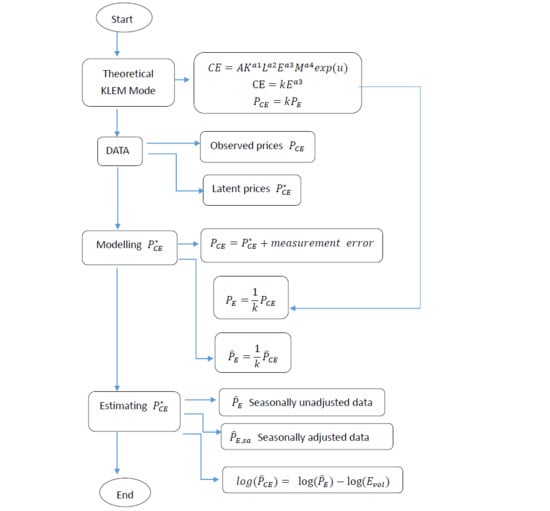
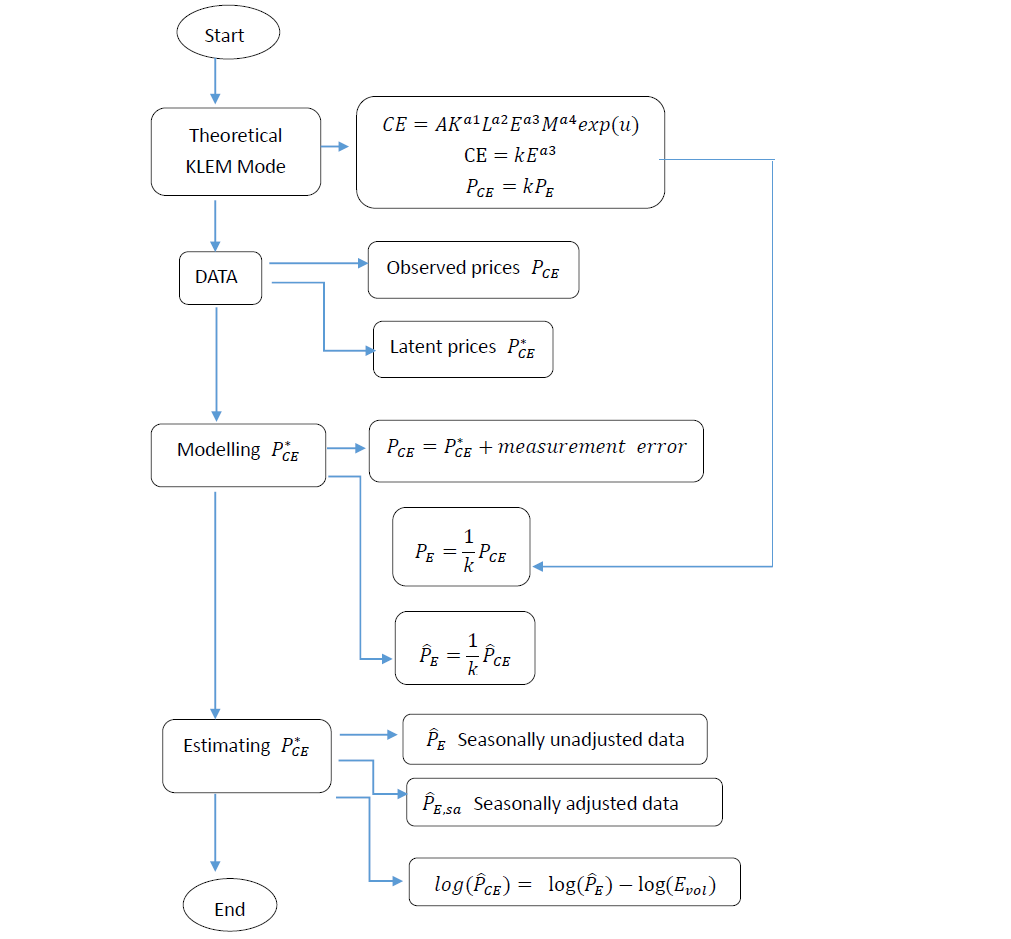
Modeling Latent Carbon Emission Prices for Japan: Theory and Practice


Abstract
:
1. Introduction
2. Literature Review
3. KLEMS Production Function for Carbon Emissions and Energy
4. Modeling Latent Carbon Emission Prices
- (i)
- ;
- (ii)
- ;
- (iii)
- ;
- (iv)
- .
5. Estimating Latent Carbon Emission Prices
- (1)
- Volume of carbon emissions;
- (2)
- Prices and volume of electricity;
- (3)
- Prices and volume of oil;
- (4)
- Prices and volume of crude coal;
- (5)
- Prices and volume of natural gas;
- (6)
- Prices and volume of nuclear energy;
- (7)
- Prices and volume of solar energy;
- (8)
- Prices and volume of wind energy;
- (9)
- Prices and volume of hydro energy;
- (10)
- Prices and volume of wave energy;
- (11)
- Prices and volume of bio-mass;
- (12)
- Prices and volume of ethanol;
- (13)
- Prices and volume of bio-ethanol.
6. Monthly Data and Diagnostic Checks
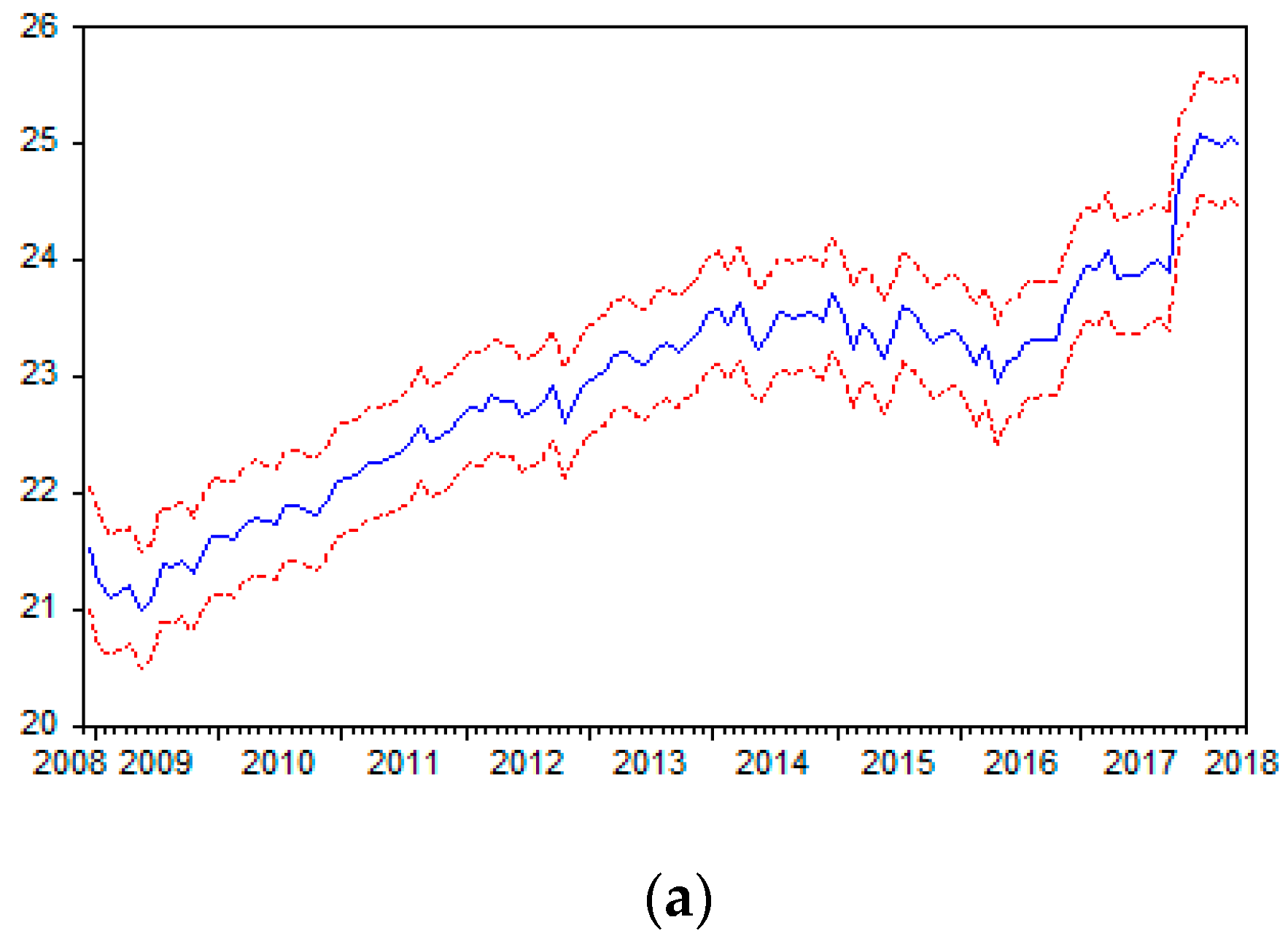
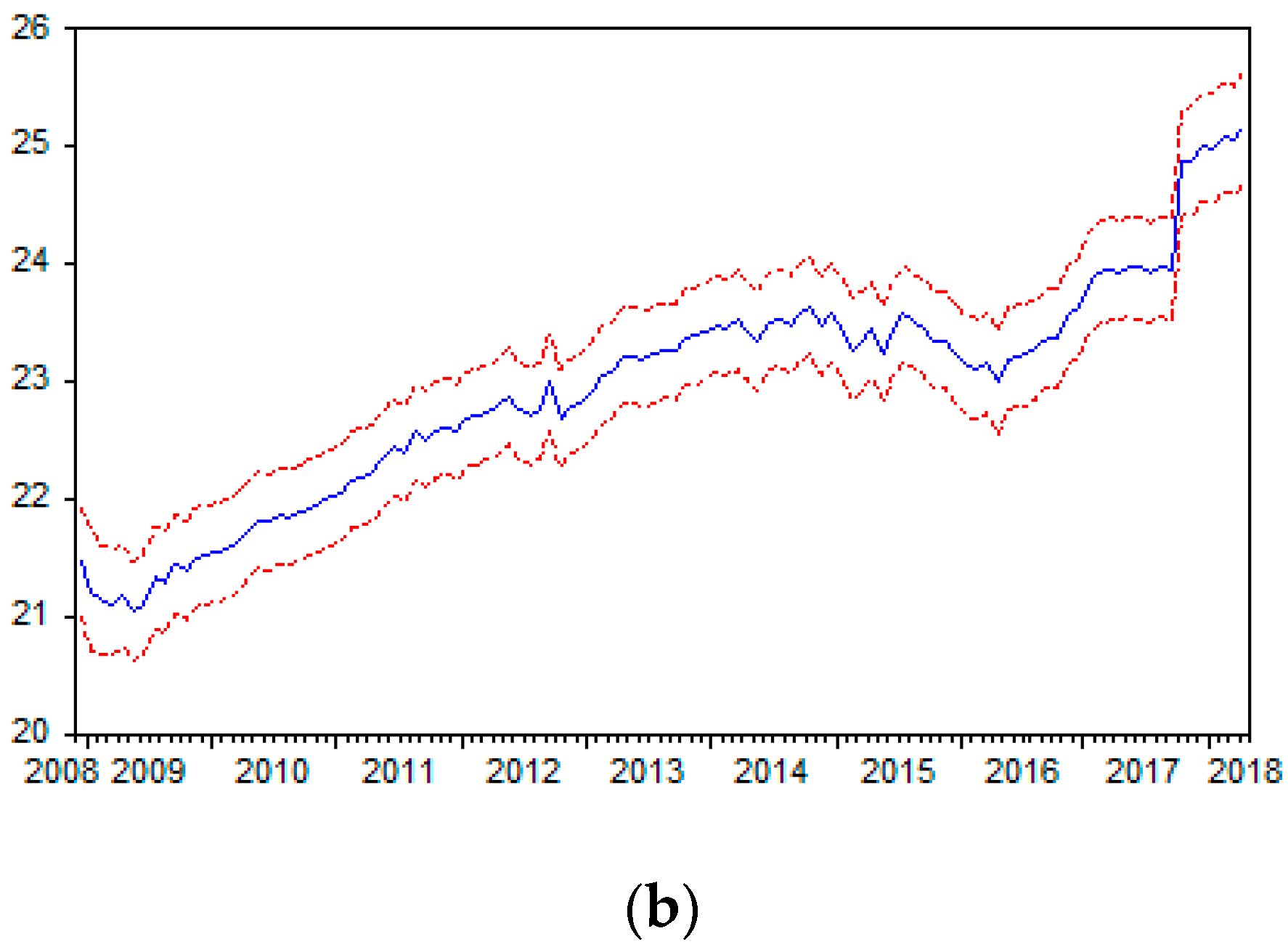
7. Empirical Estimates and Analysis
- Case 1: Seasonally unadjusted data, with a deterministic trend and dummy variable;
- Case 2: Seasonally adjusted data, with a deterministic trend and dummy variable.
8. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Derivation of Correct Standard Errors for Realized Latent Carbon Emissions and Ranking of Important Underlying Factors
- (1)
- Academic rankings of individuals, departments, faculties/schools/colleges, institutions, states, countries, and regions, which are of both academic and practical interest from individual students, parents, and institutions, to public and private policy advisors (for robust methods of ranking academic journals see, for example, [32,33,34,35,36,37] Chang and McAleer (2013, 2014a, 2014b, 2014c, 2015, 2016); [38,39,40,41,42] Chang, McAleer, and Oxley (2011a, 2011b, 2011c, 2011d, 2013); and [43] Chang, Maasoumi and McAleer (2016));
- (2)
- International rankings of universities, namely “Academic Ranking of World Universities (ARWU)” by Shanghai Ranking Consultancy (originally compiled and issued by Shanghai Jiao Tong University), “World University Rankings” by Times Higher Education (THE), and “QS World University Rankings” by Quacquarelli Symonds (QS), are based on arbitrary measures.
Appendix A.2. Theoretical Structure for Latent Endogenous and Exogenous Variables
Appendix A.2.1. Primitive Approach
Appendix A.2.2. Generated Regressors and Realized Latents
Appendix A.3. Extensions to More Complicated Decision Strategies
- (i)
- Extending “realized latent rankings” to multivariate unobserved latent endogenous variables, and establishing the theoretical properties of the new measures, as well as of the associated parametric estimators, using extensions of the technical developments in the basic model. These could include structural models, recursive models, and probabilistic models;
- (ii)
- OLS is the simplest technique that can be employed to obtain optimal weights through estimation, but it is possible to use Logistic regression to obtain optimal weights and the inherent associated probabilities;
- (iii)
- In the context of Cognitive Computing, it is widely argued that computers, computing facilities, machine hardware, mathematical algorithms, and computer software should be perceived as aids to learn dynamically, to reach managerial decisions, and to achieve strategic aims;
- (iv)
- As advanced machines can be programmed to learn through feedback, an important implication is that the outputs obtained from inputs and processing systems are not the same if learning is allowed because the outputs can differ. Consequently, outputs from such processing systems should be modeled and analyzed in a probabilistic context which, in turn, helps to make managerial decisions.
- (v)
- Defining and measuring a wide range of latent variables, such as unknown carbon emission prices and academic quality; ranking individuals, departments, faculties, and institutions based on the new measure; and establishing the theoretical properties of the new measures, as well as the associated parametric estimators;
- (vi)
- Ranking individuals, departments, faculties and institutions based on non-academic measures, and establishing the theoretical properties of the new measures, as well as of the associated parametric estimators;
- (vii)
- Applying the approach based on “realized latent rankings” commercially to any decision making strategies in business, using structural models; multiple decision making based on recursive models, that is, sequential decision making; and strategic decision making using probabilistic models, among others.
References
- Allen, D.E.; McAleer, M. Fake news and indifference to scientific fact: President Trump’s confused tweets on global warming, climate change and weather. Scientometrics 2018, 117, 625–629. [Google Scholar] [CrossRef]
- Daskalakis, G.; Markellos, R. Are electricity risk premia affected by emission allowance prices? Evidence from the EEX, Nord Pool and Powernext. Energy Policy 2009, 37, 2594–2604. [Google Scholar] [CrossRef]
- Daskalakis, G.; Psychoyios, D.; Markellos, R.N. Modeling CO2 emission allowance prices and derivatives: Evidence from the European Trading Scheme. J. Bank. Financ. 2009, 33, 1230–1241. [Google Scholar] [CrossRef]
- Bushnell, J.B.; Chong, H.; Mansur, E.T. Profiting from regulation: Evidence from the European Carbon Market. Am. Econ. J. Econ. Policy 2013, 5, 78–106. [Google Scholar] [CrossRef]
- Oestreich, A.M.; Tsiakas, I. Carbon emissions and stock returns: Evidence from the EU Emissions Trading Scheme. J. Bank. Financ. 2015, 58, 294–308. [Google Scholar] [CrossRef]
- Martin, R.; Muuls, M.; Wagner, U.J. The impact of the European Union Emissions Trading Scheme on regulated firms: What Is the evidence after ten years? Rev. Environ. Econ. Policy 2016, 10, 129–148. [Google Scholar] [CrossRef]
- Chang, C.-L.; Mai, T.-K.; McAleer, M. Pricing carbon emissions in China. Ann. Financ. Econ. 2018, 13, 1–37. [Google Scholar]
- Chang, C.-L.; Mai, T.-K.; McAleer, M. Establishing national carbon emission prices for China. Renew. Sustain. Energy Rev. 2019, 106, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Chen, W. The costs of mitigating carbon emissions in China: Findings from China MARKAL-MACRO modeling. Energy Policy 2005, 33, 885–896. [Google Scholar] [CrossRef]
- Gregg, J.S.; Andres, R.J.; Marland, G. China: Emissions pattern of the world leader in CO2 emissions from fossil fuel consumption and cement production. Geophys. Res. Lett. 2008, 35. [Google Scholar] [CrossRef]
- Li, J.; Colombier, M. Managing carbon emissions in China through building energy efficiency. J. Environ. Manag. 2009, 90, 2436–2447. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.-C. A multivariate causality test of carbon dioxide emissions, Energy consumption and economic growth in China. Appl. Energy 2010, 87, 3533–3537. [Google Scholar] [CrossRef]
- Nam, K.-M.; Waugh, C.J.; Paltsev, S.; Reilly, J.M.; Karplus, V.J. Synergy between pollution and carbon emissions control: Comparing China and the United States. Energy Econ. 2014, 46, 186–201. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Karplus, V.; Cassisa, C.; Zhang, X. Emissions trading in China: Progress and prospects. Energy Policy 2014, 75, 9–16. [Google Scholar] [CrossRef]
- Zhang, Y.-J.; Wang, A.D.; Da, Y.-B. Regional allocation of carbon emission quotas in China: Evidence from the Shapley value method. Energy Policy 2014, 74, 454–464. [Google Scholar] [CrossRef]
- Liu, L.; Chen, C.; Zhao, Y.; Zhao, E. China’s carbon-emissions trading: Overview, challenges and future. Renew. Sustain. Energy Rev. 2015, 49, 254–266. [Google Scholar] [CrossRef]
- Tang, L.; Wu, J.; Yu, L.; Bao, Q. Carbon emissions trading scheme exploration in China: A multi-agent-based model. Energy Policy 2015, 81, 152–169. [Google Scholar] [CrossRef]
- Zhang, Y. Reformulating the low-carbon green growth strategy in China. Clim. Policy 2015, 15, 40–59. [Google Scholar] [CrossRef]
- Xiong, L.; Shen, B.; Qi, S.; Price, L.; Ye, B. The allowance mechanism of China’s carbon trading pilots: A comparative analysis with schemes in EU and California. Appl. Energy 2017, 185, 1849–1859. [Google Scholar] [CrossRef]
- Zhang, Y.J.; Sun, Y.F. The dynamic volatility spillover between European carbon trading market and fossil energy market. J. Clean. Prod. 2016, 112, 2654–2663. [Google Scholar] [CrossRef]
- Chang, C.-L.; McAleer, M. The fiction of full BEKK: Pricing fossil fuels and carbon emissions. Financ. Res. Lett. 2019, 28, 11–19. [Google Scholar] [CrossRef]
- Chang, C.-L.; McAleer, M.; Zuo, G.D. Volatility spillovers and causality of carbon emissions, oil and coal spot and futures for the EU and USA. Sustainability 2017, 9, 1789. [Google Scholar] [CrossRef]
- Hitzemann, S.; Uhrig-Homburg, M.; Ehrhart, K. Emission permits and the announcement of realized emissions: Price impact, trading volume and volatilities. Energy Econ. 2015, 51, 560–569. [Google Scholar] [CrossRef]
- Kim, J.; Park, Y.; Ryu, D. Stochastic volatility of the futures prices of emission allowances: A Bayesian approach. Physica A 2017, 465, 714–724. [Google Scholar] [CrossRef]
- Hitzemann, S.; Uhrig-Homburg, M. Empirical performance of reduced-form models for emission permit prices. Rev. Deriv. Res. 2019, 22, 389–418. [Google Scholar] [CrossRef]
- OECD. OECD Productivity Manual: A Guide to the Measurement of Industry-Level and Aggregate Productivity Growth; Statistics Directorate, Directorate for Science, Technology and Industry: Paris, France, 2001. [Google Scholar]
- Lecca, P.; Swales, K.; Turner, K. An investigation of issues relating to where energy Should enter the production function. Econ. Model. 2011, 28, 2832–2841. [Google Scholar] [CrossRef]
- Chang, C.-L.; Hamori, S.; McAleer, M. Pricing carbon emissions based on energy production, unpublished paper, Department of Applied Economics and Department of Finance, National Chung Hsing University, Taiwan; Graduate School of Economics, Kobe University, Japan; Department of Finance, Asia University, Taiwan, 2018.
- Phillips, P.C.B.; Perron, P. Testing for a unit root in time series regression. Biometrika 1988, 75, 335–346. [Google Scholar] [CrossRef]
- Johansen, S. Estimation and hypothesis testing of cointegration vectors in Gaussian vector autoregressive models. Econometrica 1991, 59, 1551–1580. [Google Scholar] [CrossRef]
- Phillips, P.; Hansen, B. Statistical inference in instrumental variables regression with I(1) processes. Rev. Econ. Stud. 1990, 57, 99–125. [Google Scholar] [CrossRef]
- Chang, C.-L.; McAleer, M. Ranking leading econometric journals using citations data from ISI and RePEc. Econometrics 2013, 1, 217–235. [Google Scholar] [CrossRef]
- Chang, C.-L.; McAleer, M. How should journal quality be ranked? An application to agricultural, energy, environmental and resource economics. J. Rev. Glob. Econ. 2014, 3, 33–47. [Google Scholar]
- Chang, C.-L.; McAleer, M. Ranking economics and econometrics ISI journals by quality weighted citations. Rev. Econ. 2014, 65, 35–52. [Google Scholar] [CrossRef]
- Chang, C.-L.; McAleer, M. Just how good are the top three journals in finance? An assessment based on quantity and quality citations. Ann. Financ. Econ. 2014, 9, 1450005. [Google Scholar] [CrossRef]
- Chang, C.-L.; McAleer, M. Bibliometric rankings of journals based on the Thomson Reuters citations database. J. Rev. Glob. Econ. 2015, 4, 120–125. [Google Scholar]
- Chang, C.-L.; McAleer, M. Quality weighted citations versus total citations in the sciences and social sciences, with an application to finance and accounting. Manag. Financ. 2016, 42, 324–337. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.-L.; McAleer, M.; Oxley, L. What makes a great journal great in economics? The singer not the song. J. Econ. Surv. 2011, 25, 326–361. [Google Scholar] [CrossRef]
- Chang, C.-L.; McAleer, M.; Oxley, L. What makes a great journal great in the sciences? Which came first, the chicken or the egg? Scientometrics 2011, 87, 17–40. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.-L.; McAleer, M.; Oxley, L. Great expectatrics: Great papers, great journals, great econometrics. Econom. Rev. 2011, 30, 583–619. [Google Scholar] [CrossRef]
- Chang, C.-L.; McAleer, M.; Oxley, L. How are journal impact, prestige and article influence related? An application to neuroscience. J. Appl. Stat. 2011, 38, 2563–2573. [Google Scholar] [CrossRef]
- Chang, C.-L.; McAleer, M.; Oxley, L. Coercive journal self citations, impact factor, journal influence and article influence. Math. Comput. Simul. 2013, 93, 190–197. [Google Scholar] [CrossRef]
- Chang, C.-L.; Maasoumi, E.; McAleer, M. Robust ranking of journal quality: An application to economics. Econom. Rev. 2016, 35, 50–97. [Google Scholar] [CrossRef]
- Newey, W.; West, K. A simple, positive semi-definite, heteroskedasticity and autocorrelation consistent covariance matrix. Econometrica 1987, 55, 703–708. [Google Scholar] [CrossRef]
- Smith, J.; McAleer, M. Newey-West covariance matrix estimates for models with generated regressors. Appl. Econ. 1994, 26, 635–640. [Google Scholar] [CrossRef]
- McAleer, M. The Rao-Zyskind condition, Kruskal’s theorem and ordinary least squares. Econ. Rec. 1992, 68, 65–72. [Google Scholar] [CrossRef]
- Pagan, A. Econometric issues in the analysis of regressions with generated regressors. Int. Econ. Rev. 1984, 25, 221–247. [Google Scholar] [CrossRef]
- McAleer, M.; McKenzie, C.R. When are two-step estimators efficient? Econom. Rev. 1991, 10, 235–252. [Google Scholar] [CrossRef]
- McAleer, M.; McKenzie, C.R. Recursive estimation and generated regressors. Econ. Lett. 1992, 39, 1–5. [Google Scholar] [CrossRef]
- McAleer, M.; McKenzie, C.R. On the effects of misspecification errors in models with generated regressors. Oxf. Bull. Econ. Stat. 1994, 56, 441–455. [Google Scholar]
- McAleer, M.; McKenzie, C.R. On efficient estimation and correct inference in models with generated regressors: A general approach. Jpn. Econ. Rev. 1997, 48, 368–389. [Google Scholar]
- Fiebig, D.G.; McAleer, M.; Bartels, R. Properties of ordinary least squares estimators in regression models with non-spherical disturbances. J. Econom. 1992, 54, 321–334. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
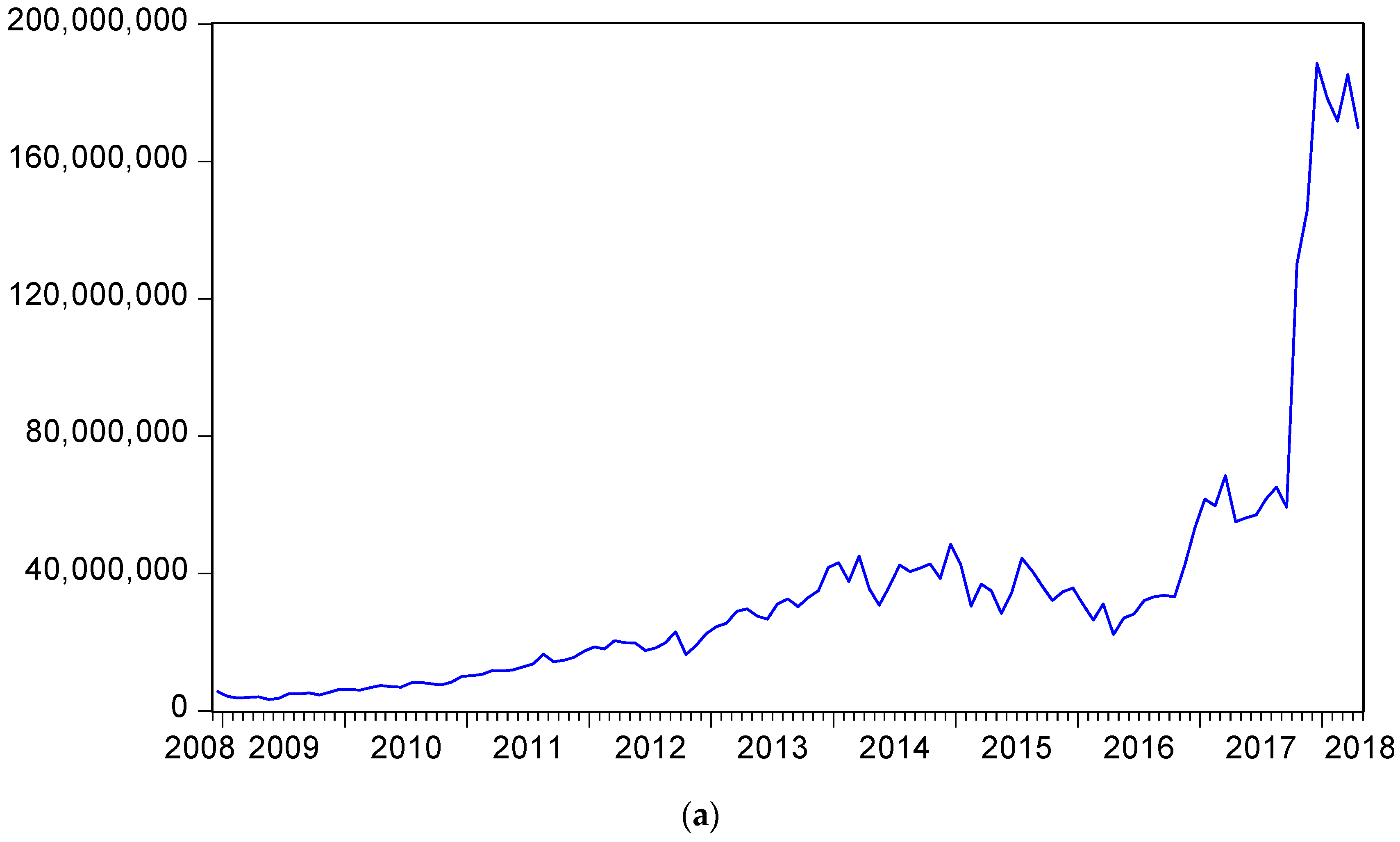{kind=link}
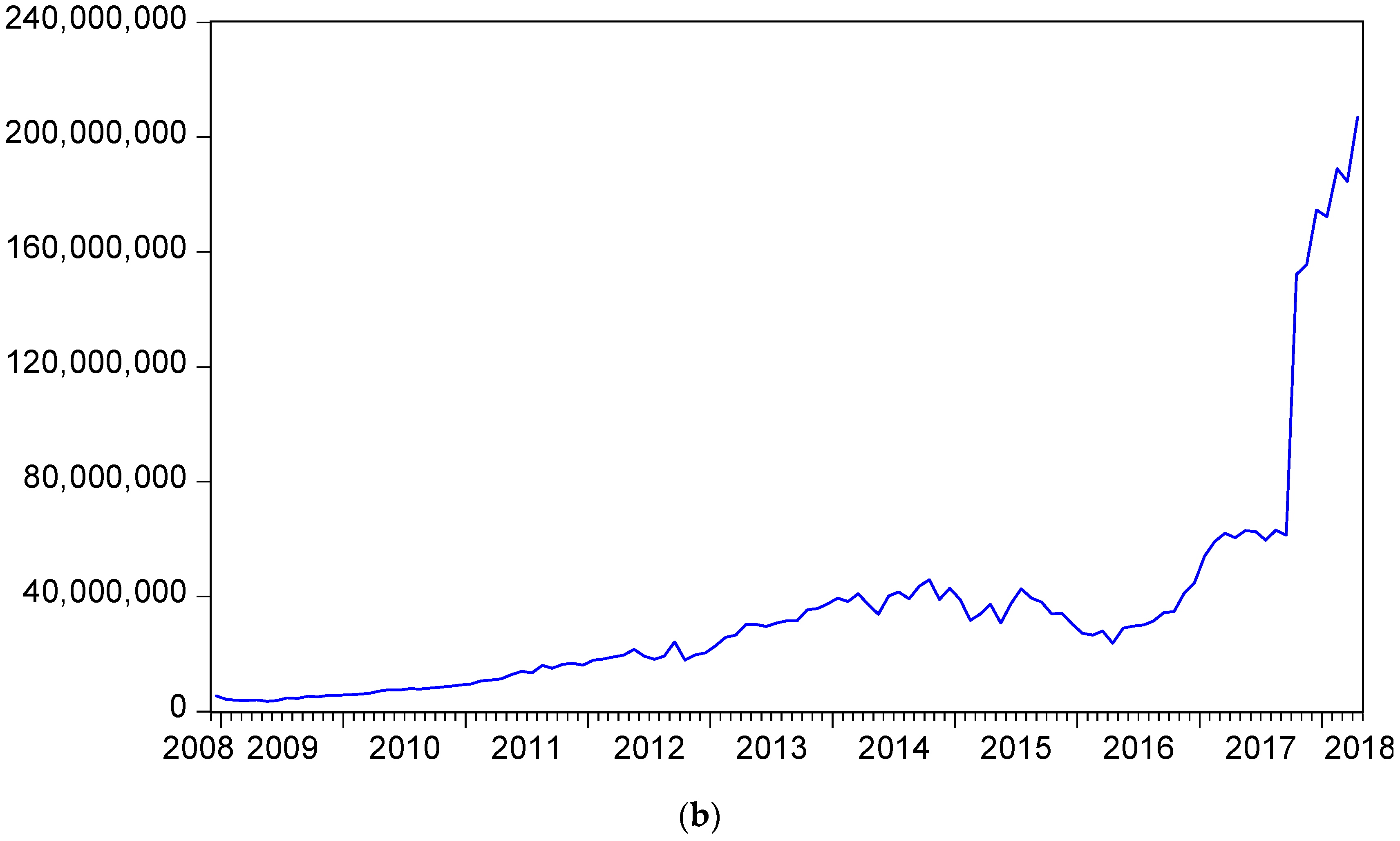{kind=link}
| Variable | Definition | Source |
|---|---|---|
| Value of coal (Import value of coal) | Trade Statistics of Japan, Ministry of Finance | |
| Value of coal seasonally adjusted by X12 | ||
| Value of LNG (Import value of LNG) | Trade Statistics of Japan, Ministry of Finance | |
| Seasonally adjusted value of LNG | ||
| Value of petroleum (Import value of petroleum) | Trade Statistics of Japan, Ministry of Finance | |
| Value of petroleum seasonally adjusted by X12 | ||
| Value of electricity obtained by P_E × E vol | ||
| Value of electricity seasonally adjusted by X12 | ||
| Volume of carbon emission (ppm) Average of observations | Japan Metrological Agency | |
| Volume of carbon seasonally adjusted by X12 | ||
| Spot electricity price (Day ahead, 24 h) | Japan Electricity Power eXchange | |
| Total transaction volume of electricity | Japan Electricity Power eXchange | |
| Total transaction volume of electricity seasonally adjusted by X12 |
| (a) Levels | ||
| Variable | Test Statistic | p-value |
| −2.320 | 0.420 | |
| −1.209 | 0.904 | |
| −3.309 | 0.070 | |
| −2.727 | 0.228 | |
| −2.541 | 0.308 | |
| −2.069 | 0.557 | |
| −2.166 | 0.504 | |
| −1.321 | 0.878 | |
| Notes: SA denotes a seasonally adjusted variable. The auxiliary regression included a constant term and time trend. OLS was used to obtain the estimator of the residual spectrum at a frequency of zero. | ||
| (b) First Differences | ||
| Variable | Test Statistic | p-value |
| −11.862 | 0.000 | |
| −10.960 | 0.000 | |
| −15.262 | 0.000 | |
| −14.411 | 0.000 | |
| −12.241 | 0.000 | |
| −12.639 | 0.000 | |
| −32.051 | 0.000 | |
| −11.336 | 0.000 | |
| Notes: SA denotes a seasonally adjusted variable. The auxiliary regression included a constant term. The number of lags for the auxiliary regression was determined by the Akaike Information Criterion (AIC). Ordinary Least Squares (OLS) was used to obtain the estimator of the residual spectrum at a frequency of zero. | ||
| (a) Seasonally unadjusted data | ||||
| 1.000 | 0.159 | −0.008 | 0.379 | |
| 0.159 | 1.000 | 0.317 | 0.341 | |
| −0.008 | 0.317 | 1.000 | 0.730 | |
| 0.379 | 0.341 | 0.730 | 1.000 | |
| Seasonally adjusted data | ||||
| 1.000 | 0.146 | −0.008 | 0.375 | |
| 0.146 | 1.000 | 0.294 | 0.295 | |
| −0.008 | 0.294 | 1.000 | 0.737 | |
| 0.375 | 0.295 | 0.737 | 1.000 | |
| (b) Seasonally unadjusted data | ||||
| 1.000 | 0.066 | 0.125 | 0.211 | |
| 0.066 | 1.000 | 0.299 | 0.401 | |
| 0.125 | 0.299 | 1.000 | 0.445 | |
| 0.211 | 0.401 | 0.445 | 1.000 | |
| Seasonally adjusted data | ||||
| 1.000 | 0.043 | 0.177 | 0.038 | |
| 0.043 | 1.000 | 0.267 | 0.267 | |
| 0.177 | 0.267 | 1.000 | 0.200 | |
| 0.038 | 0.267 | 0.200 | 1.000 | |
| Trace or Maximum Eigenvalue Test | Number of Cointegrating Vectors | Test Statistic (p-Value) |
|---|---|---|
| Trace | 66.725 (0.028) | |
| Maximum Eigenvalue | 37.215 (0.011) | |
| Trace | 77.143 (0.003) | |
| Maximum Eigenvalue | 40.017 (0.004) |
| Case 1 | Case 2 | |
|---|---|---|
| Constant | −3.180 (0.409) | −4.141 (0.253) |
| 0.410 (0.056) * | ||
| 0.451 (0.025) ** | ||
| 0.215 (0.210) | ||
| 0.265 (0.125) | ||
| 0.612 (0.001) *** | ||
| 0.573 (0.002) *** | ||
| Trend | 0.027 (0.000) *** | 0.026 (0.000) *** |
| Dummy | 0.669 (0.000) *** | 0.772 (0.000) *** |
| Adjusted R2 | 0.943 | 0.958 |
| 1.000 | 0.997 | |
| 0.997 | 1.000 |
| 1.000 | 0.992 | |
| 0.992 | 1.000 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, C.-L.; McAleer, M. Modeling Latent Carbon Emission Prices for Japan: Theory and Practice. Energies 2019, 12, 4222. https://doi.org/10.3390/en12214222
Chang C-L, McAleer M. Modeling Latent Carbon Emission Prices for Japan: Theory and Practice. Energies. 2019; 12(21):4222. https://doi.org/10.3390/en12214222
Chicago/Turabian StyleChang, Chia-Lin, and Michael McAleer. 2019. "Modeling Latent Carbon Emission Prices for Japan: Theory and Practice" Energies 12, no. 21: 4222. https://doi.org/10.3390/en12214222