
Tuberculosis in Prisons: Importance of Considering the Clustering in the Analysis of Cross-Sectional Studies
 , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study 1: Active TB
2.1.1. Variables
2.1.2. Sampling
2.2. Study 2: TBI
2.2.1. Variables
2.2.2. Sampling
2.3. Multivariable Regression Models
2.3.1. Regression Models for Non-Clustered Dichotomous Outcomes
2.3.2. Multivariable Regression Models for Dichotomous Data with Clustered Structure
2.4. Analysis
3. Results
3.1. Effect of Prevalence in General and Sub-Groups Ignoring Clustering
3.2. Effect of Cluster Level on Cluster-Robust Variance Estimates
3.3. Effect of Adjustment by Cluster-Robust Standard Errors and Bias-Corrected Standard Errors
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Walter, K.S.; Martinez, L.; Arakaki-Sanchez, D.; Sequera, V.G.; Sanabria, G.E.; Cohen, T.; Ko, A.I.; García-Basteiro, A.L.; Rueda, Z.V.; López-Olarte, R.A.; et al. The Escalating Tuberculosis Crisis in Central and South American Prisons. Lancet 2021, 397, 1591–1596. [Google Scholar] [CrossRef] [PubMed]
- Cords, O.; Martinez, L.; Warren, J.L.; O’Marr, J.M.; Walter, K.S.; Cohen, T.; Zheng, J.; Ko, A.I.; Croda, J.; Andrews, J.R. Incidence and Prevalence of Tuberculosis in Incarcerated Populations: A Systematic Review and Meta-Analysis. Lancet Public Health 2021, 6, e300–e308. [Google Scholar] [CrossRef] [PubMed]
- Ranzani, O.T.; Pescarini, J.M.; Martinez, L.; Garcia-Basteiro, A.L. Increasing Tuberculosis Burden in Latin America: An Alarming Trend for Global Control Efforts. BMJ Glob. Health 2021, 6, e005639. [Google Scholar] [CrossRef] [PubMed]
- Dar, M.; Chorgoliani, D.; de Colombani, P. Chapter 8. TB Prevention and Control Care in Prisons. In Prisons and Health; WHO Regional Office for Europe: Copenhagen, Denmark, 2014; pp. 52–56. ISBN 978 92 890 5059 3. [Google Scholar]
- Rueda, Z.V.; Arroyave, L.; Marin, D.; López, L.; Keynan, Y.; Giraldo, M.R.; Pulido, H.; Arbeláez, M.P. High Prevalence and Risk Factors Associated with Latent Tuberculous Infection in Two Colombian Prisons. Int. J. Tuberc. Lung Dis. 2014, 18, 1166–1171. [Google Scholar] [CrossRef]
- Larouzé, B.; Sánchez, A.; Diuana, V. Tuberculosis behind Bars in Developing Countries: A Hidden Shame to Public Health. Trans. R. Soc. Trop. Med. Hyg. 2008, 102, 841–842. [Google Scholar] [CrossRef]
- Vinkeles Melchers, N.V.S.; van Elsland, S.L.; Lange, J.M.A.; Borgdorff, M.W.; van den Hombergh, J. State of Affairs of Tuberculosis in Prison Facilities: A Systematic Review of Screening Practices and Recommendations for Best TB Control. PLoS ONE 2013, 8, e53644. [Google Scholar] [CrossRef] [Green Version]
- Baussano, I.; Williams, B.G.; Nunn, P.; Beggiato, M.; Fedeli, U.; Scano, F. Tuberculosis Incidence in Prisons: A Systematic Review. PLOS Med. 2010, 7, e1000381. [Google Scholar] [CrossRef]
- Urrego, J.; Ko, A.I.; da Silva Santos Carbone, A.; Paião, D.S.G.; Sgarbi, R.V.E.; Yeckel, C.W.; Andrews, J.R.; Croda, J. The Impact of Ventilation and Early Diagnosis on Tuberculosis Transmission in Brazilian Prisons. Am. J. Trop. Med. Hyg. 2015, 93, 739–746. [Google Scholar] [CrossRef]
- Herrera, M.; Keynan, Y.; López, L.; Marín, D.; Arroyave, L.; Arbeláez, M.P.; Vélez, L.; Rueda, Z.V. Incidence and Risk Factors Associated with Latent Tuberculosis Infection and Pulmonary Tuberculosis among People Deprived of Liberty in Colombian Prisons. Am. J. Trop. Med. Hyg. 2021, 106, 66–74. [Google Scholar] [CrossRef]
- Ferreira, M.R.L.; Andrade, R.L.d.P.; Bossonario, P.A.; Fiorati, R.C.; Arcêncio, R.A.; Rezende, C.E.M.d.; Orfão, N.H.; Monroe, A.A. Social determinants of health and unfavourable outcome of tuberculosis treatment in the prison system. Cien. Saude Colet. 2022, 27, 4451–4459. [Google Scholar] [CrossRef]
- Izzo, C.; Monica, A.; De Matteis, G.; De Biasi, S.; De Chiara, A.; Pagano, A.M.; Mezzetti, E.; Del Duca, F.; Manetti, A.C.; La Russa, R.; et al. Not Only COVID-19: Prevalence and Management of Latent Mycobacterium Tuberculosis Infection in Three Penitentiary Facilities in Southern Italy. Healthcare 2022, 10, 386. [Google Scholar] [CrossRef] [PubMed]
- Amirkhani, A.; Humayun, M.; Ye, W.; Worku, Y.; Yang, Z. Patient Characteristics Associated with Different Types of Prison TB: An Epidemiological Analysis of 921 TB Cases Diagnosed at an Ethiopian Prison. BMC Pulm. Med. 2021, 21, 334. [Google Scholar] [CrossRef] [PubMed]
- Gatechompol, S.; Harnpariphan, W.; Supanan, R.; Suwanpimolkul, G.; Sophonphan, J.; Ubolyam, S.; Kerr, S.J.; Avihingsanon, A.; Kawkitinarong, K. Prevalence of Latent Tuberculosis Infection and Feasibility of TB Preventive Therapy among Thai Prisoners: A Cross-Sectional Study. BMC Public Health 2021, 21, 1206. [Google Scholar] [CrossRef]
- Chekesa, B.; Gumi, B.; Chanyalew, M.; Zewude, A.; Ameni, G. Prevalence of Latent Tuberculosis Infection and Associated Risk Factors in Prison in East Wollega Zone of Western Ethiopia. PLoS ONE 2020, 15, e0233314. [Google Scholar] [CrossRef] [PubMed]
- Singano, V.; Kip, E.; Ching’ani, W.; Chiwaula, L. Tuberculosis Treatment Outcomes among Prisoners and General Population in Zomba, Malawi. BMC Public Health 2020, 20, 700. [Google Scholar] [CrossRef] [PubMed]
- Winetsky, D.E.; Almukhamedov, O.; Pulatov, D.; Vezhnina, N.; Dooronbekova, A.; Zhussupov, B. Prevalence, Risk Factors and Social Context of Active Pulmonary Tuberculosis among Prison Inmates in Tajikistan. PLoS ONE 2014, 9, e86046. [Google Scholar] [CrossRef] [PubMed]
- Carbone, A.d.S.S.; Paião, D.S.G.; Sgarbi, R.V.E.; Lemos, E.F.; Cazanti, R.F.; Ota, M.M.; Junior, A.L.; Bampi, J.V.B.; Elias, V.P.F.; Simionatto, S.; et al. Active and Latent Tuberculosis in Brazilian Correctional Facilities: A Cross-Sectional Study. BMC Infect. Dis. 2015, 15, 24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arroyave, L.; Keynan, Y.; Sanchez, D.; López, L.; Marin, D.; Posada, M.; Rueda, Z.V. Guards in Prisons: A Risk Group for Latent Tuberculosis Infection. J. Immigr. Minor Health 2019, 21, 578–585. [Google Scholar] [CrossRef]
- Salazar-De La Cuba, A.L.; Ardiles-Paredes, D.F.; Araujo-Castillo, R.V.; Maguiña, J.L. High Prevalence of Self-Reported Tuberculosis and Associated Factors in a Nation-Wide Census among Prison Inmates in Peru. Trop. Med. Int. Health 2019, 24, 328–338. [Google Scholar] [CrossRef]
- Stuckler, D.; Basu, S.; McKee, M.; King, L. Mass Incarceration Can Explain Population Increases in TB and Multidrug-Resistant TB in European and Central Asian Countries. Proc. Natl. Acad. Sci. USA 2008, 105, 13280–13285. [Google Scholar] [CrossRef] [Green Version]
- Adane, K.; Spigt, M.; Johanna, L.; Noortje, D.; Abera, S.F.; Dinant, G.-J. Tuberculosis Knowledge, Attitudes, and Practices among Northern Ethiopian Prisoners: Implications for TB Control Efforts. PLoS ONE 2017, 12, e0174692. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nunes, C.; Duarte, R.; Veiga, A.M.; Taylor, B. Who Are the Patients That Default Tuberculosis Treatment?—Space Matters! Epidemiol. Infect. 2017, 145, 1130–1134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marks, S.M.; Deluca, N.; Walton, W. Knowledge, Attitudes and Risk Perceptions about Tuberculosis: US National Health Interview Survey. Int. J. Tuberc. Lung Dis. 2008, 12, 1261–1267. [Google Scholar] [PubMed]
- Kuniholm, M.H.; Mark, J.; Aladashvili, M.; Shubladze, N.; Khechinashvili, G.; Tsertsvadze, T.; del Rio, C.; Nelson, K.E. Risk Factors and Algorithms to Identify Hepatitis C, Hepatitis B, and HIV among Georgian Tuberculosis Patients. Int. J. Infect. Dis. 2008, 12, 51–56. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Macedo, L.R.; Maciel, E.L.N.; Struchiner, C.J. Factors associated with tuberculosis in persons deprived of liberty in Espírito Santo. Rev. Saude Publica 2020, 54, 67. [Google Scholar] [CrossRef] [PubMed]
- Janani, L.; Mansournia, M.A.; Nourijeylani, K.; Mahmoodi, M.; Mohammad, K. Statistical Issues in Estimation of Adjusted Risk Ratio in Prospective Studies. Arch. Iran Med. 2015, 18, 713–719. [Google Scholar]
- Fitzmaurice, G.M. Clustered Data. In Wiley StatsRef: Statistics Reference Online; American Cancer Society: Atlanta, GA, USA, 2014; ISBN 978-1-118-44511-2. [Google Scholar]
- Vagenas, D.; Totsika, V. Modelling Correlated Data: Multilevel Models and Generalized Estimating Equations and Their Use with Data from Research in Developmental Disabilities. Res. Dev. Disabil. 2018, 81, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Leyrat, C.; Morgan, K.E.; Leurent, B.; Kahan, B.C. Cluster Randomized Trials with a Small Number of Clusters: Which Analyses Should Be Used? Int. J. Epidemiol. 2018, 47, 321–331. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Redden, D.T. Comparing Denominator Degrees of Freedom Approximations for the Generalized Linear Mixed Model in Analyzing Binary Outcome in Small Sample Cluster-Randomized Trials. BMC Med. Res. Methodol. 2015, 15, 38. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Redden, D.T. Small Sample Performance of Bias-Corrected Sandwich Estimators for Cluster-Randomized Trials with Binary Outcomes. Stat. Med. 2015, 34, 281–296. [Google Scholar] [CrossRef] [Green Version]
- Espelt, A.; Marí-Dell’Olmo, M.; Penelo, E.; Bosque-Prous, M. Applied Prevalence Ratio Estimation with Different Regression Models: An Example from a Cross-National Study on Substance Use Research. Adicciones 2016, 29, 105–112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Richardson, D.B.; Kinlaw, A.C.; MacLehose, R.F.; Cole, S.R. Standardized Binomial Models for Risk or Prevalence Ratios and Differences. Int. J. Epidemiol. 2015, 44, 1660–1672. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Petersen, M.R.; Deddens, J.A. A Comparison of Two Methods for Estimating Prevalence Ratios. BMC Med. Res. Methodol. 2008, 8, 9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yelland, L.N.; Salter, A.B.; Ryan, P. Performance of the Modified Poisson Regression Approach for Estimating Relative Risks from Clustered Prospective Data. Am. J. Epidemiol. 2011, 174, 984–992. [Google Scholar] [CrossRef]
- Zou, G.Y.; Donner, A. Extension of the Modified Poisson Regression Model to Prospective Studies with Correlated Binary Data. Stat. Methods Med. Res. 2013, 22, 661–670. [Google Scholar] [CrossRef]
- Martinez, B.A.F.; Leotti, V.B.; Silva, G.d.S.E.; Nunes, L.N.; Machado, G.; Corbellini, L.G. Odds Ratio or Prevalence Ratio? An Overview of Reported Statistical Methods and Appropriateness of Interpretations in Cross-Sectional Studies with Dichotomous Outcomes in Veterinary Medicine. Front. Vet Sci. 2017, 4, 193. [Google Scholar] [CrossRef] [Green Version]
- Janani, L.; Mansournia, M.A.; Mohammad, K.; Mahmoodi, M.; Mehrabani, K.; Nourijelyani, K. Comparison between Bayesian Approach and Frequentist Methods for Estimating Relative Risk in Randomized Controlled Trials: A Simulation Study. J. Stat. Comput. Simul. 2017, 87, 640–651. [Google Scholar] [CrossRef]
- Hubbard, A.E.; Ahern, J.; Fleischer, N.L.; Van der Laan, M.; Lippman, S.A.; Jewell, N.; Bruckner, T.; Satariano, W.A. To GEE or Not to GEE: Comparing Population Average and Mixed Models for Estimating the Associations between Neighborhood Risk Factors and Health. Epidemiology 2010, 21, 467–474. [Google Scholar] [CrossRef]
- McNeish, D.; Kelley, K. Fixed Effects Models versus Mixed Effects Models for Clustered Data: Reviewing the Approaches, Disentangling the Differences, and Making Recommendations. Psychol. Methods 2019, 24, 20–35. [Google Scholar] [CrossRef]
- Bhowmik, K.R.; Das, S. On Selection of an Appropriate Logistic Model to Determine the Risk Factors of Childhood Stunting in Bangladesh. Matern. Child Nutr. 2018, 15, e12636. [Google Scholar] [CrossRef]
- Bouwmeester, W.; Twisk, J.W.; Kappen, T.H.; van Klei, W.A.; Moons, K.G.; Vergouwe, Y. Prediction Models for Clustered Data: Comparison of a Random Intercept and Standard Regression Model. BMC Med. Res. Methodol. 2013, 13, 19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bottomley, C.; Kirby, M.J.; Lindsay, S.W.; Alexander, N. Can the Buck Always Be Passed to the Highest Level of Clustering? BMC Med. Res. Methodol. 2016, 16, 29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eldridge, S.M.; Ashby, D.; Kerry, S. Sample Size for Cluster Randomized Trials: Effect of Coefficient of Variation of Cluster Size and Analysis Method. Int. J. Epidemiol. 2006, 35, 1292–1300. [Google Scholar] [CrossRef] [Green Version]
- Staley, J.R.; Suderman, M.; Simpkin, A.J.; Gaunt, T.R.; Heron, J.; Relton, C.L.; Tilling, K. Longitudinal Analysis Strategies for Modelling Epigenetic Trajectories. Int. J. Epidemiol. 2018, 47, 516–525. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kasza, J.; Polkinghorne, K.R.; Marshall, M.R.; McDonald, S.P.; Wolfe, R. Clustering and Residual Confounding in the Application of Marginal Structural Models: Dialysis Modality, Vascular Access, and Mortality. Am. J. Epidemiol. 2015, 182, 535–543. [Google Scholar] [CrossRef] [Green Version]
- Adoma Pels, W.; Alam, S.; Carpp, L.N.; Moodie, E.E.M. A Call for Caution in Using Information Criteria to Select the Working Correlation Structure in Generalized Estimating Equations. Epidemiology 2018, 29, e51. [Google Scholar] [CrossRef]
- Tamhane, A.R.; Westfall, A.O.; Burkholder, G.A.; Cutter, G.R. Prevalence Odds Ratio versus Prevalence Ratio: Choice Comes with Consequences. Stat. Med. 2016, 35, 5730–5735. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, C.O.; Kohlmann, T. When to Use the Odds Ratio or the Relative Risk? Int. J. Public Health 2008, 53, 165–167. [Google Scholar] [CrossRef]
- Reichenheim, M.E.; Coutinho, E.S.F. Measures and Models for Causal Inference in Cross-Sectional Studies: Arguments for the Appropriateness of the Prevalence Odds Ratio and Related Logistic Regression. BMC Med. Res. Methodol. 2010, 10, 66. [Google Scholar] [CrossRef] [Green Version]
- Rueda, Z.V.; López, L.; Vélez, L.A.; Marín, D.; Giraldo, M.R.; Pulido, H.; Orozco, L.C.; Montes, F.; Arbeláez, M.P. High Incidence of Tuberculosis, Low Sensitivity of Current Diagnostic Scheme and Prolonged Culture Positivity in Four Colombian Prisons. A Cohort Study. PLoS ONE 2013, 8, e80592. [Google Scholar] [CrossRef] [Green Version]
- Zou, G. A Modified Poisson Regression Approach to Prospective Studies with Binary Data. Am. J. Epidemiol. 2004, 159, 702–706. [Google Scholar] [CrossRef] [PubMed]
- Shoukri, M.M.; Donner, A.; El-Dali, A. Covariate-Adjusted Confidence Interval for the Intraclass Correlation Coefficient. Contemp. Clin. Trials 2013, 36, 244–253. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hardin, J.W.; Hilbe, J.M. Generalized Linear Models and Extensions, 2nd ed.; Stata Press: College Station, TX, USA, 2007; ISBN 978-1-59718-014-6. [Google Scholar]
- Kleinbaum, D.G.; Klein, M. Logistic Regression for Correlated Data: GEE. In Logistic Regression. A Self-Learning Text; Springer: New York, NY, USA, 2010; pp. 489–538. ISBN 978-1-4419-1741-6. [Google Scholar]
- Thompson, J.; Hemming, K.; Forbes, A.; Fielding, K.; Hayes, R. Comparison of Small-Sample Standard-Error Corrections for Generalised Estimating Equations in Stepped Wedge Cluster Randomised Trials with a Binary Outcome: A Simulation Study. Stat. Methods Med. Res. 2021, 30, 425–439. [Google Scholar] [CrossRef]
- Koziol, N.A.; Bovaird, J.A.; Suarez, S. A Comparison of Population-Averaged and Cluster-Specific Approaches in the Context of Unequal Probabilities of Selection. Multivariate Behav. Res. 2017, 52, 325–349. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moerbeek, M.; van Schie, S. How Large Are the Consequences of Covariate Imbalance in Cluster Randomized Trials: A Simulation Study with a Continuous Outcome and a Binary Covariate at the Cluster Level. BMC Med. Res. Methodol. 2016, 16, 79. [Google Scholar] [CrossRef] [Green Version]
- Bardenheier, B.H.; Shefer, A.; Barker, L.; Winston, C.A.; Sionean, C.K. Public Health Application Comparing Multilevel Analysis with Logistic Regression: Immunization Coverage among Long-Term Care Facility Residents. Ann. Epidemiol. 2005, 15, 749–755. [Google Scholar] [CrossRef]
- Santos, C.A.S.; Fiaccone, R.L.; Oliveira, N.F.; Cunha, S.; Barreto, M.L.; do Carmo, M.B.B.; Moncayo, A.-L.; Rodrigues, L.C.; Cooper, P.J.; Amorim, L.D. Estimating Adjusted Prevalence Ratio in Clustered Cross-Sectional Epidemiological Data. BMC Med. Res. Methodol. 2008, 8, 80. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Tan, C.S.; Chia, K.S. A Practical Guide for Multivariate Analysis of Dichotomous Outcomes. Ann. Acad. Med. Singap. 2009, 38, 714–719. [Google Scholar] [CrossRef]
- Maas, C.J.M.; Hox, J.J. Sufficient Sample Sizes for Multilevel Modeling. Methodology 2005, 1, 86–92. [Google Scholar] [CrossRef] [Green Version]



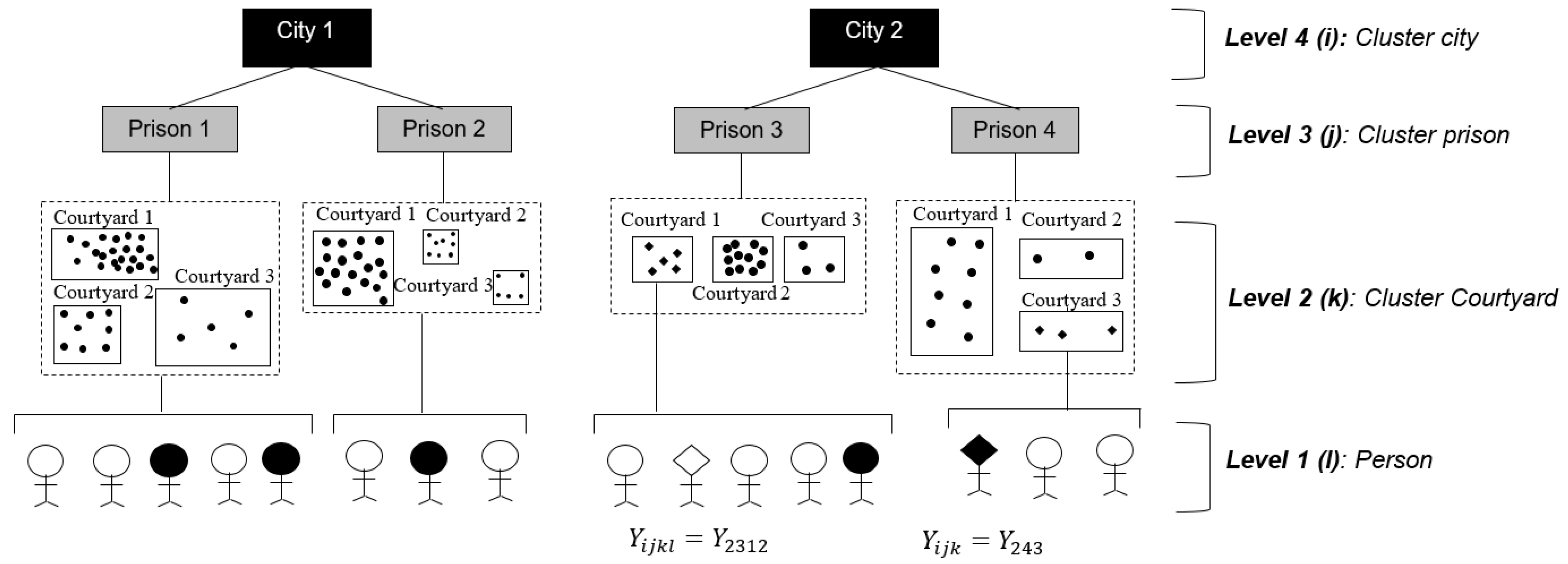{kind=link}
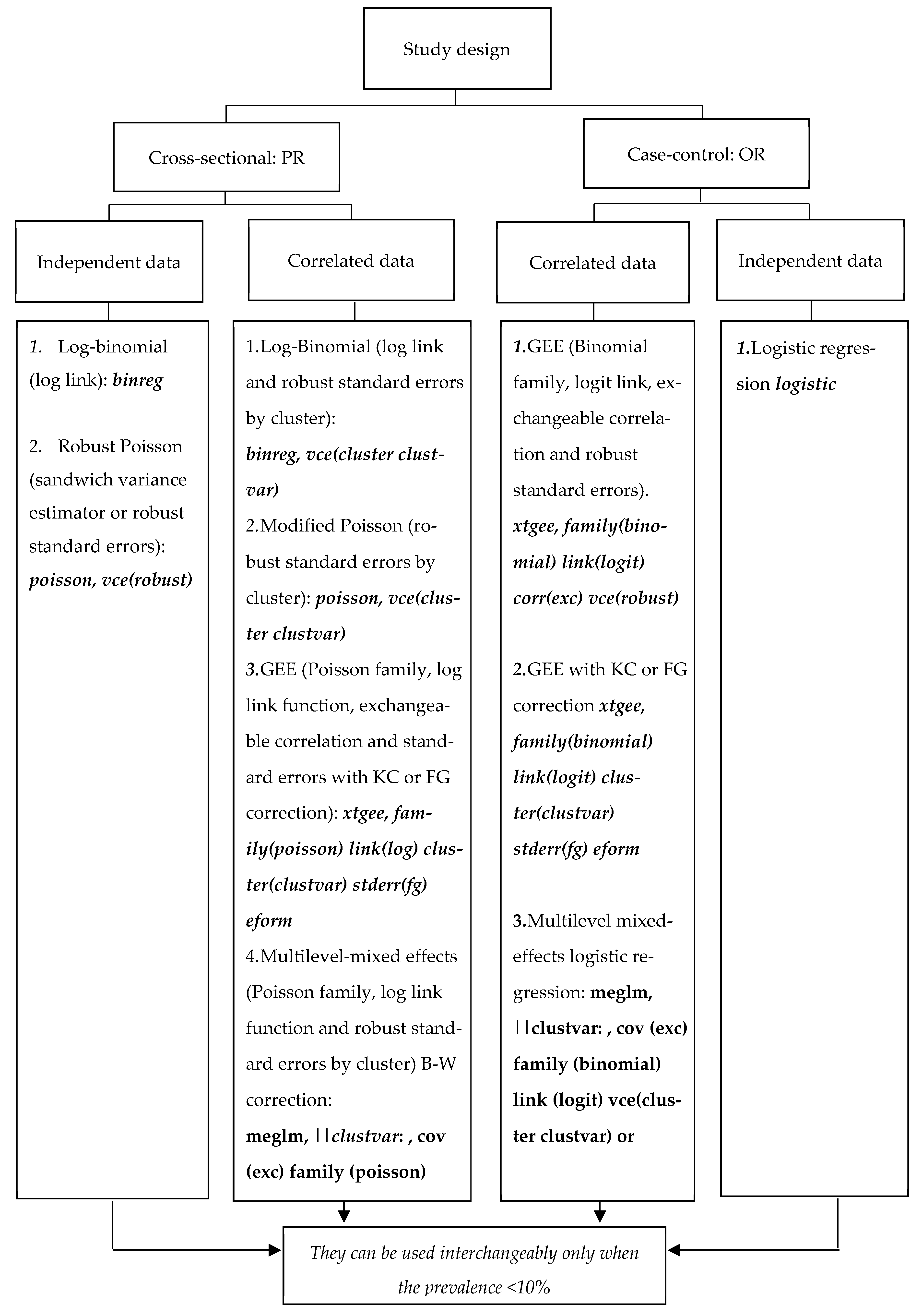{kind=link}
| Exposure Factor | Active TB Prevalence | Logistic | Log-Binomial 1 | Robust Poisson 2 | Comparison 3 |
|---|---|---|---|---|---|
| ORadjusted | PRadjusted | PRadjusted | |||
| [95%CI] | [95%CI] | [95%CI] | |||
| Age ≤ 24 (ref) | 4.61 | ||||
| Age > 24 | 5.84 | 1.43 | 1.40 | 1.39 | 7.5 |
| [0.797, 2.547] | [0.809, 2.403] | [0.798, 2.405] | |||
| No prior TB (ref) | 5.02 | ||||
| Prior TB | 18.0 | 3.31 | 2.84 | 2.84 | 25.5 |
| [1.461, 7.504] | [1.469, 5.494] | [1.447, 5.569] | |||
| Normal BMI (ref) | 5.36 | ||||
| Low weight | 16.0 | 3.32 | 2.93 | 2.89 | 20.2 |
| [1.677, 6.576] | [1.660, 5.163] | [1.638, 5.096] | |||
| Overweight | 2.89 | 0.42 | 0.43 | 0.43 | 1.8 |
| [0.147, 1.169] | [0.158, 1.187] | [0.156, 1.185] |
| Exposure Factor | Adjusted Prevalence Ratio and [95%CI] | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GEE 1 | Multilevel—Mixed-Effects 2 | Log-Binomial 3 | Modified Poisson 4 | |||||||||
| Level | Courtyard (n = 39) | Prison (n = 4) | City (n = 2) | Courtyard (n = 39) | Prison (n = 4) | City (n = 2) | Courtyard (n = 39) | Prison (n = 4) | City (n = 2) | Courtyard (n = 39) | Prison (n =4 ) | City (n = 2) |
| Age ≤ 24 (ref) | ||||||||||||
| Age > 24 | 1.38 | 1.37 | 1.37 | 1.38 | 1.38 | 1.38 | 1.40 | 1.40 | 1.40 | 1.39 | 1.39 | 1.39 |
| [1.020, 1.874] | [1.089, 1.729] | [1.310, 1.433] | [1.008, 1.878] | [1.020, 1.856] | [1.202, 1.575] | [1.015, 1.918] | [1.056, 1.843] | [1.256, 1.549 | [1.011, 1.898] | [1.043, 1.841] | [1.245, 1.542] | |
| No prior (ref) | ||||||||||||
| Prior TB | 2.73 | 2.82 | 2.81 | 2.67 | 2.67 | 2.67 | 2.84 | 2.84 | 2.84 | 2.84 | 2.84 | 2.84 |
| [1.531, 4.852 | [1.944, 4.075] | [1.988, 3.962] | [1.542, 4.637] | [1.644, 4.349] | [1.529, 4.676] | [1.571, 5.140] | [1.902, 4.246] | [1.886, 4.283] | [1.645, 4.901] | [1.757, 4.587] | [1.669, 4.828] | |
| Normal BMI (ref) | ||||||||||||
| Low weight | 2.85 | 2.85 | 2.84 | 2.84 | 2.84 | 2.84 | 2.93 | 2.93 | 2.93 | 2.89 | 2.89 | 2.89 |
| [1.842, 4.408 | [1.695, 4.781] | [2.211, 3.639] | [1.786, 4.514] | [1.615, 4.994] | [2.116, 3.811] | [1.885, 4.545] | [1.628, 5.264] | [2.048, 4.185] | [1.814, 4.601] | [1.624, 5.138] | [2.123, 3.932] | |
| Overweight | 0.42 | 0.43 | 0.44 | 0.42 | 0.42 | 0.42 | 0.44 | 0.44 | 0.44 | 0.43 | 0.43 | 0.43 |
| [0.119, 1.474 | [0.059, 3.116] | [0.049, 3.863] | [0.119, 1.491] | [0.035, 5.027] | [0.158, 11.281] | [0.125, 1.503] | [0.038, 4.896] | [0.017, 10.869] | [0.123, 1.501] | [0.037, 4.877] | [0.017, 10.846] | |
| CV(%) | 181% | 103% | - | |||||||||
| ICC | 0.043 | <0.001 | <0.001 | |||||||||
| Exposure Factor | Model 1: City 1 | Model 2: Prison 1 | Model 3: Courtyard 1 | Model 4 2 | Model 5 2 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Level | PR | [95%CI] | PR | [95%CI] | PR | [95%CI] | PR | [95%CI] | PR | [95%CI] |
| Age ≤ 24 (ref) | ||||||||||
| Age > 24 | 1.39 | [1.25–1.54] | 1.39 | [1.04–1.84] | 1.38 | [1.01–1.88] | 1.39 | [1.02–1.86] | 1.39 | [1.02–1.88] |
| No prior (ref) | ||||||||||
| Prior TB | 2.84 | [1.67–4.83] | 2.84 | [1.76–4.59] | 2.67 | [1.54–4.64] | 2.70 | [1.58–4.60] | 2.68 | [1.55–4.62] |
| Normal BMI (ref) | ||||||||||
| Low weight | 2.89 | [2.12–3.93] | 2.89 | [1.62–5.14] | 2.84 | [1.79–4.51] | 2.79 | [1.75–4.45] | 2.84 | [1.78–4.53] |
| Overweight | 0.43 | [0.02–10.84] | 0.43 | [0.04–4.88] | 0.42 | [0.12–1.49] | 0.42 | [0.12–1.51] | 0.42 | [0.12–1.49] |
| Prison D (ref) 3 | ||||||||||
| Prison A | - | - | - | - | - | - | 1.64 | [0.90–2.99] | - | - |
| Prison B | - | - | - | - | - | - | 1.63 | [0.76–3.47] | - | - |
| Prison C | - | - | - | - | - | - | 2.15 | [1.02–4.54] | - | - |
| City A (ref) 3 | ||||||||||
| City B | - | - | - | - | - | - | - | - | 1.42 | [0.79–2.54] |
| ICC | <0.001 | <0.001 | 0.043 | 0.031 | 0.034 | |||||
| Exposure Factor | GEE 1 | ||
|---|---|---|---|
| Without Any Adjustment 3 [95%CI] | With CVRE [95%CI] | With BCSE [95%CI] | |
| Age 18–24 (ref) (Years) | |||
| 25–64 | 1.14 [0.892, 1.407] | 1.14 [1.087, 1.193] | 1.14 [0.658, 1.970] |
| ≥65 | 1.10 [0.687, 1.473] | 1.10 [0.996, 1.221] | 1.10 [0.495, 2.457] |
| History of the previous incarceration | 1.09 [0.904, 1.311] | 1.09 [1.009, 1.172] | 1.09 [0.650, 1.819] |
| Time of current incarceration ≤12 (ref) (Months) | |||
| 13–24 | 1.11 [0.878, 1.408] | 1.12 [1.007, 1.228] | 1.12 [0.562, 2.201] |
| ≥25 | 1.08 [0.874, 1.332] | 1.08 [0.951, 1.234] | 1.08 [0.392, 2.995] |
| Presence of BCG scar | 1.00 [0.931, 1.070] | 1.00 [0.985, 1.013] | 1.00 [0.832, 1.198] |
| Last contact with a TB case—No contact (ref ) (Months) | |||
| 1–12 | 0.98 [0.776, 1.235] | 0.99 [0.862, 1.134] | 0.99 [0.357, 2.740] |
| ≥13 | 1.04 [0.797, 1.383] | 1.04 [0.983, 1.107] | 1.04 [0.689, 1.578] |
| Coefficient of variation | 191% | ||
| Exposure Factor | Multilevel– Mixed-Effects 2 | ||
| Without Any Adjustment [95%CI] | With CVRE [95%CI] | With B-W 4 | |
| Age 18-24 (ref) (Years) | |||
| 25–64 | 1.09 [0.877, 1.364] | 1.09 [1.023, 1.169] | - |
| ≥65 | 1.05 [0.724, 1.509] | 1.05 [0.963, 1.134] | - |
| History of the previous incarceration | 1.09 [0.904, 1.304] | 1.09 [1.010, 1.168] | - |
| Time of current incarceration ≤12 (ref) (Months) | |||
| 13–24 | 1.09 [0.865, 1.372] | 1.09 [0.994, 1.193] | - |
| ≥25 | 1.02 [0.836, 1.252] | 1.02 [0.871, 1.203] | - |
| Presence of BCG scar | 1.00 [0.936, 1.072] | 1.00 [0.993, 1.011] | - |
| Last contact with a TB case—No contact (ref) (Months) | |||
| 1–12 | 1.00 [0.804, 1.262] | 1.01 [0.862 1.176] | - |
| ≥13 | 1.02 [0.777, 1.347] | 1.02 [0.955, 1.095] | - |
| Intraclass Correlation | 0.071 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marín, D.; Keynan, Y.; Bangdiwala, S.I.; López, L.; Rueda, Z.V. Tuberculosis in Prisons: Importance of Considering the Clustering in the Analysis of Cross-Sectional Studies. Int. J. Environ. Res. Public Health 2023, 20, 5423. https://doi.org/10.3390/ijerph20075423
Marín D, Keynan Y, Bangdiwala SI, López L, Rueda ZV. Tuberculosis in Prisons: Importance of Considering the Clustering in the Analysis of Cross-Sectional Studies. International Journal of Environmental Research and Public Health. 2023; 20(7):5423. https://doi.org/10.3390/ijerph20075423
Chicago/Turabian StyleMarín, Diana, Yoav Keynan, Shrikant I. Bangdiwala, Lucelly López, and Zulma Vanessa Rueda. 2023. "Tuberculosis in Prisons: Importance of Considering the Clustering in the Analysis of Cross-Sectional Studies" International Journal of Environmental Research and Public Health 20, no. 7: 5423. https://doi.org/10.3390/ijerph20075423