1. Introduction
Fusarium and Aspergillus are the main pathogenic fungi of grain and oil crops [
1,
2]. In warm and humid areas, serious diseases will reduce the quality of crops such as wheat and corn, posing a serious threat to grain and oil production. Once the temperature and humidity of grain storage environments change, it is susceptible to pathogenic fungi and molds, and some may also produce mycotoxins, such as aflatoxin B1 (AFB1) produced by Aspergillus flavus and Fusarium. This fungus produces deoxynivalenol (DON) and zearalenone (ZEN). Therefore, a suitable environment is very important to ensure the quality of grains during storage, and experiments by Zain et al. [
3] demonstrated that temperature and moisture are important factors affecting toxin derivation. Among others, it is important to calculate the equilibrium moisture content in order to understand the behavior of moisture content of grains in storage environments [
4]. In addition, aflatoxin B1 (AFB1), deoxynivalenol (DON) and zearalenone (ZEN) are common and important toxins in wheat and maize, which pose serious risks to grain quality and human health. Other common non-toxic fungi rarely exceeded the limit values in historical testing records; therefore, in this paper, toxic fungi were selected as the main factors when conducting the quality prediction and constructing grading model of grain storage process affected by microorganisms in different environments. On this basis, temperature and moisture were selected as environmental variables, and aflatoxin B1 (AFB1), deoxynivalenol (DON) and zearalenone (ZEN) were chosen as monitoring indicators for this experiment and sampled and tested regularly.
As the world economy develops, and as people’s living standards continue to improve, food production increases year by year and food quality issues are of increasing concern. It is noteworthy that global post-production grain quantity and quality losses due to harvesting, storage, deterioration, and insect and mold contamination account for 15% to 20% of the total. Grain storage suffers from serious quality losses, the main causes of which include moderate reduction, dry matter depletion, and pest infestation. Therefore, reducing food losses due to storage and improving food utilization and safety are urgent needs that must be addressed internationally. This is an important prerequisite for establishing a resilient and developing a sustainable global agricultural food system.
In the face of such complex challenges, scholars have conducted research on predicting and evaluating quality changes during grain storage in order to determine the appropriate environmental settings, both to improve grain storage quality and to reduce grain quality losses during the storage phase. Coradi et al. [
1] developed six linear regression models to predict grain storage quality and evaluated the models to achieve high prediction accuracy. Faree et al. [
2] used multiple linear regression and the artificial neural network (ANN) to predict the quality of maize grains during storage; they achieved better prediction results. Lutz et al. [
5] used a wireless sensor network, an IoT platform, to monitor the equilibrium moisture content in real time and used ANN to predict the quality of maize grains stored under different conditions. Szwedziak et al. [
6] used a proprietary computer application based on the RGB model to assess the contamination status of maize grains. Xie et al. [
7] predicted public risk perceptions more accurately by building bp neural networks. Liu et al. [
8] constructed a bidirectional long- and short-term memory (BiLSTM) model and selected six influencing factors of municipal solid waste power generation as input indicators to achieve an effective prediction of municipal solid waste power generation.
In the current research, deep learning methods have been gradually applied to the prediction of quality changes in grain storage processes, but because of the close dependence of any quality changes in grain storage processes on environmental factors such as temperature and humidity with temporal characteristics, simple artificial neural networks (ANNs) cannot solve the problem of gradient explosion and information distortion, and their prediction accuracy is often lower than that of deep learning that can learn the close dependence of methods.
In this study, we developed a FEDformer-based prediction model for quality changes in grain storage process and a K-means++-based grading evaluation model for quality changes in grain storage process. Firstly, in the prediction model, we use three factors affecting grain quality to predict the grain quality changes during storage to reduce the uncertainty of the prediction model. Secondly, in the clustering model, we set an evaluation index S based on the conclusion of the prediction model, which integrates the current and predicted values of toxin content to grade and evaluate the quality changes during grain storage. The experimental results showed that the grain storage process quality change prediction model had the highest prediction accuracy and the lowest prediction error compared with other models. Finally, we suggest corresponding suggestions for optimizing grain storage.
The contributions of this study include three main aspects: (1) the establishment of a FEDformer-based model for predicting quality changes in grain storage process. Experiments show that the model is more accurate in predicting the quality changes of grain, as compared with several other deep learning models. (2) The establishment of a grading evaluation model based on K-means++ for the quality change of grain storage process. Based on the experimental results of this model, a reasonable grading evaluation of grain quality can be obtained. (3) The analysis, based on the changes of toxin content in grain during storage and grain quality grading evaluation obtained from the above study, of the factors influencing the quality changes in grain storage process by microbial environment. Corresponding suggestions are made for the optimization of grain storage. In addition, the environmental and quality changing data in the process of grain storage provide support for the subsequent blockchain-based grain collection, storage and transportation whole process traceability [
9,
10].
The structure of the paper is as follows:
Section 2 reviews the previous literature.
Section 3 presents the prediction model and the clustering model proposed in this paper.
Section 4 describes the experimental results and analysis.
Section 5 is the discussions and implementations section. Finally, the paper is concluded.
3. Methodology and Study Area
In recent years, Transformer [
42] has become a typical representative of neural network models used in the field of time-series prediction. FEDformer [
43] is an improved model based on Transformer; it focuses on the implementation of analyzing the relationship characteristics between data indicators, reducing the time complexity, improving the prediction accuracy and model learning efficiency of indicators, and thus reasonably and effectively predicting toxin content.
3.1. Data Source
Grain storage monitoring data for this study covered more than 20 regions with 139 wheat and corn samples totaling 2100 units of data, with wheat and corn originating from the middle and lower temperate regions. The datasets for training and testing in the experiment were divided as shown in
Table 1.
In addition, wheat and maize were obtained from the middle and lower reaches of temperate river valley production areas. The microbial toxin limits selected for this paper were as follows: 20 μg/kg for aflatoxin B1, 500 μg/kg for zearalenone ZON and 1000 μg/kg for deoxynivalenol DON for maize; 5 μg/kg for aflatoxin B1, 60 μg/kg for zearalenone ZON and 1000 μg/kg for deoxynivalenol DON for wheat. Fusarium DON was limited to 1000 μg/kg.
3.2. FEDformer-Based Model for Predicting Quality Changes in Grain Storage Processes
3.2.1. Model Fundamentals
FEDformer combines Transformer and seasonal-trend decomposition [
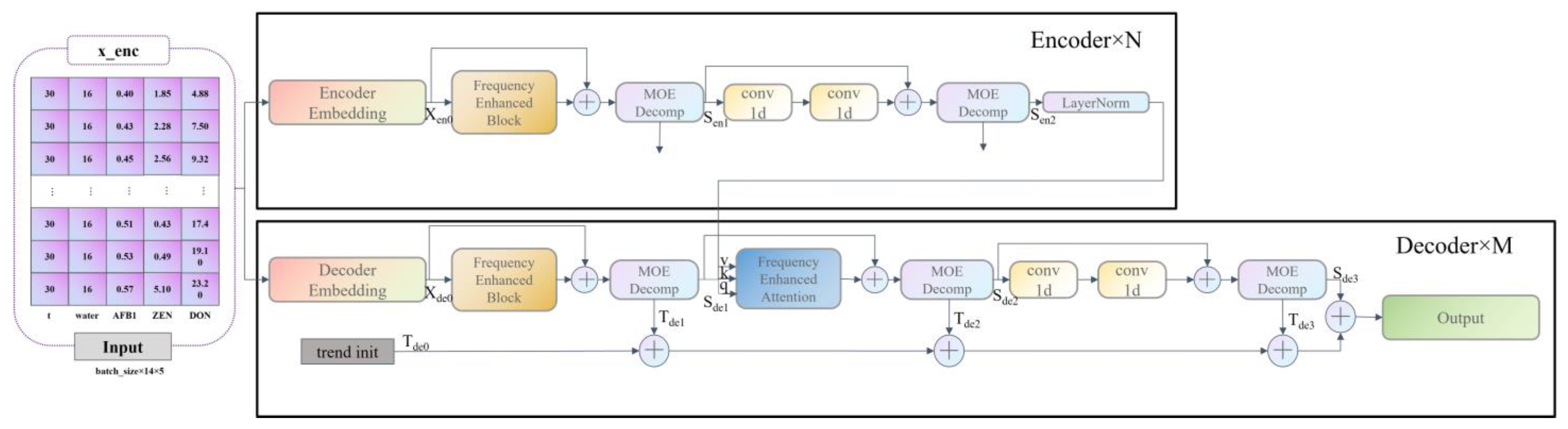
44] methods, capturing the global pattern of the world sequence with the seasonal-trend decomposition method, while capturing the more detailed structure with Transformer FEDformer’s. The main structure (backbone) uses an encoder–decoder structure, consisting of n encoders and m decoders, and it includes four internal submodules: a frequency domain learning module (Frequency Enhanced Block), a frequency domain attention module (Frequency Enhanced Attention), a period trend decomposition module (MOE Decomp), and a one-dimensional Convolution module (Conv1d).
The MOE Decomp module decomposes the sequence into a periodic term (seasonal, S) and a trend line (trend, T). This decomposition is not performed only once, but in an iterative decomposition mode. In the encoder, the input passes through two MOE Decomp layers, each of which decomposes the signal into two components: seasonal and trend. The trend component is discarded, and the seasonal component is passed to the next layers for learning and finally to the decoder. In the decoder, the input of the encoder also passes through three MOE Decomp layers and is decomposed into seasonal and trend components. Among them, the seasonal component is passed to the next layers for learning, where the frequency domain Attention (Frequency Enhanced Attention) layer learns the frequency domain correlation between the seasonal term of the encoder and the decoder, and the trend component is summed up and finally added back to the seasonal term to restore the original sequence.
Among the Frequency Enhanced Block (FEB) and the Frequency Enhanced Attention (FEA), the Attention mechanism used in the Frequency Enhanced Attention (FEA) is of linear complexity, while the Attention mechanism used in the traditional Transformer is of square complexity. This has the advantage of greatly reducing the length of the input vector and thus the computational complexity, but this sampling must be detrimental to the input information. This loss must be detrimental to the input information. However, experiments have shown that this loss has little impact on the final accuracy. This is because the general signal is sparser in the frequency domain compared to the time domain. Moreover, a large amount of information in the high frequency part is so-called noise; it can often be discarded in time series prediction problems, since noise often represents a randomly generated part and thus cannot be predicted.
In the learning phase, FEB uses a fully concatenated layer R as a learnable parameter. FEA, on the other hand, performs a cross-attention operation on the signals from the encoder and decoder in order to learn the intrinsic relationship between the two parts of the signal. The frequency domain complementation process is relative to the previous frequency domain sampling. In order to cause the signal to revert to its original length, the frequency points not picked by the previous sampling need to be zeroed and projected back to the time domain, because the signal projected back to the frequency domain is the same as the previous input signal dimension by the complementation operation in the previous step. The FEDformer model is shown in
Figure 1.
The specific function of the encoder is shown in the following Equations:
The specific function of the decoder is expressed in Equations
3.2.2. Model for Predicting Quality Changes during Grain Storage
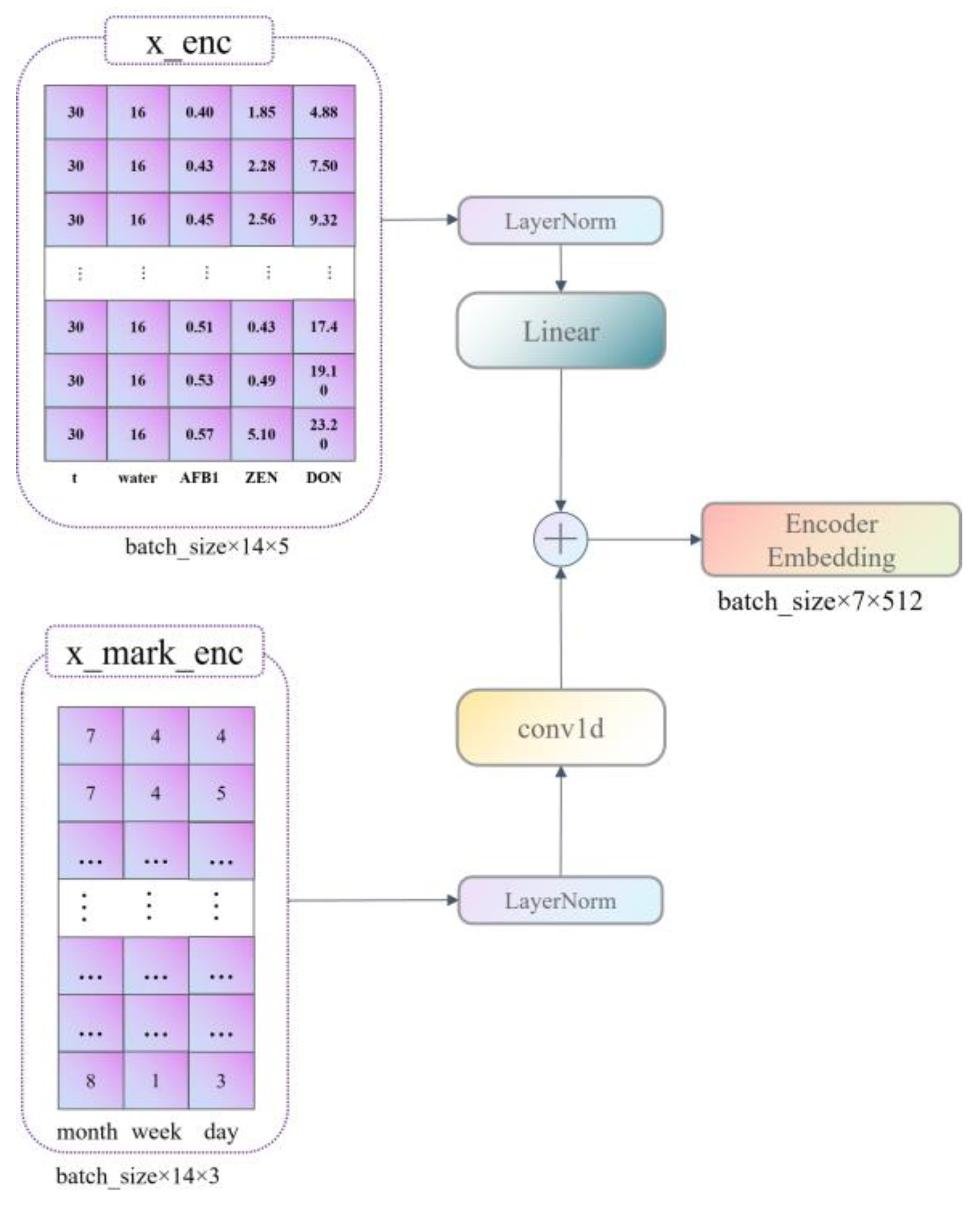
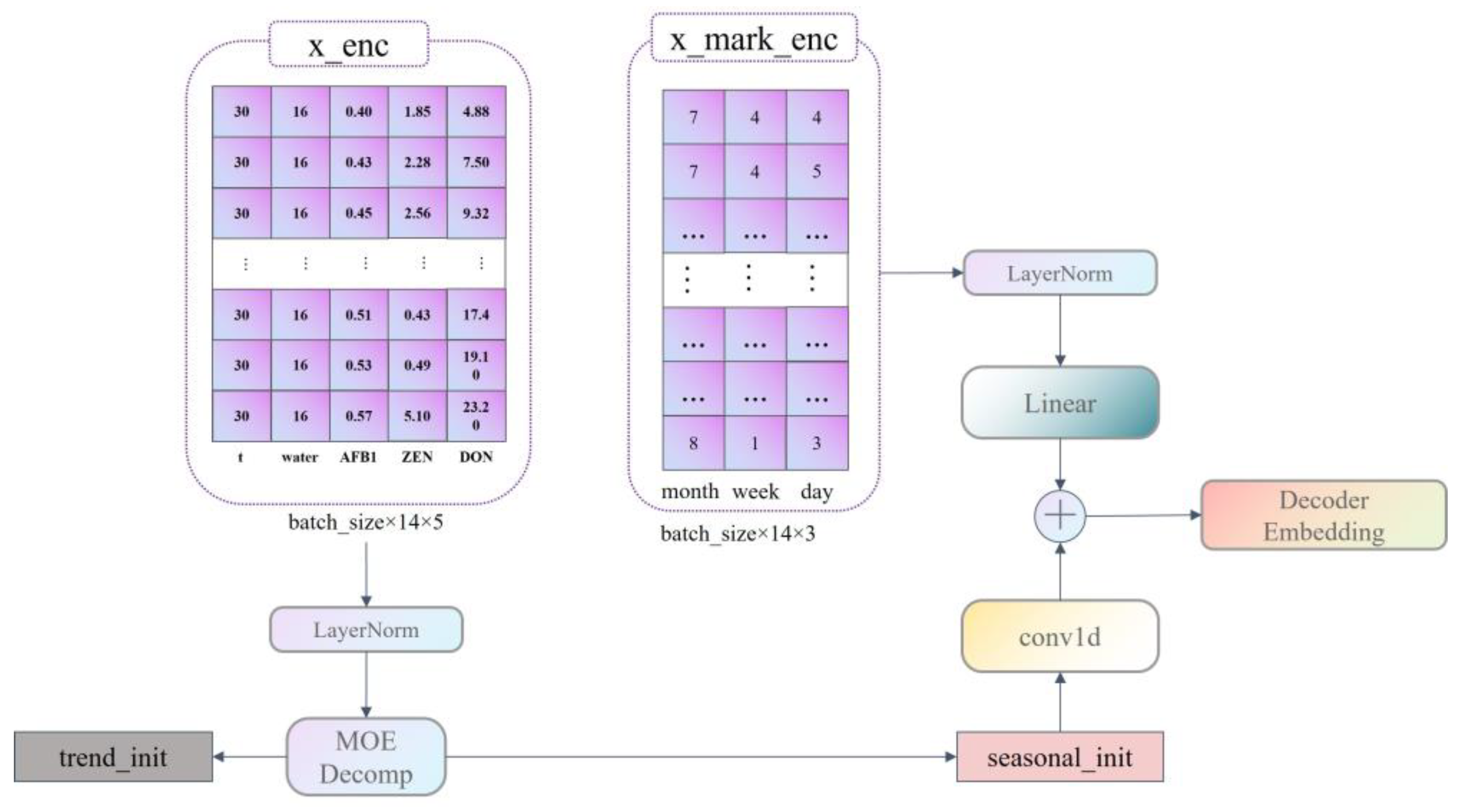
Our data are divided into six dimensions of information with a period of 30 days; these are time, temperature, moisture content, AFB1 content, ZEN content, and DON content, where AFB1, ZEN, and DON content are predictors. Therefore, to be applicable to the application scenario of this paper, we improved the construction of the model Encoder embedding as well as that of the Decoder Embedding.
First, we set the three dimensions of month, week, and day to represent the characteristics of the time dimension; this has the advantage of replacing the time dimension from one-dimensional information to three-dimensional information, and it can correctly represent the time sequence information and enhance the importance of the time dimension, making the model pay more attention to the characteristics of the time dimension in the learning process so as to predict the indicators more effectively. The construction of Encoder embedding is shown in
Figure 2. The construction of the decoder embedding is shown in
Figure 3.
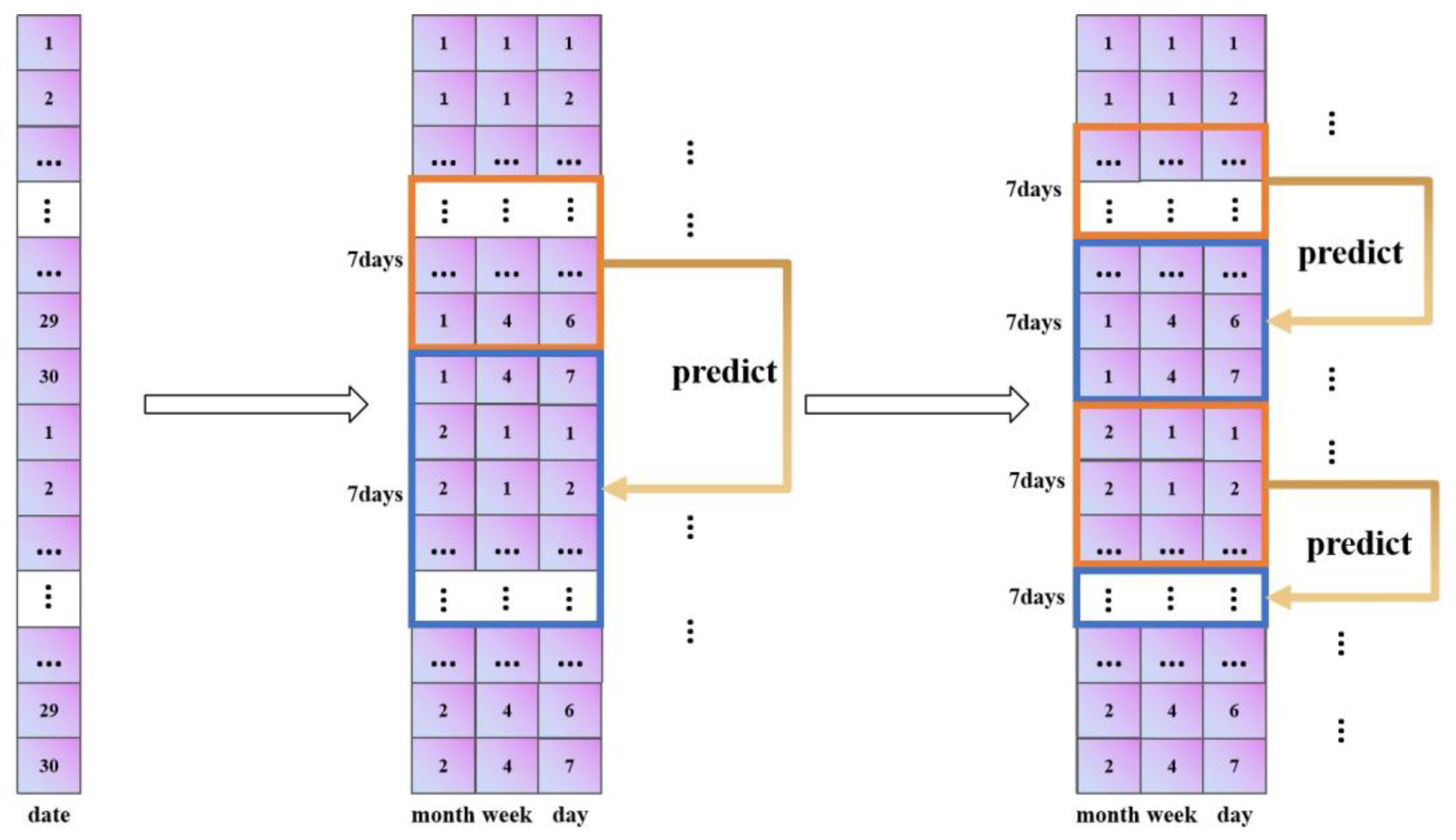
Second, in the model, we change the data reading method from sequential reading to reading with a 30-day period; this prevents the situation in which different samples predict each other, and thus it reasonably applies to the scenario in this paper. Finally, we set the data of the first seven days to predict the data of the next seven days. The specific improvement process is shown in
Figure 4.
3.3. Grading Evaluation of Quality Changes in Grain Storage Process Based on K-Means++
In order to evaluate the grade of quality changes in the grain storage process in grain silos, we set an evaluation index
S, which integrates the current and predicted values of toxin content, and the formula of the evaluation index
S is shown in Equation (6).
where
,
∈{1,2,…,
n} is the true value,
,
∈{1,2,…,
n} is the mean of the predicted values in the next 7 days, and n is the number of indicator variables.
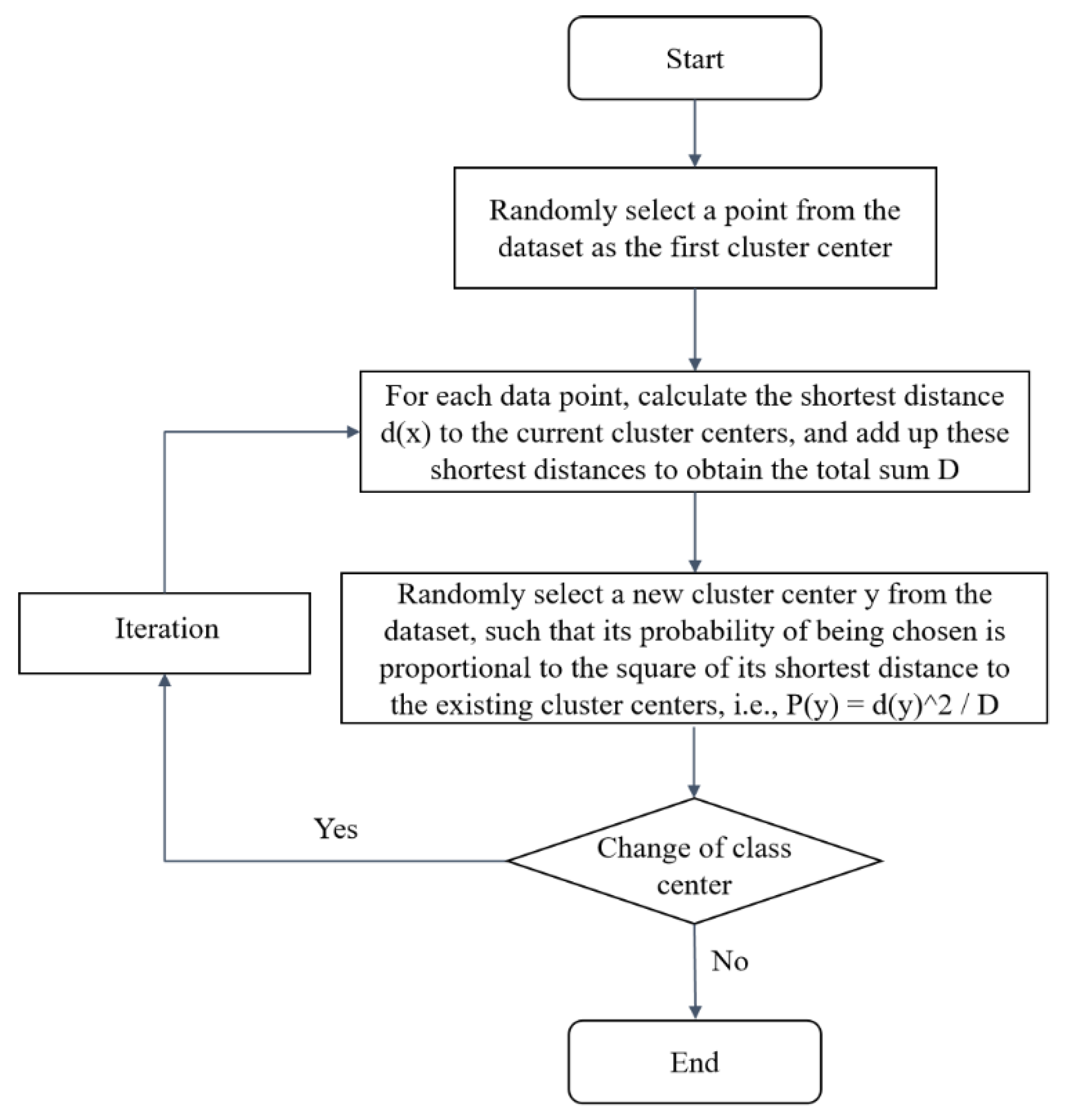
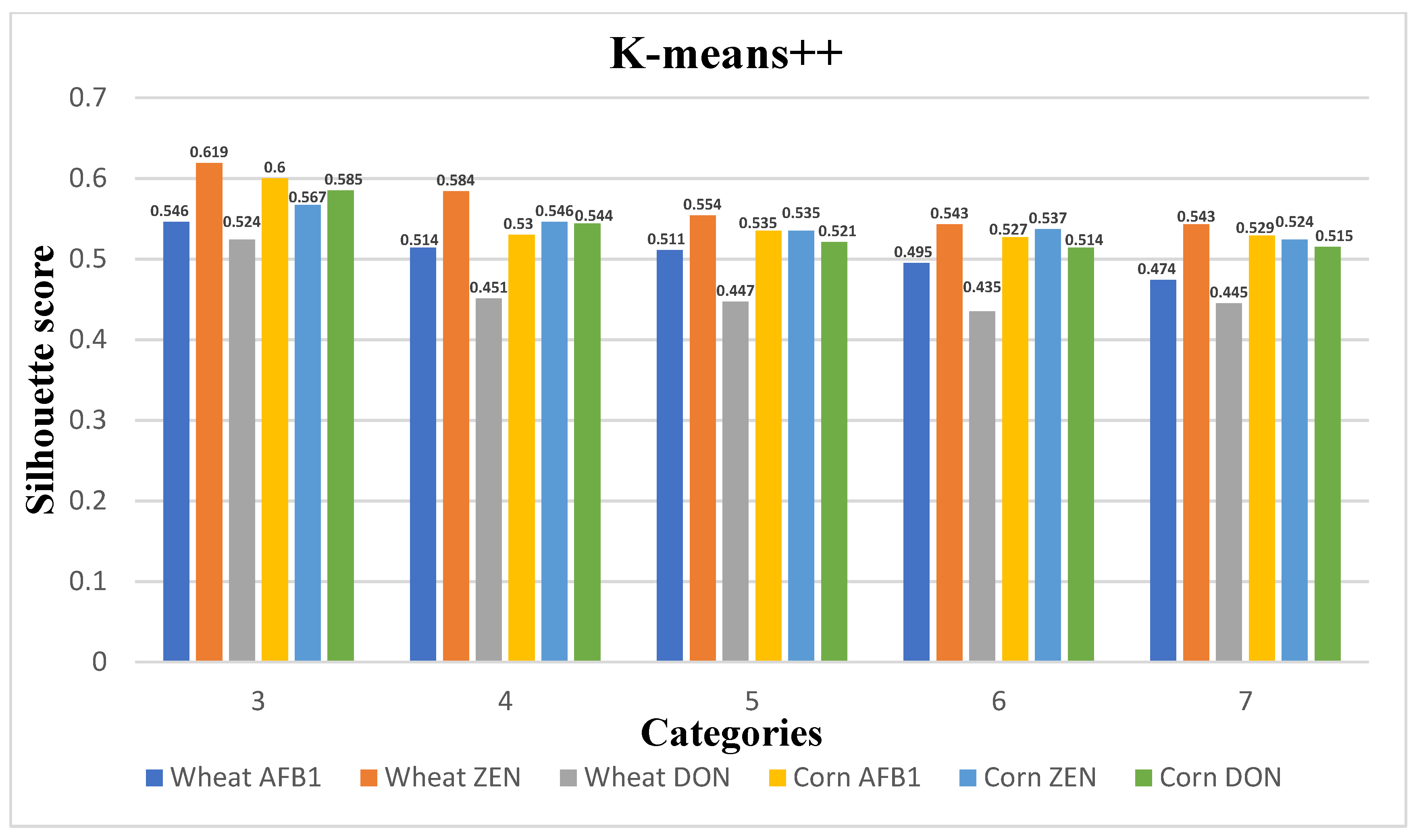
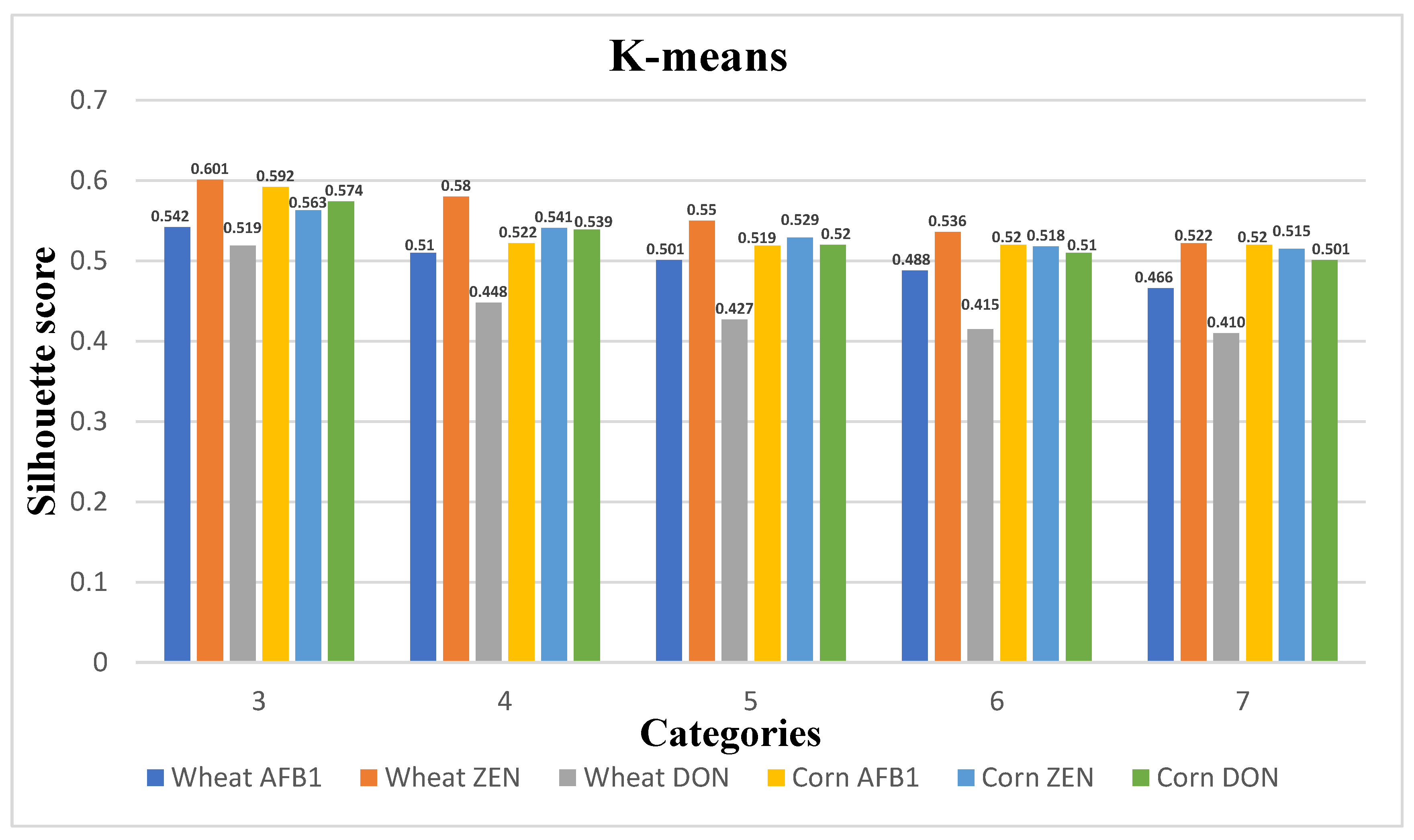
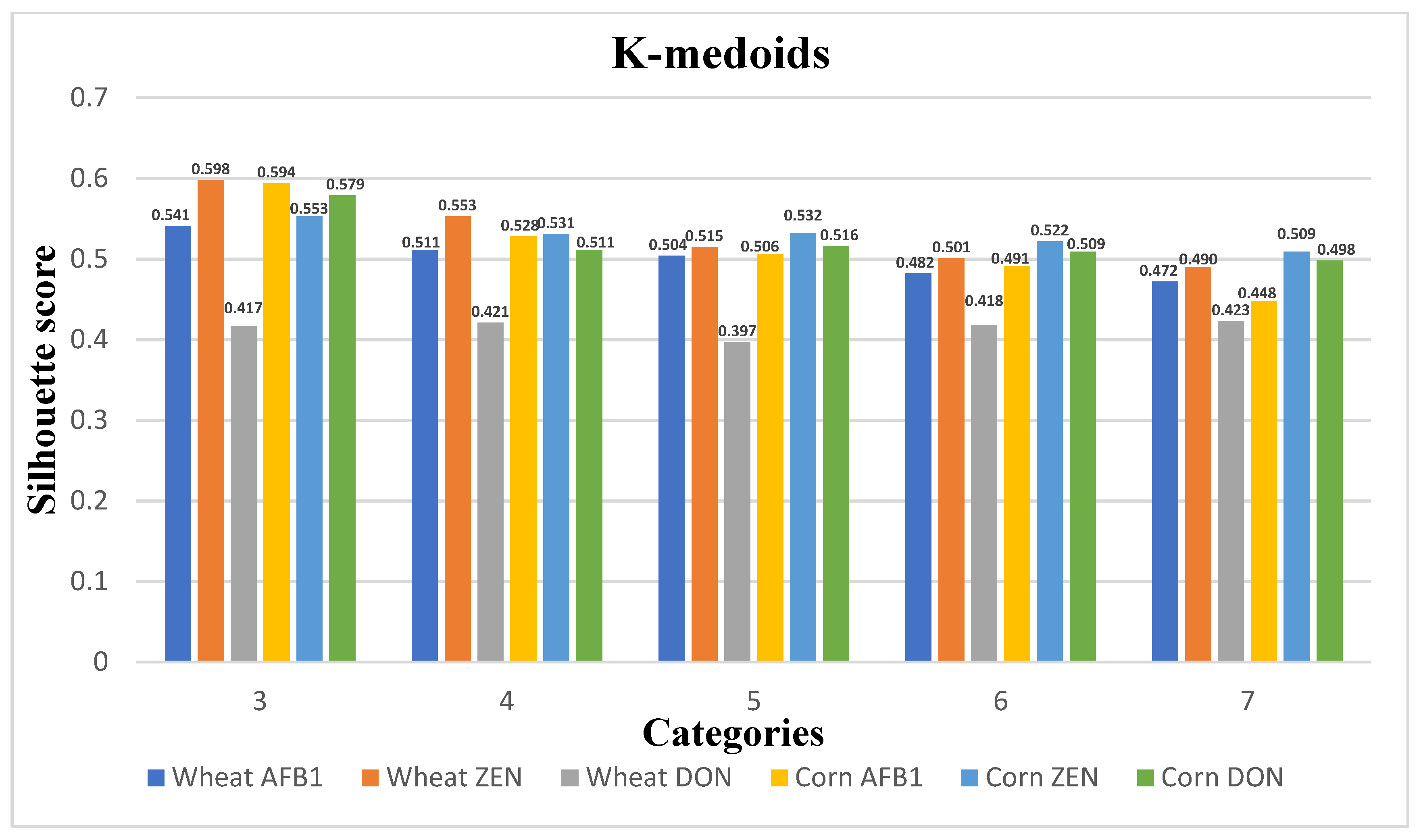
In this paper, a clustering algorithm is used to grade all samples for quality variation and to construct a quality grading space based on the evaluation index S. Since the amount of data in this subject is small and there are no dirty data, the K-means++ algorithm is fast and efficient, and it can achieve good clustering performance on the sample space of arbitrary shape, which is suitable for analyzing the model data of this study, so the K-means++ algorithm is selected for the grain quality change grading in this paper. The K-means++ algorithm is an improvement of the K-means algorithm, and its main difference is the initialization to determine the initial clustering center.
K-means algorithm determines the initial clustering center randomly, while K-means++ is based on the distance from the current sample point to the existing center point to provide the probability of the sample point’s becoming the next clustering center (the greater the distance, the greater the probability), and then, according to the probability size, to extract the next clustering center, and to repeat until the extraction of K clustering centers. The specific steps are shown in
Figure 5.
3.4. Model Evaluation Metrics
3.4.1. Evaluation Metrics for Predictive Models
The evaluation metrics of the prediction models are the mean absolute percentage error (MAPE), the mean square error (MSE), the root mean square error (RMSE), the mean absolute error (MAE), and the symmetric mean absolute percentage error (SMAPE), respectively; they are used to evaluate the prediction performance and the degree of fit of the models. MAE, MSE, RMSE, MAPE, and SMAPE are used to measure the difference between the predicted data and true data and the range of values. A perfect model is equal to zero when the predicted value exactly matches the true value; the larger the error, the larger the value.
The formula for calculating the mean absolute percentage error is shown in (7):
The formula for calculating the mean square error is shown in (8):
The formula for calculating the root mean square error is shown in (9):
The formula for calculating the mean absolute error is shown in (10):
The formula for calculating the symmetric mean absolute percentage error is shown in (11):
where
,
∈{1,2,…,
n} is the true value,
,
∈{1,2,…,
n} is the predicted value, and
n is the number of indicator variables.
3.4.2. Evaluation Metrics for Clustering Models
The evaluation index of the clustering model is the contour coefficient
S. The core idea of the contour coefficient is to determine the relative size of the inter-class distance and intra-class distance. The value is between [−1,1], and the larger the value, the better the clustering result. The formula for the profile coefficient
S is shown in (12):
where
is the average distance of other samples in the cluster to which
belongs,
is the minimum value of the average distance of samples from
i to other clusters, and
N is the number of samples.
5. Discussion
Food quality is related to human health, and a decline in food quality increases the risk of human illness [
13], in addition to the current global spread of COVID-19, which is impacting international food supply chains and straining food supplies [
41]. Sudden outbreaks of desert locusts in some countries, superimposed on global epidemics, make conventional disaster prevention and control difficult to implement, exacerbating concerns about food quality loss and food security. Therefore, it is of great interest to predict the quality of grain during storage; however, the factors that lead to changes in quality during storage are complex, and the deterioration in grain quality is due to contamination by toxins produced by microorganisms during storage, which seriously affects people’s health, where temperature and moisture are important factors that affect microbial activity; thus, the toxin content is a decisive factor in the quality of grain, and therefore our experiment used it as a monitoring indicator and temperature and moisture content as environmental variables.
According to the experiment, we determined that the content of aflatoxin B1 (AFB1), deoxynivalenol (DON) and zearalenone (ZEN) increased with the increase in moisture content in the environment, and the content of these three toxins was highest at a moisture content of 22%, which means that 22% moisture content was most suitable for the growth of the three toxins; the three toxins also showed an increasing trend with the increase in temperature. The most suitable temperature for the growth of aflatoxin B1 (AFB1) and zearalenone (ZEN) is 25°, and the most suitable temperature for the growth of deoxynivalenol (DON) is 30°. The results of this experiment are in agreement with those of Lutz et al. [
4]. In addition, we have offered some comments on the maintenance of grain quality during storage as follows.
Large losses in grain quality endanger human health, increase environmental stress, and affect the sustainable development of agricultural food. Currently, improved storage equipment is the most commonly used method to reduce food quality losses in the storage chain. A considerable number of institutions and companies around the world are using and promoting sealed storage technology, including the WFP, FAO, GrainPro, etc., by providing sealed bags and other storage equipment, thus reducing losses in the food storage chain. It is known from the results of studies that sealed bags can effectively reduce quality losses [
45,
46] and that they are less costly and suitable for economically underdeveloped areas. However, many times, the quality changes in grain are not detectable by the senses; this can increase the safety risks of consuming grain and can cause unpredictable adverse effects on human health.
Our approach is based on monitoring of the storage environment and use of artificial intelligence technology to assist in decision making. The use of artificial intelligence technology not only reduces the cost of manual sampling, but also increases the sampling period. Based on our experiments, we believe that attention should be paid to the influence of environmental factors on grain quality during storage, especially temperature and moisture content, where equilibrium moisture is important [
41]. The stored grain interacts with the storage conditions, the air between the grains and the storage structure, leading to variations in grain quality temperature, moisture content and relative humidity between the grains. The combination of these factors characterizes the storage environment in which the equilibrium moisture content of the grain varies.
The global market for quality grains is growing, and concerns and worries about grain quality are increasing. There is an urgent need to determine ways to reduce losses in the storage phase that will ensure food safety and agricultural sustainability. Many grain managers are investing more in efficient and reliable grain quality management technologies. Grain bin monitoring and artificial intelligence technology-assisted decision-making approaches are storage phase information systems that use information technology to ensure grain quality by controlling and monitoring environment-related factors. This is considered to be an intelligent approach that incorporates emerging information technology, and it is an efficient strategy to significantly reduce grain quality losses and labor costs, an issue that has attracted much attention worldwide. Grain bin monitoring and artificial intelligence technologies can be an option to assist decision making, and some countries have already started to invest in the development of related technologies and have put them to use. Thus, bin monitoring and AI technology-assisted decision making can play an important role in ensuring the safety and the high quality of grain.
The development of a combination of IoT-based grain bin monitoring and AI-assisted decision-making technology will be the main trend in the development of storage technology in the coming years, and monitoring technology and AI technology may further develop into mainstream applications. Since there are many factors that affect grain quality, a more accurate quantitative and qualitative evaluation is the main challenge at present. Therefore, a more accurate assessment of grain quality has important positive implications for grain utilization and safety, for economic development, and for human health.
In order to promote grain bin monitoring and AI technology-assisted decision-making methods, the implementation cost of this technology must be further explored. The ideal monitoring and AI-assisted decision-making technology should be an efficient and effective system that continuously improves grain safety and nutritional value, reduces quality losses, and addresses the international problem of grain storage losses in a sustainable manner. Therefore, a prudent policy should be adopted to enhance food safety and quality and to increase food utilization while promoting the development of information technology.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}