News Co-Occurrences, Stock Return Correlations, and Portfolio Construction Implications


Abstract
:1. Introduction
2. Data and Variable Definitions
2.1. News Co-Occurrence Analysis
2.2. Stock Characteristics
2.3. Descriptive Statistics
3. News Co-Occurrences and Stock Characteristics
3.1. Explaining Cross-Sectional Variation in News Co-Occurrences
3.2. Decomposing News Co-Occurrences
4. News Co-Occurrence and Investor Attention
5. News Co-Occurrence and Stock Return Correlation
5.1. Contemporaneous Relation between News Co-Occurrence and Return Correlation
5.2. Predictive Relation between News Co-Occurrence and Future Return Correlation
6. News Co-Occurrence and Portfolio Construction
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ang, Andrew, Robert Hodrick, Yuhang Xing, and Xiaoyan Zhang. 2006. The cross-section of volatility and expected returns. Journal of Finance 61: 259–99. [Google Scholar] [CrossRef]
- Baker, Scott R., Nicholas Bloom, and Steven J. Davis. 2016. Measuring economic policy uncertainty. Quarterly Journal of Economics 131: 1593–636. [Google Scholar] [CrossRef]
- Bali, Turan, Lin Peng, Yannan Shen, and Yi Tang. 2014. Liquidity shocks and stock market reactions. Review of Financial Studies 27: 1434–85. [Google Scholar] [CrossRef]
- Bao, Henghua, Rui Li, Yong Yu, and Yunbo Cao. 2008. Competitor mining with the web. IEEE Transactions on Knowledge and Data Engineering 20: 1297–310. [Google Scholar]
- Barber, Brad, and Terrence Odean. 2008. All that glitters: The effect of attention on the buying behavior of individual and institutional investors. Review of Financial Studies 21: 785–818. [Google Scholar] [CrossRef]
- Ben-Rephael, Azi, Zhi Da, and Ryan D. Israelsen. 2017. It depends on where you search: Institutional investor attention and underreaction to news. Review of Financial Studies 30: 3009–3047. [Google Scholar] [CrossRef]
- Best, Michael J., and Robert R. Grauer. 1991. On the sensitivity of mean-variance-efficient portfolios to changes in asset means: Some analytical and computational results. Review of Financial Studies 4: 315–42. [Google Scholar] [CrossRef]
- Bijl, Laurens, Glenn Kringhaug, Peter Molnr, and Eirik Sandvik. 2016. Google searches and stock returns. International Review of Financial Analysis 45: 150–56. [Google Scholar] [CrossRef]
- Broadie, Mark. 1993. Computing efficient frontiers using estimated parameters. Annals of Operations Research 45: 21–58. [Google Scholar] [CrossRef]
- Chen, Hsinchun, Roger H. L. Chiang, and Veda C. Storey. 2012. Business intelligence and analytics: From big data to big impact. Management Information Systems Quarterly 36: 1165–88. [Google Scholar] [CrossRef]
- Chopra, Vijay K., and William T. Ziemba. 1993. The effect of errors in means, variances, and covariances on optimal portfolio choice. Journal of Portfolio Management 19: 6–11. [Google Scholar] [CrossRef]
- Cohen, Lauren, and Andrea Frazzini. 2008. Economic links and predictable returns. Journal of Finance 63: 1977–2011. [Google Scholar] [CrossRef]
- Da, Zhi, Joseph Engelberg, and Pengjie Gao. 2011. In search of attention. Journal of Finance 66: 1461–99. [Google Scholar] [CrossRef]
- DellaVigna, Stefano, and Joshua M. Pollett. 2007. Demographics and industry returns. American Economic Review 97: 1167–702. [Google Scholar] [CrossRef]
- DellaVigna, Stefano, and Joshua M. Pollett. 2009. Investor inattention and friday earnings announcements. Journal of Finance 64: 709–49. [Google Scholar] [CrossRef]
- DeMiguel, Victor, Francisco J. Nogales, and Raman Uppal. 2014. Stock return serial dependence and out-of-sample portfolio performance. Review of Financial Studies 27: 1031–73. [Google Scholar] [CrossRef]
- Fama, Eugene F., and Kenneth R. French. 1992. The cross-section of expected stock returns. Journal of Finance 46: 427–66. [Google Scholar] [CrossRef]
- Fama, Eugene F., and Kenneth R. French. 1993. Common risk factors in the returns of stocks and bonds. Journal of Financial Economics 33: 3–56. [Google Scholar] [CrossRef]
- Fama, Eugene F., and James MacBeth. 1973. Risk, return and equilibrium: Empirical tests. Journal of Political Economy 51: 55–84. [Google Scholar] [CrossRef]
- Harvey, Campbell R., Yan Liu, and Heqing Zhu. 2016. … and the cross-section of expected returns. Review of Financial Studies 29: 5–68. [Google Scholar] [CrossRef]
- Hirshleifer, David A., Kewei Hou, Siew Hong Teoh, and Yinglei Zhang. 2004. Do investors overvalue firms with bloated balance sheets. Journal of Accounting and Economics 38: 297–331. [Google Scholar] [CrossRef]
- Hirshleifer, David A., Po-Hsuan Hsu, and Dongmei Li. 2013. Innovative efficiency and stock returns. Journal of Financial Economics 107: 632–54. [Google Scholar] [CrossRef]
- Hirshleifer, David A., Seongyeon Lim, and Siew Hong Teoh. 2009. Driven to distraction: Extraneous events and underreaction to earnings news. Journal of Finance 64: 2289–325. [Google Scholar] [CrossRef]
- Hirshleifer, David A., and Siew Hong Teoh. 2003. Limited attention, information disclosure, and financial reporting. Journal of Accounting and Economics 36: 337–86. [Google Scholar] [CrossRef]
- Hong, Harrison, Walter Torous, and Rossen Valkanov. 2007. Do industries lead the stock market? Journal of Financial Economics 83: 367–96. [Google Scholar] [CrossRef]
- Hou, Kewei, and Tobias J. Moskowitz. 2005. Market frictions, price delay, and the cross-section of expected returns. Review of Financial Studies 18: 981–1020. [Google Scholar] [CrossRef]
- Huberman, Gur, and Tomer Regev. 2001. Contagious speculation and a cure for cancer: A non-event that made stock prices soar. Journal of Finance 56: 387–96. [Google Scholar] [CrossRef]
- Jagannathan, Ravi, and Tongshu Ma. 2003. Risk reduction in large portfolios: Why imposing the wrong constraints helps. Journal of Finance 58: 1651–84. [Google Scholar] [CrossRef]
- Kahneman, Naniel. 1973. Attention and Effort. Upper Saddle River: Prentice Hall. [Google Scholar]
- Kim, Neri, Katarna Lucivjansk, Peter Molnr, and Roviel Villa. 2018. Google searches and stock market activity: Evidence from norway. Finance Research Letters 28: 208–20. [Google Scholar] [CrossRef]
- Korniotis, George M., and Alok Kumar. 2013. State-level business cycles and local return predictability. Journal of Finance 68: 1037–96. [Google Scholar] [CrossRef]
- Liu, Hongqi, Lin Peng, and Yi Tang. 2018. Investor Attention: Endogenous Allocations, Clientele Effects, and Asset Pricing Implications. Working Paper. Available online: http://www.fmaconferences.org/HongKong/Papers/LPT_Miami.pdf (accessed on 19 March 2019).
- Loughran, Tim, and Bill McDonald. 2016. Textual analysis in accounting and finance: A survey. Journal of Accounting Research 56: 1187–230. [Google Scholar] [CrossRef]
- Ma, Zhongming, Gautam Pant, and Olivia R. L. Sheng. 2011. Mining competitor relationships from online news: A network-based approach. Electronic Commerce Research and Applications 10: 418–27. [Google Scholar] [CrossRef]
- Markowitz, Harry. 1952. Portfolio selection. Journal of Finance 7: 77–91. [Google Scholar]
- Merton, Robert C. 1980. On estimating the expected return on the market: An exploratory investigation. Journal of Financial Economics 8: 323–61. [Google Scholar] [CrossRef]
- Michaud, Richard O. 1989. The markowitz optimization enigma: is ‘optimized’ optimal? Journal of Finance 45: 31–42. [Google Scholar]
- Nadeau, David, and Satoshi Sekine. 2007. A survey of named entity recognition and classification. Lingvisticae Investigationes 30: 3–26. [Google Scholar]
- Parsons, Christopher A., Riccardo Sabbatucci, and Sheridan Titman. 2016. Geographic Momentum. Working paper. [Google Scholar]
- Pashler, Harold, and James C. Johnston. 1998. Attentional limitations in dual-task performance. In Attention. Edited by Harold Pashler. Hove: Psychology Press, pp. 155–89. [Google Scholar]
- Peng, Lin. 2005. Learning with information capacity constraints. Journal of Financial Quantitative Analysis 40: 307–29. [Google Scholar] [CrossRef]
- Peng, Lin, and Wei Xiong. 2006. Investor attention, overconfidence and category learning. Journal of Financial Economics 80: 563–602. [Google Scholar] [CrossRef]
- Pirinsky, Christo, and Qinghai Wang. 2006. Does corporate headquarters location matter for stock returns? Journal of Finance 61: 1991–2015. [Google Scholar] [CrossRef]
- Schumaker, Robert P., and Hsinchun Chen. 2009. Textual analysis of stock market prediction using breaking financial news: The azfin text system. ACM Transactions on Information Systems 27: 12. [Google Scholar] [CrossRef]
- Schumaker, Robert P., Yulei Zhang, Chun-Neng Huang, and Hsinchun Chen. 2012. Evaluating sentiment in financial news articles. Decision Support Systems 53: 458–64. [Google Scholar] [CrossRef]
- Shumway, Tyler. 1997. The delisting bias in crsp data. Journal of Finance 52: 327–40. [Google Scholar] [CrossRef]
- Witten, Ian H., Katherine J. Don, Michael Dewsnip, and Valentin Tablan. 2004. Text mining in a digital library. International Journal on Digital Libraries 4: 56–59. [Google Scholar] [CrossRef] [Green Version]
- Yu, Liang-Chih, Jheng-Long Wu, Pei-Chann Chang, and Hsuan-Shou Chu. 2013. Using a contextual entropy model to expand emotion words and their intensity for the sentiment classification of stock market news. Knowledge-Based Systems 41: 89–97. [Google Scholar] [CrossRef]
| 1. | See Loughran and McDonald (2016) for a comprehensive review of the literature. |
| 2. | See Pashler and Johnston (1998) for a review of these studies. |
| 3. | |
| 4. | Given that our sample covers the financial crisis period of December 2007–June 2009, one legitimate concern is that the relation between news co-occurrences and stock return correlations may be significantly different between the crisis period and the post-crisis period. For a robustness check, we replicate our tests after excluding observations for the crisis period and find qualitatively similar results. |
| 5. | Lexis-Nexis provides full text access to over 6000 sources including newspapers, journals, news wire services, and newsletters. |
| 6. | The detail about the program is available at Available online: https://nlp.stanford.edu/software/CRF-NER.html. |
| 7. | Specifically, when a stock is delisted, we use the delisting return from CRSP, if available. Otherwise, we assume the delisting return is −100%, unless the reason for delisting is coded as 500 (reason unavailable), 520 (went to over the counter (OTC)), 551–573, 580 (various reasons), 574 (bankruptcy), or 584 (does not meet exchange financial guidelines). For these observations, we assume that the delisting return was −30%. |
| 8. | See, e.g., Hou and Moskowitz (2005); Hong et al. (2007); DellaVigna and Pollett (2009); Cohen and Frazzini (2008); Hirshleifer et al. (2009, 2013); Bali et al. (2014). |
| 9. | |
| 10. | We used the natural logarithm of news co-occurrence because the raw measure is highly positively skewed and fatter tailed. On the other hand, many pairs of stocks that co-occurred in news articles in month t did not appear in the same news articles in month . To avoid losing such pairs in the regression analysis, we added one to the number of news co-occurrences when calculating the natural logarithm measure. |
| 11. | The results of the expected and shock components estimated from Equation (4), which does not control for market beta, size, idiosyncratic volatility, and analyst coverage, were very similar. The average slope coefficient of the unexpected component was insignificant. The average slope coefficient of the shock component was 0.006, implying that for a one-unit increase in LNTFR, ASV increased 0.42%, or three standard deviations. |



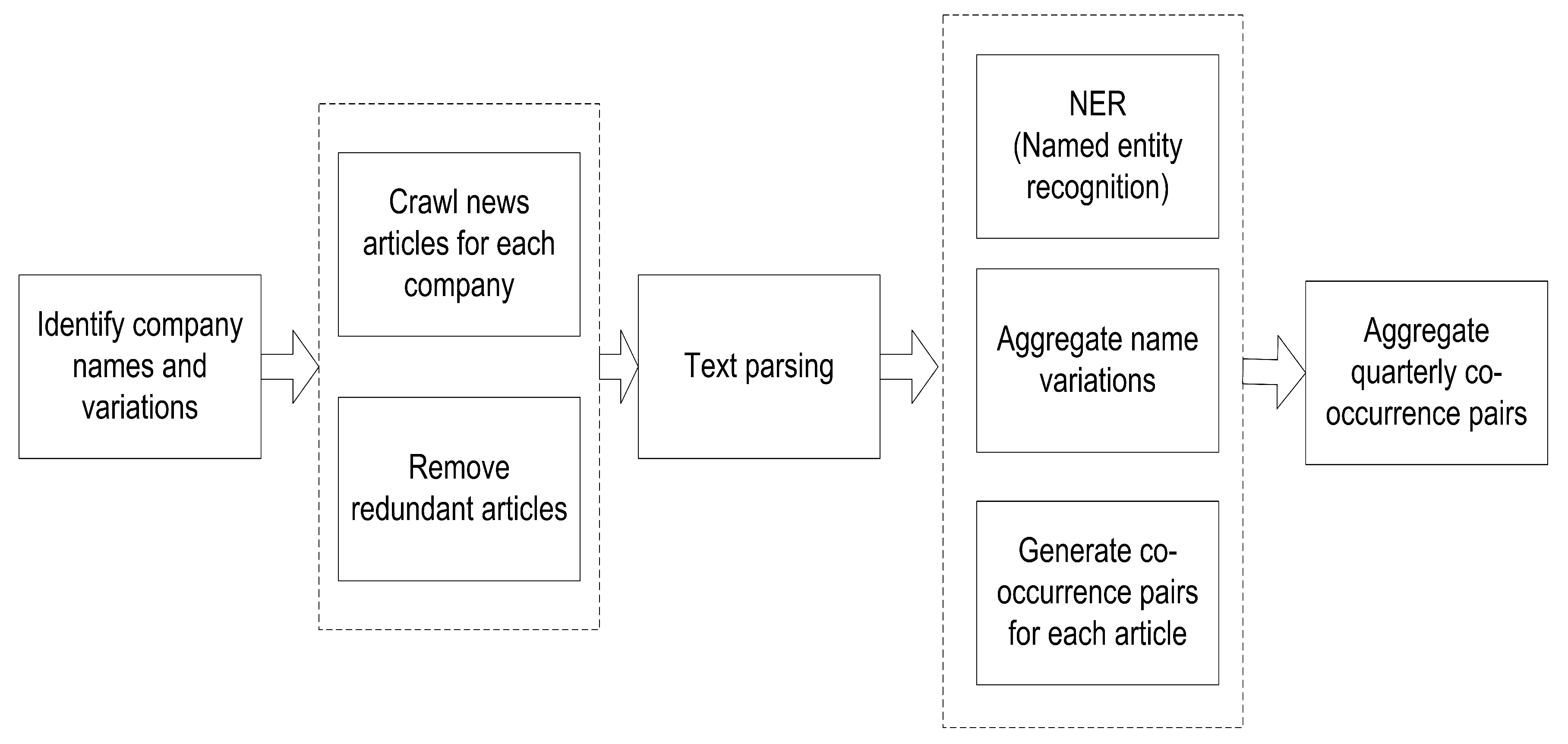{kind=link}
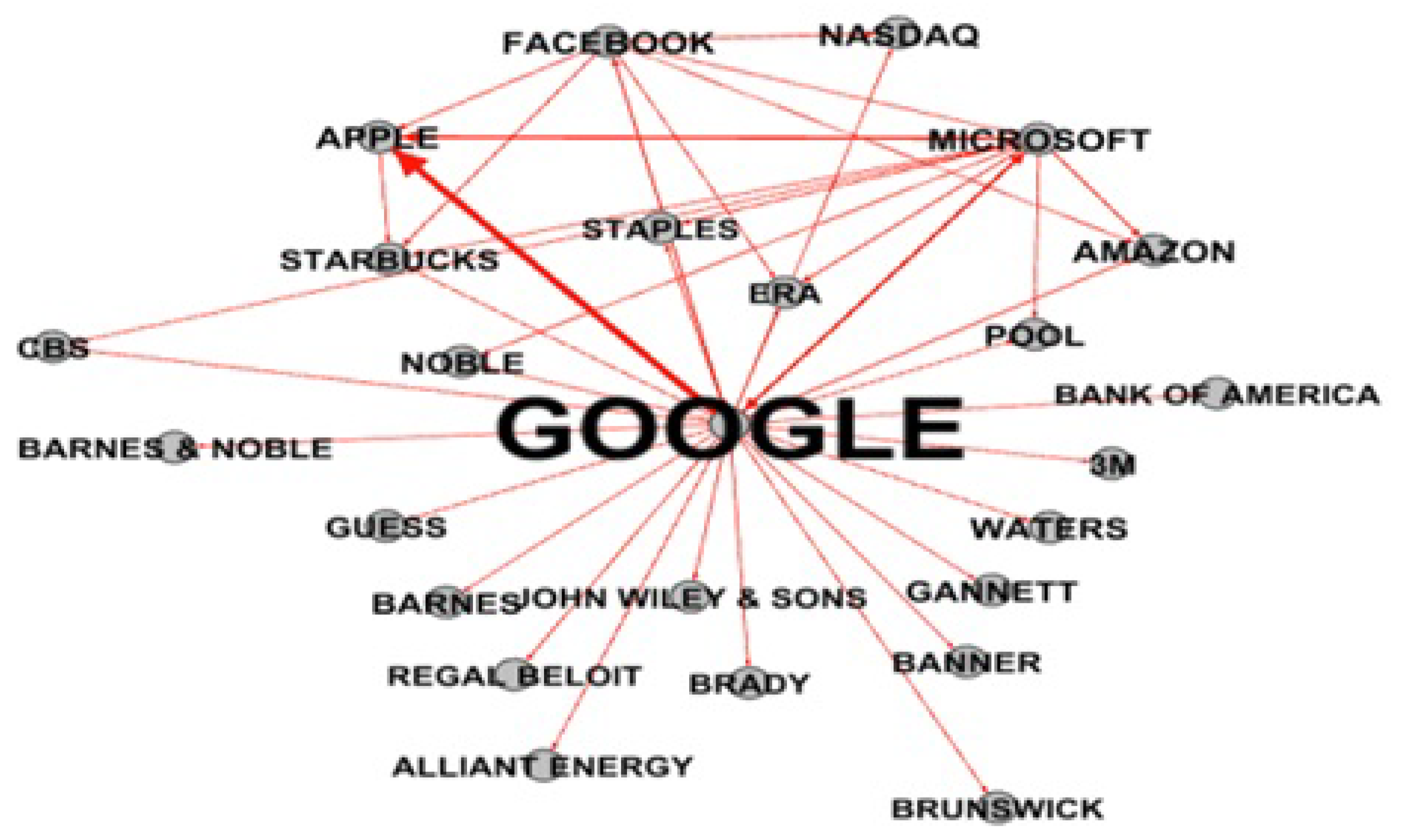{kind=link}
| Sample | BETA | ME | IVOL | CVRG | FREQ | TF | TF | CORR | CORR | |
|---|---|---|---|---|---|---|---|---|---|---|
| COC = 1 | 1.19 | 15,699 | 23.03 | 13 | 16 | 2 | 8 | 0.34 | 0.41 | |
| All stocks | 47 | 1.23 | 9951 | 25.40 | 11 | 0.33 | ||||
| COC = 0 | 1.26 | 4728 | 27.45 | 9 | 0.32 |
| Panel A. Explaining News Occurrences | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | IND | CS | GEO | LTF | BETA | SIZE | IVOL | CVRG | Adj. R |
| (1) | 0.073 | 0.098 | 0.032 | 0.307 | 0.157 | ||||
| (11.10) | (7.19) | (5.70) | (51.37) | ||||||
| (2) | 0.073 | 0.091 | 0.035 | 0.307 | −0.012 | 0.005 | 0.002 | 0.001 | 0.165 |
| (12.20) | (6.59) | (6.64) | (54.80) | (−3.01) | (3.40) | (0.73) | (1.70) | ||
| Panel B. Descriptive Statistics for Components of News Co-Occurrences | |||||||||
| Model (1) | Model (2) | ||||||||
| Expected | Shock | Expected | Shock | ||||||
| Mean | 1.016 | 0.000 | 1.017 | 0.000 | |||||
| Std. dev. | 0.036 | 0.048 | 0.034 | 0.048 | |||||
| LNTF | LNTFP | LNTFR |
|---|---|---|
| 0.004 | ||
| (2.41) | ||
| −0.003 | 0.005 | |
| (−0.85) | (3.95) |
| Model | Intercept | LNTF | LNTFP | LNTFR | ASV | ASV × LNTF | ASV × LNTFP | ASV × LNTFR | CORR | Adj. R |
|---|---|---|---|---|---|---|---|---|---|---|
| (1) | 0.270 | 0.016 | 0.308 | 0.098 | ||||||
| (18.74) | (8.87) | (26.51) | ||||||||
| (2) | 0.269 | 0.017 | −0.011 | 0.005 | 0.308 | 0.100 | ||||
| (18.69) | (9.08) | (−0.98) | (0.57) | (26.36) | ||||||
| (5) | 0.209 | 0.078 | 0.003 | 0.304 | 0.103 | |||||
| (13.06) | (12.72) | (1.78) | (26.29) | |||||||
| (6) | 0.208 | 0.079 | 0.003 | −0.016 | −0.005 | 0.011 | 0.304 | 0.105 | ||
| (12.91) | (12.57) | (2.09) | (−0.73) | (−0.27) | (1.21) | (26.09) |
| Panel A. Results from Model (1) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Intercept | LNTF | CORR | Adj. R | |||||
| 0.286 | 0.014 | 0.299 | 0.096 | |||||
| (19.43) | (7.01) | (26.93) | ||||||
| 0.275 | 0.014 | 0.309 | 0.100 | |||||
| (17.56) | (6.55) | (27.31) | ||||||
| 0.282 | 0.017 | 0.279 | 0.080 | |||||
| (16.75) | (7.23) | (26.48) | ||||||
| 0.290 | 0.017 | 0.264 | 0.075 | |||||
| (16.65) | (7.68) | (26.55) | ||||||
| 0.283 | 0.018 | 0.277 | 0.081 | |||||
| (16.49) | (7.37) | (25.35) | ||||||
| 0.289 | 0.021 | 0.251 | 0.068 | |||||
| (16.55) | (8.05) | (25.04) | ||||||
| 0.291 | 0.019 | 0.253 | 0.068 | |||||
| (17.17) | (7.75) | (24.25) | ||||||
| 0.283 | 0.019 | 0.274 | 0.079 | |||||
| (15.81) | (9.25) | (25.54) | ||||||
| 0.297 | 0.019 | 0.245 | 0.066 | |||||
| (17.36) | (8.45) | (24.48) | ||||||
| 0.302 | 0.018 | 0.239 | 0.063 | |||||
| (17.58) | (7.55) | (22.53) | ||||||
| 0.290 | 0.019 | 0.265 | 0.078 | |||||
| (18.55) | (8.46) | (28.97) | ||||||
| 0.298 | 0.017 | 0.243 | 0.064 | |||||
| (17.49) | (7.65) | (24.86) | ||||||
| Panel B. Results from Model (2) | ||||||||
| Intercept | LNTF | ASV | ASV×LNTF | CORR | Adj. R | |||
| 0.286 | 0.015 | −0.012 | 0.005 | 0.299 | 0.098 | |||
| (19.49) | (7.07) | (−1.03) | (0.62) | (26.93) | ||||
| 0.275 | 0.014 | −0.004 | 0.004 | 0.309 | 0.101 | |||
| (17.61) | (6.47) | (−0.38) | (0.46) | (27.31) | ||||
| 0.281 | 0.017 | −0.010 | 0.008 | 0.279 | 0.081 | |||
| (16.71) | (7.58) | (−0.92) | (0.94) | (26.48) | ||||
| 0.290 | 0.017 | −0.008 | 0.005 | 0.264 | 0.077 | |||
| (16.64) | (7.76) | (−0.58) | (0.49) | (26.55) | ||||
| 0.283 | 0.018 | 0.004 | −0.004 | 0.277 | 0.083 | |||
| (16.55) | (7.30) | (0.38) | (−0.44) | (25.35) | ||||
| 0.288 | 0.021 | −0.017 | 0.014 | 0.251 | 0.070 | |||
| (16.56) | (8.22) | (−1.40) | (1.47) | (25.04) | ||||
| 0.290 | 0.020 | −0.023 | 0.010 | 0.253 | 0.070 | |||
| (17.16) | (7.67) | (−1.91) | (1.09) | (24.25) | ||||
| 0.282 | 0.020 | −0.016 | 0.005 | 0.274 | 0.082 | |||
| (15.76) | (9.07) | (−1.30) | (0.50) | (25.54) | ||||
| 0.295 | 0.019 | −0.015 | 0.004 | 0.245 | 0.068 | |||
| (17.27) | (8.61) | (−1.38) | (0.52) | (24.48) | ||||
| 0.301 | 0.018 | −0.019 | 0.013 | 0.239 | 0.065 | |||
| (17.52) | (7.64) | (−1.73) | (1.57) | (22.53) | ||||
| 0.288 | 0.020 | −0.023 | 0.014 | 0.265 | 0.080 | |||
| (18.46) | (8.52) | (−2.03) | (1.73) | (28.97) | ||||
| 0.297 | 0.018 | −0.026 | 0.015 | 0.243 | 0.066 | |||
| (17.37) | (8.34) | (−1.92) | (1.48) | (24.86) | ||||
| Panel C. Results from Model (3) | ||||||||
| Intercept | LNTFP | LNTFR | CORR | Adj. R | ||||
| 0.244 | 0.060 | 0.004 | 0.295 | 0.100 | ||||
| (13.76) | (8.59) | (2.35) | (26.86) | |||||
| 0.223 | 0.066 | 0.002 | 0.305 | 0.104 | ||||
| (13.19) | (12.27) | (0.98) | (27.02) | |||||
| 0.231 | 0.073 | 0.004 | 0.274 | 0.085 | ||||
| (10.95) | (8.40) | (2.06) | (26.36) | |||||
| 0.236 | 0.073 | 0.004 | 0.260 | 0.079 | ||||
| (12.04) | (11.11) | (2.19) | (26.30) | |||||
| 0.230 | 0.075 | 0.005 | 0.273 | 0.086 | ||||
| (11.56) | (10.25) | (2.47) | (25.09) | |||||
| 0.226 | 0.085 | 0.007 | 0.246 | 0.073 | ||||
| (12.02) | (13.77) | (2.84) | (24.65) | |||||
| 0.240 | 0.075 | 0.007 | 0.249 | 0.073 | ||||
| (11.11) | (9.07) | (3.23) | (23.84) | |||||
| 0.230 | 0.074 | 0.007 | 0.269 | 0.083 | ||||
| (11.61) | (13.17) | (3.71) | (25.14) | |||||
| 0.245 | 0.073 | 0.006 | 0.241 | 0.070 | ||||
| (12.34) | (11.23) | (3.13) | (24.06) | |||||
| 0.241 | 0.079 | 0.005 | 0.234 | 0.068 | ||||
| (12.94) | (12.21) | (2.53) | (22.14) | |||||
| 0.231 | 0.077 | 0.007 | 0.261 | 0.082 | ||||
| (13.03) | (12.57) | (3.63) | (28.55) | |||||
| 0.242 | 0.076 | 0.004 | 0.238 | 0.069 | ||||
| (12.11) | (10.69) | (1.88) | (24.43) | |||||
| Panel D. Results from Model (4) | ||||||||
| Intercept | LNTFP | LNTFR | ASV | ASV×LNTFP | ASV×LNTFR | CORR | Adj. R | |
| 0.244 | 0.060 | 0.004 | −0.003 | 0.001 | 0.005 | 0.295 | 0.101 | |
| (13.87) | (8.75) | (2.38) | (−0.12) | (0.06) | (0.61) | (26.84) | ||
| 0.224 | 0.066 | 0.002 | −0.017 | 0.006 | 0.009 | 0.305 | 0.105 | |
| (13.25) | (12.11) | (1.20) | (−0.48) | (0.24) | (1.04) | (27.09) | ||
| 0.232 | 0.073 | 0.005 | 0.005 | −0.019 | 0.021 | 0.273 | 0.086 | |
| (10.98) | (8.33) | (2.66) | (0.13) | (−0.73) | (2.26) | (26.27) | ||
| 0.237 | 0.073 | 0.004 | −0.017 | 0.000 | 0.009 | 0.259 | 0.082 | |
| (12.05) | (11.07) | (2.38) | (−0.40) | (0.00) | (0.96) | (26.25) | ||
| 0.231 | 0.074 | 0.005 | −0.003 | −0.012 | 0.001 | 0.272 | 0.088 | |
| (11.60) | (10.04) | (2.54) | (−0.09) | (−0.42) | (0.14) | (25.05) | ||
| 0.225 | 0.085 | 0.007 | −0.016 | −0.001 | 0.020 | 0.246 | 0.075 | |
| (12.08) | (13.63) | (3.15) | (−0.41) | (−0.02) | (2.10) | (24.69) | ||
| 0.240 | 0.074 | 0.008 | 0.000 | −0.009 | 0.015 | 0.249 | 0.075 | |
| (11.17) | (9.05) | (3.41) | (0.02) | (−0.36) | (1.54) | (23.96) | ||
| 0.229 | 0.075 | 0.007 | −0.034 | 0.021 | 0.002 | 0.268 | 0.086 | |
| (11.56) | (13.71) | (3.69) | (−1.39) | (0.96) | (0.24) | (25.03) | ||
| 0.243 | 0.074 | 0.007 | 0.016 | −0.023 | 0.010 | 0.240 | 0.072 | |
| (12.26) | (11.36) | (3.35) | (0.63) | (−1.01) | (1.08) | (23.98) | ||
| 0.239 | 0.079 | 0.006 | 0.011 | −0.013 | 0.019 | 0.234 | 0.069 | |
| (12.91) | (12.26) | (2.60) | (0.49) | (−0.68) | (2.18) | (22.03) | ||
| 0.229 | 0.078 | 0.008 | −0.007 | 0.001 | 0.016 | 0.260 | 0.084 | |
| (13.04) | (12.74) | (3.82) | (−0.23) | (0.05) | (1.91) | (28.46) | ||
| 0.241 | 0.077 | 0.005 | −0.001 | −0.008 | 0.022 | 0.238 | 0.071 | |
| (12.14) | (10.96) | (2.50) | (−0.03) | (−0.38) | (2.05) | (24.26) | ||
| Benchmark | Model (1) | Model (2) | Model (3) | Model (4) | ||||
|---|---|---|---|---|---|---|---|---|
| GMV | GMV | Diff. | GMV | Diff. | GMV | Diff. | GMV | Diff. |
| 13.972 | 13.968 | −0.004 | 13.968 | −0.004 | 13.965 | −0.007 | 13.965 | −0.007 |
| (−1.28) | (−1.30) | (−1.86) | (−1.85) | |||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Y.; Zhou, Y.; Hong, M. News Co-Occurrences, Stock Return Correlations, and Portfolio Construction Implications. J. Risk Financial Manag. 2019, 12, 45. https://doi.org/10.3390/jrfm12010045
Tang Y, Zhou Y, Hong M. News Co-Occurrences, Stock Return Correlations, and Portfolio Construction Implications. Journal of Risk and Financial Management. 2019; 12(1):45. https://doi.org/10.3390/jrfm12010045
Chicago/Turabian StyleTang, Yi, Yilu Zhou, and Marshall Hong. 2019. "News Co-Occurrences, Stock Return Correlations, and Portfolio Construction Implications" Journal of Risk and Financial Management 12, no. 1: 45. https://doi.org/10.3390/jrfm12010045