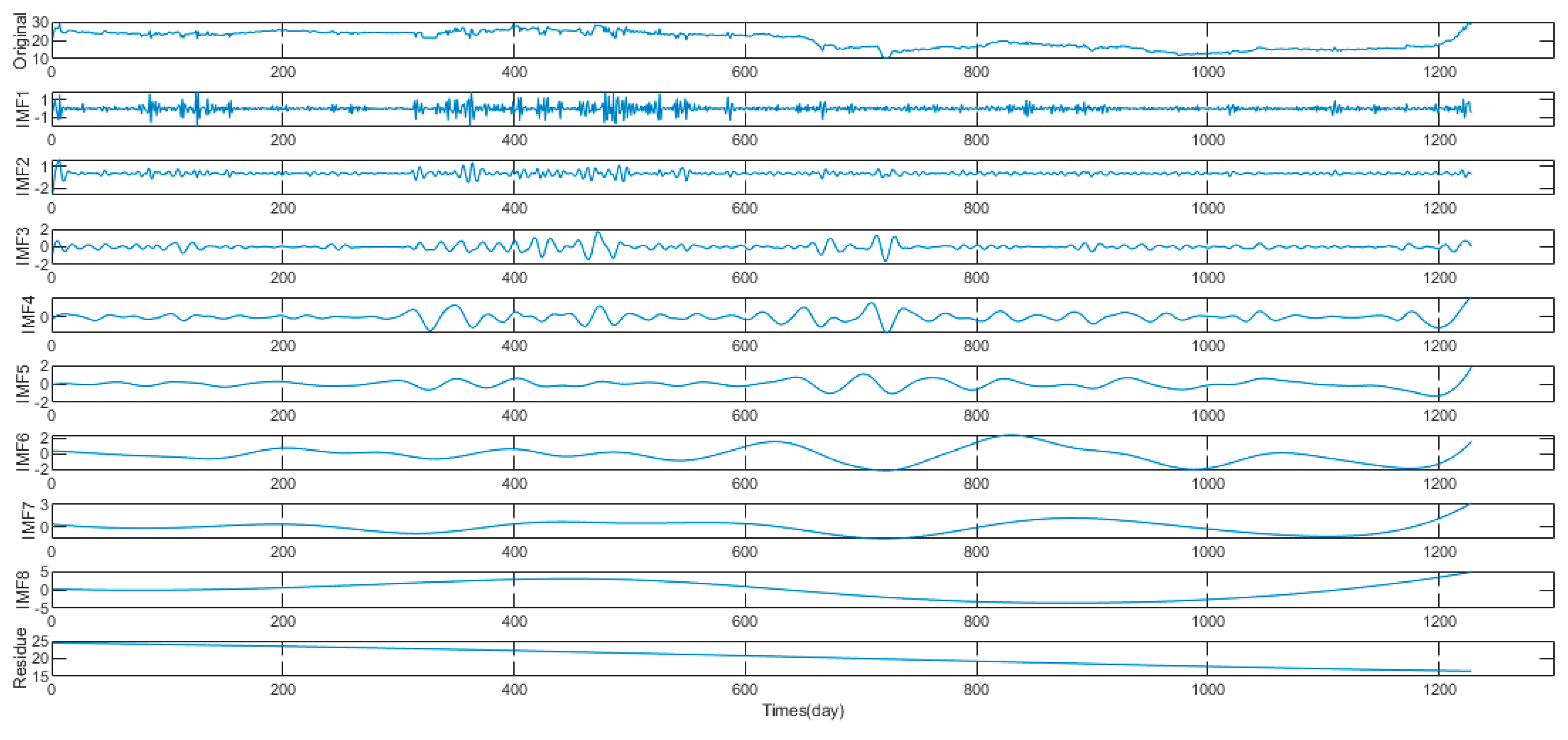
2.1. Extreme-Point Symmetric Mode Decomposition
- Step 1:
- Find all of the extreme points (maximum and minimum) of the whole data series , and record as .
- Step 2:
- Connect all of the adjacent poles with line segments, and record the midpoints of the line as
- Step 3:
- The boundary points and are added to the left and right ends, respectively, using certain methods.
- Step 4:
- Construct interpolation curves by using the obtained midpoints, and calculate the mean curve .
- Step 5:
- Repeat the above steps for the series until the number of screenings reaches the preset maximum value , and the first decomposed empirical mode is obtained and named as .
- Step 6:
- Repeat the above five steps for the remaining sequence until the remaining sequence has only a certain number of poles left, and the decomposed empirical modes can be obtained, respectively.
- Step 7:
- Change the number of screening times within the limited interval , repeat the above six steps, and then calculate the variance ratio and plot the variance ratio graph with .
- Step 8:
- Select the number of transformations as the optimal number of screenings when the variance ratio is the smallest, and repeat the previous six steps until all of the decomposed empirical modes are outputs.
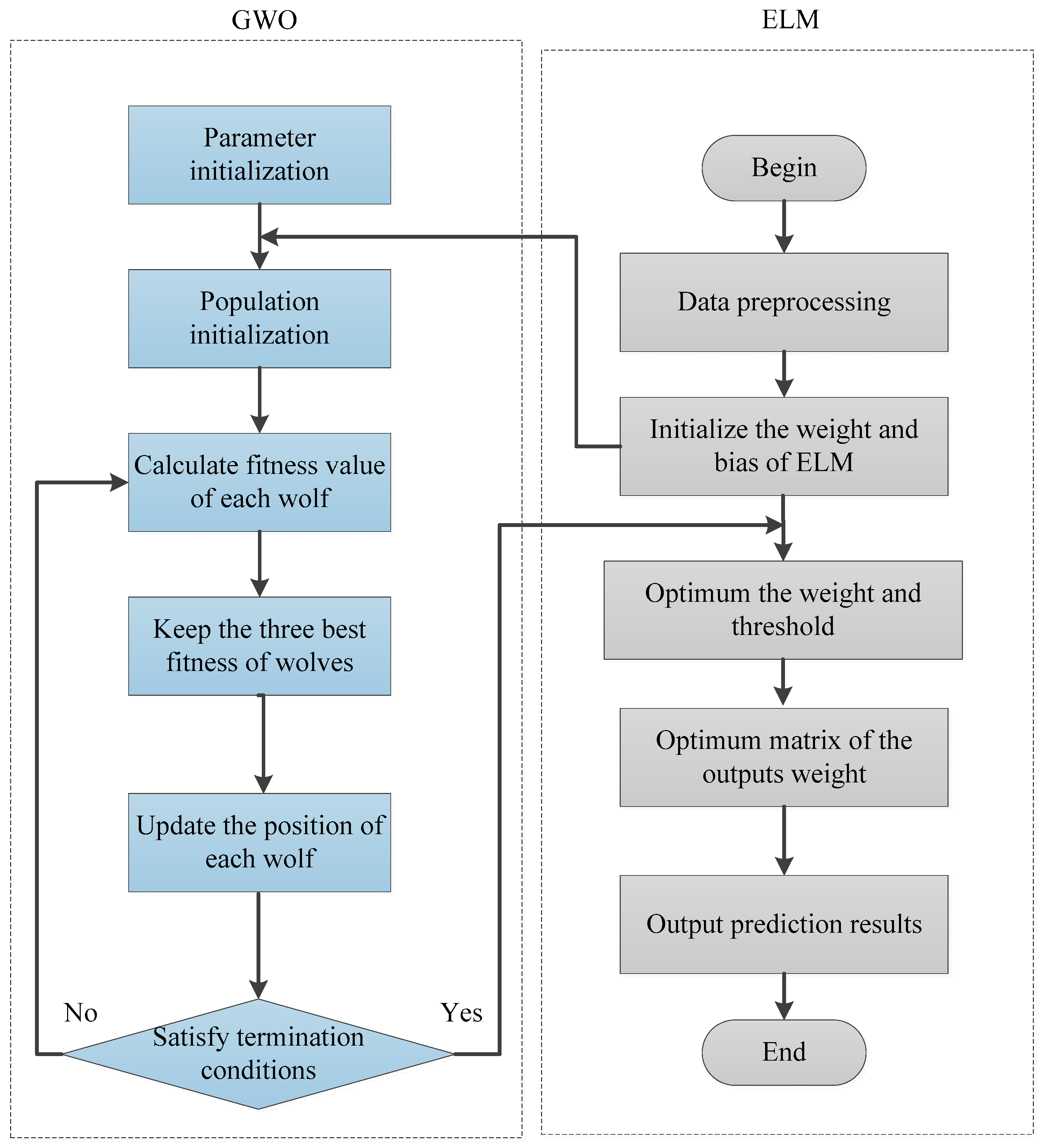
2.2. Extreme Learning Machine
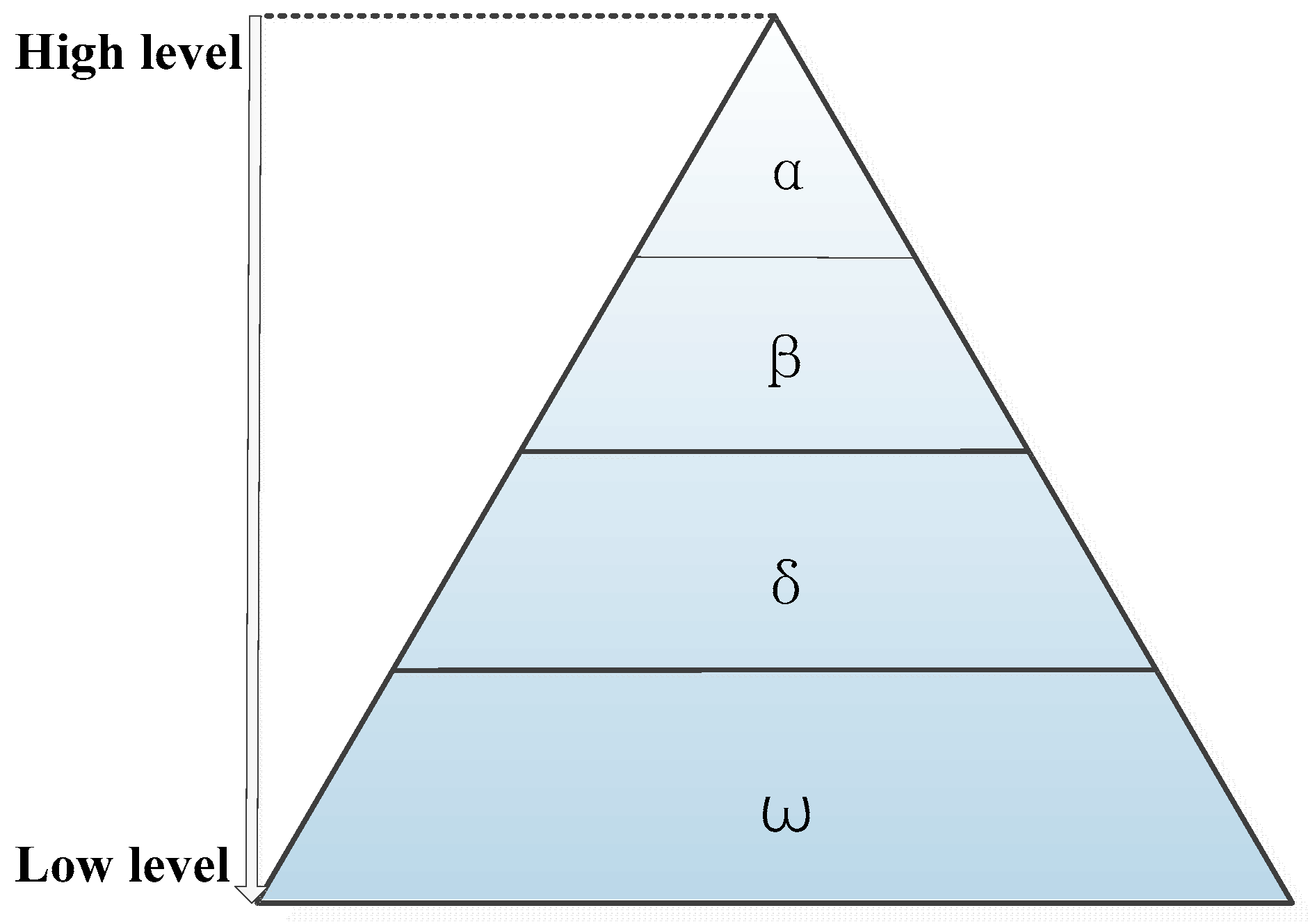
2.3. Grey Wolf optimizer Algorithm
| Algorithm 1: The GWO algorithm |
| Step 1: randomly initialize the population to be within the specified range; Step 2: calculate the fitness of each individual; Step 3: select, in order of fitness , , and ; Step 4: update the other wolves using formulas (4) to (14) Step 5: update the parameters , , and ; Step 6: if the end condition is not met, go to step 2; Step 7: output the location of the wolf. |
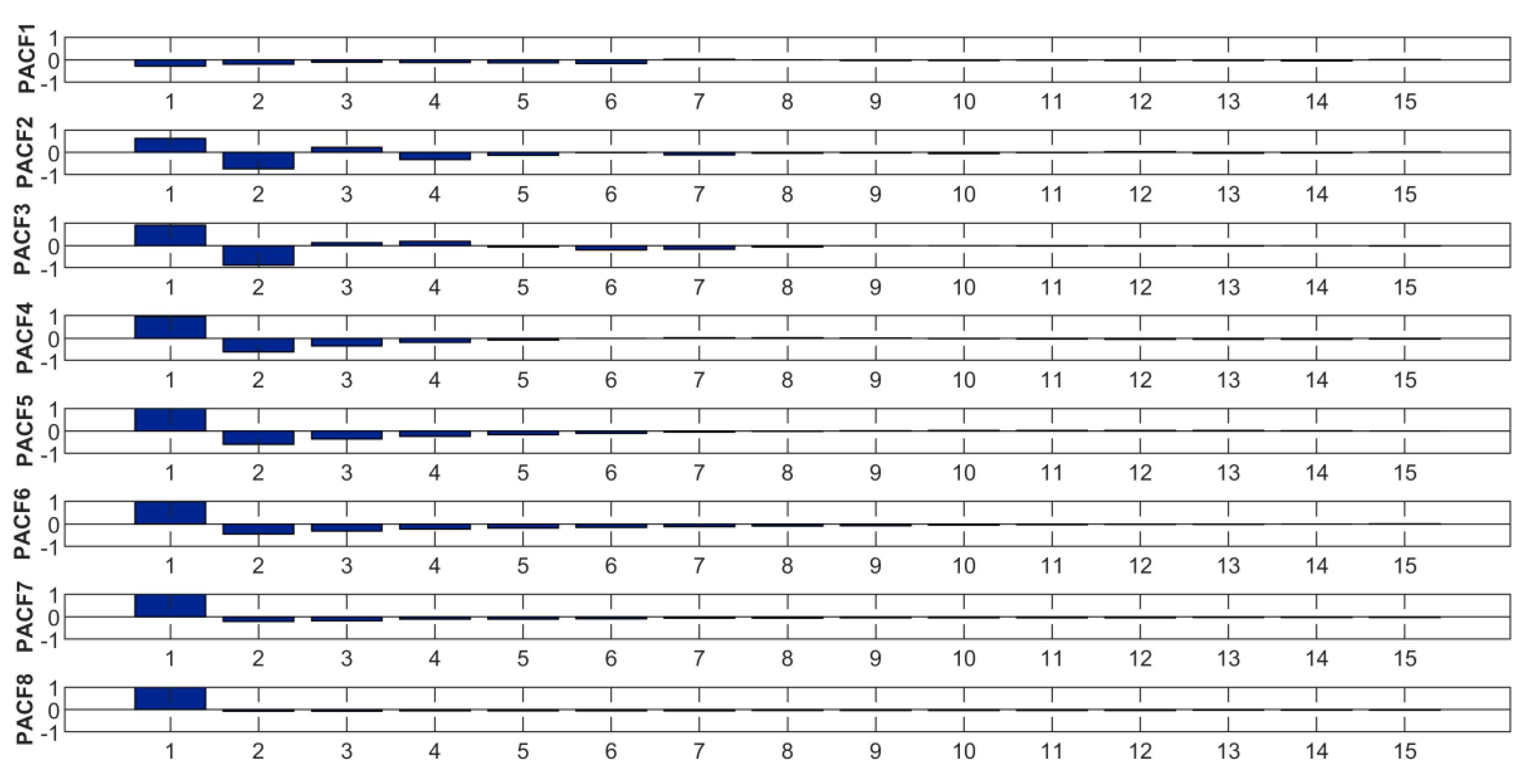
2.4. The Partial Autocorrelation Function
3. The Proposed Model
4. Empirical Analysis
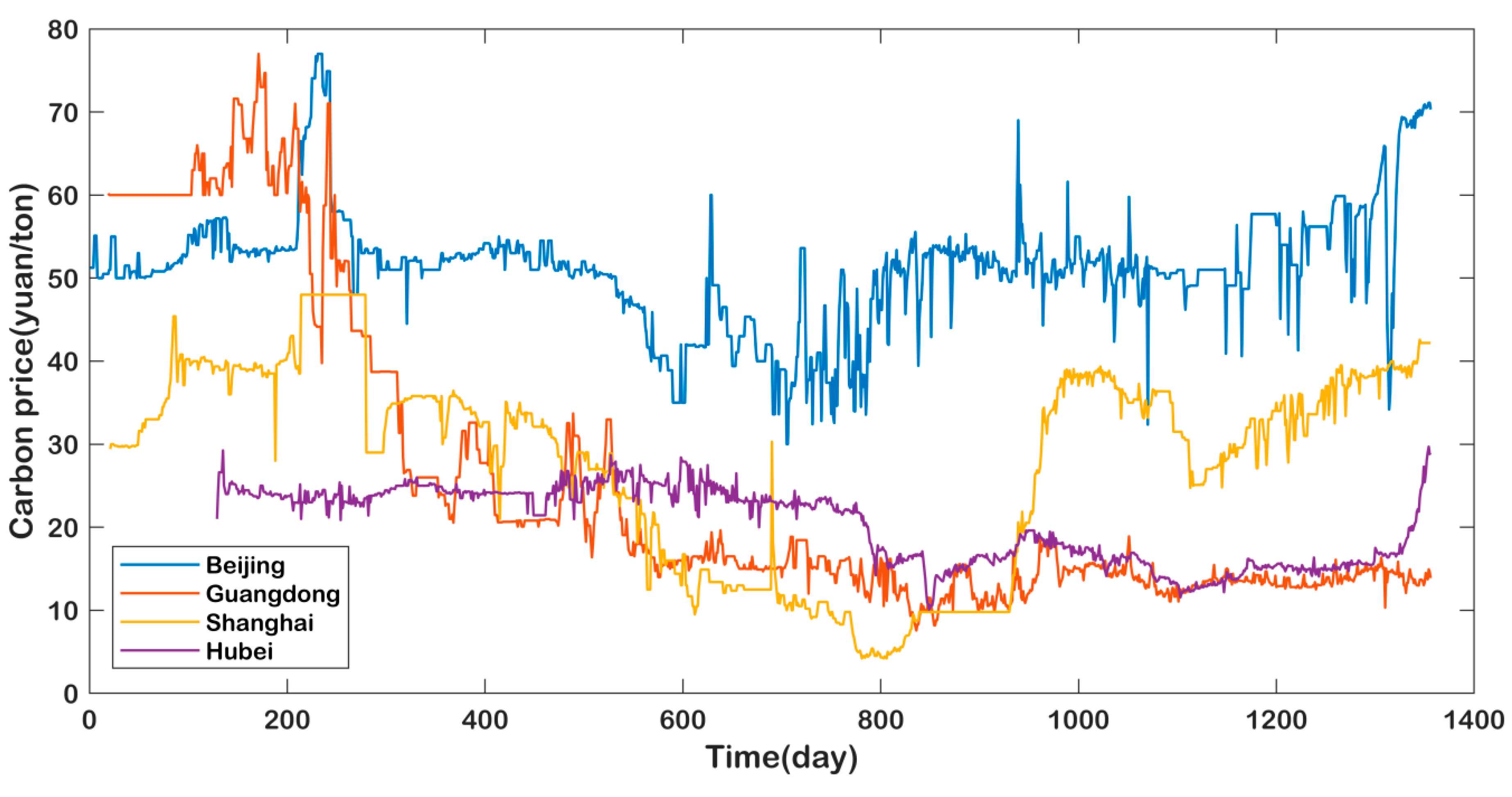
4.1. Data
4.2. Non-Stationary and Nonlinear Tests of Carbon Price
4.3. Data Processing
4.4. Determination of the Input Variables by PACF
4.5. Accuracy Assessment
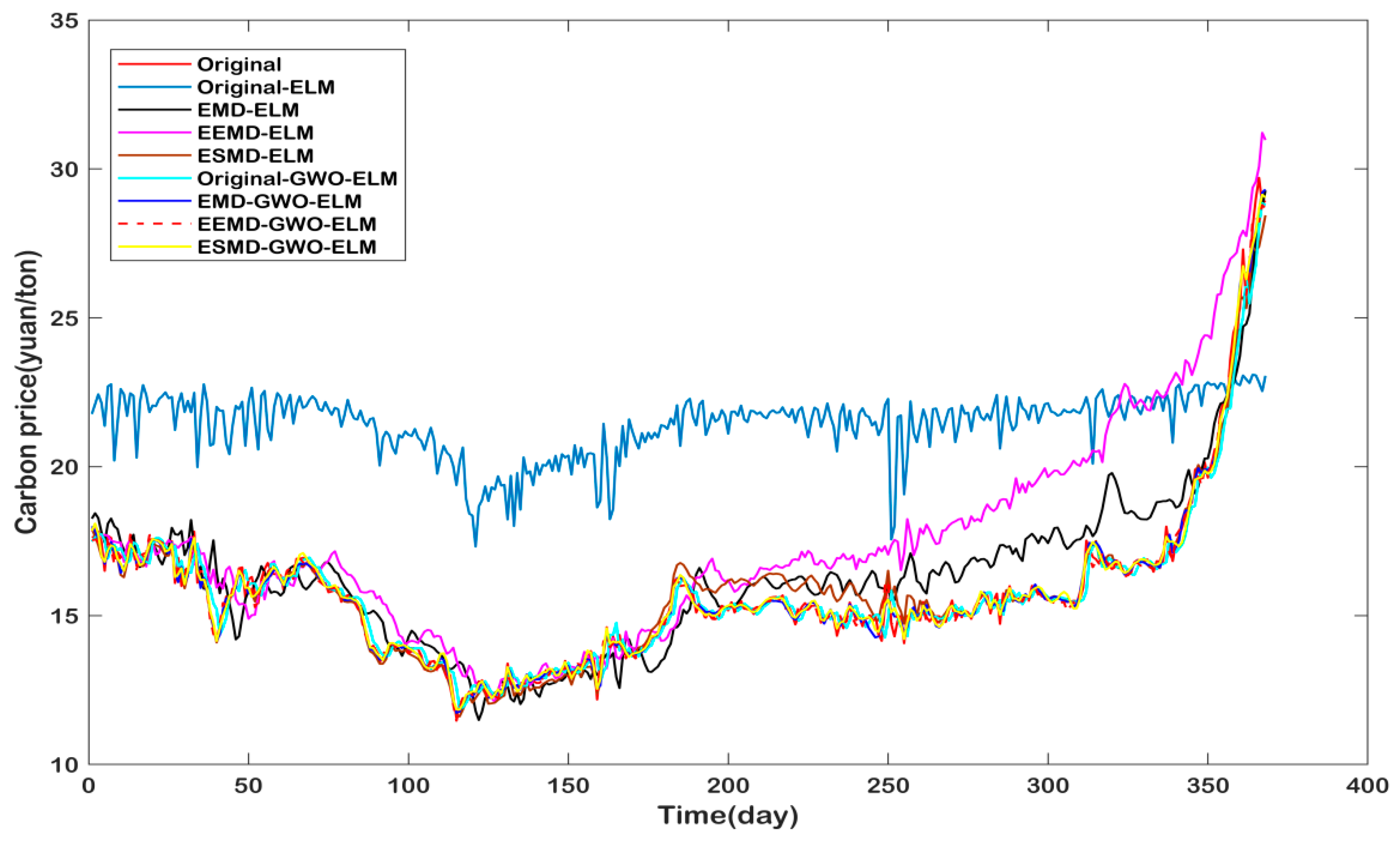
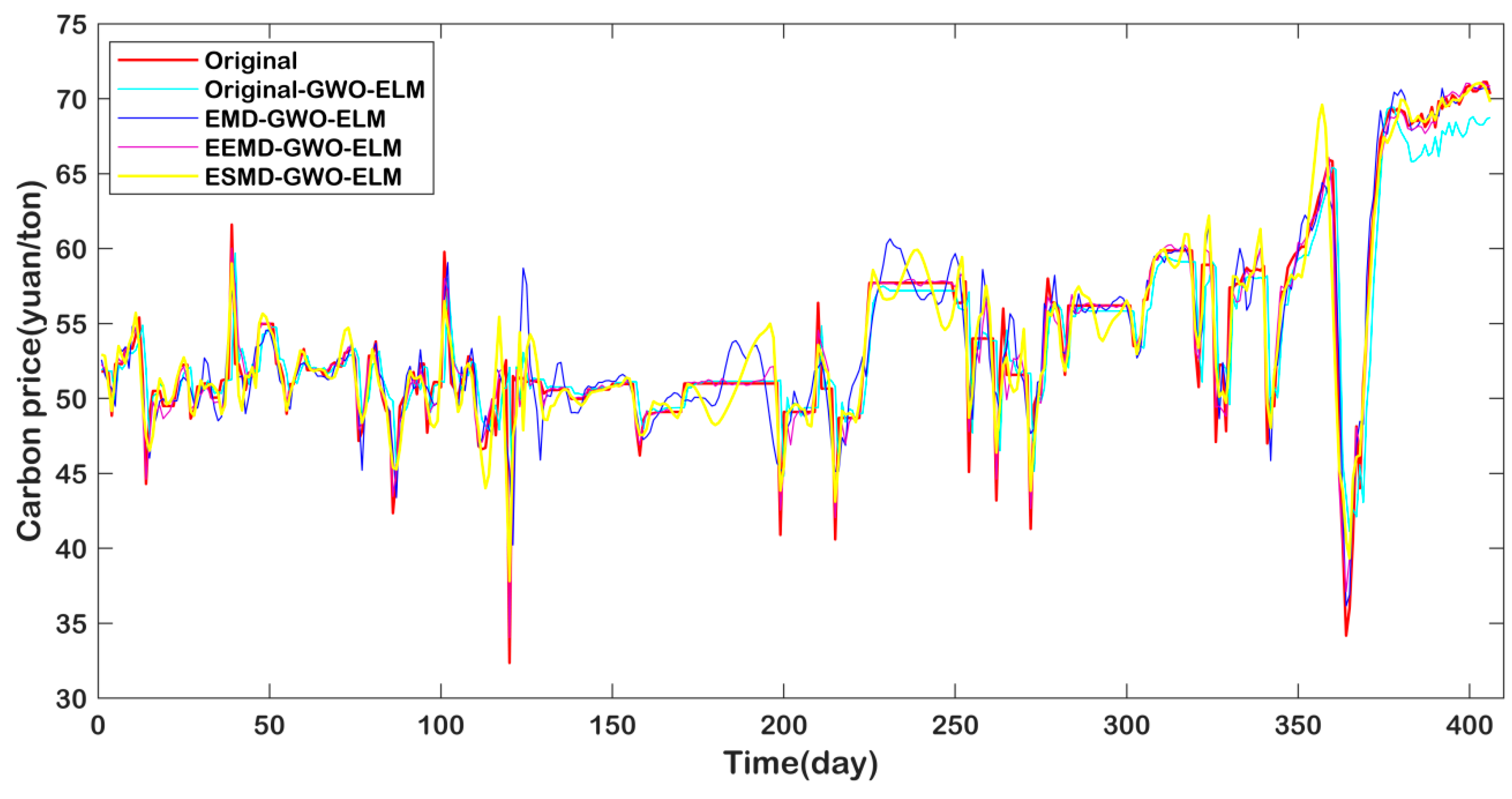
4.6. Forecasting Results and Discussion
- (a)
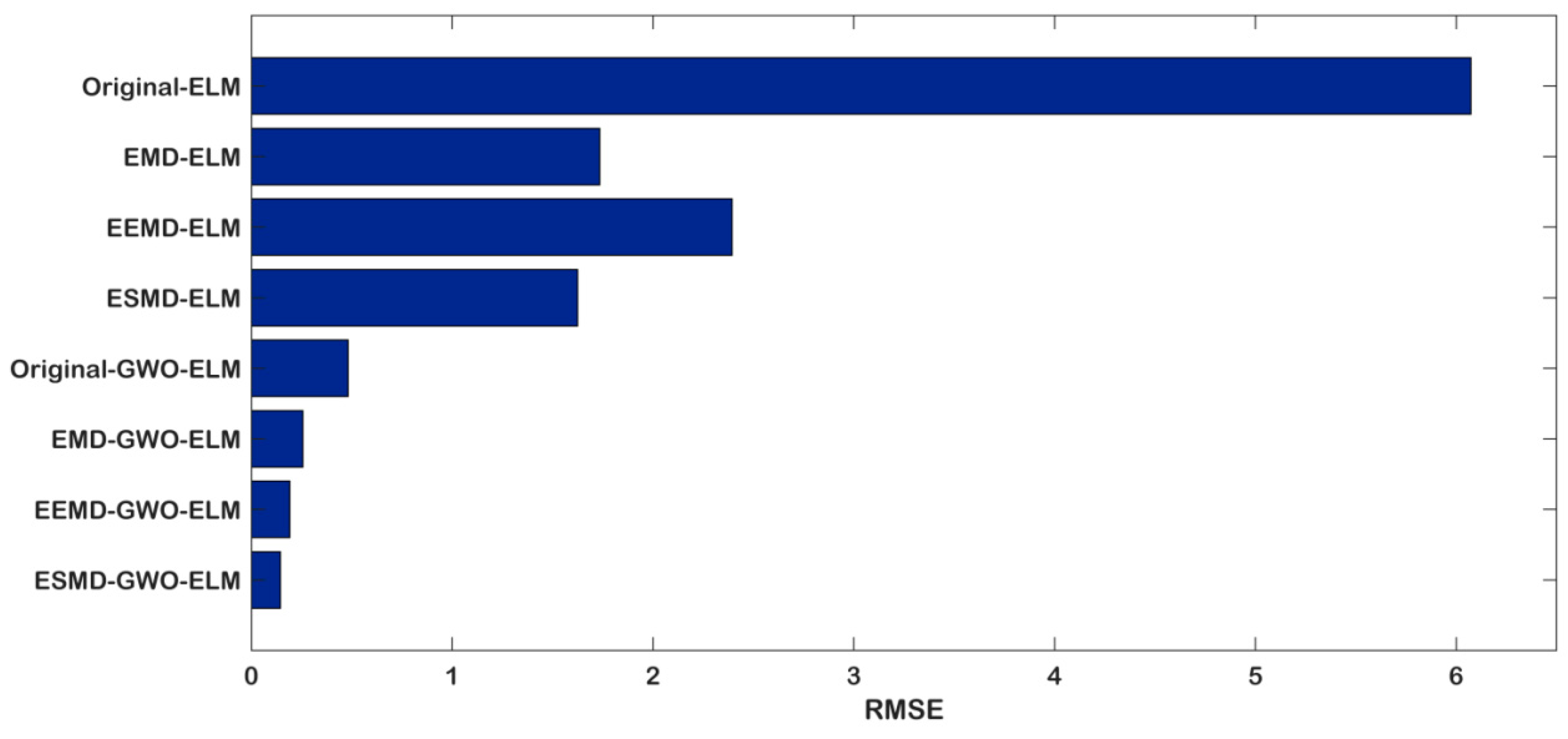
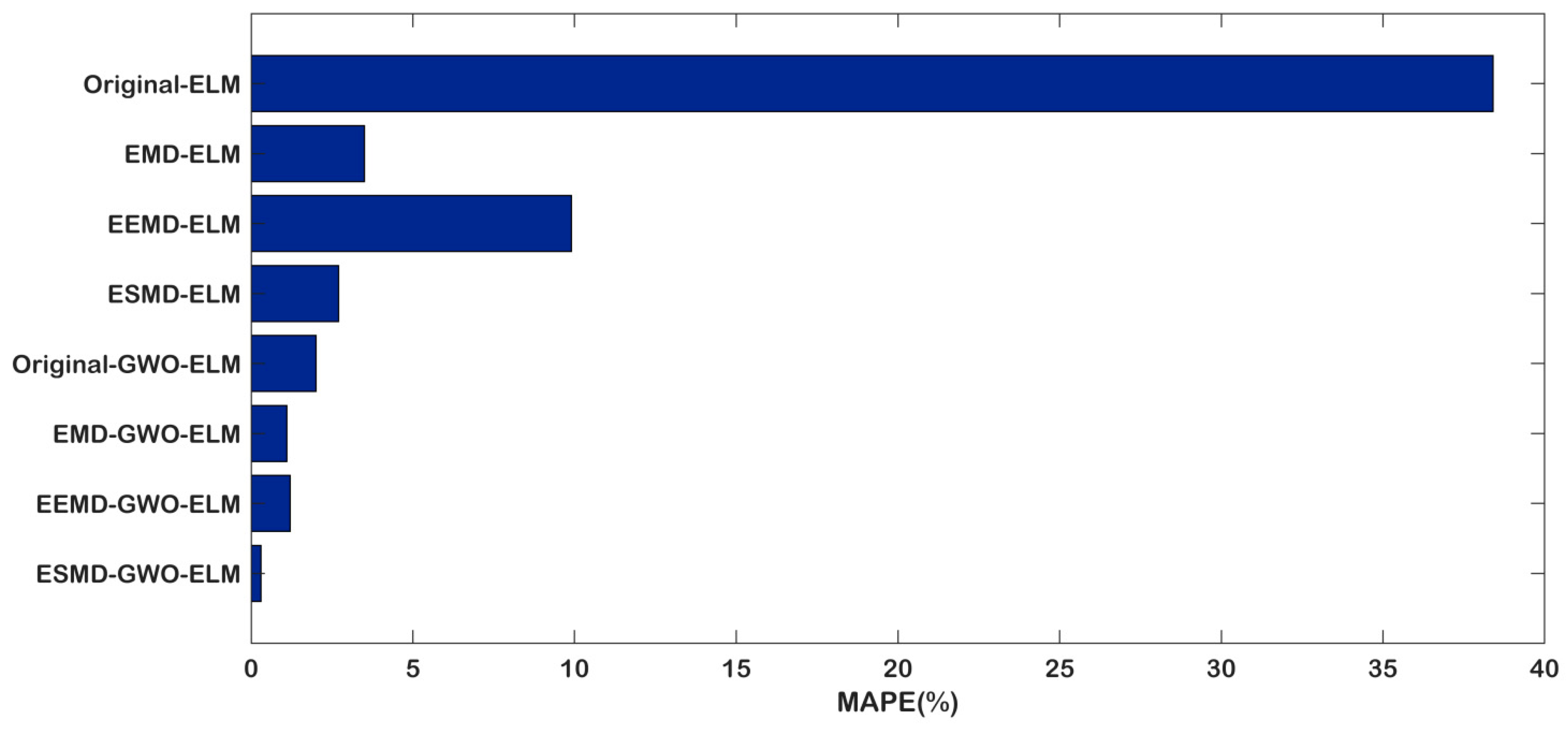
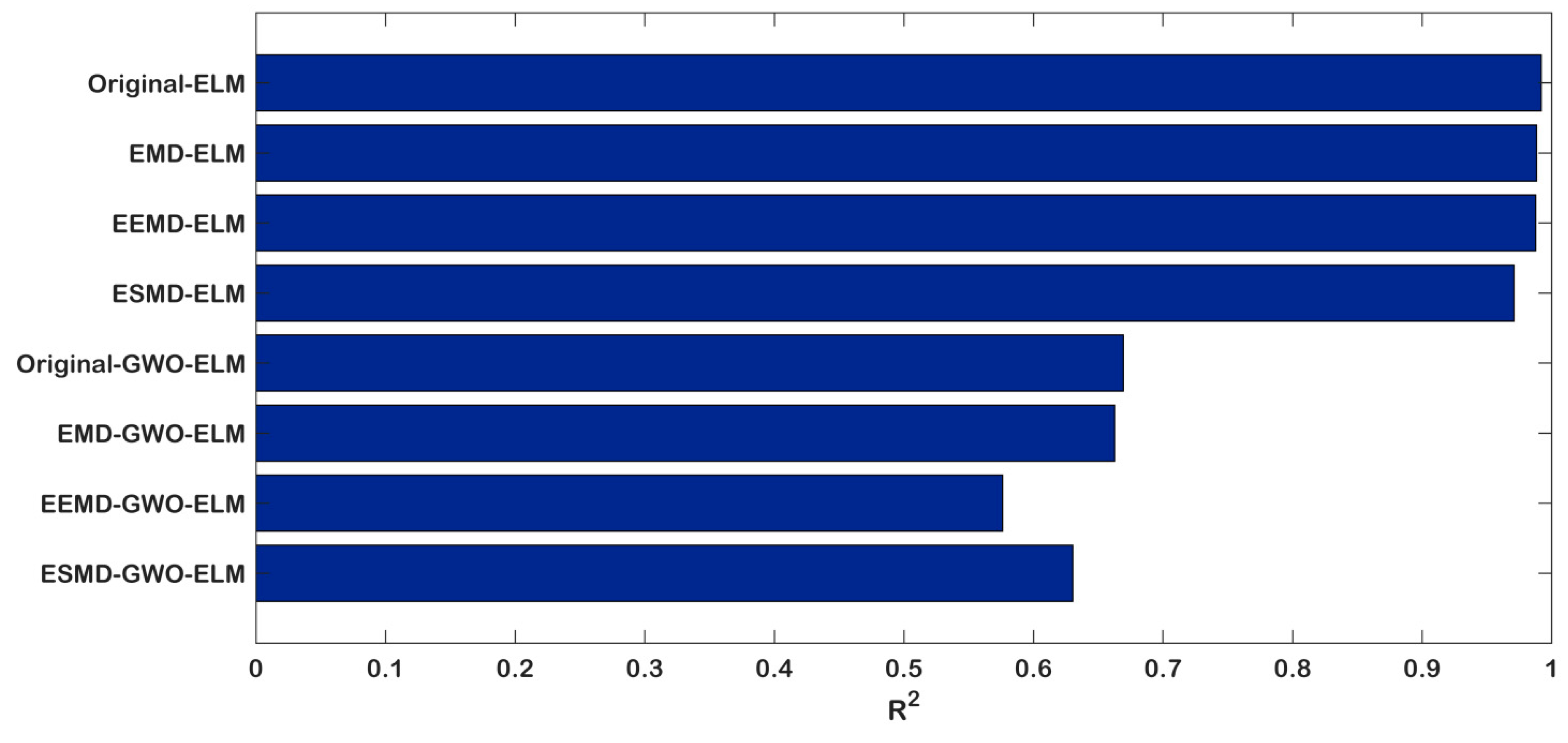
- The proposed model ESMD-GWO-ELM has the lowest RMSE (0.1438) and MAPE (0.31), and highest R2 (0.9918), which illustrates that the model performs significantly better than all of the considered benchmark models in the carbon price forecasting of Hubei.
- (b)
- Compared with the eight models, the Original-ELM model is the worst-performing, as it has the biggest RMSE (6.0734), MAPE (38.42), and lowest R2 (0.6304). This is primarily due to the fact that the original carbon price is unstable and nonlinear, so that the single model is not fit for direct forecasting without decomposition processing.
- (c)
- In the Original-ELM, EMD-ELM, EEMD-ELM, ESMD-ELM prediction models, the decomposed prediction models are obviously superior to the direct-prediction models. The main reason is that the structure and fluctuation of the decomposed IMF sequence become simpler and more stable, which enhances the forecast precision.
- (d)
- Compare with individual models (Original-ELM, EMD-ELM, EEMD-ELM, and ESMD-ELM) with optimized models (Original-GWO-ELM, EMD-GWO-ELM, EEMD-GWO-ELM, and ESMD-GWO-ELM), it is apparent that the GWO-ELM is significantly superior to the ELM model. This result demonstrates that the optimizing ELM parameter is necessary and meaningful.
- (e)
- It is evident that the ESMD decomposition method performs better than the EMD and EEMD methods, whatever the ESMD-ELM or ESMD-GWO-ELM, when compared to the decomposed models (EMD, EEMD, and ESMD). The result proves the superiority of the ESMD decomposition model.
- (f)
- However, compared with the EMD and EEMD methods, it is hard to decide which one is better. As shown in Table 7, the RMSE (1.7352) and MAPE (3.51) values of EMD-ELM are lower than those of EEMD-ELM (2.3936 and 9.92 respectively), which leads to the conclusion that the EMD-ELM performs better. However, when we compare the EMD-GWO-ELM and EEMD-GWO-ELM, the RMSE value of EEMD-GWO-ELM is 0.1917, which is lower than the value of 0.2559 of EMD-GWO-ELM; the R2 value is higher, but the MAPE value is bigger than the EMD-GWO-ELM. Therefore, the EEMD decomposes the model performances better than the EMD. Above all, there is not enough evidence on which to judge which one is better. Thus, this conclusion will be demonstrated in the following section.
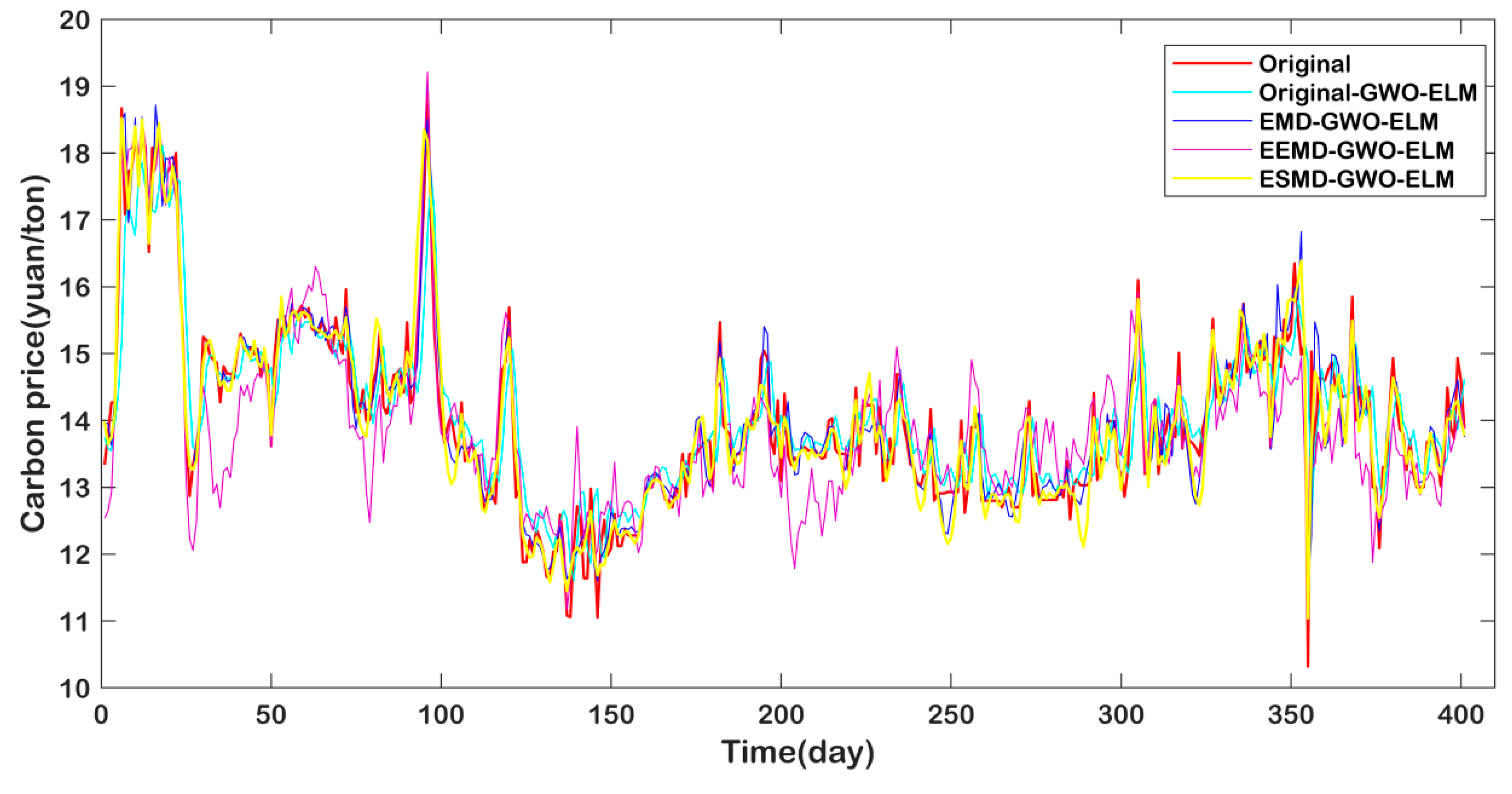
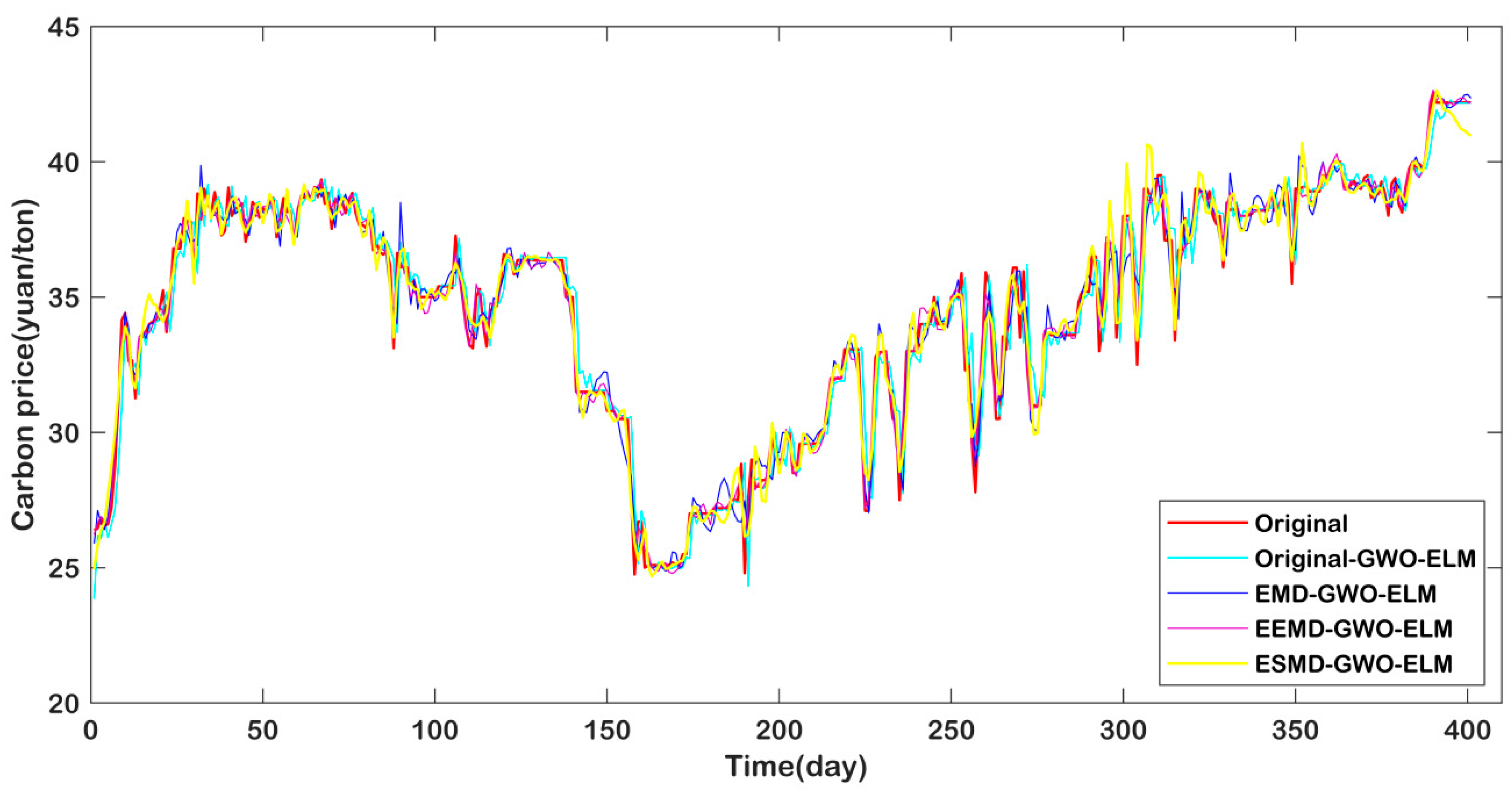
4.7. Additional Forecasting Case
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fan, J.H.; Todorova, N. Dynamics of China’s carbon prices in the pilot trading phase. Appl. Energy 2017, 208, 1452–1467. [Google Scholar] [CrossRef]
- Dormady, N.C. Carbon auctions, energy markets & market power: An experimental analysis. Energy Econ. 2014, 44, 468–482. [Google Scholar]
- Zhu, B.; Ye, S.; Wang, P.; He, K.; Zhang, T.; Wei, Y.-M. A novel multiscale nonlinear ensemble leaning paradigm for carbon price forecasting. Energy Econ. 2018, 70, 143–157. [Google Scholar] [CrossRef]
- Zhu, J.; Wu, P.; Chen, H.; Liu, J.; Zhou, L. Carbon price forecasting with variational mode decomposition and optimal combined model. Phys. A-Stat. Mech. Its Appl. 2019, 519, 140–158. [Google Scholar] [CrossRef]
- Karplus, V.J. Institutions and Emissions Trading in China. AEA Pap. Proc. 2018, 108, 468–472. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, C. Analysis and forecasting of the carbon price using multi—Resolution singular value decomposition and extreme learning machine optimized by adaptive whale optimization algorithm. Appl. Energy 2018, 231, 1354–1371. [Google Scholar] [CrossRef]
- Yi, L.; Li, Z.-P.; Yang, L.; Liu, J.; Liu, Y.-R. Comprehensive evaluation on the “maturity” of China’s carbon markets. J. Clean. Prod. 2018, 198, 1336–1344. [Google Scholar] [CrossRef]
- Tan, X.; Wang, X. The market performance of carbon trading in China: A theoretical framework of structure-conduct-performance. J. Clean. Prod. 2017, 159, 410–424. [Google Scholar] [CrossRef]
- World Bank; Ecofys. State and Trends of Carbon Pricing 2018; The World Bank: Washington, DC, USA, 2018. [Google Scholar]
- Stiglitz, J.; Stern, N.; Duan, M.; Edenhofer, O.; Giraud, G.; Heal, G.; La Rovere, E.L.; Morris, A.; Moyer, E.; Pangestu, M.; et al. Report of the High-Level Commission on Carbon Prices; Carbon Pricing Leadership Coalition: Washington, DC, USA, 2017. [Google Scholar]
- Stefano, C.S. Kallbekken;Anton Orlov, How to win public support for a global carbon tax. Nature 2019, 565, 289. [Google Scholar]
- Zhang, Y.J.; Wei, Y.M. An overview of current research on EU ETS: Evidence from its operating mechanism and economic effect. Appl. Energy 2010, 87, 1804–1814. [Google Scholar] [CrossRef]
- Hepburn, C.; Neuhoff, K.; Acworth, W.; Burtraw, D.; Jotzo, F. The Economics of the EU ETS Market Stability Reserve. J. Environ. Econ. Manag. 2016, 80, 1–5. [Google Scholar] [CrossRef]
- Keppler, J.H.; Mansanet-Bataller, M. Causalities between CO, electricity, and other energy variables during phase I and phase II of the EU ETS. Energy Policy 2010, 38, 3329–3341. [Google Scholar] [CrossRef]
- Zeitlberger, A.C.M.; Brauneis, A. Modeling carbon spot and futures price returns with GARCH and Markov switching GARCH models. Cent. Eur. J. Oper. Res. 2014, 24, 1–28. [Google Scholar] [CrossRef]
- Bredin, D.; Parsons, J.E. Why is Spot Carbon so Cheap and Future Carbon so Dear? The Term Structure of Carbon Prices. Energy J. 2016, 37. [Google Scholar] [CrossRef]
- Zhu, B.; Chevallier, J.; Ma, S.; Wei, Y. Examining the structural changes of European carbon futures price 2005–2012. Appl. Econ. Lett. 2017, 22, 335–342. [Google Scholar] [CrossRef]
- Arouri, M.E.H.; Jawadi, F.; Nguyen, D.K. Nonlinearities in carbon spot-futures price relationships during Phase II of the EU ETS. Econ. Model. 2012, 29, 884–892. [Google Scholar] [CrossRef]
- Kanamura, T. Role of carbon swap trading and energy prices in price correlations and volatilities between carbon markets. Energy Econ. 2016, 54, 204–212. [Google Scholar] [CrossRef]
- Chen, X.; Liu, M.; Liu, Y.; University, S.N. Price Drivers and Structural Breaks in China’s Carbon Prices:Based on Seven Carbon Trading Pilots. Econ. Probl. 2016, 11, 29–35. [Google Scholar]
- Tan, X.-P.; Wang, X.-Y. Dependence changes between the carbon price and its fundamentals: A quantile regression approach. Appl. Energy 2017, 190, 306–325. [Google Scholar] [CrossRef]
- Hammoudeh, S.; Nguyen, D.K.; Sousa, R.M. Energy prices and CO2 emission allowance prices: A quantile regression approach. Energy Policy 2014, 70, 201–206. [Google Scholar] [CrossRef]
- Aatola, P.; Ollikainen, M.; Toppinen, A. Price determination in the EU ETS market: Theory and econometric analysis with market fundamentals. Energy Econ. 2013, 36, 380–395. [Google Scholar] [CrossRef]
- Zhao, X.G.; Wu, L.; Li, A. Research on the efficiency of carbon trading market in China. Renew. Sustain. Energy Rev. 2017, 79, 1–8. [Google Scholar] [CrossRef]
- Daskalakis, G. On the efficiency of the European carbon market: New evidence from Phase II. Energy Policy 2013, 54, 369–375. [Google Scholar] [CrossRef]
- Montagnoli, A.; Vries, F.P.D. Carbon trading thickness and market efficiency. Energy Econ. 2010, 32, 1331–1336. [Google Scholar] [CrossRef] [Green Version]
- Daskalakis, G.; Markellos, R.N. Are the European Carbon Markets Efficient? Soc. Sci. Electron. Publ. 2008, 17. [Google Scholar]
- Zhang, J.; Li, D.; Hao, Y.; Tan, Z. A hybrid model using signal processing technology, econometric models and neural network for carbon spot price forecasting. J. Clean. Prod. 2018, 204, 958–964. [Google Scholar] [CrossRef]
- Tsai, M.T.; Kuo, Y.T. Application of Radial Basis Function Neural Network for Carbon Price Forecasting. Appl. Mech. Mater. 2014, 590, 683–687. [Google Scholar] [CrossRef]
- Guðbrandsdóttir, H.N.; Haraldsson, H.Ó. Predicting the Price of EU ETS Carbon Credits. Syst. Eng. Procedia 2011, 1, 481–489. [Google Scholar] [CrossRef] [Green Version]
- Byun, S.J.; Cho, H. Forecasting carbon futures volatility using GARCH models with energy volatilities. Energy Econ. 2013, 40, 207–221. [Google Scholar] [CrossRef]
- Glosten, L.R.; Jagannathan, R.; Runkle, D.E. On the Relation between the Expected Value and the Volatility of the Nominal Excess Return on Stocks. J. Financ. 1993, 48, 1779–1801. [Google Scholar] [CrossRef] [Green Version]
- Chevallier, J. Volatility forecasting of carbon prices using factor models. Econ. Bull. 2010, 30, 1642–1660. [Google Scholar]
- Chevallier, J. Nonparametric modeling of carbon prices. Energy Econ. 2011, 33, 1267–1282. [Google Scholar] [CrossRef]
- Conrad, C.; Rittler, D.; Rotfuß, W. Modeling and explaining the dynamics of European Union Allowance prices at high-frequency. Energy Econ. 2010, 34, 316–326. [Google Scholar] [CrossRef]
- Sanin, M.E.; Violante, F.; Mansanet-Bataller, M. Understanding volatility dynamics in the EU-ETS market. Energy Policy 2015, 82, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Koop, G.; Tole, L. Forecasting the European Carbon Market. J. R. Stat. Soc. 2013, 176, 723–741. [Google Scholar] [CrossRef]
- Tsai, M.-T.; Kuo, Y.-T. A Forecasting System of Carbon Price in the Carbon Trading Markets Using Artificial Neural Network. Int. J. Environ. Sci. Dev. 2013, 4, 163–167. [Google Scholar] [CrossRef]
- Zhu, B.; Chevallier, J. Carbon Price Forecasting with a Hybrid ARIMA and Least Squares Support Vector Machines Methodology. Omega-Int. J. Manag. Sci. 2013, 41, 517–524. [Google Scholar] [CrossRef]
- Atsalakis, G.S. Using computational intelligence to forecast carbon prices. Appl. Soft Comput. 2016, 43, 107–116. [Google Scholar] [CrossRef]
- Fan, X.; Li, S.; Tian, L. Chaotic characteristic identification for carbon price and an multi-layer perceptron network prediction model. Expert Syst. Appl. 2015, 42, 3945–3952. [Google Scholar] [CrossRef]
- Zhu, B. A Novel Multiscale Ensemble Carbon Price Prediction Model Integrating Empirical Mode Decomposition, Genetic Algorithm and Artificial Neural Network. Energies 2012, 5, 355–370. [Google Scholar] [CrossRef] [Green Version]
- Sun, G.; Chen, T.; Wei, Z.; Sun, Y.; Zang, H.; Chen, S. A Carbon Price Forecasting Model Based on Variational Mode Decomposition and Spiking Neural Networks. Energies 2016, 9, 54. [Google Scholar] [CrossRef]
- Zhu, B.; Chevallier, J. Forecasting Carbon Price with Empirical Mode Decomposition and Least Squares Support Vector Regression. Appl. Energy 2017, 191, 521–530. [Google Scholar] [CrossRef]
- Feng, Z.-H.; Liu, C.-F.; Wei, Y.-M. How does carbon price change? Evidences from EU ETS. Int. J. Glob. Energy Issues 2011, 35, 132–144. [Google Scholar] [CrossRef]
- Li, S.; Wang, P.; Goel, L. Short-term load forecasting by wavelet transform and evolutionary extreme learning machine. Electr. Power Syst. Res. 2015, 122, 96–103. [Google Scholar] [CrossRef]
- Li, S.; Goel, L.; Wang, P. An ensemble approach for short-term load forecasting by extreme learning machine. Appl. Energy 2016, 170, 22–29. [Google Scholar] [CrossRef]
- Shrivastava, N.A.; Panigrahi, B.K. A hybrid wavelet-ELM based short term price forecasting for electricity markets. Int. J. Electr. Power Energy Syst. 2014, 55, 41–50. [Google Scholar] [CrossRef]
- Hui, L.; Mi, X.; Li, Y. An Experimental Investigation of Three New Hybrid Wind Speed Forecasting Models Using Multi-decomposing Strategy and ELM Algorithm. Renew. Energy 2018, 123, 694–705. [Google Scholar]
- Abdoos, A.A. A new intelligent method based on combination of VMD and ELM for short term wind power forecasting. Neurocomputing 2016, 203, 111–120. [Google Scholar] [CrossRef]
- Rocha, H.R.O.; Silvestre, L.J.; Celeste, W.C.; Coura, D.J.C.; Rigo, L.O., Jr. Forecast of Distributed Electrical Generation System Capacity Based on Seasonal Micro Generators using ELM and PSO. IEEE Lat. Am. Trans. 2018, 16, 1136–1141. [Google Scholar] [CrossRef]
- Sun, W.M. Duan, Analysis and Forecasting of the Carbon Price in China’s Regional Carbon Markets Based on Fast Ensemble Empirical Mode Decomposition, Phase Space Reconstruction, and an Improved Extreme Learning Machine. Energies 2019, 12, 277. [Google Scholar] [CrossRef]
- Wang, J.-L.; Li, Z.-J. Extreme-point symmetric mode decomposition method for data analysis. Adv. Adapt. Data Anal. 2013, 5, 1350015. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; Volume 2, pp. 985–990. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Shanmugam, R. Introduction to Time Series and Forecasting. Technometrics 1997, 39, 426. [Google Scholar] [CrossRef]
- Qi, S.; Wang, B.; Zhang, J. Policy design of the Hubei ETS pilot in China. Energy Policy 2014, 75, 31–38. [Google Scholar] [CrossRef]
- Lan, Y.; Zhaopeng, L.; Li, Y.; Jie, L. Comparative study on the development degree of China’s 7 pilot carbon markets. China Popul. Resour. Environ. 2018, 2, 134–140. [Google Scholar]
- Liu, Y.; Tan, X.-J.; Yu, Y.; Qi, S.-Z. Assessment of impacts of Hubei Pilot emission trading schemes in China—A CGE-analysis using Term CO2 model. Appl. Energy 2017, 189, 762–769. [Google Scholar] [CrossRef]
- Hu, Y.J.; Li, X.Y.; Tang, B.J. Assessing the operational performance and maturity of the carbon trading pilot program: The case study of Beijing’s carbon market. J. Clean. Prod. 2017, 161, 1263–1274. [Google Scholar] [CrossRef]
- Available online: http://www.tanjiaoyi.com/ (accessed on 28 December 2018).
- Dégerine, S.; Lambert-Lacroix, S. Characterization of the partial autocorrelation function of nonstationary time series. J. Multivar. Anal. 2003, 87, 46–59. [Google Scholar] [CrossRef] [Green Version]
- Guo, Z.; Zhao, W.; Lu, H.; Wang, J. Multi-step forecasting for wind speed using a modified EMD-based artificial neural network model. Renew. Energy 2012, 37, 241–249. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Carbon Price | Sample | Size | Data |
|---|---|---|---|
| Hubei | Sample set | 1228 | 2014/4/02–2018/8/14 |
| Training set | 860 | 2014/4/02–2017/2/15 | |
| Testing set | 368 | 2017/2/15–2018/8/14 | |
| Beijing | Sample set | 1356 | 2013/11/28–2018/8/14 |
| Training set | 950 | 2013/12/19–2016/12/13 | |
| Testing set | 406 | 2016/12/14–2018/8/14 | |
| Guangdong | Sample set | 1338 | 2013/12/19–2018/8/14 |
| Training set | 937 | 2013/12/19–2016/12/26 | |
| Testing set | 401 | 2016/12/27–2018/8/14 | |
| Shanghai | Sample set | 1336 | 2013/12/19–2018/8/14 |
| Training set | 935 | 2013/12/19–2016/12/21 | |
| Testing set | 401 | 2016/12/22–2018/8/14 |
| Carbon Price | Means | Median | Standard Deviation | Skewness | Kurtosis | Jarque-Bera |
|---|---|---|---|---|---|---|
| Hubei | 20.31 | 22.13 | 4.48 | 0.22 | 1.59 | 111.24 |
| Beijing | 51.33 | 51.48 | 7.05 | 0.33 | 5.13 | 282.07 |
| Guangdong | 25.57 | 15.99 | 18.21 | 1.34 | 3.26 | 406.02 |
| Shanghai | 27.91 | 31.91 | 12.11 | 0.46 | 1.99 | 103.05 |
| Carbon Price | Stat | Prob. | Stationarity |
|---|---|---|---|
| Hubei | −0.5880 | 0.9791 | × |
| Beijing | −2.6140 | 0.2741 | × |
| Guangdong | −2.3184 | 0.4230 | × |
| Shanghai | −1.5097 | 0.8262 | × |
| Carbon Price | M-Dimensional Space | Linearity | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | ||||||
| Stat | Prob. | Stat | Prob. | Stat | Prob. | Stat | Prob. | ||
| Hubei | 0.1790 | 0.0012 | 0.3084 | 0.0019 | 0.3985 | 0.0022 | 0.4604 | 0.0023 | × |
| Beijing | 0.1686 | 0.0031 | 0.2844 | 0.0049 | 0.3612 | 0.0059 | 0.4101 | 0.0061 | × |
| Guangdong | 0.2042 | 0.0028 | 0.3486 | 0.0045 | 0.4500 | 0.0053 | 0.5212 | 0.0056 | × |
| Shanghai | 0.1986 | 0.0015 | 0.3375 | 0.0024 | 0.4333 | 0.0029 | 0.4996 | 0.0030 | × |
| ESMD | EMD | EEMD | |||
|---|---|---|---|---|---|
| IMFs and R | Lag | IMFs and R | Lag | IMFs and R | Lag |
| IMF1 | (, , , , , ) | IMF1 | (, , , , , ) | IMF1 | (, , , , , ) |
| IMF2 | (, , , , , , ) | IMF2 | (, , , , , , ) | IMF2 | (, , , ,, , , , , ) |
| IMF3 | (, , , , , , , ) | IMF3 | (, , , , , , ) | IMF3 | (, , , , , , , , ) |
| IMF4 | (, , , , ) | IMF4 | (, , , ) | IMF4 | (, , , , , ) |
| IMF5 | (, , , , , , ) | IMF5 | (, , , , , , , ) | IMF5 | (, , , , , , , , , ) |
| IMF6 | (, , , , , , , , , ) | IMF6 | (, , , , , , , , , ) | IMF6 | (, , , , , , , , , ) |
| IMF7 | (, , , , , , , , , ) | IMF7 | (, , , , ) | IMF7 | () |
| Residue | (, , , ) | IMF8 | (, , , , , , , , , ) | IMF8 | () |
| Residue | () | Residue | () | ||
| Name | The Calculation Formula |
|---|---|
| RMSE | |
| MAPE | |
| R2 |
| Model | RMSE | MAPE (%) | R2 |
|---|---|---|---|
| Original-ELM | 6.0734 | 38.42 | 0.6304 |
| EMD-ELM | 1.7352 | 3.51 | 0.5761 |
| EEMD-ELM | 2.3936 | 9.92 | 0.6627 |
| ESMD-ELM | 1.6237 | 2.70 | 0.6695 |
| Original-GWO-ELM | 0.4808 | 1.98 | 0.9709 |
| EMD-GWO-ELM | 0.2559 | 1.18 | 0.9876 |
| EEMD-GWO-ELM | 0.1917 | 1.66 | 0.9882 |
| ESMD-GWO-ELM | 0.1438 | 0.31 | 0.9918 |
| Model | Beijing | Guangdong | Shanghai | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAPE (%) | R2 | RMSE | MAPE (%) | R2 | RMSE | MAPE (%) | R2 | |
| Original-GWO-ELM | 2.8518 | 0.16 | 0.7982 | 0.6847 | 0.67 | 0.7419 | 1.1340 | 0.03 | 0.9316 |
| EMD-GWO-ELM | 2.0934 | 0.34 | 0.8925 | 0.4168 | 0.35 | 0.9064 | 0.8362 | 0.10 | 0.9622 |
| EEMD-GWO-ELM | 1.8768 | 0.13 | 0.8957 | 0.6338 | 0.59 | 0.7875 | 0.7311 | 0.07 | 0.9700 |
| ESMD-GWO-ELM | 1.8069 | 0.03 | 0.9192 | 0.3835 | 0.11 | 0.9213 | 0.6948 | 0.05 | 0.9739 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Huo, X.; Xu, X.; Li, Y. Forecasting the Carbon Price Using Extreme-Point Symmetric Mode Decomposition and Extreme Learning Machine Optimized by the Grey Wolf Optimizer Algorithm. Energies 2019, 12, 950. https://doi.org/10.3390/en12050950
Zhou J, Huo X, Xu X, Li Y. Forecasting the Carbon Price Using Extreme-Point Symmetric Mode Decomposition and Extreme Learning Machine Optimized by the Grey Wolf Optimizer Algorithm. Energies. 2019; 12(5):950. https://doi.org/10.3390/en12050950
Chicago/Turabian StyleZhou, Jianguo, Xuejing Huo, Xiaolei Xu, and Yushuo Li. 2019. "Forecasting the Carbon Price Using Extreme-Point Symmetric Mode Decomposition and Extreme Learning Machine Optimized by the Grey Wolf Optimizer Algorithm" Energies 12, no. 5: 950. https://doi.org/10.3390/en12050950